
Нам с командой надо было сделать инструмент сбора и визуализации метрик. Мы его создали и хотим поделиться своими наработками, возможно, они будут полезны и для ваших проектов. Собственно, о них — ниже.

У нас каждый день запускается больше 1 500 автотестов. Их-то нам и надо мониторить и анализировать в удобном и понятном виде. Есть ReportPortal, помогающий узнать причину падения и завести задачу в Jira (или в другой системе с API), но, к сожалению, он довольно тяжёлый, встроенные инструменты для анализа скудные, а историчность хранится всего несколько недель. Но у него есть отличный API, которым мы и будем пользоваться.
Как итог возникла необходимость в создании инструмента для мониторинга, анализа и оптимизации автотестов, который можно легко адаптировать под потребности бизнеса при минимальных затратах.
Для достижения поставленных целей мы выбрали путь создания метрик, отражающих качество тестов, проведённых работ и производительности, на основе которых строятся графики, диаграммы и таблицы для анализа и мониторинга. В вопросе выбора технологических решений не было особых колебаний: так как в инфраструктуре отдела уже присутствовали Prometheus и Grafana, то за основу мы взяли именно их. Для написания сервисов использовали очень дружелюбный и удобный Go, где как раз пригодились мои скромные знания синтаксиса и основных фич языка. Вишенкой на торте стало то, что всё ещё должно крутиться в кубере.
Со временем менялись идеи, процессы и варианты реализации, например, изначально сервис на Go с некоторой периодичностью ходил в ReportPortal и забирал со всех систем по последнему регрессионному запуску, обрабатывал их и выдавал метрики в Prometheus, а в Grafana они визуализировались в виде круговых диаграмм. Дальше — больше: масштабировали на смок-запуски, разбивали по бизнес-процессам и прочее, но это не давало нужного эффекта, т. к. отсутствовали метрики, позволяющие оценить отдельные элементы и этапы тестирования.
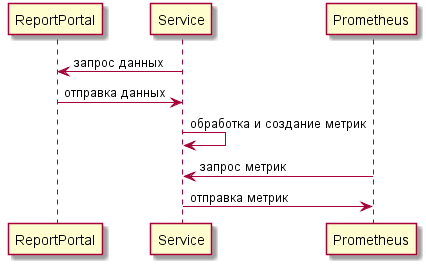
Если рассмотреть укрупнённо, то взаимодействие с ReportPortal выглядело так:
В этом разделе я подробно расскажу про особенности сервиса, фичи и проблемы, с которыми мы с командой столкнулись в процессе реализации. Не претендую на звание крутого кодера, поэтому не надо кидаться тапками за стиль кода и следование каким-либо принципам).
Как было раньше
Сервис регулярно собирал данные с API ReportPortal. Был настроен запуск двух заданий с помощью Cron:
Полученные данные обрабатывались и записывались в метрики с помощью пакета Prometheus для Go. Все используемые метрики — типа Gauge.
Далее все метрики выводились на ручку для сбора самим Prometheus.
С таким подходом возникли следующие проблемы:

В целом всё работало и выполняло свои функции, но спокойно спать не получалось, особенно из-за того, что в Prometheus каждые несколько минут уходил очень большой объём одних и тех же данных.
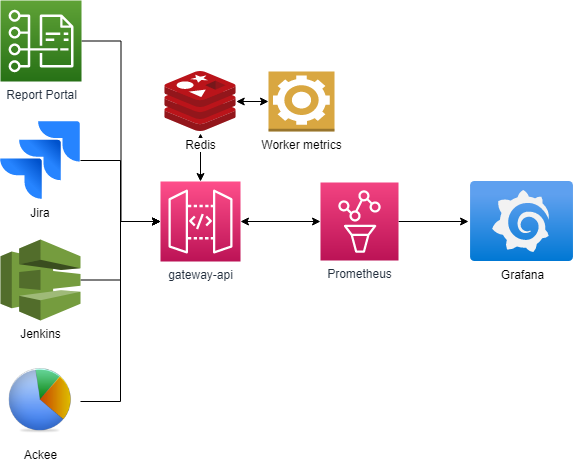
Более универсальный, масштабируемый и отказоустойчивый инструмент, решающий проблему дублирования и дающий возможность создавать метрики смежных систем, например, для Jenkins, Jira и так далее.
В отдельном сервисе мы реализовали API, который отдаёт метрики в Prometheus. В него могут приходить хуки с заданиями от разных сервисов, и в нём же создаются задания по расписанию, после чего они отправляются в Redis по системе pub/sub.
Второй сервис-обработчик (их может быть несколько) слушает топик Redis с заданиями и выполняет их по мере поступления, после чего складывает готовые метрики в Redis, откуда их забирает API-сервис и отдаёт в Prometheus.
Наработки, касающиеся метрик, остались: с ними удобно работать плюс есть возможность выводить их сразу в нужном формате.
Проблема с хранением и дублированием решилась обнулением метрик после того, как они были переданы в Redis: в таком случае туда подают только новые или обновлённые метрики (это вызовет проблему визуализации, но она решаема, об этом — ниже).
Под каждую систему создаётся свой регистр метрик, с помощью которого удобно разделять и выводить их по отдельности.
Как и говорилось, Grafana была, есть и будет. Гибкая, опенсорсная, ещё и дружит с Prometheus — золотце! Мы старались не плодить много дашбордов, а делать их более универсальными с помощью переменных. Сами дашборды условно разделили на два вида: «краткосрочные», показывающие оперативные данные по последним запускам, и «долгосрочные», отображающие ретроспективные данные.
Краткосрочные:
Долгосрочные:
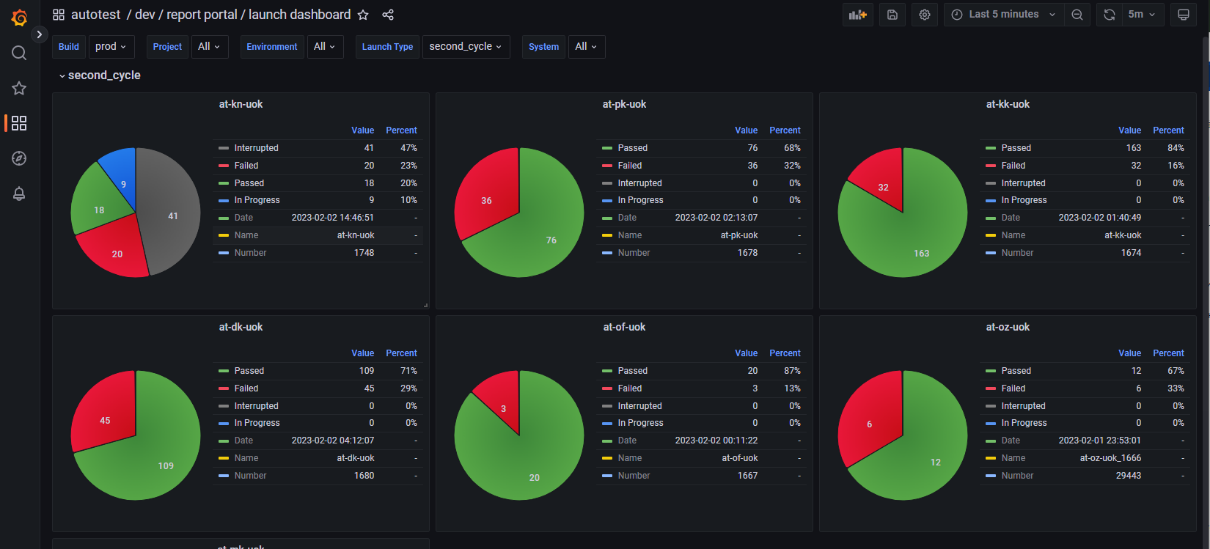
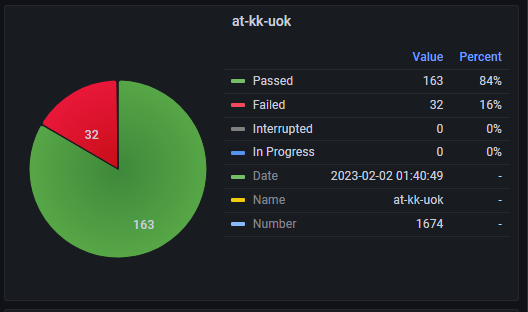
1. Метрики АТ. Отображены диаграммы и таблицы для анализа качества запусков, сценариев и шагов по успешности и длительности во временном интервале. Используется для определения проблемных элементов тестирования.
2. KPI. Отображены графики и числовые значения для анализа ретроспективных данных по запускам регрессионных сборок. Позволяет отследить динамику, оценить результаты изменений, контролировать количество сценариев, шагов и проектов, участвующих в тестировании, а также прогнозировать проблемы.
Практически все графики и диаграммы кликабельны с возможностью перейти в ReportPortal для просмотра логов конкретного элемента, а также провалиться во вспомогательный дашборд с более детальной информацией, например, посмотреть историю использования конкретного сценария в различных регрессионных запусках.
1. Качества:
2. Количества:
3. Длительности:
1. Диаграммы:
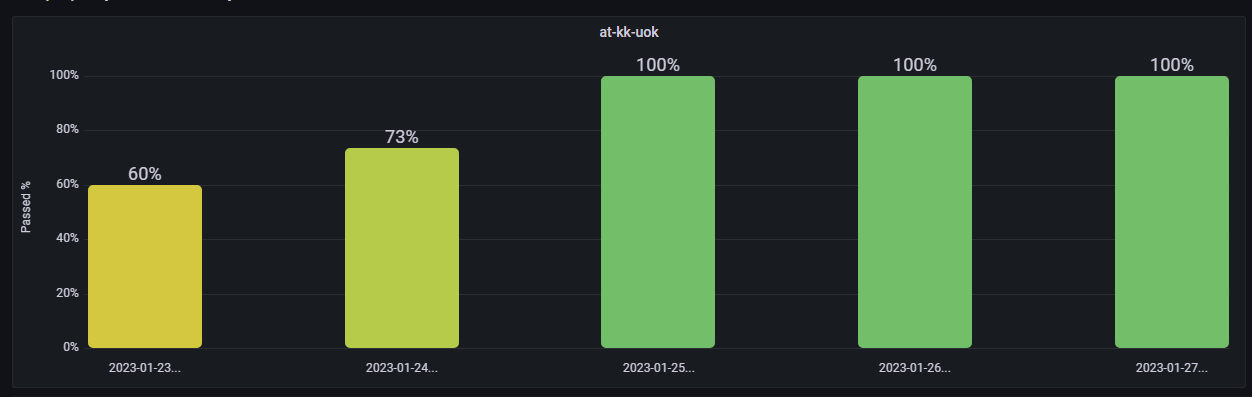
2. Графики.
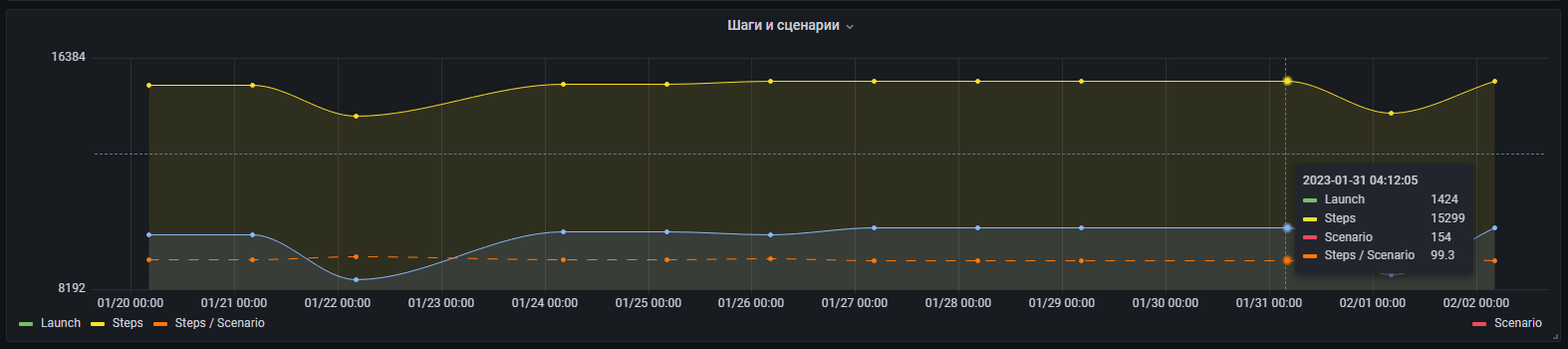
3. «Датчики» — числовые показатели.
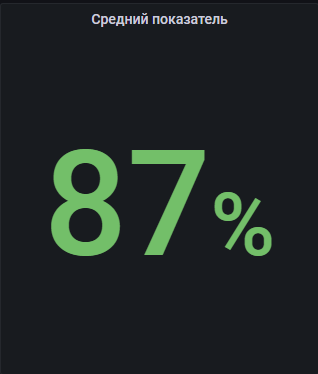
4. Таблицы.

Во время работы с Grafana для удобства использования появлялась необходимость внедрения в панели дополнительных возможностей. Какие-то фичи показались мне не совсем очевидными, а о каких-то просто напомню, что они существуют:
1. Кликабельность панелей.
В лейблы метрик, которые отвечают за конкретный тестовый элемент, добавлена ссылка на ReportPortal: на панелях, где отображена информация о конкретном запуске, сценарии или шаге, есть возможность по клику открыть этот элемент в ReportPortal и посмотреть логи, скриншоты и прочую сопутствующую информацию. Для некоторых панелей реализована возможность по клику провалиться в отдельный дашборд, на котором будет собрана дополнительная информация по элементу, например, историчность, дочерние элементы, длительность и т. д. В интерфейсе Grafana можно собрать нужный url по частям из значений лейблов и строк для того, чтобы не создавать несколько дополнительных лейблов с id элементов, входящих в путь до искомого элемента. Для этого был создан один лейбл, в который записывался готовый url, собранный на этапе обработки данных в воркере (скриншоты).
2. Отображение только последнего зафиксированного значения метрики.
Стандартно метрика поддерживается во времени, и на графиках выводится множество её значений. В нашем же случае такой необходимости нет, достаточно только знать её конечный результат, так как метрика привязана к конкретному элементу, а не процессу, вдобавок это позволяет более гибко визуализировать нужные показатели. Это достигается путём использования метрики в формате Table и типа Range, что позволяет учитывать не только метрики, которые пришли в последней итерации скрейпинга Prometheus, но и все предыдущие.
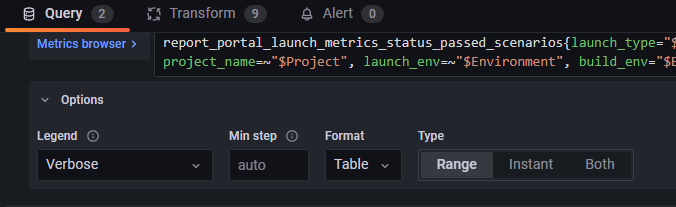
Далее во вкладке Transform необходимо сократить значения до последнего в метрике с помощью Reduce → Reduce fields/Last.
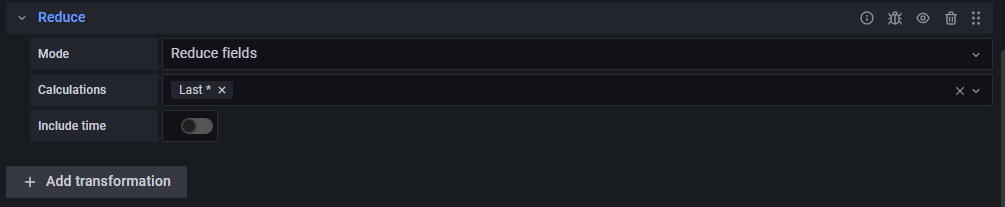
Если перед этим необходимо сгруппировать метрики по какому-либо параметру, то сокращение полей надо производить в функции Group by.
Использование этой функции решает проблему необходимости постоянно передавать метрику для её отображения на панелях (иначе получаем No Data).
3. Создание кастомной временной шкалы для использования стандартного таймлайна в Grafana.
Так как долгое время метрики постоянно дублировались, то было невозможно вывести метрику в момент её последнего изменения, да и к тому же выгоднее было видеть результат в соответствии со временем запуска того или иного кейса, а не момент его изменения.
Была попытка создать полностью кастомную метрику на Go со своей временной меткой, которая равнялась бы времени запуска. Создать получилось, но результат не увенчался успехом, так как в скрейпинге Prometheus жёстко зашито, что временная метка, если она присутствует, не должна отличаться от реального времени более чем на 10 минут: просто приходила ошибка от Прометея.
Но нашёлся другой, даже более элегантный выход, о котором почему-то нигде не было рассказано: всё в той же вкладке трансформаций есть функция изменения типов данных.
Помимо числовых и строковых, из лейбла можно сделать метку времени, и — «О чудо, оно работает!». Передаём в лейбл нужную нам дату в удобном для нас формате, группируем по этому лейблу, оставляем значимые для нас лейблы с помощью calculate → last, далее меняем тип данных нашего лейбла на Time, и произойдёт магия: график перестроится по датам из лейблов!
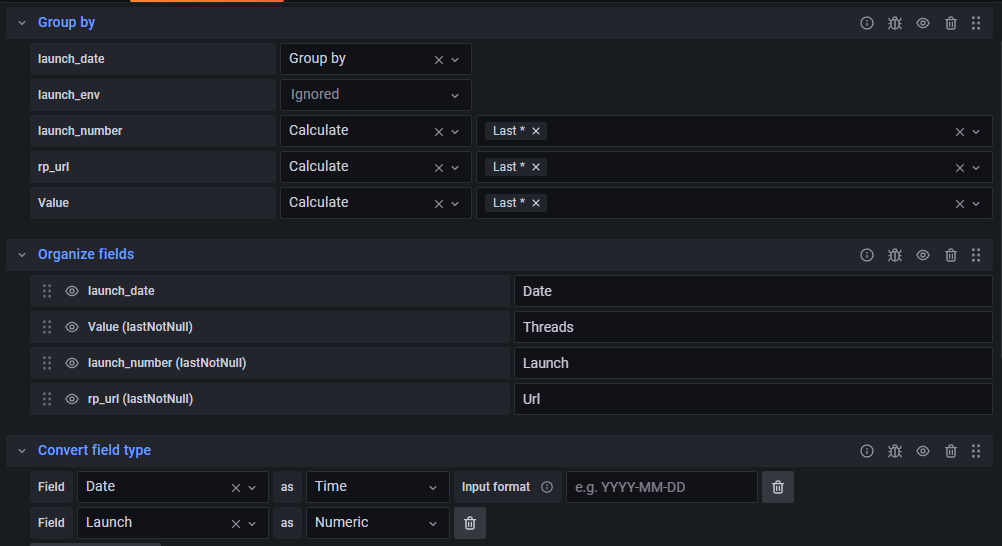
Не забудьте поизучать вкладку трансформаций: очень вероятно, что там найдётся нужная вам функция. Помните и о вкладке Overrides в опциях панели: там можно красиво причесать ваши графики.
Получился устойчивый инструмент с лёгкой масштабируемостью, в том числе — под смежные задачи, связанные с мониторингом и не только.
Grafana оказалась действительно гибким и удобным инструментом для визуализации.
В итоге мы имеем:
В общем и целом я доволен возможностями нашей связки: Grafana симпатичная и шустрая, а сервисы можно легко масштабировать для взаимодействия с новыми приложениями.
Например, сейчас я дорабатываю метрики от Jenkins и Jira, также есть идея интегрировать API-сервис в CI, но это уже совсем другая история.
У нас каждый день запускается больше 1 500 автотестов. Их-то нам и надо мониторить и анализировать в удобном и понятном виде. Есть ReportPortal, помогающий узнать причину падения и завести задачу в Jira (или в другой системе с API), но, к сожалению, он довольно тяжёлый, встроенные инструменты для анализа скудные, а историчность хранится всего несколько недель. Но у него есть отличный API, которым мы и будем пользоваться.
Как итог возникла необходимость в создании инструмента для мониторинга, анализа и оптимизации автотестов, который можно легко адаптировать под потребности бизнеса при минимальных затратах.
Цели
- Визуализировать результаты отработки сборок, сценариев и шагов, чтобы сравнивать их на разных средах и временных интервалах.
- Мониторить метрики качества, количества, производительности.
- Оптимизировать АТ (проблемные запуски/сценарии/шаги), что позволит сократить TTM (бизнес).
- Создать возможность ретроспективного анализа, чтобы получить историчные данные.
- «Игра на перспективу» — способность прогнозировать возможные проблемы, связанные с качеством тестов и инфраструктурой.
База
Для достижения поставленных целей мы выбрали путь создания метрик, отражающих качество тестов, проведённых работ и производительности, на основе которых строятся графики, диаграммы и таблицы для анализа и мониторинга. В вопросе выбора технологических решений не было особых колебаний: так как в инфраструктуре отдела уже присутствовали Prometheus и Grafana, то за основу мы взяли именно их. Для написания сервисов использовали очень дружелюбный и удобный Go, где как раз пригодились мои скромные знания синтаксиса и основных фич языка. Вишенкой на торте стало то, что всё ещё должно крутиться в кубере.
Технологический стэк
- Go — язык, на котором написан сервис для сбора и агрегации данных.
- Prometheus — инструмент хранения метрик (и не только).
- Grafana — инструмент для визуализации данных.
- ReportPortal — инструмент, агрегирующий тестовые данные.
- k8s — система оркестрации и контроля.
- Redis — СУБД.
Со временем менялись идеи, процессы и варианты реализации, например, изначально сервис на Go с некоторой периодичностью ходил в ReportPortal и забирал со всех систем по последнему регрессионному запуску, обрабатывал их и выдавал метрики в Prometheus, а в Grafana они визуализировались в виде круговых диаграмм. Дальше — больше: масштабировали на смок-запуски, разбивали по бизнес-процессам и прочее, но это не давало нужного эффекта, т. к. отсутствовали метрики, позволяющие оценить отдельные элементы и этапы тестирования.
Что сделано?
Если рассмотреть укрупнённо, то взаимодействие с ReportPortal выглядело так:
Процесс получения метрик автотестов
Сервис на языке Go
В этом разделе я подробно расскажу про особенности сервиса, фичи и проблемы, с которыми мы с командой столкнулись в процессе реализации. Не претендую на звание крутого кодера, поэтому не надо кидаться тапками за стиль кода и следование каким-либо принципам).
Как было раньше
Сервис регулярно собирал данные с API ReportPortal. Был настроен запуск двух заданий с помощью Cron:
- «Короткое» — каждые 10 минут собирались данные о качестве запусков.
- «Расширенное» — каждые один–четыре часа в зависимости от времени суток собирались данные для остальных метрик.
func CreateCron() (cr *cron.Cron, wgr *sync.WaitGroup) {
wg := &sync.WaitGroup{}
c := cron.New(cron.WithSeconds())
c.AddFunc("0 */10 * * * *", func() {
wg.Add(1)
logging.Log.Debug("Start Short Task")
task.RunShortTask()
wg.Done()
})
c.AddFunc("0 0 0-12,13-23/4 * * *", func() {
wg.Add(1)
logging.Log.Debug("Start Advanced Task")
task.RunAdvancedTask()
wg.Done()
})
return c, wg
}
Полученные данные обрабатывались и записывались в метрики с помощью пакета Prometheus для Go. Все используемые метрики — типа Gauge.
var (
launchResultsPassedScenariosVec = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Namespace: "report_portal",
Subsystem: "launch_metrics",
Name: "status_passed_scenarios",
Help: "Number of passed cases in launch.",
},
[]string{
"project_name",
"launch_name",
"launch_number",
"launch_date",
"launch_type",
"launch_env",
"build_env",
"critical",
"system",
"rp_url",
"replay",
},
)
.
.
.
)
func init() {
prometheus.MustRegister(launchResultsPassedScenariosVec)
.
.
.
}
func ResetRpMetrics() {
launchResultsPassedScenariosVec.Reset()
.
.
.
}
func SetLaunchResults(projectName, launchName, launchType, launchEnv string, launchNumber, launchDate, totalScenarios,
passedScenarios, failedScenarios, interruptedScenarios, inProgressScenarion int, buildEnv, rpUrl, system, replay string) {
launchNumberStr := strconv.Itoa(launchNumber)
launchDateStr := tools.FormatDate(launchDate)
launchResultsPassedScenariosVec.WithLabelValues(projectName, launchName, launchNumberStr, launchDateStr, launchType, launchEnv, buildEnv, "", system, rpUrl, replay).Set(float64(passedScenarios))
.
.
.
}
Далее все метрики выводились на ручку для сбора самим Prometheus.
srv.HandleFunc("/prometheus", promhttp.Handler().ServeHTTP)С таким подходом возникли следующие проблемы:
- Передача слишком большого объёма данных в Prometheus: стандартно метрики собираются каждые 10 минут, но сервис обновляет и создаёт их из «расширенного» задания только несколько раз в сутки, в результате раз за разом накапливается и передаётся большое количество неизменных данных.
- Создание множества метрик из-за уникальности значений лейблов.
- Метрики держатся в кеше, что избыточно нагружает сервис (проблема решалась регулярными ресетами метрик, но глобально она осталась).
- Невозможность нативно проставить временную метку, отличающуюся более чем на 10 минут от реального времени. Была написана кастомная метрика для проставления временной метки, равной началу теста из прошлого, но Prometheus не позволяет поставить временную метку, отличающуюся более чем на 10 минут от настоящего времени.
В целом всё работало и выполняло свои функции, но спокойно спать не получалось, особенно из-за того, что в Prometheus каждые несколько минут уходил очень большой объём одних и тех же данных.
Было решено сделать
Более универсальный, масштабируемый и отказоустойчивый инструмент, решающий проблему дублирования и дающий возможность создавать метрики смежных систем, например, для Jenkins, Jira и так далее.
В отдельном сервисе мы реализовали API, который отдаёт метрики в Prometheus. В него могут приходить хуки с заданиями от разных сервисов, и в нём же создаются задания по расписанию, после чего они отправляются в Redis по системе pub/sub.
Второй сервис-обработчик (их может быть несколько) слушает топик Redis с заданиями и выполняет их по мере поступления, после чего складывает готовые метрики в Redis, откуда их забирает API-сервис и отдаёт в Prometheus.
Наработки, касающиеся метрик, остались: с ними удобно работать плюс есть возможность выводить их сразу в нужном формате.
Проблема с хранением и дублированием решилась обнулением метрик после того, как они были переданы в Redis: в таком случае туда подают только новые или обновлённые метрики (это вызовет проблему визуализации, но она решаема, об этом — ниже).
Под каждую систему создаётся свой регистр метрик, с помощью которого удобно разделять и выводить их по отдельности.
func pushRpMetrics() error {
// Передаем в конвертер указатель на prometheus.Registry,
// в который были записаны только метрики Report Portal
text, err := utils.MetricsToText(rpmetrics.GetRpRegistry())
if err != nil {
return err
}
// Следом обнуляем метрики
rpmetrics.ResetRpMetrics()
// Пушим в Redis
if err = redis.PushToList("metrics", text.String()); err != nil {
return err
}
return nil
}
Визуализация
Как и говорилось, Grafana была, есть и будет. Гибкая, опенсорсная, ещё и дружит с Prometheus — золотце! Мы старались не плодить много дашбордов, а делать их более универсальными с помощью переменных. Сами дашборды условно разделили на два вида: «краткосрочные», показывающие оперативные данные по последним запускам, и «долгосрочные», отображающие ретроспективные данные.
Дашборды в Grafana
Краткосрочные:
- Регрессионный. Отображаем оперативные данные качества последнего запуска, группируем по системам, проектам и т. д. Используем круговые диаграммы с разбивкой на успешные, упавшие, остановленные или «в процессе». Поддерживается кликабельность, чтобы провалиться в ReportPortal для просмотра логов и более детального анализа.
- Критичность. Данные о прохождении тестов, разделённые по критичности. Аналогичен регрессионному, но каждый проект разбит по критическим тегам: minor, major, critical.
- Смок. Аналогичен регрессионному, но отображаются проекты, отвечающие за смок-тестирование.
Долгосрочные:
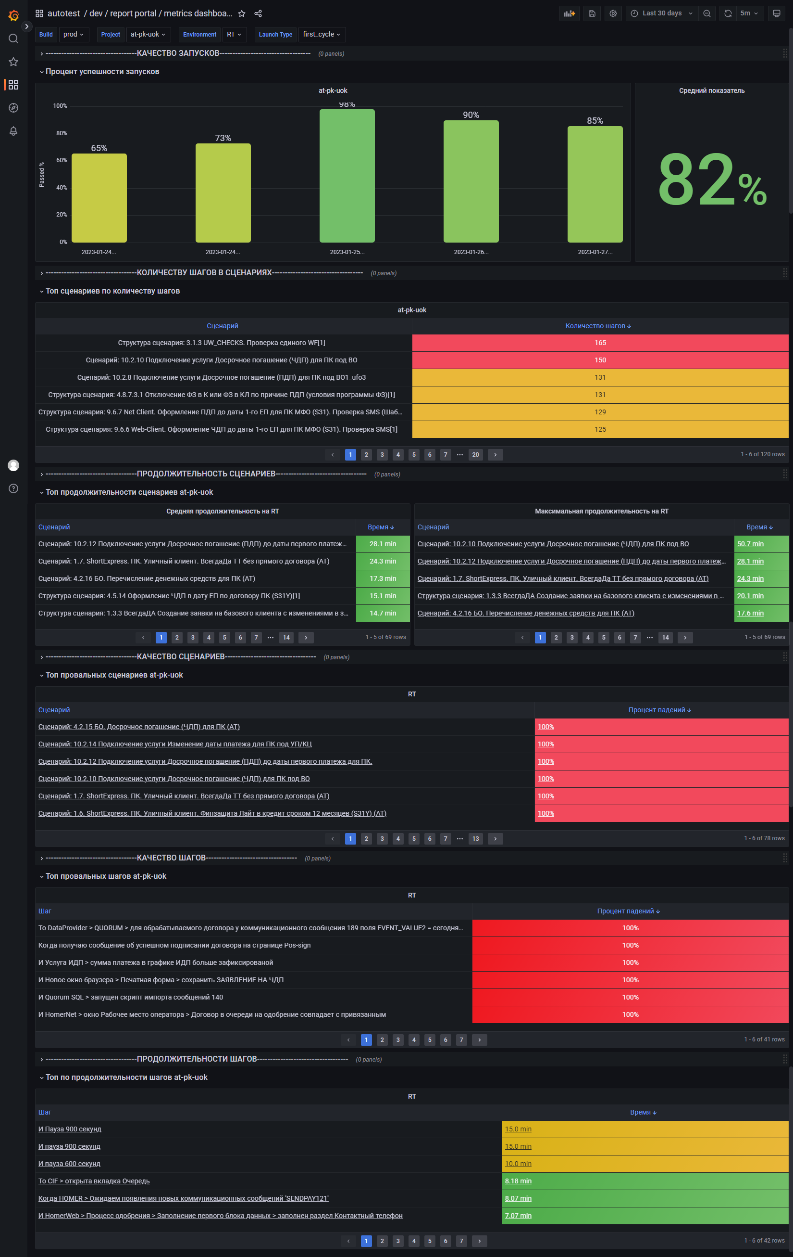
1. Метрики АТ. Отображены диаграммы и таблицы для анализа качества запусков, сценариев и шагов по успешности и длительности во временном интервале. Используется для определения проблемных элементов тестирования.
Скриншот
2. KPI. Отображены графики и числовые значения для анализа ретроспективных данных по запускам регрессионных сборок. Позволяет отследить динамику, оценить результаты изменений, контролировать количество сценариев, шагов и проектов, участвующих в тестировании, а также прогнозировать проблемы.
Скриншот
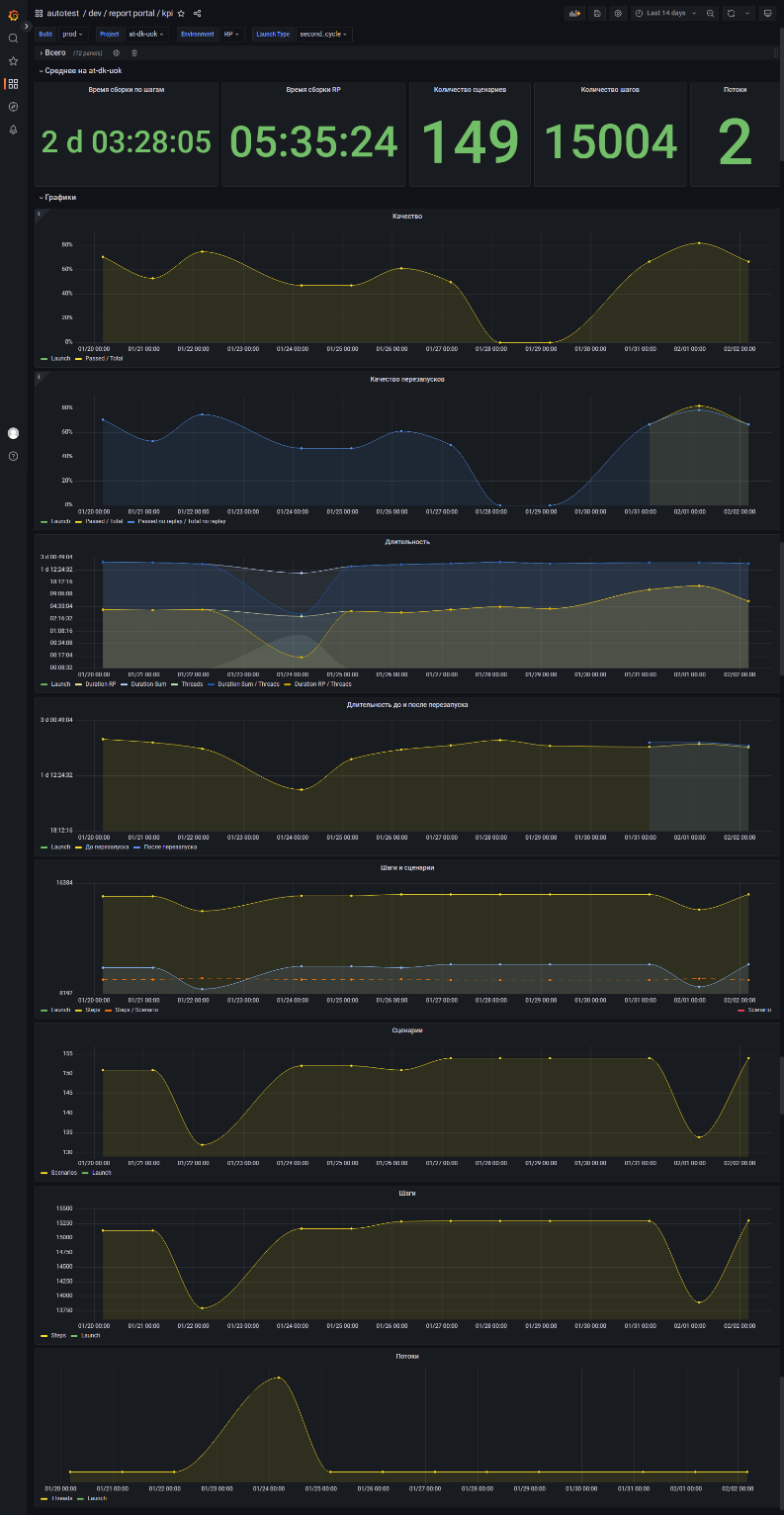
Практически все графики и диаграммы кликабельны с возможностью перейти в ReportPortal для просмотра логов конкретного элемента, а также провалиться во вспомогательный дашборд с более детальной информацией, например, посмотреть историю использования конкретного сценария в различных регрессионных запусках.
На дашбордах пока выводим метрики:
1. Качества:
- запусков;
- сценариев;
- шагов.
2. Количества:
- сценариев в запуске;
- шагов в сценарии.
3. Длительности:
- запусков;
- сценариев;
- шагов.
Для визуализации используем:
1. Диаграммы:
- круговые;
- столбчатые.
2. Графики.
3. «Датчики» — числовые показатели.
4. Таблицы.
Особенности реализации
Во время работы с Grafana для удобства использования появлялась необходимость внедрения в панели дополнительных возможностей. Какие-то фичи показались мне не совсем очевидными, а о каких-то просто напомню, что они существуют:
1. Кликабельность панелей.
В лейблы метрик, которые отвечают за конкретный тестовый элемент, добавлена ссылка на ReportPortal: на панелях, где отображена информация о конкретном запуске, сценарии или шаге, есть возможность по клику открыть этот элемент в ReportPortal и посмотреть логи, скриншоты и прочую сопутствующую информацию. Для некоторых панелей реализована возможность по клику провалиться в отдельный дашборд, на котором будет собрана дополнительная информация по элементу, например, историчность, дочерние элементы, длительность и т. д. В интерфейсе Grafana можно собрать нужный url по частям из значений лейблов и строк для того, чтобы не создавать несколько дополнительных лейблов с id элементов, входящих в путь до искомого элемента. Для этого был создан один лейбл, в который записывался готовый url, собранный на этапе обработки данных в воркере (скриншоты).
2. Отображение только последнего зафиксированного значения метрики.
Стандартно метрика поддерживается во времени, и на графиках выводится множество её значений. В нашем же случае такой необходимости нет, достаточно только знать её конечный результат, так как метрика привязана к конкретному элементу, а не процессу, вдобавок это позволяет более гибко визуализировать нужные показатели. Это достигается путём использования метрики в формате Table и типа Range, что позволяет учитывать не только метрики, которые пришли в последней итерации скрейпинга Prometheus, но и все предыдущие.
Далее во вкладке Transform необходимо сократить значения до последнего в метрике с помощью Reduce → Reduce fields/Last.
Если перед этим необходимо сгруппировать метрики по какому-либо параметру, то сокращение полей надо производить в функции Group by.
Использование этой функции решает проблему необходимости постоянно передавать метрику для её отображения на панелях (иначе получаем No Data).
3. Создание кастомной временной шкалы для использования стандартного таймлайна в Grafana.
Так как долгое время метрики постоянно дублировались, то было невозможно вывести метрику в момент её последнего изменения, да и к тому же выгоднее было видеть результат в соответствии со временем запуска того или иного кейса, а не момент его изменения.
Была попытка создать полностью кастомную метрику на Go со своей временной меткой, которая равнялась бы времени запуска. Создать получилось, но результат не увенчался успехом, так как в скрейпинге Prometheus жёстко зашито, что временная метка, если она присутствует, не должна отличаться от реального времени более чем на 10 минут: просто приходила ошибка от Прометея.
Но нашёлся другой, даже более элегантный выход, о котором почему-то нигде не было рассказано: всё в той же вкладке трансформаций есть функция изменения типов данных.
Помимо числовых и строковых, из лейбла можно сделать метку времени, и — «О чудо, оно работает!». Передаём в лейбл нужную нам дату в удобном для нас формате, группируем по этому лейблу, оставляем значимые для нас лейблы с помощью calculate → last, далее меняем тип данных нашего лейбла на Time, и произойдёт магия: график перестроится по датам из лейблов!
Не забудьте поизучать вкладку трансформаций: очень вероятно, что там найдётся нужная вам функция. Помните и о вкладке Overrides в опциях панели: там можно красиво причесать ваши графики.
Результат
Получился устойчивый инструмент с лёгкой масштабируемостью, в том числе — под смежные задачи, связанные с мониторингом и не только.
Grafana оказалась действительно гибким и удобным инструментом для визуализации.
В итоге мы имеем:
- Инструмент, позволяющий найти проблемные места в процессе тестирования.
- Визуализацию показателей качества, количества и производительности с возможностью сравнения во времени.
- Точки развития.
В общем и целом я доволен возможностями нашей связки: Grafana симпатичная и шустрая, а сервисы можно легко масштабировать для взаимодействия с новыми приложениями.
Например, сейчас я дорабатываю метрики от Jenkins и Jira, также есть идея интегрировать API-сервис в CI, но это уже совсем другая история.
bekanur98
Также можно добавить алерты, чтобы когда показатели в графане доходят до критического показателя отправлять сообщения в дискорд/слак с нужным тэгом команды и вовремя реагировать