
Как обычно происходит стандартное реагирование в SOC? Получил аналитик оповещение об инциденте от какой-то системы безопасности, посмотрел логи SIEM, чтобы собрать дополнительные данные, уведомил заказчика и составил для него короткий отчет о произошедшем.
А что дальше? А дальше — переключился на новый инцидент или ожидает его появления. В крайних случаях — участие в расследовании инцидентов и разработка новых сценариев выявления атак.
Такова «хрестоматийная», стандартная схема работы аналитика в коммерческом SOC. Это и не хорошо, и не плохо — это, как правило, просто данность. Однако формат действий security-аналитика можно сделать кардинально иным, и за счет этого помочь амбициозному специалисту расти быстрее и шире, а компании-заказчику — дополнительно укрепить свою безопасность.

Я, Никита Чистяков, тимлид команды security-аналитиков в «Лаборатории Касперского». Под катом я расскажу, как и зачем в Kaspersky помогаю выстраивать новые условия работы для security-аналитиков и как эти условия помогают им стать эдакими витрувианскими ИБшниками эпохи Возрождения.
Если вы сами аналитик или в целом работаете в инфобезе, хотите узнать, какой скрытый потенциал есть у профессии и как его раскрыть, эта статья — для вас.
Я пришел в «Лабораторию Касперского» около 12 лет назад и все десятилетие постоянно рос вместе с компанией. Каждый этап этого совместного роста — очередная доминошка в ряду, который вел к тому, что компании стало необходимо развивать зрелых security-аналитиков.
2014 год. Команде ИБ не хватает продукта для защиты от таргетированных атак, и мы совместно с нашим R&D запускаем его разработку. Один из таких продуктов — наша платформа Kaspersky Anti-Target Attack (KATA). Вскоре в отсутствии SOC мы сами себе аналитики мониторинга и активно разбираем первые алерты от KATA и других источников. Нас мало, логов становится больше, а будет еще больше; значит, нужны более зрелые процессы.
2015 год. Нам стало очевидно, что пора создавать собственный SOC, который будет работать и для нас, как внутреннего заказчика, и для внешних клиентов. Поэтому участвуем в формировании SOC-команды внутри R&D — помогаем набрать первых в компании SOC-аналитиков. Объем покрытия телеметрии растет, развиваются *DR-сервисы, а мониторинг угроз идет теперь 24/7.
2020 год. SOC разросся до полусотни человек, аналитики в нем занимаются мониторингом и первичным реагированием на инциденты, а сложные внутренние кейсы передают для реагирования специалистам, менеджерам и архитекторам отдела ИБ. Сотрудники ИБ — мастера своих специальностей, но реагирование на инциденты для них — задача зачастую непрофильная, им приходится буквально отрываться от собственной важной работы, из-за чего проекты ИБ по развитию, аудиту, внедрению требований могут отодвигаться и простаивать.
При этом количество телеметрии по-прежнему растет, поиск информации об атакованных ресурсах, серверах или учетках может занимать несколько драгоценных часов, а реагирование в худшем случае может длиться и месяц. Поэтому требовался новый уровень зрелости — выделенная группа экспертов, каждый из которых будет полноценным incident handler и сможет выстроить эффективные процессы реагирования. Чтобы, получая от SOC информацию о каком-либо сложном инциденте, такой специалист смог в сверхкороткое время ее проанализировать, определить критичность ситуации, а затем либо отработать ее самостоятельно, либо собрать виртуальную команду реагирования из разных экспертов в компании, распределить задачи между ее участниками, чтобы сократить потенциальный ущерб. А по итогам решения этих задач такой специалист совместно с коллегами разработал бы оптимальный план митигации подобных инцидентов в будущем и помог воплотить его в жизнь.
Вот и последняя доминошка в нашем ряду — перерожденный в новой роли security-аналитик. А точнее, целая команда.
Давайте вернемся к «хрестоматийному» аналитику, про которого мы говорили в самом начале.
У такого специалиста обычно ограниченный SLA, чтобы обработать инцидент и объяснить в отчете, как его митигировать. И он, будучи в том же «хрестоматийном» пайплайне, не занимается тем, что помогает создавать и улучшать продукты, не может помогать модернизировать инфраструктуру и архитектуру ИБ, не ставит задачи по разработке для R&D и в целом мало сотрудничает с коллегами из других отделов.
Повторюсь, это и не хорошо, и не плохо: но данность такова, что после составления отчета у аналитика вообще нет никаких рычагов влияния на процессы заказчика по митигации инцидентов. А если копнуть еще глубже, у такого аналитика может быть профессиональный диссонанс: даже если у него имеется отличная идея, как митигировать последствия инцидента и предотвратить подобные ситуации в будущем, он едва ли сможет ее воплотить.
Поэтому задачи такого специалиста часто сводятся к довольно однообразной работе и мониторингу телеметрии в режиме 24/7, написанию правил корреляции. В лучшем случае с предоставлением минимальных рекомендаций.
Выходит, что амбициозный специалист может быть вымотан монотонной работой, устает от недосыпа и не растет в профессии так быстро и разнопланово, как жаждет. Чем не причины для трансформации?
Естественно, сперва нужна техническая база — и у нас есть все необходимое: от классических железных серверов, СЗИ и до средств оркестрирования контейнеризации. Но одного только железа мало, если не налажены процессы: мы проработали их с командами Threat Intelligence и Threat Hunting, расширили способы автоматизации реагирования и других аспектов работы аналитика, определили, как будут проходить аудиты процессов SOC.
Следующим логичным шагом было сформировать те самые команды, которые будут участвовать в реагировании на сложные инциденты, — с экспертами высочайшего уровня, в том числе администраторами IT- и ИБ-систем, SOC, членами наших команд глобальной аналитики (GReAT), AMR, CFR, форензики. В общем, для аналитика-incident handler руководство такой командой — серьезная ответственность, требующая опыта и экспертизы.
В качестве последнего важного шага мы дали аналитикам возможность участвовать в перестройке и доработке уже существующих IT-/ИБ-процессов, сервисов и продуктов, а также включили в процесс разработки новых. Ведь подразделение ИБ — одно из ключевых заказчиков для R&D «Лаборатории Касперского», а наши аналитики IRT стали настоящими продуктовыми визионерами.
Менее глобально, но по-человечески приятно: смены 24/7 мы заменили на обычный график 8/5 в московском офисе. Конечно, полностью устранить ночные алармы не удалось, это просто невозможно по очевидным причинам. Вероятность подняться ночью из-за внезапного инцидента остается, но как минимум сидеть на смене ночью в ожидании (нередко напрасном) этого инцидента больше не приходится.
Это не единственная комфортная плюшка: аналитикам (и сотрудникам в целом) компания помогает релоцироваться в Москву. Компенсирует переезд, проживание, риелтора, а также выдает подъемные.
Итак, какие задачи стоят перед нашими security-аналитиками.

Основа основ, работа аналитика всегда так или иначе связана с выявлением IoC. Как их помогают выявить те или иные задачи, я расскажу дальше.
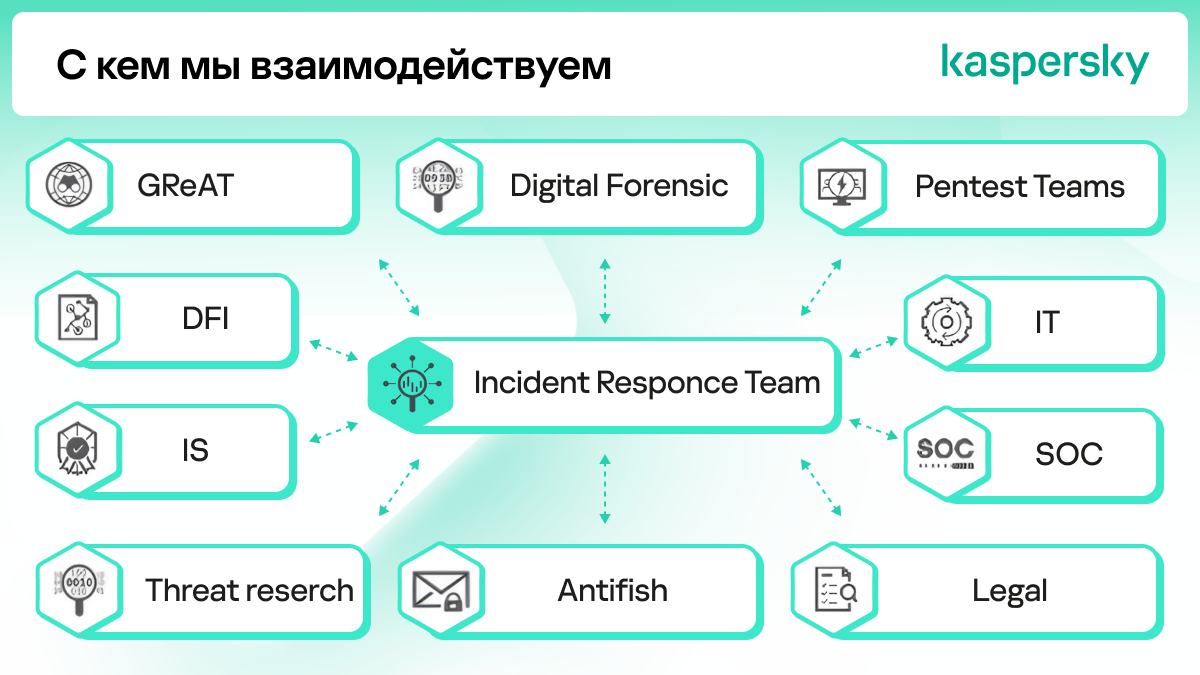
Итак, большая часть инцидентов расследуется самостоятельно аналитиком IRT. Но в сложных кейсах security-аналитик становится главой виртуальной команды, где собраны ключевые эксперты — от спецов по сетевым технологиям и представителей SOC до уже упомянутой GReAT и форензики.
Для эффективного реагирования на инцидент нужно, чтобы аналитик мог со всеми экспертами общаться на их языке. Поэтому специалист должен разбираться во множестве сфер: чем глубже экспертиза в ИБ и IT, тем лучше. Еще, конечно, нужны софт-скилы — и благо развиваются они на этих задачах быстро.
Условно говоря, нужно в достаточной мере разбираться в сетевых технологиях, чтобы, покопавшись в SIEM, уметь проанализировать конкретные конфигурации файерволов, обнаружить IoC в сетевом траффике. Потом провести забор артефактов и первичный форензик-анализ, обсудить с реверс-инженером строки в найденном эксплойте. Далее, на основе полученных данных вернуться с задачей в SOC… В общем, вы поняли.
По окончании реагирования аналитик в отчете объясняет клиенту, как митигировать риски, устранить недостатки в инфраструктуре или при необходимости перестроить процессы ИБ. Кто этот клиент? То же подразделение ИБ, в котором сам аналитик работает. То есть, написав отчет, наш аналитик не заканчивает работу с инцидентом, а только начинает ее: ему предстоит напрямую участвовать в митигации. В зависимости от ситуации он может помогать коллегам или даже быть основным ответственным за митигацию.
Благодаря этой работе аналитики сами нацелены писать четкие и подробные отчеты по митигации: по этим отчетам потом будет работать все управление ИБ, в том числе с привлечением самого аналитика. А разноплановые задачи помогают аналитику глубоко развиваться не только в мониторинге, но и в построении архитектур, в управлении проектами, в DevSecOps…
Автоматизация — одна из центральных задач для security-аналитика. Главный показатель эффективности респонса — уменьшение времени реагирования и, соответственно, снижение потенциального ущерба.
Чтобы автоматизировать плейбуки, используем скрипты и порталы для реагирования. Так, помимо классических автоматизированных плейбуков по почтовым угрозам, малвари или сетевым атакам, мы автоматизируем интеграции между внутренними сервисами: например MDR как источником телеметрии, базой данных TR, KUMA и CMDB и другими системами. Все четыре системы завязаны в рамках одного плейбука, и если мы выявляем вредоносные пакеты на машинах разработчиков или сборочных конвейерах, то при срабатывании сигнатуры KUMA автоматически через API сигнализирует в CMDB, чтобы та выслала бы письмо зааффекченному сотруднику или, если возможно, заблокировала бы конвейер и уведомила сервис-менеджера. Плюс у нас грядет релиз собственной SOAR-платформы (Security Orchestration, Automation and Response): мы и в сфере автоматизации выходим на новый уровень зрелости.
Также стоит отметить собственные разработки аналитиков группы. Для оптимизации ресурсов и времени респонса внутри группы разрабатываем фреймворки, позволяющие сократить временные затраты (в некоторых случаях кратно) на многие рутинные процессы, которых не избежать во время респонса по большинству инцидентов. Многие внутренние разработки группы после выхода в «прод» начинают пользоваться спросом у коллег в других смежных подразделениях.
Threat Intelligence — буквально означает: сбор и обработка информации о текущих угрозах на рынке, анализ атак и уязвимостей.
Мы постоянно на связи с нашими коллегами из других подразделений и других компаний, сами пишем парсеры интересных источников информации об угрозах Internet и DarkNet — и, например, когда от коллег из Threat Research мы получаем информацию о какой-то свежей уязвимости, то аналитики тут же по процедуре начинают ее анализировать. Проводят анализ применимости. Ищут следы компрометации по известным IoC. Разбираются, что будет, если кто-то с эксплойтом для этой уязвимости попробует нас атаковать, и как этого избежать либо обнаружить. Разрабатывают правила, по которым команды мониторинга будут выявлять потенциальные атаки.
В общем, все выстроено так, чтобы информация приходила как можно быстрее и обрабатывалась в максимально автоматическом режиме.
Threat Hunting — более проактивная штука. А не взломали ли нас уже каким-нибудь продвинутым способом? Может, мы просто не заметили, а злоумышленник уже внутри нашей системы? Это парадигма здоровой паранойи: надо проверять различные гипотезы, искать иоки, акторы в логах, следы атак. Тем более у нас действительно есть злоумышленники внутри: наша собственная Red Team постоянно проверяет нас на прочность.
Естественно, TI и TH работают в связке, одна практика невозможна без другой. Эти концепции не новые, однако они сильно меняют и развивают экспертизу аналитика: он теперь проактивно ищет угрозы, а не только реагирует на уже произошедшие инциденты.
Security-аналитики в Kaspersky пишут правила корреляции для нашей собственной SIEM, которая называется KUMA (Kaspersky Unified Monitoring and Analysis Platform). Чтобы отыскать угрозу, очевидно, полезно сперва найти подозрительные события.
SIEM-системы не стоят на месте, и чем сильнее они развиваются, тем более сложные правила корреляции для них может создать аналитик. Мы уже начали применять технологии машинного обучения для выявления специфических, не всегда детектируемых классическими методами атак: наша SIEM уже сейчас позволяет описать сложные правила корреляции, которые обнаруживают атаку, через три, четыре, пять зависимостей.
Уже сейчас правила корреляции нужно напрямую связывать с правилами реагирования. Для безопасности это критично: напоминаю, что лучший респонс — быстрый респонс.

Я уже говорил, что у нас есть своя Red Team: мы с ней постоянно взаимодействуем в рамках полноценной Purple Team. Иногда ребята из красной команды нас атакуют по классической схеме: происходит неанонсированная атака от Red Team, мы защищаемся, а после нее обе стороны пишут отчеты. «Красные» рассказывают, как нас ломали, а мы — какие индикаторы атаки заметили, какие не заметили, на основе этого делаем выводы.
Также мы часто создаем совместную виртуальную группу для эмулирования какой-либо угрозы. Если мы считаем, что существует метод проэксплуатировать уязвимость либо развить атаку, которые не покрыты нашим мониторингом, то зовем красную команду. Они эмулируют атаку, мы наблюдаем за телеметрией, выясняем, чего нам не хватает, меняем процессы, ребята повторяют взлом, и так — пока не поймем, что все покрыто телеметрией и детектирующими правилами.
Красная команда также прокачивается в рамках этой же активности: ищет новые пути и лазейки. Например, мы тестируем выявление туннелей. Нам ребята в чат пишут: туннель с такими-то параметрами построили, видите? Видим. Они уходят, возвращаются позже: окей, построили с другими параметрами, видите? Выясняется, что теперь не видим, то есть надо исправлять.
Киберполигон — среда для обучения и тренировки аналитиков, и это не просто два сервера, развернутых на гипервизоре, как часто бывает. У нас более продвинутый подход — мы применяем подход Infrastructure as a code и используем Terraform, Ansible, Vagrant, чтобы добавить как можно больше автоматизации, сделать среду тонко настраиваемой и эффективной.
В 2024 году мы планируем сделать так, чтобы любую инфраструктуру — хоть три, а хоть тридцать серверов с тремя доменными лесами и в различных конфигурациях — можно было бы развернуть уже не по старинке, а только лишь через скриптовые наработки и конфиг-файлы.
Но главное, на киберполигоне удобно самостоятельно, без участия Red Team, имитировать атаки на копию реальной инфраструктуры через автоматизированные фреймворки. А можно добавить в такую копию приложения, серверы, сервисы, которых в реальной инфраструктуре пока нет, — и тогда тренировки становятся максимально проактивными: здесь уже можно прогонять векторы и смотреть на срабатывания, что дает возможность писать правила на будущее и опережать грядущие угрозы, развивая Threat Hunting.
Security-аналитик в Kaspersky борется с самыми продвинутыми угрозами. Значит, ему нужны самые современные средства защиты. И поэтому он становится security-евангелистом.
По возможности мы в ИБ стараемся использовать только собственные разработки. Поэтому аналитики взаимодействуют с R&D, чтобы дополнять существующие продукты и разрабатывать новые. Это не разовая ситуация: в подразделении безопасности рождается идея, а R&D воплощает ее в жизнь. Например, так появилась уже упомянутая выше KUMA. Один из наших аналитиков, к слову, возглавил подразделение ее разработки. Та же история с нашим EDR, Endpoint Detection and Response.
Еще один яркий пример — наша KATA. Та самая, появлению которой мы с товарищами так радовались в 2014 году. Тогда у нас было немного возможностей детектировать сетевые и почтовые угрозы, поэтому мы выдвигали к зарождающейся KATA много требований, постоянно были в контакте с R&D. А вскоре после ее релиза мы поймали с ее помощью мощные целевые атаки. Самая громкая из них, наверное, Duqu 2.0.
От KATA нам нужен был глобальный IDS для всей инфраструктуры, почтовый анализ, «песочница», работа с правилами YARA, обработка телеметрии с эндпоинтов. В скором времени нашим аналитикам понадобились средства удаленного реагирования, съема артефактов и форензики. Сейчас почти весь функционал KATA реализован и развивается в соответствии с нашими требованиями.
Все те сервисы и продукты, которые мы разрабатываем, мы прежде всего тестируем на себе, а когда они достигают зрелости — выводим на рынок. Так что быть евангелистами в этом плане тоже важно — ты отчасти определяешь развитие будущих клиентских продуктов.
В целом, как видите, задач много, они сложные, разнообразные и интересные. Но в этом контексте мне нравится пословица, что просить надо не о малой ноше, а о крепких плечах. Амбициозный эксперт, который имеет за плечами уже три-пять лет опыта в ИБ или SOC, либо же матерый Threat Hunter со знаниями в Python или Go и глубоко разбирающийся в Linux, став security-аналитиком, смогут развить эти скилы до высочайшего уровня. Не побоюсь показаться нескромным: мои коллеги по уровню своей экспертизы сравнимы с Head of SOC целого ряда других компаний.
Мы активно ищем экспертов в нашу команду и готовы инвестировать в их развитие. Даже если отдельных навыков недостает, то компания поможет их прокачать: в моей команде аналитики параллельно с работой учатся на разных курсах, в том числе от того самого SANS Institute.
Так что, если мой рассказ заинтересовал и захотелось попробовать себя в роли security-аналитика эпохи Возрождения, откликайтесь!
А что дальше? А дальше — переключился на новый инцидент или ожидает его появления. В крайних случаях — участие в расследовании инцидентов и разработка новых сценариев выявления атак.
Такова «хрестоматийная», стандартная схема работы аналитика в коммерческом SOC. Это и не хорошо, и не плохо — это, как правило, просто данность. Однако формат действий security-аналитика можно сделать кардинально иным, и за счет этого помочь амбициозному специалисту расти быстрее и шире, а компании-заказчику — дополнительно укрепить свою безопасность.
Я, Никита Чистяков, тимлид команды security-аналитиков в «Лаборатории Касперского». Под катом я расскажу, как и зачем в Kaspersky помогаю выстраивать новые условия работы для security-аналитиков и как эти условия помогают им стать эдакими витрувианскими ИБшниками эпохи Возрождения.
Если вы сами аналитик или в целом работаете в инфобезе, хотите узнать, какой скрытый потенциал есть у профессии и как его раскрыть, эта статья — для вас.
Почему нам понадобилось развивать security-аналитиков
Я пришел в «Лабораторию Касперского» около 12 лет назад и все десятилетие постоянно рос вместе с компанией. Каждый этап этого совместного роста — очередная доминошка в ряду, который вел к тому, что компании стало необходимо развивать зрелых security-аналитиков.
2014 год. Команде ИБ не хватает продукта для защиты от таргетированных атак, и мы совместно с нашим R&D запускаем его разработку. Один из таких продуктов — наша платформа Kaspersky Anti-Target Attack (KATA). Вскоре в отсутствии SOC мы сами себе аналитики мониторинга и активно разбираем первые алерты от KATA и других источников. Нас мало, логов становится больше, а будет еще больше; значит, нужны более зрелые процессы.
2015 год. Нам стало очевидно, что пора создавать собственный SOC, который будет работать и для нас, как внутреннего заказчика, и для внешних клиентов. Поэтому участвуем в формировании SOC-команды внутри R&D — помогаем набрать первых в компании SOC-аналитиков. Объем покрытия телеметрии растет, развиваются *DR-сервисы, а мониторинг угроз идет теперь 24/7.
2020 год. SOC разросся до полусотни человек, аналитики в нем занимаются мониторингом и первичным реагированием на инциденты, а сложные внутренние кейсы передают для реагирования специалистам, менеджерам и архитекторам отдела ИБ. Сотрудники ИБ — мастера своих специальностей, но реагирование на инциденты для них — задача зачастую непрофильная, им приходится буквально отрываться от собственной важной работы, из-за чего проекты ИБ по развитию, аудиту, внедрению требований могут отодвигаться и простаивать.
При этом количество телеметрии по-прежнему растет, поиск информации об атакованных ресурсах, серверах или учетках может занимать несколько драгоценных часов, а реагирование в худшем случае может длиться и месяц. Поэтому требовался новый уровень зрелости — выделенная группа экспертов, каждый из которых будет полноценным incident handler и сможет выстроить эффективные процессы реагирования. Чтобы, получая от SOC информацию о каком-либо сложном инциденте, такой специалист смог в сверхкороткое время ее проанализировать, определить критичность ситуации, а затем либо отработать ее самостоятельно, либо собрать виртуальную команду реагирования из разных экспертов в компании, распределить задачи между ее участниками, чтобы сократить потенциальный ущерб. А по итогам решения этих задач такой специалист совместно с коллегами разработал бы оптимальный план митигации подобных инцидентов в будущем и помог воплотить его в жизнь.
Вот и последняя доминошка в нашем ряду — перерожденный в новой роли security-аналитик. А точнее, целая команда.
Зачем самому аналитику такая трансформация
Давайте вернемся к «хрестоматийному» аналитику, про которого мы говорили в самом начале.
У такого специалиста обычно ограниченный SLA, чтобы обработать инцидент и объяснить в отчете, как его митигировать. И он, будучи в том же «хрестоматийном» пайплайне, не занимается тем, что помогает создавать и улучшать продукты, не может помогать модернизировать инфраструктуру и архитектуру ИБ, не ставит задачи по разработке для R&D и в целом мало сотрудничает с коллегами из других отделов.
Повторюсь, это и не хорошо, и не плохо: но данность такова, что после составления отчета у аналитика вообще нет никаких рычагов влияния на процессы заказчика по митигации инцидентов. А если копнуть еще глубже, у такого аналитика может быть профессиональный диссонанс: даже если у него имеется отличная идея, как митигировать последствия инцидента и предотвратить подобные ситуации в будущем, он едва ли сможет ее воплотить.
Поэтому задачи такого специалиста часто сводятся к довольно однообразной работе и мониторингу телеметрии в режиме 24/7, написанию правил корреляции. В лучшем случае с предоставлением минимальных рекомендаций.
Выходит, что амбициозный специалист может быть вымотан монотонной работой, устает от недосыпа и не растет в профессии так быстро и разнопланово, как жаждет. Чем не причины для трансформации?
Как мы способствовали трансформации
Естественно, сперва нужна техническая база — и у нас есть все необходимое: от классических железных серверов, СЗИ и до средств оркестрирования контейнеризации. Но одного только железа мало, если не налажены процессы: мы проработали их с командами Threat Intelligence и Threat Hunting, расширили способы автоматизации реагирования и других аспектов работы аналитика, определили, как будут проходить аудиты процессов SOC.
Следующим логичным шагом было сформировать те самые команды, которые будут участвовать в реагировании на сложные инциденты, — с экспертами высочайшего уровня, в том числе администраторами IT- и ИБ-систем, SOC, членами наших команд глобальной аналитики (GReAT), AMR, CFR, форензики. В общем, для аналитика-incident handler руководство такой командой — серьезная ответственность, требующая опыта и экспертизы.
В качестве последнего важного шага мы дали аналитикам возможность участвовать в перестройке и доработке уже существующих IT-/ИБ-процессов, сервисов и продуктов, а также включили в процесс разработки новых. Ведь подразделение ИБ — одно из ключевых заказчиков для R&D «Лаборатории Касперского», а наши аналитики IRT стали настоящими продуктовыми визионерами.
Менее глобально, но по-человечески приятно: смены 24/7 мы заменили на обычный график 8/5 в московском офисе. Конечно, полностью устранить ночные алармы не удалось, это просто невозможно по очевидным причинам. Вероятность подняться ночью из-за внезапного инцидента остается, но как минимум сидеть на смене ночью в ожидании (нередко напрасном) этого инцидента больше не приходится.
Это не единственная комфортная плюшка: аналитикам (и сотрудникам в целом) компания помогает релоцироваться в Москву. Компенсирует переезд, проживание, риелтора, а также выдает подъемные.
Чем занимаются трансформированные аналитики — и как свежие задачи помогают им расти
Итак, какие задачи стоят перед нашими security-аналитиками.
Выявление IoC
Основа основ, работа аналитика всегда так или иначе связана с выявлением IoC. Как их помогают выявить те или иные задачи, я расскажу дальше.
Реагирование и расследование сложных атак на инфраструктуру и сервисы «Лаборатории Касперского»
Итак, большая часть инцидентов расследуется самостоятельно аналитиком IRT. Но в сложных кейсах security-аналитик становится главой виртуальной команды, где собраны ключевые эксперты — от спецов по сетевым технологиям и представителей SOC до уже упомянутой GReAT и форензики.
Для эффективного реагирования на инцидент нужно, чтобы аналитик мог со всеми экспертами общаться на их языке. Поэтому специалист должен разбираться во множестве сфер: чем глубже экспертиза в ИБ и IT, тем лучше. Еще, конечно, нужны софт-скилы — и благо развиваются они на этих задачах быстро.
Условно говоря, нужно в достаточной мере разбираться в сетевых технологиях, чтобы, покопавшись в SIEM, уметь проанализировать конкретные конфигурации файерволов, обнаружить IoC в сетевом траффике. Потом провести забор артефактов и первичный форензик-анализ, обсудить с реверс-инженером строки в найденном эксплойте. Далее, на основе полученных данных вернуться с задачей в SOC… В общем, вы поняли.
Работа с инцидентами после отчета по митигации
По окончании реагирования аналитик в отчете объясняет клиенту, как митигировать риски, устранить недостатки в инфраструктуре или при необходимости перестроить процессы ИБ. Кто этот клиент? То же подразделение ИБ, в котором сам аналитик работает. То есть, написав отчет, наш аналитик не заканчивает работу с инцидентом, а только начинает ее: ему предстоит напрямую участвовать в митигации. В зависимости от ситуации он может помогать коллегам или даже быть основным ответственным за митигацию.
Благодаря этой работе аналитики сами нацелены писать четкие и подробные отчеты по митигации: по этим отчетам потом будет работать все управление ИБ, в том числе с привлечением самого аналитика. А разноплановые задачи помогают аналитику глубоко развиваться не только в мониторинге, но и в построении архитектур, в управлении проектами, в DevSecOps…
Организация процессов автоматизированного реагирования, разработка IR-плейбуков
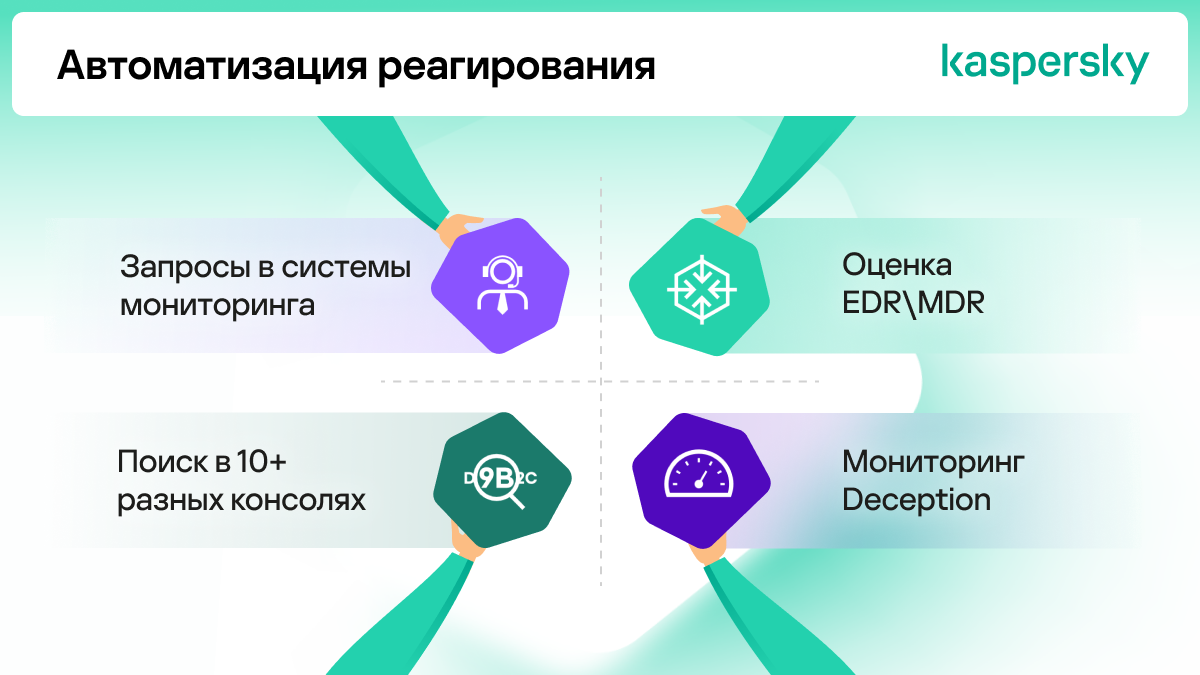
Автоматизация — одна из центральных задач для security-аналитика. Главный показатель эффективности респонса — уменьшение времени реагирования и, соответственно, снижение потенциального ущерба.
Чтобы автоматизировать плейбуки, используем скрипты и порталы для реагирования. Так, помимо классических автоматизированных плейбуков по почтовым угрозам, малвари или сетевым атакам, мы автоматизируем интеграции между внутренними сервисами: например MDR как источником телеметрии, базой данных TR, KUMA и CMDB и другими системами. Все четыре системы завязаны в рамках одного плейбука, и если мы выявляем вредоносные пакеты на машинах разработчиков или сборочных конвейерах, то при срабатывании сигнатуры KUMA автоматически через API сигнализирует в CMDB, чтобы та выслала бы письмо зааффекченному сотруднику или, если возможно, заблокировала бы конвейер и уведомила сервис-менеджера. Плюс у нас грядет релиз собственной SOAR-платформы (Security Orchestration, Automation and Response): мы и в сфере автоматизации выходим на новый уровень зрелости.
Также стоит отметить собственные разработки аналитиков группы. Для оптимизации ресурсов и времени респонса внутри группы разрабатываем фреймворки, позволяющие сократить временные затраты (в некоторых случаях кратно) на многие рутинные процессы, которых не избежать во время респонса по большинству инцидентов. Многие внутренние разработки группы после выхода в «прод» начинают пользоваться спросом у коллег в других смежных подразделениях.
Threat Intelligence и Threat Hunting
Threat Intelligence — буквально означает: сбор и обработка информации о текущих угрозах на рынке, анализ атак и уязвимостей.
Мы постоянно на связи с нашими коллегами из других подразделений и других компаний, сами пишем парсеры интересных источников информации об угрозах Internet и DarkNet — и, например, когда от коллег из Threat Research мы получаем информацию о какой-то свежей уязвимости, то аналитики тут же по процедуре начинают ее анализировать. Проводят анализ применимости. Ищут следы компрометации по известным IoC. Разбираются, что будет, если кто-то с эксплойтом для этой уязвимости попробует нас атаковать, и как этого избежать либо обнаружить. Разрабатывают правила, по которым команды мониторинга будут выявлять потенциальные атаки.
В общем, все выстроено так, чтобы информация приходила как можно быстрее и обрабатывалась в максимально автоматическом режиме.
Threat Hunting — более проактивная штука. А не взломали ли нас уже каким-нибудь продвинутым способом? Может, мы просто не заметили, а злоумышленник уже внутри нашей системы? Это парадигма здоровой паранойи: надо проверять различные гипотезы, искать иоки, акторы в логах, следы атак. Тем более у нас действительно есть злоумышленники внутри: наша собственная Red Team постоянно проверяет нас на прочность.
Естественно, TI и TH работают в связке, одна практика невозможна без другой. Эти концепции не новые, однако они сильно меняют и развивают экспертизу аналитика: он теперь проактивно ищет угрозы, а не только реагирует на уже произошедшие инциденты.
Разработка и внедрение сценариев детектирования сложных атак в SIEM
Security-аналитики в Kaspersky пишут правила корреляции для нашей собственной SIEM, которая называется KUMA (Kaspersky Unified Monitoring and Analysis Platform). Чтобы отыскать угрозу, очевидно, полезно сперва найти подозрительные события.
SIEM-системы не стоят на месте, и чем сильнее они развиваются, тем более сложные правила корреляции для них может создать аналитик. Мы уже начали применять технологии машинного обучения для выявления специфических, не всегда детектируемых классическими методами атак: наша SIEM уже сейчас позволяет описать сложные правила корреляции, которые обнаруживают атаку, через три, четыре, пять зависимостей.
Уже сейчас правила корреляции нужно напрямую связывать с правилами реагирования. Для безопасности это критично: напоминаю, что лучший респонс — быстрый респонс.
Развитие процессов Purple Team
Я уже говорил, что у нас есть своя Red Team: мы с ней постоянно взаимодействуем в рамках полноценной Purple Team. Иногда ребята из красной команды нас атакуют по классической схеме: происходит неанонсированная атака от Red Team, мы защищаемся, а после нее обе стороны пишут отчеты. «Красные» рассказывают, как нас ломали, а мы — какие индикаторы атаки заметили, какие не заметили, на основе этого делаем выводы.
Также мы часто создаем совместную виртуальную группу для эмулирования какой-либо угрозы. Если мы считаем, что существует метод проэксплуатировать уязвимость либо развить атаку, которые не покрыты нашим мониторингом, то зовем красную команду. Они эмулируют атаку, мы наблюдаем за телеметрией, выясняем, чего нам не хватает, меняем процессы, ребята повторяют взлом, и так — пока не поймем, что все покрыто телеметрией и детектирующими правилами.
Красная команда также прокачивается в рамках этой же активности: ищет новые пути и лазейки. Например, мы тестируем выявление туннелей. Нам ребята в чат пишут: туннель с такими-то параметрами построили, видите? Видим. Они уходят, возвращаются позже: окей, построили с другими параметрами, видите? Выясняется, что теперь не видим, то есть надо исправлять.
Разработка киберполигонов для отработки защиты от атак
Киберполигон — среда для обучения и тренировки аналитиков, и это не просто два сервера, развернутых на гипервизоре, как часто бывает. У нас более продвинутый подход — мы применяем подход Infrastructure as a code и используем Terraform, Ansible, Vagrant, чтобы добавить как можно больше автоматизации, сделать среду тонко настраиваемой и эффективной.
В 2024 году мы планируем сделать так, чтобы любую инфраструктуру — хоть три, а хоть тридцать серверов с тремя доменными лесами и в различных конфигурациях — можно было бы развернуть уже не по старинке, а только лишь через скриптовые наработки и конфиг-файлы.
Но главное, на киберполигоне удобно самостоятельно, без участия Red Team, имитировать атаки на копию реальной инфраструктуры через автоматизированные фреймворки. А можно добавить в такую копию приложения, серверы, сервисы, которых в реальной инфраструктуре пока нет, — и тогда тренировки становятся максимально проактивными: здесь уже можно прогонять векторы и смотреть на срабатывания, что дает возможность писать правила на будущее и опережать грядущие угрозы, развивая Threat Hunting.
Сотрудничество с R&D
Security-аналитик в Kaspersky борется с самыми продвинутыми угрозами. Значит, ему нужны самые современные средства защиты. И поэтому он становится security-евангелистом.
По возможности мы в ИБ стараемся использовать только собственные разработки. Поэтому аналитики взаимодействуют с R&D, чтобы дополнять существующие продукты и разрабатывать новые. Это не разовая ситуация: в подразделении безопасности рождается идея, а R&D воплощает ее в жизнь. Например, так появилась уже упомянутая выше KUMA. Один из наших аналитиков, к слову, возглавил подразделение ее разработки. Та же история с нашим EDR, Endpoint Detection and Response.
Еще один яркий пример — наша KATA. Та самая, появлению которой мы с товарищами так радовались в 2014 году. Тогда у нас было немного возможностей детектировать сетевые и почтовые угрозы, поэтому мы выдвигали к зарождающейся KATA много требований, постоянно были в контакте с R&D. А вскоре после ее релиза мы поймали с ее помощью мощные целевые атаки. Самая громкая из них, наверное, Duqu 2.0.
От KATA нам нужен был глобальный IDS для всей инфраструктуры, почтовый анализ, «песочница», работа с правилами YARA, обработка телеметрии с эндпоинтов. В скором времени нашим аналитикам понадобились средства удаленного реагирования, съема артефактов и форензики. Сейчас почти весь функционал KATA реализован и развивается в соответствии с нашими требованиями.
Все те сервисы и продукты, которые мы разрабатываем, мы прежде всего тестируем на себе, а когда они достигают зрелости — выводим на рынок. Так что быть евангелистами в этом плане тоже важно — ты отчасти определяешь развитие будущих клиентских продуктов.
Заключение
В целом, как видите, задач много, они сложные, разнообразные и интересные. Но в этом контексте мне нравится пословица, что просить надо не о малой ноше, а о крепких плечах. Амбициозный эксперт, который имеет за плечами уже три-пять лет опыта в ИБ или SOC, либо же матерый Threat Hunter со знаниями в Python или Go и глубоко разбирающийся в Linux, став security-аналитиком, смогут развить эти скилы до высочайшего уровня. Не побоюсь показаться нескромным: мои коллеги по уровню своей экспертизы сравнимы с Head of SOC целого ряда других компаний.
Мы активно ищем экспертов в нашу команду и готовы инвестировать в их развитие. Даже если отдельных навыков недостает, то компания поможет их прокачать: в моей команде аналитики параллельно с работой учатся на разных курсах, в том числе от того самого SANS Institute.
Так что, если мой рассказ заинтересовал и захотелось попробовать себя в роли security-аналитика эпохи Возрождения, откликайтесь!
Комментарии (3)

vasyakolobok77
22.03.2024 16:59В подобных статьях, напичканных сотней узкоспециализированных аббревиатур, просто обязан был глоссарий. Soc - System on Chip? IoC - Inversion of control? Что это, для кого вообще это статья?

kost_tr
22.03.2024 16:59+2Всё верно, если тема цепляет то отклик будет
Если всё разжевать, то отклик получит дополнительно не релевантную выборку
Отличная статья!
av_sysoev
Спасибо очень интересно