
Бывало у вас так, что некоторые аналитики запрашивают побольше вычислительных ядер и оперативной памяти для своих Jupyter-ноутбуков, а у вас в это время ничего не работает? У меня бывало, ведь недостаточно уметь разрабатывать код на Spark — ещё нужно уметь его настраивать, правильно инициализировать сеансы работы и эффективно управлять доступом к вычислительным ресурсам. Если отдать настройку на волю случая, Spark может (и будет) потреблять ресурсы всего кластера, а другие приложения будут стоять в очереди.
Меня зовут Владислав, я работаю Дата инженером в Альфа-Банке, и в этой статье мы поговорим о том, как правильно подобрать необходимое количество параметров и не положить кластер на коленочки.
Примечание. В данном примере рассмотрим версию Spark 2.4.8.
Если вы здесь, значит хорошо знакомы с Apache Spark и вводная про него вам не нужна. Перейдем сразу к делу.
Как Spark управляет ресурсами?
Схематически по шагам этот процесс выглядит так:
№1. Запуск Spark-приложения
Ваше Spark-приложение запускается через менеджера приложений, такой как YARN, Mesos или Standalone Cluster Manager, в зависимости от вашей конфигурации. Менеджер приложений выделяет ресурсы для вашего приложения на кластере.
Менеджер приложений (Application Manager) — это часть архитектуры Spark, которая отвечает за управление жизненным циклом и выполнением Spark-приложений на кластере. Он играет ключевую роль в управлении приложениями и их ресурсами, координации задач и мониторинге выполнения.
Роль менеджера приложений включает в себя следующие задачи:
Запуск приложения.
Координация задач.
Мониторинг и отчеты.
Обработка сбоев.
№ 2. Инициализация исполнителей
После успешного запуска приложения менеджер приложений создаёт начальное количество исполнителей (executors) в кластере. Эти исполнители являются вычислительными узлами вашего приложения.
№ 3. Выделение ресурсов
Исполнители получают выделенные ресурсы, такие как ядра CPU и память, в соответствии с конфигурацией приложения. Ресурсы могут быть разделены на исполнителей на основе требований приложения.
№ 4. Запуск задач
Ваше Spark-приложение начинает отправлять задачи на исполнителей для выполнения. Каждый исполнитель выполняет задачи в своем собственном процессе.
№ 5. Мониторинг и сбои
Менеджер приложений мониторит выполнение приложения, собирает метрики производительности и обрабатывает сбои задач или исполнителей. В случае сбоя, исполнители могут быть перезапущены.
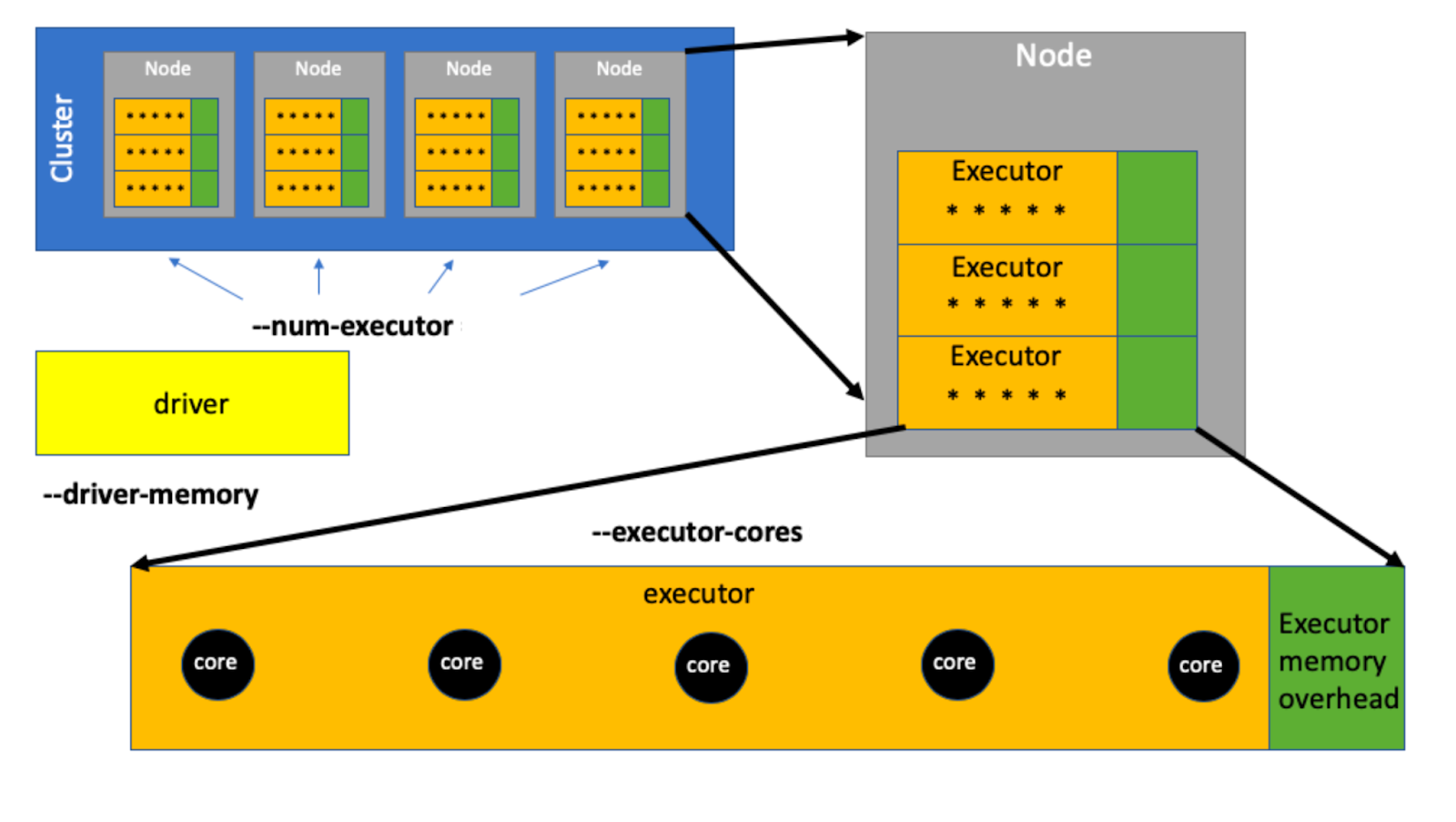
Приложение Spark функционирует в рамках всего двух типов процессов: драйвера и исполнителя(executor).
Поэтому нас интересует только драйвер и исполнитель.
Исполнитель или Executor — это вычислительный процесс. Каждый исполнитель выполняет код Spark в форме задач (тасок), хранит часть данных в памяти для обработки (которые пользователь хочет кэшировать) и обменивается данными между своими «коллегами» и драйвером.
Задачи выполняются на ядре (Core) — это вычислительный ресурс на узле, который представляет собой одну потоковую единицу на физическом или виртуальном процессоре. Многие современные процессоры имеют несколько ядер, что позволяет выполнять множество задач параллельно.
Исполнителями командует драйвер — точка входа в Spark приложение, которая контролирует его выполнение. Драйвер выполняет код приложения и обеспечивает связь между пользовательским кодом и кластером. Это основной процесс, который управляет выполнением задач и координирует работу исполнителей.
Драйвер может быть только один, а вот исполнителей может быть много. Поэтому важно аккуратно управлять количеством доступных исполнителей.
Драйвер управляет рабочим процессом, а исполнитель — обеспечивает выполнение задач. На исполнителей у нас выделяются ядра и оперативная память. Исходя из этого делаем вывод — нам необходимо корректно рассчитать параметры драйвера и исполнителя.
Начнем с драйвера.
Настраиваем драйвер
В рамках Spark драйвер выполняет две ключевые функции: планирование вычислений и агрегирование результатов.
Для планирования вычислений дополнительные вычислительные ресурсы не обязательны.
Поэтому переходим к процессу агрегирования результатов.
В pySpark за сбор результатов отвечает функция toPandas(). Важно учитывать, что toPandas() не предназначен для извлечения больших наборов данных (как правило многие ограничиваются 2 ГБ)
Драйвер в Spark может работать в трех режимах, но рассмотрим два (чаще используемые).
Client Mode (режим клиента):
В режиме клиента драйверное приложение запускается на клиентской машине, которая инициирует выполнение Spark задачи.
Драйверное приложение взаимодействует с кластером Spark, управляя распределенными вычислениями.
Этот режим удобен для разработки и отладки, так как драйверное приложение выполняется локально, и вы можете легко мониторить процесс.
Однако он не рекомендуется для больших объемов данных, так как клиентская машина может стать узким местом.
Cluster Mode (режим кластера):
В режиме кластера драйверное приложение запускается на одной из машин в кластере, что позволяет легче масштабировать выполнение Spark задач.
Клиентская машина инициирует задачу, но драйверное приложение выполняется внутри кластера.
Этот режим рекомендуется для больших и ресурсоёмких задач, так как он распределяет нагрузку на кластер.
Большая часть параметров применимы во всех трёх режимах.
Для настройки драйвера будем конфигурировать следующие параметры (данные параметры выбраны исходя из личного опыта):
spark.driver.cores— определяет количество выделенных вычислительных ядер (CPU cores). Для драйвера рекомендую ставить 2 (важно отметить, что в Client Mode данный параметр не задается, поэтому подумайте предварительно, где будут запускаться расчеты на стороне сервера или на стороне кластера).spark.driver.memory— определяет количество памяти, выделенной для драйвера Spark, по умолчанию стоит, как правило, 1 ГБ. Это критический фактор — слишком маленький объем памяти на драйвере приведет к ошибкам, из-за которых и родилась эта статья.spark.driver.maxResultSize— определяет максимальный размер результата, который может быть передан от исполнителей (вычислительных узлов) обратно к драйверу Spark. Параметр полезен для контроля использования памяти и предотвращения переполнения памяти драйвера при обработке больших данных или выполнении операций, которые могут генерировать большие результаты. Рекомендуется ставить эквивалентное значениеspark.driver.memory.spark.driver.memoryOverhead— определяет дополнительный объем памяти, выделяемый драйверу Spark для обеспечения более надежной работы и предотвращения переполнения памяти. По умолчанию равно 10% памяти исполнителя при минимальном размере 384 МБ. Даже если пользователь явно не задает этот параметр, фреймворк сам выделит 10% памяти исполнителя или 384 МБ, в зависимости от того, что больше для накладных расходов JVM.
Собирая всё вместе, получим такие настройки:
spark.conf.set("spark.driver.cores", 2)
spark.conf.set("spark.driver.memory", 2g)
spark.conf.set("spark.driver.maxResultSize", "2g")Данные параметры применимы в большинстве случаев использования, позволят не нагружать сильно кластер и использовать оптимальные параметры. Эти настройки драйвера универсальные и подойдут как для Статического выделения ресурсов так и для Динамического. Кстати, о нём.
Динамическое выделение ресурсов
Данный метод особенно хорошо подойдет специалистам с небольшим опытом работы со Spark, но будет безопасен для всех, кто с ними работает.
В методе динамического выделения ресурсы могут быть выделяемыми и освобождаемыми динамически, в зависимости от нагрузки приложения. Система может автоматически адаптировать объём памяти и количество ядер исполнителей, чтобы удовлетворить текущим потребностям приложения. Этот метод позволяет управлять ресурсами в режиме реального времени, что делает его подходящим для приложений с переменной нагрузкой.
Но для этого нам надо сконфигурировать следующие параметры:
spark.dynamicAllocation.enabled— управляет активацией или деактивацией функции динамической аллокации ресурсов. Здесь необходимо поставитьtrue. Когда это свойство установлено вtrue, нам не нужно упоминать executor (spark.dynamicAllocation.initialExecutors).spark.dynamicAllocation.minExecutors— определяет минимальное количество исполнителей (executors), которое должно быть выделено в кластере в рамках динамической аллокации ресурсов. Рекомендую прописывать 0.spark.dynamicAllocation.maxExecutors— определяет максимальное количество исполнителей (executors), которое может быть выделено в кластере в рамках динамической аллокации ресурсов. Если вы не уверены в предстоящих объемах расчета поставьте 6 или 7, должно хватить.spark.dynamicAllocation.executorIdleTimeout— определяет время в миллисекундах, в течение которого исполнитель (executor) может находиться без активности до его автоматической остановки и освобождения ресурсов. Обычно ставят 600 s — эквивалентно 10 минутам.spark.dynamicAllocation.schedulerBacklogTimeout— определяет максимальное время в миллисекундах, в течение которого динамическая аллокация ресурсов ожидает активацию дополнительных исполнителей, когда в очереди задач (планировщике) есть задачи ожидающие выполнения.
Пара нюансов. Если вы включите динамическое распределение, то верхняя граница для количества исполнителей равна бесконечности! Это значит, что теоретически приложение Spark может съесть все ресурсы, если потребуется.
Это не то, что вы хотели бы получить. Поэтому прописываем ещё один параметр.
spark.dynamicAllocation.initialExecutors— определяет начальное количество исполнителей (executors), которые будут автоматически выделены при старте приложения с использованием динамической аллокации ресурсов. Этот параметр позволяет настроить сколько исполнителей будет запущено автоматически в начале выполнения приложения, а затем динамически управляться на основе текущей нагрузки и потребностей приложения.
Получилось так:
.set("spark.dynamicAllocation.enabled", True)
.set("spark.dynamicAllocation.initialExecutors", 1)
.set("spark.dynamicAllocation.minExecutors", 0)
.set("spark.dynamicAllocation.maxExecutors", 3)
.set("spark.dynamicAllocation.schedulerBacklogTimeout", "1s")
.set("spark.dynamicAllocation.executorIdleTimeout", "600s")В случае если вы боитесь и у вас мало опыта, рекомендую вам воспользоваться Динамическим выделением ресурсов так как в данном случае вы будете более оптимально использовать ресурсы кластера.
Примечание. Но поскольку выделение и освобождение ресурсов происходит динамически, это может сделать выполнение задач менее предсказуемым и увеличить сложность отладки и внести небольшие накладные расходы на управление ресурсами и дополнительные задержки при их выделении и освобождении.
Теперь перейдем к самому основному и достаточно сложному — настройке исполнителей, так как именно это имеет значительное воздействие на общую производительность и эффективность кластера.
Статическое выделение ресурсов
В этом методе объём памяти и количество ядер выделяем на этапе запуска Spark приложения и оставляем неизменными в течение всего выполнения приложения. Подходит для задач, в которых требуется предсказуемое и стабильное распределение ресурсов на протяжении всего выполнения. Поскольку ресурсы фиксированы, это снижает вероятность неожиданных сбоев из-за нехватки ресурсов. Приложение не будет «гоняться» за дополнительными ресурсами в случае внезапной нагрузки
К тому же, это достаточно просто настраивать, так как вам нужно только определить их значения до запуска приложения. Давайте это сделаем?
Например, так.
spark.conf.set("spark.executor.instances", 1)
spark.conf.set("spark.executor.cores", 1)
spark.conf.set("spark.executor.memory", "3g")Но здесь при использовании только одного исполнителя на ядро мы не сможем воспользоваться преимуществами выполнения нескольких задач в одной JVM.
А если так?
spark.conf.set("spark.executor.instances", 16)
spark.conf.set("spark.executor.cores", 16)
spark.conf.set("spark.executor.memory", "64g")Пропускная способность HDFS пострадает и это приведет к чрезмерному количеству мусора.
А вот золотая середина.
spark.conf.set("spark.executor.instances", 3)
spark.conf.set("spark.executor.cores", 5)
spark.conf.set("spark.executor.memory", "20g")Эффективное количество ядер составляет 5 для лучшей отработки процессов hdfs.
Но есть нюансы метода:
Недоиспользование ресурсов. В случае, если вы предоставляете слишком много ресурсов, они могут оставаться неиспользованными в течение большей части выполнения задач, что приводит к неэффективному использованию кластера.
Неустойчивость при изменяющейся нагрузке. В приложениях с изменяющейся интенсивностью нагрузки статическое выделение ресурсов может быть неэффективным. Оно не может адаптироваться к пиковым нагрузкам.
Что по итогу получилось
В итоге мы имеем два конфига, которые можно смело использовать:
Статическая аллокация.
.set("spark.driver.memory", "2g")
.set("spark.driver.cores", 2) #Задаем только в Cluster Mode
.set("spark.executor.cores", 5)
.set("spark.executor.instances", 3)
.set("spark.dynamicAllocation.enabled",'false')
.set("spark.master", "yarn")
.set("spark.submit.deploymode", "client")Динамическая аллокация.
.set("spark.driver.memory", "2g")
.set("spark.driver.cores", 2) #Задаем только в Cluster Mode
.set("spark.executor.cores", 5)
.set("spark.submit.deploymode", "client")
.set("spark.dynamicAllocation.enabled", "true")
.set("spark.dynamicAllocation.initialExecutors", "1")
.set("spark.dynamicAllocation.minExecutors", "0")
.set("spark.dynamicAllocation.maxExecutors", "3")
.set("spark.dynamicAllocation.executorIdleTimeout", "360s")Покажу на опыте как себя показывают данные настройки. Для эксперимента возьмём простую задачу, запрос к таблице в которой порядка 100к записей, небольшая фильтрация и агрегация результатов.
Со Статической аллокацией задача рассчиталась чуть быстрее.

Динамическая чуть медленнее, но в целом результат подтверждает то, что мы подобрали эффективные параметры.

А в случае когда мы задаем 1 executor и 1 instance у нас получается достаточно долгая задача.

Как рассчитывать необходимое количество ресурсов
Рассмотрев способы настройки ресурсов, попробуем рассчитать на реальном примере.
Для настройки исполнителя будем конфигурировать следующие параметры:
spark.executors.cores— чем больше данный параметр, тем меньше количество исполнителей и, как следствие, параллелизм. Малое количество ядер увеличивает объем операций ввода-вывода. На практике данный параметр принято устанавливать «5» для любого размера кластера:spark.executors.cores = 5.spark.executors.memory— определяет объем памяти, выделяемый для каждого исполнителя (executor) Spark в кластере. Слишком много памяти на исполнителе может улучшить производительность, если памяти достаточно, а если нет — может привести к излишнему использованию памяти и конкуренции за ресурсы. Как тогда рассчитать память? Приведу пример.
Допустим у нас есть кластер, который состоит из 5 узлов, на каждом узле памяти 64 ГБ и каждый узел имеет по 17 ядер.
Оставляем одно ядро на фоновые процессы и у нас остается 16 ядер на исполнителя.
Ещё одно ядро оставляем менеджеру приложений. Итого 15 ядер на исполнителя.
Это число делим на количество узлов (5) и получим 3 исполнителя на кластер.
Имеющуюся память в 64 ГБ делим на 3 и получим 21,3. Округлим и поставим 21 ГБ на исполнителя.
У нас есть ещё два параметра, которые нам надо рассчитать.
spark.executors.instances — определяет количество исполнителей в кластере (как правило достаточно 3 для небольших задач).
И spark.executors.memoryOverhead — определяет дополнительный объем памяти, выделенный для каждого исполнителя (executor) Spark, чтобы обеспечить более надежную работу и предотвратить переполнение памяти. Дополнительный объем памяти, как правило это примерно от 6% до 10% от выделяемой памяти на исполнителя, будет 2,1. Пусть будет примерно 2 ГБ.

Далее следует вычесть из выделенной памяти на исполнителя дополнительные объемы памяти: 21 - 2 = 19.
Готово.
Итоговый результат конфигов
Давайте подведём итог по подобранным параметрам, нашей золотой середины. Стоит отметить, что данный конфиг получился универсальным и применим на более мощных кластерах (единственное, что стоит все таки для каждого случая подбирать объем памяти отдельно).
Статическая аллокация
.set("spark.driver.memory", "2g")
.set("spark.driver.cores", 2) #Задаем только в Cluster Mode
.set("spark.executor.cores", 5)
.set("spark.executor.memory", "20g")
.set("spark.executor.instances", 3)
.set("spark.dynamicAllocation.enabled",'false')
.set("spark.master", "yarn")
.set("spark.submit.deploymode", "client")Динамическая аллокация.
.set("spark.driver.memory", "2g")
.set("spark.driver.cores", 2) #Задаем только в Cluster Mode
.set("spark.executor.cores", 5)
.set("spark.executor.memory", "20g")
.set("spark.submit.deploymode", "client")
.set("spark.dynamicAllocation.enabled", "true")
.set("spark.dynamicAllocation.initialExecutors", "1")
.set("spark.dynamicAllocation.minExecutors", "0")
.set("spark.dynamicAllocation.maxExecutors", "3")
.set("spark.dynamicAllocation.executorIdleTimeout", "60s")Заключение
Правильный подбор параметров в Apache Spark критически важен для обеспечения высокой производительности, стабильности и эффективного использования ресурсов вашего кластера. Неэффективное использование ресурсов может привести к снижению производительности, переполнению памяти, сбоям и даже краху вашего Spark приложения.
Вот почему правильная настройка так важна:
Производительность. Параметры Spark влияют на способность вашего приложения обрабатывать данные и выполнять операции. Неправильно выбранные параметры могут замедлить выполнение задач, что не только увеличит время выполнения, но и сделает приложение неэффективным. Взяв мало ресурсов мы можем потерять преимущество использования распределенных расчетов, а взяв слишком много пропускная способность HDFS пострадает, и это приведет к чрезмерному количеству мусора.
Стабильность. Неправильные настройки могут привести к сбоям приложения или краху кластера. Например, если вы устанавливаете слишком большой объём памяти для исполнителей, это может привести к исчерпанию памяти и сбою. Сбои могут привести к потере данных и долгому времени восстановления.
Использование ресурсов. Spark-приложения часто работают на кластерах с ограниченными ресурсами. Неправильные настройки могут привести к неэффективному использованию этих ресурсов. Например, слишком большой объем памяти на исполнителе может привести к тому, что большая часть памяти будет неиспользуемой, что неправильно расходует ресурсы.
Стоимость обслуживания. Эффективное использование ресурсов также важно с экономической точки зрения. Если вы используете облачные вычислительные ресурсы, неэффективное использование может привести к излишним расходам на вычисления и хранение данных.
С этими настройками, в большинстве случаев, решается проблема с загрузкой очередей. Проблема возвращается только когда приходят новые аналитики и этих правил и настроек не знают).
Друзья, если вам интересна данная тема, подписывайтесь на блог (и канал ниже). В дальнейшем выпущу продолжение про более продвинутые параметры.
Рекомендуем почитать:
Знакомство с Apache Airflow: установка и запуск первого DAGа
Нейросетевой подход к кредитному скорингу на данных кредитных историй
Нейросетевой подход к моделированию транзакций расчетного счета
Как и зачем мы начали искать бизнес-инсайты в отзывах клиентов с помощью машинного обучения
Как оптимизировать процесс привлечения клиентов B2B с помощью методов Продвинутой Аналитики
Как мы заняли первое место в хакатоне ВК «Машинное обучение на графах», где не было графов
Также подписывайтесь на Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
Комментарии (7)

NoGotnu
07.11.2023 12:46Небольшое замечание: собираете результаты с помощью функции toPandas() может быть конкретно вы в вашем случае, но это далеко не самая широко используемая функция. Это ещё pandas должен быть установлен. По умолчанию используется родная функция collect()
aruslantsev
Для динамической аллокации еще полезно знать про опцию
spark.dynamicAllocation.cachedExecutorIdleTimeout, потому что если экзекутор закэшировал данные, то по истечению executorIdleTimeout он не будет остановлен.И указывать 20 гигабайт и 5 ядер -
страннаянеобоснованная практика. Например, я (тоже почти ничем не обоснованно, да) чаще использую 4 ядра и 10 гигабайт, и в 99% случаев этого достаточно.sshikov
Слух про оптимальные 5 ядер - он давно ходит по интернету. И всегда все ссылаются на одну и туже статью, где это основано на утверждении, что если больше 5 ядер выделить, то HDFS будет якобы плохо. Только вот измерений там никаких нет, и в итоге непонятно, каким образом вообще на HDFS может влиять то, сколько ядер выделено на один executor.
Я уже не говорю о том, что в принципе, spark может не работать с HDFS, в частном случае. А например, читать данные из реляционной БД по JDBC, или скажем из HBase, ну или из кафки. В общем, заниматься чем-то другим.
А еще практически все подобные тексты исходят из того, что кластер находится в полном нашем распоряжении. В то время как в реальности, под управлением Yarn, вы можете запросить больше ресурсов, чем выделено для вашей Yarn очереди (а не имеющихся в кластере), и будете именно что ждать в очереди, пока ресурсы освободятся. Так что тема стояния в очереди вообще не раскрыта.
sshikov
Да, я не хочу сказать, что 5 ядер вообще смысла не имеют. Я хочу сказать, что конкретно 5 ядер ни на чем не основаны. И еще, если вы увеличиваете число ядер - то вы должны и память на executor практически пропорционально увеличить. А это уже повлечет определенные негативные последствия. То есть, какой-то оптимум тут скорее всего есть, но каков он конкретно - зависит от многих параметров, и в первую очередь от профиля нагрузки - т.е. от того, чем ваше приложение вообще занимается.
aruslantsev
Про слух про оптимальные 5 ядер я думаю в курсе все, кто использует pyspark :)
В идеале при регулярных расчетах надо все обвесить мониторингами потребления памяти, процессоров, смотреть, есть ли spill. И еще исходить из баланса времени расчета, ресурсов и человеческих договоренностей, ведь на кластере мы никогда не бываем в одиночестве.
При разовых расчетах всем хочется быстрее получить результат, но тут опять же надо учитывать тот баланс ресурсов, времени и загруженности кластера.
А чтобы не стоять в очереди, достаточно иметь один экзекутор, одно ядро и гигабайт памяти. Только вот зачем?
sshikov
Я пишу на Java/Scala, если что, та же фигня :)
Число возможных вариантов далеко не бесконечно, от 1 до числа ядер на узле кластера (минус константа). И где-то там очевидно оптимум есть. И я даже не исключаю, что иногда он равен пяти.
И да, вопрос мониторинга был поднят возможно в первой статье на эту тему, что мне попалась на хабре с год назад.
Тут на самом деле имелось в виду, что мы знаем параметры очереди Yarn (хотя с учетом наследования от родительской очереди определить их далеко не тривиально). И ориентироваться при выборе ресурсов вполне можем на очередь, а не на параметры голого кластера. В зависимости от текущего профиля его нагрузки. Но это сложный вопрос, и у меня нет на него даже примерных ответов.
vladislav_shevchenko Автор
Спасибо большое за фидбек, по поводу spark.dynamicAllocation.cachedExecutorIdleTimeout мы планируем рассказать по данному параметру в следующей статье, что касается выбора 5 ядер, выбрано в рамках практических решений, плюс также был выполнен тест, в виде простой задачи которая также описана, в случае с 5ю ядрами результат оказался самым эффективным, никто не запрещает уменьшать или увеличивать, также хочу отметить что данная статья подходит больше для молодых специалистов, которые не выполняют сложных расчетов, и делают базовые запросы вызова и вывода результатов