
Привет, хабр! Моя прошлая статья об устройстве памяти в Linux набрала большой отклик. Сегодня мы поговорим о процессах и потоках в операционной системе.
Начнем по порядку.
В обычных ОС процесс определяется соответствующим адресным пространством и одиночным управляющим потоком. Но часто встречаются ситуации, когда в одном адресном пространстве предпочтительно иметь несколько квазипараллельных управляющих процессов.
Модель процесса базируется на двух независимых концепциях: группировании ресурсов и выполнении программы. Когда их разделяют, появляется понятие потока.
С одной стороны, процесс можно рассматривать как способ объединения родственных ресурсов в одну группу. У процесса есть адресное пространство, содержащее программу, данные и другие ресурсы. Ресурсами являются открытые файлы, дочерние процессы, аварийные необработанные сообщения, обработчики сигналов, учетная информация и многое другое. Гораздо проще управлять ресурсами, объединив их в форме процесса.
С другой стороны, процесс можно рассматривать как поток исполняемых команд. У потока есть счетчик команд, отслеживающий порядок выполнения действий. У него есть регистры, в которых хранятся текущие переменные. У него есть стек, содержащий протокол выполнения процесса, где на каждую вызванную процедуру отведена отдельная структура. Хотя поток протекает внутри процесса, следует различать концепции потока и процесса. Процессы используются для группирования ресурсов, а потоки являются объектами, поочередно исполняющимися на ЦП.
Концепция потоков добавляет к модели процесса возможность одновременного выполнения в одной и той же среде процесса нескольких достаточно независимых программ. Несколько потоков, работающих параллельно в одном процессе, аналогичны нескольким процессам, идущим параллельно на одном компьютере. В первом случае потоки разделяют адресное пространство, открытые файлы и другие ресурсы. Во втором — процессы совместно пользуются физической памятью, дисками, принтерами и другими ресурсами. Потоки обладают некоторыми свойствами процессов, поэтому их иногда называют упрощенными процессами. Термин многопоточность также используется для описания использования нескольких потоков в одном процессе.
При запуске многопоточного процесса в системе с одним процессором потоки работают поочередно. Процессор быстро переключается между потоками, создавая впечатление параллельной работы потоков, даже не на очень быстром процессоре. Например, в случае трех потоков в одном процессе все потоки будут работать параллельно. Каждому потоку будет соответствовать виртуальный процессор с быстродействием, равным одной трети быстродействия реального процессора.
Почему же потоки так необходимы? Основной причиной является выполнение большинством приложений большого количества действий, некоторые из них могут время от времени блокироваться. Схему программы можно существенно упростить, если разбить приложение на несколько последовательных потоков, запущенных в квазипараллельном режиме.
При использовании потоков имеется также возможность совместного применения параллельными объектами одного адресного пространства и всех содержащихся в нем данных. Для некоторых приложений эта возможность является существенной. В таких случаях схема параллельных процессов с разными адресными пространствами не подходит.
В пользу потоков работает еще один аргумент — легкость их создания и уничтожения, так как с потоком не связаны никакие ресурсы. В большинстве систем на создание потока уходит примерно
в 100 раз меньше времени, чем на создание процесса. Это свойство особенно полезно при необходимости динамического и быстрого изменения числа потоков.
Третьим аргументом является производительность. Концепция потоков не дает увеличения производительности, если они ограничены возможностями процессора. Но когда имеется одновременная потребность в выполнении большого объема вычислений и операций ввода‑вывода, наличие потоков позволяет совмещать эти процедуры во времени, увеличивая, тем самым, общую скорость работы приложения.
Концепция потоков полезна также в системах с несколькими процессорами, где возможен настоящий параллелизм.
Поток — это наименьшая единица обработки, исполнение которой может быть назначено ядром операционной системы.
Реализация потоков выполнения и процессов в разных операционных системах отличается друг от друга, но в большинстве случаев поток выполнения находится внутри процесса. Несколько потоков выполнения могут существовать в рамках одного и того же процесса и совместно использовать ресурсы, такие как память, тогда как процессы не разделяют этих ресурсов.
В частности, потоки выполнения разделяют последовательность инструкций процесса (его код) и его контекст — значения переменных (регистров процессора и стека вызовов), которые они имеют в любой момент времени.
Аналогию потоков выполнения процесса можно уподобить нескольким вместе работающим поварам. Все они готовят одно блюдо, читают одну и ту же кулинарную книгу с одним и тем же рецептом и следуют его указаниям, причём не обязательно все они читают на одной и той же странице.
Поток (thread) — это, сущность операционной системы, процесс выполнения на процессоре набора инструкций, точнее говоря программного кода. Общее назначение потоков — параллельное выполнение на процессоре двух или более различных задач. Как можно догадаться, потоки были первым шагом на пути к многозадачным ОС.
Процесс — это идентифицируемая абстракция совокупности взаимосвязанных системных ресурсов на основе отдельного и независимого виртуального адресного пространства, в контексте которого организуется выполнение потоков.
Компьютерная программа сама по себе — лишь пассивная последовательность инструкций. В то время как процесс — непосредственное выполнение этих инструкций. Также процессом называют выполняющуюся программу и все её элементы: адресное пространство, глобальные переменные, регистры, стек, открытые файлы и так далее.
Процессы и потоки связаны друг с другом, но при этом имеют существенные различия.
Процесс — экземпляр программы во время выполнения, независимый объект, которому выделены системные ресурсы (например, процессорное время и память). Каждый процесс выполняется в отдельном адресном пространстве: один процесс не может получить доступ к переменным и структурам данных другого. Если процесс хочет получить доступ к чужим ресурсам, необходимо использовать межпроцессное взаимодействие. Это могут быть конвейеры, файлы, каналы связи между компьютерами и многое другое.
Поток использует то же самое пространства стека, что и процесс, а множество потоков совместно используют данные своих состояний. Как правило, каждый поток может работать (читать и писать) с одной и той же областью памяти, в отличие от процессов, которые не могут просто так получить доступ к памяти другого процесса. У каждого потока есть собственные регистры и собственный стек, но другие потоки могут их использовать.
Поток — определенный способ выполнения процесса. Когда один поток изменяет ресурс процесса, это изменение сразу же становится видно другим потокам этого процесса.
Элементы процесса
Адресное пространство
Потоки
Открытые файлы
Дочерние процессы
Так теперь мы знаем элементы процесса, но что‑то не то, если потоки‑это процесс выполнения на процессоре набора инструкций, точнее говоря программного кода., открытые файлы — это общедоступная спецификация хранения цифровых данных., дочерние процессы — это процесс, который создается другим процессом и называется родительским процессом и не понятно что такое адресное пространство? Адресное пространство — это не только пространство в оперативной памяти (начало адресов и конец), но также может иногда использоваться и виртуальная память. Адресное пространство — это абстрактная вещь, через которую программа может получать доступ к памяти например так: memory[0], не зная к какой памяти вообще обращается, а доступ к оперативной или виртуальной памяти обеспечивают другие вещи.
После разбора элементов процесса,остается открытый вопрос, какие элементы потока?
Элементы потока
Счётчик команд
Регистры
Стек
Наверное стоит немного пояснить. Счётчик команд — регистр процессора, который хранит адрес ячейки памяти, в которой содержится команда, которую необходимо выполнить следующей. Регистр — устройство для записи, хранения и считывания n‑разрядных двоичных данных и выполнения других операций над ними. Стек — это абстрактный тип данных, представляющий собой список элементов.
Теперь мы точно может углубиться в изучение Процесса и потока, мы разберем парочку примеров.
Пример № 1(процесс)
Два студента запускают на одной ВС (вычислительная система) программу извлечения квадратного корня. Один хочет вычислить квадратный корень из 4, а второй — из 1.
С точки зрения студентов: запущена одна и та же программа
С точки зрения ВС: запущено два различных вычислительных процесса, так как разные исходные данные приводят к разному набору вычислений.
Пример № 2(процесс)
Два студента пытаются выполнить идентичные задания, но запущенные в ВС с некоторым сдвигом во времени — извлечь квадратный корень из 1.
В то время как 1-е задание приступило к печати полученного значения и ждет окончания операции ввода‑вывода, а 2-е только начинает исполняться.
Исходя из данных примеров мы можем прийти к выводу, что процесс характеризует некоторую обособленную совокупность набора исполняющихся команд, которые в свою очередь выделенная для исполнения память или адресное пространство, стеки, используемые файлы и устройства ввода‑вывода и так далее.
Так надо немного нужно пояснить что такое обособленность Это процесс который нужен для того, чтобы защитить один процесс от другого, поскольку они, совместно используя все ресурсы вычислительной системы, конкурируют друг с другом за доступ к ним.
Предпосылки появления потоков
При необходимости взаимодействия, процессы обращаются к ОС (Операционная система), которая, выполняя функции посредника, предоставляет им средства межпроцессной связи — конвейеры, разделяемую память и других, стоит отметить что такой способ взаимодействия параллельно действующих процессов является достаточно затратным(требуются дополнительные затраты времени на переключение контекста). К тому же на создание каждого процесса ОС тратиться системные ресурсы.
Почему нужна поддержка множества потоков внутри одного процесса?
Поддержка множества потоков внутри одного процесса нужна потому, что для работы программы обычно требуется выполнение множества задач. Такую возможность могут предоставлять потоки внутри процесса, таким образом они используют адресное пространство процесса, которому принадлежат.
Стоит отметить что, можно было бы создать ещё один процесс под эту задачу, но:
У процесса будет отдельное адресное пространство и данные.
По вопросам производительности: создание и уничтожение процесса дороже, чем создание потока.
Отличие процесса от потока
Процесс описывает выполняющуюся программу, а сама программа же, её процедуры выполняются в потоках. Главное надо понимать, что программа — это не один поток.
Программа — это набор взаимодействующих между собой потоков, и может быть, даже процессов.
Конечно, может быть 1 поток, если это какая‑то совсем простая программа. Более того, в самых простейших операционных системах процесс имеет только единственный поток выполнения, поэтому в таких случаях размываются границы между потоками и процессами.
Состояния процесса
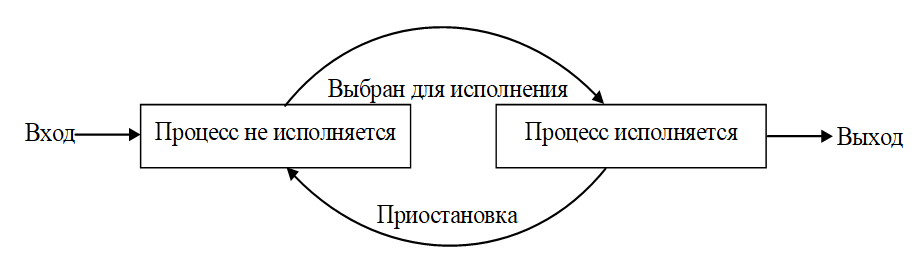
Процесс, выбранный для исполнения, может все еще ждать события, из‑за которого он был приостановлен, и реально быть не готовым к выполнению. Для того чтобы избежать такой ситуации, разобьем состояние процесс не исполняется на два новых состояния: 1) Готовность 2) Ожидание
Состояния потоков
В операционной системе выполняет планирование потоков, принимая во внимание их состояние. В мультипрограммной системе поток может находиться в одном из трех основных состояний:
Выполняемый — поток, который выполняется в текущий момент на процессоре
Готовый — поток ждет получения кванта времени и готов выполнять назначенные ему инструкции. Планировщик выбирает следующий поток для выполнения только из готовых потоков.
Заблокированный — работа потока заблокирована в ожидании блокирующей операции
Операции над процессами
Нужно разобраться в операциях над процессами, всего их три:
Создание процесса — завершение процесса (одноразовые);
Запуск процесса — приостановка процесса (перевод из состояния исполнение в состояние готовность);
Блокирование процесса — разблокирование процесса (перевод из состояния ожидание в состояние готовность).
Но есть еще непарная операция: изменение приоритета процесса
Мы не определили что такое многозадачность, и для чего она вообще нужна.
Что такое многозадачность
Многозадачность — это свойство, позволяющее обеспечивать выполнение сразу нескольких задач на одном процессоре. Многозадачность может быть параллельной (если каждая задача выполняется на отдельном процессоре) или псевдопараллельной (если задачи выполняются на одном процессоре).
Для чего нужна многозадачность?
Если простым языком, многозадачность позволяет запускать сразу несколько программ на компьютере.
Но мы с вами умные, и простой язык на не подойдет, по этому многозадачность нужна для того, чтобы на процессоре могли выполняться сразу несколько потоков. Данная необходимость возникла потому, что крайне нежелательная пустая трата процессорного времени, то есть простаивание процессора. Простаивание возникает тогда, когда какой‑либо поток блокируется в ожидании результата блокирующей операции. Тогда, лучше отдать процессорное время другому потоку, чтобы процессор не простаивал, таким образом повышая производительность.
После изучение информации про многозадачность, остается один открытый вопрос что такое Кэширование данных?
Кэширование данных
Для начала мы разберем что такое кэширование — это процесс сохранения данных локально, который позволяет быстрее получить к ним доступ при будущих запросах.
Но стоит уточнить что для ускорения доступа к данным используется принцип кэширования (который описан выше). В вычислительных системах существует иерархия запоминающих устройств:
Нижний уровень занимает емкая, но относительно медленная дисковая память;
Оперативная память;
Верхний уровень — сверхоперативная память процессорного кэша.
Но нужно не забывать важную составляющую, что каждый уровень играет роль кэша по отношению к нижележащему.
Что такое процесс
Процесс — это абстракция, существующая на программном уровне — уровне операционной системы.
Процесс был придуман для организации всех данных, необходимых для работы программы. Можно сказать, что процесс — это просто контейнер, в котором находятся ресурсы программы.
Элементы процесса:
адресное пространство
потоки
открытые файлы
дочерние процессы
Просто к слову, адресное пространство — это не только пространство в оперативной памяти (начало адресов и конец), но также может иногда использоваться и виртуальная память. Адресное пространство — это абстрактная вещь, через которую программа может получать доступ к памяти например так: memory, не зная к какой памяти вообще обращается, а доступ к оперативной или виртуальной памяти обеспечивают другие вещи.
Что такое поток
Поток — это сущность, в которой выполняются процедуры программы. Поток легче, чем процесс, и создание потока стоит дешевле.
Потоки используют адресное пространство процесса, которому они принадлежат, поэтому потоки внутри одного процесса могут обмениваться данными и взаимодействовать с другими потоками.
Элементы потока:
Счётчик команд
Регистры
Стек
Почему нужна поддержка множества потоков внутри одного процесса
Поддержка множества потоков внутри одного процесса нужна потому, что для работы программы обычно требуется выполнение множества задач. Также, часто, задачам необходимо обмениваться данными, использовать общие данные или результаты других задач. Такую возможность предоставляют потоки внутри процесса, так как они используют адресное пространство процесса, которому принадлежат.
Конечно, можно было бы создать ещё один процесс под задачу, но:
у процесса будет отдельное адресное пространство и данные
создание и уничтожение процесса дороже, чем создание потока
Отличие процесса от потока
Процесс описывает выполняющуюся программу (описывает, значит содержит необходимые данные и ресурсы для работы программы), а сама программа же, её процедуры выполняются в потоках. Главное надо понимать, что программа — это не один поток.
Программа — это набор взаимодействующих между собой потоков, и может быть, даже процессов.
Конечно, может быть 1 поток, если это какая‑то совсем простая программа. Более того, в самых простейших операционных системах процесс имеет только единственный поток выполнения, поэтому в таких случаях размываются границы между потоками и процессами (о потоках говорится равнозначно процессам).
Вывод: процесс — это всего лишь способ сгруппировать взаимосвязанные данные и ресурсы, а потоки — единица выполнения (unit of execution), которая распределяется и выполняется на процессоре. Процессы сменяться на процессоре не могут, сменяются и выполняются на процессоре именно потоки.
Что такое счётчик команд
Счётчик команд (Program counter, Instruction Pointer) — регистр процессора, который хранит адрес ячейки памяти, в которой содержится команда, которую необходимо выполнить следующей.
Счётчик команд — это один из наиболее важных регистров процессора, так как позволяет выполнять алгоритмы (простая программа выводящая Hello, World — тоже алгоритм по сути. Алгоритм — это абстрактная вещь). Последовательности команд и являются алгоритмами по сути.
После взятия команды из регистра счётчик увеличивается (инкрементируется), и в регистре будет храниться следующая команда, которую необходимо выполнить.
В зависимости от архитектуры, в счётчике команд может храниться текущая выполняемая команда, а не следующая, если инкрементация предшествует взятию команды.
Состояния потоков
Выполняемый (Executing) — поток, который выполняется в текущий момент на процессоре
Готовый (Runnable) — поток ждет получения кванта времени и готов выполнять назначенные ему инструкции. Планировщик выбирает следующий поток для выполнения только из готовых потоков.
Заблокированный (Waiting) — работа потока заблокирована в ожидании блокирующей операции
Однако в каждой ОСи свое устройство планировщика, а значит и набор состояний. Более того, часто даже языки абстрагируют системные потоки от пользователя путем введения своих классов потоков, которые обычно под капотом ложатся на системные. Так, например, Java имеет свои потоки — см. java.lang.Thread.State.
А вот информация про Linux — Understanding Linux Process States
Почему создание и уничтожение процессов дороже, чем потоков
Процесс — полностью описывает программу: адресное пространство, потоки, открытые файлы, дочерние процессы, все эти таблицы данных должны инициализироваться при создании процесса. Тогда как потоки не хранят таких данных (т.к. они используют данные процесса, к которому они прикреплены), а хранит только счетчик команд, стек и регистры (поэтому потоки также называют «легкими процессами»).
Что такое многозадачность
Многозадачность — свойство ОСи, позволяющее обеспечивать выполнение сразу нескольких задач на одном процессоре. Многозадачность может быть параллельной (если каждая задача выполняется на отдельном процессоре) или псевдопараллельной (если задачи выполняются на одном процессоре).
Для чего нужна многозадачность
Многозадачность нужна для того, чтобы на процессоре могли выполняться сразу несколько потоков.
Данная необходимость возникла потому, что крайне нежелательная пустая трата процессорного времени, то есть простаивание процессора. Простаивание возникает тогда, когда какой‑либо поток блокируется в ожидании результата блокирующей операции. Тогда, лучше отдать процессорное время другому потоку, чтобы процессор не простаивал, таким образом повышая производительность.
Также, многозадачность позволяет запускать сразу несколько программ на компьютере.
Вытесняющая и кооперативная многозадачность
Существуют вытесняющие (preemptive) и кооперативные (cooperative) алгоритмы планирования:
При вытесняющем режиме работы потоки могут прерываться принудительно при истечении отведенного им кванта времени.
При кооперативном режиме работы потоки могут работать столько, сколько им необходимо. Переключение контекста произойдет только при завершении работы потока, блокировке или при добровольном предоставлении возможности выполнения (например, функция yield() в Unix). При использовании кооперативной многозадачности нужно быть предельно осторожным, иначе может возникнуть ситуация, когда один поток полностью захватит процессор.
Применение вытесняющей многозадачности: вытесняющая многозадачность применяется в интерактивных системах. В такой системе ни один поток не может получать больше процессорного времени, чем какой‑либо другой эквивалентный ему: каждый поток должен получать справедливое процессорное время. Значит, потоки не могут сами решать, сколько им выполняться, поэтому в интерактивной среде следует применять вытесняющую многозадачность.
Вытесняющая многозадачность называется так потому, что потоки будто вытесняют друг друга, ведь каждый хочет выполняться.
Применение кооперативной многозадачности: кооперативная многозадачность применяется в системах реального времени, так как в такой среде потоки знают, что они могут запускаться только на непродолжительные отрезки времени. Также, в среде реального времени потоки запускаются только для решения определённой задачи с последующим самостоятельным блокированием, в отличие от интерактивных систем, где задачи произвольны и не преследуют цель решить конкретную задачу. Кроме того, из‑за отсутствия принудительного переключения потоков, повышается производительность и эффективность работы системы, так как количество прерываний сильно сокращается.
Кооперативная многозадачность называется так потому, что потоки должны кооперировать между собой, то есть правильно распределять время выполнения, передавая возможность работы другим потокам, чтобы происходила работа системы. Потоки не хотят выполняться, пока им не передадут возможность выполнения, все потоки терпеливо ждут своей очереди, потому что знают, что каждый выполняет свою определённую задачу, и в разные моменты времени требуется выполнение определённых задач для работы программы.
Вывод: кооперативная многозадачность может быть особенно на системах реального времени. Вытесняющая многозадачность подходит лучше для интерактивных систем.
Что такое Context switch
Context switch (переключение контекста) — это процесс сохранения состояния прерванного потока и загрузка состояния следующего потока (который тоже был сохранен раннее), к выполнению которого приступит процессор. Следует отметить, что Context switch не прерывает текущий выполняемый поток, прерывание потока происходит благодаря прерываниям: происходит прерывание (текущий поток приостанавливается), вызывается планировщик, планировщик инициирует context switch.
Вызов Context switch инициируется планировщиком. Планировщик должен решить, какой поток будет выполняться следующим, и происходит context switch, который загружает состояние данного потока. Однако, если планировщик решит, что потоки сменяться не должны и прервавшемуся потоку разрешается работать дальше, context switch может и не произойти.
Различие между процессами и потоками
С помощью процессов можно организовать параллельное выполнение программ. Для этого процессы клонируются вызовами fork() или exec(), а затем между ними организуется взаимодействие средствами IPC. Это довольно дорогостоящий в отношении ресурсов процесс.
С другой стороны, для организации параллельного выполнения и взаимодействия процессов можно использовать механизм многопоточности. Основной единицей здесь является поток.
Поток представляет собой облегченную версию процесса. Чтобы понять, в чем состоит его особенность, необходимо вспомнить основные характеристики процесса.
Процесс располагает определенными ресурсами. Он размещен в некотором виртуальном адресном пространстве, содержащем образ этого процесса. Кроме того, процесс управляет другими ресурсами (файлы, устройства ввода / вывода и т. д.).
Процесс подвержен диспетчеризации. Он определяет порядок выполнения одной или нескольких программ, при этом выполнение может перекрываться другими процессами. Каждый процесс имеет состояние выполнения и приоритет диспетчеризации.
Если рассматривать эти характеристики независимо друг от друга (как это принято в современной теории ОС), то:
-
владельцу ресурса, обычно называемому процессом или задачей, присущи:
виртуальное адресное пространство;
индивидуальный доступ к процессору, другим процессам, файлам, и ресурсам ввода — вывода.
-
Модулю для диспетчеризации, обычно называемому потоком или облегченным процессом, присущи:
состояние выполнения (активное, готовность и т. д.);
сохранение контекста потока в неактивном состоянии;
стек выполнения и некоторая статическая память для локальных переменных;
доступ к пространству памяти и ресурсам своего процесса.
Все потоки процесса разделяют общие ресурсы. Изменения, вызванные одним потоком, становятся немедленно доступны другим.
При корректной реализации потоки имеют определенные преимущества перед процессами. Им требуется:
меньше времени для создания нового потока, поскольку создаваемый поток использует адресное пространство текущего процесса;
меньше времени для завершения потока;
меньше времени для переключения между двумя потоками в пределах процесса;
меньше коммуникационных расходов, поскольку потоки разделяют все ресурсы, и в частности адресное пространство. Данные, продуцируемые одним из потоков, немедленно становятся доступными всем другим потокам.
Что такое планировщик задач в ОС
Планировщик задач (scheduler) — это программа (демон), на которую ложится задача выбора потока, который будет выполняться следующим. Планировщик применяется в многозадачности.
Как работает планировщик задач
Алгоритм планирования — алгоритм, который используется в планировщике. От алгоритма планирования зависит распределение порядка работы потоков.
Основной принцип планирования — предоставление каждому потоку справедливой доли процессорного времени. Однако, в некоторых алгоритмах планирования различные категории потоков могут получать большее процессорное время, чем потоки с низким приоритетом
Алгоритмы планирования зависят от среды выполнения:
Пакетные системы
Интерактивная система
Система реального времени
Вызов планировщика происходит в следующих ситуациях:
При создании нового потока
При завершении работы потока
При блокировке потока в ожидании результата блокирующей операции (операция ввода‑вывода, блокировка на семафоре или мьютексе или другая причина блокировки)
При возникновении прерывания ввода‑вывода
Далее рассмотрим работу планировщика в описанных выше ситуациях.
Создание нового потока
Планировщик должен решить, какому потоку позволить выполняться следующим: дочерний (только что созданный) или родительский (инициировавший создание нового потока), или вообще какой‑нибудь третий поток.
Завершение работы потока
Когда поток завершает свою работу, необходимо выбрать следующий поток для выполнения
Блокировка потока
Когда поток блокируется, планировщик должен выбрать поток, который будет выполняться следующим во избежании пустой траты процессорного времени
Возникновение прерывания ввода-вывода
Если устройство ввода‑вывода завершило свою работу и готово вернуть результат, то какой‑то поток, который был заблокирован в ожидании результата данной операции, теперь может быть готов к выполнению. Планировщик должен решить, какой из заблокированных потоков или каких‑либо других потоков должен продолжить свое выполнение.
Процессы
Все современные компьютеры могут выполнять одновременно несколько операций. Так, одновременно с запущенной пользователем программой может выполняться чтение с диска и вывод текста на экран монитора или на принтер. В многозадачной системе процессор переключается между программами, предоставляя каждой от десятков до сотен миллисекунд.
Операционной системе нужен способ создания и прерывания процессов по мере необходимости. Обычно при загрузке ОС создаются несколько процессов. Некоторые из них обеспечивают взаимодействие с пользователем и выполняют заданную работу. Остальные процессы являются фоновыми. Они не связаны с конкретными пользователями, но выполняют особые функции. Например, один фоновый процесс может обеспечивать вывод на печать, другой может обрабатывать запросы к web -страницам.
Процессы могут создаваться не только в момент загрузки системы. Так, текущий процесс может создать один или несколько новых процессов, при этом текущий процесс выполняет системный запрос на создание нового процесса. Создание новых процессов особенно полезно в тех случаях, когда выполняемую задачу проще всего сформировать как набор связанных, но независимо взаимодействующих процессов. Если необходимо организовать выборку большого количества данных из сети для дальнейшей обработки, удобно создать один процесс для выборки данных и размещения их в буфере, другой — для считывания и обработки данных из буфера. Такая схема даже ускорит обработку данных, если каждый процесс запустить на отдельном процессоре в случае многопроцессорной системы.
Как правило, процессы завершаются по мере выполнения своей работы.. В текстовых редакторах, браузерах и других программах такого типа есть кнопка или пункт меню, с помощью которых можно завершить процесс.
Процесс является независимым объектом со своим счетчиком команд и внутренним состоянием, однако существует необходимость взаимодействия с другими процессами. Например, выходные данные одного процесса могут служить входными данными для другого процесса.
Модель процессов упрощает представление о внутреннем поведении системы. Некоторые процессы запускают программы, выполняющие команды, введенные с клавиатуры пользователем. Другие процессы являются частью системы и обрабатывают такие задачи, как выполнение запросов файловой службы, управление запуском диска или магнитного накопителя.
Нижний уровень ОС — это планировщик — небольшая программа. На верхних уровнях расположены процессы. Обработка прерываний и процедуры, связанные с остановкой и запуском процессов, выполняются планировщиком. Вся остальная часть ОС структурирована в виде набора процессов.
Реализация модели процессов базируется на таблице процессов с одним элементом для каждого процесса. Элемент таблицы содержит информацию о состоянии процесса, счетчике команд, распределении памяти, состоянии открытых файлов, об указателе стека, использовании и распределении ресурсов, а также всю остальную информацию, которую необходимо сохранять при переключении в состояние готовности или блокировки для последующего запуска процесса, как если бы он не останавливался.
Управление памятью
Память представляет собой важный ресурс, требующий тщательного управления, поскольку программы увеличиваются в размерах быстрее, чем память.
Память в компьютере имеет иерархическую структуру. Небольшая ее часть представляет собой очень быструю энергозависимую (теряющую информацию при выключении питания) кэш‑память.
Компьютеры обладают также десятками мегабайт энергозависимой оперативной памяти ОЗУ ( RAM, Random Access Memory — память с произвольным доступом) и десятками или сотнями гигабайт медленного энергонезависимого пространства на жестком диске. Одной из задач ОС является координация использования всех этих составляющих памяти.
Часть операционной системы, отвечающая за управление памятью, называется модулем управления памятью или менеджером памяти. Менеджер следит за тем, какая часть памяти используется в данный момент, выделяет память процессам и по их завершении освобождает ресурсы, управляет обменом данных между ОЗУ и диском.
Самая простая схема управления памятью — однозадачная система без подкачки на диск — заключается в том, что в каждый момент времени работает только одна программа, и память разделяется между программами и операционной системой. Когда система организована таким образом, в каждый конкретный момент времени может работать только один процесс. Как только пользователь набирает команду, ОС копирует запрашиваемую программу с диска в память и выполняет ее, а после окончания процесса выводит на экран символ приглашения и ждет новой команды. Получив команду, она загружает новую программу в память, записывая ее поверх предыдущей. Так работают компьютеры с операционной системой MS — DOS.
Большинство современных систем позволяет одновременный запуск нескольких процессов. Наличие нескольких процессов, работающих в один и тот же момент времени, означает, что когда один процесс приостановлен в ожидании завершения операции ввода‑вывода, другой может использовать центральный процессор. Таким образом, многозадачность увеличивает загрузку процессора. На сетевых серверах всегда одновременно работают несколько процессов (для разных клиентов), но и большинство клиентских машин в наши дни также имеют эту возможность. Самый простой способ достижения многозадачности состоит в разбиении памяти на несколько, возможно, не
равных, разделов. Когда задание поступает в память, оно располагается во входной очереди к наименьшему разделу, достаточно большому для того, чтобы вместить это задание. Так как размер разделов неизменен, то все неиспользуемое работающим процессом пространство в разделе пропадает. Недостаток этого способа заключается в том, что к большому разделу очереди почти не бывает, а к маленьким разделам выстраивается довольно много задач. Небольшие задания должны ждать своей очереди, чтобы попасть в память, несмотря на то, что свободна основная часть памяти. Усовершенствованный способ заключается в организации одной общей очереди для всех разделов. Как только раздел освобождается, задачу, находящуюся ближе к началу очереди и подходящую для выполнения в этом разделе, можно загрузить в него и начать ее обработку. С другой стороны, нежелательно тратить большие разделы на маленькие задачи, поэтому существует другая стратегия. Она заключается в том, что каждый раз после освобождения раздела происходит поиск в очереди наибольшего для этого раздела задания, и именно оно выбирается для обработки. Однако этот алгоритм отстраняет от обработки небольшие задачи, хотя необходимо предоставить для мелких задач лучшее обслуживание. Выходом из положения служит создание хотя бы одного маленького раздела, который позволит выполнять мелкие задания без долгого ожидания освобождения больших разделов. Другой подход предусматривает следующий алгоритм: задачу, которая имеет право быть выбранной для обработки, можно пропустить не более к раз. Когда задача пропускается, к счетчику добавляется единица. Если значение счетчика стало равным к, игнорировать задачу больше нельзя.
При использовании многозадачности повышается эффективность загрузки ЦП. Если средний процесс выполняет вычисления только 20% от времени, которое он находится в памяти, то при обработке
пяти процессов ЦП должен быть загружен полностью. Реальная же ситуация предполагает, что все пять процессов никогда не ожидают завершения операции ввода‑вывода одновременно.
Организация памяти в виде фиксированных разделов проста и эффективна для работы с пакетными системами. До тех пор, пока в памяти может храниться достаточное количество задач для обеспечения постоянной занятости ЦП, причин для усложнения алгоритма нет.
Однако совсем другая ситуация складывается с системами разделения времени или компьютерами, ориентированными на работу с графикой. Оперативной памяти иногда оказывается недостаточно для того, чтобы разместить все активные процессы, и тогда избыток процессов приходится хранить на диске, а для обработки переносить их в память.
Существуют два основных способа управления памятью, зависящие частично от доступного аппаратного обеспечения. Самая простая стратегия, называемая свопингом ( swapping ) или подкачкой, состоит в том, что каждый процесс полностью переносится в память, работает некоторое время и затем целиком возвращается на диск. Другая стратегия, носящая название виртуальной памяти, позволяет программам работать даже тогда, когда они только частично находятся в оперативной памяти.
Работа системы свопинга заключается в следующем. Пусть имеются 4 процесса — А, В, С, D. На начальной стадии в памяти находится только процесс А. Затем с течением времени создаются или загружаются с диска последовательно процессы В и С. В следующий момент процесс А выгружается на диск. Затем появляется процесс D, а процесс В завершается. Наконец, процесс А снова возвращается в память. Распределение памяти изменяется по мере того, как процессы поступают в память и покидают ее. Так как теперь процесс А имеет другое размещение в памяти, его адреса должны быть перенастроены или программно во время загрузки в память, или аппаратно во время выполнения программы.
Основная разница между фиксированными и изменяющимися разделами состоит в том, что во втором случае количество, размещение и размер разделов изменяются динамически по мере поступления и завершения процессов. Здесь нет ограничений, связанных с количеством разделов и их объемом. Это улучшает использование памяти, но значительно усложняет операции размещения процессов, освобождения памяти и отслеживание происходящих изменений.
Основная идея виртуальной памяти заключается в том, что объединенный размер программы, данных и стека может превысить количество доступной физической памяти. ОС хранит части программы, использующиеся в настоящий момент в оперативной памяти, остальные — на диске. Например, программа размером 16 Мбайт сможет работать на машине с 4 Мбайт памяти, если тщательно продумать, какие 4 Мбайт должны храниться в памяти в каждый момент времени. При этом части программы, находящиеся на диске и в памяти, будут меняться местами по мере необходимости.
Виртуальная память может также работать в многозадачной системе при одновременно находящихся в памяти частях многих программ. Когда программа ждет перемещения в память очередной своей
части, она находится в состоянии ввода‑вывода и не может работать, поэтому ЦП может быть отдан другому процессу.
Процесс VS поток в Linux
Вы когда‑нибудь задумывались о разнице между процессом и потоком в операционной системе? Давайте обсудим детали процесса и потока в контексте Linux.
Процесс — это выполняемая компьютерная программа. В Linux в любой момент времени запущено множество процессов. Мы можем отслеживать их в терминале с помощью команды ps или в пользовательском интерфейсе System Monitor. Например, давайте посмотрим пример использования команды ps для просмотра всех процессов, запущенных на моей машине:
$ ps -fa
UID PID PPID C STIME TTY TIME CMD
argentum 419 399 0 14:46 tty1 00:00:00 /bin/sh /usr/bin/startx
argentum 434 419 0 14:46 tty1 00:00:00 xinit /home/okulus/.xinitrc -- /etc/X11/xinit/xserverrc :0 vt1 -keeptty -auth /tmp/serverauth.he7xhMVRnf
argentum 435 434 3 14:46 tty1 00:10:48 /usr/lib/Xorg -nolisten tcp :0 vt1 -keeptty -auth /tmp/serverauth.he7xhMVRnf
argentum 440 434 0 14:46 tty1 00:00:17 dwm
argentum 444 440 0 14:46 tty1 00:01:41 slstatus
argentum 15910 15802 99 20:11 pts/3 00:00:00 ps -faПо мере запуска новых команд/приложений или завершения работы старых команд мы можем наблюдать динамическое увеличение и уменьшение числа процессов. Процессы в Linux изолированы и не прерывают выполнение друг друга.
С помощью PID мы можем идентифицировать любой процесс в Linux. Внутри ядра этот номер присваивается уникальным образом и освобождается для повторного использования после выхода процесса. Мы можем увидеть PID во втором столбце в выводе приведенной выше команды ps.
Поскольку в Linux в каждый момент времени запущено множество процессов, им приходится делить процессор. Процесс переключения между двумя выполняющимися процессами на CPU называется переключением контекста процесса. Переключение контекста процесса требует больших затрат, поскольку ядру приходится сохранять старые регистры и загружать текущие регистры, карты памяти и другие ресурсы.
Потоки в Linux
Поток — это легкий процесс. Процесс может выполнять более одной единицы работы одновременно, создавая один или несколько потоков. Эти потоки, будучи легковесными, могут быстро порождаться.
Давайте рассмотрим пример и определим процесс и его поток в Linux с помощью команды ps -aLf. Нас интересуют атрибуты PID, LWP и NLWP:
PID: уникальный идентификатор процесса
LWP: Уникальный идентификатор потока внутри процесса
NLWP: количество потоков для данного процесса
$ ps -aLf
UID PID PPID LWP C NLWP STIME TTY TIME CMD
argentum 419 399 419 0 1 14:46 tty1 00:00:00 /bin/sh /usr/bin/startx
argentum 434 419 434 0 1 14:46 tty1 00:00:00 xinit /home/okulus/.xinitrc -- /etc/X11/xinit/xserverrc :0 vt1 -keeptty -auth /tmp/serverauth.he7xh
argentum 435 434 435 2 4 14:46 tty1 00:09:14 /usr/lib/Xorg -nolisten tcp :0 vt1 -keeptty -auth /tmp/serverauth.he7xhMVRnf
argentum 435 434 436 0 4 14:46 tty1 00:01:11 /usr/lib/Xorg -nolisten tcp :0 vt1 -keeptty -auth /tmp/serverauth.he7xhMVRnf
argentum 435 434 437 0 4 14:46 tty1 00:00:00 /usr/lib/Xorg -nolisten tcp :0 vt1 -keeptty -auth /tmp/serverauth.he7xhMVRnf
argentum 435 434 439 0 4 14:46 tty1 00:00:29 /usr/lib/Xorg -nolisten tcp :0 vt1 -keeptty -auth /tmp/serverauth.he7xhMVRnf
argentum 440 434 440 0 1 14:46 tty1 00:00:18 dwm
argentum 444 440 444 0 1 14:46 tty1 00:01:42 slstatus
argentum 16007 15802 16007 99 1 20:13 pts/3 00:00:00 ps -aLfМы можем легко определить однопоточные и многопоточные процессы по их значениям NLWP. PID 690 и 709 имеют NLWP 2 и 4, соответственно. Следовательно, они являются многопоточными, с 2 и 4 потоками. Все остальные процессы имеют NLWP, равный 1, и являются однопоточными.
При внимательном наблюдении видно, что однопоточные процессы имеют одинаковые значения PID и LWP, как будто это одно и то же. Однако в многопоточном процессе только один LWP соответствует его PID, а остальные имеют разные значения LWP. Также обратите внимание, что значение, однажды присвоенное LWP, никогда не передается другому процессу.
Любой поток, созданный в рамках процесса, использует ту же память и ресурсы, что и процесс. В однопоточном процессе процесс и поток — одно и то же, поскольку происходит только одно действие. Мы также можем подтвердить вывод ps ‑aLf из нашего предыдущего обсуждения, что PID и LWP одинаковы для однопоточного процесса.
В многопоточном процессе имеется более одного потока. Такой процесс выполняет несколько задач одновременно или почти одновременно.
Как известно, поток разделяет одно и то же адресное пространство процесса. Поэтому порождение нового потока внутри процесса становится дешевым (с точки зрения системных ресурсов) по сравнению с запуском нового процесса. Потоки также могут переключаться быстрее (поскольку у них общее адресное пространство с процессом) по сравнению с процессами в CPU. Внутри памяти у потока есть только стек, а кучу (память процесса) он делит с родительским процессом.
Из‑за такой природы нити мы также называем их легковесными процессами (Light‑Weight Process, LWP).
У совместного использования одной и той же памяти с другими потоками есть как преимущества, так и недостатки.
Самое важное преимущество заключается в том, что мы можем создавать потоки быстрее, чем процессы, поскольку нам не нужно выделять память и ресурсы. Другое преимущество — низкая стоимость межпотокового взаимодействия.
Подобно контекстному переключению процесса, существует понятие контекстного переключения потока. Переключение контекста потока происходит быстрее, так как поток записывает только свои значения стека перед переключением.
Есть один существенный недостаток: Поскольку потоки используют одну и ту же память, они могут стать медленными, если процесс выполняет много параллельных задач.
Внутренние процессы
В Linux есть системные вызовы, определенные для основных функций ОС, таких как управление файлами, управление сетью, управление процессами и другие. Любая работающая программа Linux использует эти системные вызовы. Поэтому для удобства разработки приложений библиотека GNU C предоставляет их в виде API.
Для создания процесса в Linux мы используем системные вызовы fork (или clone) и execve. Здесь системный вызов fork создает дочерний процесс, эквивалентный родительскому процессу. Системный вызов execve заменяет исполняемый файл дочернего процесса. В современных реализациях системный вызов fork внутренне использует системный вызов clone. Поэтому мы подробнее остановимся на системном вызове clone.
Как пользователям системы Linux, нам никогда не приходится создавать внутреннюю структуру данных для процесса. Однако важно понимать внутреннюю структуру данных процесса Linux. Linux создает каждый процесс с помощью структуры данных на языке C под названием task_struct. Ядро Linux хранит их в динамическом списке, представляющем все запущенные процессы, который называется tasklist. В этом списке задач каждый элемент имеет тип task_struct, который изображает процесс Linux.
Мы классифицируем различные поля в структуре задачи как параметры планирования, образ памяти, сигналы, машинные регистры, состояние системных вызовов, дескрипторы файлов, стек ядра и так далее. Таким образом, когда мы создаем новый процесс, ядро Linux создает в памяти ядра новую структуру task_struct, указывающую на вновь созданный процесс.
Заключение
Все взято из открытых источников.
Интересный сторонний материал и лекции:
Работа UNIX систем (англ)
С вами был доктор Аргентум! Спасибо за прочтение и комментарии!
Комментарии (4)

Yuri0128
01.12.2023 17:09+3ТС, вы упоминаете о ОС, а базовой единицей в ОС была (хотя сейчас это несколько не так) задача, и уж никак не поток (нить, в общем-то, будет все-таки правильнее). Ну как-бы с первых многозадачных ОС (именно так). А задача уже организовывала процессы (сейчас несколько не так, все изменилось). Ну и нету отдельного программного счетчика/указателя у нити, есть "контекст" (это просто пачка регистров проца/ядра выделенных конктретно этому потоку) и при одном процессоре идет переключение контекста (то есть выгрузка текущего состояния обрабатывающего проца/ядра в некую область хранения отработавшего потока и загрузка контекста (всех необходимых регистров) запускаемого. И в общем случае, для многопроцессорных/многоядерных систем, поток может исполняться на любом "доступном" процессоре/ядре и не факт что на одном и том-же. Ну и нету упоминаний о ядрах (core) процессора ибо их может быть несколько и даже очень много. А потоки буду исполняться на одном процессоре но на разныъ его ядрах весьма даже параллельно.
А так читабельность статьи плохая, реально есть впечатление что писано методом подбора кусков в Инете (ну с помощью ИИ или еще каким-то образом).
rukhi7
Это явно состряпано с помощью искусственного "интеллекта". Да! Именно «интелект» здесь достоин кавычек! Я бы попросил модераторов Хабра обратить внимание на это творение. Это практически смерть Хабра, если это не остановить, я считаю!
Вот просто несколько цитат из статьи собранных по ключевому слову "стек":
DrArgentum Автор
Ни капли искусственного интеллекта. Последний раз я его использовал в первых статьях, и то они в черновиках
rukhi7
Зачем вы пишите о том в чем совершенно не разбираетесь???
Это просто шедевр, причем один из многих (я не про опечатку "немного нужно", хотя она вполне укладывается в контекст):