
Всем привет! Меня зовут Николай Безносов, я отвечаю за применение и развитие машинного обучения и продвинутой аналитики в билайне. В одной из прошлых статей мои коллеги рассказывали о месте Seldon в ML-инфраструктуре компании, а сегодня мы поднимемся на уровень выше и поговорим о том, что из себя представляет MLOps в билайне в целом — как с точки зрения инфраструктуры, так и с точки зрения процессов.
В статье речь пойдет о нашем опыте создания ML-платформы, которая помогает дата-сайентистам самостоятельно управлять всем жизненным циклом ML-моделей — от разработки до постановки в production. Я рассчитываю, что статья будет полезна как небольшим командам, которые только начинают выстраивать у себя ML-инфраструктуру, так и корпорациям с большим количеством команд и жесткими требованиями к безопасности, которые при этом хотят эффективно масштабироваться.
Статья будет состоять из двух частей. В первой части мы посмотрим верхнеуровнево, как и по каким причинам менялись наши ML-процессы и инфраструктура в билайне — с чего мы начинали и к чему в итоге пришли. Во второй части поговорим о конкретных инструментах и технологиях, которые мы внедрили, чтобы сделать наш процесс разработки и деплоя моделей простым, воспроизводимым, автоматизируемым и наблюдаемым.
Если вы привыкли воспринимать подобную информацию в видео-формате, то можете посмотреть мое выступление на Data Fest 2023, по мотивам которого и написана данная статья.
План
Big Data в билайн
Зачем нужна ML-платформа?
Что мы ждем от ML-платформы?
Кто должен заниматься внедрением ML-модели в production?
С чего мы начали
-
Что мы поменяли
Ускоряем разработку и делаем эксперименты воспроизводимыми
Масштабируемся на 10+ команд
Оркестрируем ML-пайплайны
Добавляем моделям наблюдаемости
Автоматизируем дообучение моделей
Заключение
Big Data в билайн
Начнем с небольшой вводной о том, что из себя сегодня представляет Big Data в билайне, чтобы у вас, во-первых, было понимание масштаба того, о чем пойдет речь в статье, а во-вторых, предпосылок, которые сформировали потребность в появлении ML-платформы.
Big Data в билайн — это, прежде всего, люди и продукты:
500+ дата-специалистов
100+ дата-продуктов
10++ ML-команд
А также данные и технологии:
25+ ПБ данных в Hadoop
Spark-on-Yarn в качестве основного ETL-движка
Kubernetes для деплоя сервисов и приложений
Платформа для анализа данных и машинного обучения
И множество других инструментов и технологий
Зачем нужна ML-платформа?
Не знаю, есть ли какое-то общепризнанное определение MLOps, но для нас это набор процессов, фреймворков, практик, которые помогают устранить барьер между разработкой моделей и их внедрением.
И прежде чем приступать к разработке ML-платформы и MLOps-процессов, стоит задать самый главный вопрос — зачем нам это нужно?
Сегодня многие компании (в том числе и билайн) проповедуют продуктовый подход и работают по Agile независимыми кросс-функциональными командами. В условиях децентрализации, когда в компании много разрозненных команд и при этом постоянно появляются новые, возникают некоторые сложности. Предположим, что создается новая команда. В какой-то момент ей потребуется полный набор инструментов для работы: настроенная инфраструктура, сервисы и процессы для разработки. И было бы неплохо, если бы команда могла воспользоваться чем-то готовым, а не изобретать все с нуля.
Таким образом, ответ на вопрос “зачем” вроде бы очевиден — мы хотим разрабатывать быстрее, дешевле и качественнее. Но за счет чего? За счет того что команды по кнопке получают готовый набор “лего” вместе с инструкциями как из этих деталек собрать “космический корабль”.
Также платформу можно считать необходимым элементом, способствующим возникновению новых ML-продуктов — чем более доступными наши технологии будут, тем большее количество ML-продуктов появится в компании.
Что мы ждем от ML-платформы?
Теперь давайте разберемся с тем, что конкретно мы ожидаем от ML-платформы — какой она должна быть и что должна уметь.
Во-первых, платформа должна выполнять свою главную функцию — предоставлять инфраструктуру как self-service. Картинка ниже наглядно демонстрирует огромное количество существующих фреймворков, относящихся к MLOps. Из-за того что их так много, сложно не только выбрать конкретную технологию под свою задачу, сложно все эти технологии между собой интегрировать и связать единым понятным процессом. И это именно то, что мы ожидаем от платформы — не набор разрозненных сервисов, а единый клиентский путь для создания ML-продуктов.

Во-вторых, чтобы быстро разрабатывать и внедрять наши модели, платформа должна быть простой в использовании, особенно для новичков, с низким порогом входа, а также удобной и гибкой. Желательно, чтобы у дата-сайентистов было ощущение, что они работают на своей локальной машине, но с мощностями большой компании.
В-третьих, мы ожидаем, что платформа будет покрывать полный MLOps-цикл — от разработки модели до ее внедрения в production. Разумеется, с учетом основных MLOps принципов, а это означает, что с помощью платформы команды должны уметь без особых трудностей создавать пайплайны, которые автоматизированы, воспроизводимы, наблюдаемы и т.д.
Кто должен заниматься внедрением ML-модели в production?
Помимо вышесказанного, хочется заострить внимание на том, кто и как может быть пользователем ML-платформы. В жизни ML-модели выделяют 2 этапа — этап разработки модели и этап, когда она начинает приносить пользу в production. И если с первым этапов все понятно — это работа дата-сайентиста, то вот кто должен внедрять и поддерживать модели — вопрос в целом дискуссионный. В некоторых компаниях этим могут заниматься отдельные разработчики или ML-инженеры, но мы в билайне изначально по ряду причин решили, что будем стремиться к тому, чтобы дата-сайентист полностью владел всем жизненным циклом своей модели.
Во-первых, у нас достаточно типовые задачи с точки зрения внедрения — 90-95% это batch-джобы на PySpark или Python, которые мы запускаем по расписанию. Есть реалтайм, но он тоже хорошо поддается шаблонизации. Во-вторых, мы считаем, что это более эффективно, когда разработчик модели, досконально понимающий, как она работает, в дальнейшем занимается ее поддержкой и доработкой. И в-третьих, это просто вопрос ресурсов - нанимать отдельного ML-инженера в каждую команду дорого для компании.
Поэтому теперь, руководствуясь всеми этими предпосылками, предлагаю вернуться к тому моменту, когда мы только начинали выстраивать у себя ML-инфраструктуру и процессы, и пройти заново тот путь, который нам удалось проделать вместе с компанией.
С чего мы начали
Давайте начнем с того, что вспомним, как выглядит классический, каноничный жизненный цикл ML-модели. Предположим, что мы занимаемся разработкой ML-модели и уже определились с постановкой задачи, бизнес-требованиями и начинаем непосредственно работу с данными.
Для этого у нас должен быть Data Lake (это не обязательно должен быть Hadoop) или какое-то хранилище, из которого мы можем наши данные забирать и анализировать. На этом этапе наша основная задача - понять, нужна ли нам ML-модель и сможем ли мы ее построить (достаточно ли данных, приемлемого ли они качества и т.п.). Если модель нам нужна, построить мы ее можем, тогда переходим к этапу R&D (проведения экспериментов).
R&D — это ручной длительный процесс со множеством итераций в Jupyter Notebook, в ходе которого мы обрабатываем данные, проверяем гипотезы, генерируем признаки, строим модель и оцениваем ее качество. Результат этого этапа — натренированная модель в pickle (или другом) формате, которую мы должны потом сложить в определенное место. Это место принято называть Model Registry.
Model Registry здесь подразумевается в очень широком смысле. Это не обязательно должен быть специализированный фреймворк, заточенный конкретно под задачи хранения ML-моделей. Если вы сохраняете ваши модели в Git или HDFS, как-то правильно присваиваете им теги и версионируете, то, наверное, это тоже можно считать Model Registry.
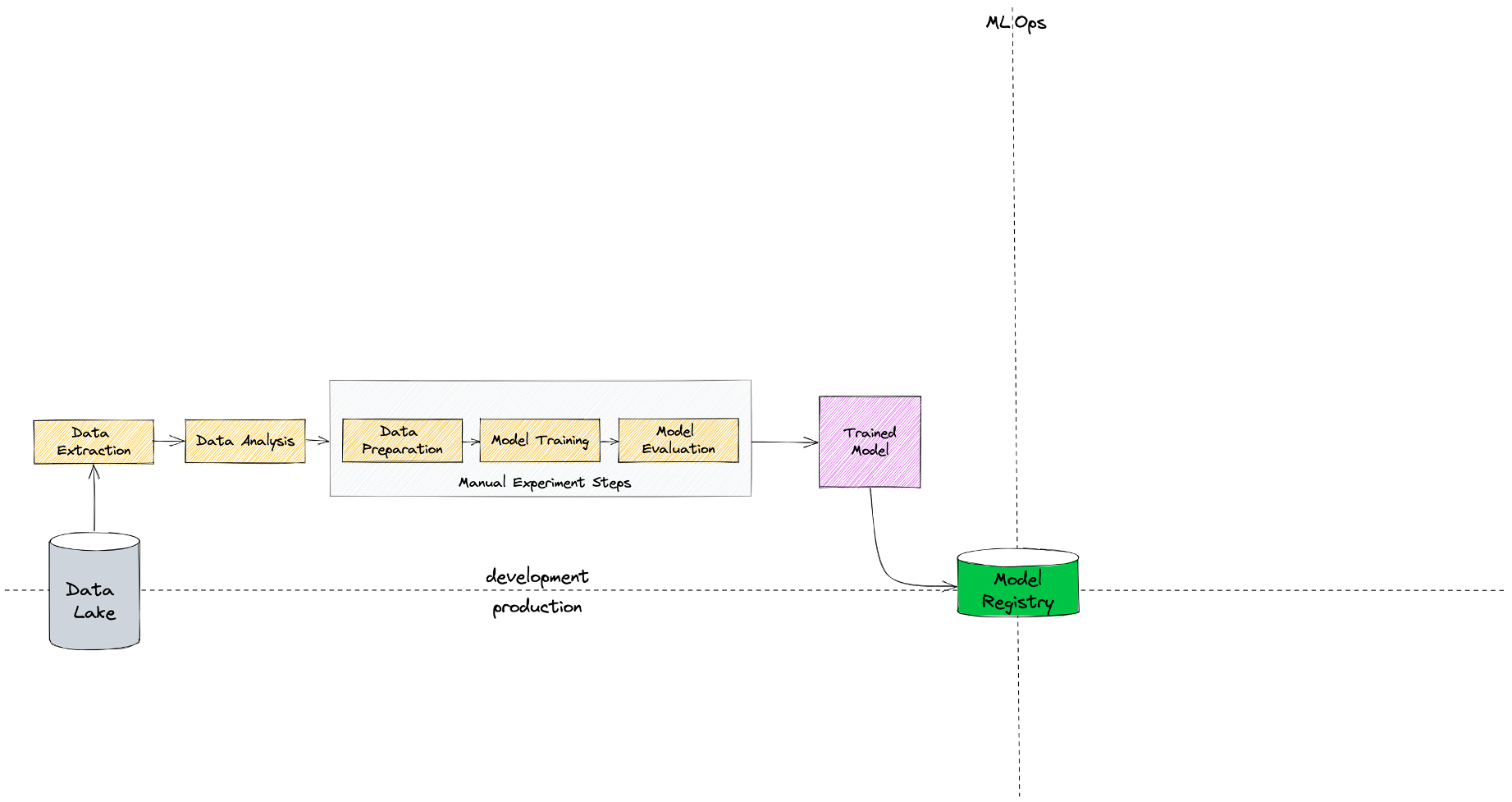
На схеме выше видно, что Model Registry является своеобразным разделителем между этапом разработки модели и этапом ее внедрения в production. В некоторых компаниях работа дата-сайентиста на этом этапе может завершиться — он перекидывает свой Jupyter Notebook с моделью разработчику, который дальше ее уже внедряет и поддерживает. Если же у вас (как и у нас) таких разработчиков нет, то за дальнейшую судьбу модели придется отвечать тоже дата-сайентисту.
Поэтому на следующем этапе у нас дата-сайентист пишет код инференса модели и кладет его в репозиторий.
Как я упоминал ранее, у нас в билайне большая часть задач — это batch-джобы, поэтому помимо кода с логикой модели нам требуется код пайплайнов, в которых будет описано - где, каким образом и с какой периодичностью мы нашу модель запускаем. Код пайплайнов мы тоже храним в репозитории.
Чтобы изолировать сервисы от друга и упростить управление зависимостями (ведь часто разным проектам требуются разные версии библиотек), мы запускаем наши модели в контейнерах. Для этого мы добавили CI/CD, который собирает окружения с кодом и пушит их в Image Registry.
Сами же пайплайны с периодичностью запуска модели доставляются непосредственно на прод с помощью Continuos Delivery, где ими уже управляет специализированный шедулер.
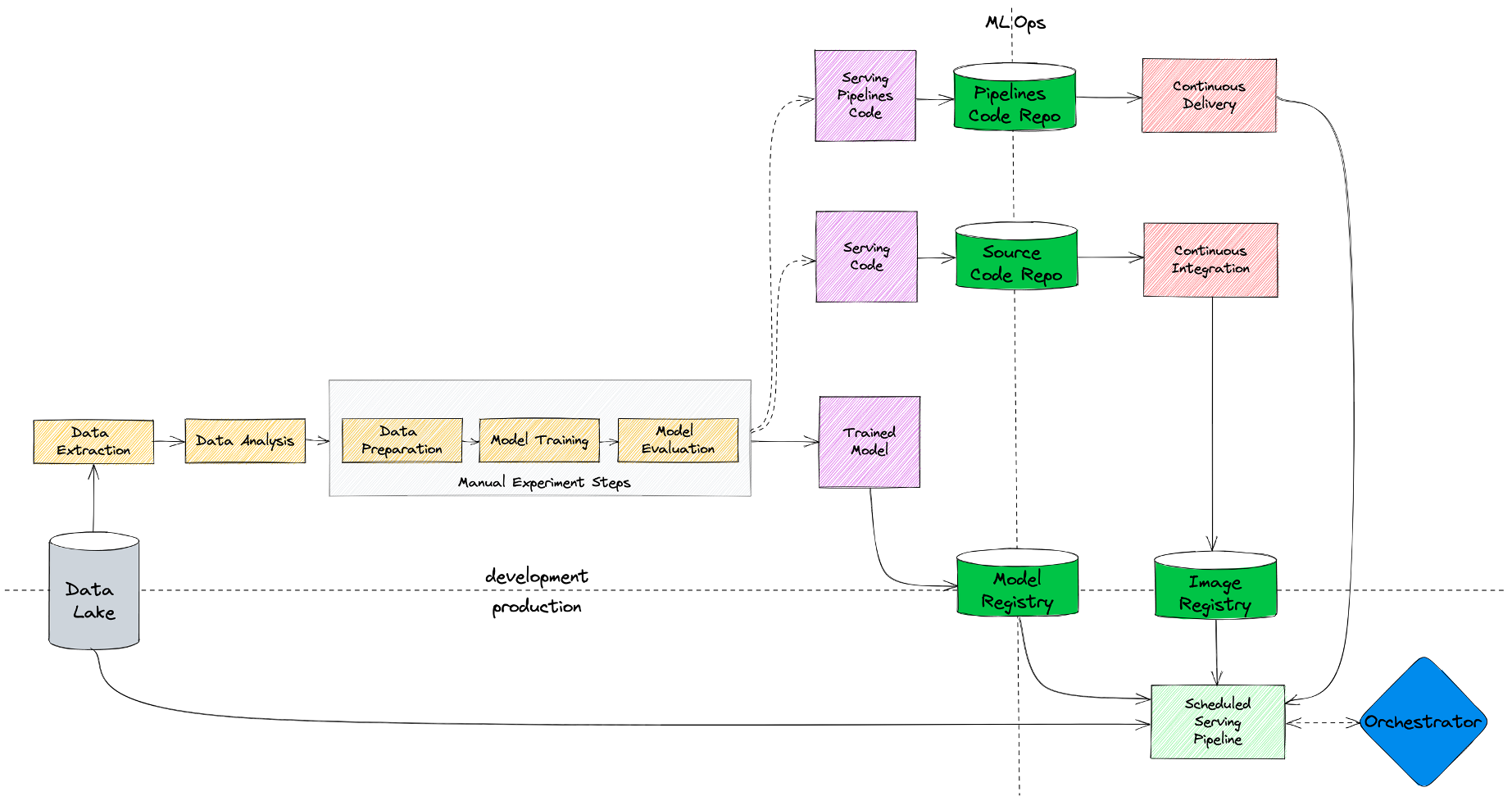
Итого — мы получили сервис, который запускается по расписанию оркестратором, забирая контейнер с кодом из Image Registry, модель — из Model Registry, а данные подтягивая из хранилища. И здесь мы стремимся к тому, чтобы в проде модель использовала такие же данные, с такими же преобразованиями, на которых дата-сайентист проводил обучение. На этом моменте зачастую возникает множество ошибок, поэтому этап создания признаков для модели в production рекомендую тщательно валидировать.
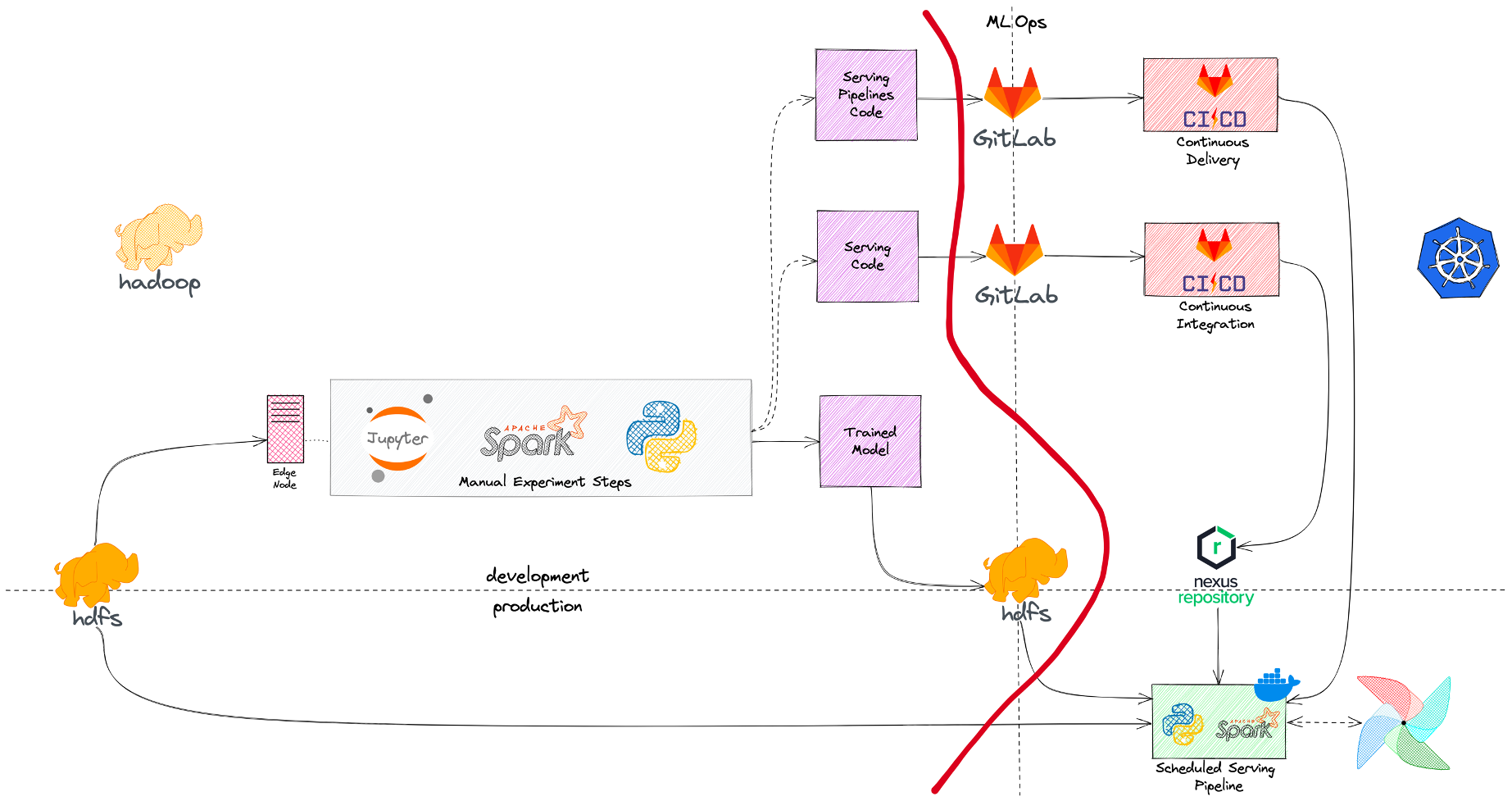
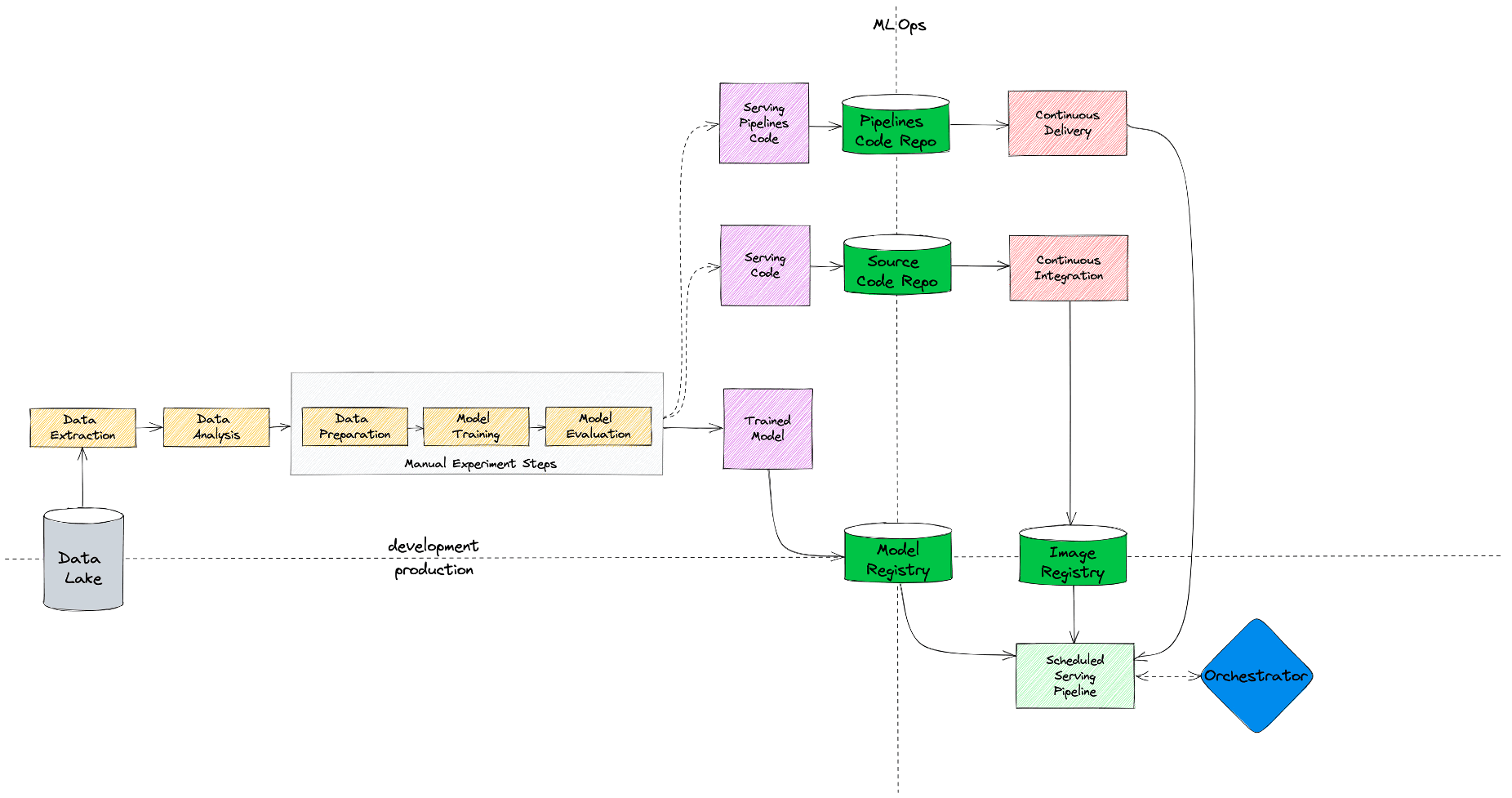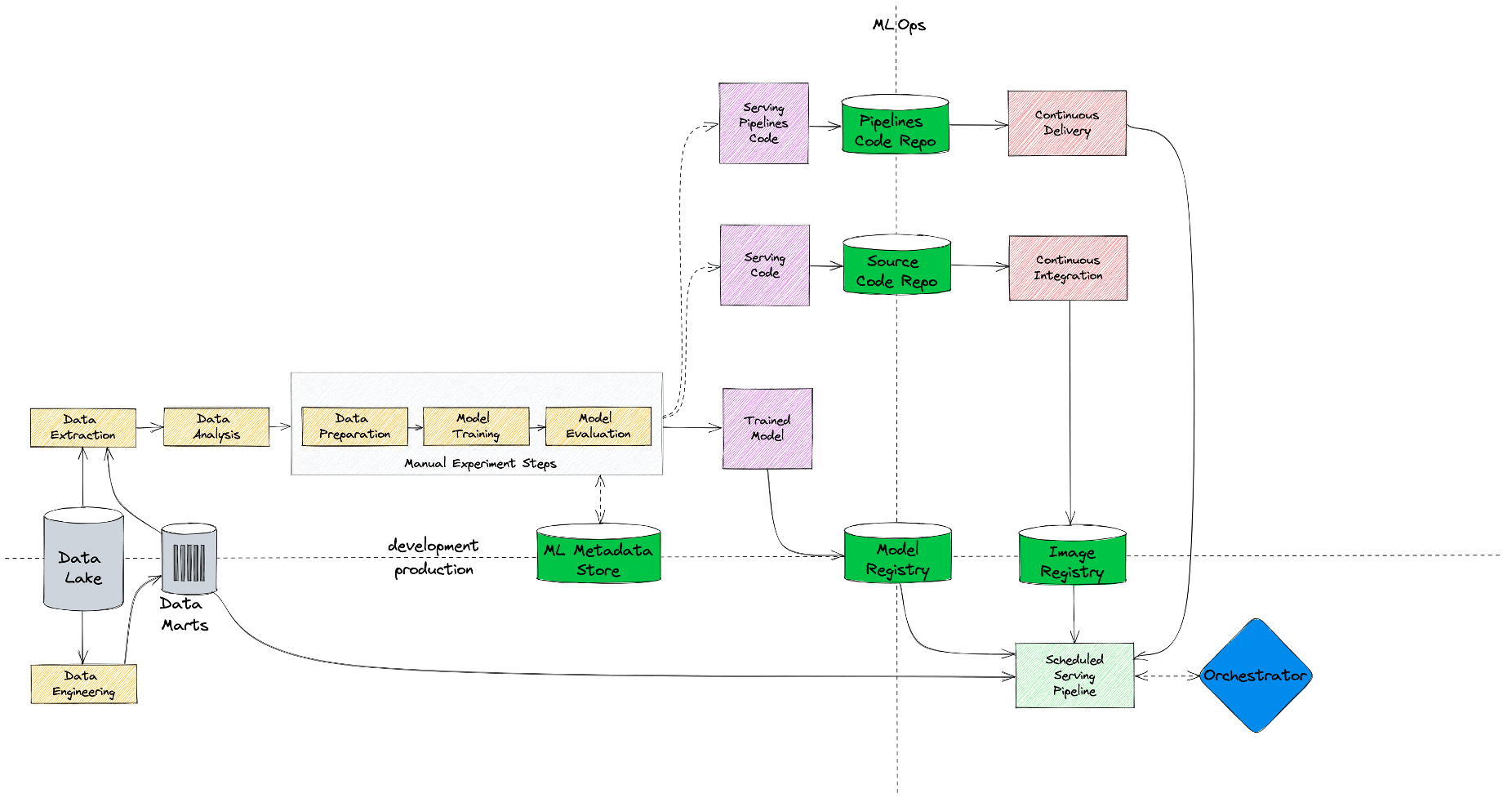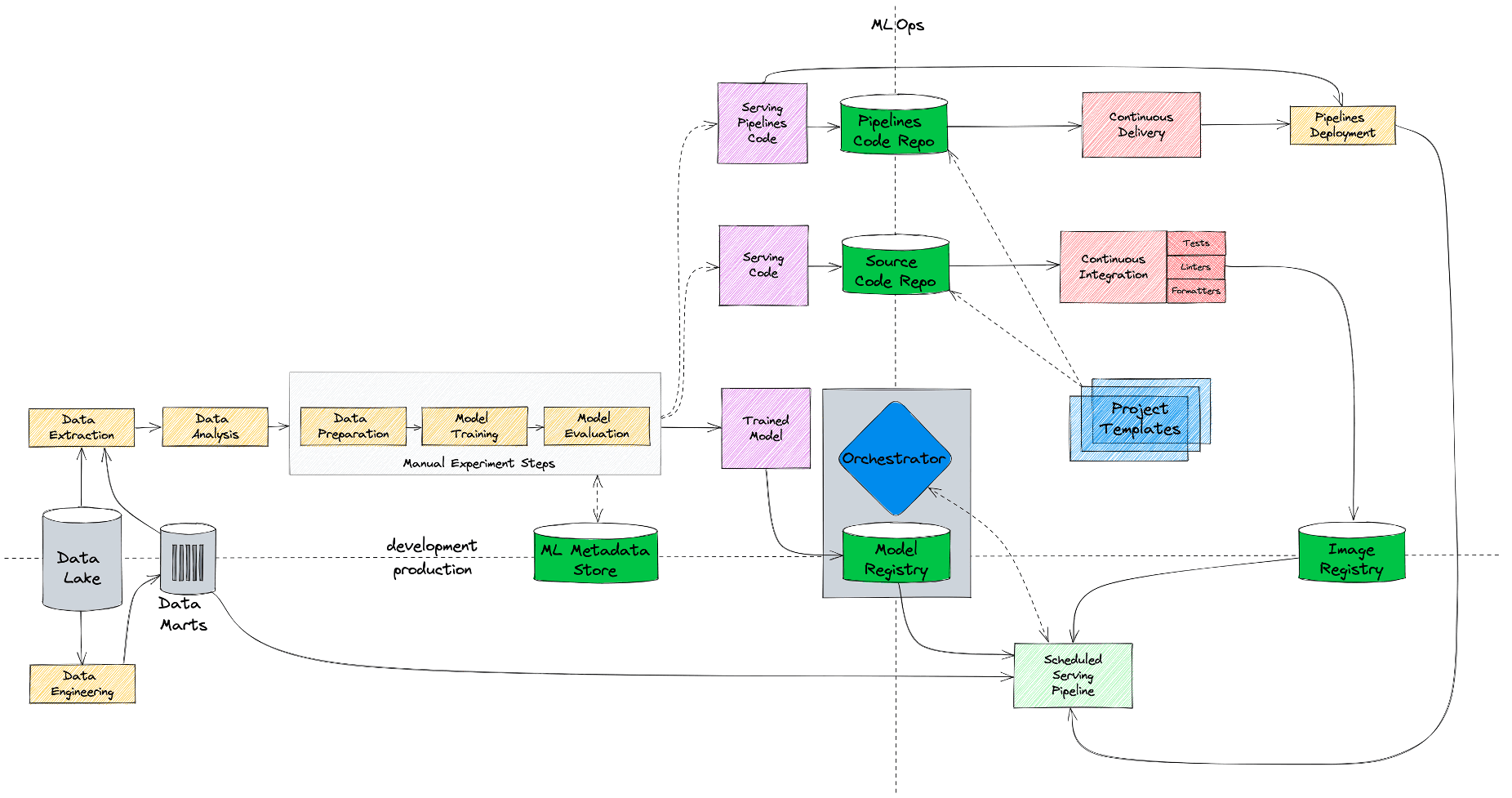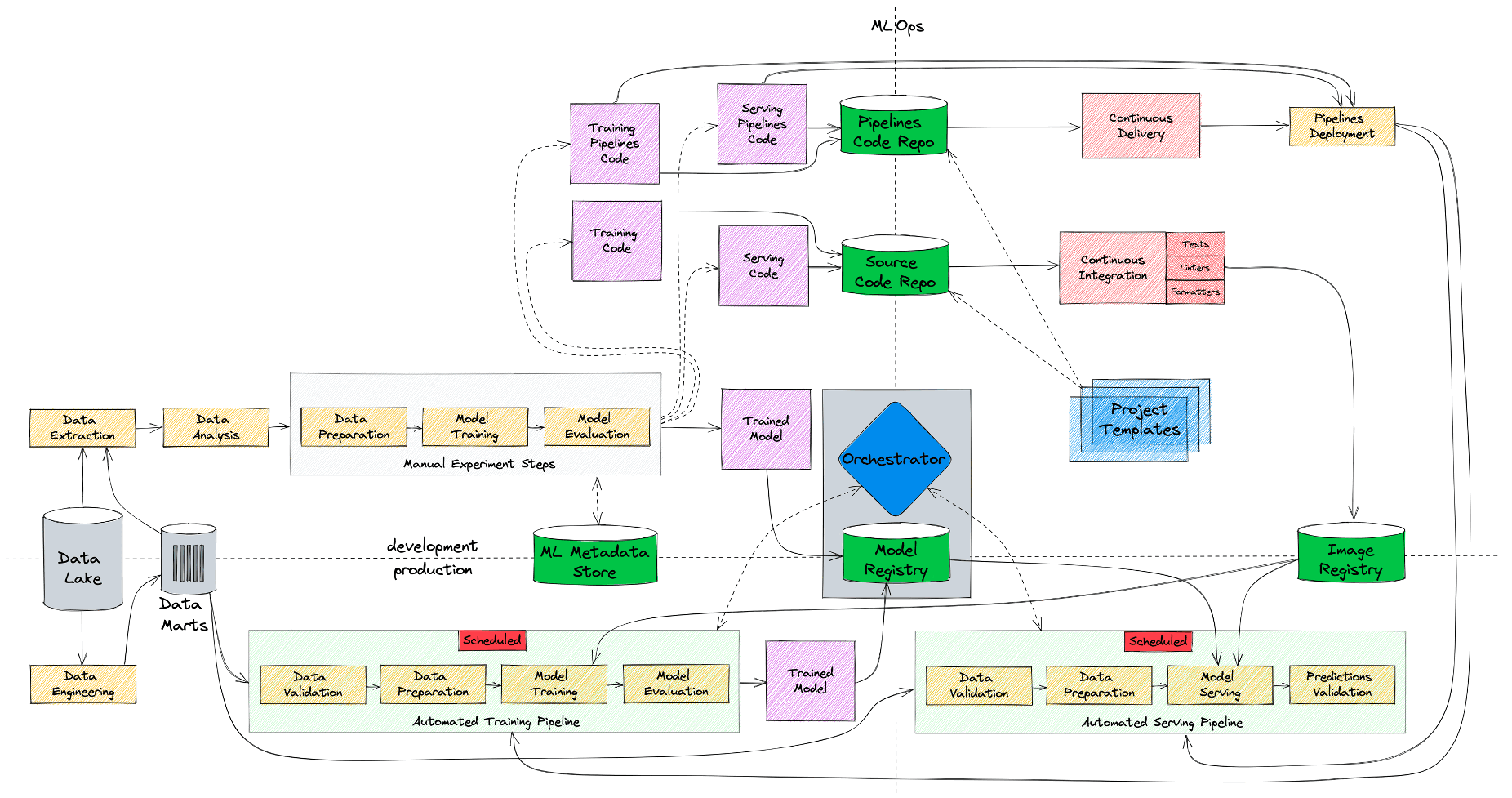
На схеме выше показано, как выглядел наш стартовый MLOps-процесс с точки зрения инструментов и инфраструктуры. Данные мы хранили (и до сих пор храним) в HDFS/Hive, эксперименты проводили в Jupyter Notebook на Edge-нодах хадупа, модели складывали и версионировали тоже на HDFS, код — в Gitlab, а Docker-образы — в Nexus. Оркестрировал у нас все джобы Airflow в K8s с помощью KubernetesPodOperator. Все, что слева от красной линии на схеме, это инфраструктура Hadoop, а справа - инфраструктура Kubernetes. То есть мы просто взяли те инструменты, которые уже были в компании и адаптировали их под потребности задач машинного обучения.

Собственно, это то состояние, с которого мы начали и по которому прошел не один десяток наших первых ML-моделей. Процесс не идеален, в нем много моментов, которые можно улучшить (и далее мы этим займемся), однако если у вас не очень большая команда и не очень требовательные к постоянному дообучению модели, то такой процесс - достаточно сильный бейзлайн, на котором можно жить достаточно долго.
Что мы поменяли
Ускоряем разработку и делаем эксперименты воспроизводимыми
Сначала мы решили поработать над самыми трудоемкими и длительными этапами - этапом обработки данных и этапом R&D.
Первое, что мы сделали — это добавили витрины с фичами (Data Marts), которые создаются дата-инженерами. Во-первых, это позволило нам обучаться и делать предсказания на одних и тех же данных, что существенно сократило количество ошибок в проде. А во-вторых, мы теперь можем переиспользовать разные признаки между нашими моделями, а не создавать их каждый раз с нуля на лету.
Второе, что мы усовершенствовали, это этап экспериментов. Традиционно этот процесс может значительно растягиваться во времени, поэтому нам критически важно уметь сохранять параметры и результаты наших экспериментов, чтобы иметь возможность в какой-то момент к ним вернуться и воспроизвести, а не начинать все сначала. Для этого мы добавили фреймворк (ML Metadata Store), с помощью которого дата-сайентисты могут логировать свои эксперименты.
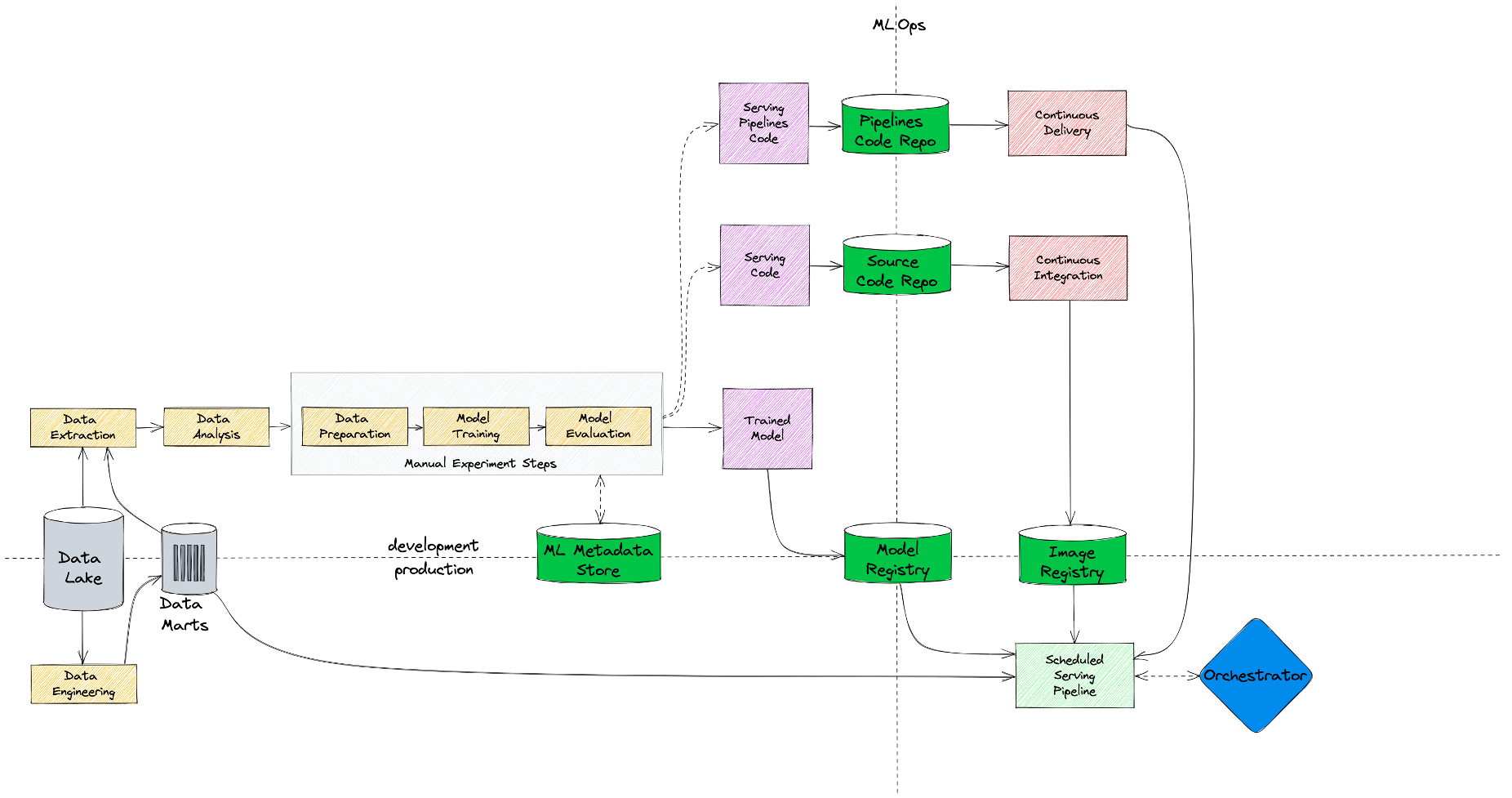
Масштабируемся на 10+ команд
Итак, самые трудоемкие части мы успешно оптимизировали. Но когда продуктов, которым нужно выводить модели в production, стало больше 10, у нас возникли проблемы масштабирования. Одно дело — пустить по этому процессу несколько команд, и совсем другое, если мы хотим, чтобы любой дата-сайентист мог самостоятельно модель обучить и вывести в production.
Если взглянуть на схему выше, становится понятно, что процесс уже достаточно сложный, и новым командам было непросто начать по нему работать. Поэтому чтобы хоть как-то упростить им жизнь, мы добавили шаблоны ML-проектов (Project Templates), из которых можно раскатить себе стартовый репозиторий.
Репозиторий включает в себя базовую структуру проекта, CI/CD со сборкой образа и установкой зависимостей, различные проверки качества кода, стайлчеки, линтеры, форматеры и т.п. Другими словами, техническую обвязку, которая необходима пользователям, когда они выводят свою модель в production. С помощью данных шаблонов мы хотим добиться нескольких вещей. Во-первых, чтобы сотрудники думали о разработке модели, а не о технической рутине вокруг нее. А во-вторых, чтобы все работали по единым лекалам, используя разработанные нами лучшие практики.
Оркестрируем ML-пайплайны
Следующий неоптимальный элемент в нашей схеме — это оркестратор. У нас Airflow — это, пожалуй, самый популярный, production-ready, проверенный временем шедулер. Но применительно к ML-задачам у Airflow немало недостатков, самый главный из которых - это низкая скорость итераций. Запустить adhoc или протестировать свои пайплайны с помощью Airflow — это проблема. К помощи Airflow мы прибегаем в тот момент, когда у нас все готово, протестировано и осталось лишь поставить свой код на расписание. Именно поэтому на схеме Airflow расположен в production области. А хочется, чтобы оркестратор можно было использовать и в процессе разработки модели, и в процессе ее внедрения в прод.
Другими словами, нужна возможность быстро запустить любой adhoc на кластере или поставить модель на расписание на пару дней, не дожидаясь длительного процесса синхронизации дагов из Git. И именно это мы и сделали. Теперь дата-сайентисты могут запускать свои пайплайны как вручную (в обход Git), так и через Continuous Delivery, как и ранее.
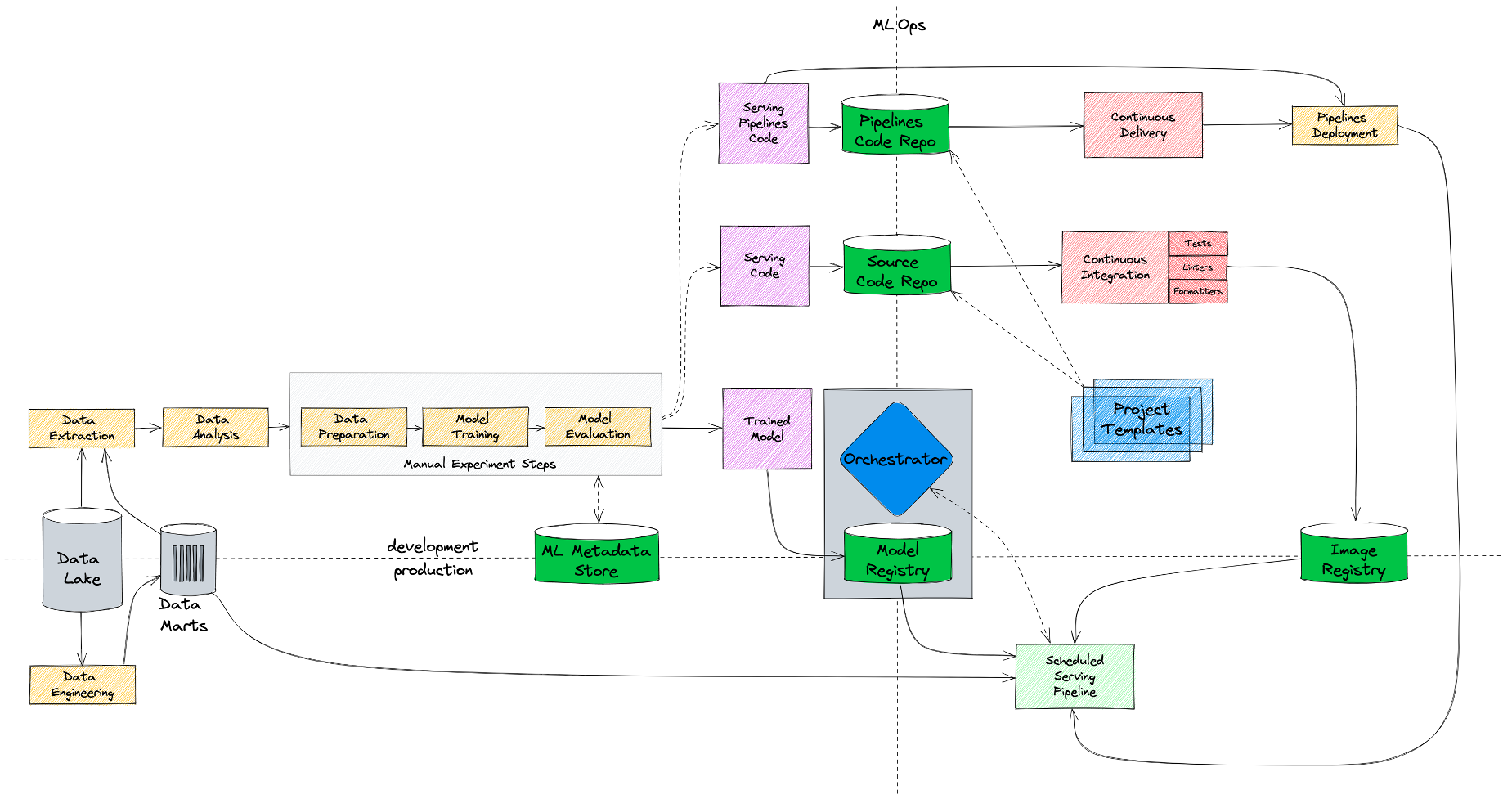
Добавляем моделям наблюдаемости
И, наконец, мониторинг — та часть, которая до этих пор отсутствовала в наших моделях. Так как мы работаем с batch-джобами, нам нужно уметь валидировать как входные данные, так и предсказания модели. И поэтому мы добавили стадию мониторинга.
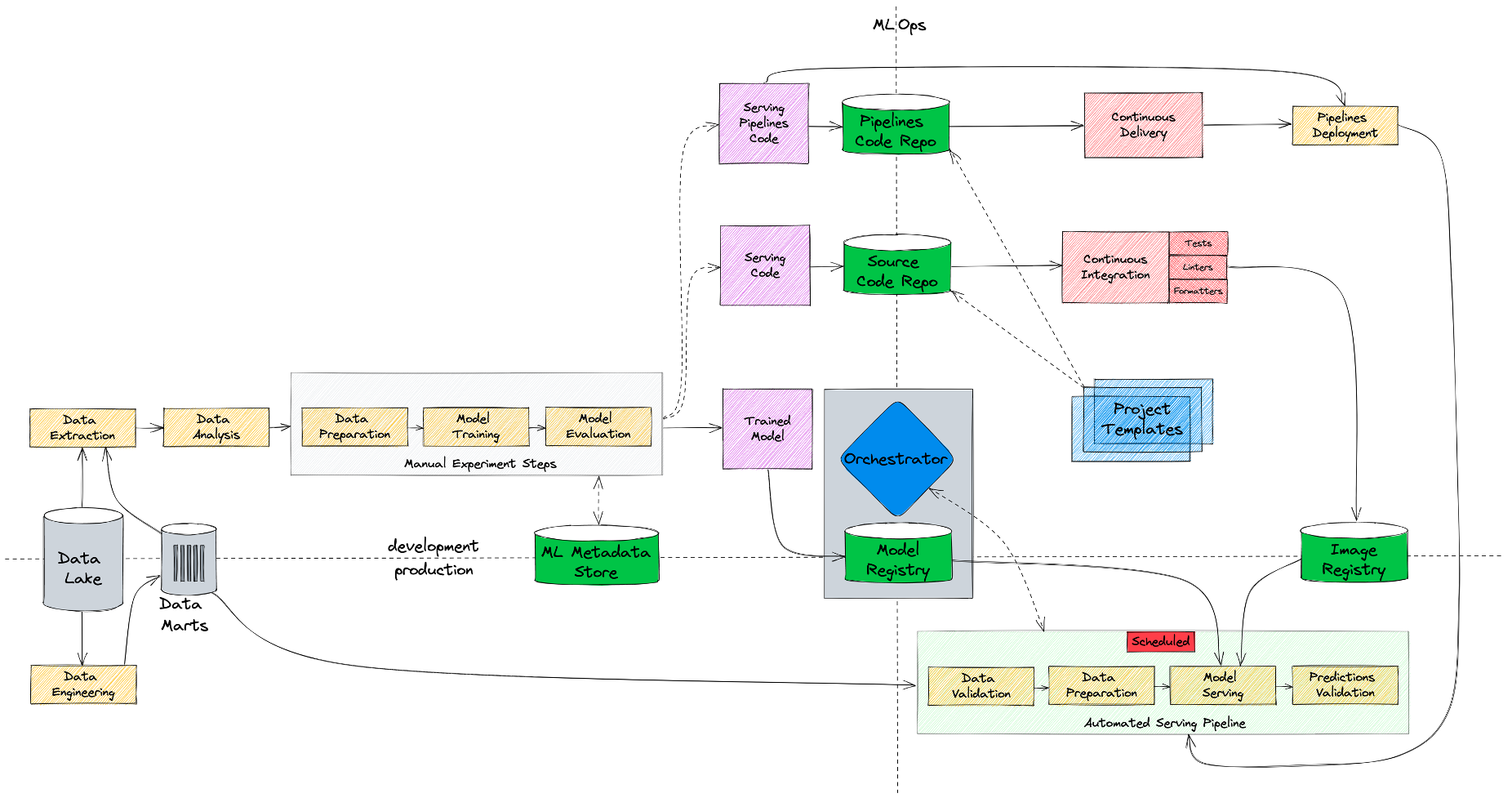
Автоматизируем дообучение моделей
Но что делать, если мониторинг обнаруживает деградацию качества модели и эта деградация вызвана дрифтом в данных? Изменилось поведение пользователей или каких-то показателей. Хорошая практика — дообучить модель на новых данных. Мы можем сделать это вручную, потому что весь процесс тренировки у нас воспроизводимый. Но будет еще лучше, если не придется отвлекать дата-сайентиста от его текущих задач. С технической точки зрения мы можем этот процесс автоматизировать, так как вся инфраструктура и инструменты у нас есть. Но самое сложное — это не настроить инфраструктуру, самое сложное — это изменить процессы. И в нашем случае пришлось изменить процесс так, чтобы мы начали относиться к коду тренировки модели точно так же, как к production коду. Поэтому теперь дата-сайентист, помимо кода инференса, должен написать код тренировки модели. После этого он может либо запускать дообучение вручную, либо поставить его на расписание.

Конечно, требование писать тренировочный код достаточно жесткое, поэтому пока что оно исполняется не для всех моделей, а только для самых критичных, где это действительно необходимо. Но ничто не мешает использовать этот подход для любой модели.
На схеме выше представлено, как выглядит наш процесс сейчас, а на схеме ниже — эволюция наших MLOps-процессов от базового состояния, по которому мы выводили наши первые модели, до текущего.
Заключение
В первой части статьи мы с высоты птичьего полета посмотрели на эволюцию наших MLOps-процессов. Все изменения были естественной реакцией как на увеличение количества команд и дата-сайентистов, так и на ужесточение требований к качеству моделей, скорости и стоимости их разработки и поддержки. В следующей части мы спустимся на уровень конкретных инструментов и технологий, которые мы используем. Обсудим их преимущества, недостатки и сложности, с которыми мы столкнулись при их внедрении в контур большой корпорации и интеграции в единую ML-платформу. А также расскажем о том, к каким результатам все это нас привело.
Комментарии (3)

stranger1101
17.10.2023 17:00+1Спасибо большое за статью! Будет очень интересно увидеть вторую часть.
Интересно понять про Data Marts - как вы добиваетесь того что эти же данные доступны и в training и в real-time inference? Или у вас большинство инференса не real-time?
iimoto
Подскажите, каким инструментом рисовали схемы?
x-sile Автор
excalidraw.com