
 Привет, Хаброжители!
Привет, Хаброжители!Инструменты оценки производительности на основе BPF дают беспрецедентную возможность анализа систем и приложений. Вы сможете улучшить производительность, устранить проблемы в коде, повысить безопасность и сократить расходы. Книга «BPF: профессиональная оценка производительности» — ваш незаменимый гайд по применению этих инструментов.
Брендан Грегг — эксперт и пионер проекта BPF — представляет более 150 готовых инструментов анализа и отладки, рекомендации по их применению, а также пошаговые инструкции по разработке ваших собственных инструментов. Вы узнаете, как анализировать процессоры, память, дисковый ввод/вывод, файловую систему, сети, языки программирования, приложения, контейнеры, гипервизоры, безопасность и ядро. Вы сможете выработать глубокое понимание того, как улучшить буквально любую Linux-систему или приложение.
Для кого эта книга
Книга адресована широкому кругу читателей. Для применения инструментов BPF, о которых я рассказываю, вам не потребуется писать программы: вы можете использовать книгу как сборник рецептов с уже готовыми инструментами. Если вы решите создавать свои инструменты, то приведенные примеры исходного кода и глава 5 помогут быстро научиться этому.
Наличие опыта в сфере анализа производительности также не требуется; каждая глава кратко излагает все необходимое.
В частности, книга адресована:
Проще говоря, эта книга фокусируется на использовании инструментов BPF и предполагает минимальный уровень знаний, включая знание сетей (например, что такое адрес IPv4) и владение командной строкой.
Наличие опыта в сфере анализа производительности также не требуется; каждая глава кратко излагает все необходимое.
В частности, книга адресована:
- Системным администраторам, SRE-инженерам, администраторам баз данных, перформанс-инженерам и сотрудникам служб поддержки, отвечающим за эксплуатацию систем. Они могут использовать ее как справочник по диагностике проблем производительности, анализу использования ресурсов и устранению неполадок.
- Разработчикам приложений, которые могут использовать описанные здесь инструменты для анализа собственного кода и его исследования в комплексе с системными событиями. Например, события дискового ввода/вывода можно исследовать в совокупности с кодом приложения, вызвавшим их. Это позволит получить более полное представление о поведении, чем это делается с помощью типичных прикладных инструментов, не имеющих прямого доступа к событиям ядра.
- Инженерам по безопасности, которые могут узнать, как отслеживать все события, обнаруживать подозрительное поведение и создавать белые списки типичной активности (см. главу 11).
- Разработчикам средств мониторинга производительности, которые могут почерпнуть идеи по добавлению новых возможностей в свои продукты.
- Разработчикам ядра, которые могут научиться писать однострочные инструменты для bpftrace с целью отладки собственного кода.
- Студентам, изучающим операционные системы и приложения, которые могут использовать инструменты BPF для исследования действующих систем новыми и нестандартными способами. Вместо изучения абстрактных технологий ядра на бумаге студенты могут воочию увидеть, как они работают.
Проще говоря, эта книга фокусируется на использовании инструментов BPF и предполагает минимальный уровень знаний, включая знание сетей (например, что такое адрес IPv4) и владение командной строкой.
КОНТЕЙНЕРЫ
Контейнеры стали широко используемым методом развертывания сервисов в Linux, предлагая безопасную изоляцию, быстрый запуск приложений, управление ресурсами и простоту развертывания. В этой главе я расскажу, как использовать инструменты BPF в контейнерных средах, а также покажу, чем отличаются инструменты и методы анализа для контейнеров.
Цели обучения:
- познакомиться с устройством контейнеров и целями для трассировки в них;
- понять сложности, связанные с привилегиями, идентификаторами контейнеров и FaaS;
- количественно оценивать совместное использование процессора контейнерами;
- измерять ограничение ввода/вывода в группе cgroup blk;
- измерять производительность файловой системы OverlayFS.
Эта глава начинается с описания основ, необходимых для анализа контейнеров, потом знакомит с возможностями BPF и, наконец, переходит к представлению различных инструментов BPF и однострочных сценариев.
Базовые сведения и инструменты для анализа производительности приложений в контейнерах были приведены в предыдущих главах: процессоры в контейнерах так и остаются процессорами, файловые системы — файловыми системами, а диски — дисками. Основное внимание в этой главе уделяется характерным особенностям контейнеров: пространствам имен и контрольным группам (cgroups).
15.1. ОСНОВЫ
Контейнеры позволяют запустить сразу несколько экземпляров ОС на одном компьютере. Есть два основных способа реализации контейнеров:
- Виртуализация ОС: предполагает разделение системы с использованием пространств имен в Linux и обычно комбинируется с контрольными группами для управления ресурсами. Все контейнеры используют одно общее ядро. Этот подход применяется в Docker, Kubernetes и других контейнерных средах.
- Виртуализация оборудования: предполагает запуск облегченных виртуальных машин, каждая из которых имеет свое ядро. Этот подход применяется в Intel Clear Containers (сейчас Kata Containers [165]) и AWS Firecracker [166].
Некоторые идеи по анализу контейнеров при использовании виртуализации оборудования представлены в главе 16. А в этой главе рассмотрим контейнеры, реализованные с помощью виртуализации ОС.
На рис. 15.1 показана типичная реализация контейнера в Linux.
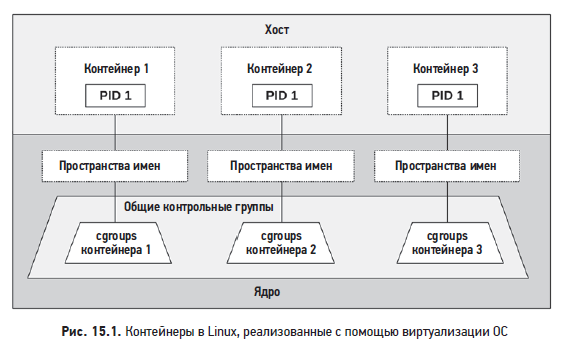
Пространство имен ограничивает видимую часть системы. Пространства имен: cgroup, ipc, mnt, net, pid, user и uts. Пространство имен pid ограничивает видимость процессов в /proc только собственными процессами контейнера. Пространство имен mnt ограничивает видимость смонтированных файловых систем. Пространство имен uts ограничивает детали, возвращаемые системным вызовом uname(2), и т. д.
Контрольная группа ограничивает доступность ресурсов. В ядре Linux есть две версии контрольных групп: v1 и v2. Многие проекты, например Kubernetes, продолжают использовать v1. В контрольные группы версии v1 входят: blkio, cpu, cpuacct, cpuset, devices, hugetlb, memory, net_cls, net_prio, pids и rmda. Они поддерживают возможность настройки для ограничения конфликтов между контейнерами, например, при использовании ресурсов путем установки аппаратных ограничений на использование процессора и памяти или программных ограничений на совместное использование процессора и диска. Есть и иерархия контрольных групп, включая системные, которые совместно используются контейнерами, как показано на рис. 15.1.
Во второй версии (v2) контрольных групп устранены различные недостатки, имеющиеся в v1. Ожидается, что в ближайшие годы контейнерные технологии перейдут на версию v2, а версия v1 в конечном итоге устареет и будет удалена из ядра.
Типичная сложность анализа производительности контейнеров — это потенциальные «шумные соседи»: арендаторы контейнеров, которые активно потребляют ресурсы и вызывают конкуренцию за доступ к ним. Поскольку все контейнерные процессы выполняются под управлением одного ядра и могут анализироваться на уровне хоста, их анализ ничем не отличается от традиционного анализа производительности нескольких приложений, выполняющихся в одной системе разделения времени. Основное отличие заключается в использовании контрольных групп, накладывающих дополнительные программные ограничения на ресурсы, которые обычно меньше аппаратных ограничений. Инструменты мониторинга, которые не поддерживают контейнеры, могут не замечать этих программных ограничений и вызываемых ими проблем с производительностью.
15.1.1. Возможности BPF
Инструменты анализа контейнеров обычно основаны на метриках, показывающих, какие существуют контейнеры, контрольные группы и пространства имен, их настройки и размеры. Инструменты трассировки BPF могут дать гораздо больше деталей и ответить на вопросы:
- Как долго процессы в каждом контейнере находятся в очереди на выполнение?
- Использует ли планировщик один и тот же процессор, переключаясь между контейнерами?
- Достигнуто ли программное ограничение на использование процессора или диска?
Ответы на них можно получить с помощью BPF, инструментируя точки трассировки для событий планировщика и зонды kprobes для функций ядра. В предыдущих главах я говорил, что некоторые из этих событий (например, планирование) могут происходить очень часто и их трассировка — это удел специального анализа, а не непрерывного мониторинга.
Есть точки трассировки для событий контрольных групп, включая cgroup:cgroup_setup_root, cgroup:cgroup_attach_task и др. Это высокоуровневые события, которые помогают в отладке запуска контейнера.
Есть и возможность писать программы BPF с типом BPF_PROG_TYPE_CGROUP_SKB (не показаны в этой главе) для анализа сетевых пакетов и подключать их к контрольным группам на входе и на выходе.
15.1.2. Сложности
В подразделах ниже описаны некоторые сложности, свойственные трассировке контейнеров с использованием BPF.
Привилегии для BPF
На момент написания книги для выполнения трассировки с помощью BPF требуются привилегии root, и для большинства контейнерных сред это означает, что трассировка средствами BPF может выполняться только с хоста, но не из контейнеров. В будущем это требование должно быть ослаблено: обсуждается возможность непривилегированного доступа к BPF специально для решения проблемы с контейнерами. Об этом также шла речь в разделе 11.1.2.
Идентификаторы контейнеров
Управление идентификаторами контейнеров, которые используются в Kubernetes и Docker, осуществляется ПО, действующим в пространстве пользователя. Например (выделено жирным шрифтом):
# kubectl get pod
NAME READY STATUS RESTARTS AGE
kubernetes-b94cb9bff-kqvml 0/1 ContainerCreating 0 3m
[...]
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6280172ea7b9 ubuntu "bash" 4 weeks ago Up 4 weeks eager_bhaskara
[...]Контейнер представлен в ядре набором контрольных групп и пространств имен, но в пространстве ядра нет идентификатора, связывающего их воедино. В свое время предлагалось добавить идентификатор контейнера в ядро [168], но пока это не сделано.
Это может вызвать проблемы при запуске инструментов трассировки BPF на уровне хоста (как они обычно и запускаются: см. подраздел «Привилегии для BPF» в разделе 15.1.2). Выполняясь на уровне хоста, инструменты трассировки BPF перехватывают события из всех контейнеров, поэтому лучше иметь возможность оставлять только события, принадлежащие определенному контейнеру, или группировать их по контейнерам. Но в ядре нет идентификатора контейнера, который можно использовать для этого.
К счастью, есть ряд обходных решений, каждое из которых зависит от конкретной конфигурации исследуемых контейнеров. Контейнеры используют некоторую комбинацию пространств имен. Детали этой комбинации можно прочитать из структуры nsproxy в ядре. Вот определение этой структуры в linux/nsproxy.h:
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct cgroup_namespace *cgroup_ns;
};Контейнеры почти всегда используют пространство имен PID, которое позволяет различать их. Вот пример получения пространства имен для текущей задачи из bpftrace:
#include <linux/sched.h>
[...]
$task = (struct task_struct *)curtask;
$pidns = $task->nsproxy->pid_ns_for_children->ns.inum;Этот код записывает в $pidns идентификатор (целое число) пространства имен PID, который можно вывести или использовать для фильтрации. Он будет соответствовать идентификатору пространства имен PID, указанному в символической ссылке /proc/PID/ns/pid_for_children.
Если среда выполнения контейнера использует пространство имен UTS и в качестве имени узла берет имя контейнера (как это часто бывает в Kubernetes и Docker), то это имя тоже можно использовать в программах BPF для идентификации контейнеров. Вот пример с применением синтаксиса bpftrace:
#include <linux/sched.h>
[...]
$task = (struct task_struct *)curtask;
$nodename = $task->nsproxy->uts_ns->name.nodename;Именно так реализован инструмент pidnss(8) (см. раздел 15.3.2).
При анализе подов Kubernets идентификатором будет сетевое пространство имен, поскольку контейнеры в поде почти всегда используют одно и то же сетевое пространство имен.
Эти идентификаторы, включая идентификатор пространства имен PID или строку с именем узла UTS вместе с PID, можно добавить в инструменты из предыдущих глав и тем самым сделать их совместимыми с контейнерами. Обратите внимание, что это возможно, только если точка инструментации находится в контексте процесса, когда есть действительная структура curtask.
Оркестрация
Запуск инструментов BPF на нескольких хостах с контейнерами — это проблема, похожая на развертывание облака на нескольких виртуальных машинах. В вашей компании уже может быть нужное ПО оркестрации, которое умеет запускать заданную команду на нескольких хостах и собирать выходные данные. Есть и специализированные решения, в том числе kubectl-trace.
kubectl-trace — это планировщик Kubernetes для запуска программ bpftrace в кластере Kubernetes. Он предоставляет переменную $container_pid для использования в программах bpftrace, содержащую идентификатор pid корневого процесса. Например, следующая команда:
kubectl trace run -e 'k:vfs* /pid == $container_pid/ { @[probe] = count() }' mypod –aсчитает вызовы функции ядра vfs*() из приложения в контейнере mypod, пока вы не нажмете Ctrl-C. Программы могут быть однострочными сценариями, как в этом примере, или извлекаться из файлов с помощью параметра -f [169]. Более подробно kubectl-trace рассмотрен в главе 17.
Function as a Service (FaaS)
Новая модель вычислений предполагает определение прикладных функций, которые выполняются провайдером, возможно, в контейнерах. Конечный пользователь определяет только функции и может не иметь SSH-доступа к системе, в которой эти функции выполняются. Ожидается, что такая среда не будет поддерживать конечных пользователей, использующих инструменты трассировки BPF. (Она также не сможет запускать другие инструменты.) Когда ядро будет поддерживать непривилегированную трассировку BPF, прикладная функция сможет напрямую выполнять вызовы BPF, но это создаст множество проблем. Анализ FaaS с использованием BPF, вероятно, будет возможен только на уровне хоста и только пользователями или интерфейсами, имеющими доступ к хосту.
15.1.3. Стратегия
Если вы еще только осваиваете анализ контейнеров, то, вероятно, не знаете, с чего начать — с какой цели и с какого инструмента. Я приведу общую стратегию для старта. Упомянутые здесь инструменты подробно рассмотрены в последующих разделах.
1. Исследуйте систему и выясните нехватку ресурсов и другие проблемы, рассмотренные в предыдущих главах (6, 7 и т. д.). В частности, создайте флейм-графики потребления процессора для работающих приложений.
2. Проверьте, не было ли достигнуто ограничение, накладываемое контрольной группой.
3. Подберите и запустите инструменты BPF, перечисленные в главах с 6-й по 14-ю.
Большинство встречавшихся мне сложностей с контейнерами были обусловлены проблемами в приложениях или в оборудовании, но не конфигурацией контейнера. Флейм-графики потребления процессора часто помогают выявить проблемы в приложениях, которые никак не связаны с выполнением внутри контейнеров. Обязательно проверьте такие проблемы и исследуйте ограничения контейнера.
15.2. ТРАДИЦИОННЫЕ ИНСТРУМЕНТЫ
Работу контейнеров можно анализировать с помощью многих инструментов оценки производительности из предыдущих глав. В этом разделе обобщаются особенности анализа контейнеров традиционными инструментами как на уровне хоста, так и внутри контейнеров.
15.2.1. Анализ на уровне хоста
Для анализа поведения контейнера, особенно использования контрольных групп, можно брать инструменты и метрики, доступные на уровне хоста и перечисленные в табл. 15.1.
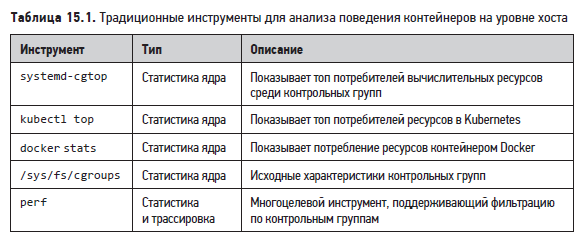
В разделах ниже дано общее описание основных возможностей этих инструментов.
15.2.2. Анализ на уровне контейнера
Традиционные инструменты также можно применять на уровне отдельных контейнеров, но при этом важно помнить, что значения некоторых характеристик будут относиться ко всему хосту, а не только к контейнеру. В табл. 15.2 перечислены некоторые часто используемые инструменты и их описание, действительное для ядра Linux 4.8.

Обратите внимание, что под термином совместимые с контейнерами подразумеваются инструменты, которые при использовании внутри контейнера отображают только процессы и ресурсы контейнера. Ни один из инструментов этой таблицы не является полностью совместимым с контейнерами. По мере развития ядра и инструментов ситуация может измениться, но пока сложность анализа производительности в контейнерах остается.
15.2.3. systemd-cgtop
Команда systemd-cgtop(1) выводит самые ресурсоемкие контрольные группы. Вот пример, полученный на промышленном хосте с контейнерами:
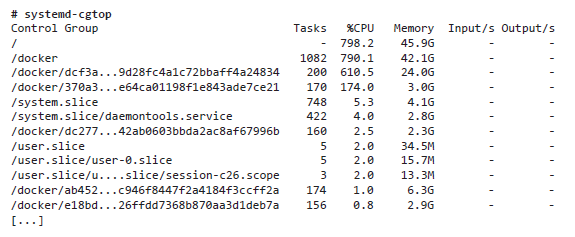
Мы видим, что в течение интервала обновления контрольная группа «/docker/dcf3a...» потребила 610.5% процессорного времени (на нескольких процессорах) и 24 Гбайт оперативной памяти на выполнение 200 задач. В выводе видны и контрольные группы, созданные демоном systemd для сервисов (/system.slice) и пользовательских сеансов (/user.slice).
15.2.4. kubectl top
Kubernetes предлагает команду kubectl top для проверки использования основных ресурсов. Вот пример проверки хостов (узлов, «nodes»):
# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
bgregg-i-03cb3a7e46298b38e 1781m 10% 2880Mi 9%В столбце «CPU(cores)» отображается накопленное процессорное время в миллисекундах, а в столбце «CPU%» — текущее потребление процессора узлом. А вот пример проверки контейнеров (подов, «pods»):
# kubectl top pods
NAME CPU(cores) MEMORY(bytes)
kubernetes-b94cb9bff-p7jsp 73m 9MiЗдесь отображается накопленное процессорное время и текущий объем занятой памяти.
Для правильной работы этих команд должен быть запущен сервер метрик, что может происходить по умолчанию, в зависимости от того, как был инициализирован Kubernetes [170]. Есть и другие инструменты мониторинга, отображающие эти метрики в графическом интерфейсе: cAdvisor, Sysdig и Google Cloud Monitoring [171].
15.2.5. docker stats
Docker предлагает несколько подкоманд команды docker(1) для анализа, включая stats. Вот пример с промышленного хоста:

Здесь видно, что за интервал обновления контейнер с UUID «353426a09db1» потребил в общей сложности 527% процессорного времени и использовал 4 Гбайт оперативной памяти из доступных 8.5 Гбайт. В течение этого интервала сетевой ввод/вывод отсутствовал и был небольшой объем (несколько мегабайт) дискового ввода/вывода.
15.2.6. /sys/fs/cgroups
Этот каталог содержит виртуальные файлы со статистиками контрольных групп. Они используются и отображаются в виде графиков различными продуктами для мониторинга контейнеров. Например:
# cd /sys/fs/cgroup/cpu,cpuacct/docker/02a7cf65f82e3f3e75283944caa4462e82f...
# cat cpuacct.usage
1615816262506
# cat cpu.stat
nr_periods 507
nr_throttled 74
throttled_time 3816445175Файл cpuacct.usage содержит общее процессорное время в наносекундах, использованное этой контрольной группой. Файл cpu.stat сообщает, сколько раз потребление процессора этой контрольной группой подвергалось ограничению (nr_throttled), а также общее время ограничения в наносекундах. Здесь видно, что потребление процессора этой контрольной группой ограничивалось 74 раза в течение 507 периодов, и в общей сложности из-за ограничений группа недополучила 3.8 секунды.
Есть и файл cpuacct.usage_percpu, показывающий время, затраченное контрольной группой Kubernetes на каждом процессоре:
# cd /sys/fs/cgroup/cpu,cpuacct/kubepods/burstable/pod82e745...
# cat cpuacct.usage_percpu
37944772821 35729154566 35996200949 36443793055 36517861942 36156377488 36176348313
35874604278 37378190414 35464528409 35291309575 35829280628 36105557113 36538524246
36077297144 35976388595Для этой системы с 16 процессорами вывод содержит 16 полей с общим временем, потраченным этой контрольной группой на каждом процессоре.
Метрики контрольных групп версии v1 задокументированы в исходном коде ядра, в файле Documentation/cgroup-v1/cpuacct.txt [172].
15.2.7. perf
Инструмент perf(1) из главы 6 можно использовать на уровне хоста и фильтровать данные по контрольным группам с применением параметра --cgroup (-G). С помощью подкоманды perf record можно профилировать потребление процессора:
perf record -F 99 -e cpu-clock --cgroup=docker/1d567... -a -- sleep 30Событием может быть все, что происходит в контексте процесса, включая системные вызовы.
Этот параметр доступен и в подкоманде perf stat. Он позволяет подсчитывать количество событий вместо их записи в файл perf.data. Вот пример подсчета обращений к системным вызовам из семейства read и использования другого формата определения контрольных групп (с опущенными идентификаторами):
perf stat -e syscalls:sys_enter_read* --cgroup /containers.slice/5aad.../...Можно указать несколько контрольных групп.
perf(1) может трассировать те же события, что и BPF, но не предлагает возможности программирования, которые поддерживают BCC и bpftrace. В действительности perf(1) имеет свой интерфейс BPF: пример вы найдете в приложении D. На странице c примерами в [73] вы найдете другие варианты применения perf для анализа контейнеров.
15.3. ИНСТРУМЕНТЫ BPF
В этом разделе рассмотрены инструменты BPF, которые можно использовать для анализа работы контейнеров и устранения неполадок. Эти инструменты находятся в репозитории BCC или были созданы специально для этой книги. Они перечислены в табл. 15.3.
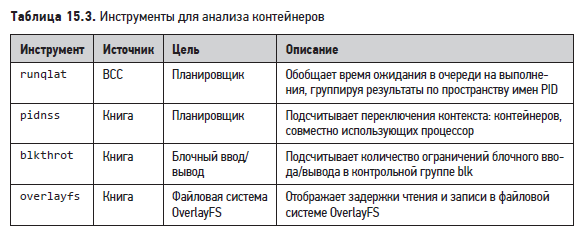
Для анализа контейнеров используйте их вместе с другими инструментами из предыдущих глав.
15.3.1. runqlat
runqlat(8) был представлен в главе 6: он показывает задержки в очереди на выполнение в виде гистограмм, помогая выявлять проблемы с насыщением CPU.
Поддерживает параметр --pidnss, при использовании которого показывает пространство имен PID. Вот пример из промышленной системы с контейнерами:
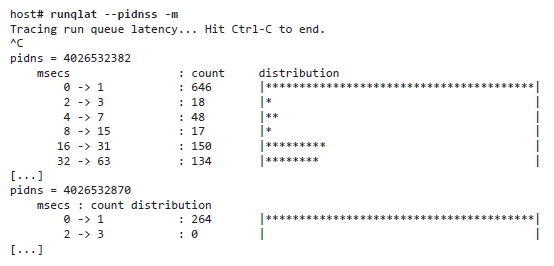
Мы видим, что одно из пространств имен PID (4026532382) страдает от значительно большей задержки в очереди на выполнение, чем другое.
Этот инструмент не сообщает имена контейнеров, потому что соответствие пространства имен контейнеру зависит от используемой контейнерной технологии. Для определения пространства имен, которому принадлежит конкретный процесс, можно использовать команду ls(1), запуская ее с привилегиями root. Например:
# ls -lh /proc/181/ns/pid
lrwxrwxrwx 1 root root 0 May 6 13:50 /proc/181/ns/pid -> 'pid:[4026531836]'Здесь видно, что процесс с идентификатором PID 181 принадлежит пространству имен PID 4026531836.
15.3.2. pidnss
pidnss(8) подсчитывает переключения контекста между контейнерами по смене пространства имен PID. Этот инструмент можно использовать, чтобы убедиться, нет ли проблемы конкуренции нескольких контейнеров за один процессор. Например:
# pidnss.bt
Attaching 3 probes...
Tracing PID namespace switches. Ctrl-C to end
^C
Victim PID namespace switch counts [PIDNS, nodename]:
@[0, ]: 2
@[4026532981, 6280172ea7b9]: 27
@[4026531836, bgregg-i-03cb3a7e46298b38e]: 28В каждой строке инструмент выводит два поля (идентификатор пространства имен PID и имя узла, если есть) и количество переключений. Как показывает этот вывод, за время трассировки пространство имен PID с именем узла «bgregg-i-03cb3a7e46298b38e» (хост) переключалось на другое пространство имен 28 раз, а другое пространство имен PID с именем узла «6280172ea7b9» (контейнер Docker) переключалось 27 раз. Эти данные можно подтвердить на уровне хоста:
# uname -n
bgregg-i-03cb3a7e46298b38e
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6280172ea7b9 ubuntu "bash" 4 weeks ago Up 4 weeks eager_bhaskara
[...]pidnss(8) трассирует переключение контекста с помощью kprobes. Ожидается, что в системах с большим объемом ввода/вывода он будет иметь значительный оверхед.
Вот еще один пример, полученный во время настройки кластера Kubernetes:
# pidnss.bt
Attaching 3 probes...
Tracing PID namespace switches. Ctrl-C to end
^C
Victim PID namespace switch counts [PIDNS, nodename]:
@[-268434577, cilium-operator-95ddbb5fc-gkspv]: 33
@[-268434291, cilium-etcd-g9wgxqsnjv]: 35
@[-268434650, coredns-fb8b8dccf-w7khw]: 35
@[-268434505, default-mem-demo]: 36
@[-268434723, coredns-fb8b8dccf-crrn9]: 36
@[-268434509, etcd-operator-797978964-7c2mc]: 38
@[-268434513, kubernetes-b94cb9bff-p7jsp]: 39
@[-268434810, bgregg-i-03cb3a7e46298b38e]: 203
[...]
@[-268434222, cilium-etcd-g9wgxqsnjv]: 597
@[-268434295, etcd-operator-797978964-7c2mc]: 1301
@[-268434808, bgregg-i-03cb3a7e46298b38e]: 1582
@[-268434297, cilium-operator-95ddbb5fc-gkspv]: 3961
@[0, ]: 8130
@[-268434836, bgregg-i-03cb3a7e46298b38e]: 8897
@[-268434846, bgregg-i-03cb3a7e46298b38e]: 15813
@[-268434581, coredns-fb8b8dccf-w7khw]: 39656
@[-268434654, coredns-fb8b8dccf-crrn9]: 40312
[...]Исходный код pidnss(8):
#!/usr/local/bin/bpftrace
#include <linux/sched.h>
#include <linux/nsproxy.h>
#include <linux/utsname.h>
#include <linux/pid_namespace.h>
BEGIN
{
printf("Tracing PID namespace switches. Ctrl-C to end\n");
}
kprobe:finish_task_switch
{
$prev = (struct task_struct *)arg0;
$curr = (struct task_struct *)curtask;
$prev_pidns = $prev->nsproxy->pid_ns_for_children->ns.inum;
$curr_pidns = $curr->nsproxy->pid_ns_for_children->ns.inum;
if ($prev_pidns != $curr_pidns) {
@[$prev_pidns, $prev->nsproxy->uts_ns->name.nodename] = count();
}
}
END
{
printf("\nVictim PID namespace switch counts [PIDNS, nodename]:\n");
}Этот код — пример извлечения идентификаторов пространств имен. Идентификаторы других пространств имен извлекаются похожим способом.
Если вам нужно получить подробности о конкретном контейнере, помимо пространства имен и контрольной группы, то этот инструмент можно перенести в BCC и реализовать в нем извлечение данных непосредственно из Kubernetes, Docker и т. д.
15.3.3. blkthrot
blkthrot(8) подсчитывает, сколько раз контрольная группа blk блочного ввода/вывода ограничивалась по достижении аппаратного предела. Например:
# blkthrot.bt
Attaching 3 probes...
Tracing block I/O throttles by cgroup. Ctrl-C to end
^C
@notthrottled[1]: 506
@throttled[1]: 31В ходе трассировки я увидел, что контрольная группа blk с ID 1 ограничивалась 31 раз и не ограничивалась 506 раз.
blkthrot(8) трассирует функцию ядра blk_throtl_bio(). Оверхед должен быть небольшим, потому что обычно события блочного ввода/вывода следуют с относительно невысокой частотой.
Исходный код blkthrot(8):
#!/usr/local/bin/bpftrace
#include <linux/cgroup-defs.h>
#include <linux/blk-cgroup.h>
BEGIN
{
printf("Tracing block I/O throttles by cgroup. Ctrl-C to end\n");
}
kprobe:blk_throtl_bio
{
@blkg[tid] = arg1;
}
kretprobe:blk_throtl_bio
/@blkg[tid]/
{
$blkg = (struct blkcg_gq *)@blkg[tid];
if (retval) {
@throttled[$blkg->blkcg->css.id] = count();
} else {
@notthrottled[$blkg->blkcg->css.id] = count();
}
delete(@blkg[tid]);
}Этот код — пример извлечения идентификаторов контрольных групп, он находится в структуре cgroup_subsys_state, в данном случае как css в blkcg.
То же самое можно реализовать иначе: проверять наличие флага BIO_THROTTLED в структуре bio после завершения блока.
15.3.4. overlayfs
overlayfs(8) трассирует задержки чтения и записи в OverlayFS. Подобные файловые системы широко используются в контейнерах, поэтому инструмент помогает получить представление о производительности файловой системы контейнера. Например:

Инструмент отображает распределение задержек чтения и записи. Как показывает вывод, в интервале от 21:21:06 до 21:21:06 задержки чтения обычно составляли от 16 до 64 микросекунд.
overlayfs(8) трассирует функции ядра из структуры file_operations_t в overlayfs. Оверхед зависит от частоты вызова этих функций и для большинства рабочих нагрузок должен быть незначительным.
Исходный код overlayfs (8):
#!/usr/local/bin/bpftrace
#include <linux/nsproxy.h>
#include <linux/pid_namespace.h>
kprobe:ovl_read_iter
/((struct task_struct *)curtask)->nsproxy->pid_ns_for_children->ns.inum == $1/
{
@read_start[tid] = nsecs;
}
kretprobe:ovl_read_iter
/((struct task_struct *)curtask)->nsproxy->pid_ns_for_children->ns.inum == $1/
{
$duration_us = (nsecs - @read_start[tid]) / 1000;
@read_latency_us = hist($duration_us);
delete(@read_start[tid]);
}
kprobe:ovl_write_iter
/((struct task_struct *)curtask)->nsproxy->pid_ns_for_children->ns.inum == $1/
{
@write_start[tid] = nsecs;
}
kretprobe:ovl_write_iter
/((struct task_struct *)curtask)->nsproxy->pid_ns_for_children->ns.inum == $1/
{
$duration_us = (nsecs - @write_start[tid]) / 1000;
@write_latency_us = hist($duration_us);
delete(@write_start[tid]);
}
interval:ms:1000
{
time("\n%H:%M:%S --------------------\n");
print(@write_latency_us);
print(@read_latency_us);
clear(@write_latency_us);
clear(@read_latency_us);
}
END
{
clear(@write_start);
clear(@read_start);
}Функции ovl_read_iter() и ovl_write_iter() были добавлены в Linux 4.19. Этот инструмент принимает аргумент с идентификатором пространства имен PID: он создавался для работы с Docker и запускался из следующего сценария командной оболочки (overlayfs.sh), который принимает аргумент с идентификатором контейнера Docker.
#!/bin/bash
PID=$(docker inspect -f='{{.State.Pid}}' $1)
NSID=$(stat /proc/$PID/ns/pid -c "%N" | cut -d[ -f2 | cut -d] -f1)
bpftrace ./overlayfs.bt $NSIDВы можете изменить его, чтобы привести в соответствие с используемой контейнерной технологией. Необходимость этого шага обсуждается в разделе 15.1.2: в ядре нет ID контейнера, он есть только в пространстве пользователя. Этот сценарий преобразует идентификатор контейнера в пространство имен PID, с которым может работать ядро.
15.4. ОДНОСТРОЧНЫЕ СЦЕНАРИИ ДЛЯ BPF
Здесь перечислены однострочные сценарии для bpftrace.
Подсчитывает идентификаторы контрольных групп с частотой 99 Гц:
bpftrace -e 'profile:hz:99 { @[cgroup] = count(); }'Трассирует имена открытых файлов для cgroup v2 с именем «container1»:
bpftrace -e 't:syscalls:sys_enter_openat
/cgroup == cgroupid("/sys/fs/cgroup/unified/container1")/ {
printf("%s\n", str(args->filename)); }'15.5. ДОПОЛНИТЕЛЬНЫЕ УПРАЖНЕНИЯ
Упражнения можно выполнить с помощью bpftrace или BCC, если явно не указано иное.
1. Измените runqlat(8) из главы 6 и добавьте вывод имени узла из пространства имен UTS (см. pidnss(8)).
2. Измените opensnoop(8) из главы 8 и добавьте вывод имени узла из пространства имен UTS.
3. Разработайте инструмент, показывающий, какие контейнеры вытесняются из оперативной памяти из-за ограничений в контрольной группе mem (см. функцию ядра mem_cgroup_swapout()).
15.6. ИТОГИ
В этой главе я рассмотрел контейнеры Linux и показал, как механизм трассировки BPF может выявлять конкуренцию между контейнерами за обладание процессором, регулирование доступности ресурсов контрольными группами, а также задержки в OverlayFS.
Об авторе
.
Брендан Грегг — старший перформанс-инженер в Netflix, основной контрибьютор проекта BPF (eBPF), помогавший разрабатывать и поддерживать оба интерфейса BPF. Впервые применил BPF для анализа производительности и создал десятки инструментов на основе BPF. Автор бестселлера «Systems Performance: Enterprise and the Cloud»
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — BPF