
В своей работе я столкнулся с задачей вывода результата запроса с уже сформированными общими и промежуточными итогами по разным полям и решить ее мне помогла группировка с использованием Grouping Sets.
Я думаю многие знают что группировка начинается с GROUP BY и далее перечисляются все поля, по которым необходимо сгруппировать наши данные, например:
SELECT district, region, count(smth) as summ
FROM table
GROUP BY district, region;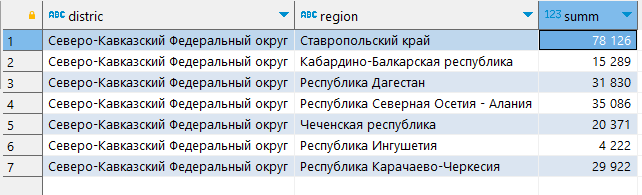
Причем мы обязаны указать все поля (кроме агрегирующей функции) в группировке, что логично, иначе зачем нам указывать поле, если по нему не нужна информация. Таким образом мы получим таблицу с уникальными строчками и суммой по каждой такой строчке.
Вроде бы все понятно, но а что если нам нужно добавить строчку с общей суммой по всем данным или отдельным полям прямо в самом запросе? Тут на помощь мне пришла конструкция GROUPING SETS. Давайте добавим её в запрос, чтобы получить строчку с общей суммой по всем данным:
SELECT district, region, count(smth) as summ
FROM table
GROUP BY GROUPING SETS ((district, region),());
Как видно, мы оставили группировку по (district, region) как в первом случае и еще добавили (), т.е. пустое поле, что означает общий итог по всем полям. И теперь добавилась строчка № 2 со значениями NULL в тех полях, по которым была произведена группировка, в данном случае оба поля участвовали в группировке, соответственно NULL в обоих полях. Давайте усложним запрос и посмотрим на общую сумму по каждому district.
SELECT district, region, count(smth) as summ
FROM table
GROUP BY GROUPING SETS ((region),(),(district));
Федеральный округ у нас один, сумма тоже одна, все сходится, но остальные строки district стали NULL. Это произошло из-за того, что мы разделили изначальную группировку (district, region) на две разные: (region), (district). Давайте попробуем расшифровать полученную конструкцию GROUP BY GROUPING SETS ((region),(),(district)):
мы говорим, сгруппируй нам данные по следующим наборам:
(region) - т.е. выведи общую сумму по каждому региону и добавь соответствующую строчку,
() - т.е. выведи общую сумму по всем полям и добавь соответствующую строчку,
-
(district) - т.е. выведи общую сумму по каждому федеральному округу и добавь соответствующую строчку.
А что будет, если оставить изначальную (классическую) группировку по всем полям и добавить группировку по district?:
SELECT district, region, count(smth) as summ
FROM table
GROUP BY GROUPING SETS ((region,district),(),(district));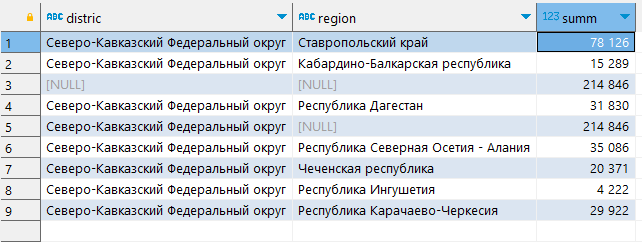
Красота! - здесь именно то, что и хотелось в начале - добавилась строчка с названием Федерального округа и суммой, а все NULL из прошлого запроса как бы заполнились district (кроме NULL, который для общего итога, конечно).
И что дальше с этим знанием делать? Напомню, у меня была задача в одном запросе добавить общий и промежуточный итог по федеральным округам. Давайте применим конструкцию CASE для замены NULL в полях, а именно:
SELECT district, region, count(smth) as summ,
CASE WHEN region is null and district is not null then CONCAT (district, ' ИТОГО')
else case when district is null and region is null then 'ОБЩИЙ ИТОГ'
else district end end as district_new
FROM table
GROUP BY GROUPING SETS ((region,district),(),(district))
ORDER BY district nulls FIRST, region nulls FIRST;
В итоге мы получили новое поле с общим и промежуточным итогами. Если было бы больше одного Федерального округа, общий итог просуммировал все значения по всем ФО.
Вот таким образом была решена задача с промежуточными итогами в одном SQL запросе. Тут конечно нужно будет доработать запрос, если в самих значениях будут NULL и как их отличить от NULL, получившихся в результате группировок, но это уже другая история.
Комментарии (12)

Portnov
01.10.2023 09:36+2В данном случае (когда группировка, по сути, иерархическая), вероятно, удобнее будет делать GROUP BY ROLLUP (district, region).

ptr128
01.10.2023 09:36Это без разницы, так как конструкции ROLLUP и CUBE - лишь синтаксический сахар над GROUPING SETS
Portnov
01.10.2023 09:36+2да, но если синтаксический сахар в данном случае удобен, то почему бы им не пользоваться :)

Akina
01.10.2023 09:36как конструкции ROLLUP и CUBE - лишь синтаксический сахар над GROUPING SETS
Ммм... а можно не согласиться? Что GROUPING SETS, что ROLLUP - всё это фильтрованный CUBE. А потому что над чем, ещё надо подумать..
ptr128
01.10.2023 09:36Не согласиться можно. Но фильтрованный CUBE подразумевает все же сначала вычисление всех агрегаций, с фильтрацией тех, которые не нужны. Так что вместо синтаксического сахара рискуем потерей в производительности. Все зависит от развитости оптимизатора запросов. Поймет ли он, что не нужно считать агрегаты, которые потом отфильтруются?
Akina
01.10.2023 09:36В поле группировки есть значения NULL - как отличить частную строку выходного набора (с группировкой по всем полям из выражения группировки) от дополнительной строки (с группировкой только по нескольким их них)? Тест поля на NULL - благополучно провалится...

Sdolgov
01.10.2023 09:36+2Действительно, использование null как признака группировки странновато. В Oracle есть спец функция grouping которой передается название столбца и она возвращает 1 или 0 в зависимости от того, свернут этот столбец (в статье null) или нет. Postgres не знаю, но почти наверняка эта функция есть и там.
ptr128
01.10.2023 09:36+2Для этой цели в PostgreSQL есть функция grouping(), возвращающая битовую маску, указывающую по каким именно столбцам была выполнена свёртка.
Akina
01.10.2023 09:36Да знаю... просто автору следовало бы описать эту функцию и дать ссылку на документацию (https://www.postgresql.org/docs/current/functions-aggregate.html#FUNCTIONS-GROUPING-TABLE) - а лучше даже с примером. Хотя в статье по рассматриваемой теме столько не упомянуто и пропущено, что и это не спасёт.
anton_t
А БД-то какая?
bolik_23 Автор
Postgres!)
strelkan
желательно указывать в посте, в тегах хотя бы