
В условиях отсутствия возможности лицензирования и поддержки иностранных вендорских решений по хранилищам данных, встал вопрос о замене этих решений на отечественное программное обеспечение, с вендорской поддержкой, находящееся в реестре российского ПО и которое не уступает по производительности и объемам хранения зарубежным аналогам, таким как Teradata, Oracle, SAP HANA. Как показал анализ, таким требованиям отвечают лишь решения, основанные на MPP СУБД на базе Greenplum, в частности Arenadata DB (ADB). Но как быстро и безболезненно начать миграцию с привычных хранилищ на open-source? Постараюсь в статье рассказать и показать, что удалось придумать в этом направлении.
Исходя из нашего опыта разработки хранилищ данных на Greenplum и миграций на них, можем сказать, что для их внедрения в крупном бизнесе наличие общего инструмента и подхода, как стандарта разработки просто обязательно, иначе разработка и поддержка решения будет колоссально трудоемка.
«В статье мы говорим только о хранилище для условно теплых данных – ядра DWH (Data WareHouse). В качестве хранилища под регулярную отчетность мы Greenplum не рассматриваем»
Для начала быстрый ликбез о том, что такое MPP (Massively Parallel Processing) от Microsoft:
“Массивно-параллельная обработка (MPP) — это скоординированная обработка одной задачи несколькими обработчиками, каждый из которых использует свою операционную систему, память и взаимодействуют друг с другом с помощью того или иного интерфейса обмена сообщениями.”
Если вам нужно больше информации, то рекомендуем прочитать Как устроен massively parallel processing (MPP) в Trino
Особенности СУБД на базе Greenplum:
Массивно-параллельная система обработки – MPP
Колоночное хранение данных (что это такое?) – оптимально для OLAP сценариев
Широкие возможности интеграции с различными исходными системами – JDBC совместимыми СУБД, HDFS, S3, файловые системы - в рамках миграций это бывает критически важно
Открытый исходный код – нет вендор-лока
Возможность развертывания в облаке как сервиса (у некоторых провайдеров)
С какими проблемами можно столкнуться на начальных этапах при внедрении или миграции на Greenplum?
Во-первых, MPP-хранилище не оптимизировано для операций update, merge, delete так как, например, Oracle Database. Поэтому единственным оптимальным способом записи данных является вставка разово большого объема записей в таблицу и последующие манипуляции с партициями
Во-вторых, текущие вендорские ETL-решения (например, Informatica, SAP Data Services и другие) не оптимизированы для эффективной загрузки данных в кластерную базу, так как они не учитывают особенности многокомпонентной архитектуры Greenplum. В результате предпочтительные инструменты для параллельной загрузки данных, такие как pxf и gpfdist, не используются по-умолчанию, и их необходимо настраивать и адаптировать для работы с текущими решениями
В-третьих, даже если у вас есть настроенные инструменты для автоматизации процесса загрузки данных, необходим оркестратор. Оркестратор должен обеспечивать возможность установки расписания загрузок, просмотра истории загрузок, логирования выполнения заданий и управления зависимостями загрузок
Наконец, как показывает практика, внедрение инструментария с нуля выливается в целый серьёзный проект с командой разработки, тестирования, DevOps инженерами, значительно увеличивая сроки и бюджет миграции/внедрения.
Поэтому мы разработали инструмент автоматизации, позволяющий быстро и оптимально загружать данные в базу на основе MPP из исходных систем (заполнение слоя ODS) и выполнять вычисления для целевых витрин (DDS и слой витрин), автоматизируя при этом множество рутинных операций. Этот инструмент был разработан нашей внутренней командой и протестирован на нескольких проектах.
Мы выделили следующие ключевые моменты:
Внедрение фреймворка при исправной инфраструктуре занимает всего один день
Минимальное количество настроек и простота разработки позволяют оперативно загружать данные в базу
Фреймворк написан на процедурном языке PL/pgSQL для Greenplum и на Python для оркестрации на Apache Airflow, что обеспечивает прозрачность и упрощает будущие доработки
При загрузке данных используются особенности базы Greenplum, такие как работа с партициями, а также минимизируются тяжелые операции типа Update и Delete
Автоматизация рутинных операций – сбор статистики, добавление партиций, ведение интервалов дельты
В процессе миграции не требуется большая команда специалистов, и необходимые компетенции формируются в ходе работы
Фреймворк предоставляет инструменты оркестрации, логирования и мониторинга загрузок с помощью инструмента Apache Airflow с интуитивно понятным интерфейсом и большим активным комьюнити
Состав ETL-фреймворка
Из каких же компонентов состоит наш фреймворк?
-
Настроечные таблицы – метаданные
a. Основная таблица с настройками загружаемого объекта, способах загрузки, параметрах подключения и т.д. Например:
…для загрузки таблицы в ODS-слой (данные бенчмарка TPC-H, таблица позиций заказов ods_tpch.lineitem):
таданные для загрузки таблицы ods_tpch.lineitem …для расчета таблицы слоя DDS (очищенные данные счетов dds_tpch.sales):

Метаданные для расчета таблицы dds_tpch.sales b. Таблица с id загрузки, хранящая параметры загрузки объекта, в том числе параметры загружаемого инкремента данных для дельта-загрузок, количество загруженных строк, время выполнения:

Настройка отдельной загрузки данных c. Таблица с зависимостями между загружаемыми объектами – для построения графа загрузки

Зависимости при загрузке данных d. Логи – информация, записываемая в процессе работы механизма загрузки и расчетов. Опционально могут находиться в другой базе. Пока хранится в табличном виде, но мы планируем перейти на другой формат хранения логов в частично структурированном виде:

Логи процесса загрузки данных Ядро загрузчика представляет собой набор PL/pgSQL-функций (~70), которые обеспечивают загрузку данных различными способами, указанными в настройках объекта загрузки. Условно, эти функции можно разделить на следующие группы:
a. Сервисные функции занимаются ведением логов, сбором статистики, управлением блокировками и установкой/получением параметров.
b. Функции для манипуляции с данными (DML) позволяют выполнять операции вставки (вставка новых данных), обновления (изменение существующих данных) и удаления (удаление данных) в таблицах.
c. Функции для манипуляции с таблицами (DDL) занимаются созданием и удалением таблиц, а также добавлением/заменой партиций для оптимизации работы с данными.-
Оркестрация происходит через набор Python-модулей, создающих Directed Acyclic Graphs (DAG) - это набор связанных задач без циклов, которые содержат вызовы необходимых функций для расчета или загрузки нужного объекта данных (подробнее про концепцию можно прочитать тут). При создании DAG учитываются зависимости, которые были определены в исходных таблицах. Итоговый DAG выглядит следующим образом:

Граф загрузки данных Вызовы функций в Greenplum скрываются в соответствующих тасках каждой группы для отдельно загружаемого объекта:

Вызов функций в Greenplum Если развернуть DAG полностью, выглядит достаточно громоздко, но это для случая, когда мы хотим грузить все таблицы одним заданием:

Граф в развернутом виде
Описание работы ETL-фреймворка
Остановимся немного подробнее на способах обработки данных внутри фреймворка.
Для удобства во фреймворке разделены способы экстракции и загрузки данных как при загрузке из внешних систем, так и для внутренних расчетов.
Поддерживаемые способы экстракции: полная, дельта по метке времени, дельта по бизнес-дате:

Для экстракции данных фреймворк использует различные источники, такие как внутренние таблицы или представления, а также внешние таблицы, работающие по протоколу PXF, gpfdist или с помощью внешнего модуля на Python. Для загрузки данных из PostgreSQL, Greenplum, Oracle мы можем использовать dblink в сочетании с сервером foreign data wrapper. Когда данные извлечены, они попадают в слой стейджинга, и затем начинается этап загрузки, где эти данные применяются к целевой таблице.
При загрузке данных поддерживаются следующие способы:
Прямая вставка новых данных
Полная перегрузка данных, когда таблица полностью обновляется
Загрузка данных по определенному интервалу бизнес-даты, основанному на интервале партиционирования
-
Обновление дельты в различных вариациях

Варианты применения данных к цели
На нашем совместном вебинаре с компанией Arenadata мы более подробно рассказывали о загрузках данных из внешних систем с помощью фреймворка. Вы можете ознакомиться с примерами загрузок и демонстрацией работы по ссылке
В качестве примера рассмотрим загрузку данных в партиционированную таблицу Greenplum из другого хранилища, способного поставлять дельту. Анализируя возможные варианты настроек, мы пришли к выводу, что для поля extraction_type нужно выбрать DELTA, а для load_type - UPDATE_PARTITION.
Схематически процесс экстракции и загрузки будет выглядеть следующим образом:
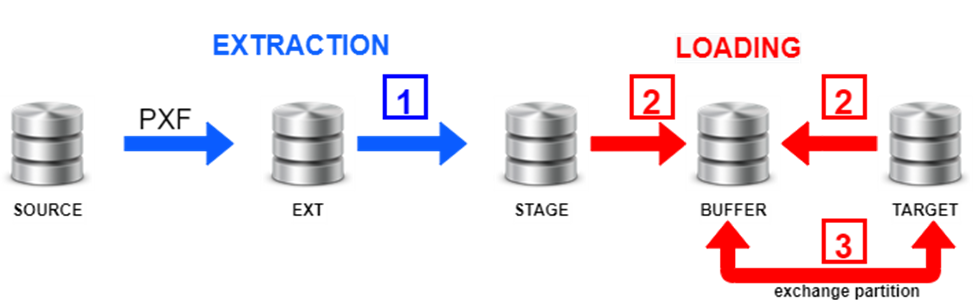
В этом процессе:
1 – происходит экстракция дельты,
2 – формируется буферная таблица из существующих данных в целевой таблице и новых данных из слоя стейджинга с приоритетом новых записей,
3 – происходит подмена соответствующей партиции в целевой таблице.
В контексте автоматизации загрузки данных и расчетов внутри Greenplum сделали следующее: все возможные преобразования данных от источника к целевой таблице (source -> target) оборачиваются в представление на уровне базы данных, которое соответствует структуре целевой таблицы. Затем, используя заранее написанный обработчик для внутренних загрузок – функцию простой загрузки f_load_simple, производится загрузка данных в целевую таблицу. Такой подход широко применялся для загрузки данных в слой детальных данных на наших проектах. Важно отметить, что этот способ не исключает использование различных моделей детального слоя данных, таких как Data Vault или 3NF, так как всю логику преобразований можно легко абстрагировать в представлениях.
Общая схема фреймворка с вариантами реализации представлена на схеме:

В наших проектах мы не ограничены определенным стеком технологий. В части оркестрации фреймворк был испытан с использованием различных инструментов, таких как Airflow, NiFi и SAP Data Services. В качестве источников данных использовались различные базы данных, такие как Oracle, SAP HANA, SAP BW on Oracle и PostgreSQL. Также мы проводили загрузки данных из файлов и выполняли расчеты с использованием Python-процедур
Как начать пользоваться?
В компании было принято решение об открытии кода проекта и помещении в open source под лицензией Apache на github
Это позволит заинтересованным в миграции компаниям быстро провести пилотный проект, оценить преимущества хранилище, удобство инструментария и, в конце концов, приступить к полноценной замене проприетарного ПО на open-source стек.
Со своей же стороны, мы надеемся на активное участие комьюнити в развитии нашего решения, свежие идеи и классные предложения по улучшению
Что в итоге?
Использование фреймворка решительно экономит трудозатраты при разработке и внедрении. О проекте в компании Комус можно послушать на выступлении с конференции "Большие данные большой страны"
Инструмент позволяет интегрировать в работу большую команду или команды как со стороны подрядчика, так и со стороны заказчика
Также он предоставляет возможность подключить внешнюю систему мониторинга загрузок и интегрировать ее с удобным для заказчика оркестратором
Из-за того, что загрузки идут через стандартизированные настройки, внедрение Data Lineage становится значительно проще. В наших разработках был использован Arenadata Catalog, для которого мы написали коннектор
Фреймворк не зависит от модели данных в хранилище и позволяет успешно применять различные модели, такие как 3NF, Data Vault или собственную внутреннюю
Приглашение на вебинар
Если вас заинтересовал наш инструмент, приглашаем на вебинар, посвященный демонстрации работы с фреймворком на живых данных.
igor_suhorukov
Какую версию GreenPlum вы используете?
ismailovda Автор
пока 6 (6.25.1), но с выходом GP7 фреймворк будет переделываться с учетом изменений в базе, в частности операций с партициями