
Привет, меня зовут Настя, я руководитель направления по управлению данными в Московском кредитном банке. В этом посте я расскажу, как мы организовали каталог данных в МКБ в текущих условиях — когда многие вендоры ушли, и по-настоящему рабочих вариантов осталось два: или пилить что-то самим с нуля, или обратиться к опенсорсным решениям. Пилить самим — тут как всегда, это и дорого, и долго. Брать же готовую коробку и использовать ее вчистую тоже достаточно сложно, вы же не знаете наверняка и досконально, чего там и как на самом деле внутри работает.
Когда речь идет о корпоративных данных, это важно. К примеру, та же OpenMetadata — если не знать ее подкапотное устройство, работать с ней будет сложно. А разобраться сложно, потому что документация по ней на сегодня скудноватая, и экспертизы у людей на рынке еще не набралось, из-за чего до много приходится додумываться самим уже в процессе.
Под катом — немного о проблематике работы с данными (и о доверии), о плюсах, которые даст вам каталог данных, а также наша подробная инструкция для разворачивания каталога у себя.
Проблематика
Люди, работающие с данными, часто тратят уйму времени на их поиск. Но найти мало — надо быть уверенным в их правильности, актуальности и полноте. Всё это формирует такой важный фактор как доверие к данных. Если его нет — это большая проблема для организации, принимающей решения на основе данных. Ведь именно на основе больших данных принимаются решения, осуществляется управление банком, строятся и развиваются ставшие такими привычными рекомендательные системы, а еще не стоит забывать про скоринг.
И это как раз тот случай, когда чистое IT и отличные технические специалисты вам не сильно помогут. Да, они могут виртуозно работать с данными, выстраивать системы для их хранения, анализировать, компоновать, создавать дашборды, выдавать права доступа и прочее. Это все прекрасно. А если на входе в системы просто нет этих данных в качестве исходника, как вам поможет айтишник?
Поэтому необходимо создание каталога данных как единственного достоверного источника обо всех информационных активах банка. Подобный каталог при должном усердии и подходе к делу становится единой точкой входа для поиска данных. Причем наглядный и простой, чтобы новый сотрудник банка мог в этом разобраться в течение дня и начать использовать этот каталог в работе.
Все эти данные должны иметь корректное и подробное описание, чтобы работающий с ними человек точно понимал, что это именно те данные, которые ему нужны. Это поможет и понимать контекст. Для этого в идеале создавать платформу с гибкими технологиями (Python, Pyspark и подобное), чтобы все расчеты делать на них, а их результаты загружать в каталог данных. Так пользователю даже с точки зрения user experience будет сильно проще все найти и быть уверенным в полноте и свежести данных.
А если вы вдруг сомневаетесь, нужно ли вашей большой компании вообще с этим заморачиваться, помните, что есть отличная книга, «DAMA DMBOK — Управление данными». Там вообще много полезного, но главное — это одна простая цитата вида «Рано или поздно вам нужно будет начать управлять своими данными».
Лично нам кажется, что в рабочем плане данным стоит начинать управлять уже тогда, когда они перестают помещаться в одну голову. К сожалению, во многих компаниях пока живет парадигма, в которой менеджеры (включая бизнес и даже IT) частенько говорят, мол, эти каталоги данных какая-то странная штука, технари накрутили чего-то ненужного. Но этой этой парадигмы полезно бы уходить.
Вишенкой — при наличии хорошего каталога данных вы получите приятный бонус под названием «Ответственность за данные». Больше не будет текстов, таблиц и документов, которые непонятно кому принадлежат, неясно, кто владелец, кто должен был что-то обновить или поправить, но не сделал этого. Помогает как в работе в целом, так и в решении инцидентов и поддержании должного уровня SLA.
Каталоги данных и безопасность
Реальность такова, что утечки бывают у всех. Вообще без разницы — частная компания или государственная, в какой стране находится, какие меры защиты использует и прочее. Отличия проявляются лишь постфактум в поведении компании после утечки, сделанных выводах и уровнях ответственности. Так что серебряной пули нет. Каталоги данных на ее статус и не претендуют, но они могут сильно снизить ущерб от возможной утечки, потому что позволяют гораздо тщательнее работать с различной чувствительной информацией в плане хранения, каталогизирования, обновления и выдачи доступов (включая и отзыв прав). Поэтому если что и утечет, то не весь пул данных разом, а какая-то часть. При этом вы будете знать, что именно утекло и какие меры стоит принять для минимизации рисков.
В общем, с проблематикой мы разобрались, давайте теперь про инструменты.
Что умеет OpenMetadata?
OpenMetadata — молодой инструмент, ему пара лет, но его в целом можно считать достаточно стабильным для использования, с каждым релизом он становится все дружелюбнее и функциональнее, разработчики активно закрывают баги, пользователи не менее активно находят новые, в общем, работа кипит.
Мы в МКБ решили развернуть OpenMetadata в dev-контуре. Всё-таки, финтех — это не та отрасль, где ИБ даст вам развернуть что-то новое из опенсорса на проде. Сначала dev, потом довольно серьезные проработки со специалистами по безопасности, минимизация рисков, никаких подозрительных активностей в коде — и только потом выкатка на прод.
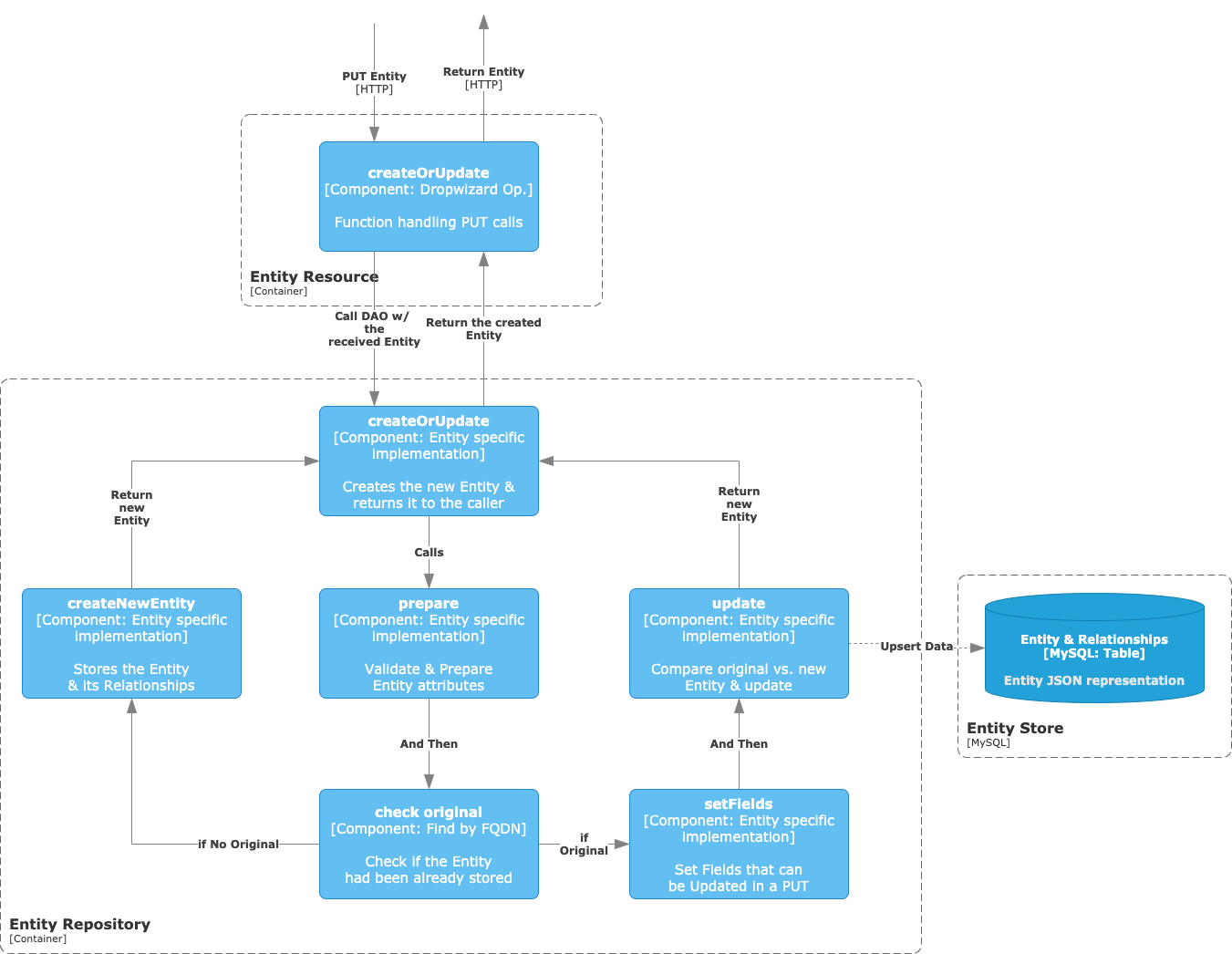
Для работы OpenMetadata мы используем Kubernetes.
Архитектурно это выглядит так:
есть под, сам UI в вебе
для считывания метаданных используется Airflow (4 пода)
Elasticsearch
Postgres (была MySQL, но, к счастью, переехали на Postgres).
Зачем нужна связка Open Metadata + Airflow?
Любой каталог данных должен уметь подключаться к системам источников и считывать их метаинформацию. Это данные о данных — таблицы, структура таблиц, где эти таблицы лежать, название базы, название схемы, название таблицы. В идеальном состоянии — еще и комментарии.
Open Metadata это как раз делает умеет.
Чтобы она могла без проблем подключаться к источникам и считывать данные, используется как раз эта связка — Open Metadata и Airflow. То есть в User Interface Open Metadata мы создаем ingestion и нажимаем кнопочку deploy. После этого создается DAG в Airflow, и он запускается по расписанию. Считываются метаданные.
У OpenMetadata есть небольшая киллер-фича, она умеет коннектиться не только к базам данных, но еще и к Kafka, Airflow и к средствам BI.
На что обратить внимание при разворачивании OpenMetadata
Прежде всего, имейте в виду, что OpenMetadata по умолчанию также имеет в себе функцию Data Quality-инструмента. Штука хорошая, но, в зависимости от специфики работы, подходит не всем и не всегда, так что надо тестировать.
Мы протестировали, нам такая реализация DQ не подошла. При подключении к системам-источникам она запрашивает специфические гаранты, специфические доступы. В основном она 99% случаев требует Select Any Table, мы как раз с этим столкнулись. И это, мягко скажем, излишне, если вы не планируете использовать ее функционал Data Quality.
Но при желании проблему можно решить.
Мы использовали синонимы и дали ей меньшие гаранты — Select Any Dictionary вместо Select Any Table. Это если говорить при первый найденный нами подводный камень.
А вот второй. Разворачивать Open Metadata можно несколькими способами:
Docker
Kubernetes
Как развернуть у себя каталог данных
Для этого вам понадобятся:
Проработанная архитектура (для mvp можно и без нее), но дальше на dev и prod без проработанной архитектуры будет больно и есть опасность на одни и те же грабли наступить множество раз
Хотя бы один девопс
Менеджер, который оградит девопса от бюрократии
Кластер k8s
Helm Charts Openmetadata
Развернутая вне k8s Поисковая система Elasticsearch (также можно развернуть OpenSearch или Elasticsearch в k8s).
Развернутая БД MySQL / PostgreSQL с достаточным объемом памяти
В МКБ мы разворачивали версию 0.13.3 и в ближайшее время будем поднимать ее до 1.03. Личный совет — не ставьте самую последнюю версию на прод никогда. Да и на дев тоже не стоит, если у вас нет лишнего времени. Лучше дождитесь выкатки обновлений — например, 0.13.0 не надо ставить, а вот 0.13.3 — приемлемо.
1.0 не надо ставить, 1.03 приемлемо.
1.1 не надо ставить, 1.1.2 приемлемо.
И в таком духе.
Также учитывайте, что OMD — это опенсорс, и могут вноситься необратимые изменения, так что всегда тестируйте на dev,
всегда делайте бекап. Как только OMD разворачивается на проде, делайте бекап и обязательно протестируйте и запишите, как происходит восстановление из бекапа.
И только после этого можно приступать к каким-либо работам.
Подготовка к развертыванию
Развертывание Openmetadata в кластере Kubernetes осуществляется с помощью Helm Charts. Мы рассмотрим вариант, позволяющий развернуть Openmetadata версии 0.13.3 с подключением к внешним компонентам: Postgres и Elasticsearch. Ещё есть настройки для подключения аутентификации с помощью Keycloak.
Далее предлагается рассмотреть последовательный процесс развертывания, с учетом особенностей нашей инфраструктуры. Например, не все хранят образы в локально registry, соответственно не для всех этот пункт будет актуален.
Важно: Необходимо учитывать изменения в процессе развертывания при переходе на новую версию, поэтому данный пример лучше рассматривать параллельно с основной документацией. Вот она:
Подключение docker registry.
Создание секрета для работы с docker registry.
Добавление необходимых образов в репозиторий docker.
При развертывании OpenMetadata используются 4 компоненты:
Openmetadata server.
Openmetadata ingestion / Airflow.
Elasticsearch.
MySQL / PostgreSQL.
Так как Elasticsearch и БД используются вне кластера Kubernetes, то необходимо загрузить только два образа, каждый из которых должен соответствовать одной версии, к примеру, если используется версия 0.13.3 для Openmetadata, то в docker registry загружаются следующие образы:
openmetadata/server:0.13.3
openmetadata/ingestion:0.13.3
Настройка для Keycloak
Настроить Realm для работы с Openmetadata в соответствии с данной документацией для необходимой версии
Указать соответствующие настройки клиента в конфигурации openmetadata.yaml.
Создать Secret для Keycloak Client (необходимо подставить Credential Secret из Client Keycloak)
Особенности настройки
Если у вас нет Keycloak, каталог позволяет использовать разные способы аутентификации — на первом этапе можно не очень заморачиваться и развернуть каталог с базовой аутентификацией (то есть с ручным созданием пользователей).
В настройках конфигурации важно указать следующие параметры:
authorizer:
className: "org.openmetadata.service.security.DefaultAuthorizer"
containerRequestFilter: "org.openmetadata.service.security.JwtFilter"
principalDomain: "mkb.ru"
initialAdmins:
- "omd"
authentication:
provider: "custom-oidc"
publicKeys:
- ""
- ""
authority: ""
clientId: "openmetadata"
callbackUrl: "https://openmetadata.....ru/callback"
jwtTokenConfiguration:
enabled: true
rsapublicKeyFilePath: "./conf/public_key.der"
rsaprivateKeyFilePath: "./conf/private_key.der"
jwtissuer: "open-metadata.org"
keyId: ""Рассмотрим некоторые параметры подробнее:
initialAdmins — в данном списке можно определить пользователя, который будет иметь права администратора. Этого же пользователя нужно будет создать в Keycloak.
publicKeys — перечисляются url, по которым хранятся токены jwt, адреса обязательно должны быть внутренними, иначе будет получена ошибка, подробнее об этом тут.
Создание БД
Так как в данном развертывании используется подключение к внешней БД, то рассмотрим процесс создания и подключения БД.
Для создания достаточно выполнить в заданной БД создание двух баз данных, пример скрипта:
initdbScripts:
init_openmetadata_db_scripts.sql: |
CREATE DATABASE openmetadata_db;
CREATE USER 'openmetadata_user'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON openmetadata_db.* TO 'openmetadata_user'@'%' WITH GRANT OPTION;
commit;
init_airflow_db_scripts.sql: |
CREATE DATABASE airflow_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
CREATE USER 'airflow_user'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON airflow_db.* TO 'airflow_user'@'%' WITH GRANT OPTION;
commit;В данном случае создаются две базы данных, одна используется для Aiflow, другая — для Openmetadata.
Пример подключения в openmetadata-dependencies.yaml для aiflow:
externalDatabase:
type: postgres
host: <host postgres>
port: <port>
database: airflow_db
user: airflow_user
passwordSecret: airflow-postgresql-secrets
passwordSecretKey: airflow-postgresql-passwordПример подключения в openmetadata для openmetadata/server:
database:
host: <host postgres>
port: <port>
driverClass: org.postgresql.Driver
dbScheme: postgresql
dbUseSSL: false
databaseName: openmetadata_db
auth:
username: openmetadata_user
password:
secretRef: postgresql-secrets
secretKey: openmetadata-postgresql-password
Elasticsearch
При подключении к Elasticsearch главное, чтобы пользователь от которого происходит подключение имел права на создание индексов.
Список индексов:
tag_search_index
team_search_index
mlmodel_search_index
dashboard_search_index
table_search_index
topic_search_index
user_search_index
pipeline_search_index
glossary_search_index
Создание PVC
Для развертывания Airflow необходимо указывать два хранилища с ACCESS MODES=RWX:
openmetadata-dependencies-dags
openmetadata-dependencies-logs
Перед подключением необходимо изменить пользователя и права доступа к директориям, которые потом будут хранить логи и даги. Подробнее об этом можно почитать тут.
Обязательно создать перед развертыванием чарта openmetadata-dependencies.
Развертывание OpenMetadata
Создание Secrets.
postgresql-secrets
airflow-secrets
airflow-postgresql-secrets
openmetadata-elasticsearch-secrets
Создание секретов для ingress.
ariflow-openmetadata-ingress-tls-secret
openmetadata-ingress-tls-secret
Сначала разворачиваем Airflow
1. Инициализируем зависимости:
helm dep up ./openmetadata-helm-charts-0.0.58/charts/deps/
2. Установка:
helm install openmetadata-dependencies ./openmetadata-helm-charts-0.0.58/charts/deps/ --values openmetadata-dependencies.yaml
затем разворачиваем Openmetadata
(в целом можно и наоборот)
Обновление Openmetadata
При глобальном обновлении лучше обращаться к документации.
Общая последовательность действий при обновлении:
Создание бэкапа БД.
Скачивание новой версии Helm Charts с обновленной версией Openmetadata.
При необходимости редактирование манифестов openmetadata-dependencies.yaml и openmetadata.yaml.
После подготовительных действий необходимо сначала обновить зависимости:
helm upgrade openmetadata-dependencies ./openmetadata-helm-charts-0.0.58/charts/deps/ --values openmetadata-dependencies.yaml
Далее выполняем обновление openmetadata:
helm upgrade openmetadata ./openmetadata-helm-charts-0.0.58/charts/openmetadata/ --values openmetadata.yaml
После того как обновление будет завершено, необходимо выполнить реиндексацию данных в Elasticsearch с помощью администратора в Openmetadata.
Необходимо перейти Settings → Elasticsearch → Re Index all.
Далее в зависимости от критичности обновления (об этом лучше прочитать в документации) либо нажать Submit, выполнится реиндексация, либо указать Re Create → Yes, в таком случае индексы пересоздаются в Elasticsearch и данные реиндексируются.
Ещё немного полезной документации по теме.
Архитектура

API — это основа OpenMetadata. Здесь мы определили, как мы можем взаимодействовать с сущностями метаданных. Он питает все остальные компоненты решения.
Пользовательский интерфейс — инструмент, ориентированный на обнаружение, который помогает пользователям отслеживать все активы данных в организации. Его цель – обеспечить и стимулировать сотрудничество.
Ingestion Framework — согласно спецификациям API, эта система является основой всех соединителей, т. е. компонентов , определяющих взаимодействие между OpenMetadata и внешними системами, содержащими метаданные, которые мы хотим интегрировать.
Хранилище сущностей — хранилище MySQL, содержащее информацию в реальном времени о состоянии всех сущностей и их взаимосвязях.
Поисковая система — основанная на ElasticSearch, это система индексирования пользовательского интерфейса, которая помогает пользователям находить метаданные.
Схемы JSON
Если мы на мгновение абстрагируемся от уровня хранения, то поймем, что реализация OpenMetadata представляет собой интеграцию трех блоков:
Основной API, объединяющий и централизующий связь с внутренними и внешними системами.
Пользовательский интерфейс для уровня обслуживания метаданных, ориентированного на команду.
Платформа приема как интерфейс между OpenMetadata и внешними источниками.
Единственное, что общего у этих компонентов, — это словарь -> Все они формируют, описывают и перемещают сущности метаданных.
OpenMetadata основана на стандартном определении метаданных. Поэтому нам необходимо убедиться, что в нашей реализации этого стандарта мы используем это определение в сквозном рабочем процессе. С этой целью основной словарь определяется как схемы JSON — читаемое и независимое от языка решение.
Затем, упаковывая основные компоненты, мы генерируем конкретные классы программирования для всех Entities. Чего мы добиваемся, так это трех просмотров из одного источника:
Классы Java для API;
Классы Python для платформы приема;
Классы Javascript для пользовательского интерфейса.
Каждый из них создан по образцу единственного источника истины. Благодаря этому подходу мы можем быть уверены, что не имеет значения, в какой момент мы увеличиваем масштаб на протяжении всего процесса, мы всегда найдем однозначную, четко определенную Сущность.
Итого
Если вы всё сделали правильно, поздравляем, теперь у вас есть каталог данных, который при верном использовании позволит вам улучшить множество процессов, связанных с данными, а также стать на шаг ближе к data-driven-company. Возможно, вы разворачивали каталог данных у себя, и добавили в предложенную нами схему какие-то улучшения или упрощения — если так, не стесняйтесь писать об этом в комментариях :)
Хочу поблагодарить коллег из Департамента ИТ- обеспечения Казакова Эйнара и Кузьмина Станислава за помощь в разворачивании каталога данных и подготовке этой статьи.
Комментарии (3)

astoulov
12.10.2023 21:03Добрый день. Подскажите, пожалуйста,
1) смотрели ли или смотрите сейчас в сторону Arenadata Дата Каталог?
2) Писали ли свои коннекторы или обходитесь теми, что есть из коробки
3) Насколько активно сообщество, отвечали/помогали ли вам разбираться с проблемами или в основном решали сами
BogdanPetrov
Спасибо, что делитесь своим опытом. Понятно, что целью статьи было раскрыть именно техническую сторону развертывания и показать немного мотивации. Но раз уж такую тему поднимаете, то отсюда возникает только больше вопросов :)
Проведя все эти технические манипуляции в каталоге появляются списки схем, таблиц и колонок из всех подключенных источников. Как это соотносится с моментами, обозначенными в начале статьи в разделе "Проблематика"? Что это реально дает пользователям каталога данных? Там ведь по-прежнему нереально найти нужные данные и невозможно понять их применимость к конкретной задаче.
В общем, интересно было бы почитать также о сопутствующих организационных вопросах, которые нужно решить, чтобы каталог реально стал полезен. В первую очередь, как назначаются ответственные за таблицы и как вывести в каталог информацию о том, что таблица актуальна, обновляется, поддерживается и данные в ней пригодны к использованию.
Isenanao Автор
Спасибо за интерес к статье, тема управления данными достаточно объемная.
О том, какие шаги стоит пройти для того чтобы каталог данных реально стал полезен постараюсь раскрыть в следующей статье.