

Deny-All-политики — один из базовых инструментов повышения безопасности кластеров Kubernetes. Но для многих они остаются «черным ящиком» — не все понимают, как их внедрять и настраивать, а также что делать после интеграции. Еще сложнее, если Default Deny надо внедрить на живом кластере.
Я Александр Кожемякин, системный администратор группы разработчиков сервисов VK. В этом материале я на основе нашего опыта расскажу, как повысить безопасность эксплуатации приложений в Kubernetes, какие сетевые политики позволяет использовать Cilium и как безопасно внедрить Deny All.
Материал подготовлен на основе моего выступления на конференции VK Kubernetes Conf «Как внедрить Default Deny на живом кластере и выжить».
С чего и зачем мы начинали
Мы используем Kubernetes версии 1.23. Везде в наших кластерах плоская L3-сеть, а для защиты мы применяем централизованное управление глобальными правилами и формирование правил приложений на уровне кластера.
Вместе с тем у нас не было:
- единого решения для обеспечения безопасности и отказоустойчивости в группе кластеров;
- точечных сетевых политик, как следствие — долгий процесс выдачи доступов (они выдавались классические, на фаерволах, глобально);
- единого инструмента с простым управлением, способного заменить «зоопарк технологий».
В результате мы пришли к необходимости внедрения Deny-All-политик, с помощью которых можно контролировать все процессы и доступы.
В качестве инструмента для их внедрения и основного CNI выбрали Cilium. Это достаточно новый CNI, но в то же время с интересным набором фичей. Например, только у него в бесплатной версии есть policy editor.
Более того, мы не просто внедряли политики на новых кластерах, а еще и собирали cluster-mesh. Это был важный критерий, поэтому выбрали Cilium.
Сейчас для каждого контейнера у нас формируется EBPF, который управляет правилами. Cillium через Cilium Daemon предоставляет много утилит для мониторинга и управления этими правилами.

Также мы используем мультикластерную сеть Cluster mesh. При этом каждый из них работает в собственном сетевом пространстве, но связан с остальными на уровне сети. Таким образом мы можем объединять и распределять рабочие нагрузки в кластерах.

Также мы используем политики Deny-All. Этот режим работы Cillium снижает риски, повышает сетевую безопасность и делает приложения более изолированными. Основной недостаток работы с Deny All — необходимость писать правила для всех сетевых взаимодействий. То есть требуется много ручного труда или хорошо продуманной автоматизации.
Мы используем три основных типа политик:
CiliumNetworkPolicy. Применяется к конкретным сущностями в четко обозначенных рамках.

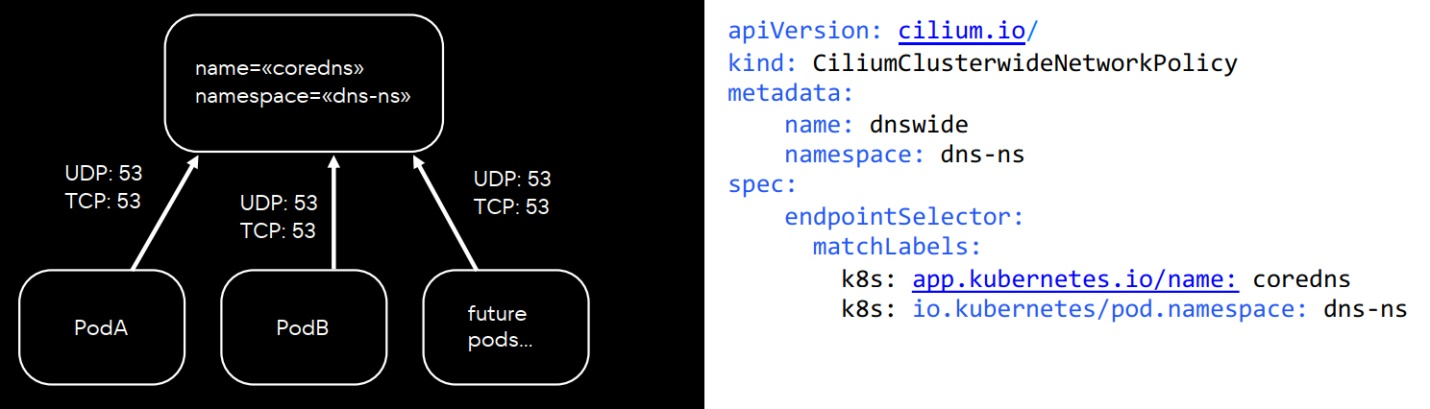
CiliumClusterWideNetworkPolicy. Позволяет выдавать разрешение сразу на весь кластер. Этот тип удобен для кластерных сервисов. Например, мы используем политику для Core DNS, систем логирования, метрик.
Allow-All. Также при включении режима Deny-All мы писали Allow-All-политики. Их использование полезно, так как:
- не блокирует уже работающие приложения;
- позволяет гранулярно делать политики для каждого namespace;
- позволяет заранее выявить граф сетевых взаимодействий.

Примечательно, что политика Allow-All не подходит для production, поскольку не отличается от режима с отключенными политиками. Вместе с тем без нее сложно заранее отследить сетевое взаимодействие, если уже есть готовый, работающий кластер с продовой нагрузкой.
Denny-All — кластер должен выжить
Нашей основной проблемой при внедрении Deny-All-политик был риск полной блокировки сетевых взаимодействий без установленных правил — это абсолютно не подходит для живого кластера. Есть два пути, которые позволяют исключить эту проблему.
Короткий путь
Можно пользоваться встроенными инструментами, чтобы:
- собрать дампы трафика в неймспейсах;
- сгенерировать правила на основе дампов;
- загрузить все правила в кластер.
Один из таких инструментов — Cilium Editor, который:
- помогает удобно познакомиться с синтаксисом политик;
- позволяет за две минуты написать политику «hello world»;
- имеет встроенный генератор политик из дампа.

С его помощью можно двигать кубики, нажимать кнопочки и, не написав ни строчки кода, собрать свою первую политику. Это удобно для знакомства: поможет понять, как все работает, как устроено, как выглядит синтаксис. Но при этом Cilium Editor не дает такой гибкости, как при ручном написании политик.
В теории способ удобен и эффективен, но на практике у него есть несколько недостатков:
- В дампе может не оказаться некоторых правил, а значит, не будет покрыто все сетевое взаимодействие.
- Автогенератор выдает громоздкие конструкции, которые в большинстве случаев можно упростить.
- Генератор не учитывает топологию нашей сети, иногда для адресов из дампа просто появляется
entity: world, что совсем не подходит, если мы делаем кластер безопасным.
Более того, иногда даже продуктовые команды не знают всего алгоритма запросов от приложения. Поэтому учесть все взаимодействия сложно, а если этого не делать, приложение может «падать» без видимых причин.
Описанный способ прост и понятен: чтобы создать политики, не нужно писать манифесты и вникать в нюансы. Это полезно, если:
- нужна тестовая среда для экспериментов;
- нет времени и ресурсов на сложные механики.
При этом придется мириться с тем, что онлайн-редактор поддерживает не все конструкции. Гибкости при создании политик будет меньше, как и вариантов их генерирования.
Чтобы воспользоваться автогенерацией политик, можно, например, загрузить protobuff — конкретный дамп был снят для mesh-server, когда он идет в кубовый api-server.

Что здесь можно улучшить:
- открытый
entity world;
- пустой
endpointSelector.
В нашем случае при создании автоматической политики у mesh-сервера было бы разрешение на обращение к любым внешним IP-адресам, поэтому точность генерируемой политики была бы низкой.
Политика, собранная руками, выглядела бы вот так

Забегая вперед, скажу, что мы выбрали длинный путь.
Длинный путь
Он сложнее, но безопаснее для кластера. Для его реализации мы провели комплексную подготовку:
- Добавили в каждый namespace Allow-All-политики. Это позволило продолжить нашему кластеру работать.
- Включили режим Deny-All.
- В каждом namespace отслеживали сетевые взаимодействия и добавляли политики гранулярно, после чего убирали Allow-All.
Благодаря этому мы смогли:
- детально отслеживать сетевое взаимодействие;
- создавать гибкие правила;
- шаблонизировать под однотипные кластеры с разной адресацией.
Из недостатков — только высокие затраты времени.
Собираем политики
Для сбора политик мы использовали три инструмента:
- Hubble CLI;
- Hubble UI;
- Editor Policy Generator.
Также нам помогало понимание того, как именно работают наши приложения, и наличие настроенного мониторинга сетевой доступности на уровне приложения, который помогает отслеживать события, в том числе блокированные соединения.
Hubble UI
Это бесплатный Open Source-инструмент, который позволяет смотреть графы сетевых взаимодействий, но ограничен только одним неймспейсом. Решение востребовано, когда политики для неймспейсов уже созданы и нужно убедиться, что нет ошибок и других проблем.

В основном мы отсматривали графы для неймспейсов, где уже включены политики, чтобы убедиться, что ничего не упустили; либо в случае, когда мы понимаем, что у приложения есть проблемы с сетью, — можно быстро взглянуть, не виноваты ли в этом политики.
Hubble CLI
По моему мнению, это один из лучших инструментов, который можно использовать при создании сетевых политик. Чтобы работать с Hubble CLI, нужно привыкнуть к синтаксису и научиться писать точные фильтры. Но преимущества решения с лихвой оправдывают этот недостаток:
- можно записывать JSON-файлs для последующей автогенерации политик;
- есть множество фильтров, которые намного богаче, чем в веб-интерфейсе.
Например, в своей практике мы часто использовали такие фильтры:
-
verdict=DROPPED. Позволяет выбрать и отобразить дропы (заблокированные операции) по нужным лейблам, namespace или IP.
-
hubble observe – n, hubble observe – ip. Фильтры для namespace и IP-адресов.
Помимо них, в Hubble CLI есть фильтры, которые позволяют фильтровать трафик вплоть до типа запроса: например, можно отфильтровать только постзапросы, которые попадают в namespace. Такую политику легко шаблонизировать и ограничивать с учетом нужных критериев. При этом она более безопасна и позволяет настроить гранулярный доступ к ресурсам. Для шаблонизации нужны:
- хорошо читаемый и сразу оптимизированный код;
- код, доступный для повторного использования в других контурах (dev, stage);
- соответствующие знания.

Использование шаблонизации хорошо тем, что позволяет получить гранулярные политики, которые можно считать production ready-решением. Но на описание политик требуется много времени.
После того, как политики собраны и задеплоены в кластере, а Allow-All убраны, приложения должны работать практически без дропов. Но все равно обязательно нужны мониторинг и решение для отслеживания дропов в дальнейшем — эти задачи также решает Cilium.
Что дало внедрение Default Deny и использование clustermesh
Сейчас у нас 7 кластеров со включенными Default-Deny-политиками. Благодаря их внедрению:
- Длительность открытия нового доступа для приложения сократилось до длительности выкатки пайплайна. Поскольку мы катим через пайплайн, как только они применяются, приложение получает сетевой доступ.
- Мы стали лучше понимать, что происходит в сети кластера и как клиентские приложения взаимодействуют между собой. Это неизбежно приходит в процессе написания политик.
- Мы получили возможность тестировать гипотезы «на живую» — например, добавить руками правило через kubectl.
Отдельно мы получили выгоды от использования clustermesh:
- Повысили сетевую стабильность.
- Уверены, что приложение получит трафик, даже если отвалятся все Ingress в соседнем кластере.
- Легко управляем доступом приложений, по каким-либо причинам живущим в конкретном кластере.
- Получили единую точку просмотра дампов: если что-то пойдет не так, это видно из любого кластера в mesh.
Вы прямо сейчас можете воспользоваться Kubernetes от VK Cloud. Для тестирования мы начисляем новым пользователям 3 000 бонусных рублей и будем рады вашей обратной связи.
Stay tuned
Присоединяйтесь к Telegram-каналу «Вокруг Kubernetes», чтобы быть в курсе новостей из мира K8s: регулярные дайджесты, полезные статьи, а также анонсы конференций и вебинаров.