

Осторожно: далее слово “пайплайн” будет использоваться неимоверно-чудовищное количество раз!
Интро
Данный материал будет описывать опыт нашей команды по построению end-to-end рекомендательной ML-системы визуального поиска похожих товаров с помощью инструментов, предоставляемых облачной платформой Google Cloud Platform (далее – GCP) и структурно будет состоять из трех частей, описывающих три этапа разработки: от простой реализации задачи к более сложной, или точнее – из двух с половиной, так как второй этап оказался не жизнеспособным, но обо всем по порядку.
Материал, в первую очередь, будет идейно интересен тем, кому впервые понадобится реализовать схожие задачи на GCP без опыта работы с аналогичными облачными платформами.
Дисклеймер:
Вся описанная работа велась тремя разработчиками, ранее не имевшими опыта взаимодействия с облачными технологиями, языком Python и ML/DS.
Cам процесс, специфика и детали построения жизненного цикла машинного обучения в этом материале описаны не будут, здесь мы сосредоточимся по большей части на работе с инструментами GCP и MLOps-специфике.
Для конечного пользователя наш продукт выглядит следующим образом: представим веб-сайт онлайн ритейлера одежды. Листая плитку из товаров, вы проваливаетесь в интересующий вас товар и среди прочего в его карточке видите карусель из похожих товаров, где они отсортированы по убыванию степени похожести. Товары, выведенные в карусели, являются результатом работы нашей рекомендательной системы (см. картинку ниже):

Ниже представлена первоначальная общая схема работы всей системы:

Далее будут описаны два компонента системы (продуктовый каталог и web-приложение онлайн-магазина), которые были реализованы один раз и более не претерпевали значимых изменений. После чего мы перейдем к описанию этапов проекта.
Web и Cloud Run
В ходе реализации компонентов системы был написан прототип онлайн-магазина на фреймворке Flask по схеме MVC со стандартной связкой HTML+Bootstrap+jinja, а также каплей JavaScript.
Для развёртывания магазина в облачной среде Google была выбрана serverless платформа Cloud Run, как наиболее подходящий сервис с точки зрения быстроты развертывания, простоты использования и дешевизны. Из прочих бонусов Cloud Run можно отметить удобство локального использования при помощи плагина Google Cloud Code, который поддерживается такими IDE, как Intellij Idea и Visual Studio Code, что позволяет локально запускать и тестировать работу приложения в эмулируемой среде Cloud Run прямо у себя в IDE.
Для запуска приложения в Cloud Run нужно сбилдить Docker образ приложения через gcloud sdk shell, запушить его в управляемый облачный сервис для хранения артефактов Artifact Registry, откуда можно с нуля развернуть приложение в Cloud Run за считанные минуты, либо накатить новую версию на уже работающее приложение. Всю работу с развертыванием контейнезированного приложения в инфраструктуре облачной среды Cloud Run при этом берет на себя.
Product catalog = Cloud Storage + Cloud Firestore
Продуктовый каталог, как система, состоит из связки сервисов Cloud Storage + Cloud Firestore: метаданные хранятся в облачной NoSQL-базе данных Cloud Firestore (далее по тексту – БД), а сами изображения в унифицированном облачном хранилище объектов Cloud Storage (далее по тексту – хранилище).
В хранилище хранится набор изображений в исходном виде (файлы с .jpg- расширением), каждое из изображений доступно по прямой ссылке для скачивания.
Метаданные представляют собой набор характеристик объекта на изображении: id, тип, категория и подкатегория, полное название, сезон применения, год изготовления товара и ссылка на изображение в хранилище. В условиях реализации БД в Firestore метаданные каждого объекта хранятся в отдельном "документе". Общая совокупность документов представляет собой "коллекцию". Помимо изначальных данных о товаре в каждом документе находится информация о похожих на него изображениях. Это набор из 10 элементов, которые представлены в виде подколлекции документа. Они хранят в себе id, полное название, ссылку и процент “похожести” товара на исходный.

В качестве используемого датасета мы взяли готовый вариант с Kaggle, который представлял собой папку с изображениями и метаданные в csv таблице, соответствующие каждому из них. Для выгрузки датасета была написана утилита, которая последовательно проходит по csv таблице и выгружает метаданные в БД, а по id строки читает и выгружает изображение в хранилище.
Часть 1. GCP HelloWorld
Для реализации простейшего пайплайна, запускающего модель на сервинг, мы выбрали связку сервисов Cloud Composer, известный многим как Airflow, инструмент для разработки, планирования и мониторинга рабочих процессов и Compute Engine – IaaS предложение от Google, с помощью которого мы можем свободно создавать виртуальные машины.
Код жизненного цикла модели изначально был написан локально в jupyter ноутбуке, после чего мы перенесли его в обычное Python-приложение с единственным REST api: GET /get_similars, при обращении по которому запускался весь жизненный цикл машинного обучения. Как говорилось ранее, здесь мы не будем вдаваться в подробности работы нашей модели, только отметим, что результатом работы модели было формирование и запись в БД суб-коллекции из десяти похожих картинок для каждого документа основной коллекции.
Приложение с моделью было обернуто в Docker-образ, который мы запушили в Artifact Registry, откуда прямо в UI-сервиса задеплоили на виртуальную машину платформы Compute Engine. К слову, GCP почти везде предлагает подсказки и step-by-step гайды, которые сильно облегчают освоение инструмента на базовом уровне. Итого мы имеем сервер, где крутится наше приложение с моделью.
Для Cloud Composer* (он же Airflow) был создан DAG с единственной заданием на отправку http-GET запроса на api по адресу ВМ-инстанса(Compute Engine) с моделью.
* – неподготовленным людям иметь в виду, что созданный инстанс Компоузера ест довольно много денег, даже если у вас на нем ничего не работает.
Что мы имеем: в Airflow руками или по расписанию запускается DAG, в котором запускается задание, которое отправляет REST-запрос на виртуальную машину в Compute Engine, где запускается работа приложения с моделью, в результате которой она итерируется по коллекции документов с картинками в БД и для каждого документа записывает ему в суб-коллекцию 10 других похожих документов.
Далее уже бекенд магазина по запросу с сайта берет то, что нужно из БД, обрабатывает и отдает на фронт.
О каких-либо плюсах или минусах данного подхода говорить вряд ли стоит, так как данную реализацию ML-пайплайна, мягко говоря, трудно назвать полноценным, боевым end-to-end решением. Это просто то, с чего мы начали наше знакомство с GCP на уровне helloWorld.
Часть 2. Vertex AI: Auto-ML
На втором этапе проекта мы начали щупать всемогущий Vertex AI, облачную платформу машинного обучения от Google, которая предлагает комплексный подход для рабочего процесса по созданию, обучению и развертыванию моделей машинного обучения.
Для начала мы решили ознакомиться с сервисом AutoML и попытаться повторить всё то же самое, но используя нативные инструменты сервиса. AutoML заявлен как сервис, позволяющий разработчикам с ограниченным опытом ML обучать высококачественный модели, соответствующие потребностям бизнеса.
Но наша задача оказалась не реализуема, так как ограниченный функционал возможностей AutoML позволил лишь произвести классификацию картинок по категориям, но сравнить картинки по степени похожести между собой не представилось возможным. Оттолкнула также и дороговизна телодвижений в ходе наших HelloWorld экспериментов.
В целом AutoML показывает себя, как UI-ориентированный user-friendly сервис, охватывающий простые типовые задачи машинного обучения без возможности тонкой настройки и кастомизации.
Часть 3. Vertex AI Pipeline + Cloud CI/CD
Здесь начинается все самое интересное.
Vertex AI Pipelines
Платформа Vertex AI предоставляет отдельный сервис Pipelines для удобной разработки собственных ML-пайплайнов, а также другие сопутствующие ML-сервисы.
Пайплайны в Вертексе имеют serverless архитектуру и работают на двух фреймворках: KFP (KubeFlow) и TFX (TensorFlow). Мы выбрали KFP, как более подкрепленный документацией и популярный в народе. Но как оказалось позже, в некоторых вопросах документация гугла нередко написана довольно сухо или просто содержит устаревшую/deprecated информацию. Здесь нам на помощь приходили все средства: дока от KubeFlow, Git, статьи Medium/TowardsDataScience, Youtube и реже StaсkOverFlow (куда без него).
Для нас как для пользователей, пайплайн состоит из компонентов – степов. В рантайме каждый степ это по сути отдельная виртуальная среда, запускаемая на отдельной ВМ, то есть степы друг от друга изолированы и не имеют общего контекста, привычного по локальной работе в jupyter ноутбуках. По-хорошему, это нужно заранее учитывать в ситуации, когда data-scientist в команде локально разрабатывает жизненный цикл ML, а в свою очередь MLOps/ML-Engineer переносит всё это в пайплайн, пытаясь заставить работать, что не всегда получается сделать быстро и безболезненно. Это связано с тем, что специфика или порой ограничения Вертекса и фреймворка KubeFlow вносят свои коррективы в процесс разработки, принципиально отделяя локальную методику разработки от облачной:
Локально в ноутбуке мы объявляем какую-либо переменную, структуру данных, функцию и далее можем спокойно обращаться к ней из любой ниже идущей ячейки, так как у нас есть общий контекст ноутбука;
В вертекс пайплайне контекст существует только в рамках каждого степа;
C точки зрения кода каждый степ – это просто функция, которая может принимать на вход какие-то аргументы и/или что-то возвращать;
Степы общаются между собой только посредством входных/выходных данных. Эти данные могут быть в виде простых литералов, структур данных или артефактов машинного обучения (датасеты, метрики, модели);
Порядок и условия выполнения степов мы устанавливаем в тасках главного компонента пайплайна. Там же мы указываем какие аргументы и какой степ передает другому;
Если какие-то промежуточные или выходные данные из одного степа нужны в других, мы должны передавать их туда отдельно, с чем порой могут возникнуть сложности, так как типы передаваемых переменных, структур данных или артефактов ограничены. В таких случаях приходится либо изобретать велосипед или делать некоторый рефакторинг, либо идти на компромисс;
Мы должны подстраиваться под логическую декомпозицию жизненного цикла модели на степы. Причём фактическая декомпозиция в пайплайне может отличаться от изначально задуманной дата-сайентистом, так как иногда, например, проще совместить два степа ML-ноутбука в один степ пайлпайна, чем изобретать велосипед и заниматься лишней перекладкой данных.
Да, безусловно, когда схема пайплайна в UI отрисовывается, будучи красивой и массивной, это выглядит солидно и клиенто-привлекательно, но это не всегда оправданно. В нашем случае это был бы откровенный овер-инжиниринг. Более того, каждый лишний степ увеличивает общее время работы пайплайна, так как запуск каждой джобы на выполнение степа происходит не по щелчку пальцев. Порой на это может уходить до нескольких минут, а увеличенное время работы пайплайна – это увеличенные расходы. Этот процесс завязан на serverless архитектуре платформы и мы его не контролируем.
Ниже приведен базовый пример простейшего вертекс пайплайна из пары степов:
from kfp import compiler
from kfp.dsl import pipeline, component
from google.cloud import aiplatform
PIPELINE_ROOT = "gs://your_google_storage_bucket_name/pipeline_root/"
@component()
def step_1() -> str:
return "hello string from step_1"
@component()
def step_2(input_var: str):
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.info(f'Input var is: {input_var}')
@pipeline(name="pipeline", pipeline_root=PIPELINE_ROOT)
def pipeline():
step_1_task = step_1()
step_2_task = step_2(step_1_task.output)
compiler.Compiler().compile(
pipeline_func=pipeline,
package_path="pipeline.json"
)
job = aiplatform.PipelineJob(
display_name="pipeline",
template_path="pipeline.json",
pipeline_root=PIPELINE_ROOT,
enable_caching=True
)
job.run(sync=False)Забегая вперёд также отметим, что, помимо указанного выше, в процессе разработки были сделаны следующие выводы:
Выгружать картинки из хранилища в оперативную память ВМ, на которой отрабатывает степ, мягко говоря, неэффективно. Вместо этого рациональнее использовать память на локальном диске ВМ;
Статические данные, константы, URL-адреса, названия бакетов и прочее лучше вынести из степов и вообще из пайплайна. Их следует хранить отдельно в БД и получать при инициализации пайплайна, далее по цепочке передавать в главную джобу > в главный компонент > в таски конкретных степов;
Функции и классы вполне можно и лучше вынести в отдельную кастомную Python либу, которая будет храниться в Artifact Registry, что сильно сократит количество повторяющегося кода в теле степов пайплайна и увеличит удобочитаемость.
Разработку пайплайна и учебные эксперименты оказалось удобно* вести прямо на платформе Vertex в сервисе Workbench, где был создан Jupyter ноутбук, в котором было проведено довольно много времени и что не потянуло за собой каких-либо значимых затрат.
*Этот подход не лишен своих недостатков, так как ноутбук на воркбенче, в отличии от IDE, ничего вам не подсказывает и не подсвечивает элементарных ошибок/опечаток, из-за чего иной раз при желании проверить работоспособность написанного, вы сталкиваетесь со своего рода дебагом мелких ошибок через пробные запуски** пайпа.
**Можно, конечно, хоть и неудобно, заниматься копипастом между воркбенчем и IDE. Это может сэкономить некоторое время, так как иногда довольно расточительно ждать, пока пайп запустится и, например, через 20 минут работы свалится, дойдя до какой-нибудь опечатки в коде.
Для начала мы просто следовали гугловым обучалкам по созданию разных пайплайнов и повторяли показанное. Изучив доступные обучалки и некоторые туториалы, строили с нуля свои простые HelloWorld пайплайны.
Быстро наигравшись в песочнице, мы перешли к построению пайплайна под наш жизненный цикл ML (который к третьей фазе претерпел сильные изменения), и начали интегрировать код из нашего ML/DS ноутбука. Пайплайн строился пошагово и с целью проверок гипотез/догадок довольно часто запускался для отладки. Попутно дописывался необходимый код, появлялись новые функции, что-то рефакторилось, решались возникающие проблемы, например, с невозможностью передачи между степами некоторых структур данных, таких как многомерный NumPy массив с векторным представлением картинок или список из кастомных @dataclass объектов, так как при передаче между степами KubeFlow под капотом пытается спарсить наши данные в json.
Завершив интеграцию ML/DS ноутбука и отладку пайлайна, UI-схема в вертексе получила следующий вид:
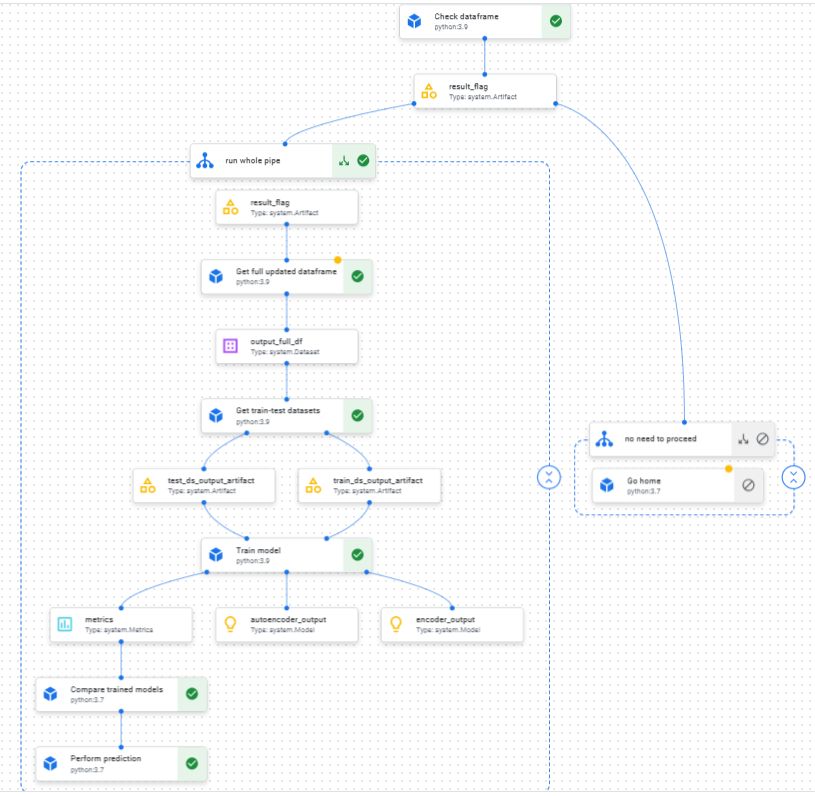

Происходящее на схеме выше можно описать следующим образом:
в нулевом степе “Check dataframe” мы проверяем исходный датафрейм на наличие изменений (были ли добавлены новые товары). Если изменения есть, мы входим в основную ветку пайплайна;
в основной ветке мы первым делом препроцессим исходный, сырой датафрейм в рабочий датафрейм, который выходным артефактом передается на вход следующему степу;
где происходит разделение датафрейма на Train/Test датасеты, которые в свою очередь передаются на тренировочный степ;
в результате тренировки модели мы получаем метрики и артефакт тренированной модели. Сама модель сохраняется в хранилище, а метаданные, содержащие айдишник, метрики и путь до расположения в хранилище сохраняются в БД;
на следующем степе происходит сравнение моделей и выбор победителя. В нашем случае этот степ несколько условен, так как мы просто выбираем модель из хранилища, у которой лучший показатель по метрике среднеквадратичной ошибки (loss mse);
наконец, финальный степ пайплайна – Predict, куда на вход из предыдущих степов стекается множество разной информации: метрики модели победителя, строки с путями, статические переменные и прочее. Из полученных данных мы восстанавливаем модель-победителя, выгружаем архив сжатых картинок, вычленяем эмбеддинги из картинок. После чего делаем предсказания, то есть для каждой картинки находим 10 других наиболее похожих и записываем метаданные о них в суб-коллекцию для каждого документа в БД.
Облачный CI/CD
С целью автоматизации работы нашей системы и для того, чтобы всё запускалось условно по одному клику, параллельно с разработкой ML-пайплайна на Вертексе, мы также построили своего рода облачный CI/CD пайплайн со следующей схемой:
Git > Cloud Build + Terraform > Cloud Run > Vertex AI Pipeline
Идея в том, что при пуше кода в нужную ветку репозитория на гите, в клауде через webhook запускается сервис Cloud Build, где в процессе билда отрабатывают следующие шаги:
выгрузка репозитория и переход к коммиту, на основе которого произошел триггер;
проверка docker-образов и сборка основного docker-образа с пушем образа в Artifact Registry;
Terraform входит в чат и по заданному ему плану, вносит необходимые изменения инфраструктуры для нашего клауда. Здесь мы также создаём Cloud Run сервис и указываем ему контейнер с нашим docker-образом к деплою
запуск Cloud Run сервиса с нашим приложением из указанного ранее контейнера и там же запуск джобы для нашего Вертекс ML-пайплайна по REST api. После чего просыпается Вертекс и всю остальную работу касательно ML-пайплайна уже делает за нас.
Пройдя вышеуказанные шаги, далее происходит всe то, что было описано в начале третьей части, то есть создается ML-пайплайн и, по схеме с приведённых выше картинок, он начинает степ за степом проходить жизненный цикл модели. В конечном итоге записывает в БД результат предсказаний, выводимый в карусель похожих товаров на сайте онлайн-магазина.
Заключение
Подводя итоги, можно сказать, что лишь на третьем этапе разработки, используя функционал Vertex AI мы смогли реализовать изначально поставленную задачу в рамках доступного инструментария GCP.
Платформа Vertex AI оказалась не лишенным своих специфических нюансов инструментом для процесса полноценной ML-разработки.
Ввиду некоторой схожести устройства аналогичных облачных сервисов, полученный опыт работы на GCP можно смело транслировать для миграции на другие облачные платформы (Amazon Web Services, Microsoft Azure, Yandex Cloud и другие).
Автор статьи: Олег Климкин, специалист отдела разработки в Neoflex.