
Привет, Хабр. Меня зовут Марат Хамадеев. Я — физик-теоретик, хотя кто-то, возможно, знает меня как научного журналиста, писавшего про физику для N + 1. Профессионально я рос в провинциальной академической среде, представители которой довольно скептически относились к применениям машинного обучения и, в частности нейронных сетей, для решения рутинных научных задач. Мне передался этот консерватизм — пока я писал новости про физику, я старался избегать исследований, построенных вокруг этого подхода.
Но жизнь не стоит на месте, и на новой работе я столкнулся с необходимостью поближе познакомиться с искусственным интеллектом и машинным обучением. Мне выпала замечательная возможность послушать лекции на Летней школе Искусственного интеллекта, организованной AIRI, и среди них была серия докладов, посвященных применению машинного обучения для физического моделирования. Они полностью развеяли мои страхи и побудили меня кратко рассказать вам о том, как связаны две эти области.
Скепсис
Прежде, чем перейти к сути, хотелось бы поговорит о причинах такого скепсиса. Я бы выделил две из них, самые важные.
Первая — общая, присущая многим людям, не только физикам. Она связана с тем, насколько обывательские ожидания от термина «искусственный интеллект» (или просто ИИ), сформированные научной фантастикой, контрастируют с реальными возможностями обучающихся систем. Во всяком случае, с теми возможностями, которыми они обладали, пока я учился на физика. И несмотря на до, что современный прогресс ИИ уже сложно оспорить, многие до сих пор видят в этом уловки маркетологов.
Вторая — слабая интерпретируемость результатов. Алгоритм, в особенности если это нейронная сеть — зачастую черный ящик. Мы не можем отследить происходящие в нем процессы, как это принято в численных методах, поскольку трекинг отдельных параметров не дает нам существенной информации. А если физик не может убедиться своими собственными глазами, что все идет правильно, он не доверяет вычислению.
Впрочем, скепсис — это тоже важный инструмент. Доверие может возникнуть только тогда, когда «черный ящик» раз за разом демонстрирует точность и воспроизводимость для широкого круга задач, и здоровая критика позволяет правильно выставить границы этого доверия. Сейчас ученые редко полагаются исключительно на машинное обучение, работая с гибридными моделями, в которые тем или иным образом внедряется знание о физических законах. Совокупность таких подходов получила название физически информированного машинного обучения (Physics-informed Machine Learning, PIML).
Одними из тех, кто довольно плотно занимается PIML в России, стали ученые из центра прикладного ИИ Сколтеха — это направление является для них приоритетным. Руководитель этой группы, а заодно и доцент кафедры общей физики МФТИ Владимир Вановский, сделал на Школе интересный доклад с обзором того, что представляет собой физически информированное машинное обучение сегодня. Текст ниже является кратким конспектом этой лекции.
Зачем вообще нужно включать машинное обучение в физику?
В современном преподавании физики в ВУЗах есть перекос в сторону задач, точно решаемых аналитическими методами. Это объяснимо с дидактической точки зрения, но совершенно не отражает реальные будни физиков, которые обычно имеют дело с численными расчетами. Ситуация усугубляется тем фактом, что многие проблемы, лежащие на переднем крае науки, становятся вычислительно неподъемными для существующих компьютеров.
Типичный пример — это задача о моделировании атмосферы, где требуется сшивать разные масштабы и разные физические модели: аэродинамическую, радиационную и так далее. Физикам приходится прибегать с помощи различных параметризаций для замены точных моделей на приближенные. Машинное же обучение — это тоже чаще всего некоторая аппроксимация выходных результатов по входным данным, что делает его привлекательным инструментом для решения проблем, связанных с моделированием физики атмосферы.
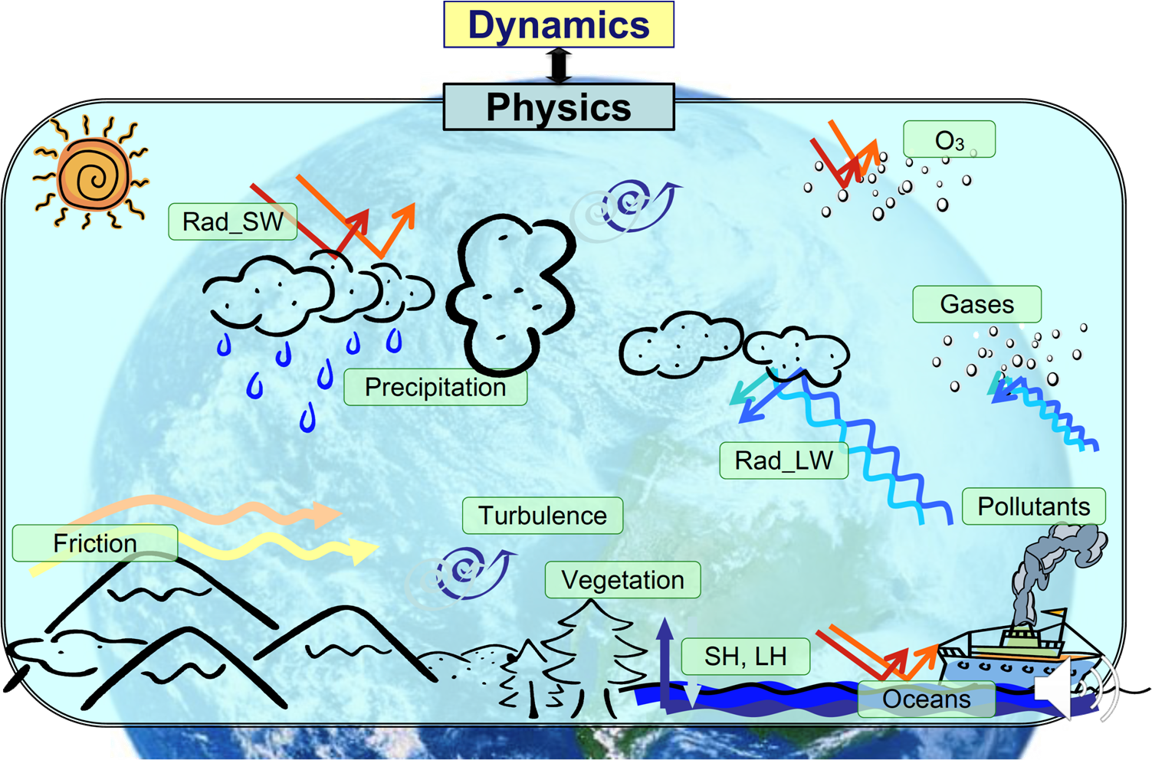
В этой и многих других задачах (от геологии до физики высоких энергий) машинное обучение способно выдать результат быстрее, чем традиционные солверы. В случае же, когда прямое вычисление невозможно, оно ставится единственным выходом из ситуации.
В поисках баланса
Границы, которые я упоминал, говоря про скепсис, представляют собой баланс между количеством физики, заложенной в модель, и количеством данных, необходимых для ее успешного обучения. Его хорошо иллюстрирует шкала, приведенная на рисунке ниже:

Слева изображена ситуация, когда данных очень мало, но в модель заложено много знания о физических законах. В предельном случае, когда данных нет совсем, мы имеет дело с традиционными методами, например, методом конечных элементов. Хотя иногда без данных могут справится и нейросети, но только в совсем простых задачах вроде движения маятника.
Справа — случай, когда данных очень много. Тогда мы можем взять нейросеть с большим числом слоев и воспользоваться теоремой о том, что это универсальный аппроксиматор. Это так называемый data-driven подход. В этом случае мы можем получить предсказание о том, как будет вести себя некоторая система, никак не помогая модели с физикой. Данные могут быть добыты с помощью реального либо численного эксперимента.
В первом случае мы имеем хорошую точность и интерпретируемость результатов. Однако физическая модель не всегда точно описывает эксперимент, и учесть это зачастую невозможно. Кроме того, такие расчеты дороги и очень громоздки с точки зрения кода, который часто вообще написан на Фортране физиками старой школы. Кто из вас хорошо знает Фортран, поднимите руку?

Нейронки же хороши тем, что они очень быстро считают (но долго обучаются, да) и что они дифференцируемы, что позволяет эффективнее решать задачи оптимизации. Но минусы тоже существенны: нужно много данных, которые не всегда есть в наличии. Кроме того, чистые модели на основе нейронных сетей неустойчивы по входным данным. Это означает, что даже небольшое отклонение в начальных параметрах способно привести к существенно другому результату, из-за чего доверие к нейросетевому подходу низкое.
Со временем стало понятно, что максимально эффективным будет использовать что-то посередине. То есть мы можем использовать нейронные сети для ускорения, уточнения или замены части расчетов, которые вычислительно сложны, и при этом с относительно разумными усилиями добавлять в модель знания физики, которые обеспечат определенный уровень интерпретируемости данных, а значит и гарантию качества вычислений. Такие гибридные модели будут работать быстро, требовать мало данных для обучения и обладать приемлемой достоверностью.
Как внедрять физику в ML?
Классификация подходов PIML либо их отсутствия достаточно условна, но их все же можно разбить на три большие группы:
Обучение физике на основе данных, напрямую воплощающих собой закономерности, присущие реальной системе. Фактически, это data-driven подход.
Выбор архитектуры модели таким образом, чтобы какие-то закономерности были автоматически ей присущи, например, симметрии.
Добавление знаний о физике в функцию потерь модели. В этом случае градиентный метод заставляет модель тяготеть к тем динамическим траекториям, что соответствуют нужным нам законам. Последний подход носит название Physics-informed neural networks, PINN, и является, пожалуй, самым известным.
Data-driven подход довольно прост: достаточно взять большое количество данных, полученных численно либо экспериментально, и попытаться на них что-то обучить. В такой простой формулировке в алгоритме нет ничего, чтобы указывало на внедрение физики.
Но если при подготовке данных вы руководствовались некоторыми физическими соображениями, это уже можно назвать физическим информированием. Например, при моделировании геологических процессов полезно логарифмировать переменную, ответственную за проницаемость породы, так как она имеет логнормальное вероятностное распределение — такой прием повысит качество работы модели.
Подход с физически информированным проектированием архитектуры нейросети опирается на глубокую связь между симметриями уравнений и законами сохранения. В теоретической физике эту связь описывает теорема Нётер. Из нее следует, например, что инвариантность физической системы, описанной лангранжианом, к трансляциям на произвольный вектор в пространстве приводит к закону сохранения импульса, во времени — закону сохранения энергии и так далее. Это означает, что, если мы обеспечим определенные симметрии в структуре модели, предсказываемые ею решения будут гарантированно удовлетворять соответствующим физическим законам.

Наконец, третий подход — самый известный — закладывает физику в функцию потерь. Чаще всего для этого мы строим функцию потерь в том же виде, в котором записывается динамическое уравнение нашей системы, все члены которого перенесены в левую часть. Таким образом, стремление функции потерь к минимуму будет обеспечивать ноль в правой части уравнения.
Уравнения в физике по большей части дифференциальные. Чтобы конструировать для них производные, можно дифференцировать выход по входам, что позволяет делать большинство фреймворков машинного обучения. Если входных переменных несколько (например, мы ищем зависимость y от x и t), то такое дифференцирование даст нам частные производные. Таким же методом можно вычислять и вторые производные.
: 422-440")
В численных методах решения уравнений нужно учитывать еще начальные и граничные условия. Если с начальных условий мы стартуем, то граничные также можно заложить в функцию потерь вместе с самим уравнением. Правда, тогда обученная нейронка не будет нормально работать в случае, если мы захотим поменять граничные условия. Альтернатива — это подавать граничные условия на вход.
 и PINN-фреймворком под названием DeepXDE (B). Справа показана абсолютная ошибка вычислений (C). Источник: Lu, Lu, et al. \"DeepXDE: A deep learning library for solving differential equations.\" SIAM Review 63.1 (2021): 208-228")
Также к третьему подходу относится случай, когда в функцию потерь закладывают не сами уравнения, а некоторые характеристики, которые мы ожидаем от решения: статистические распределения, спектры и так далее.
Проблемы
Описанные выше подходы отличаются и проблемами, с которыми можно встретиться при их использовании, причем причины их появления и пути решения далеко не всегда очевидны. Например, применение PINN к решению простого уравнения переноса может столкнуться с тем, что при больших значениях коэффициента переноса решение разваливается. Так происходит из-за того, что из-за дисбаланса параметров ландшафт функции потерь становится изрезанным и нейронка не может найти глобальный минимум. Чтобы решить эту проблему, есть несколько путей: можно переопределить переменные, чтобы нивелировать дисбаланс, обучать последовательно и так далее.

В целом, проблемой кейсов, основанных на реальных датасетах, является дефицит высококачественных данных и их большая погрешность. Приходится добиваться, чтобы модели были устойчивы к этой погрешности и обучались на относительно небольшом многообразии данных.
В заключении хотелось бы отметить, что в одном материале невозможно охватить всю область физически-информированного обучения — она очень богата деталями и ныне активно развивается. Хотелось бы также подчеркнуть, что на пути внедрения PIML стоит много сложностей, и это не волшебная таблетка от всех проблем. И все же это довольно перспективный инструмент, с которым большинство физиков пока, увы, мало знакомо.
phenik
Спасибо за обзор!
Интересно ваше мнение о работах Ванчурина с соавторами, среди которых известный эволюционист Кунин, см. 1, 2, 3, популярно 1, 2, видео. Они затрагивают вопросы фундаментальной физики, эволюции Вселенной и ее законов, как самообучающейся нейросети. К какому пункту приведенной классификации нейросетевых методов в физике этот проект можно отнести?