
Начав свою карьеру в качестве C# разработчика, я постоянно сталкивался с использованием техники внедрения зависимостей (Dependency Injection). За то время, что я работаю с C++, я не заметил здесь такого же широкого распространения этой идеи.
В то же время мне показалась весьма интересной такая возможность C++, как написание кода, который частично либо полностью может быть выполнен на этапе компиляции.
Объединив две эти идеи, у меня получилась простая библиотека для внедрения зависимостей, которая обходится средствами статического полиморфизма, не прибегая к позднему связыванию. О ней и пойдёт речь в этой статье. На её примере разберёмся с тем, как работает внедрение зависимостей и какие каждодневные проблемы оно решает.
Зачем внедрять зависимости?
Пожалуй каждый, кто работал с большими системами, хоть раз сталкивался с похожей ситуацией: внутри класса A создаётся объект класса B, который в свою очередь создаёт объект класса C.
class C {
...
};
class B {
C Dependency_;
...
};
class A {
B Dependency_;
...
};Написать тесты на класс A, не учитывая поведение классов B и C не получится. Как не получится безболезненно добавить конструктор с параметрами в класс C, ведь по цепочке эти параметры придётся добавить в конструкторы классов B и A.
Можно сказать, что система, состоящая из классов A, B и C обладает сильной связностью, поскольку изменение в одном из этих типов или замена его на другой приведёт к изменению кода в других частях системы.
Со временем программы обладающие сильной связностью становится трудно поддерживать и расширять; уменьшается частота релизов, увеличиваются количество багов и расходов на ручное тестирование.
Техника внедрения зависимостей (Dependency Injection) помогает решить эти проблемы через уменьшение связности кода и избавление от необходимости ручного управления зависимостями.
Как работает внедрение зависимостей
Внедрение зависимостей обычно требует использования специальной библиотеки (хотя в этом случае правильнее было бы сказать фреймворка, поскольку пользовательский код напрямую почти не использует компоненты библиотеки, а как бы встраивается в неё). Единственной точкой взаимодействия пользовательского кода с библиотекой является специальный класс - контейнер зависимостей (DI Container).
Можно сказать, что контейнер зависимостей - это фабрика объектов на стероидах, так как кроме создания самих объектов он умеет рекурсивно обходить и создавать все требующиеся этим объектам зависимости и управлять их временем жизни.
Особую прелесть технике внедрения зависимостей придаёт тот факт, что она поощряет программиста к созданию слабо связных, легко тестируемых и взаимозаменяемых типов. Это обусловлено тем, что для использования контейнера зависимостей пользовательские типы должны удовлетворять двум условиям:
Все зависимости пользовательских типов представлены абстракциями: базовыми абстрактными классами либо шаблонными параметрами.
Пользовательские типы сами не создают свои зависимости - они получают их через специальные методы-сеттеры либо через конструктор.
Вот как с учётом этих условий должны были бы выглядеть классы A, B и С, о которых мы говорили в самом начале:
template <typename T>
struct A {
T Dependency_;
explicit A(T dependency) : Dependency_(dependency) {
}
};
template <typename T>
struct B {
T Dependency_;
explicit B(T dependency) : Dependency_(dependency) {
}
};
struct C {
...
};Добавим контекст, чтобы понять от каких типов зависят A и B:
auto c = C();
auto b = B(c);
auto a = A(b);Для того, чтобы создать объект типа A, нам потребовалось предварительно создать объекты b и c. Давайте взглянем, как изменился бы этот код, если бы мы использовали контейнер зависимостей:
auto a = container.Resolve<A<>>();Как видите, мы не указываем явно, что создаваемый объект параметризован типом B. Это значит, что если мы решим заменить тип B на B*, нам не придётся долго выискивать все места в коде, где создаются объекты типа A.
Однако как контейнер узнаёт, объект какого типа нужно передать в конструктор типа A? Это знание настраивается специальным кодом либо конфигом в зависимости от библиотеки, которую вы используете. Кроме этого, конфиг обычно содержит описание времени жизни тех или иных объектов, но об этом поговорим чуть позже.
Пример выше слегка спекулятивный - он упускает некоторые детали, без которых контейнер зависимостей работать не будет. Однако это упрощение, на которое я иду намеренно, чтобы создать у вас общее понимание того, что из себя представляет внедрение зависимостей.
О том, как использовать эту технику в реальной жизни мы поговорим с вами прямо сейчас.
Шаг 1. Инвертируйте зависимости ваших типов
Первым делом нужно убедиться, что пользовательские типы в вашей системе обладают низкой связностью и удовлетворяют необходимым условиям.
Класс UnitOfWork представляет из себя обёртку над таблицами или коллекциями в базах данных, хранящих информацию о сотрудниках и департаментах. Каждая такая коллекция представлена репозиторием (Repository). UnitOfWork скрывает разрозненность данных за простым интерфейсом, позволяя работать с ними так, будто они все хранятся в одном месте.
template <
typename TEmployeeRepository = RepositoryDescriptor<Employee>,
typename TDepartmentRepository = RepositoryDescriptor<Department>>
class UnitOfWork {
private:
TEmployeeRepository* EmployeeRepository_;
TDepartmentRepository* DepartmentRepository_;
public:
// constructor
UnitOfWork(
TEmployeeRepository* employeeRepository, // injected dependency #1
TDepartmentRepository* departmentRepository // injected dependency #2
)
: EmployeeRepository_(employeeRepository)
, DepartmentRepository_(epartmentRepository) {
}
void CrateEmployee(const std::string& employeeName, int departmentId)
{
// create employee record
auto employeeId = EmployeeRepository_->Create({
.Name = employeeName
});
// add employee to department
auto department = DepartmentRepository_->Load(departmentId);
department.Add(employeeId);
// save updated department record
DepartmentRepository_->Update(department);
}
...
};UnitOfWork удовлетворяет двум условиям, о которых мы говорили выше:
он ничего не знает о том, с какими реализациями репозиториев работает, поскольку они скрываются за шаблонными аргументами TEmployeeRepository и TDepartmentRepository.
сущности репозиториев создаются и получаются из вне через конструктор.
Почему для скрытия реальных типов зависимостей используются шаблонные аргументы, а не абстрактные классы
Использование абстрактных классов подразумевает, что реальные типы зависимостей станут известны лишь на этапе выполнения. Это становится возможным благодаря виртуальными методам и возможности позднего связывания вызываемого кода с вызывающим.
Мы же нацелены на то, чтобы реальные типы зависимостей были известны уже на этапе компиляции, что позволило бы использовать раннее связывание. Типы шаблонных аргументов вычисляются на этапе компиляции, поэтому мы можем спокойно использовать их для скрытия реальных типов зависимостей.
Шаг 2. Зарегистрируйте зависимости
Возможно, вы обратили внимание на значения по умолчанию у шаблонных параметров:
template <
typename TEmployeeRepository = RepositoryDescriptor<Employee>,
typename TDepartmentRepository = RepositoryDescriptor<Department>>Эти типы есть не что иное как ключи (дескрипторы), которым соответствуют настоящие типы зависимостей, которые должна быть подставлены вместо них.
То, какая реализация должна быть использована вместо того или иного дескриптора описывается Binding-ами:
template <typename T>
struct RepositoryDescriptor {};
struct UnitOfWorkDescriptor {};
// RepositoryDescriptor<Employee>
template <>
struct Binding<RepositoryDescriptor<Employee>> {
using TService = MongoDBRepository<Employee>;
using TLifetime = Singleton;
};
// RepositoryDescriptor<Department>
template <>
struct Binding<RepositoryDescriptor<Department>> {
using TService = PostgreSQLRepository<Department>;
using TLifetime = Singleton;
};
// UnitOfWorkDescriptor
template <>
struct Binding<UnitOfWorkDescriptor> {
using TService = UnitOfWork<>;
using TLifetime = Singleton;
};Код выше декларирует, что везде, где встречается тип RepositoryDescriptor<Employee>, вместо него должен быть подставлен тип MongoDBRepository<Employee>, а вместо RepositoryDescriptor<Department> - тип PostgreSQLRepository<Department>. Следовательно, везде, где встретится UnitOfWorkDescriptor, должен использоваться тип UnitOfWork<>, или точнее UnitOfWork<MongoDBRepository<Employee>, PostgreSQLRepository<Department>>.
Структура Binding
Структура Binding описывает какой реальный тип (TService) должен быть подставлен вместо того или иного ключа (TDescriptor):
template <typename TDescriptor>
struct Binding {
using TService = TDescriptor;
using TLifetime = Transient;
};Зная дескриптор, получить соответствующий ему реальный тип можно прямо на этапе компиляции:
Binding<RepositoryDescriptor<Employee>>::TService; // MongoDBRepository<Employee>
Binding<RepositoryDescriptor<Department>>::TService; // PostgreSQLRepository<Department>При этом по умолчанию, если для указанного типа не определена спецификация шаблона Binding, он будет соответствовать самому себе:
Binding<MongoDBRepository<Employee>>::TService; // MongoDBRepository<Employee>
Binding<int>::TService; // intЗачем такие сложности? Почему было не написать прямо в коде класса UnitOfWork, какие реализации ему стоит использовать?
template <
typename TEmployeeRepository = MongoDBRepository<Employee>, // BAD!!!
typename TDepartmentRepository = PostgreSQLRepository<Department>> // BAD!!!Причина та же, по которой мы объявляем константы в коде. Если однажды мы решим мигрировать данные о департаментах из PostgreSQL в MongoDB, то нам придётся вносить соответствующее изменение во всех местах программы, где используется репозиторий департаментов, а так у нас такое место в программе лишь одно и переезд на новую базу потребует изменения лишь одной строчки кода:
template <>
struct Binding<RepositoryDescriptor<Department>> {
- using TService = PostgreSQLRepository<Department>; // before
+ using TService = MongoDBRepository<Department>; // after
using TLifetime = Singleton;
};Шаг 3. Задайте время жизни
Вероятно, уже заметили строчку using TLifetime =... внутри Binding-ов.
Это весьма интересная возможность, которую предоставляет контейнер зависимостей. Она заключается в том, что вы можете сами выбирать, объекты каких типов должны создаваться заново при каждом обращении к контейнеру (Transient); какие должны жить столько же, сколько породивший их контейнер и переиспользоваться в качестве зависимостей при создании других объектов внутри этого же контейнера (Scoped); а какие создадутся лишь однажды и будут уничтожены только при завершении программы (Singleton).
Шаг 4. Создайте контейнер
Прежде, чем начать пользоваться контейнером, в нём нужно зарегистрировать зависимости ваших типов. Регистрации представляет из себя перечисления всех типов, создание которых может быть запрошено у контейнера напрямую или косвенно при инициализации зависимостей этих объектов:
Container<
RepositoryDescriptor<Employee>,
RepositoryDescriptor<Department>,
UnitOfWorkDescriptor
> container;
UnitOfWork<>* unitOfWork = container.Resolve<UnitOfWorkDescriptor>();Если реальному типу соответствует дескриптор, то при регистрации зависимостей в контейнере указывается именно дескриптор, а не реальный тип.
Шаг 5. Начните пользоваться
Давайте создадим парочку сервисов, используя наш контейнер:
std::cout << "Create container...\n";
TContainer container;
std::cout << "Create unitOfWork1...\n";
auto* unitOfWork1 = container.Resolve<UnitOfWorkDescriptor>();
unitOfWork1->CrateEmployee("Bob", /* departmentId: */ 1);
std::cout << "Create unitOfWork2...\n";
auto* unitOfWork2 = container.Resolve<UnitOfWorkDescriptor>();
unitOfWork2->CrateEmployee("Alice", /* departmentId: */ 2);
std::cout << "End\n";UnitOfWork был зарегистрирован с временем жизни Scoped, поэтому контейнер создаст его сущность лишь один раз и в обоих случаях вернёт один и тот же указатель на неё.
> Create container...
> Container: Ctor
> Create unitOfWork1...
> MongoDBRepository<Employee>: Ctor
> PostgreSQLRepository<Department>: Ctor
> UnitOfWork<MongoDBRepository<Employee>, PostgreSQLRepository<Department>>: Ctor
> Create unitOfWork2..
> EndРепозитории были зарегистрированы с временем жизни Singleton. Это значит, что даже если обернуть весь код из листинга выше в цикл, то репозитории всё-равно будут созданы не более одного раза.
> ############################ Iteration 1 #######################################
> Create container...
> Container: Ctor
> Create unitOfWork1...
> MongoDBRepository<Employee>: Ctor
> PostgreSQLRepository<Department>: Ctor
> UnitOfWork<MongoDBRepository<Employee>, PostgreSQLRepository<Department>>: Ctor
> Create unitOfWork2..
> End
> ############################ Iteration 2 #######################################
> Create container...
> Container: Ctor
> Create unitOfWork1...
> UnitOfWork<MongoDBRepository<Employee>, PostgreSQLRepository<Department>>: Ctor
> Create unitOfWork2..
> End
> ############################ Iteration 3 #######################################
> Create container...
> Container: Ctor
> Create unitOfWork1...
> UnitOfWork<MongoDBRepository<Employee>, PostgreSQLRepository<Department>>: Ctor
> Create unitOfWork2..
> EndОтлично, мы увидели, как работает внедрение зависимостей. Самое время разобраться за счёт чего оно работает. Для этого заглянем под капот контейнера зависимостей, который использовался в примерах выше.
Фабрика объектов
Одной из основных функции контейнера зависимостей является создание объектов, запрашиваемого типа, что подходит под определение фабрики. С неё и начнём.
Типы без зависимостей
Простейшая фабрика для создания объектов, имеющих конструктор без параметров, выглядит так:
template <typename TService>
struct ServiceFactory {
static TService Create() {
return TService();
}
};Про стиль кода, именования и мелкие оптимизации
Код выше можно немного улучшить:
template <typename TService>
struct ServiceFactory {
static constexpr TService Create() {
static_assert(std::is_default_constructible_v<TService> /* , пояснение ошибки */);
return {};
}
};В случае, когда TService имеет конструктор без параметров, помеченный как constexpr и способный выполниться на этапе компиляции, метод Create может быть также выполнен на этапе компиляции.
Хорошим тоном по отношению к пользователям вашей библиотеки будет добавить проверки времени компиляции. Это позволит им быстро находить проблемы в своём коде и проще разобраться в возможностях и ограничениях вашей библиотеки. Здесь, например, мы можем проверить, что тип, сущность которого мы создаём, имеет доступный конструктор без параметров.
Лишь для того, чтобы не отпугнуть читателя от и так не самого тривиального кода, я специально не буду добавлять проверки времени компиляции и необязательные оптимизации там, где этого можно избежать. Я уверен, что после прохождения вместе со мной всего пути по созданию своего контейнера, вам не составит труда сделать эти улучшения самим.
Стиль кода, которого я буду придерживаться, может быть не тем, к которому вы привыкли или используете у себя на работе. Я ни в коем случае его не навязываю, как и не настаиваю на назывании тех или иных компонентов.
Используя такую фабрику, можно создать объект любого типа, имеющего конструктор без параметров:
Employee employee = ServiceFactory<Employee>::Create();Типы с зависимостями
Для типов, имеющих зависимости, например UnitOfWork реализация фабрики станет немного сложнее, но не пугайтесь, ниже мы разберём её по винтикам:
template <template<typename ...> class TService, typename... TTemplateArgs>
struct ServiceFactory<TService<TTemplateArgs...>> {
static auto Create(auto& container) {
using TRealType = ReplaceDescriptors<TService<TTemplateArgs...>>::TResult;
if constexpr (std::is_constructible_v<TRealType, decltype(container.template Resolve<TTemplateArgs>())...>) {
return TRealType(container.template Resolve<TTemplateArgs>()...);
} else {
return TRealType();
}
}
};template<template>
Благодаря объявлению этой фабрики как шаблон шаблонов (template <template>), она будет вызвана для всех типов TService, которые являются шаблонами. Для всех остальных будет вызвана первая версия фабрика для типов без зависимостей. При этом компилятор сможет вычислить шаблонные аргументы такого типа и поместить их в TTemplateArgs.....
В случае вызова такой фабрики для UnitOfWork<>, значение TService окажется равно типу UnitOfWork<>, а TTemplateArgs... будут содержать в себе RepositoryDescriptor<Employee> и RepositoryDescriptor<Department> в соответствии со значениями по умолчанию шаблонных аргументов класса UnitOfWork<>:
template <
typename TEmployeeRepository = RepositoryDescriptor<Employee>,
typename TDepartmentRepository = RepositoryDescriptor<Department>>
class UnitOfWork {Получение реального типа создаваемого объекта
Первой строчкой кода в фабрике идёт вычисление реального типа создаваемого объекта:
using TRealType = ReplaceDescriptors<TService<TTemplateArgs...>>::TResult;Дело в том, что тип объекта, созданного фабрикой, может отличаться от того типа, с которым фабрика была вызвана (TService<TTemplateArgs...>). Это происходит в том случае, если среди шаблонных параметров содержатся типы-дескрипторы, которые заменяются на соответствующие им реальные типы.
В случает UnitOfWork<> значение типа TService<TTemplateArgs...> будет равно:
UnitOfWork<RepositoryDescriptor<Employee>, RepositoryDescriptor<Department>>Однако, в соответствии с кодом регистрации зависимостей, будет создан объект типа:
UnitOfWork<MongoDBRepository<Employee>, PostgreSQLRepository<Department>>При этом, стоит учитывать, что шаблонные аргументы могут также быть шаблонами и иметь свои вложенные дескрипторы. Утилита ReplaceDescriptors позволяет рекурсивно обойти все шаблонные аргументы и, если они являются дескрипторами, заменить их на соответствующие им реальные типы.
template <typename TDescriptor>
struct ReplaceDescriptors {
using TResult = TDescriptor;
};
template <template <typename ...> class T, typename ...TDescriptors>
struct ReplaceDescriptors<T<TDescriptors...>> {
using TResult = T<
typename ReplaceDescriptors<typename Binding<TDescriptors>::TService>::TResult...
>;
};Давайте разберёмся, как ReplaceDescriptors работает для UnitOfWork<>:
Тип UnitOfWork<> шаблонный, поэтому мы попадаем во вторую спецификацию шаблона ReplaceDescriptors. В качестве T будет UnitOfWork, а в качестве TDescriptors... - RepositoryDescriptor<Employee> и RepositoryDescriptor<Department>.
T, то есть UnitOfWork<>, остаётся без изменений, а вот для каждого из шаблонных аргументов происходит вычисление его реального типа через
typename Binding<TArgs>::TService.
Если тип на самом деле является дескриптором, то мы получим соответствующий ему реальный тип: RepositoryDescriptor<Employee> станет MongoDBRepository<Employee>.
Если же он не является дескриптором (например, Employee), то мы получим этот же тип без изменений.Для каждого реального типа, полученного на шаге 2, рекурсивно вызывается ReplaceDescriptors.
Если тип является шаблоном, то мы попадаем на шаг 1 и рекурсия продолжается.
Если же тип шаблоном не является, то попадаем в первую спецификацию утилиты ReplaceDescriptors и рекурсия на этом заканчивается.

На изображении выше зелёным отмечены реальные типы, которые не требуют замены. Красным же отмечены типы, которые потенциально могут оказаться дескрипторами и в этом случае их нужно заменить. Рекурсия продолжается до тех пор, пока не доходит до реальных нешаблонных типов Employee и Department.
Инициализация зависимостей
Зависимости внедряются в объект через его конструктор. Мы уже умеем вычислять реальный тип создаваемого объекта (TRealType). Самое время научиться получать аргументы для конструктора.
В силу того, что в нашем арсенале отсутствует такой механизм как отражение (reflection), нам придётся пойти на одну уловку. Сделаем допущение: если тип имеет конструктор с параметрами, то список этих параметров по структуре совпадает со списком шаблонных аргументов.
Иначе говоря, если тип Foo зависит от типов A, B, и С, то описание его шаблонных аргументов и конструктора выглядит следующим образом:
template <typename A, typename B, typename C>
struct Foo {
Foo(A a, B b, C c); // constructor
};Значения типов A, B и C содержатся в шаблонном аргументе TTemplateArgs... нашей фабрики. Вызов контейнера зависимостей для каждого типа из TTEmplateArgs... позволит создать объекты типов A, B и C, которые и являются аргументами конструктора класса Foo.
return TRealType(container.template Resolve<TTemplateArgs>()...);Почему вызываем контейнер, а не фабрику? Контейнер внутри себя использует фабрику, однако если какой-нибудь из типов A, B, C окажется дескриптором, контейнер предварительно заменит его на соответствующий тому реальный тип. Кроме того, контейнер хранит в себе пул Scoped и Singleton объектов, что позволяет переиспользовать ранее созданные объекты.
Получается, что контейнер просит фабрику создать объект некоторого конкретного типа. Фабрика извлекает зависимости этого типа в виде дескрипторов и идёт с ними обратно в контейнер. Контейнер, получив дескрипторы, определяет соответствующие им реальные типы и просит фабрику создать объекты уже этих типов. Созданные объекты контейнер отдаст вызвавшее его фабрике. Этот рекурсивный пинг-понг продолжается до тех пор, пока не будет построено всё дерево зависимостей.

Примерно так выглядел бы вызов конструктора UnitOfWork<>:
return UnitOfWork<MongoDBRepository<Employee>, PostgreSQLRepository<Department>>(
container.Resolve<RepositoryDescriptor<Employee>>(),
container.Resolve<RepositoryDescriptor<Department>>());Как быть с шаблонами, у которых нет зависимостей?
Однако возможности автоматического вычисления аргументов конструктора из шаблонных параметров не достаточно для удобной работы с контейнером.
Что будет, если попросить фабрику создать объект типа std::vector<std::string>? Это шаблон, значит будет вызвана фабрика для типов с зависимостями. Но ведь вектор не имеет конструктора, принимающего строку. А даже, если и имел, то вызовы конструкторов std::vector<std::string>()и std::vector<std::string>("") явно давали бы разный результат.
Именно поэтому, прежде чем вызывать конструктор с параметрами, необходимо убедиться, что такой конструктор вообще существует. Для этого используется условная конструкция:
if constexpr (std::is_constructible_v<
TRealType,
decltype(container.template Resolve<TTemplateArgs>())...
>) {std::is_constructible_v<T, ...TArgs> - это проверка времени компиляции, позволяющая определить, можно ли создать объект типа T из аргументов типа TArgs....
Здесь мы проверяем, что объект типа TRealType может быть сконструирован из значений, полученных при разрешении зависимостей контейнером. Если условие не выполняется, нам не остаётся ничего другого, кроме как вызвать конструктор без параметров:
} else {
return TRealType();
}Отличие if constexpr от обычного if
Сам по себе оператор if является оператором времени выполнения. Ключевое слово constexpr позволяет ещё на этапе компиляции вычислить значение условия и отбросить ненужную ветвь.
Если бы проверка делалась на этапе выполнения, то компилятор был бы вынужден всегда держать в уме обе ветви, а значит шаблонные типы были бы обязаны всегда иметь оба конструктора (с набором параметров, соответствующим списку шаблонных аргументов, и без параметров). В противном случае компиляция завершалась бы ошибкой.
Фабрики для нетривиальных типов
Две спецификации фабрики, представленные выше, покрывают абсолютное большинство пользовательских типов. Однако, время от времени некоторые типы всё-равно выбиваются из общей картины мира и для них приходится заводить свои отдельные фабрики.
Сделать это совсем не сложно. Для этого достаточно объявить спецификацию шаблона фабрики для нужного типа.
template<>
struct ServiceFactory<LoggerDescriptor> {
static auto Create(auto&) {
return Logger("[%s] %s %s\n"); // Logger with custom format
}
};Кроме того, из спецификации фабрики для отдельного типа остаётся возможность обращения к контейнеру:
template<typename T>
struct ServiceFactory<MongoDBRepository<T>> {
static auto Create(auto& container) {
return MongoDBRepository<T>(container.template Resolve<MongoDBSettings>());
}
};Время жизни
В библиотеке DependencyInjection на платформе .Net используется 3 типа времени жизни объекта:
Transient - при каждом обращении за таким объектом, контейнер будет создавать новый объект. Используется редко, в основном в ситуациях, когда по каким-либо причинам вам не хотелось бы явно создавать объект через явный вызов конструктора (например, объект создаётся во многих местах программы и имеет нетривиальный набор аргументов конструктора).
Singleton - один и тот же объект используется при каждом обращении. Объект создаётся при первом обращении. Используется когда тип не имеет состояния (stateless), либо состояние должно быть доступно на всём протяжении жизни программы, а его пересоздание нежелательно - например, соединение с базой данных.
Scoped - то же самое, что Singleton, только уникальность и время жизни объекта ограничены областью видимости, внутри которой он создан. Например, это может быть локальный кэш, ограниченный временем жизни одного HTTP-запроса.
По моему опыту такого набора оказывается достаточно в 99.99% случаев, во всех остальных случаях имеют место быть ошибки в проектировании системы, исправив которые можно обойтись этими тремя типами.
Тем не менее в нашей библиотеке мы опишем этот механизм таким образом, чтобы при желании добавить свой тип времени жизни или области видимости объекта (например, ThreadLocal), не составило бы большого труда.
Объявим наши типы времени жизни объектов:
struct Singleton {};
struct Scoped {};
struct Transient {};Следуя принципу наименьшего удивления, в базовом Binding-е по умолчанию устанавливаем время жизни Transient:
template <typename TDescriptor>
struct Binding {
using TLifetime = Transient;
using TService = TDescriptor;
};Согласитесь, вы были бы удивлены, если бы оказалось, что объект, для которого вы явно не "продлевали" время жизни, жил бы до самого завершения программы и использовался разными её частями, как это происходит в случае Singleton-а.
Сами по себе типы времени жизни ничего не делают - это просто теги. Для каждого из них нужно создать свой LifetimeManager, который будет управлять временем жизни подопечного объекта.
template <typename TDescriptor, typename TLifetime = typename Binding<TDescriptor>::TLifetime>
struct LifetimeManager;Transient
Здесь всё достаточно просто: на каждый новый вызов мы просто создаём новый объект, используя фабрику:
template <typename TDescriptor>
struct LifetimeManager<TDescriptor, Transient> {
using TService = Binding<TDescriptor>::TService;
auto GetOrCreate(auto& container) {
return ServiceFactory<TService>::Create(container);
}
};Фабрика в качестве шаблонного аргумента принимает дескриптор, а не реальный тип, поэтому нам предварительно нужно его получить, используя Binding.
Singleton
template <typename TDescriptor>
struct LifetimeManager<TDescriptor, Singleton> {
using TService = Binding<TDescriptor>::TService;
auto GetOrCreate(auto& container) {
static auto instance = ServiceFactory<TService>::Create(container);
return std::addressof(instance);
}
};Здесь у нас реализация простейшего синглтона. Важно заметить вот что: в отличие от Transient, где мы просто возвращали созданный объект, здесь мы возвращаем указатель на объект, то есть сохраняем владение объектом. Это необходимо, чтобы объект продолжал существовать в единственном экземпляре.
Ещё один интересный момент - это функция std::addressof. Не забывайте, что мы пишем библиотеку, а значит должны держать в уме всё обилие техник и средств, которое нам предоставляет C++. Одной из них является переопределение оператора &. std::addressof защищает нас от этого (благодарю стажёра и в последствие коллегу, который мне об этом рассказал).
Scope
template <typename TDescriptor>
struct LifetimeManager<TDescriptor, Scoped> {
using TService = Binding<TDescriptor>::TService;
using TRealType = ReplaceDescriptors<TService>::TResult;
auto GetOrCreate(auto& container) {
if (!Instance_.has_value()) [[unlikely]] {
Instance_ = ServiceFactory<TService>::Create(container);
}
return std::addressof(Instance_.value());
}
private:
std::optional<TRealType> Instance_;
};Scoped похож на Singleton. Однако в отличие от Singleton-а время жизни объекта здесь ограничено временем жизни смого LifetimeManager-а, то есть его скоупом.
Созданный объект хранится как поле класса Instance_. Здесь у нас снова возникает проблема связанная с тем, что настоящий тип созданного фабрикой объекта (TRealType) может отличаться от того типа, с которым мы фабрику вызывали (TService). Это происходит в том случае, если TService является шаблоном (например, UnitOfWork<>) и среди его шаблонных параметров есть дескрипторы, которые в при создания объекта заменяются на соответствующие им реальные типы.
Для того, чтобы узнать нужный для хранения объекта объём памяти и правильно выровнять в памяти поле Instance_, нам нужно знать реальный тип объекта, который вернёт фабрика. Для этого можем снова воспользоваться утилитой ReplaceDescriptors.
using TRealType = ReplaceDescriptors<TService>::TResult;Почему не decltype(ServiceFactory<TService>::Create(container))
Согласен, так было бы куда удобнее и получилось бы избавиться от утилиты ReplaceDescriptors (которую, между нами, я воспринимаю как занозу, а не красивое инженерное решение).
Проблема здесь в наличии аргумента containerу метода ServiceFactory::Create, тип которого не известен вне метода GetOrCreate(). Использовать declval вместо контейнера не получается, так как контейнер - это шаблонный тип с переменным количеством аргументов, которые не известны внутри класса LifetimeManager.
Я потратил много времени, пытаясь обойти это ограничение, но в условиях текущего дизайна библиотеки мне это сделать не удалось. Буду очень рад свежим и более простым идеям решения этой задачи.
Контейнер зависимостей
Последним кирпичиком, которого не хватало нашей библиотеке, является сам контейнер зависимостей:
template <typename ...TDescriptors>
class Container {
private:
std::tuple<LifetimeManager<TDescriptors>...> ObjectPool_;
public:
template <OneOf<TDescriptors...> TDescriptor>
constexpr auto Resolve() {
return std::get<LifetimeManager<TDescriptor>>(ObjectPool_)
.GetOrCreate(*this);
}
template <typename TDescriptor>
constexpr auto Resolve() {
return std::nullopt;
}
};Контейнер хранит LifetimeManager-ы для всех дескрипторов, о которых ему известно. Используя LifetimeManager-ы он получает доступ к создаваемым фабрикой объектам, однако контроль за временем жизни объектов остаётся у LifetimeManager-ов.
При вызове LifetimeManager-ов контейнер передаёт в них ссылку на себя на случай, если создаваемый внутри объект будет иметь зависимости на другие объекты уже созданные этим контейнером.
Зачем нужна вторая перегрузка метода Resolve()
Вы могли заметить, что метод Resolve() имеет 2 перегрузки: одна выполняет полезную работу, а вторая всегда возвращает std::nullopt. Выбор нужной перегрузки осуществляется на основе концепта OneOf, который проверяет, известен ли запрошенный дескриптор контейнеру, сравнивая его с TDescriptors...:
template <typename TDescriptor, typename ...TDescriptors>
concept OneOf = (std::same_as<TDescriptor, TDescriptors> || ...);Почему бы просто не бросить исключение, если контейнер вызвали с неизвестным типом? Дело в том, что вторая перегрузка иногда используется фабрикой объектов, когда та пробует проверить, можно ли сконструировать тот или иной объект из его шаблонных параметров:
if constexpr (std::is_constructible_v<
TRealType,
decltype(container.template Resolve<TTemplateArgs>())...
>)Если бы второй перегрузки не было, то данная проверка вызвала бы ошибку компиляции для типа Repository<Employee>. Поскольку Employee является шаблонным параметром, то был бы сгенерирован код:
decltype(container.template Resolve<Employee>())...В результате контейнер попытался бы получить LifetimeManager<Employee> из своего внутреннего tuple-а, что вызвало бы ошибку, потому что его там нет.
Как объединить несколько контейнеров в один
Большие программы обычно можно разбить на несколько относительно независимых модулей. Наличие отдельного контейнера для каждого модуля позволяет уменьшить пересечения и merge-конфликты при параллельной разработке разной функциональности несколькими людьми или командами.
Рассмотрим пример условного сервиса по управлению сотрудниками компании, частью которой является уже известный вас класс UnitOfWork.

Можно выделить 3 относительно независимые части:
инфраструктурные сервисы
бизнес-логика
сервисы для доступа к данным
Для каждого из них объявлен свой контейнер. Вместе они образуют один общий контейнер (TContainer):
// Infrastructure container
using TInfraContainer = class Container<
Infra::ContainerAbstract::LoggerDescriptor,
Infra::ContainerAbstract::PrinterDescriptor>;
// Data access layer container
using TDaoContainer = class Container<
Dao::ContainerAbstract::RepositoryDescriptor<Employee>,
Dao::ContainerAbstract::RepositoryDescriptor<Department>,
Dao::ContainerAbstract::UnitOfWorkDescriptor>;
// Business logic container
using TServiceContainer = class Container<
App::ContainerAbstract::DepartmentManagementServiceDescriptor,
App::ContainerAbstract::EmployeeManagementServiceDescriptor,
App::ContainerAbstract::ReportManagementServiceDescriptor>;
// Main container
using TContainer = class Container<
TInfraContainer,
TDaoContainer,
TServiceContainer>;Для реализации такого поведения необходима отдельная спецификация класса Container:
template <typename ...TContainerArs, typename ...TRest>
class Container<Container<TContainerArs...>, TRest...>
: public Container<TRest..., TContainerArs...> {
};Эта спецификация будет выбрана в том случае, если на первом месте в её шаблонных параметрах также находится контейнер. Шаблонные параметры этого под-контейнера (TContainerArs...) извлекаются и помещаются в конец общего списка шаблонных параметров. Обновлённый список шаблонных параметров используется для рекурсивного наследования, которое продолжается до тех пор, пока на первой позиции не окажется класс, не являющийся контейнером - например, дескриптор.
Давайте посмотрим, как эта работает на примере. На нижнем уровне в иерархии наследования находится класс
Container<
TInfraContainer,
TDaoContainer,
TServiceContainer>Первым его шаблонным параметром является контейнер. Из TInfraContainer извлекаются дескрипторы и помещаются в конец списка шаблонных параметров родительского класса:
Container<
TDaoContainer,
TServiceContainer,
Infra::ContainerAbstract::LoggerDescriptor, // TInfraContainer
Infra::ContainerAbstract::PrinterDescriptor> // TInfraContainerТеперь на первой позиции оказался другой контейнер - TDaoContainer. Поэтому снова происходит распаковка уже этого контейнера с последующим наследованием:
Container<
TServiceContainer,
Infra::ContainerAbstract::LoggerDescriptor, // TInfraContainer
Infra::ContainerAbstract::PrinterDescriptor, // TInfraContainer
Dao::ContainerAbstract::RepositoryDescriptor<Employee>, // TDaoContainer
Dao::ContainerAbstract::RepositoryDescriptor<Department>, // TDaoContainer
Dao::ContainerAbstract::UnitOfWorkDescriptor> // TDaoContainerНаконец, остаётся последний контейнер TServiceContainer, после распаковки которого мы получаем список, полностью состоящий из дескрипторов, а значит попадаем в базовую спецификацию контейнера и на этом завершаем рекурсивное наследование:
Container<
Infra::ContainerAbstract::LoggerDescriptor, // TInfraContainer
Infra::ContainerAbstract::PrinterDescriptor, // TInfraContainer
Dao::ContainerAbstract::RepositoryDescriptor<Employee>, // TDaoContainer
Dao::ContainerAbstract::RepositoryDescriptor<Department>, // TDaoContainer
Dao::ContainerAbstract::UnitOfWorkDescriptor, // TDaoContainer
App::ContainerAbstract::DepartmentManagementServiceDescriptor, // TServiceContainer
App::ContainerAbstract::EmployeeManagementServiceDescriptor, // TServiceContainer
App::ContainerAbstract::ReportManagementServiceDescriptor> // TServiceContainerУ такого способа компоновки есть изъян. Если один или несколько дескрипторов будут предшествовать контейнерам, то следующие за ними контейнеры не будут распакованы:
using TContainer = class Container<
TInfraContainer, // Container
Dao::ContainerAbstract::RepositoryDescriptor<Employee>, // Descriptor
Dao::ContainerAbstract::RepositoryDescriptor<Department>, // Descriptor
Dao::ContainerAbstract::UnitOfWorkDescriptor, // Descriptor
TServiceContainer>; // ContainerПоскольку Dao::ContainerAbstract::RepositoryDescriptor не является контейнером, цепочка наследований завершится в состоянии:
using TContainer = class Container<
Dao::ContainerAbstract::RepositoryDescriptor<Employee>, // Descriptor
Dao::ContainerAbstract::RepositoryDescriptor<Department>, // Descriptor
Dao::ContainerAbstract::UnitOfWorkDescriptor, // Descriptor
TServiceContainer, // !!! Container !!!
Infra::ContainerAbstract::LoggerDescriptor, // Descriptor
Infra::ContainerAbstract::PrinterDescriptor>; // DescriptorОднако решить эту проблему при желании можно, но статья уже и так получилось достаточно длинной, поэтому на этом остановимся.
Итог
Мы познакомились с концепцией внедрения зависимостей и посмотрели как она реализуется на практике. Приятным сайд-эффектом использования техники внедрения зависимостей является то, что вы сами того не замечая берёте себе в привычку написание слабо связного кода. Такой код куда проще тестировать, переиспользовать и расширять по сравнению с кодом, обладающим сильной связностью.
Кроме того мы разобрались в том, как работает простейшая библиотека для внедрения зависимостей. Код библиотеки доступен в репозитории на Github и под спойлерами ниже:
Container
template <typename TDescriptor, typename... TDescriptors>
concept OneOf = (std::same_as<TDescriptor, TDescriptors> || ...);
template <typename ...TDescriptors>
class Container;
template <typename ...TDescriptors>
class Container {
private:
std::tuple<LifetimeManager<TDescriptors>...> ObjectPool_;
public:
template <OneOf<TDescriptors...> TDescriptor>
constexpr auto Resolve() {
return std::get<LifetimeManager<TDescriptor>>(ObjectPool_)
.GetOrCreate(*this);
}
template <typename TDescriptor>
constexpr auto Resolve() {
return std::nullopt;
}
};
template <typename ...TContainerArs, typename ...TRest>
class Container<Container<TContainerArs...>, TRest...>
: public Container<TRest..., TContainerArs...> {
};template <typename TDescriptor, typename... TDescriptors>
concept OneOf = (std::same_as<TDescriptor, TDescriptors> || ...);Lifetime
struct Transient {};
struct Singleton {};
struct Scoped {};template <
typename TDescriptor,
typename TLifetime = typename Binding<TDescriptor>::TLifetime>
struct LifetimeManager;
template <typename TDescriptor>
struct LifetimeManager<TDescriptor, Transient> {
using TService = Binding<TDescriptor>::TService;
auto GetOrCreate(auto& container) {
return ServiceFactory<TService>::Create(container);
}
};
template <typename TDescriptor>
struct LifetimeManager<TDescriptor, Singleton> {
using TService = Binding<TDescriptor>::TService;
auto GetOrCreate(auto& container) {
static auto instance = ServiceFactory<TService>::Create(container);
return std::addressof(instance);
}
};
template <typename TDescriptor>
struct LifetimeManager<TDescriptor, Scoped> {
using TService = Binding<TDescriptor>::TService;
using TRealType = ReplaceDescriptors<TService>::TResult;
auto GetOrCreate(auto& container) {
if (!Instance_.has_value()) [[unlikely]] {
Instance_ = ServiceFactory<TService>::Create(container);
}
return std::addressof(Instance_.value());
}
private:
std::optional<TRealType> Instance_;
};ServiceFactory
template <typename TService>
struct ServiceFactory {
static TService Create(auto&) {
return TService();
}
};
template <template<typename ...> class TService, typename... TTemplateArgs>
struct ServiceFactory<TService<TTemplateArgs...>> {
static auto Create(auto& container) {
using TRealType = ReplaceDescriptors<TService<TTemplateArgs...>>::TResult;
if constexpr (std::is_constructible_v<TRealType, decltype(container.template Resolve<TTemplateArgs>())...>) {
return TRealType(container.template Resolve<TTemplateArgs>()...);
} else {
return TRealType();
}
}
};template <typename T>
struct ReplaceDescriptors {
using TResult = T;
};
template <template <typename ...> class T, typename ...TArgs>
struct ReplaceDescriptors<T<TArgs...>> {
using TResult = T<typename ReplaceDescriptors<typename Binding<TArgs>::TService>::TResult...>;
};Несмотря на небольшой размер, библиотека получилась достаточно функциональной. В отличие от многих аналогов, она использует средства статического полиморфизма, а значит позволяет пользоваться всеми преимуществами раннего связывания. Для большинства проектов выигрыш от этого не стоит того, чтобы переезжать на новую библиотеку, если вы уже используете внедрение зависимостей на основе динамического полиморфизма. Тем не менее, в некоторых особенно чувствительных к времени исполнения кода областях, данная характеристика может оказаться очень важной.
Комментарии (19)


Emelian
03.10.2023 13:19как обуздать зависимости
Статья достаточно интересная, для общего развития, но человеку не в теме, чтобы увлечься, лучше "один разу пощупать, чем сто раз увидеть", т.е., лицезреть конкретный пример на уровне GUI, реализованного с помощью C++ / WTL или WinAPI. Тогда, даже не вникая в детали, сразу видны достоинства и недостатки, "блеск и нищета" и все такое.
Ну, а если рассуждать теоретически о "зависимостях" в программном коде, то лично я предпочитаю термин "сильные связи". Да, частично их можно заменить "слабыми связями", но, вообще говоря, это задачи по упрощению сложного кода не решает.
Более практичным, на мой взгляд, является "растягивание" связей или зависимостей, а затем, естественно образующиеся узлы кода оформлять в модули, псевдомодули, блоки или даже отдельные функции используемого кода, с явным выделением связей в виде, как вариант, ссылочных файлов.
Я сейчас пытаюсь программировать подобным образом. Что-то получается, что-то не очень, экспериментирую на ходу. Также пробую итерационно-порционное и модульное программирование, но, одновременно с плюсами возникают и минусы. Проще говоря, пытаюсь выработать собственную концепцию программирования, поскольку существующие парадигмы меня не слишком устраивают (судя по опенсорсному коду).

aradzevich Автор
03.10.2023 13:19Большое спасибо за развёрнутый комментарий, многие мысли резонируют с моими собственными.
Вы справедливо заметили, что прикладной пример в отличие от искусственного имеет куда больший шанс донести суть идеи и заинтересовать читателя. К сожалению, если мы хотим использовать примеры из жизни для демонстрации техники внедрения зависимостей, то вынуждены обращаться к большим и неуклюжим программам с нетривиальной структурой классов и связей между ними, иначе использование этой техники теряет смысл или даже переходит в разряд антипаттернов.
Примеры в статье взяты из моего бэкендского опыта и представляют из себя части тех самых больших и неуклюжих программ. Недостаток контекста может создавать ощущение искусственности этих примеров. И это ощущение тем сильнее, чем дальше читатель по своему направлению деятельности от разработки бэкэнда. Использование в качестве примеров WTL -компонентов может иметь обратный эффект - уже бэкэнд-разработчики посчитают их высосанными из пальца.
Тем не менее у меня не достаточно знаний, чтобы судить об этом с полной уверенностью. Возможно, примеры с использование GUI действительно окажутся куда более иллюстративными, выразительными и понятными большему количеству людей. Я познакомлюсь ближе с этой библиотекой, благодарю вас за подсказку.
Emelian
03.10.2023 13:19+1Правы классики: «Практика – критерий Истины!». Мы можем сколько угодно строить теоретических конструкций, но если они, при соприкосновении с действительностью, начинают «сыпаться», то возникает резонный вопрос, а всё ли ладно в «Датском Королевстве»?
Я думаю, что для демонстрации концепции совсем не обязательно «обращаться к большим и неуклюжим программам с нетривиальной структурой классов и связей между ними». Ведь что мы хотим, если я правильно понял, так это уметь контролировать достаточно сложные программы. Потому, как лично у меня даже собственные программы, написанные пару лет назад, при попытке их модернизации вызывают ступор. Все кажется настолько сложным и непонятным, что просто ужас.
Для примера. Начал я писать простую программу для распознавания встроенных субтитров в видео-роликах. Там всего три окна. Файловая панель, для выбора медиа-файла, окно с видео (на базе FFPlay.c из опенсорсного пакета FFMpeg) и окно с распознанным текстом субтитров. В принципе программа была почти готова, даже научился распознавать субтитры из однотипных ютубовских роликов, типа «EasyFrench». Но потом проект забросил по двум причинам. Первая, лень было делать настройку на разные шрифты из нетиповых видео и, вторая, более важная, смысла в этом особого не было. Поскольку все эти данные я собирал для своей обучающей программы «Сколиум», а там основная концепция это «запоминание руками». Поэтому, какой резон тратить силы на автоматическое распознавание, чтобы потом набирать этот текст вручную для целей его лучшего усвоения? Ведь, можно и сразу набрать его вручную, не так ли? Чем чаще будешь набирать иностранные фразы, тем скорее их запомнишь.
Таким образом, через некоторое время я решил вернуться к этому проекту, только вместо окна распознавания добавить туда окно редактора текста, типа RichEdit. При этом программа получается даже проще. Думал, что за пару дней наваяю ее и смогу вручную переносить текст из произвольных медиа-файлов (видео, звук, сканы книг и т.п.) в текстовый редактор, чтобы затем конвертировать в данные для своей программы и пересоздания видео с двуязычными и даже трехязычными субтитрами.
Оказалось, что я был слишком наивен. Вот уже мучаюсь пару месяцев, чтобы просто понять, как я делал вывод видео в поток, как вообще все там было устроено и организовано? Промежуточный вариант моих экспериментов показан ниже.
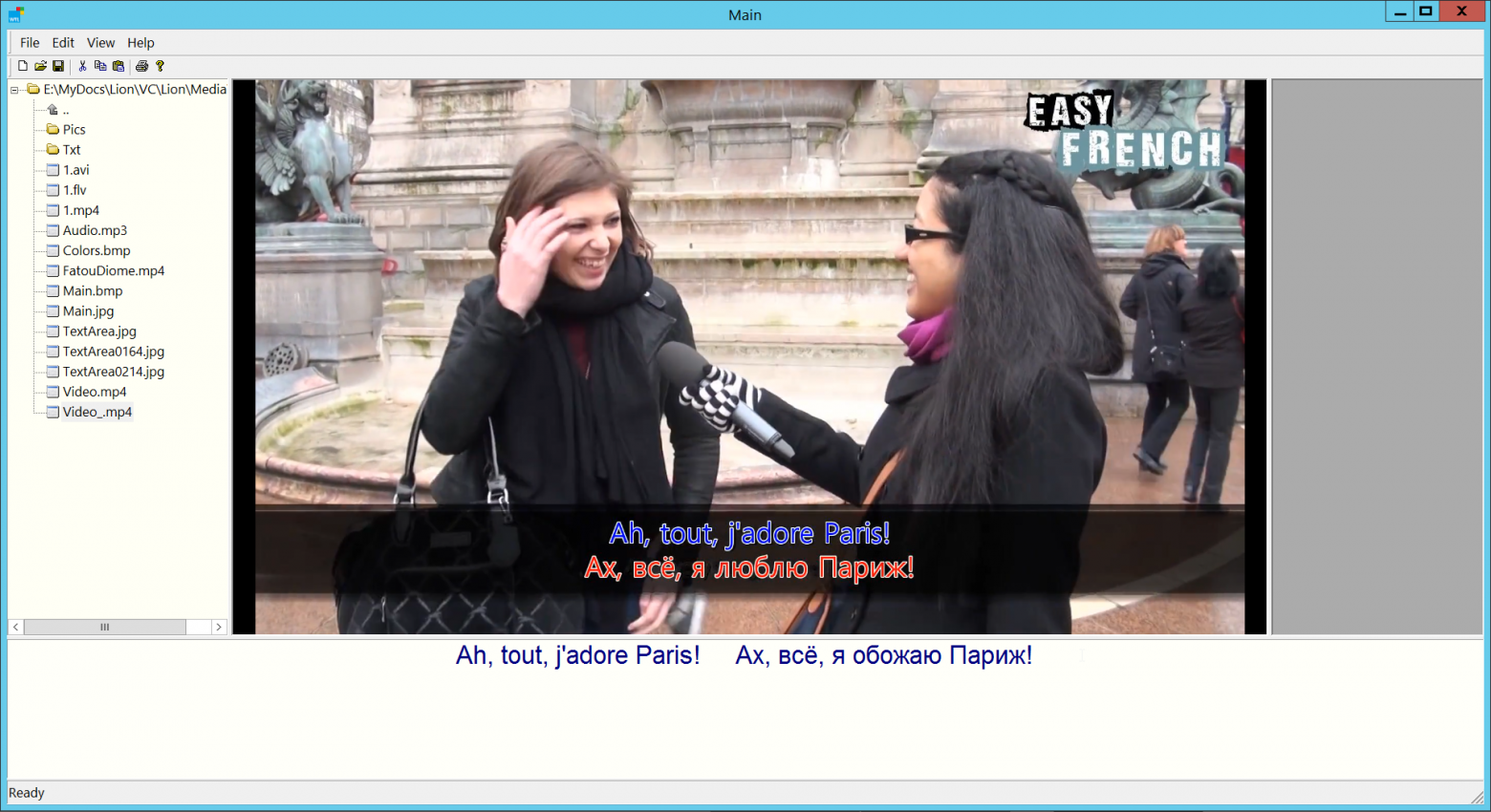
В правую панель я собираюсь добавить элементы управления медиа-файлами (масштабирование, перемещение, перемотку и т.п.).
Очень хочется программировать так, чтобы при внесении изменений, через какое-то время, не было «мучительно больно», вспоминая, а как я вообще делал это? Отсюда мой интерес к простому программированию сложного кода.
Мне кажется, что ваша статья тоже об этом, о желании упростить сложный код. Поэтому, если, допустим, удастся выработать подобную концепцию программирования ходя бы для подобных, в принципе, не сложных задач, то тогда можно было и статью написать на аналогичную вашей тему и картинку соответствующую показать.
aradzevich Автор
03.10.2023 13:19Да, пожалуй соглашусь с вами, это интересное замечание. Я постарался хотя бы частично учесть его в README и точно учту в следующей статье.



avbochagov
03.10.2023 13:19+5После 6 лет сопровождения проекта с использованием Dependency Injection скажу только одно - прежде чем вводить их в проект ПОДУМАЙТЕ и откажитесь!

boldape
03.10.2023 13:19+2Опишите подробнее ваш не удачный опыт использования:
с++ или язык с рефлексией
рантайм/позднее связывание/интерфейсы или как здесь шаблоны/дженерики/компилтайм
Описание самих зависимостей обрабатывается в рантайме или как здесь в компил тайме
Какая именно боль у вас от ДИ
Ответы на эти вопросы сильно меняют ощущения от использования. Вот автор выставляет одним из главных достоинств скорость работы, которая ему важна в лоу латенси коде, а на самом деле сам факт компил тайма намного важнее скорости.
Если собралось, то доброй половины проблем которые вы имеете с интерфейсами просто не будет, а если не собралось, то конечно вы сначало проклянете все эти шаблоны с их очень понятными ошибками, но потом когда все таки почините, то снова будете рады тому, что это не интерфейсы.
А ещё вам не надо на каждую зависимость писать интерфейс и еслииу вас моки то при каждом изменение интерфейса вам не надо делать его 3 раза, а ещё в дебаге вы увидите настоящие типы ВСЕХ зависимостей сразу и одновременно, а не какой-нибудь пимпл который пока не пробьешься сквозь стэк не узнаешь и то по одной штуке за раз. Ну и само собой без виртуальных вызовов конечно же сильно быстрее, но это уже как раз вишенка, а не сам торт.
avbochagov
03.10.2023 13:19+5Итак по порядку:
Java + Guice
Runtime связывание, интерфейсы, шаблоны и все как принято
Само связывание осуществляется в runtime, но все поставляемые зависимости описываются в статике. Слава богу, хотя бы без XML.
А боль получилась такая - везде используются интерфейсы, реализации которых не всегда очевидны ибо есть несколько реализаций. К тому же, легкость внедрения зависимостей привела к тому, что практически нет классов без зависимостей (в том или ином количестве).
В результате, это привело к тому, что читая текст программы ты никогда не можешь точно угадать, что именно стоит за тем или иным вызовом метода. Помогает только запуск отладчика, но это не точно, потому что для тестов есть отдельный набор зависимостей.
Про успешную компиляцию, но неуспешный запуск (не забываем про runtime связывание) я просто не буду писать. Привык и научился исправлять.
Тестирование такого кода - это отдельная песня... Я иногда начинаю завидовать бурлакам на Волге... некоторые участки кода не покрыты тестами просто потому, что это невозможно сделать (ну или стоимость написания такого теста превышает допустимые затраты).
Это легкое описание той головной боли, которая получена благодаря Dependency Injection. И да, DI никак не помогает упростить написание логики приложения.
PS имел счастье почитать код, до внедрения механизма DI... читал код и плакал - все понятно, логично и надёжно. Нет, вот так - НАДЕЖНО!
aradzevich Автор
03.10.2023 13:19Подход из статьи должен как раз решить часть ваших болей: благодаря тому, что подставляемый тип будет известен уже на этапе компиляции, IDE сможет вам подсказать, какую именно реализацию класса вы используете:

avbochagov
03.10.2023 13:19Конечно, такой подход уберет часть головной боли.
Но фокус состоит в том, что если бы не DI - то у меня вообще не было бы головной боли.Если честно, то по прошествии нескольких лет я вообще считаю механизм DI вредным. Именно из-за таких головных болей...

Lukerman
03.10.2023 13:19+1Спасибо за статью и за этот коментарий.
Тоже страдал !).
.net framework 4.5 , рефлексия , шарились интерфейсы на тысячи классов ,тестирование IRepository - боль.


maximpossible
03.10.2023 13:19+2Внедрение зависимостей как паттерн, или, если угодно, подход к проектированию классов и модулей очень правильная вещь, которую уже многократно описали во всевозможных книгах и статьях. Но у меня есть ощущение, что использование более декларативных подходов для ее реализации, будь то файл конфигурации, либо шаблонный менеджер, только усложнит проект.
В хорошем модульном коде редко бывает больше условных 10 зависимостей для одного класса, допускающих возможности замены другой реализацией. Под этим я имею ввиду, что класс вполне может использовать маленькие вспомогательные классы в рамках собственной реализации, наряду с действительно важными внешними зависимостями, которые уже «внедряются» извне.
Когда, например, в конструкторе класса явно перечислены все зависимости, этого вполне достаточно, а конкретная реализация, чаще всего, может быть подставлена на старте приложения. Таким образом мы получаем так называемый self-describing код и безо всяких дополнительных усилий, позволяя программисту быстрым взглядом на конструктор понять, от чего этот класс зависит.
В любом случае спасибо за статью, подобная работа очень полезна в целях обучения, хотя я легко допускаю, что в некоторых проектах такое решение может дать преимущества.

t-jet
03.10.2023 13:19+1Отличная статья, сам пользуюсь этим подходом. Автор и целый ряд комментаторов правильно заметили:
это отдельный стиль и к нему следует привыкнуть
да, отладка на этапе компиляции не тривиальна, но действительно, после успешной сборки, тебя не ждут неожиданности
код получается шустрым, конкретно мне для криптографической библиотеки это сильно помогает. Пример такой открытой библиотеки: Botan, моя проприетарная поэтому смысла ссылаться на нее здесь нет. Но сам подсматриваю идею в Botan, в том числе :-)
ну и ещё один из минусов, это большая библиотека и да, компилятору может не хватить памяти :-) особенно 32-х разрядной версии vc++
Автору спасибо за систематизацию и детальное пояснение.

semenyakinVS
03.10.2023 13:19+1Увы, у шаблонного решения для DI до прихода концептов и модулей есть несколько проблем:
Очень плохая поддержка парсерами IDE и, как следствие, сутствие автоподстройки по месту использования типов из шаблонных аргументов. Это фиксят концепты.
Сложности с как раз-таки "разделением логики". Шаблонны требуют выносить реализацию в хедеры из-за чего зависимости реализации вываливаются в общий скоуп. Это фиксят приватные зависимости модулей.
Но до С++20 использовать решение из статьи, думаю, на практике достаточно больно
aradzevich Автор
03.10.2023 13:19+1Согласен с обоими пунктами, пришёл к тем же выводам, пока делал библиотеку.
Но решить проблему отсутствия концептов частично всё-таки можно.Для этого нужно объявить члены шаблонного аргумента внутри соответствующего ему типа-дескриптра.
struct UnitOfWorkDescriptor { int AddDepartment(const std::string& departmentName); int AddEmployee(int departmentId, const std::string& employeeName); void RemoveDepartment(int departmentId); void RemoveEmployee(int departmentId, int employeeId); ... };Поскольку дескриптор подставляется как тип по умолчанию, автокомплит начнёт работать. Очевидный минус - обновлять методы нужно не только в реализации, но и в деcкрипторе.
semenyakinVS
03.10.2023 13:19О, интересная идея, кстати. Запомнил как полезный костыль для проектов без С++20
HemulGM
У вас тут ошибка
И на мой взгляд, интерфейсами это было решить куда удобнее
aradzevich Автор
Большое спасибо, исправил.
Согласен, через интерфейсы было бы проще и привычнее, да и материалов про это в интернете куда больше, чем про внедрние зависимостей через шаблоны. Это хорошо при выборе технологии для использовании в продакшене, но является скорее минусом при написании статьи - не хочется повторятся, хотчется пробовать что-то новое или хотя бы не заезженное.
Если говорить про сложность для программиста, который будет библиотекой пользоваться, то я старался сделать её максимально похожей на аналоги, которые работают с интерфейсами. Главное отличие в том, что вместо интерфейсов используются дескрипторы.
Безусловно, я согласен, что такой подход имеет свои недостатки в сравнении с интерфейсами. Например, разнесения кода шаблонного класса по .h и .cpp файлам становится сущей головной болью. Но хочется верить, что для программ, которые работают в режиме реального времени и не допускают использования позднего связывания, это может оказаться допустимыми неудобствами.