
Эта статья посвящена реально работающей информационной системе (ИС), основанной на иерархической модели данных. Скажу точнее - это не просто ИС - это инструмент разработки ИС любого уровня сложности, включая ERP, CRM, PPM и т.д., обладающий полным набором средств разработки (инструментом описания структуры данных, встроенным процедурным языком и языком запросов, инструментом разработки экранных форм, инструментом написания программного кода и т.д).
В статье я расскажу не только как это выглядит, но и как это все устроено. Статья будет большая, и поэтому мне придется разбить ее на несколько частей.
Собственно, причина, по которой я взялся за написание этой статьи, следующая: ИС, про которую я рассказываю, достаточно «тяжелая» и использует в качестве СУБД Oracle версии 11g, что в настоящих условиях является неприемлемым из-за санкционной политики и требования импортозамещения. Поэтому у нас (тех, кто был связан в свое время с разработкой этой системы) возникло желание посмотреть, возможен ли перевод такой ИС на импортонезависимое ПО. Понятно, что для начала необходимо проверить возможность использования импортонезависимых СУБД, например, PostgreSQL.
Таким образом статья будет состоять из трех частей. В первой части я опишу идеологию ИС и дам некоторое представление о процедуре разработки структуры данных. Во второй части я опишу внутреннее устройство ИС, то есть опишу структуру БД, которая реализует иерархическую модель данных. И в третьей части я попробую определить возможность реализации такой структуры БД на PostgreSQL.
Часть 1. Что чобой представляет ИС
Итак, что из себя представляет эта ИС (называть ее я не буду, так как это не рекламный материал). ИС имеет трехзвенную структуру: Сервер БД (Oracle 11g), сервер приложений и тонкий клиент под MS Windows. Система доказала свою работоспособность на предприятиях с одновременно активно работающими сотрудниками в количестве 200+. С точки зрения разработчика система реализует иерархическую модель данных и предоставляет разработчику все необходимые встроенные инструменты разработки: инструмент формирования структуры данных, редактор экранных форм, редактор кода. Разработка ведется на двух встроенных языках программирования: APL – процедурный язык и AQL – язык запросов к данным. Процедурный язык содержит полный набор функций для работы с обычными данными (строковыми, числовыми, датами, списками, таблицами и т.д.) и, кроме того, содержит функции со специфичными для данной ИС данными. Ну а в необходимости использования специального языка запросов вы убедитесь во второй части статьи.
Идеология построения ИС
В основе идеологии построения ИС лежит направленный граф понятий (сущностей) предметной области (например: Предприятие, Подразделение, Сотрудник, Накладная, Строка накладной, Номенклатура и т.д.).

Соответственно, в ИС используются следующие понятия:
Категория – некоторая сущность предметной области (например, предприятие, сотрудник, накладная и т.д.). Категория характеризуется уникальным номеров и неуникальным наименованием.
Атрибут – характеристика категории. Атрибут характеризуется уникальным номером, неуникальным наименованием и типом (одним из 3-х: число, дата, строка). Каждая категория может обладать своим набором атрибутов из общего списка. Например, категория «Предприятие» может иметь атрибут с номером 1 «Наименование», предназначенный в данной категории для хранения наименования предприятия, а категория «Сотрудник» может иметь тот же атрибут номер 1 «Наименование» для хранения ФИО сотрудника.
Связь – отношение между категориями. Связь всегда направленная имеет отношение сверху вниз «один-ко-многим» (1:М), а снизу вверх «один-к-одному» (1:1). То есть, если установить связь сверху вниз между предприятием и подразделением предприятия, то к одному предприятию может быть привязано несколько отделов, а одел может быть привязан только к одному предприятию.
Небольшое лирическое отступление
Кстати, много видел в различных публикациях, посвященным типам БД, что недостатком иерархических БД является невозможность обеспечения отношения М:М («многие-ко-многим»). Для этого и были придуманы расширения иерархических БД (сетевая, графовая). Это полная ерунда. Отношение М:М между двумя сущностями легко реализуется через нижний узел (абcтрактную сущность). Приведу небольшой пример. Пусть у нас есть некий холдинг, состоящий из 3-х предприятий и некий набор контрагентов наших предприятий, причем, контрагенты могут вести дела с несколькими нашими предприятиями, как и предприятия могут вести дела с несколькими контрагентами. То есть, классическое отношение М:М. Вот как это реализуется с использованием абстрактной категории связи:

Здесь без нарушения 1:1 для связи снизу вверх реализуется связь М:М. Так Предприятие 1 имеет 2х контрагентов 1 и 2, предприятие 2 имеет 2х контрагентов 1 и 3, а Предприятие 3 имеет 1 контрагента 3. В свою очередь Контрагент 1 работает с предприятиями 1 и 2, Контрагент 2 работает только с предприятием 2, а Контрагент 3 работает с Предприятиями 2 и 3.
Объект – конкретный экземпляр категории, который может иметь (или не иметь) конкретные значения атрибутов (установленных для категории) и обладать (или не обладать) связями с объектами других категорий (если между категориями установлена связь). Объект характеризуется номером категории и уникальным по всей ИС номером объекта.
Немного об языках программирования
Для реализации модели данных в процедурный язык (APL) введен тип данных COV (category, object, value) (категория, объект, значение). Значение данного типа содержит номер категории и номер объекта, а также может содержать значение одного из атрибутов объекта. Параметр типа COV имеет форму записи [N_CAT N_OBJ].VALUE. Например: [1 12345].ИП Иванов (объект номер 12345 по категории 1 со значением «ИП Иванов». Естественно, процедурный язык содержит полный набор функций по работе с данными типа COV.
Соответственно, в язык запросов (AQL), который имеет значительное сходство с SQL введены лексемы для «навигации» по дереву объектов: «:N_CAT» (спуститься вниз по дереву объектов на категорию с номером N_CAT), «^N_CAT» (подняться вверх по дереву объектов на категорию с номером N_CAT) и «.N_ATR» (получить значение атрибута c номером N_ATR для объекта). Спуститься вниз по дереву объектов означает получить список объектов указанной категории, привязанных снизу к объекту, полученному в результате предыдущего перехода. Естественно, язык запросов имеет фильтры по значению атрибута: WHERE(#.N_CAT [=][!=][>][<][=>][<=] VALUE), а также полный набор RANGE_VAL, FLOOR_VAL, CEIL_VAL, MAX_VAL, MIN_VAL и т.д.
Например, имеется такая структура данных: категория номер 1 «Предприятие» с одним атрибутом номер 1 «Наименование», категория 2 «Подразделение» с одним атрибутом номер 1 «Наименование», категория 3 «Сотрудник» с 2-мя атрибутами: 2 «Табельный номер» и 3 «ФИО». Между категориями установлены связи сверху вниз от Предприятия к Подразделению и от Подразделения к Сотруднику.

В рамках это структуры есть объекты: Объект номер 1 по категории номер 1 со значением атрибута 1, равным «Рога и копыта», … объект номер 8 по категории номер 3 с атрибутом 2=«ТО2» и атрибутом 3=«Козлевич».

Тогда AQL-запрос для получения списка подразделений предприятия «Рога и копыта» будет выглядеть:
[1 1] :2.1
От объекта номер 1 по категории 1 ([1 1]) спускаемся вниз на категорию с номером 2 (:2) и запрашиваем для каждого объекта, получившегося в результате предыдущего перехода списка атрибут номер 1 (.1). В результате получим такой список:
{[2 2].Администрация, [2 3]. Отдел работы с клиентами, [2 4].Транспортный отдел}
Для получения списка всех сотрудников предприятия «Рога и копыта» запрос будет выглядеть:
[1 1] :2:3.3
От объекта [1 1] спускаемся вниз на категорию с 2 (Подразделение), далее спускаемся на категорию 3 (Сотрудник) и запрашиваем атрибут 3 (ФИО). В результате получим полный список сотрудников предприятия:
Аналогично, для получения наименования подразделения, в котором работает сотрудник Козлевич, запрос будет выглядеть:
[3 8] ^2.1
От объекта [3 8] поднимаемся вверх на категорию с 2 (Подразделение) и запрашиваем атрибут 1 (ФИО). В результате получим полный список сотрудников предприятия:
Еще один небольшой пример для иллюстрации фильтров. Если номер объекта сотрудника Козлевича неизвестен, то необходимо получить это объект по ФИО:
[3 *] where(#.3=”Козлевич”)^2.1
Из списка всех объектов по категории 3 ([3 8]) выбираем объект, у которого атрибут 3 равен «Козлевич» (where(#.3=”Козлевич”)). Далее как и в предыдущем примере.
Последнее, что надо знать об языке запросов это то, что есть два вида запросов: простой, возвращающий список (как в предыдущих примерах), и «многоколончатый», возвращающий таблицу. Его синтаксис такой:
select
# (колонка 1),
…
# (колонка n)
from вершина запроса и переходы
Вершина запроса и переходы формируют строки таблицы, а колонки, которые также могут включать различные переходы, формируют столбцы таблицы
Например, для вывода не только ФИО сотрудника, но и табельного номера:
select
#.2,
#.3
from [1 1]:2:3
То есть: от объекта [1 1] “спускаемся вниз” на категорию 2, затем “спускаемся вниз” на категорию 3, а затем для каждого объекта (сотрудника) из полученного списка в первую колонку выводим значение атрибута 2 (Табельный номер), а во вторую значение атрибута 3 (ФИО). А если нам необходимо вывести еще и подразделение, в котором работает сотрудник, то можно написать так:
select
#^2.1,
#.2,
#.3
from [1 1]:2:3
То есть, в первой колонке таблицы для каждого сотрудника “поднимаемся вверх” на категорию 2 (подразделение) и получаем для этой категории значение атрибута 1 (Наименование).
И так, чтобы уж сразу напугать, приведу пример из реальной системы. Так выглядит запрос, который возвращает список сотрудников с данными табеля за месяц, начислениями, удержаниями, долгами за предыдущие месяцы и результатом к выдаче:
select
#.2,
#.7,
#.187,
#:2015 range2_val(#.1,#.52,%CP).25,
#:2015 range2_val(#.1,#.52,%CP)^205.184,
#:2016 where(#^100=%CP).13,
#:2016 where(#^100=%CP):2023 where(#.2=1) sum(#.na),
#:2016 where(#^100=%CP):2023 where(#.2>1) sum(#.na),
#:2016 where(#^100=%CP):2024 where(#.2=1) sum(#.na),
#:2016 where(#^100=%CP):2024 where(#.2=2) sum(#.na),
#:2016 where(#^100.1<%CP):2023 sum(#.na),
#:2016 where(#^100.1<%CP):2024 sum(#.na),
#:2025 where(#.18=3 and #.1<%CP and #^1304^1306.18=1) sum(#.na),
#:2026 where(#.18=3 and #.1<%CP and #^1304^1306.18=1) sum(#.na),
#:2025 where(#.18=3 and #^1304^1306.18=1) range_val(#.1,%CP,d2) sum(#.na),
#:2026 where(#.18=3 and #^1304^1306.18=1) range_val(#.1,%CP,d2) sum(#.na),
#:2025 where(#.18=2) sum(#.na),
#:2026 where(#.18=2) sum(#.na),
#.12
from vc
returning
$1, $2, $19, $3, $4, $5, $6, $7, $8, nvl($7,0)+nvl($8,0), $9, $10, nvl($9,0)+nvl($10,0),
nvl($7,0)+nvl($8,0)-nvl($9,0)-nvl($10,0), nvl($11,0)-nvl($12,0)+nvl($14,0)-nvl($13,0),
nvl($15,0)-nvl($16,0), nvl($17,0)-nvl($18,0)
Практическая реализация
Клиент ИС имеет единый интерфейс для пользователя и разработчика. Отличие заключается только в том, что разработчик (пользователь с соответствующими правами) имеет несколько дополнительных пунктов меню и кнопок на панели инструментов клиента. Разработчик может также, как и обычный пользователь, работать в системе и в тоже время заниматься разработкой.
Инструмент разработки имеет также поддерживает совместную разработку. Разработчик может взять любую форму или процедуру на редактирование, изменить ее и отдать в использование. В это время до тех пор, пока форма или процедура не будет отдана в использование, все остальные пользователи будут работать со старым вариантом формы или процедуры.
Основными инструментами разработчика являются:
Администратор атрибутов – инструмент, предназначенный для добавления в ИС новых атрибутов;
Администратор категорий и связей – инструмент, предназначенный для добавления новых категорий, установки связей между категориями и добавление атрибутов в категорию;
Редактор процедур – инструмент для создания и редактирования процедур на языке APL;
Редактор форм – инструмент для редактирования интерфейса экранной формы.
Хочу обратить особое внимание на то, что разработчик не имеет доступа непосредственно к БД и не может изменять ее структуру. Он может работать только с уровнем категорий, связей и атрибутов.
Для примера создадим небольшую структуру категорий (далее УС – учетная схема) приложения. Задачей приложения будет организация взаимодействия предприятий холдинга с контрагентами и назначение для каждого контрагента куратора от предприятия холдинга. Причем куратор для контрагента назначается на определенный период, то есть существует дата начала и дата окончания действия куратора. УС приложения будет выглядеть следующим образом:

Обратите внимание, что категория 3 «Контрагент предприятия» не имеет атрибутов. Эта категория предназначена для обеспечения связи М:М между предприятиями и контрагентами. А категория 5 имеет два атрибута дата начала и дата окончания для задания временных рамок действия связи.
То есть, необходимо создать 6 атрибутов, 5 категорий и установить 5 связей между категориями.
Для начала обратимся к Администратору Атрибутов.

Добавляем атрибут номер 1 «Наименование» с типом «Строка». Шифр – необязательный параметр атрибута – может быть использован в AQL-запросе вместо номера. Формат также необязательный параметр.

Таким же образом добавляем остальные атрибуты.
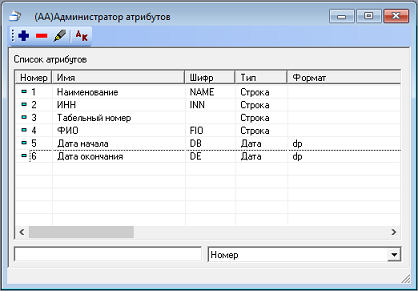
Теперь обратимся к Администратору Категорий и Связей (АКС).
")
Левое окно АКС содержит список категорий, правое верхнее отображает связи категорий, правое нижнее отображает атрибуты категории.
Добавим категорий номер 1 «Предприятие». Параметр шифр является необязательным и может быть использован в AQL-запросах.

Добавим в категорию 1 атрибуты 1 и 2. Для атрибута 1 «Наименование» установим свойство «Обязательный». То есть, без ввода наименования предприятия мы не сможем создать новое предприятие.

Создадим все категории с их атрибутами.

И, наконец, установим связи между категориями.

Таким образом, вся процедура создания УС такого приложения занимает 5 минут.
Теперь перейдем к созданию экранных форм. В общем случае для каждой значимой категории необходимы 2 формы: список и форма добавления объекта категории.
Сделаем такие формы для категории 1 «Предприятие». Первая форма со списком предприятий в редакторе форм выглядит так:

Форма содержит таблицу с двумя столбцами и скрытый экранный элемент (мы называем его «Контрол») SELECT (за границами видимой части окна) типа «Вычисляемое поле», который предназначен для выполнения формулы. В данном случае формула этого контрола выполняет AQL-запрос для вывода списка предприятий и заполняет результатом запроса таблицу:

Функция aql выполняет запрос: выбирает все объекты категории 1 (from [1*]) и для каждого объекта выводит значения атрибута 1 в первый столбец и 2 во второй столбец.
Вторая форма для ввода предприятия в редакторе форм выглядит совсем просто:

Форма содержит два вводимых контрола, связанных с соответствующими атрибутами категории.
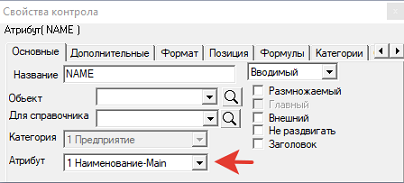
Здесь не требуется написания ни строчки кода. Достаточно в свойствах контрола установить параметр «Вводимый» и установить атрибут для данного контрола (см. стрелку).
Теперь мы можем добавлять предприятия в список.
Таким образом, на разработку такого приложения понадобиться не более часа.
Конечно, в приложении есть документы чуть посложнее. Например, форма отображения контрагента с кураторами, действующими на текущую дату, по разным предприятиям.

А так выглядит эта форма в Редакторе форм:

Здесь таблица действующих кураторов заполняется таким запросом:
DECLARE
dt as DATE
{
dt := cur_date();
%TABLE := aql(select
#^4^1.1,
#^4.4
from %NAME:5 range2_val(#.5,#.6,dt));
}
Переменной dt присваивается значение текущей даты, затем в запросе от объекта контрагента, который получаем из контрола NAME, «опускаемся вниз на категорию 5 «Куратор контрагента» (см. УС), выбираем только те объекты, у которых текущая дата лежит в диапазоне даты начала и даты окончания (range2_val(#.5,#.6,dt)) и для каждого полученного объекта в первом столбце «поднимаемся вверх» на категорию 4 «Сотрудник» и далее на категорию 1 «Предприятие» и выводим значение атрибут 1 «Наименование», а во втором столбце «поднимемся вверх» на категорию 4 «Сотрудник» и выводим атрибут 4 «ФИО».
Такое описание разработки приложения я привожу лишь для того, чтобы подчеркнуть, что разработчику не требуется доступа к БД и ему не требуется создавать таблицы, представления, индексы, констрейнты, триггеры и т.д. и т.п.
Я показал, как устроен паровоз, а в следующей части я покажу, почему он ездит без лошади, то есть покажу как устроена структура БД, обеспечивающая такую иерархическую структуру данных приложения.
Комментарии (21)

maximw
03.11.2023 08:11Какие преимущества по сравнению с обычными RDBMS и использованием нормального SQL? Я так понимаю все равно под капотом там реляцоинная БД?
В чем смысл атрибуты нумеровать, а не использовать строки как идентификаторы, хотя бы для улучшения читабельности?

torus1st Автор
03.11.2023 08:11Да. Под капотом там действительно RDBMS Oracle 11g. И, естественно, это не графовая БД. ИБД это заголовок статьи, а по сути это иерархическая модель данных, реализованная на RDBMS. Внутренний язык запросов и отражает эту сущность. Во второй части, которую я выложу на днях, я и показываю, насколько легче пользоваться AQL по сравнению с SQL. То что на AQL пишется в 3 строчки, на SQL потребует 30. И разрабатывалась такая структура для существенного снижения требования к разработчикам. Разработчику вообще не требуется быть специалистом в БД и SQL.

nin-jin
03.11.2023 08:11Так почему было не взять графовую субд и получить те же самые запросы в 3 строчки?
torus1st Автор
03.11.2023 08:11Когда эта система разрабатывалась (1994-2001) графовых баз и в помине не было. А потом эта система для разработки ERP. Она "одноклассник" SAP R/3, Microsoft Dynamics AX, Oracle Application. Есть хотя бы одна ERP на графовой базе?

Akina
03.11.2023 08:11+1Прочитал всё... но так и не понял, что вообще заставило использовать подход иерархической БД (ИБД), когда снизу - реляционная СУБД, на которой ИБД реализуется легко и непринуждённо, считай нативно, достаточно всего лишь некоторого самоограничения. Ну и терминология - что бы не использовать стандартную и уже устоявшуюся?
Отношение М:М между двумя сущностями легко реализуется через нижний узел (абcтрактную сущность).
Ну то есть просто превращаем иерархическую БД в реляционную, что ли? Ну или не превращаем, да, маловато будет, но используем технологию из реляционной БД. Просто с точки зрения иерархической БД такая промежуточная сущность безусловно является самостоятельной сущностью, возможно, не имеющей атрибутов, тогда как в реляционной БД считать такую промежуточную таблицу сущностью никто не заставляет (хотя и не запрещает - и порой считают). Но это всего лишь вопрос терминологии. Или глубины анализа предметной области.
nin-jin
03.11.2023 08:11-2реляционная СУБД, на которой ИБД реализуется легко и непринуждённо, считай нативно, достаточно всего лишь некоторого самоограничения
Это как?
Akina
03.11.2023 08:11+1А что есть такого в ИБД, что отсутствует в РСУБД? Я что-то навскидку и не нахожу... а, значит, ИБД - это РСУБД с дополнительными ограничениями.
nin-jin
03.11.2023 08:11Упорядоченность, например. Или прямые ссылки между узлами, позволяющие выбирать поддеревья без лукапа.
Akina
03.11.2023 08:11-1Упорядоченность
А теперь точно и подробно, что именно имеется в виду. Хранимая таблица - это несортированная и неупорядоченная куча, причём так дело обстоит в обеих СБД. Что именно упорядочено? где? как?
прямые ссылки между узлами, позволяющие выбирать поддеревья без лукапа
Да ладно! Вот так прям в каждой записи каждой таблицы и лежит полный путь текущей записи, перечисляющий узлы во всех таблицах аж до самого корня дерева связей? Вот что-то не верится.
nin-jin
03.11.2023 08:11Речь про иерархические субд, а не про идб поверх рсубд. Там нет никаких таблиц, а каждая запись хранит список ссылок на дочерние.

vagon333
03.11.2023 08:11-1Сложно понять в деталях. Задам вопросы.
В вашем инструменте, каким образом реализован:
1. DDL - модификация схемы бд, согласно метаданным (в окошках скриншотов)?
2. UI - виндовый / веб?
3. Сервисы (фоново-работающие процессы)?
4. Логика валидации данных на UI?
5. Логика валидации данных SQL?
6. Есть ли возможность создавать микросервисы из вашей универсальной среды, или это исключительно описание модели предприятия?
7. Версионирование всех ваших метаданных
8. Перенос изменений из среды разработки в среды тестирования, прод и DR?torus1st Автор
03.11.2023 08:11Во вторник-среду выложу вторую часть. Там на большинство вопросов будут ответы.
Модификации схемы БД не требуется. Разработчик ее вообще не видит.
UI - виндовый.
Валидация данных происходит на сервере приложений (в самом начале написано, система трехзвенная СУБД - сервер приложений (Windows или Linus) - тонкий клиент под Windows).
Система поддержания версионности и совместной разработки встроенная. Разработчик "берет на редактирование" процедуру или экранную форму, изменяет и "отдает в использование". Пока не "отдал", для всех пользователей "видна" старая версия. Версии можно откатить.
Отдельных сред разработки и тестирования нет. Есть единая система, в которой пользователь с правами разработчика может для любой экранной формы вызвать редактор, "забрать форму на редактирование", изменить, работать с ней, тестировать и т.д.. И после "отдачи" она становиться "видимой" для всех.
И главное - система разрабатывалась где-то с 1994 года. Практически законченный вид она приобрела в 2000-2001. Тогда еще "устоявшейся" терминологии не было. Ни GIT, ни SVN, ни Postgres, ничего этого еще не было. Даже SQL сервер и близко не мог того, что мог Oracle.
vagon333
03.11.2023 08:11+1Зашел прояснить свои вопросы, увидел "минус" на свой предыдущий коммент и решил что "нунафиг". Лучше буду только читать. :)

hVostt
03.11.2023 08:11+1Было бы здорово провести исследование, почему подобные мышко-прикладные системы, где разработчик по сути и не разработчик, а интегратор, не поглотили всю индустрию целиком. Абстракции над БД, создающие свой специфический язык к данным, высокоуровневые бизнес-концепции "сущность", "связь", "подчинённость", не наблюдаю пока повального погребения устаревшего SQL, и построения систем на низкоуровневых фреймворках. Как думаете, с чем это связано, не логично же?

HADGEHOGs
03.11.2023 08:11Потому что, если мы посмотрим на текст запросов то мы увидим, что там - ебанина.
avf48
Идея хорошая, но, судя по "примерам", матчасть нужно подтянуть)))
матчасть