

Чем больше задач выполняет приложение, тем тщательнее нужно следить за его производительностью. Под катом на примере Яндекс Браузера и приложения Яндекс с Алисой подробно расскажу о том, как мы отслеживаем аномалии метрик производительности на стороне клиента с помощью перф-тестов: основные принципы универсальны, и вы легко сможете использовать их для других типов приложений.
Читайте до конца: там вас ждёт чек-лист, на что обратить внимание и к каким инструментам присмотреться.
Производительность и её аномалии
Для начала предлагаю синхронизировать определения.
Формально производительность — это насколько эффективно мы используем ресурсы устройства. На деле гораздо важнее, как ощущает производительность наш пользователь: обычно он оценивает качество реакции приложения на свои действия в гораздо более бытовых метриках. Например, быстро ли работает приложение и не перегревается ли телефон в процессе его использования. Сейчас в индустрии всё чаще используют user-centric-подход.
Аномалия — статистически значимое изменение метрики производительности. Причём не только в худшую, но и в лучшую сторону (почему это важно, расскажу чуть позже). Для наглядности можно считать, что аномалия — это когда значения параметра, за состоянием которого вы следите, внезапно отклоняются на величину больше погрешности (в норме, когда на производительность ничего не влияет, значения должны быть примерно одинаковыми).
Как обнаружить аномалии производительности и измерить их: самые важные метрики
Зачем нужно уметь обнаруживать аномалии? В первую очередь, чтобы заранее понимать, как изменение продукта повлияет на его производительность. Или хотя бы быстро узнать, когда в продакшене что-то пошло не так, если предсказать аномалию не вышло: заметить проблему на графиках или получить уведомление о проблеме.
Также обнаруживать и измерять аномалии бывает полезно, когда мы оптимизируем производительность приложения: это ускоряет тесты и упрощает поиск возможностей для улучшения производительности. В итоге мы можем инвестировать ресурсы только в действительно полезные гипотезы.
Теперь расскажу о метриках, которые мы используем. Ключевыми мы считаем две группы метрик — скорость старта и скорость браузинга. Ещё мы следим за отзывчивостью интерфейса, потреблением RAM и CPU, но тут у нас, честно говоря, нет явных порогов и целей — просто исследуем и устраняем деградации, если вдруг они возникают.
Зачем ускорять именно старт и браузинг? На это у нас есть три причины:
Мы постоянно мониторим фидбэк и знаем, что у пользователей периодически что-то тормозит при загрузке. Как говорится, всё познаётся в сравнении: мы должны быть как минимум не хуже других браузеров. По многим показателям нам это удалось: например, по метрике FCP (First Contentful Paint или Первая отрисовка контента) на нашей SERP (Search Engine Result Page или Страница поисковой выдачи) мы лучше и на Android, и на iOS.
Мы проводили эксперименты — пробовали замедлять старт приложения. В итоге обнаружили закономерность: если ухудшить скорость старта на 10%, это отнимет 1% ретеншна (метрики удержания пользователей), что очень существенно.
Снижение производительности и замедление загрузки страниц часто вызывает деградацию продуктовых метрик. Приведу пример из статьи Google: замедление загрузки на 400 миллисекунд уменьшает количество поисков через приложение на 0,44%.
Так как у нас много браузинговых сценариев (практически все пользователи активно что-то ищут, переходят по ссылкам из поисковой выдачи и просто открывают новые вкладки с сайтами), нам важно следить, чтобы мы никак не замедляли действия пользователей в приложении.
Как получить данные для метрик
Сбор технической телеметрии
Получить, агрегировать, обработать. Для этого хорошо подходит, например, Firebase Performance Monitoring, или органайзер iOS. У нас в Яндексе есть свой инструмент для обработки телеметрии, а также для организации регулярных прогонов перф-тестов и анализа их результатов — Pulse.
Плюсы:
Полная репрезентативность. Агрегируя данные, мы получаем полную картину происходящего.
Можно проводить A/B-эксперименты. То есть сравнивать, насколько реальность совпадает с нашими предположениями. Но это реализовано не во всех аналитических системах: например, в органайзере iOS таким образом можно сравнить только разные версии продукта.
Минусы:
Нужна специальная система аналитики: либо платить за готовую, либо развивать собственную, а это довольно сложно.
Вы будете получать результаты с задержкой. Например, если мы что-то случайно ухудшили при очередном обновлении, то узнаем об этом уже постфактум.
Сложно корректно сравнить разные версии продукта. Версии раскатываются постепенно: кто-то устанавливает обновления сразу, кто-то долго продолжает пользоваться старой версией. На срезе метрик производительности в любой момент у пользователей, которые обновляются реже всех, обычно и устройство похуже и приложение работает помедленнее. Из-за этого выборки всегда будут смещёнными. Чтобы найти точки, в которых их можно честно сравнить, приходится, например, выравнивать на день раскатки метрики — это довольно-таки неудобно.

Стендовое измерение метрик с помощью перф-тестов
Собрать стенд, выполнить на нём перф-тесты, получить значения метрик и анализировать их.
Плюсы:
Раннее обнаружение аномалий. С помощью этого способа вы сможете обнаружить аномалии ещё до того, как продукт окажется у пользователя, и действовать проактивно.
Стабильность замеров. Это важно, поскольку пользовательские метрики обычно очень шумные, и постоянно меняются.
Минусы:
Нужно собрать перф-ферму. Комментарии, думаю, излишни.
Перф-ферма не сможет охватить все сценарии использования приложения, потому что невозможно собрать все на свете типы устройств в достаточном количестве и постоянно докупать новые, — это будет очень дорого.
Не до конца репрезентативные данные. Результаты не всегда можно перенести на реальных пользователей, потому что вы никогда не догадаетесь, как они используют ваше приложение на самом деле. Какое у них состояние окружения, используют ли они режим энергосбережения, роняли ли они телефон в бассейн — на конечную производительность влияет почти бесконечное количество факторов, которые вряд ли получится воспроизвести на перф-ферме.
Моя команда сталкивалась с тем, что результаты перф-тестов отличные, а в продакшене — ноль изменений или даже хуже. Но это редкость: чаще всего измерения на перф-ферме коррелируют с реальностью.
Погружение в перф-тесты
Готовые средства запуска перф-тестов для Android есть в свободном доступе в коде Chromium. Подобных инструментов для iOS мы не нашли, поэтому разработали своё решение. Chromium, который мы используем, довольно сильно отличается от Chrome, который содержит некоторые закрытые части. Возможно, перф-тесты для iOS со стороны Google просто не опубликовали, но мне, конечно, приятнее думать, что мы смогли решить задачи, с которыми до нас никто не справился.
Итак, зачем нужны перф-тесты? Конечно же, затем чтобы дать волшебный пинок всему, что замедляет наш продукт, и ускорить его!

Если серьёзно, то во-первых, перф-тест позволяет оценить быстродействие и потребление ресурсов в типичных сценариях, а также получить статистически значимые значения этих метрик.
Во-вторых, перф-тесты помогают мониторить параметры приложения прямо во время разработки, даже не задумываясь об этом. Разработчики спокойно занимаются кодом, делают пул-реквесты, вливают их, а потом система автоматически производит замеры и заводит тикеты со списками ухудшившихся метрик. Изучив эти изменения, обычно легко определить точное место просадки метрик и устранить его.
В-третьих, перф-тесты можно настроить так, как вам удобно, и выявлять аномалии (деградации и улучшения) производительности и потребления ресурсов на регулярной основе или для каких-то разовых задач.
Например, можно сравнивать быстродействие и потребление ресурсов между разными конфигурациями продукта, скажем, в разных экспериментах. Это помогает подготовиться к экспериментам заранее и выпустить их в продакшен уже протестированными, чтобы они не вызвали существенные деградации у пользователя и прошли для него как можно незаметнее.
Как устроены перф-тесты в Яндексе
Перф-ферма — это набор реальных устройств, специально настроенных для стабилизации замеров + хосты, которые запускают перф-тесты на устройствах и собирают результаты + инфраструктура обработки и анализа результатов перф-тестов на базе Chromium telemetry из набора Catapult.

Девборд (devboard) — это развёрнутая на плате начинка телефона без элемента питания, которая может быть вставлена в серверную стойку. Её нужно настроить специальным образом: так, чтобы перф-замеры были стабильными, а производительность не деградировала в зависимости от времени работы. Перф-тест на такой стойке будет стабильным и полезным.
Но так получается не всегда. Например, для iPhone девборды не выпускают. И для некоторых Android-смартфонов нам тоже пришлось собирать ферму самостоятельно: удалять аккумулятор, чтобы он опять-таки не вздулся и присоединять кабелем к отдельному компьютеру (мы называем такие компьютеры зомбиками — один из них как раз на картинке, с которой начинается пост). Зомбики устанавливают перф-тесты на эти устройства, гоняют их, собирают данные и отправляют на сервер для дальнейшей обработки.
Зомбики для Android работают на Linux, для iOS — на Mac mini. Инфраструктура обработки данных построена на базе Chromium Catapult: в этом наборе много полезных скриптов для статистической обработки результатов и визуализации данных, чтобы взаимодействовать непосредственно с устройством и красиво представлять всё, что получается.
Два перф-теста, которые мы запускаем, отражают производительность для двух самых популярных сценариев использования приложения:
StartupMetrics— старт приложения.NewTabNavYaSerpTop10— открытие поиска с New Tab Page.
Оба этих перф-теста можно запустить на ферме через наш CI-инструмент Pulse или локально на девайсе (на симуляторе для iOS или на эмуляторе для Android). Спустя время можно получить замеры и отладиться.
Какие метрики мы используем в перф-тесте StartupMetrics

Мы рассматриваем старт приложения с самой начальной точки — когда условный пользователь (на самом деле, естественно, автотест) запустил приложение. В этот момент происходит какая-то работа системы, которую описывают метрики Pre-Main.
Затем начинает выполняться Application Main — код нашего приложения. Он отображает главный экран и первый кадр, который мы отрисовали — это уже зависит от того, что мы написали в коде. Всё это измеряется метрикой First Contentful Paint: мы назвали её по аналогии с метриками из набора Web Vitals для веба.
Дальше происходит загрузка приложения и контента: на экране отображается то, что уже было загружено, появляются дополнительные элементы. Как только загрузится основной контент, который занимает бо́льшую часть экрана, мы измеряем метрику Largest Contentful Paint.
Потом в приложении продолжаются все те задачи, которые программисты любят запускать на старте. Если они выполняются на UI-потоке, они, как правило, вызывают лаги на старте — эту проблему можно заметить во многих приложениях. Чтобы такого не произошло, мы следим за UI-потоком и его загрузкой: ждём момента, когда он в течение незначительного промежутка времени — в нашем случае трёх секунд — будет свободен от задач, блокирующих его больше, чем на 50 миллисекунд. Этот момент называется Consistently Interactive State, и метрика, которая измеряет, когда эта стадия наступает, называется Time to Interactive.
Давайте разберёмся, как это работает на перф-ферме. Для измерения быстродействия в сценарии перф-тестирования взаимодействуют три приложения:
Target — наш браузер. Запускается на устройстве.
Runner — вспомогательное приложение, которое выполняет UI-тест и взаимодействует с Target.
Launcher на зомбике-хосте. Конфигурирует перф-тест и обрабатывает полученные результаты.
Так как перф-тест StartupMetrics существует сразу для двух приложений (Яндекс Браузер и Яндекс с Алисой), мы постарались его как-то унифицировать, объединить и параметризовать:
унифицировали перф-тест для приложений;
параметризовали метрики, аргументы запуска и количество итераций;
выполняем множество итераций для статистической значимости результатов;
реализовали прогон в виде UI-теста на каждый пул-реквест для защиты от слома.
Обратите внимание: прогнать перф-тест один раз недостаточно, нужно несколько итераций. Многие метрики постоянно отклоняются, они не до конца стабильны, и для того чтобы получить действительно статистически значимые результаты, нужна выборка данных. Но и прогонять перф-тест на каждое изменение тоже не получится. Просто потому, что это слишком дорого, перф-ферма не вынесет такого.
А ещё мы сталкивались с тем, что постоянные изменения в продукте могут ломать единожды написанный перф-тест: получаются нестабильные результаты или, например, перестаёт отображаться определённый экран, потому что его заслонили каким-нибудь поп-апом. Чтобы этого избежать, мы специально добавили в прогоны на каждое изменение укороченный перф-тест по факту — UI-тест с одной итерацией.
Теперь перейдём к тому, как мы снимаем эти метрики при запуске приложения. У нас есть несколько наборов.
Стандартные XCTest-метрики. Они есть в XCTest-фреймворке для iOS. Мы используем из доступного набора следующие метрики:XCTApplicationLaunchMetric — время старта, XCTCPUMetric — потребление CPU, XCTMemoryMetric — потребление RAM.
xcTestCase.measure(metrics: metrics, options: options) {
let app = XCUIApplication()
app.launchArguments = appLaunchArguments
app.launch()
_ = app.wait(for: .notRunning, timeout: 3) // need this to stabilize metrics collection
}Signpost-метрики. Это замер интервала с отметками через os_signpost: с помощью него можно отметить в коде приложения начало процесса и его окончание. Если задать в перф-тесте в XCTest-фреймворке signpost-метрику для вычисления продолжительности, вы получите просто разницу между timestamp конца и начала.
Мы используем эту метрику для Application Init и Application Launch: XCTOSSignpostMetric(name: "applicationInit") — время инициализации AppDelegate, а XCTOSSignpostMetric(name: "applicationLaunch") — время от создания AppDelegate до окончания didFinishLaunchingWithOptions.
os_signpost(.begin, log: signpostMarker, name: processName)
…
os_signpost(.end, log: signpostMarker, name: processName)Главный недостаток этого способа — нам сразу должно быть известно, когда приложение запускается и прекращает работать. Это не всегда возможно: например, с метрикой Pre-Main так не получится, так как момент её запуска не внутри нашего приложения, и мы не можем поставить там signpost.
Custom-метрики. Некоторые метрики можно измерить только ретроспективно. Например, Time to Interactive — 3 секунды, в течение которых приложение должно быть полностью интерактивным. Мы не можем вернуться в прошлое на 3 секунды и поставить там timestamp — signpost не позволяет это делать. Измерить с помощью signpost метрику Pre-Main тоже не получится, поскольку в нашем коде находится только завершение интервала Pre-Main, а начало — в коде операционной системы.
Чтобы передавать такие метрики, мы используем специальную систему: собираем их в коде браузера или приложения Яндекс и упаковываем в структуру, а потом открываем порт по TCP, чтобы отправить их. Порт всегда случайный, перф-тест передаёт его в параметрах запуска. За счёт этого при постоянном перезапуске перф-тестов мы случайно не наткнёмся на занятый порт. С клиента устанавливается соединение на localhost (потому что и перф-тест, и приложение выполняются на одном и том же устройстве) и пересылает метрики:
public struct StartupPerfMetrics: Codable {
public let preMainTime: Double
public let firstContentfulPaint: Double
public let largestContentfulPaint: Double
public let timeToInteractive: Double
public let mviTotalScore: Double
}
let host = "127.0.0.1"
let port = ProcessInfo.performanceMetricsPort
func send(payload: StartupPerfMetrics) {
let conn = NWConnection(host: self.host, port: self.port, using: .tcp)
let transmission = ClientDataTransmission(conn: conn, payload: payload)
DispatchQueue.global(qos: .userInteractive).async { [transmission] in
transmission.send()
}
}Здесь preMainTime содержит значение метрики Pre-Main, firstContentfulPaint — время отрисовки первого кадра, largestContentfulPaint — время отрисовки значимого контента, timeToInteractive — время наступления состояния устойчивой интерактивности.
Кроме того, в перф-тестах мы вычисляем Mobile Velocity Index (MVI) — это свёртка на базе трёх метрик: First Contentful Paint, Largest Contentful Paint и Time to Interactive. Они преобразуются к стобалльной шкале по оценкам:
Значение → Балл |
|||||||
Метрика |
100 |
95 |
85 |
70 |
50 |
25 |
0 |
First Contentful Paint |
0 |
500 |
1000 |
2000 |
3500 |
5000 |
10 000 |
Largest Contentful Paint |
0 |
500 |
1000 |
2000 |
3500 |
5000 |
10 000 |
Time to Interactive |
0 |
333 |
900 |
2000 |
4800 |
14 000 |
28 000 |
А затем по этой формуле вычисляется окончательная величина:
MVI — Mobile Velocity Index, FCP — First Contentful Paint, LCP — Largest Contentful Paint, TTI — Time to Interactive.
Это очень удобно в случае, когда метрики красятся в разных направлениях. Подробнее об этом можно узнать из моего доклада на конференции Mobius.
На стороне перф-теста мы наоборот открываем listener и ждём метрику. Потом сохраняем её в файл xcresult. А дальше xcresult понадобится зомбику для обработки результатов — он распарсит этот JSON и перешлёт данные для обработки в Pulse:
var additionalMetrics = [StartupPerfMetrics]()
let listener = try PerfMetricsListener<StartupPerfMetrics>()
listener.waitForMetrics(timeout: .xLongTimeout) { result in
additionalMetrics.append(result)
}
let metaAttachment = XCTAttachment(
uniformTypeIdentifier: "com.apple.property-list",
name: StartupMetricsMeta.metaAttachmentName,
payload: try PropertyListEncoder().encode(
StartupMetricsMeta(
iterationCount: iterationCount,
additionalMetrics: additionalMetrics
)
),
userInfo: nil
)
metaAttachment.lifetime = .keepAlways
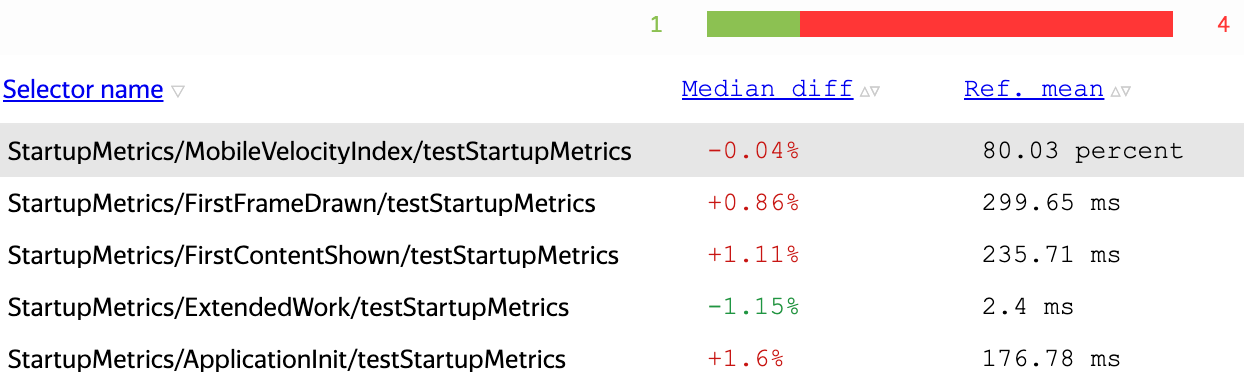
xcTestCase.add(metaAttachment)На скриншоте ниже для каждого изменения, помимо его относительной величины (в процентах) и абсолютной величины (в миллисекундах), отображается также статистическая значимость — p-value. Когда p-value=0, скорее всего, изменение не случайно, когда p-value>0, есть вероятность, что это всё-таки случайное отклонение.

В списке отображаются метрики, которые изменились: красные — ухудшились, зелёные — улучшились. p-value — вероятность того, что отклонение метрики случайно, жёлтые значения — недостоверные. Обратите внимание: мы записываем конфигурацию, в которой запускался именно перф-тест.
 и поверх него наложено изменение")
Жёлтый и чёрный графики — две конфигурации, которые сравнивались в перф-тесте. Жёлтый график немного выше. Значит, изменение, скорее всего, достоверное.
Из этих же мониторингов можно узнать сложные статистические параметры распределений, если требуется дополнительный анализ. Но мы обычно доверяем графикам.
Минусы перф-тестов и как их победить
Как я уже говорил, у перф-тестов есть свои минусы. Чтобы система перф-тестов для iOS заработала, нам пришлось решить несколько проблем.
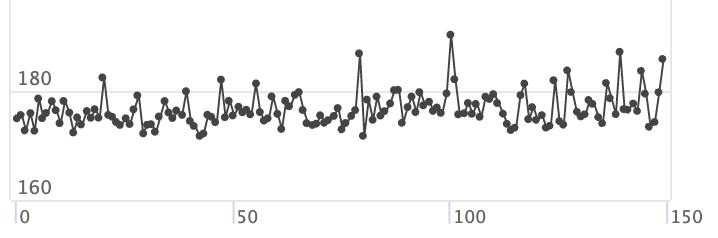
«Уплывание» перфов. Если постоянно запускать что-то на устройстве, оно постепенно нагревается, и центральный процессор замедляется. Из-за этого мы не могли достоверно сравнить несколько конфигураций приложения: те, которые мы запустили позже, всегда были медленнее.
Чтобы победить эту проблему, мы прогреваем устройство: то есть повторяем измерения метрик до тех пор, пока температура устройства не достигнет максимума и не перестанет расти. Чтобы определить этот момент, мы оцениваем наклон графиков по 50 итерациям измерений: если на линейной регрессии детектируем наклон с p-value больше чем 1%, отбрасываем эти результаты и гоняем тесты дальше, пока устройство не стабилизируется.
Разнонаправленные прокрасы. Часто бывает, что если в новой версии приложения что-то одно ускорилось, что-то другое тут же замедлилось. Чтобы понимать, уменьшилась или увеличилась при этом производительность всего приложения, мы разработали интегральную метрику Mobile Velocity Index (MVI): когда этот индекс улучшается или остаётся неизменным, можно принимать изменения в коде, даже если часть метрик, из которых складывается метрика, ухудшилась. А вот если MVI ухудшилась, надо выяснять, что не так.
Нестабильность окружения. Наше приложение часто выполняет сетевые запросы или как-то ещё взаимодействует с внешней средой через API операционной системы. Чтобы результаты перф-тестов не зависели от стабильности окружения, мы используем моки для простых вещей вроде геолокации и сетевых запросов. Если ответ сервера сложно заменить обычным моком, на помощь нам приходит технология Web Page Replay.
WPR — это инструмент Chromium, который воспроизводит ответы сервера на HTTP и HTTPS-запросы. Работает он в двух режимах — на запись и на воспроизведение заранее подготовленной WPR-ки.

У нас есть хост — зомбик на Mac mini, где мы подняли WPR-сервер. На этом хосте также есть DNS-табличка, которая отдаёт адреса для нужных сайтов: перенаправляет запросы на открытые порты устройства, которые слушает WPR-сервер. Естественно, чтобы такое провернуть, на устройство нужно установить доверенный сертификат.
После того как устройство отправляет запрос, он перенаправляется к WPR-серверу по DNS. Если на этот запрос есть предварительно записанная WPR-ка, сервер воспроизводит её и сразу возвращает ответ. Если WPR-ки нет, то сервер выпускает запрос наружу, в интернет. Это допустимо для некритичных запросов, но ответы на самые важные лучше всё-таки записывать.
Самый сложный для нас перф-тест — тот, что измеряет производительность страницы с поисковой выдачей: на него сервер должен выдавать самые заковыристые ответы. Поэтому мы предзаписываем для таких тестов WPR-ки: как откроется приложение, как на главной странице вводится запрос в Omnibox, как нажимается кнопка «Найти» и открывается веб-вкладка. Когда веб-вкладка выполняется, она собирает свои перф-метрики в JS-скрипте, а мы отправляем их в перф-тест по TCP-соединению и сохраняем то, что получится, в xcresult-файл.
Поиск аномалий
При разработке новых фич мы постоянно сравниваем сборки приложения из разных веток коммитов и сборки с разными конфигурациями фич. Это позволяет прокидывать дополнительные параметры командной строки и для iOS, и для Android, и даже для десктопного браузера: нужно только указать название фичи, имя параметра и его значение.
А ещё мы всегда мониторим производительность нашей главной ветки с автоматическим bisect, то есть обнаружением аномалии с точностью до коммита, в котором она появляется.

Восклицательными знаками показаны аномалии, которые система смогла детектировать сама. Понятно, что если с каждым коммитом привносить по очень маленькому изменению в одну миллисекунду, то это даст меньше погрешности, и там система не сработает. Но если есть какой-то коммит, который внёс существенную деградацию или, наоборот, улучшение, то система его найдёт.
Почему полезно детектировать не только ухудшения, но и улучшения? Потому что улучшение — это некоторые подсказки, как ещё можно повысить скорость приложения, в какую сторону продолжать исследования. Когда мы выбираем какую-то аномалию, то сразу видим информацию по ней. В случае, показанном на иллюстрации выше, bisect уже прошёл и сошёлся, к тому же одновременно автоматически завёлся тикет на аномалию, который выпадет на автора коммита.
Два примера практической пользы нашего подхода
Создание списка сервисов Яндекса
Всё, что создаётся на главном экране приложения Яндекса (список сервисов, кнопочки, которые можно нажать, и другие элементы) хранится у нас в компоненте, которая называется BottomSheet. При этом во время разработки мы поместили создание этого компонента сразу после отсечки метрики Largest Contentful Paint. То есть когда отрисовался основной контент — у нас это называется метрики фида — сразу грузится BottomSheet:
func makeFeedCardShownObserver(
mviReporter: MobileVelocityIndexReporter?,
appLaunchHistogramHelper: AppLaunchHistogramHelper,
reportFirstCardDisplayedExtended: @escaping Action,
weakBottomSheetGraph: Lazy<BottomSheetGraph>
) -> Action { {
mviReporter?.onFirstContentShown()
appLaunchHistogramHelper.onDidFirstCardDisplay()
reportFirstCardDisplayedExtended()
weakBottomSheetGraph.value.loadViewController()
} }
Но одна из составляющих нашей метрики Mobile Velocity Index — интерактивность. И оказалось, что операция, которая форсирует загрузку BottomSheet, вызывает лаг на UI-потоке. Хотя мы не видели этого на метриках, которые показывают просто время отрисовки контента, на метриках вида Time to Interactive и Total Blocking Time это стало очевидным.
На профайлере именно это место занимает много времени на UI-потоке, поэтому мы подготовили фичу, где инициализация всего BottomSheet полностью переносится на on-demand-действие: когда пользователь нажал, тогда и загружаем.
По результатам перф-сравнений гипотеза подтвердилась: метрика Time to Interactive выросла, Mobile Velocity Index тоже подрос (потому что выросла его составляющая Time to Interactive). Остальные метрики практически не изменились: индикаторной метрикой мы считаем CPU.
Таким образом нам удалось улучшить отзывчивость приложения на старте: +0.25% MVI Score, +1.66% TTI Score. Вот так выглядит эксперимент на продакшене — это данные нашей аналитической системы, которая обрабатывает всю телеметрию пользователей:

Починка переиспользования плейсхолдеров в DivKit
В этом примере всё начиналось совсем с другого сценария. Мы пытались пофиксить один баг, который наблюдался на первом старте приложения: плейсхолдеры странно мелькали. Когда мы начали исследовать код, обнаружили, что в этом месте одна из переменных сравнивается с собой же:
extension RemoteImageHolder {
public func reused(with placeholder: ImagePlaceholder?,
remoteImageURL: URL?) -> ImageHolder? {
(placeholder === placeholder && url == remoteImageURL) ? self : nil
}
}Добавили self:
extension RemoteImageHolder {
public func reused(with placeholder: ImagePlaceholder?,
remoteImageURL: URL?) -> ImageHolder? {
(self.placeholder === placeholder && url == remoteImageURL) ? self : nil
}
}Вроде бы всё отлично, всё починили, ничто, как говорится, не предвещало. Но разработчику после этой сложнейшей правки вдруг прилетает тикет с кучей деградировавших метрик:

Продолжили исследовать код и выяснили, что там, где сравнение раньше выдавало true, теперь возвращается false: плейсхолдеры постоянно пересоздаются, если их никак не кешировать. Тогда мы реализовали LRU cache для плейсхолдеров. Провели повторный перф-замер — победа, вся просадка отыгралась:

Как это всё применить: чек-лист
Надеюсь, мне удалось объяснить, как работает наш космолёт наша сложная, но полезная система. В качестве заключения соберу в один список все советы из статьи. Итак, как применить описанные мной подходы на практике, пока у вас нет собственных систем мониторинга.
Используйте мониторинги и телеметрию приложения, а также результаты перф-тестов. Выбрать что-то одно вряд ли получится: достоинства и недостатки подходов не пересекаются, поэтому лучше всего они работают вместе, а не по отдельности.
Обрабатывать телеметрию пользователей можно, например, с помощью Firebase Performance Monitoring или любых других открытых систем.
Стандартные фреймворки для перф-тестов вполне подходят для работы с основными метриками. Для iOS это XCTest от Apple, для Android — Macrobenchmark. Конечно, идеальный сценарий — собрать перф-ферму. Но, если не задаваться целью получить данные для всех существующих метрик, достаточно симуляторов или эмуляторов.
Что бы вы ни выбрали — перф-ферму из реальных устройств или симуляторы/эмуляторы — постарайтесь максимально устранить сайд-эффекты: их могут вызвать сторонние программы, работающие на том же устройстве, или, например, перегрев центрального процессора. Систему можно считать рабочей, если вам удалось добиться воспроизводимых результатов.
Одного перф-замера недостаточно. Всегда делайте несколько прогонов, а потом работайте не со средними значениями, а со статистически верными результатами. Все статистические методы уже реализованы и для Chromium Catapult, и для Python: есть готовые скрипты для вычисления p-value и сравнения групп.
Если пренебречь этим пунктом, вы рискуете отвлечься на шумные, а не настоящие изменения: по абсолютным значениям метрик легко получить ложное срабатывание мониторингов или выбрать высокий порог срабатывания и пропустить реальное ухудшение показателей.
Для разнонаправленных изменений лучше использовать интегральные метрики. Мы используем Mobile Velocity Index и всем советуем.
Комментарии (6)

Aquahawk
19.09.2023 07:28+1И ещё комментарий, только после создания перфтестов я понял насколько они жрут время на обслуживание, и насколько система тестирования деградирует, как только никто на ней не фокусируется. Чтобы перфтесты жили и нужно чтобы команда разработчиков хотела фокусироваться на производительности.

pavor84 Автор
19.09.2023 07:28Да, тут спасает покрытие тестами и какая-то автоматика, которая если вдруг все-таки что-то сломалось, автоматом заводит задачу на ответственного.
Aquahawk
19.09.2023 07:28А что за тул у вас такие графики рисует с учётом разброса?https://hsto.org/r/w1560/getpro/habr/upload_files/1ae/ab1/0df/1aeab10df8fe428d1c6f65df42b293a0.png
{kind=link}

klounader
19.09.2023 07:28А как отключить все эти метрики с перфтестами, чтобы все эти приложения перестали тормозить и начали наконец-то работать?
Aquahawk
О да, понимаю боль. У меня тоже есть маленькая перф фермочка на работе моего авторства. Мне надо тестировать, в том числе, производительность сети в приложении. Не смогли побороть пинги на wifi, в итоге девайсы подключены через type-c расширители где есть проводная сеть и зарядка. Мобила перестаёт быть подключена по usb, а становится подключена только по сети, ходить туда только через adb, а потыкать экранчик через https://github.com/Genymobile/scrcpy Работает.