
Примеры кода на Python для работы с Apache Spark для «самых маленьких» (и немного «картинок»).

В прошлой статье мы рассмотрели пример создания Spark-сессий, здесь поговорим о возможностях и функция Spark для обработки данных. И теперь я смогу кидать эту статью всем своим новичкам.
Данная статья представляет собой обзор основных функций Apache Spark и рассматривает способы их применения в реальных задачах обработки данных. Apache Spark — это мощная и гибкая система для обработки больших объемов данных, предлагающая широкий спектр возможностей для аналитики и машинного обучения. В нашем обзоре мы сфокусируемся на ключевых функциях чтения, обработки и сохранения данных, демонстрируя примеры кода, которые помогут новичкам быстро включиться в работу и начать использовать эти возможности в своих проектах.
Важно понимать, что, несмотря на обширность и полезность предоставляемой информации, для глубокого понимания всех аспектов работы с Spark необходимо также ознакомиться с официальной документацией. Она содержит полное руководство по всем функциям и возможностям, а также подробные инструкции по установке, конфигурации и оптимизации работы с системой. Для дальнейшего изучения и получения более подробной информации о Apache Spark, рекомендуем посетить официальную страницу документации Apache Spark.
С основной инструкцией на руках и примерами из нашей статьи, вы будете хорошо подготовлены к началу работы
Статья сделана для быстрого поиска функций и возможностей.
№2. Обработка: анализ данных (фильтрация и сортировка, агрегация).
№ 3.1. Дополнительные опции для настройки сохранения
№1. Чтение
Чтение из таблицы
df = spark.read.table(“s_schema.new_table”)Этот метод используется для загрузки данных из таблицы в Spark DataFrame. Это удобный способ начать работу с данными, находящимися в вашем хранилище данных. Особенно полезно, когда вы работаете с хорошо структурированными данными, имеющими заранее определённую схему.
Чтение из директории
df = spark.read.parquet('/shema/dir/db/table_name/partition_1/')Этот метод позволяет загружать данные напрямую из файловой системы. Parquet — это эффективный и компактный формат хранения, который подходит для работы с большими объемами данных, так как он обеспечивает высокую степень сжатия данных и оптимизацию производительности за счет колоночного хранения.
Чтение через SQL-запрос, мы рассмотрим Hive
df = spark.sql(‘SELECT * FROM SHCEMA.NEW_TABLE’)Использование SQL-запросов в Spark позволяет вам воспользоваться всей мощью SQL для анализа данных, находящихся в вашем кластере Spark. Это особенно удобно, если вы уже знакомы с SQL. Spark SQL позволяет выполнять сложные запросы, объединения и агрегации, делая ваш код более читаемым.
Чтение CSV файлов
df = spark.read.format("csv").option("header", "true").load("path/to/file.csv")Этот метод используется для чтения CSV файлов. Опция header указывает, содержит ли первая строка заголовки столбцов. Метод load загружает файл по указанному пути. Это удобный способ для работы с табличными данными в формате CSV.
Чтение JSON файлов
df = spark.read.json("path/to/file.json")Метод read.json позволяет загружать JSON файлы напрямую в DataFrame. Spark автоматически интерпретирует структуру JSON и преобразует его в таблицу. Это особенно полезно при работе с данными, имеющими сложную вложенную структуру.
Чтение данных из JDBC источников
df = spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql://host:port/database") \
.option("dbtable", "schema.table") \
.option("user", "username") \
.option("password", "password") \
.load()
Этот метод позволяет подключаться к базам данных через JDBC. Вы можете указать URL подключения, имя таблицы, имя пользователя и пароль. Это идеально подходит для случаев, когда данные уже хранятся в реляционной базе данных и вы хотите анализировать их с помощью Spark.
Чтение Avro файлов
df = spark.read.format("avro").load("path/to/file.avro")Avro — это бинарный формат сериализации, который обеспечивает компактное, быстрое и эффективное хранение данных. Чтение данных в формате Avro позволяет легко интегрироваться с системами, которые используют этот формат для хранения данных.
Чтение текстовых файлов
df = spark.read.text("path/to/textfile.txt")Если ваши данные представлены в формате обычного текста, этот метод позволит загрузить текстовый файл как DataFrame с одним столбцом value, содержащим строки текста. Это полезно для задач анализа текста или обработки лог-файлов.
№2. Обработка: анализ данных (фильтрация и сортировка, агрегация)
Фильтрация данных
filtered_df = df.filter(df["age"] > 30)Метод filter позволяет выбирать строки по заданному условию. Это аналог SQL операции WHERE. Пример выше выбирает всех пользователей старше 30 лет.
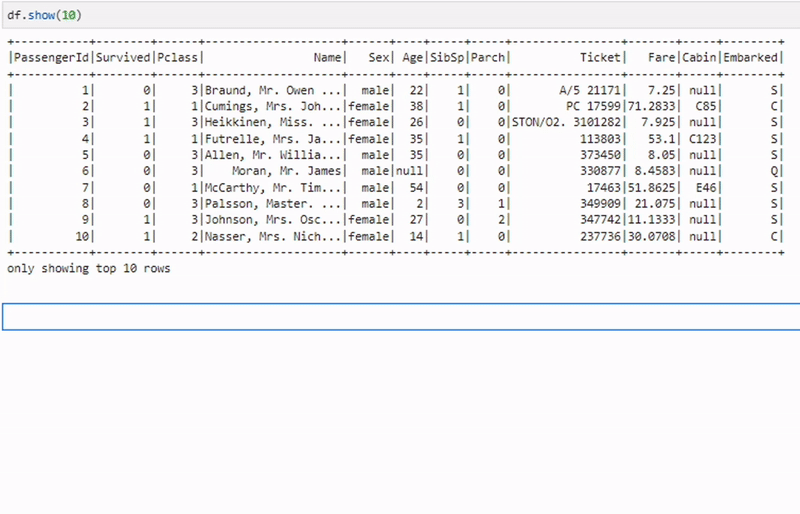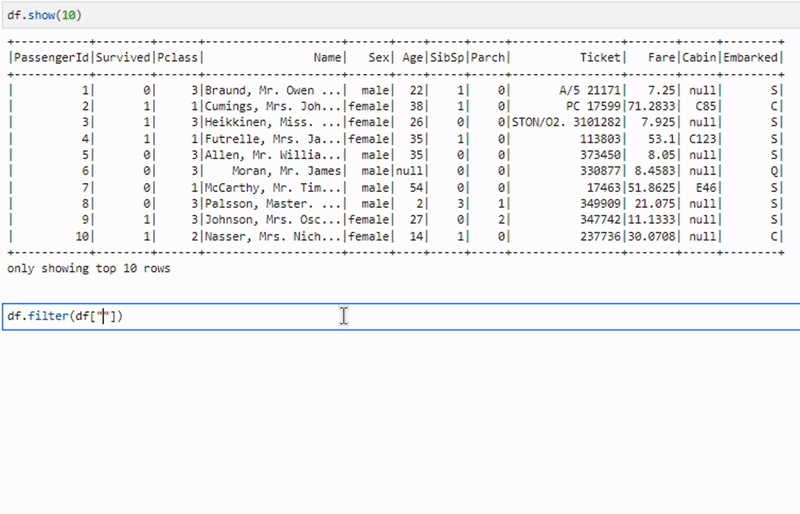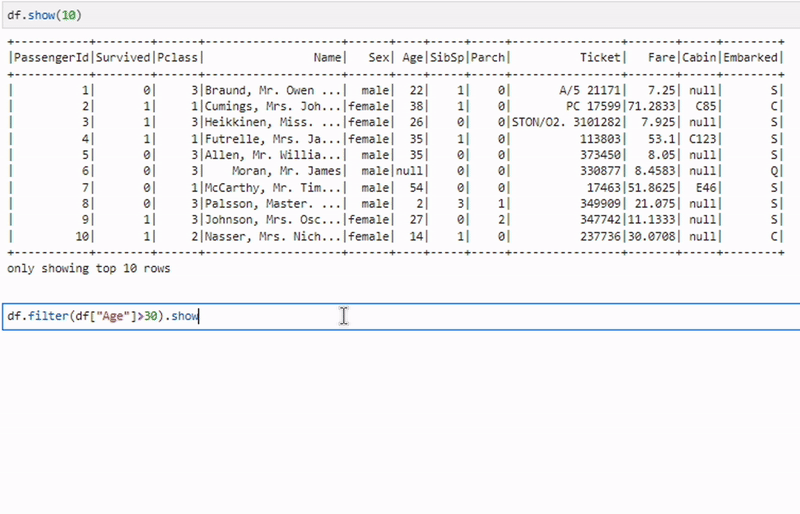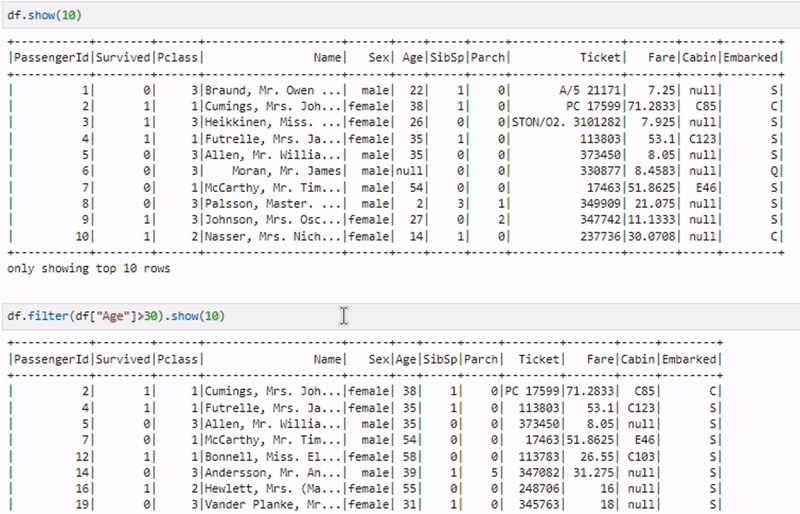
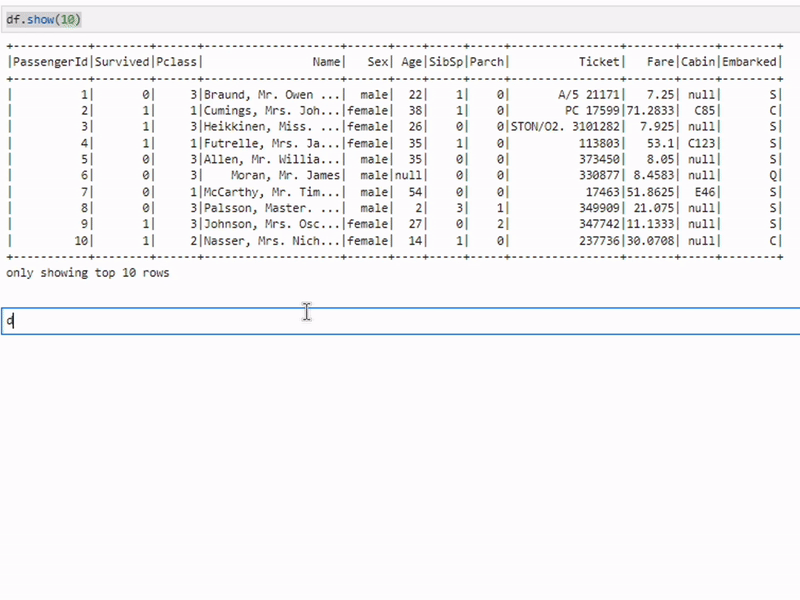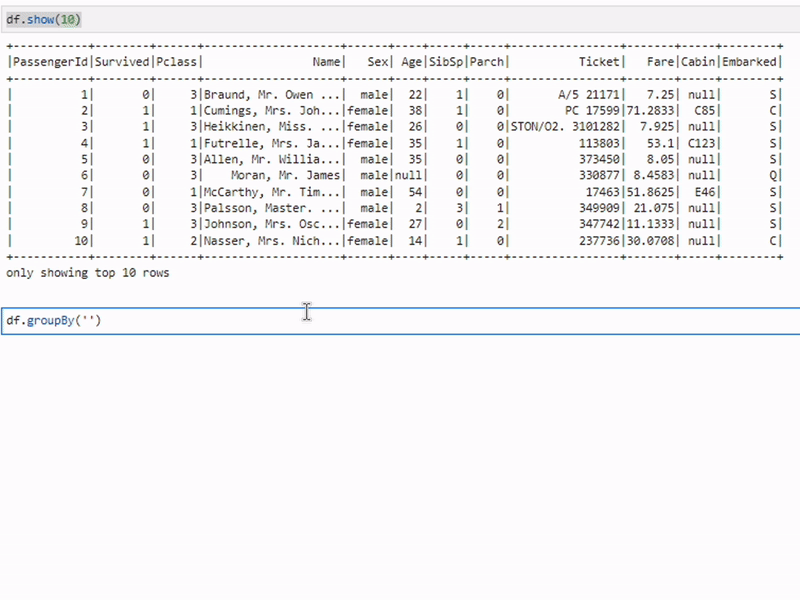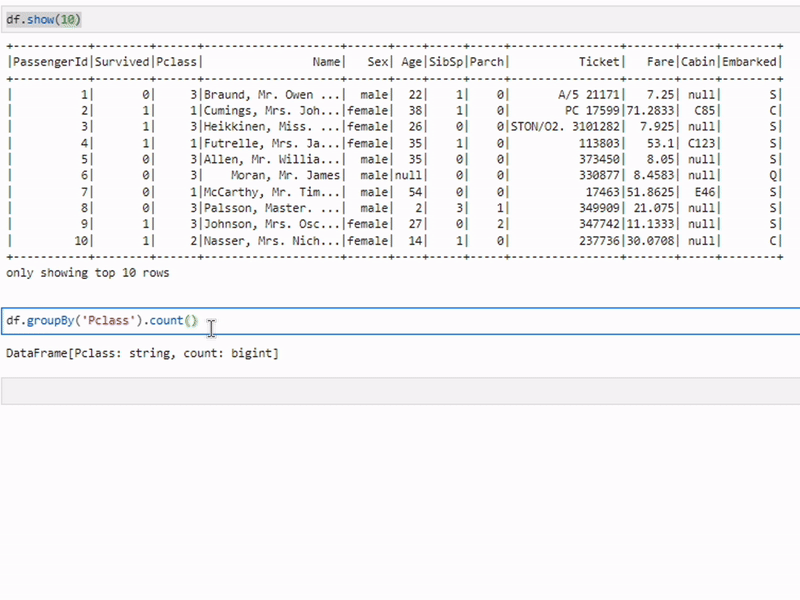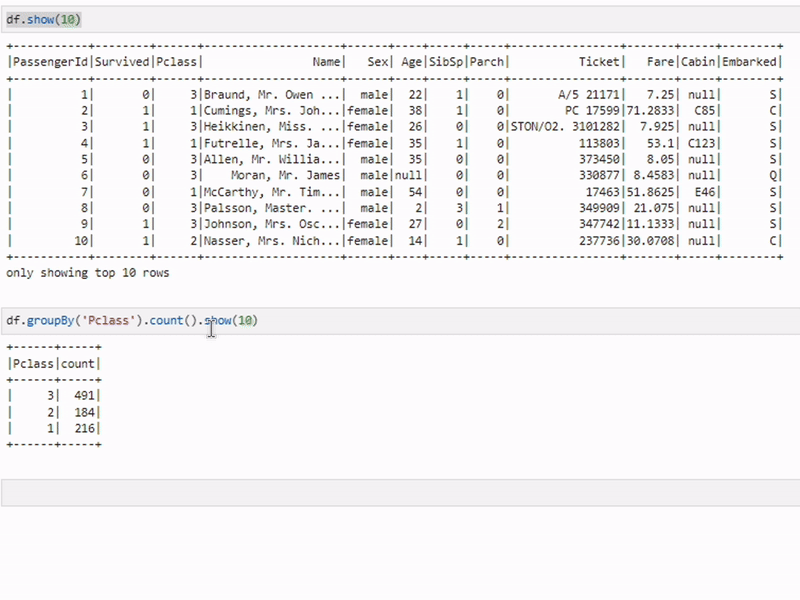
Группировка данных
grouped_df = df.groupBy("city").count()Метод groupBy используется для группировки данных по одному или нескольким столбцам и последующего выполнения агрегатных функций (например, count, max, min, avg). В данном примере подсчитывается количество записей для каждого города.
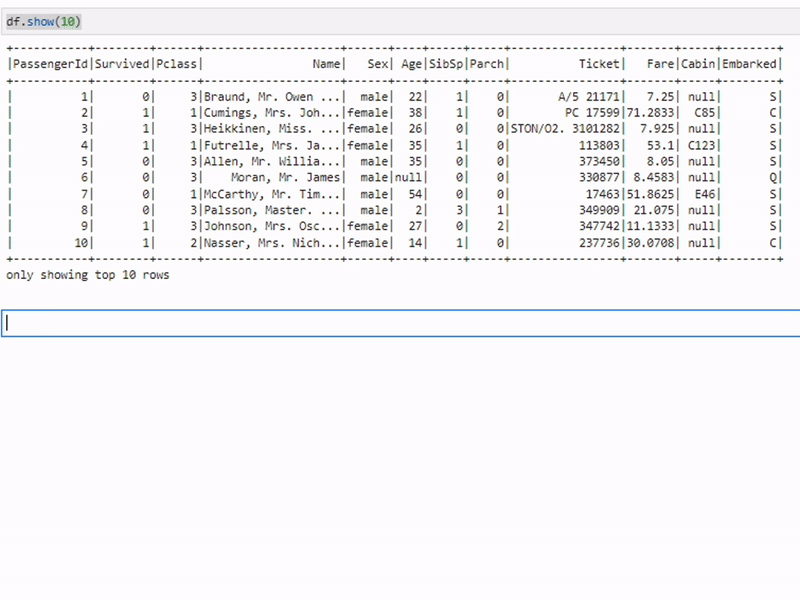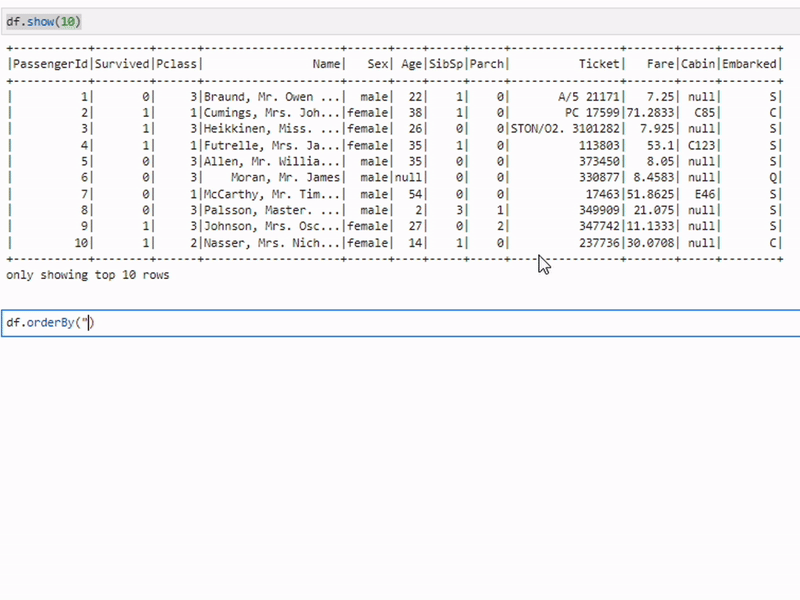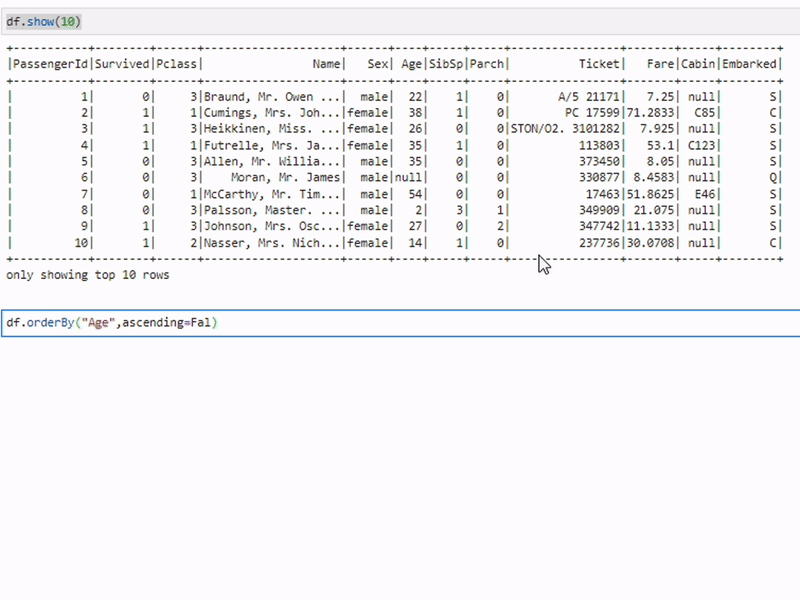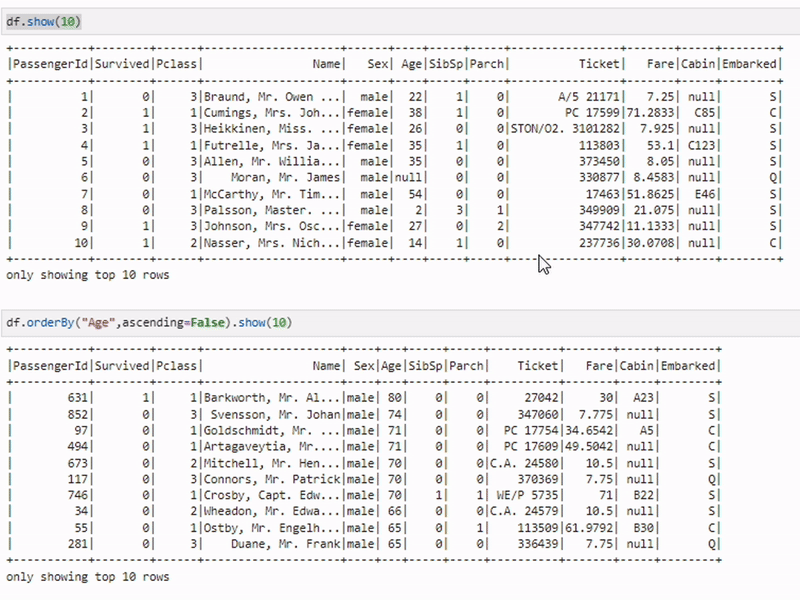
Сортировка данных
sorted_df = df.orderBy("age")Метод orderBy используется для сортировки данных по одному или нескольким столбцам. В примере данные сортируются по возрасту.
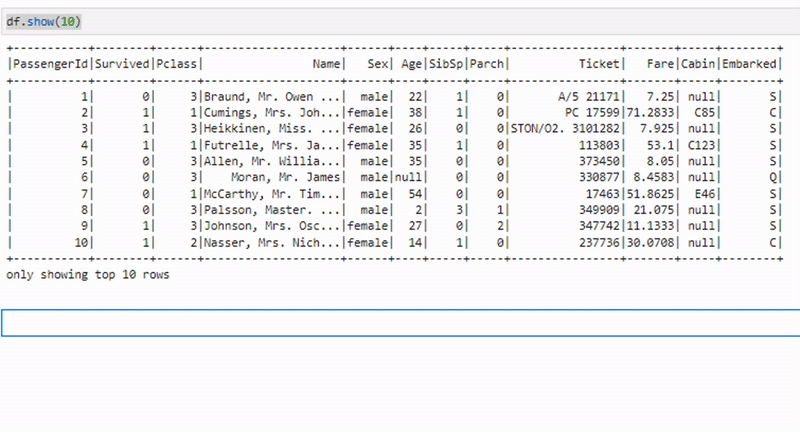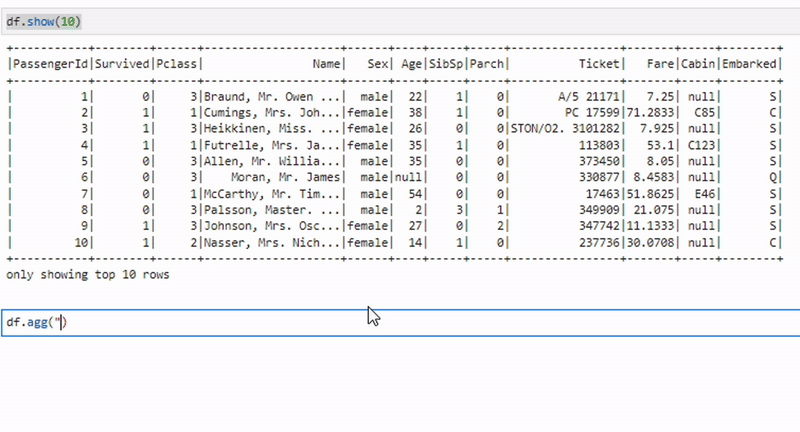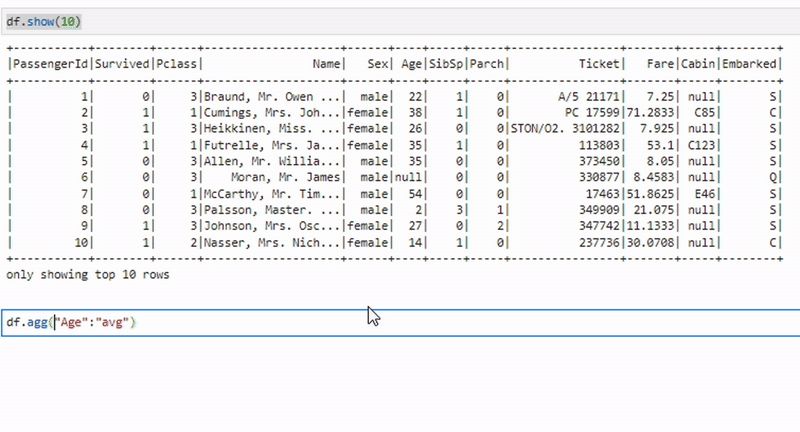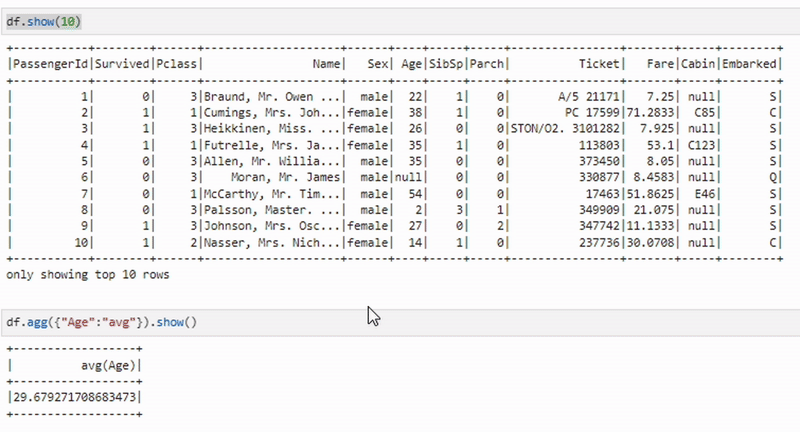
Агрегация данных
aggregated_df = df.agg({"salary": "avg"})Метод agg применяется для выполнения одной или нескольких агрегатных операций на всем DataFrame. Пример выше вычисляет среднюю зарплату.
Добавление нового столбца
df_with_new_column = df.withColumn("is_adult", df["age"] >= 18)withColumn добавляет новый столбец или перезаписывает существующий, используя выражение или значение. В данном случае добавляется столбец, показывающий, является ли человек взрослым.
Удаление столбца
df_without_column = df.drop("is_adult")Метод drop удаляет столбец из DataFrame. В примере удаляется столбец is_adult.
Изменение типа данных столбца
df_with_casted_column = df.withColumn("age", df["age"].cast("integer"))Изменение типа данных столбца может быть выполнено с помощью метода cast, который используется в withColumn.
Разделение столбца
split_col = pyspark.sql.functions.split(df["name"], " ")
df_with_split_columns = df.withColumn("first_name", split_col.getItem(0))
df_with_split_columns = df_with_split_columns.withColumn("last_name", split_col.getItem(1))
Метод split из модуля pyspark.sql.functions разделяет строку столбца на массив подстрок. getItem используется для извлечения элементов из массива.
Объединение таблиц (JOIN)
joined_df = df1.join(df2, df1["id"] == df2["user_id"], how='inner')JOIN используется для объединения двух DataFrame'ов по одному или нескольким ключам. В параметре how можно указать тип JOIN (например, inner, outer, left_outer, right_outer).
Применение пользовательских функций (UDF)
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType
def square(x):
return x * x
square_udf = udf(square, IntegerType())
df_with_square = df.withColumn("squared_value", square_udf(df["value"]))User Defined Functions (UDF) позволяют применять пользовательские функции на данные в DataFrame. В этом примере создается UDF для возведения числа в квадрат.
Эти методы представляют собой основу для манипулирования и анализа данных в Spark и могут быть комбинированы для решения сложных задач обработки больших объемов данных.
№3. Запись данных в Spark
Запись данных в файлы CSV
df.write.format("csv").option("header", "true").save("path/to/save/file.csv")Этот метод позволяет сохранить DataFrame в формате CSV. Опция header указывает на необходимость добавления строки с заголовками столбцов в файл.
Запись данных в формате Parquet
df.write.parquet("path/to/save/file.parquet")Parquet — это колончатый формат хранения данных. Запись данных в Parquet эффективна по скорости и позволяет существенно экономить место на диске.
Запись данных в формате JSON
df.write.json("path/to/save/file.json")JSON широко используется для хранения структурированных данных. Spark позволяет сохранять данные в формате JSON, что удобно для дальнейшего использования в веб-приложениях и системах, которые поддерживают JSON.
Запись в базы данных через JDBC
df.write \
.format("jdbc") \
.option("url", "jdbc:mysql://host:port/database") \
.option("dbtable", "table_name") \
.option("user", "username") \
.option("password", "password") \
.save()
Этот метод позволяет сохранять DataFrame непосредственно в реляционную базу данных через JDBC. Это может быть полезно для интеграции с легаси системами и прямого доступа к данным через SQL.
Запись в формате ORC
df.write.orc("path/to/save/file.orc")ORC (Optimized Row Columnar) — это формат хранения данных, оптимизированный для больших объемов данных. Он обеспечивает эффективное сжатие и производительность, что делает его подходящим для использования в больших дата-лейках.
Запись с разбиением по партициям
df.write.partitionBy("year", "month").parquet("path/to/save")Этот метод позволяет разделить данные по указанным столбцам (в этом случае по году и месяцу), что упрощает управление данными и оптимизирует процесс чтения при необходимости доступа только к определенным сегментам данных.
Запись с использованием режима перезаписи
df.write.mode("overwrite").parquet("path/to/save/file.parquet")Режим overwrite указывает Spark на необходимость удаления существующих данных перед записью новых. Это полезно при обновлении данных в хранилище.
Запись с использованием режима добавления
df.write.mode("append").parquet("path/to/save/file.parquet")В режиме append новые данные добавляются к уже существующим без удаления предыдущих данных. Это подходит для ситуаций, когда данные должны накапливаться со временем.
Запись в таблицу Hive
df.write.saveAsTable("database.table_name")Метод saveAsTable позволяет сохранять DataFrame непосредственно в Hive таблицу, что интегрирует данные с экосистемой Hadoop и позволяет их использовать в различных Big Data приложениях.
Запись с InsertInto
Метод insertInto выполняет вставку данных в указанную таблицу. Он требует, чтобы структура DataFrame совпадала со структурой целевой таблицы, включая названия и типы столбцов. Если структура DataFrame и таблицы не совпадает, операция завершится ошибкой.
#Параметры метода:
tableName: имя таблицы, в которую будут вставлены данные. Это имя может включать имя базы данных (например, database.table).
mode: режим записи данных, может принимать значения:
append— данные добавляются к существующим в таблице;overwrite— существующие данные в таблице удаляются перед вставкой новых (это поведение может зависеть от настроек конфигурации Spark и Hive).
Добавление данных в таблицу
df.write.mode("append").insertInto("my_database.my_table")В этом примере данные из df добавляются к данным, уже существующим в таблице my_table базы данных my_database.
Перезапись данных в таблице
df.write.saveAsTable("database.table_name")Здесь данные в my_table будут полностью заменены данными из df. Важно отметить, что в зависимости от настроек Hive, операция может не только заменить данные в указанной таблице, но и удалить все предыдущие партиции, что может повлиять на производительность запросов к данным.
ВНИМАНИЕ НЕ ПОВТОРЯЙТЕ — ОПАСНО ДЛЯ ЖИЗНИ!!
insertInto и удаление партиций
Сценарий использования insertInto с удалением партиций.
Предположим, у нас есть партиционированная таблица sales в Hive, которая разделена по годам и месяцам (year, month). Если мы используем метод insertInto в режиме overwrite для вставки данных в эту таблицу, это может привести к удалению всех существующих партиций, если не указать конкретные партиции для записи.
df.write.mode("overwrite").insertInto("database.sales")#Почему это происходит?
Когда Spark выполняет операцию overwrite без явного указания партиций, он может интерпретировать это как необходимость замены всех данных в таблице, включая все партиции. В результате Spark удалит все существующие партиции в таблице sales и заменит их данными из df. Это поведение может быть крайне нежелательным, особенно, если в таблице хранится много данных, разделённых по партициям для оптимизации запросов.
#Как предотвратить нежелательное удаление партиций?
1) Явное указание партиций при записи.
Указывая партиции при записи, можно контролировать, какие именно партиции должны быть перезаписаны. Например, если мы хотим перезаписать данные только за конкретный месяц и год:
df.write.mode("overwrite").partitionBy("year", "month").insertInto("database.sales")В этом случае Spark перезапишет только те партиции, которые соответствуют году и месяцу в данных df, а остальные останутся нетронутыми.
2) Использование настроек конфигурации.
В некоторых случаях можно настроить поведение Spark и Hive для более тонкой работы с партициями. Например, настройка spark.sql.sources.partitionOverwriteMode в Spark может быть установлена в dynamic, что позволяет Spark динамически определять, какие партиции должны быть перезаписаны, основываясь на содержимом DataFrame.
spark.conf.set("spark.sql.sources.partitionOverwriteMode","dynamic")
df.write.mode("overwrite").insertInto("database.sales")
Рекомендации.
Всегда тщательно проверяйте настройки Spark и Hive при работе с
insertInto, особенно при использованииoverwrite.При работе с критически важными данными рекомендуется сначала тестировать операции записи на небольших объемах данных или в тестовой среде, чтобы избежать потери данных.
При необходимости использовать
overwrite, старайтесь явно указывать партиции, которые требуется перезаписать, чтобы минимизировать риск нежелательного удаления данных.
Это позволит избежать потери данных и обеспечит более контролируемое и безопасное использование Spark для обработки и сохранения больших объемов данных.
№ 3.1. Дополнительные опции для настройки сохранения
partitionBy
Позволяет указать столбцы для партиционирования данных при сохранении.
Партиционирование данных заключается в их физическом разделении по определённым ключам (столбцам), что может значительно ускорить операции чтения и записи, а также запросы, которые фильтруют данные по этим ключам. Партиционирование особенно полезно в больших распределённых системах, где управление доступом к данным и их обработка может быть дорогостоящими по времени и ресурсам.
#Пример использования partitionBy
df.write.partitionBy("country", "state").format("parquet").save("/path/to/data")#Параметры метода partitionBy
columnNames: столбцы, по которым будут разделены данные. Количество и выбор столбцов для партиционирования зависят от особенностей данных и требований к запросам.
#Преимущества использования partitionBy
Улучшение производительности чтения. Партиционирование позволяет выполнять «предварительный фильтр» данных на уровне файловой системы, что снижает объём данных, загружаемых при выполнении запросов.
Оптимизация ресурсов. Партиционирование помогает управлять ресурсами, распределяя данные по файлам и директориям, что оптимизирует хранение и доступ к данным.
Масштабируемость. Партиционирование улучшает масштабируемость приложений, поскольку обработка и хранение данных становятся более эффективными.
#Рекомендации по использованию partitionBy
Выбор ключей партиционирования. Важно выбирать такие ключи партиционирования, которые часто используются в запросах для фильтрации. Это позволяет максимально использовать преимущества партиционирования.
Учёт размера партиций. Слишком маленькие или слишком большие партиции могут снижать производительность. Необходимо стремиться к равномерному распределению размера партиций.
Ограниченное количество партиций. Слишком большое их количество может привести к увеличению числа мелких файлов, что затруднит управление файловой системой и может снизить производительность.
bucketBy
Организует данные в пакеты по указанным столбцам, что может улучшить производительность запросов.
Bucketing или корзинное разбиение — это техника, которая разделяет данные на управляемые и равномерно распределённые части. Данные распределяются по бакетам на основе хэш-функции одного или нескольких столбцов. Все данные с одинаковым значением хэш-функции попадают в один бакет, что значительно ускоряет операции соединения таблиц, так как Spark может выполнять соединения локально в пределах одного бакета, минимизируя перемещение данных между узлами кластера.
#Пример использования bucketBy
df.write.bucketBy(42, "column1")
.sortBy("column2")
.saveAsTable("bucketed_table")
#Параметры метода bucketBy
numBuckets: количество бакетов, на которое будут разбиты данные. Выбор правильного количества бакетов зависит от размера данных и структуры кластера. Слишком маленькое количество бакетов может не привести к значительной оптимизации, а слишком большое может ухудшить производительность из-за накладных расходов на управление большим количеством мелких файлов.columnNames: столбцы, по которым будут сгенерированы бакеты. Эти столбцы должны быть теми же, по которым часто производятся операции соединения или агрегации, чтобы максимизировать эффективность.
#Преимущества использования bucketBy
Улучшение производительности соединений. При соединении двух таблиц, разбитых по одним и тем же столбцам, Spark может выполнять соединение бакетов независимо друг от друга, что сокращает время выполнения запроса.
Оптимизация агрегации. Агрегации по ключам, по которым выполнено bucketing, могут быть оптимизированы, так как данные уже сгруппированы по нужным ключам.
Уменьшение перемещения данных. Поскольку данные локализованы по бакетам, перемещение данных по сети (shuffle) при соединениях и агрегациях минимизируется.
#Рекомендации по использованию bucketBy
Тестирование. Начните с меньшего числа бакетов и увеличивайте количество, наблюдая за изменением производительности.
Консистентность. Используйте одинаковые поля для bucketing в таблицах, которые часто соединяются между собой.
Избегайте мелких бакетов. Слишком много маленьких бакетов может привести к увеличению накладных расходов на обработку множества мелких файлов.
sortBy
Определяет столбцы, по которым будет выполнена сортировка в каждом пакете при использовании bucketBy.
sortBy позволяет указать один или несколько столбцов, по которым данные будут отсортированы внутри каждого бакета. Сортировка данных внутри бакетов может существенно повысить эффективность последующих операций, таких как соединения и оконные функции, поскольку данные, которые должны быть обработаны вместе, физически находятся ближе друг к другу.
#Пример использования sortBy
df.write.bucketBy(10, "department_id").sortBy("employee_salary").saveAsTable("employees_bucketed_sorted")#Параметры метода sortBy
columnNames: список столбцов, по которым будет выполнена сортировка внутри каждого бакета. Порядок столбцов в списке определяет приоритет сортировки
#Преимущества использования sortBy
Улучшение производительности запросов. Сортировка данных внутри бакетов позволяет Spark эффективнее проводить соединения и агрегации, поскольку данные, необходимые для этих операций, физически располагаются ближе друг к другу.
Оптимизация сканирования данных. Когда запросы требуют доступа к отсортированным данным (например, при использовании оконных функций), предварительно отсортированные бакеты могут значительно ускорить обработку.
#Рекомендации по использованию sortBy
Ограниченное использование. Используйте
sortByтолько когда есть чёткое понимание того, как запросы будут использовать данные. Неоправданное использование сортировки может привести к дополнительным накладным расходам при записи данных.Сочетание с
bucketBy. Чаще всегоsortByиспользуется в сочетании сbucketByдля оптимизации операций, которые могут извлечь выгоду из предварительно отсортированных данных.Тестирование производительности. Всегда полезно провести тестирование производительности, чтобы убедиться, что применение
sortByдействительно улучшает время ответа на запросы, особенно в больших и сложных дата-лейках.
В конце
В этой статье мы подробно разобрали основные функции Apache Spark, которые позволяют эффективно работать с большими объемами данных. От чтения различных форматов данных до сложных операций обработки и, наконец, различные способы сохранения обработанных данных — все эти возможности делают Spark мощным инструментом для анализа данных.
Использование функций чтения данных облегчает интеграцию с различными источниками данных и позволяет легко загружать данные в вашу рабочую среду.
Функции обработки, такие как фильтрация, группировка, сортировка, и агрегация, предоставляют гибкие инструменты для манипулирования данными и извлечения полезной информации.
Различные опции сохранения данных помогают оптимизировать как конечное хранение данных, так и последующий доступ к ним.
Надеюсь, что представленные в статье примеры помогут новичкам быстрее освоиться с Apache Spark и начать свой путь в области обработки больших данных. Помимо функциональных возможностей Spark, также затронул лучшие практики и рекомендации по оптимальному использованию этого инструмента, что несомненно пригодится в реальных проектах.
Помните, что регулярное обновление знаний и умение адаптироваться к новым технологиям — ключевые навыки для специалиста в области данных. Поэтому продолжайте изучать и экспериментировать с Apache Spark, чтобы находить новые и эффективные способы работы с данными. Удачи в ваших начинаниях и до новых встреч в мире больших данных!
Следите за новыми статьями, и не забывайте делиться своими успехами и открытиями с коллегами и сообществом. Spark — это не только технология, но и активно развивающееся сообщество специалистов, которое всегда открыто к обмену знаниями и опытом.