
Введение
Привет Хабр! Думаю многие читали кучу книжек по поводу Hexagonal, Onion, Clean, Layer Architecture и у вас могли остаться спорные вопросы как в сложности понимания материала, так и в реализации данных подходов в ваших проектах. Сегодня я хочу затронуть тему “Организации кода” и показать насколько это важно и легко одновременно на примере Layer Architecture (Слоистая архитектура).
Сразу оговорюсь: никого не призываю использовать свой подход, это лишь субъективный взгляд исходя из моего опыта разработки приложений на Python.
В каких случаях будет полезна данная статья?
Если вы не знаете как начать реализовывать проект
Если вы сталкиваетесь с проблемой при создании файла у себя в проекте
Если не хотите, чтобы через короткий промежуток времени ваш код превратился в спагетти
Если вам нравится аккуратность не только на рабочем столе компьютера, но и в написании кода
В статье будут описаны следующие темы:
Почему организация кода так важна и в чем заключается задача программиста
Вопрос довольно банальный, но после года разработки состояние кода иногда напоминает картинку снизу.

Превращение кода в “спагетти” несёт за собой бóльшие проблемы, чем нечитаемость или его скорость, а именно: время на реализацию бизнес задач, нахождение и исправление багов в проекте становится слишком большим.
Выбор архитектурного подхода – очень спорная тема. Работая в одной из компаний, я потратил много часов на обсуждения с командой, но в итоге мы пришли к тому, что ни одна из упомянутых во введении архитектур не реализовывалась в полной мере, везде требовались какие-то доработки и уточнения. Мы забыли, что одна из важнейших задач разработчика – писать код так, чтобы он был прост в чтении другими разработчиками и масштабируемым для быстрой реализации будущих бизнес задач.
Я пришёл к выводу, что основные архитектуры – это лишь базовые знания, на основе которых мы строим собственные архитектуры, которые, в свою очередь, должны решать требуемые задачи, а хорошо организованный код помогает увеличить скорость разработки.

Слоистая архитектура как базовый выбор
Любой проект начинается со сбора требований, проектирования диаграмм и т.д., но мы пропустим эти шаги, предполагая, что сделали все необходимое и приступаем к написанию кода.
Спроектированная диаграмма отображает входные точки в приложение, обработку бизнес правил, информации, а также взаимодействие с другими приложениями. Элементы диаграммы и есть те самые слои архитектуры, по которым передвигается ваша информация. Таким образом слоистая архитектура проста в использовании и легка для восприятия и понимания большинству разработчиков.
Но использование данной архитектуры может порождать множество абстракций, которые создают зависимости между слоями. Это произойдет, если допустить следующие ошибки в вашем приложении:
Неправильно определены ответственности каждого слоя
Неправильно определены контракты между слоями
Слой входных точек
Рассмотрим пример реализации интерфейса в виде вызова “ручек”, где пользователь отправляет запрос на создание сущности.
@router.post("/api/v1/entities/", name="create_entity", status_code=status_code.HTTP_201_CREATED)
def create(self, entity: api_schemas.DTO()) -> api_schemas:
return api_schemas.from_business_layer(business_layer.create(entity=entity.to_service_model())) # обращение к слою сервисов с преобразованием моделейПочему реализовано именно так? Да всё очевидно! Во время тестирования интерфейса “общения с клиентом” происходит инкапсуляция бизнес логики, что позволяет проводить тестирование в рамках только этого слоя, а также гибко управлять типами интерфейсов будь то API, CLI или Crontab Task. Интерфейс – это входная точка в наше приложение, которая организует канал связи между клиентом и бизнес логикой, и как раз на ней лежит ответственность за преобразование моделей.

Задачи слоя:
Организация канала связи между клиентом и бизнес логикой
Валидация, сериализация, десериализация входных-выходных данных, применение различных middleware
Слой бизнес логики
Данный слой отвечает за управление информацией на основе бизнес правил. Рассмотрим пример:
def create(dto: bll_schemas.DTO()) -> bll_schemas.dto:
with database.start_session():
if database.get(**object):
raise bll_exc.DuplicateError("Object is already created")
database_entity = database_models.Entity(**object.model_dump())
database.create(session=session, object=database_entity)
return self.service_schema.from_orm(database_entity)Как вы можете заметить в примере есть правило, что сущность необходимо создать, если ее не существует. Для этого мы идём в БД за информацией на основе входных данных и проверяем есть ли там эта сущность. Работа с БД, соответственно, инкапсулирована. Это необходимо для того, чтобы тестировать только бизнес правила и то, как они влияют на управление сущностями, но не тестировать работу базы данных. Такое разделение позволяет описывать бизнес правила в одном месте и не размазывать их по всему приложению.

Задачи слоя:
Применение бизнес правил
Вызов слоя передачи/получения информации
Валидация, сериализация, десериализация входных-выходных данных
Слой выходных точек
Он отвечает за организацию и настройку канала связи с внешним источником данных. Пример:
def create(entity: Entity, session: Session) -> Entity:
try:
session.add(entity)
session.commit()
session.refresh()
except DatabaseException as exc:
session.rollback()
raise exc
return entityВыше мы описали как бы мог выглядеть create из бизнес логики для БД. Мы спрятали всю сложность управления БД в отдельный метод интерфейса, упростив бизнес логику.
При физическом управлении информацией, используя каналы взаимодействия, мы начинаем передавать информацию вовне и управлять этим каналом.

Задачи слоя:
Организация канала связи с внешним источником информации
Управление каналом связи
Масштабируемость и немного о unit тестировании
Бывают ситуации, когда с появлением новых требований к проекту рассмотренных выше слоев уже недостаточно для решения задач, поэтому они становятся всё более сложными и большими.
Описание примера
Представим, что в нашем приложении уже есть ручки Create и Delete, которые позволяют создавать и удалять определенный объект. К нам приходит бизнес и просит ручку для пересоздания объекта (Recreate). Так как у нас есть часть готового функционала, то для этого нам необходимо вызвать сначала Delete, а затем Create. Кроме этого могут появиться дополнительные условия, из-за которых придется обращаться в другие приложения, поэтому нам нужно будет описать дополнительную обработку данных. В итоге задача будет реализована, но каждая такая фича ведет к разрастанию размера кода как внутри ручек, так и в бизнес логике, чего хотелось бы избегать, чтобы код оставался более лаконичным и легким для восприятия.
Поэтому ниже представлю вам описание дополнительных слоев, которые помогают сделать код более читаемым, а масштабирование менее болезненным.
При использовании нескольких методов бизнес логики добавляется слой композит, который отвечает за создание различных сессий и вызовы этих методов, что позволяет избежать сложного кода в слое входных точек и не давать ему ответственность за управление сессиями.
Множество обращений в другие приложения решаются внутренними функциями бизнес логики, но для каждого такого обращения необходима дополнительная обработка информации, поэтому чтобы бизнес логика не разрасталась, можно выделить обработку данных в отдельный слой.
Немного о Unit-тестах. В каждой команде по-разному договариваются о том как покрывать код тестами. Часто 100% покрытие не приносит никакой пользы, а только увеличивает кодовую базу и добавляет рутины в написании тестов. Так как некоторый функционал меняется редко, его можно протестировать и вручную, а есть вещи которые в рамках Unit-тестов проверять и вовсе не нужно, например, прямое взаимодействие с БД. Поэтому полезной практикой является тестирование бизнес логики с заглушками внешних вызовов, так как там кроется основная часть логики приложения, которую необходимо разрабатывать и часто менять.
Заключение
В конечном итоге, если воспользоваться рекомендациями выше, то получится диаграмма ниже (исключил конвертацию данных у каждого слоя для простоты):
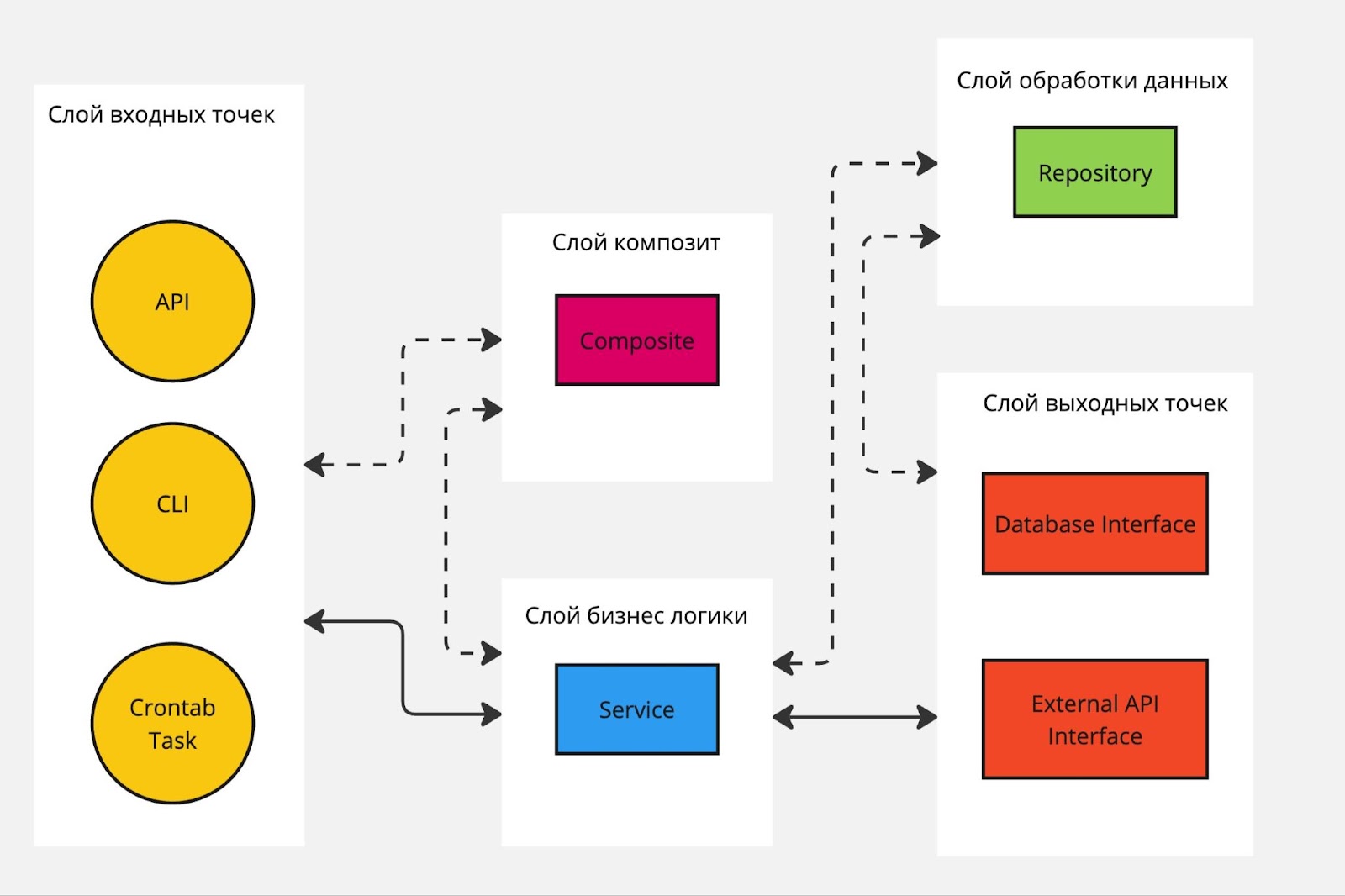
Это база, от которой можно отталкиваться для выработки своей собственной архитектуры и паттернов в команде. Данная архитектура дает гибкость разработки, более чистый код, явное распределение ответственности и более высокую скорость разработки проекта.
Как маленький бонус рекомендую книги, которые помогли в моем пути разработчика:
Паттерны разработки на Python: TDD, DDD и событийно-ориентированная архитектура. Боб Грегори, Гарри Персиваль
Чистая архитектура. Искусство разработки программного обеспечения. Мартин Роберт
Микросервисы. Паттерны разработки и рефакторинга Ричардсон Крис
Комментарии (7)

stepacool
17.04.2024 11:16+6Мне кажется тут полностью текут абстракции, слоенность нарушена, не пахнет какой-либо архитектурой, а статью писал технический писатель.
Почему в слое бизнес логики есть понятие Database? session? EntityDatabaseModel? Это все детали конкретной реализации инфраструктурного слоя, если быть точнее - orm/sql специфика. У вас могут entity создаваться через http запросы, к примеру, и вам придется все переписывать.
С нормальным расслоением у вас будет EntityRepository(к примеру) интерфейс, который можно реализовать как DatabaseEntityRepository, где в методе create уже будет вся специфика базы данных - как создание session, всякие ОРМ модели и тп. А можно реализовать как HttpEntityRepository, где уже своя специфика - работа с json и обработка статус кодов. В вашем коде все переплетено сильным coupling, слой бизнес логики зависит от слоя инфраструктуры(должно быть наоборот, если что), а DI и не пахнет.
В настоящей слоеной архитектуре слой бизнес логики не зависит от других слоев, все зависят от него. Из других слоев ничего не импортируется, а все слои зависят от слоя бизнеса, принимая и возвращая его сущности, а также реализуя его интерфейсы.
Покажу на примере, сначала ваш код:def create(dto: bll_schemas.DTO()) -> bll_schemas.dto: with database.start_session(): # Это не бизнес логика, sql специфика if database.get(**object): # специфика базы данных raise bll_exc.DuplicateError("Object is already created") # ошибка ОРМ database_entity = database_models.Entity(**object.model_dump()) # ОРМ модель database.create(session=session, object=database_entity) # вызов ОРМ return self.service_schema.from_orm(database_entity) # слой представления знает о слое архитекртурыИ как это могло быть:
def business_create(dto: EntityDomain, repo: EntityRepo) -> EntityDomain: # EntityRepo - интерфейс, можно послать любую реализацию try: res = repo.create(dto) except DuplicateError: # бизнес ошибка ... ... return resclass SQLEntityRepo(EntityRepo): # SQL-пример репозитория, EntityRepo определен в бизнес слое как абстракция для реализаций def create(self, dto: EntityDTO) -> EntityDTO: q = database_models.Entity(**object.model_dump()) try: session.add(q) session.commit() session.refresh() except DatabaseException as exc: session.rollback() raise DuplicateError # Рейзим именно бизнес ошибку return dto class HTTPEntityRepo(EntityRepo): # Http-пример репозитория def create(self, dto: EntityDTO) -> EntityDTO: res = requests.post("create-url", data=dto.dict()) if res.status_code == 409: raise DuplicateError return EntityDTO(**res.json())Детали реализации мы прячем, к примеру бизнес кейс "DuplicateError" в случае sql - это IntegrityError, а в случае http - статус код и какой-то текст в json. Бизнес слою об этому знать не надо, репозиторий обрабатывает все и выдает уже бизнес ошибку DuplicateError. В вашем же коде почему-то бизнес обрабатывает IntegrityError конкретной ORM. С кодом выше - именно бизнес слой изолирован, у нас есть интерфейс для инфраструктурного слоя, который можно реализовать как угодно, в тестах можно через DI протестировать бизнес логику, послав специальный тестовый репозиторий и т.д.
Все максимально книжно и утрированно, в реальном мире есть побольше абстракций - всякие Gateways, Interactors, UoW и тп, но для примера - это и есть слоенная архитектура.
Если честно, не понимаю, как можно прочитать хотя бы одну из книг по теме и написать то, что написано в статье. А у вас подача, словно вы перечитали их много, вот ваша цитата: "Думаю многие читали кучу книжек по поводу Hexagonal, Onion, Clean, Layer Architecture".
kasatkinilyaandreevich Автор
17.04.2024 11:16По поводу нормального расслоения, мне хотелось в статье скорее сделать акцент на то что на организацию кода необходимо уделять время чтобы потом не бить шишки, и дал слоёную архитектуру как базу от которой можно оттолокнуться. Поэтому не планировал описывать более детальное расслоение(UOW, Repository и тд.) в будущем учту что раз взялся за тему, то более детально всё описывать. Спасибо за комментарий очень полезный, надеюсь разработчики воспользуются этим дополнением к статье.

saaivs
17.04.2024 11:16+2Парадокс в том, что Layer Driven Architecture находится в противоречии с Domain Driven Architecture в смысле организации кода. С дной стороны, хочется чтоб отдельно и рядышком были тут components, тут services, тут templates и т.д. а с другой хотелось бы чтоб вот тут были User, Company, Client и т.д. и там внутри всё, что с ним связано.
Когда и первого и второго много (т.е. типичный проект средней сложности) возникает вопрос организации этого хозяйства и тут, на мой взгляд, плохи только крайности, а выходом является волевое решение в виде некоторого компромиса.
Например, как вариант, естественную иерархию domain сущностей внутри упорядочивать по плоской фиксированной layer driven структуре. Сложно сказать, какая форма порядка самая лучшая, но точно можно сказать, что если ничего такого не делать, то с точки зрения Evolutionary Driven Architecture о временем отсутствие какого-либо порядка со всей неизбежностью уткнет проект в п.24
guryanov
Да про слоистую архитектуру, мне кажется, во-первых, все знают уже со времен, когда кто-то догадался что можно на диск не байтики и секторы писать, а сделать файловую систему, чтоб по именам к областям хранения данных обращаться. Реально самая древняя архитектура наверное. А во-вторых, это самый очевидный подход, первая мысль, которая возникает в голове начинающего разработчика это: "А сложу-ка я все функции для работы с БД в один пакет, а обработку HTTP запросов - во второй".
Проблема стоистой архитектуры в том, что она очень плохо подходит для написания таких бизнес приложений. Потому что все функции и структуры, которые используются вместе лежат на разных слоях. Но при этом в каждом слое лежит набор функций, которые никак не связаны.
95% времени моя программистская работа такая: мне нужно исправить баг, доработать какую-то функциональность или сделать новую. Во всех случаях грубо говоря это какой-то один API вызов. И в идеале я должен открыть один файл и там должен быть весь код, который мне нужен в текущий момент. Понятное дело, что это только в теории возможно, так как иначе утонем в копипасте, но открывать 10 папок и по ним перемещаться очень неудобно.
В небольших приложениях любой вызов API работает по схеме handler.CreateUser -> businessLogic.CreateUser -> repo.CreateUser [-> dao.CreateUser] За исключение 5-10 "библиотечных" функций типа GetUserByID. В них вообще слоеная архитектура вредна, получается. В крупных проектах "библиотечных" функций гораздо больше получается, но все-равно слоеную архитектуру ну никак не получается назвать идеальным решением.
guryanov
Слоистая архитектура противоречит принципу Low Coupling - High Cohesion
kasatkinilyaandreevich Автор
Если я правильно понял о чём вы говорите. Согласитесь читать 1 вызов API который содержит 1000 строк это не самое приятное занятие, ведь можно всё разделить(постараться) на логические компоненты по зонам отвественности, которые вы бы могли импортировать на каждом слое по мере необходимости и проваливаться в более сложные частички кода. А не хранить это всё в одной "Ручке".
Для примера представьте вы наняли нового разработчика к себе в команду, он открывает код, а у вас в Presentation Layer весь код вашего приложения. Поверьте это сложно читаемый код и никакое переименование переменных не поможет в этой ситуации. А если бы это было разбито на "папочки и файлики", новый разработчик более быстро погрузился в процесс разработки.
Мой главный посыл был в том что стоит уделять время на организацию кода, так как это важно, а Layer Architecture не панацея как и другая архитектура.
guryanov
Опыт подсказывает, что очень часто одна функция в 1000 строк делится на 2 функции по 800 строк или на 4 функции по 600 строк. Проще одну прочитать. В целом если весь код писать в presentation то тоже можно аккуратно разбить на функции, которые все будут лежать в одном пакете.
Когда новый разработчик приходит ему наоборот, сложно окинуть взглядом весь код, проще, если он будет погружаться постепенно, по функциональным частям а не по слоям.