
В программировании микроконтроллеров часто приходится в UART консоли вводить в прошивку какие-то калибровочные коэффициенты: значения токов, пороговых напряжений, уровней освещений и прочего. Как правило это действительные числа с плавающий запятой.
Потом часто надо анализировать текстовые логи с SD-карты. Надо выхватывать вещественные числа из CSV строчек.
Еще это синтаксический разбор NMEA 0183 протокола, который есть во всех навигационных приемниках, чтобы банально прочитать широту и долготу.
Для всего этого нужен какой-то надежный переносимый прозрачный и простой алгоритм, чтобы распознавать вещественные числа из строчек.
Постановка задачи
Дана строка символов. Распознать вещественное (действительное) число из строчки символов. Если числа нет, то выдать ошибку. При этом прототип должен быть такой
bool try_str2real(const char* const text, double* const double_value);Вот легальный алфавит символов в строчке: ' ', '+', '-', 0 1 2 3 4 5 6 7 8 9, 'e', 'E' '.' '\n' '\r'
Вот список тест кейсов:
№ |
Входная строка |
Распознанное число |
это вещественное число? |
1 |
".0" |
0.0 |
да |
2 |
"+." |
-- |
нет |
3 |
"005047e+6" |
5047000000 |
да |
4 |
"-8115e957" |
INF |
да |
5 |
"2e0" |
2 |
да |
6 |
"4e+" |
-- |
нет |
7 |
"." |
-- |
нет |
Парсинг чисел из строки это еще тот классический случай когда без Test-driven development (TDD) эту задачу решить не просто нереально. Поэтому полный список тест-кейсов можно посмотреть тут.
По непонятной причине сайт LeetCode оценивает эту задачку уровня hard.
Хотя мне кажется, что тут нет ничего сложного. Вообще это тот редкий случай, когда на LeetCode мелькают реальные задачи из prod(а).
Решение
вещественное число- это по сути число для представления непрерывных физических величин (масса, напряжение, освещение и прочее).
Стандартная функция парсинга sscanf() ненадежная для ответственных систем. Функция sscanf() делает синтаксический разбор double тогда, когда это не требуется, да ещё и при этом выдает непредсказуемый результат. Вот отчет тестирования функции sscanf().
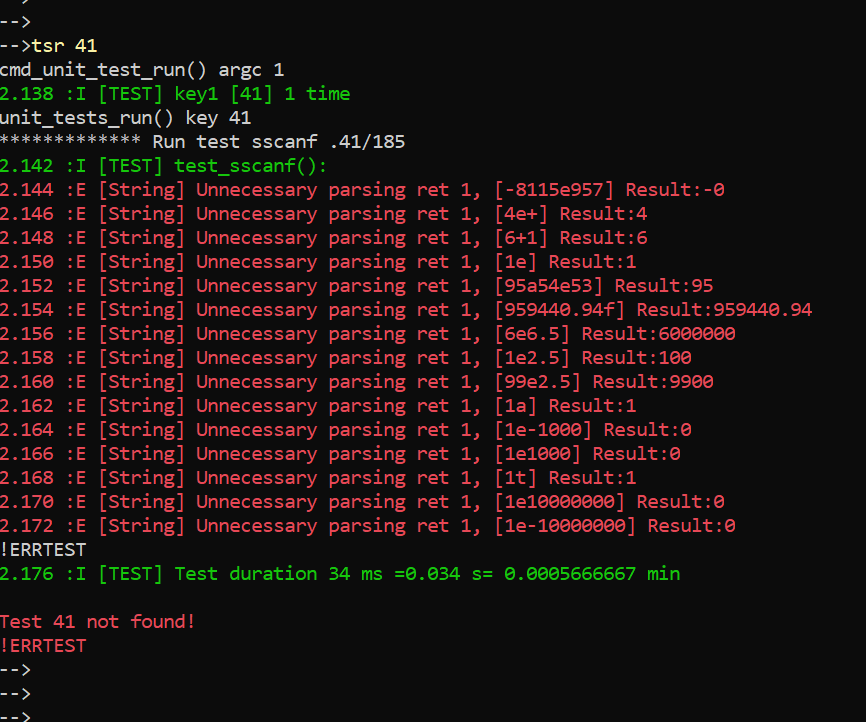
А если в sscanf() подать кириллическую 'е', то процесс и вовсе упадет в исключение!
Нужна более надежная реализация функции синтаксического разбора вещественных чисел из строчки.
Для начала определимся со схемой синтаксического разбора вещественного числа (DFS). Вот приблизительная схема разбора рационального числа

Глядя на эту схему можно выделить 5 или 6 четко выраженных состояния.
typedef enum{
PARSE_NUMBER_STATE_PARSE_SIGN=1,
PARSE_NUMBER_STATE_PARSE_INTEGER=2,
PARSE_NUMBER_STATE_PARSE_FRACTION=3,
PARSE_NUMBER_STATE_PARSE_EXPONENTA_SIGN=4,
PARSE_NUMBER_STATE_PARSE_EXPONENTA_INTEGER=5,
PARSE_NUMBER_STATE_DONE=6,
PARSE_NUMBER_STATE_UNDEF=0
}ParseNumberStates_t;Поэтому и решать эту задачу я буду при помощи конечно-автоматной методологии. Вот основная функция. Она прокручивает конечный автомат распознавания числа из строки.
typedef struct {
double value;
double mantissa;
double exponenta;
char cur_letter;
int8_t sign;
uint64_t integer ;
uint32_t fraction_order;
double fraction;
ParseNumberStates_t state;
bool spot_mantissa;
bool spot_exponent;
int8_t exponent_sign;
uint32_t exponent_integer;
}Text2NumberFsm_t;
bool try_str2real(const char* const text, double* const double_value){
bool res = false;
uint32_t len = 0;
if(text){
len = strlen(text);
if(len){
if(double_value){
res = true;
}
}
}
if(res) {
Text2NumberFsm_t Fsm;
res = text_2_number_init(&Fsm);
uint32_t i = 0;
uint32_t ok = 0;
uint32_t err = 0;
LOG_DEBUG(STRING, "ParseDoubleIn:%u:[%s]", len, text);
for(i=0; i<len; i++){
Fsm.cur_letter = text[i];
res = number_proc_one(&Fsm);
if (res) {
ok++;
} else {
err++;
LOG_ERROR(STRING,"ProcErr: ch[%u]=%c ",i, text[i]);
break;
}
}
if(0==err) {
Fsm.cur_letter ='\n';
res = number_proc_one(&Fsm);
if (res) {
ok++;
} else {
err++;
}
}
if (0==err) {
*double_value = Fsm.value;
res = true;
} else {
LOG_ERROR(STRING,"len:%u ok:%u",len, ok);
res = false;
}
}
return res;
}Вот обработчик символа. Алгоритм меняется в зависимости от текущего состояния конечного автомата
static bool number_proc_one(Text2NumberFsm_t* Node){
bool res = false;
LOG_DEBUG(STRING, "Proc: %s",NumberParserFsm2Str(Node));
if(Node) {
switch (Node->state) {
case PARSE_NUMBER_STATE_PARSE_SIGN:
res = number_proc_parse_sign(Node); break;
case PARSE_NUMBER_STATE_PARSE_INTEGER:
res = number_proc_parse_integer(Node); break;
case PARSE_NUMBER_STATE_PARSE_FRACTION:
res = number_proc_parse_fracion(Node); break;
case PARSE_NUMBER_STATE_PARSE_EXPONENTA_SIGN:
res = number_proc_parse_exponenta_sign(Node); break;
case PARSE_NUMBER_STATE_PARSE_EXPONENTA_INTEGER:
res = number_proc_parse_exponenta_integer(Node); break;
case PARSE_NUMBER_STATE_DONE:
res = number_proc_done(Node); break;
default: res = false; break;
}
}
return res;
}Вот инициализация конечного автомата для разбора вещественного числа.
static bool text_2_number_init(Text2NumberFsm_t* Node){
bool res = false;
if (Node) {
Node->value = 0.0;
Node->sign = 1;
Node->integer = 0;
Node->exponent_integer = 0;
Node->fraction = 0.0;
Node->fraction_order = 1;
Node->spot_mantissa = false;
Node->spot_exponent = false;
Node->mantissa = 1.0;
Node->exponent_sign = 1;
Node->exponenta = 1.0;
Node->cur_letter ='\0';
Node->state = PARSE_NUMBER_STATE_PARSE_SIGN;
res = true;
}
return res;
}А это вспомогательные функции обработчики каждого отдельного состояния для того, чтобы всё функции в отдельности умещались на одном экране
bool number_compose_result(Text2NumberFsm_t* Node){
bool res = false;
if(Node) {
if(Node->spot_mantissa) {
Node->value = ( (double)Node->sign ) * (((double) Node->integer) + Node->fraction);
LOG_DEBUG(STRING,"Val:%f",Node->value);
Node->state = PARSE_NUMBER_STATE_DONE;
res = true;
} else {
LOG_ERROR(STRING,"NoMantissa");
}
}
return res;
}
static bool number_proc_parse_sign(Text2NumberFsm_t* Node){
bool res = false;
switch(Node->cur_letter) {
case 'E':
case 'e': {
Node->mantissa = 1.0;
Node->spot_mantissa = false;
Node->integer = 1;
Node->fraction = 0.0;
Node->state = PARSE_NUMBER_STATE_PARSE_EXPONENTA_SIGN;
res = true;
}break;
case ' ': {
res = true;
}break;
case '+': {
Node->sign = 1;
Node->state = PARSE_NUMBER_STATE_PARSE_INTEGER;
res = true;
}break;
case '-': {
Node->sign =-1;
Node->state = PARSE_NUMBER_STATE_PARSE_INTEGER;
res = true;
}break;
case '0': {
Node->sign =1;
Node->spot_mantissa=true;
Node->state = PARSE_NUMBER_STATE_PARSE_INTEGER;
res = true;
}break;
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9': {
uint8_t digit = 0;
Node->spot_mantissa = true;
res= try_hex_char_to_u8((uint8_t) Node->cur_letter, &digit) ;
Node->integer *=10;
Node->integer += digit;
Node->state = PARSE_NUMBER_STATE_PARSE_INTEGER;
}break;
case '.': {
Node->fraction_order = 1;
Node->integer = 0;
Node->spot_mantissa = false;
Node->state = PARSE_NUMBER_STATE_PARSE_FRACTION;
res = true;
}break;
case '\n':
res = false;
break;
case '\r':
res = false;
break;
default:
res = false;
break;
}
return res;
}
static bool number_mantissa_save(Text2NumberFsm_t* Node){
bool res = false;
if(Node) {
Node->mantissa = ( (double)Node->sign ) * (((double) Node->integer) + Node->fraction);
LOG_DEBUG(STRING,"Mantissa:%f",Node->mantissa);
res = true;
}
return res;
}
static bool number_proc_parse_integer(Text2NumberFsm_t* Node){
bool res = false;
switch(Node->cur_letter) {
case 'E':
case 'e': {
res = number_mantissa_save(Node);
Node->state =PARSE_NUMBER_STATE_PARSE_EXPONENTA_SIGN;
}break;
case ' ': {
res = false;
}break;
case '.':{
Node->fraction_order=1;
Node->state = PARSE_NUMBER_STATE_PARSE_FRACTION;
res = true;
} break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9': {
uint8_t digit = 0;
res= try_hex_char_to_u8((uint8_t) Node->cur_letter, &digit) ;
LOG_PARN(STRING,"ParseInt %u", digit);
Node->integer *= 10;
Node->integer += digit;
Node->spot_mantissa = true;
res = true;
}break;
case '\r':
case '\n':{
res = number_compose_result(Node);
} break;
default:{
res = false;
} break;
}
return res;
}
static bool number_proc_parse_exponenta_sign(Text2NumberFsm_t* Node){
bool res = false;
switch(Node->cur_letter) {
case '+': {
Node->exponent_sign = 1;
Node->state = PARSE_NUMBER_STATE_PARSE_EXPONENTA_INTEGER;
res = true;
}break;
case '-': {
Node->exponent_sign = -1;
res = true;
Node->state= PARSE_NUMBER_STATE_PARSE_EXPONENTA_INTEGER;
} break;
case '0':{
Node->exponent_integer = 0;
Node->exponent_sign = 1;
Node->spot_exponent = true;
Node->state = PARSE_NUMBER_STATE_PARSE_EXPONENTA_INTEGER;
res = true;
}break;
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':{
uint8_t digit = 0;
res= try_hex_char_to_u8((uint8_t) Node->cur_letter, &digit) ;
LOG_PARN(STRING,"ParseExpInt %u",digit);
Node->exponent_integer *=10;
Node->spot_exponent = true;
Node->exponent_integer += digit;
Node->state= PARSE_NUMBER_STATE_PARSE_EXPONENTA_INTEGER;
res = true;
}break;
case '\r':
case '\n':{res = false;} break;
default: res = false; break;
}
return res;
}
static bool number_exponenta_calc(Text2NumberFsm_t* Node){
bool res = false;
if(Node) {
if(Node->spot_exponent ){
int32_t rank = ((int32_t)Node->exponent_integer) * ((int32_t)Node->exponent_sign);
LOG_DEBUG(STRING,"ExpRank %d",rank);
double power = (double )rank;
LOG_DEBUG(STRING,"power %f",power);
if(rank < 306) {
if(-306 < rank) {
Node->exponenta = pow(10.0,power);
LOG_DEBUG(STRING,"Exponenta: %f",Node->exponenta);
res = true;
} else {
Node->exponenta = 0.0;
LOG_ERROR(STRING,"MathError:TooSmalExpPower %d",rank);
res = false;
}
} else {
LOG_ERROR(STRING,"MathError:TooBigExpPower %d",rank);
res = false;
}
} else {
LOG_ERROR(STRING,"NoExponents");
}
}
return res ;
}
static bool number_proc_parse_exponenta_integer(Text2NumberFsm_t* Node){
bool res = false;
switch(Node->cur_letter) {
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9': {
uint8_t digit = 0;
res= try_hex_char_to_u8((uint8_t) Node->cur_letter, &digit) ;
LOG_PARN(STRING,"ParseExpInt %u",digit);
Node->exponent_integer *=10;
Node->exponent_integer += digit;
Node->spot_exponent = true;
Node->state= PARSE_NUMBER_STATE_PARSE_EXPONENTA_INTEGER;
res = true;
}break;
case '\r':
case '\n': {
res = number_exponenta_calc(Node);
if (res) {
if(Node->spot_mantissa) {
double mantissa = 0.0;
mantissa =((double)Node->sign)*(((double)Node->integer)+((double)Node->fraction));
LOG_DEBUG(STRING,"mantissa %f", mantissa);
Node->value = mantissa*(Node->exponenta);
Node->state= PARSE_NUMBER_STATE_DONE;
}else {
LOG_DEBUG(STRING,"NoMantissa");
res = false;
}
}
}break;
default:
res = false;
break;
}
return res;
}
bool number_compose_mantissa(Text2NumberFsm_t* Node){
bool res = false;
if(Node) {
Node->mantissa =((double)Node->sign)*(((double)Node->integer)+((double)Node->fraction));
res = true;
}
return res;
}
static bool number_proc_parse_fracion(Text2NumberFsm_t* Node){
bool res = false;
switch(Node->cur_letter){
case 'E':
case 'e':{
res = number_compose_mantissa(Node);
Node->state = PARSE_NUMBER_STATE_PARSE_EXPONENTA_SIGN;
}break;
case ' ': {
LOG_ERROR(STRING,"TornFlowErr!");
res = false;
}break;
case '.': {
LOG_ERROR(STRING,"DoubleDotErr!");
res = false;}break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9': {
uint8_t digit = 0;
res = try_hex_char_to_u8((uint8_t) Node->cur_letter, &digit) ;
double fraction_digit = ( (double)digit ) / ( pow(10.0, (double) Node->fraction_order) );
LOG_DEBUG(STRING,"+ %f",fraction_digit);
Node->spot_mantissa= true;
Node->fraction += fraction_digit;
Node->fraction_order++;
res = true;
}break;
case '-':
case '+': {res = false;}break;
case '\r':
case '\n':{
res = number_compose_result(Node);
} break;
}
return res;
}
static bool number_proc_done(Text2NumberFsm_t* Node){
bool res = false;
LOG_DEBUG(STRING, "Proc: %s",NumberParserFsm2Str(Node));
switch(Node->cur_letter){
case '\n':
case '\r':{
res = true;
} break;
default:{
res = false;
}break;
}
return res;
}
Я очень рад, что нашел эту задачу на LeetCode (65. Valid Number). Там уже заготовлено очень много тестов. Их сайт просто пытался разбомбить unit тестами моё решение и тем не менее оно выстояло!
Моё решение прошло верификацию на сайте LeetCode и оказалось быстрее всех решений на языке программирования Си!
Если знаете оригинальные тестовые данные для задачи распознавания вещественного числа из строки, то пишите, пожалуйста, их в комментариях.
Вывод
Конечные автоматы идеально идеально подходят для синтаксического разбора разнообразных типов данных из строчек, в частности double. Если вы научились распознавать тип double, то можно сразу утверждать, что вы этим же кодом научились и распознавать и uint8_t int8_t int32_t, uint64_t, float. Один парсер double является универсальным!
Словарь
Акроним |
Расшифровка |
DFA |
Deterministic finite automaton |
CSV |
Comma-separated values |
NMEA |
National Marine Electronics Association |
TDD |
Test-driven development |
Links
https://leetcode.com/problems/valid-number/description/
https://docs.google.com/spreadsheets/d/1rbEw8p8CMHzM5DJUYGxDX-BCQ8sZsp4jDMRsbifJD9k/edit#gid=0
Вопросы
Вам известны примеры реальных практических задач на LeetCode решение которых пригодилось бы в реальных embedded проектах?
Комментарии (75)

Helltraitor
26.08.2023 23:20+3Не ясно откуда такой оверхед (может это из-за логов, которые вы почему-то оставили?), у меня решение на Rust справляется также быстро и потребляет максимум 2.2mb (0ms 2.1mb, 4ms 2.2mb).
Также, не думаю, что
\nи\r- легальные символы. Но они, собственно, в коде и задействуются как условия завершения работы.Может
case '1'...case '9'стоило поместить вdefaultветку и сравнить два раза (с'1'и'9'соответственно)?Посмотрел на функцию
number_exponenta_calcи заметил, что вы производите много работы с числами. Не думаю, что это хорошо, потому что от вас этого не требуют. Условно, если добавить этот код в какой-то проект (просто представьте), то число будет вычисляться дважды - для проверки и при построении после.Кому интересно, код на Rust можно посмотреть тут

kipar
26.08.2023 23:20+4потребление памяти на leetcode, по-моему, близко к случайному. Очевидно же что для этой функции и 2 килобайта памяти много, откуда там мегабайты.
Helltraitor
26.08.2023 23:20+1Не настолько же
kipar
26.08.2023 23:20+2Именно настолько. Уверен, автор успешно запустит свою функцию на микроконтроллере с несколькими килобайтами рам (и несколькими десятками кб флеша). На этом же контроллере запустится и растовский вариант. Но если на функцию ушло 2 килобайта, то остальные мегабайты ушли на библиотеки рантайма, файловые кеши, прочее не относящиеся к задаче вещи. Скорее всего ключи компилятора повлияют намного сильнее на размер памяти чем то что там понаписал пользователь.

aabzel Автор
26.08.2023 23:20Уверен, автор успешно запустит свою функцию на микроконтроллере с несколькими килобайтами рам (и несколькими десятками кб флеша).
Да!

Cheater
26.08.2023 23:20+2Почему не sscanf? Железка настолько сурова, что недоступна libc?
оказалось быстрее всех решений на языке программирования Си!
Ну тк в задаче на Leetcode требуется определить валидность/невалидность числа, а не зачитать его в double, то можете выбросить все арифметические операции из вашего решения и получить ещё более быстрое...
(Upd: не обновил комменты перед ответом)
aabzel Автор
26.08.2023 23:20Железка настолько сурова, что недоступна libc
Железка-то норм.
Вот загрузчик для MCU c UART-CLI должен быть 16кByte-32kByte.

kotan-11
26.08.2023 23:20-1Можно упростить: https://onlinegdb.com/4U-2Q6w0K
aabzel Автор
26.08.2023 23:20-2Упростить -то можно, однако по ISO26262 надо чтобы код ещё оставался читаемым, тестируемым, ремонто-пригодным, конфигурируемым, переносимым и поддерживаемым.
А это
https://onlinegdb.com/4U-2Q6w0K
выглядит как код написанный неземным существом
kotan-11
26.08.2023 23:20+1Это классический LL(0) парсер рекурсивным спуском (конечно однобуквенные переменные надо переименовать). Но код все равно понятен как отче наш любому, кто знаком с "Драконом" Ахо-Ульмана. Или учился на книгах Вирта.
Не думаю, что стандарт на прошивки автомобилей ISO26262 требует, чтобы код прошел одобрение Шалыто.

dyadyaSerezha
26.08.2023 23:20Пальцем можно показать рекурсию?
kotan-11
26.08.2023 23:20В методе рекурсивного спуска есть поток токеров, словари правил и матчер, который рекурсивно вызывает себя с различными словарями правил. Если матчер захардкодить, и для разных словарей правил построить отдельные функции матчинга, например: "skip_whitespace", "get_sign", "parse_int",- то такая реализация рекурсивного спуска может и не содержать явную рекурсию, но метод все равно будет называться методом рекурсивного спуска.
dyadyaSerezha
26.08.2023 23:20+1Вот именно, что тут захардкоден абсолютно жёсткий формат, а вместо токенов простые символы.
kotan-11
26.08.2023 23:20+2Вы это так написали как будто это что-то плохое. Да именно жесткий формат числа с плавающей точкой. Это было исходное задание. Причем код построчно повторяет грамматику, то есть самодокументирующийся. А токены не нужны. Они были нужны во времена перфокарт, когда надо было между пассами компиляторов передавать промежуточные данные, и хранить один байт вместо ключевого слова из пяти байт было принципиально. Сегодня и ключевые слова в языках стали контекстно зависимы, и токенизация больше не может различать границы (как например >> в именах шаблонов С++) и поток токенов, увешанный метаданными значительно превышает по объему и исходный текст и усложняет/замедляет парсеры. Сегодня даже в грамматиках напрямую используют символы (например, в ANTLR).

Tangeman
26.08.2023 23:20+4В приниципе код хороший, отличный даже, и наверняка закроет 99.9% всех типичных кейсов, хотя пара моментов всё же не учтена.
Я не знаю что там в стандарте, но зравый смысл требует чтобы код вернул ошибку в случае потери точности (если мантиссы не хватит), а не только если на входе не число.
Т.е. даже если наш
doubleсоответствует IEEE 754 то у нас всего 52 бита, а это маловато как-то если получим на входе хотя бы 17 знаков, но поскольку C не гарантирует что это будет именно 64 бита double precision (не говоря уже о том что это может быть и вовсе не IEEE 754) то результат может оказаться чуть печальней чем хотелось бы, особенно если код используется в чём-то критичном типа авиации или автомобилей.Подобная проверка может показаться избыточной на таких многозначных числах - но её наличие позволит поймать случаи когда входные данные неадекватны.
С переполнением тоже не всё гладко - если повезет, то получим на выходе INF (хотя его ещё нужно будет проверять в месте вызова), но можем нарваться и на SIGFPE (или его аналог) или просто на мусор в результате.
@aabzelВаш код из статьи тоже "посыпется" если на входе будет что-то многозначное, но ситуация усугубляется ещё и тем что вы используете
uint64_tдля разбора целой части - т.е. возможные переполнения вообще могут оказаться незамеченными. Может быть именно по этой причине задачка получила уровень "hard" - разбор чисел с плавающей точкой (да и просто целых тоже) это совсем не так просто если нет никаких гарантий о качестве входных данных. И да, судя по всему их тесты описанные выше случаи явно не покрывают.К тому же, конечный автомат в данном случае это перебор - медленно, громоздко и плохо читаемо и понимаемо (= высокая когнитивная нагрузка).
aabzel Автор
26.08.2023 23:20Ваш код из статьи тоже "посыпется" если на входе будет что-то многозначное, но ситуация усугубляется ещё и тем что вы используете
uint64_tдля разбора целой части - т.е. возможные переполнения вообще могут оказаться незамеченными.Есть ли возможность прислать test case?
aabzel Автор
26.08.2023 23:20-2Не думаю, что стандарт на прошивки автомобилей ISO26262 требует
В вашем коде в функции 3 раза return. По ISO26262 в каждой функции должен быть только один return.

kotan-11
26.08.2023 23:20+4В моей компании используется другой стиль кодирования, в котором приветствуется ранний return. Вы легко можете изменить мой код, чтобы поддержать единственный return.
Кстати обратите внимание на 1h No hidden data/control flow. Боюсь, это - прямой запрет на стейт-машины.

Tiriet
26.08.2023 23:20-1так можно сказать, что и локальные переменные запрещены- они же "hidden" для вызывающего кода. Это скорее запрет на использование стейт-машины без ее явной инициализации при каждом вызове.
aabzel Автор
26.08.2023 23:20-1В моей компании используется другой стиль кодирования, в котором приветствуется ранний return.
В вашей компании разрабатывают firmware для автомобильных ECU?
aabzel Автор
26.08.2023 23:20обратите внимание на 1h No hidden data/control flow. Боюсь, это - прямой запрет на стейт-машины.
ISO26262 не запрещает использование конечных автоматов.





randomsimplenumber
26.08.2023 23:20+1Можно упростить себе задачу: передавать в МК только нормированные целые числа (милливольты вместо вольтов, микроамперы вместо амперов етц) и не закатывать солнце вручную.
Tiriet
26.08.2023 23:20+1Самому себе конечно можно упростить задачу. А если у Вас ТЗ? А в нем сказано, что вот эти данные вылетают из провода в формате строки с вещественным числом, и на ТЗ стоит печать со звездочкой. :-).

buratino
26.08.2023 23:20+1В программировании микроконтроллеров часто приходится в UART консоли вводить в прошивку какие-то калибровочные коэффициенты: значения токов, пороговых напряжений, уровней освещений и прочего. Как правило это действительные числа с плавающий запятой.
Я так понимаю что весь вышеописанный гемморой связан именно с этим? Настолько часто надо вводить, что нужно рожать решение, которое быстрее всех что-то делает?
Потом часто надо анализировать текстовые логи с SD-карты. Надо выхватывать вещественные числа из CSV строчек.
наши погромисты настолько суровы, шо не помнят, как пишут текстовые (!) логи на SD карту? Или какая религия запрещает использовать xprintf/xscanf с одним и тем же (ну или почти) форматом?
И что это вообще получается, боремся за быстрее всех распознавание текстовых логов, но при этом безбожно тормозим при записи этих логов в текстовом виде и на SD карту?
Или вообще речь идет о борьбе за наносекунды при анализе логов на компе, где обычно и ядер и памяти до и больше?
И вообще, как минимум по моему опыту, при анализе логов проблема не с засасыванием CSV, а с визуализацией данных для больших логов. Если эксель или LibreOffice еще как-то способны засасывать логи под 100k строк, то с построением графиков в этом случае у них все плохо и как раз тут надо городить свою приблуду на чистом Це/Це++
aabzel Автор
26.08.2023 23:20Я так понимаю что весь вышеописанный гемморой связан именно с этим? Настолько часто надо вводить, что нужно рожать решение, которое быстрее всех что-то делает?
Пользуюсь UART-CLI каждый день. И знаю еще с пол дюжены embedded контор, где тоже умеет UART-CLI.
Тут же представлен универсальный алгоритм, который парсит все числовые типы данных!
И задача парсинга вещественного числа из строчки на самом деле очень-очень простая для тех, кто не прогулял курс по теории автоматов в универе.Tiriet
26.08.2023 23:20+1да она и без МК актуальна- эксель до сих пор не понимает числа с точкой вместо запятой, а куча научного софта для всяких разрывных машин сохраняет данные в текстовый формат и именно с точкой. И пользователи этого софта тоже хотят вводить вещественные числа, и при этом не париться вопросом- запятую они там влупили, или точку, английскую е или русскую, 0.1 или .1е+0.
aabzel Автор
26.08.2023 23:20-1Я так понимаю что весь вышеописанный гемморой связан именно с этим?
Не только.
Double(ы) надо на лету парсить в NMEA протоколе, которым флудит каждый GNSS приемник в UART.
Так выделяются значения для широты и долготы инфа про спутники и много прочих системных параметров.buratino
26.08.2023 23:20+1Double(ы) надо на лету парсить в NMEA протоколе, которым флудит каждый GNSS приемник в UART.
Википедия говорит, что там 4800 бод скорость, в расширенном 38400, т.е. скорости никакие, Формат фиксированный, кривых ручечек нет.
Пользуюсь UART-CLI каждый день.
и что, что пользуетесь? сколько времени вы набираете в этом CLI double число? Допустим, секунду. И какой эффект будет от того что, вы сэкономите микросекунду на парсинге?
Tiriet
26.08.2023 23:20+1а реальная практика радиосвязи говорит, что иногда эти данные приходят битые- и тогда парсинг строки фиксированного формата превращается в черте что.
aabzel Автор
26.08.2023 23:20-2Я сделал парсер не для выйгрыша времени, а для корректного парсига любых форм записи.
С этим вот как раз проблемы у sscanf, которая даже "abc" считает double числом.

mayorovp
26.08.2023 23:20+3Да ну?
double d; int r; r = sscanf("abc", "%lf", &d); printf("r = %d", r); // r = 0Возвращаемое значение 0 означает что вещественное число прочитать не удалось. Ну и о каком "даже abc считает double числом" речь-то?

Zenitchik
26.08.2023 23:20-1Я так понял, что автору по ТЗ нужна ошибка при поступлении невалидной строки, а не интерпретация её как 0.
buratino
26.08.2023 23:20+1а кто ее интерпретирует как ноль?
int main(int argc, char * argv[]) { char *str = "abc"; char *str1 = "3.14"; double d = -1.; int rc; rc = sscanf(str, "%lf", &d); printf("rc = %d, str=%s, d=%f\n", rc, str, d); rc = sscanf(str1, "%lf", &d); printf("rc = %d, str1=%s, d=%f\n", rc, str1, d); return 0; } //Вывод //rc = 0, str=abc, d=-1.000000 //rc = 1, str1=3.14, d=3.140000


mayorovp
26.08.2023 23:20-1Почему перевод не отмечен как перевод? Судя по "словарю" в конце поста, где даётся расшифровка ни разу не применявшейся в тексте аббревиатуры DFA, это точно не авторский контент...

nikolz
26.08.2023 23:20+1вариант на Lua
function nkff(S) z0=string.byte('0'); z9=string.byte('9'); zE=string.byte('E'); zp=string.byte('+'); zm=string.byte('-'); zt=string.byte('.'); len=string.len(S); for j=1,len do m=string.byte(S,j); if m>32 then if m>=z0 and z9>=m then z2=true s1=true; else m=m&0xdf; if s1 then if m==zp or m==zm then if s1==nil or z1==zE then s1=true; end else if m==ze and (z1==zp or z1==zm) then s1=nil; break else s1=true; end end else if m~=ze then s1=true; end end z1=m; end z1=m; end end if z1==ze or z1==zp or z1==zm or z2==nil then s1=nil end return s1; endвариант на C
char nkff(char *ps) { char f=0; char z1=0; char s1=0; char z2=0; long len=strlen(ps); long j=0; while(len>j) { char m=ps[j]; if (m>32){ if(m>='0' && m<='9'){ s1=1; z2=1;} else { m=m&0xdf; if(s1){ if (m=='+' || m=='-') s1=1; else { if(m=='E' && (z1=='+' ||z1=='-')){ s1=0;break;} else s1=1; } } else { if (m!='E') s1=1;} } z1=m;} j++;} if (z1=='E' ||z1=='+' || z2==0)s1=0; return s1;}
dyadyaSerezha
Непонятно, почему scanf или подобные функции работают медленнее. Автор точно сравнивал с широко используемыми вариантами? Кстати, я бы вообще начал с того, что нашёл исходник какой-то известной функции, делающей то же самое, если уж нельзя по каким-то причинам использовать стандартную библиотеку.
DrSmile
Потому что у них требование выдавать абсолютно точный ответ (число, ближайшее к написанному). Эта задача, в общем случае, не решаема без софтварных флоатов повышенной точности, например. Собственно, вся сложность чтения вещественных чисел состоит именно в этом, а не в разборе символов, который пишется за один вечер.
zatim
Как может функция чтения вещественных чисел выдать число с точностью выше написанного? Сама придумает недостающие значащие разряды?
mayorovp
Я так понимаю, суть не в "точности выше написанного", а в отсутствии потерь точности при преобразовании в строку и обратно.
zatim
Ну, так если распознал/разобрал все цифры в строке, то и ничего не потерял, верно? Или я чего-то не понимаю? Что имел в виду комментатор выше?
VBDUnit
Число пишут в десятичной системе, а хранится оно в двоичной. Последние знаки часто невозможно сохранить точно, но можно компенсировать это избыточностью.
zatim
Число в одной системе счисления всегда точно конвертируется в число в другой системе счисления. В чем проблема то? Вообще то все числа, на минуточку, хранятся в двоичном коде, а выводятся на экран в десятичном. Почему со всеми остальными числами проблем нет, а тут вдруг они появились? Не хватает разрядности под мантиссу? Ну так надо взять число бОльшей разрядности, дабл вместо флоат.
VBDUnit
Так я и говорю, что
По поводу
а если у нас уже double? Вот мы и приходим к софтварным костылям.
zatim
В дабл 52 бита под мантиссу, это примерно 16 десятичных разрядов. Кому в микроконтроллере может понадобится точность с 15-ю знаками после запятой? В какой задаче с микроконтроллером может потребоваться выводить в строку числа с такими разрядностями? При такой огромной точности самый нормальный и простой костыль - просто откинуть младшие разряды.
mayorovp
Вот именно. Но для стандартной библиотеки такие костыли запрещены.
zatim
И какие же там костыли разрешены? Мне очень интересно стало) Пользователь пытается записать 20-разрядное число на место 16-разрядного. Что, интересно, функция будет с этим делать? Тут вообще то вариантов всего 2: сообщить пользователю что он дурак и ничего не делать и сообщить пользователю что он дурак и откинуть младшие разряды. Иных вариантов впихнуть невпихуемое не существует.
Zenitchik
На наивный взгляд, есть третий вариант: найти два соседних представимых числа, между которыми попадает заданное, и выбрать из них то, которое ближе.
zatim
А смысл? Точность самого числа от этого не повысится. Как было 16 разрядов, так и останется.
mayorovp
То что 20-разрядное число не впихнуть в 16 разрядов — это понятно, проблема в другом, когда пытаются впихнуть 4 разряда в 16. Казалось бы, чего тут сложного, но стоит один раз прочитав условные 0.003 записать их же обратно как 0.0029999999999999...
zatim
0,0029999999... получаются в результате математических операций с округлением. Причем здесь это? В статье и в комментариях речь идет о другом. О преобразовании строки "3е-3" в вещественное число 3е-3.
mayorovp
Притом, что ввод-вывод — это тоже операция с округлением. Ну нет среди возможных значений double такого числа как 3е-3!
zatim
Это кто вам такую чушь сказал?
trinxery
Ну вот так это работает. Есть 2.99999999999999919508830714676E-3 (0x3F689374BC6A7EF8) и следом за ним 3.00000000000000006245004513517E-3 (...EFA), на один бит различаются. Или как вы это себе представляли, почему нельзя, чтобы не было?
zatim
Ну, во первых, между 8 и А есть еще 9. Это так, к слову.
А во вторых, 3.00000000000000006245004513517E-3 это и есть 3е-3. Я же писал ранее, 52 разряда дабл - это 16 десятичных разрядов. Все остальное, что в них не поместилось - это мусорные данные.
dyadyaSerezha
Вам надо почитать про представление floating Point в двоичной виде. В частности, про представление мантисы в виде 1/2 + 1/4 +1/8....
zatim
И к чему вы эту "умную" мысль написали? С каким именно моим утверждением вы не согласны? Я бы, например, тоже предложил вам пойти кое-куда и почитать там кое-что.
Zenitchik
0x3F689374BC6A7EF9 = 2.99999999999999962876917614096E-3
0x3F689374BC6A7EFA = 3.00000000000000006245004513517E-3
У первого числа погрешность 3e-19, у второго - 6e-20.
А Вы предлагаете всегда вниз округлять.
UPD: Могу писать раз в час. На ответ ниже: похоже, что-то недопонял.
zatim
Ээээ... так ведь я это и утверждал в последнем комментарии. То есть, вы соглашаетесь со мной или просто недопоняли что я хотел сказать?
Tiriet
проблема в том, что нет вещественного числа 3e-3 (вещественного в смысле float, вещественное в смысле Re есть :-)). есть оооочень близкое к нему другое(!) вещественное число потому что 1/1000 = b1/b1111101000=(1/b1000)/b1111101=b1/(b10*b10*b10*b101*b101*b101)- и это бесконечная периодическая дробь, которая будет округлена до первых 52х знаков- округлена!
Tiriet
Подскажите, 1/5 в двоичной системе как точно представляется? у меня почему-то получается двоичная периодическая дробь, которая точно не представима в конечным числом двоичных знаков.
VBDUnit
Ну так, получается, избыточность c этим справится, но есть незначительный нюанс с требованиями к оборудованию :)
Разумеется, конечная избыточность не осилит то, что не представимо конечным числом знаков. К сожалению, или к счастью, арифметические сопроцессоры не умеют в периодические дроби на аппаратном уровне. Хотя это было бы интересно.
Речь не о том, что мы делаем избыточность, и, якобы, при каком‑то конечном уровне этой избыточности, получаем точное значение. Разумеется, это не так. Речь о том, что при каком‑то уровне избыточности точность будет достаточной для нашей конкретной задачи: при переводе из строки в бинарный вид и обратно, будет накапливаться такая ошибка, которой мы можем пренебречь.
Tiriet
это невозможно же! строка-то в десятичной системе, а число мы получим в двоичной системе. Конечные десятичные дроби могут быть периодичными двоичными дробями, поэтому число 0,2 в двоичной системе точно не представимо и преобразование туда-обратно обязательно даст отклонения в младшем бите. В численных расчетах сохранение промежуточных результатов в человекочитаемом виде приводит к тому, что повторная загрузка этих данных и продолжение счета с них отличаются от того, что рассчитывается без промежуточных сохранок-загрузок, а если нужно точное продолжение счета после загрузки сохранения- то приходится вещественные числа сохранять побитово, в разных форматах, но чтоб гарантировать побитовое совпадение записанного и считанного.
mayorovp
Отклонение в младшем бите — результат ожидаемый, конечная цель всех костылей — чтобы не было отклонения в младшем разряде строкового представления после преобразования туда и обратно.
aabzel Автор
Стандартная функция sscanf ненадежная для ответственных систем.
sscanf делает синтаксический разбор double тогда, когда это не требеется и при этом еще и выдает непредсказуемый результат.
Вот отчет тестирования функции sscanf.