
Всем привет! Меня зовут Андрей, я — разработчик в БФТ-Холдинге.
С каждым днем проекты становятся все сложнее и масштабнее. Для того, чтобы выстроить взаимодействие между их многочисленными компонентами, используются брокеры сообщений. Но возникают закономерные вопросы: какой из них выбрать? В каком случае использовать тот или иной брокер? Как с помощью брокеров достичь максимальную производительность и гибкость в обработке данных?
В статье постараемся разобраться в этих вопросах и сравнить особенности, достоинства и недостатки двух популярных брокеров: Apache Kafka и RabbitMQ. Тема будет интересна разработчикам на проектах, где требуется обмен информацией между разными компонентами или системами. Поехали!
Содержание
RabbitMQ

RabbitMQ Написан на Erlang и совместим с большинством популярных ОС. В отношении сервиса он работает по принципу «Умный брокер, тупой потребитель». Это означает, что брокер берет на себя много дополнительных обязательств. Например, следит за прочитанными сообщениями и удаляет их из очереди. Или сам организует процесс распределения сообщений между подписчиками.
RabbitMQ изначально реализует протокол AMQP. Но может поддерживать и другие стандартизированные протоколы с помощью плагинов. Например, MQTT, STOMP, HTTP и прочие.
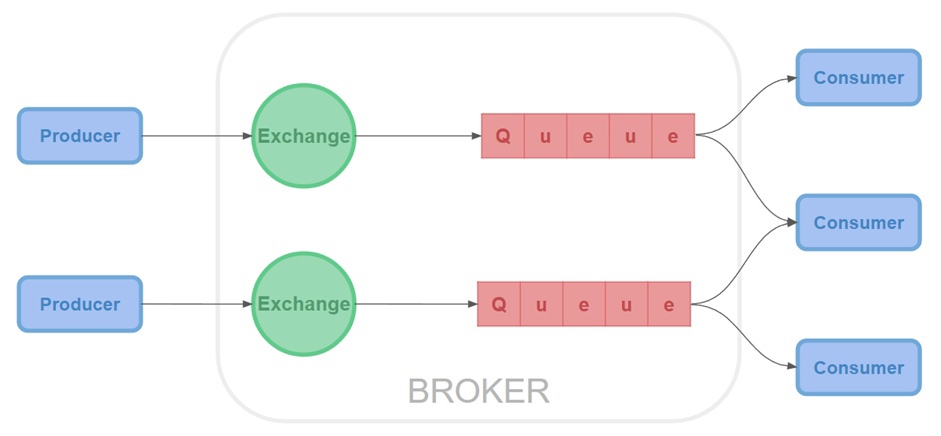
Ниже приведены компоненты RabbitMQ:
Производитель (Producer) — это приложения или сервисы, которые создают и отправляют сообщения в RabbitMQ.
-
Обменник (Exchange) — в него отправляются сообщения. Он маршрутизирует сообщения в очередь или в очереди на основе созданных биндингов между ним и очередью.
Direct Exchange — сообщения отправляются в каждую очередь, которая имеет один и тот же ключ маршрутизации.
-
Topic Exchange — в отличие от direct exchange, задает ключ по шаблону. При создании шаблона используются ноль или более слов, состоящие из цифр от 0 до 9, букв английского алфавита (строчных и заглавных, разделенных точкой), а также символы * и #, где:
* — может быть заменена на ровно 1 слово
# — может быть заменена на 0 или более слов
Fanout exchange — здесь все сообщения доставляются во все очереди, даже если в сообщении задан routing key.
-
Headers Exchange — отправляет сообщения в очереди на основе сравнения пар с определенным признаком x-match:
Если x-match со значением any, то сообщение маршрутизируется при частичном совпадении пар.
По умолчанию x-match равен all. Это означает, что сообщение маршрутизируется только при полном совпадении пар.
Биндинг (Binding) — условие, по которому обменник определяет, в какую из очередей сообщения должны попадать.
Очередь (Queue) — структура данных, которая хранит ссылки на сообщения и отдает копии сообщений потребителям.
Потребитель (Consumer) — получает и обрабатывает сообщения от RabbitMQ. Это может быть любое приложение или сервис, который может подключаться к RabbitMQ и подписываться на сообщения.
Кратко работу RabbitMQ можно описать следующим образом:
Производители отправляют сообщения в exchange;
Exchange отправляет сообщения в очереди и на другие обменники;
При получении сообщения RabbitMQ отправляет отправителям подтверждения;
Потребители поддерживают постоянные TCP-соединения с RabbitMQ и объявляют, какую очередь они получают;
RabbitMQ направляет сообщения потребителям;
Потребители отправляют подтверждения об успешном получении сообщения или ошибке;
После успешного получения сообщение удаляется из очереди.
Apache Kafka

На самом деле, Apache Kafka позиционирует себя не столько брокером сообщений, сколько стриминговой платформой. То есть, кроме распределений сообщений Kafka еще может использоваться для поиска событий, отслеживания веб-активности и метрик. Также ее можно использовать как базу данных. Сама Kafka написана на Java и Scala компанией LinkedIn.
Kafka работает по принципу «Умный потребитель, тупой брокер». Так, в отличие от RabbitMQ, Kafka не занимается контролем и распределением сообщений, то есть, не выполняется лишняя логика в брокере. Благодаря этому Kafka специализируется на высокой пропускной способности данных и низкой задержке для обработки потоков данных в реальном времени.
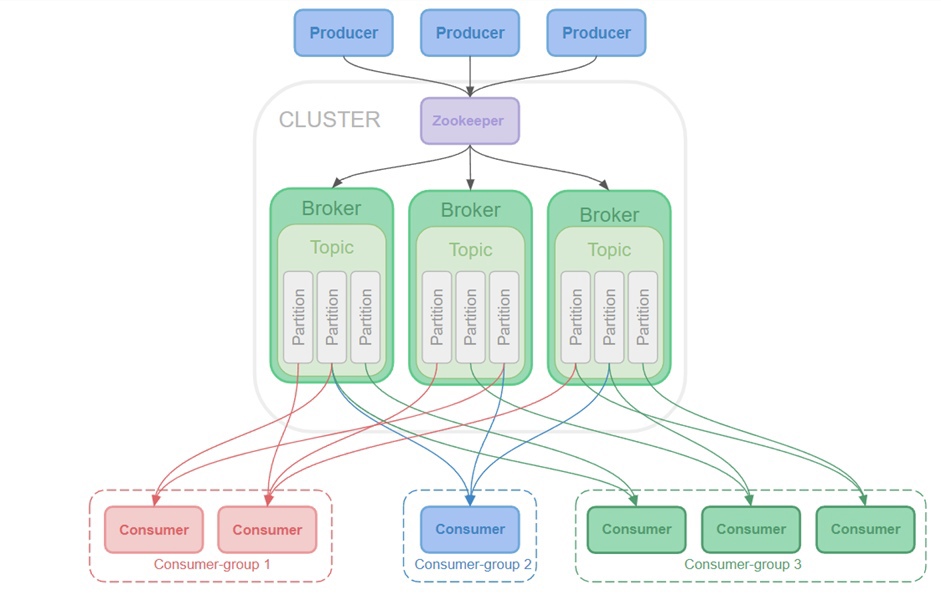
Основные концепции Kafka:
Производитель (Producer) — в отличие от RabbitMQ, в Apache Kafka отсутствуют очереди. Вместо этого приложения или сервисы отправляют сообщения в определённые топики.
Топик (Topic) — это элемент, который объединяет все сообщения, которые относятся к одной тематике. Сами сообщения в топике по умолчанию хранятся одну неделю. При этом мы вправе выставить любое значение.
Партиция (Partition) — в каждом топике есть партиции, одна или более. Они разделяют очереди, чтобы уберечь топик от переполнения.
Сообщения, отправленные производителем, попадают в конец топика одной из партиций.Брокер — это сервер Kafka, через который проходят топики с партициями. Он отвечает за приём и хранение сообщений с последующей передачей потребителю. Каждый брокер хранит у себя несколько партицией и разных топиков.
Репликация — помимо того, что топик разделяется на партиции, партии разделяются в свою очередь на реплики. То есть, партиции дублируются на другие брокеры. Это нужно на случай, если вдруг один из брокеров выйдет из строя. Если это произошло, мы можем использовать партиции с уцелевшего брокера.
Кластер (Cluster) — если бы брокер был один, то была бы проблема с его производительностью и надежностью данных. Поэтому для диверсификации этих самых данных добавляются новые брокеры. Они общаются между собой, создавая кластер.
Zookeeper — всё это должен кто-то координировать, и делает это Zookeeper. Это небольшая база данных, которая оперативно работает на операции чтения и медленно на операции записи. То есть, Zookeeper идеально подходит для хранения метаданных кластера или состояния кластера. Он хранит в себе конфигурацию кластера, его состояние и то, какие в нем есть брокеры, топики и партиции. В общем, всю важную информацию Apache Kafka.
Потребитель (Consumer) — получает одно или несколько сообщений на определенную тему. В отличии от RabbitMQ, потребитель сам ходит за сообщениями.
Группа потребителей (Consumer-group) — это способ организации и координации множества потребителей сообщений. Когда у нас есть несколько потребителей, связанных с одной или несколькими темами Kafka, мы можем объединить их в группу. Каждой группе потребителей назначается определенное количество партиций для чтения. Когда новые сообщения поступают в тему, Kafka автоматически распределяет их между подписчиками внутри группы, чтобы каждый потребитель читал только свою часть данных. Таким образом, Consumer Group позволяет параллельно обрабатывать сообщения и обеспечивает масштабируемость и отказоустойчивость системы.
Коммитеры (Commiters) — отвечают за сохранение положения потребителя в топике, чтобы при перезапуске приложения он мог продолжить чтение сообщений с последней подхватки.
В целом, архитектура Apache Kafka очень гибкая и позволяет разрабатывать высокопроизводительные приложения для обработки потоков данных в режиме реального времени. Она может быть интегрирована в различные экосистемы и использована для решения различных задач, включая анализ данных, мониторинг и обработку событий.
Kafka Streams — это библиотека, которая позволяет обрабатывать и анализировать потоки данных в режиме реального времени, используя Apache Kafka. Она предоставляет удобный Java API для выполнения различных операций обработки данных, таких как фильтрация, преобразование и агрегация данных.
Основное преимущество Kafka Streams состоит в том, что она позволяет писать код обработки данных, используя обычные языки и библиотеки программирования, включая Kotlin, Java и Scala, что делает ее доступной для широкой аудитории программистов.
KTable — это промежуточное представление данных, которые доступны для чтения и записи в Apache Kafka Streams.
KTable работает на основе ключей (keys) и значений (values). Он организован как состояние, обрабатываемое в режиме реального времени.
Каждый ключ связывается со своим значением в локальной таблице и обновляется при получении новых сообщений от соответствующего топика Kafka. Каждое обновление в KTable приводит к изменению соответствующей записи в таблице. Как результат, KTable отображает текущее состояние данных из топика.
Сравнение RabbitMQ и Apache Kafka
Основные отличия Apache Kafka и RabbitMQ – это принципиально разные модели доставки сообщений. Apache Kafka работает по принципу pull: получатели сами достают из топика нужные им сообщения. RabbitMQ работает по принципу push: брокер сам отправляет сообщения получателям.
Архитектура: Apache Kafka работает в лог-центричной архитектуре, что подходит для обработки потоков данных, а RabbitMQ — в централизованной архитектуре, что позволяет легко управлять очередями.
Протоколы: RabbitMQ поддерживает множество протоколов обмена сообщениями, к примеру, AMQP, STOMP, MQTT. А Apache Kafka использует свой собственный протокол.
Хранение сообщений: после подтверждения о доставке RabbitMQ удаляет сообщение, а Apache Kafka сохраняет все сообщения, пока не наступит запланированная очистка.
Приоритетность: приоритет для всех сообщений в Kafka одинаков и его нельзя изменить, а RabbitMQ позволяет назначать приоритет сообщениям. Также Kafka гарантирует доставку сообщений в определенном порядке.
Масштабируемость: Kafka легко масштабируется горизонтально, что позволяет добавлять новые брокеры для обработки большего объема данных. RabbitMQ также может масштабироваться горизонтально, но это требует большего количества настроек и управления.
Распределение сообщений: RabbitMQ предлагает множество опций роутинга и содержит широкий спектр паттернов обработки сообщений (publish/subscribe, request/reply и т.д.).
В Apache Kafka, также присутствует функционал publish/subscribe, но она сфокусирована на поддержке большого количества потребителей и обеспечивает упорядоченное хранение и обработку событий.
Сценарии использования
Apache Kafka, пожалуй, является одним из самых популярных инструментов для работы с потоковыми данными. Он почти уникален в своем подходе к обработке данных в реальном времени. Вот почему ему так подходят следующие паттерны:
Log Aggregation (Сбор логов)
Это процесс централизованного сбора лог-файлов из различных источников. Этот процесс обычно включает в себя сбор, обработку, хранение и анализ этих логов.
Apache Kafka идеально подходит для этой задачи, потому что это надежная, распределенная система, которая может обрабатывать большие объемы данных в реальном времени.
Также Kafka имеет несколько ключевых особенностей, которые делают ее идеальным выбором для агрегации логов:
Длительное хранение данных: в Kafka можно настроить время хранения данных (retention time), что позволяет хранить входящие данные в течение долгого времени (например, нескольких недель или месяцев), что очень полезно для анализа логов.
Фильтрация: потребители могут выбирать, какие сообщения они хотят получить по темам или другим критериям, что также полезно для анализа логов.
Репликация: Kafka автоматически реплицирует данные на несколько серверов, что обеспечивает избыточность данных и улучшает отказоустойчивость.
Масштабирование: В Kafka можно легко добавить больше серверов, когда объем данных увеличивается.
Высокая пропускная способность: Kafka может обрабатывать большое количество лог-событий в секунду, что с легкостью удовлетворяет потребности большинства применений.
Так что с помощью Apache Kafka вы можете эффективно собирать и обрабатывать большие объемы логов в реальном времени и получать из них ценную информацию.
Stream Processing (Обработка потоков)
Это подход, позволяющий производить анализ и обработку данных в реальном времени по мере их поступления.
Стримы в Apache Kafka - это просто порядочные наборы событий или сообщений. Kafka сохраняет эти потоки в течение определенного периода времени, и различные приложения (например, приложение для анализа настроений) могут подписаться и обрабатывать эти потоки.
Фреймворк Kafka Streams позволяет создавать приложения для обработки потоков. Они могут выполнять такие функции, как фильтрация, преобразование, агрегирование и объединение данных из различных потоков в реальном времени.
Важнейшая особенность стрим-обработки в Kafka состоит в том, что она обеспечивает точность обработки данных «точно один раз», что означает, что каждое сообщение будет обработано только один раз, даже в случае сбоев.
RabbitMQ используется там, где нужна надежность и гарантированная доставка. А также там, где требуются паттерны, которые не поддерживает Apache Kafka:
RPC (Remote Procedure Call) — это метод взаимодействия между клиентом и сервером, позволяющий клиенту вызывать удаленные процедуры на сервере. В RabbitMQ для реализации RPC используется шаблон Request-Reply, который позволяет клиентам отправлять запросы серверу, а серверу – отвечать на эти запросы. Процесс взаимодействия между клиентом и сервером состоит из нескольких шагов:
Клиент отправляет запрос на выполнение процедуры в виде сообщения в очередь сервера.
Сервер обрабатывает запрос и отправляет ответ в виде сообщения в очередь клиента, указав идентификатор запроса в свойстве "correlation_id". 3.Клиент читает сообщение из своей очереди и проверяет "correlation_id". Если идентификатор ответа соответствует запросу, то клиент получает ответ, иначе – сообщение игнорируется.
Для реализации RPC в RabbitMQ необходимо создать клиентский и серверный код. Клиентский код должен отправлять запросы на выполнение процедуры, а серверный код – обновлять состояние системы и отправлять ответы. Клиент и сервер могут быть как на одном компьютере, так и на разных.
То есть, у нас есть клиент и есть сервис. И если клиент у сервера запрашивает какую-либо информацию, он должен получить ответ. И если бы мы запрашивали через REST, при нагрузках могли бы быть проблемы. Но благодаря очередям – нагрузка распределяется равномерно.
Важно, что каждое сообщение в RabbitMQ имеет свойство correlation_id. Этот уникальный идентификатор сообщения, устанавливаемый при его отправке, используется для сопоставления ответного сообщения с его оригинальным запросом. Таким образом, даже если приложение клиента обрабатывает несколько запросов параллельно, оно всегда сможет сопоставить каждый полученный ответ с его запросом.

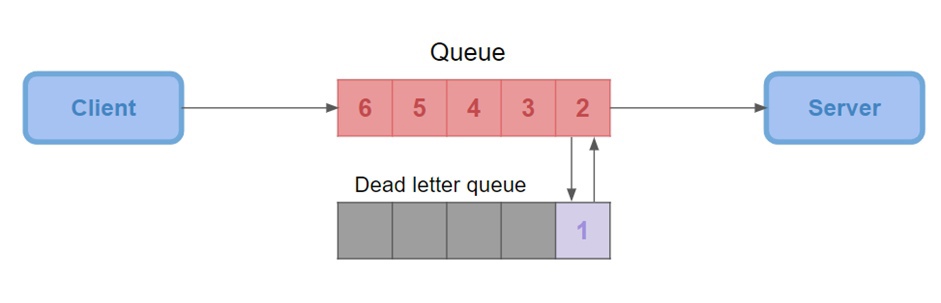
Dead-lettering
Это механизм, который можно использовать для обработки недоставленных сообщений.
Если сообщение не может быть обработано по одной из следующих причин: оно было отклонено или прошёл его срок годности или достигнут предел очереди, вместо того чтобы потерять его, можно перенаправить это сообщение в специальную очередь, называемую «мертвой» очередью.
«Мертвые» очереди в RabbitMQ имеют свои обменники и ключи маршрутизации, как и любые другие обычные очереди.
Заголовок сообщения в «мертвой» очереди будет дополнен содержанием, указывающим, по какой причине сообщение было отклонено. Это позволяет разработчикам принимать решения о том, как следует обрабатывать эти недоставленные сообщения.
В общем, Dead-lettering в RabbitMQ – это полезный инструмент, который позволяет управлять ошибками и событиями, приводящими к недоставке сообщений, гораздо эффективнее.
Delayed Messaging
Это процесс сдвига доставки сообщения в очередь на определенный интервал времени. Это довольно полезно в различных сценариях, например, для отправки напоминаний или для выполнения задач, которые должны быть выполнены через определенный промежуток времени.
RabbitMQ изначально не поддерживает отложенные сообщения, но мы можем добавить эту функциональность, используя RabbitMQ Delayed Message Plugin.
Когда мы отправляем сообщение, мы можем установить параметр "x-delay", который определяет, сколько миллисекунд сообщение должно быть отложено. После установки задержки, наше сообщение передается в обменник, который был настроен с помощью этого плагина. Сообщение затем задерживается на указанный период времени, после чего оно передается в очередь для обработки.
Заключение
Apache Kafka и RabbitMQ являются отличными инструментами, но каждый из них лучше использовать в различных случаях в зависимости от потребностей твоего проекта.
Apache Kafka это больше про большие данные и потоковую обработку.
Kafka идеально подойдет, если в реальном времени требуется обрабатывать огромные куски данных, требующие обработки сообщений с частотой от тысяч до миллионов сообщений в секунду.
Kafka также подходит для реализации систем логирования и мониторинга, где данные собираются с большого числа источников.
Или если есть сценарии, когда несколько потребителей должны получить все сообщения (например, в системах подписок).
RabbitMQ идеален для более стандартной очереди или брокера сообщений:
Если нужна сложная маршрутизация сообщений (например, выборочная подписка или публикация), он предоставляет очень гибкие функции.
Он может стать отличным выбором для обычных задач, связанных с посылкой краткосрочных сообщений от одного микросервиса к другому.
RabbitMQ также подходит, когда нужна поддержка разных протоколов обмена и более зрелый подход к стандартной очереди задач.
Несколько примеров использования в больших корпорациях:
Apache Kafka и LinkedIn
Kafka был изначально разработан командой LinkedIn для обработки активности пользователей на сайте и использования этих данных для усовершенствования продуктов. Например, предоставления рекомендаций на основе действий пользователей в реальном времени. До сих пор LinkedIn активно использует Kafka для обработки более чем 1,4 триллиона сообщений в день.Apache Kafka и Netflix
Kafka в Netflix используется для обработки и анализа огромного количества логов, которые приходят на их серверы при воспроизведении видео. Информация в реальном времени используется для мониторинга производительности и улучшения качества потокового воспроизведения.RabbitMQ и Mozilla
Mozilla использует RabbitMQ для сбора статистической информации от своих пользователей. Вместо того, чтобы каждый клиент напрямую отправлял статистику на центральный сервер, которому может быть сложно справиться с таким большим объемом данных, клиенты отправляют свои данные в RabbitMQ, который затем обрабатывает их в более управляемый формат.RabbitMQ и Vanguard
Vanguard, одна из крупнейших компаний управления инвестициями, использует RabbitMQ в качестве посредника сообщений для своей сложной инфраструктуры. RabbitMQ помогает Vanguard поддерживать надежность и эффективность своих услуг.
В итоге, выбор между Apache Kafka и RabbitMQ зависит в основном от требований к пропускной способности, сообщениям и обработке данных в твоем проекте. Как всегда, нужно всегда тестировать и оценивать различные инструменты, чтобы найти лучший для своих задач.
Использование RabbitMQ и Apache Kafka на одном проекте
Такое решение может объединить преимущества обоих брокеров сообщений для обработки различных типов сообщений и данных. Это дает возможность позволить получить максимальную производительность и гибкость в обработке данных.
В проекте, где необходимо обрабатывать большие объемы потоков данных, можно использовать Kafka, а для обработки очередей сообщений можно использовать RabbitMQ. Также это может быть полезным в случаях, когда требуется обработать данные и события в режиме реального времени, а затем передать их для задач более широкого использования.
Например, представим стартап, который выпускает мобильное приложение для фитнес-отслеживания. В этом приложении пользователи могут записывать свои тренировки, отслеживать прогресс, а также получать обратную связь и советы.
Вот, как могут быть использованы Apache Kafka и RabbitMQ:
Apache Kafka. Когда пользователи ведут активный образ жизни и во время тренировок делают много действий в приложении (например, стартуют и останавливают трекер, записывают упражнения, делают заметки и т.д.), все эти действия генерируют огромное количество данных. Kafka используется для сбора этих данных в реальном времени и обработки их в виде потока.
RabbitMQ. Всегда есть важные события, которые должны быть обработаны немедленно и гарантированно, такие, как уведомления пользователей. Например, если приложение должно отправить уведомление пользователю о достижении его ежедневной цели активности, использование RabbitMQ позволит гарантировать, что это уведомление будет отправлено и доставлено.
Итак, Kafka используется для обработки больших потоков данных, а RabbitMQ – для гарантии доставки важных уведомлений. Оба эти инструмента работают вместе, чтобы обеспечить надежную и эффективную обработку данных в реальном времени для этого фитнес-приложения.
При этом важно отметить, что это всего лишь один из потенциальных вариантов использования. В зависимости от конкретных потребностей проекта инструменты могут быть использованы в совершенно других целях и на разных этапах обработки данных. Все зависит от бизнес-требований, архитектуры системы и технической среды.
Комментарии (4)

vadiml
26.07.2023 12:47+4Биндинг (Binding) — условие, по которому обменник определяет, в какую из очередей сообщения должны попадать.
Не обязательно, можно соединять и exchange-и, а ещё может занимается фильрацией по шаблонам, выбирая куда послать сообщение
Для реализации RPC в RabbitMQ необходимо создать клиентский и серверный код.
Он не сильно отличается от обычного коннекта к очереди или эксченджю, а по размеру так вообще тоже самое (это через amqp - другие не пробовал)
после подтверждения о доставке RabbitMQ удаляет сообщение
это зависит от парамеров коннекта консюмера, может и не удалять, можно двигаться по очереди, как кафки, только этим мало пользуются
Репликация: Kafka автоматически реплицирует данные на несколько серверов, что обеспечивает избыточность данных и улучшает отказоустойчивость.
Масштабирование: В Kafka можно легко добавить больше серверов, когда объем данных увеличивается.
У раббита всё это есть, только оно чуть по другому работает из-за другой архитектуры. Нужна отказоустойчивать - сразу ставит 3 реплики раббита. Потом наращивают
RabbitMQ Написан на Erlang и совместим с большинством популярных ОС.
Жуткая морока с этим эрлангом, если надо собрать раббит, а не использовать готовый бинарник: собираются не все версии, собирается очень долго, возня с плагинами, которые опять не со всеми версиями собираются, а про некоторые функции, типа дедупликатора сообшений, посылают только ставить плагины
Zookeeper — всё это должен кто-то координировать, и делает это Zookeeper.
только этого координатора постепенно выпиливают из кафки, чтобы могла работать сама :)
Kafka ... если есть сценарии, когда несколько потребителей должны получить все сообщения
В раббите 1 exchange соединяется с несколькими очередями, если 1 потребитель - добавляем очередь, ушёл потребитель - удалили очередь. Разница в другом: кафка может быть базой, хранящей сообщения хоть за пару лет, и новая группа может вычитать все сообщения с нуля, а вот в раббите это надо планировать очень заранее, т. к. очередь хотя и может хранить сообщения, но работать базой она всё же не планировалась, надо заранее подумать о хранении.
RabbitMQ используется там, где нужна надежность и
гарантированная доставка. А также там, где требуются паттерны, которые
не поддерживает Apache Kafka:Не знаю, может я что-то не так настраивал, но если раббит пишет в clickhouse через view, то у меня терялись сообщения, причём чем больше поток, тем больше потерь, а вот у кафки такой проблемы не было. Но я потом обошёлся AsyncInsert-ом в clickhouse.
PS Веб-морда для управления удобнее у раббита.


FruTb
26.07.2023 12:47+2Кафка уже несколько лет как может работать без zookeeper. Все оффсеты она тогда хранит (если ничего опять не поменялось) внутри полностью реплицированного системного топика

hard_sign
26.07.2023 12:47На картинке ошибка – клиент с Zookeeper’ом не общается и вообще не знает, что он есть. Это чисто внутренняя кафковская заморочка для надёжного хранения конфигурации кластера.
vadiml
Не обязательно, можно соединять и exchange-и, а ещё может занимается фильрацией по шаблонам, выбирая куда послать сообщение
Он не сильно отличается от обычного коннекта к очереди или эксченджю, а по размеру так вообще тоже самое (это через amqp - другие не пробовал)
это зависит от парамеров коннекта консюмера, может и не удалять, можно двигаться по очереди, как кафки, только этим мало пользуются
У раббита всё это есть, только оно чуть по другому работает из-за другой архитектуры. Нужна отказоустойчивать - сразу ставит 3 реплики раббита. Потом наращивают
Жуткая морока с этим эрлангом, если надо собрать раббит, а не использовать готовый бинарник: собираются не все версии, собирается очень долго, возня с плагинами, которые опять не со всеми версиями собираются, а про некоторые функции, типа дедупликатора сообшений, посылают только ставить плагины
только этого координатора постепенно выпиливают из кафки, чтобы могла работать сама :)
В раббите 1 exchange соединяется с несколькими очередями, если 1 потребитель - добавляем очередь, ушёл потребитель - удалили очередь. Разница в другом: кафка может быть базой, хранящей сообщения хоть за пару лет, и новая группа может вычитать все сообщения с нуля, а вот в раббите это надо планировать очень заранее, т. к. очередь хотя и может хранить сообщения, но работать базой она всё же не планировалась, надо заранее подумать о хранении.
Не знаю, может я что-то не так настраивал, но если раббит пишет в clickhouse через view, то у меня терялись сообщения, причём чем больше поток, тем больше потерь, а вот у кафки такой проблемы не было. Но я потом обошёлся AsyncInsert-ом в clickhouse.
PS Веб-морда для управления удобнее у раббита.