
С помощью построения абстрактных синтаксических деревьев на основе разбора исходного текста, им удалось выделить устойчивые отличительные признаки при написании кода, которые трудно скрыть даже целенаправленно. Используя машинное обучение и набор эвристик, удалось добиться впечатляющей точности определения авторства среди выборки из 1600 программистов Google Code Jam.
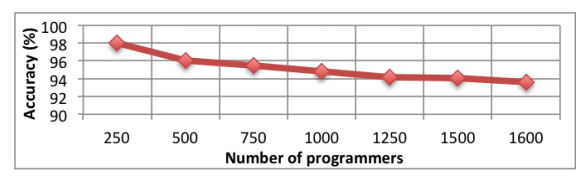
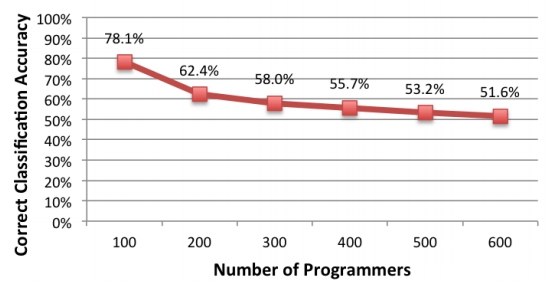
В своей новой работе, исследователи продемонстрировали, что деанонимизация возможна и через анализ уже скомпилированных бинарных файлов в отсутствии исходных кодов (видео презентации доклада). В этот раз для исследования использовались исходные коды 600 участников Google Code Jam, которые были скомпилированы в исполняемые файлы, а потом подвергались разбору. Благодаря тому, что задания на соревнованиях были одинаковы для всех, разница файлов заключалась в значительной степени именно в стиле программирования, а не в алгоритме. Изначально, при сборке бинарных файлов отключались оптимизации компилятора и не применялась обфускация исходных кодов. Но, как утверждают авторы работы, некоторые отличительные признаки сохраняются и при применении этих способов сокрытия авторства, снижая точность деанонимизации до 65%.
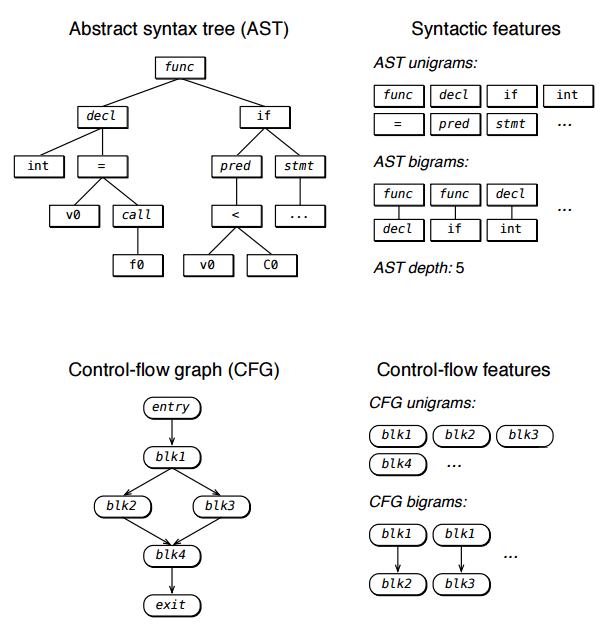
С помощью дизассемблирования и декомпиляции, применяя все те же абстрактные синтаксические деревья, проводится анализ графа потока управления, выделяются отличительные признаки кодирования и производится обучение классификатора на основе векторов признаков.

Что интересно, было обнаружено, что боле профессиональные программисты гораздо легче могут быть деанонимизированы по сравнении с менее опытными коллегами, т.к. имеют более выраженный и индивидуальный стиль программирования.
Авторы уверены, что с помощью подобных методов когда-нибудь будут выявлены настоящие авторы таких разработок как Bitcoin, TrueCrypt, а также разработчики известных вредоносных программ.
Комментарии (45)
mtp
05.01.2016 11:36+35> настоящие авторы таких разработок как Bitcoin, TrueCrypt и известных вредоносных программ.
Напомнило: «Можно сказать: „космонавты и педерасты“. Мы не сказали ничего плохого про космонавтов, но неприятный осадок остался». Переформулируйте, пожалуйста.

ankh1989
05.01.2016 13:17+1У метода есть очевидный недостаток: чтобы он работал, нужна большая база кода у которого авторы изестны и при этом в этой базе кодить все должны отдельно.

fakedream
05.01.2016 14:47+1github? :)
ankh1989
06.01.2016 06:14+1гитхаб не подходит потому что там далеко не каждый пишет под своим именем как в паспорте. У меня там например штук десять аккаунтов с именами вроде 1h27sh (чуть ли не для каждого проекта свой аккаунт) и логика за этим стоит простая: даже если я такой неуловимый Джо который никому не нужен, не стоит складывать все яйца в одну корзину.

ilmirus
06.01.2016 06:44+2А имейлы для регистрации берете из 10minutemail?

Wesha
06.01.2016 07:20+1«Если вы параноик, то из этого ещё не следует, что за вами никто не следит!» (с)
ilmirus
06.01.2016 07:45Это был не сарказм. Мне действительно интересен способ генерации (почти) одноразовых имейлов, отличный от 10minutemail.
Wesha
06.01.2016 07:51Собственный сервер на просторах интернета, на котором взведён sendmail, и правка aliases. Лично у меня так.
ilmirus
06.01.2016 07:54Хм, все, оказывается, просто. А домен один или несколько?
Wesha
06.01.2016 07:57У меня один, но не вижу никаких причин, почему бы не завести несколько (кроме того, что лично мне одного вполне хватает, а дополнительные надо регистрировать и т.п.).
mtp
06.01.2016 16:06Ну вот по домену-то вас и отловят.
Wesha
06.01.2016 18:55-1Ну, во-первых, при регистрации домена паспорт (пока) предьявлять не требуют, поэтому у Васисуалия Пупкина так много доменов; а во-вторых, ilmirus не уточнял, что его интересуют именно неотслеживаемые государством емейлы — я его вопрос понял так, что его интересует защита от спамеров уровня BugMeNot.
fakedream
06.01.2016 11:15+1для многих акк на гитхабе — это своего рода лицо программиста. его можно указать во всевозможных резюме и профайлах. для такого никто не регит левые акки. а между делом кодер может писать вирусы и ботнет админки, т.к. там очень хорошо платят.
ankh1989
06.01.2016 11:23Про это я не забываю и все мои акки выглядят как хеш от моего имени/фамилии + что то (условная «соль»). Если мне когда либо понадобиться показать пару проектов, я дам ссылки и скажу как получено имя аккаунта — для того, кто способен понять что я там накодил это будет очевиным доказательством того, что акк мой, но случайный человек его не найдёт.
fakedream
06.01.2016 12:06+1я не про тебя конкретно говорю в данный момент. а про тенденцию в целом. а она такова, что огромное количество кодеров выкладывает свой код в гитхаб акк и прилепляет этот акк к своему резюме. это первое.
второе — случайным людям не нужно искать. достаточно владельцам гитхаба дать специальным людям просканить все сорцы в репозиториях, а потом по нужным дать данные про почтовый ящик и про айпи, с которого осуществлен был доступ.ankh1989
06.01.2016 13:41Не понял про просканить. Вот у нас есть условный тор/и2п/биткоин автора которого очень хочет найти тот у кого длинные руки: он берет код/бинарник и… дальше что? Ищет по этому коду похожий код в гитхабе? Так ведь машинное обучение работает наоброт: ему надо дать 100500 репозиториев одного автора и тогда нейросеть сможет с 60% вероятностью сказать является ли этот человек автором данного куска кода или нет.

0x0FFF
05.01.2016 16:20+1Даже не так — нужна большая база кода, в которой разные программисты решали одну и ту же задачу, в противном случае их решение работать не будет
Плюс тут еще много тонкостей — в GCJ почти у всех участников есть свои «шаблоны» решений, в которых для ответа на поставленную задачу чаще всего достаточно дописать только одну функцию. Отсюда и такое качество классификации, т.к. шаблоны чаще всего индивидуальны
Wesha
05.01.2016 22:14Деанонимизация программиста возможна не только через исходный код, но и через скомпилированный бинарный файл
Похоже, нас ждёт новый этап охоты на Сатоши Накамото. Запасаемся попкорном…

pehat
06.01.2016 02:21+1Google Code Jam? Вы серьёзно что ли?
GCJ – соревнование по программированию для алгоритмистов (в подавляющем большинстве случаев это призёры финала ACM ICPC), которые (внимание, сильно утрирую!) годами учатся писать по памяти пачку алгоритмов из книжки, а на соревновании (всё на нервах и с нехваткой времени) придумывают, как эти алгоритмы модифицировать, чтобы решить конкретные задачи. Программисты участвуют в аналогичных соревнованиях много лет подряд, поэтому у каждого есть своя библиотечка шаблонов. Этот код не предназначен для работы на продакшне, под нагрузкой в 100K RPS и какой-либо поддержки в дальнейшем. Утверждать про какую-либо связь GCJ с реальной разработкой open source-кода промышленного качества может утверждать разве что большой шутник.
Maccimo
06.01.2016 03:06>> GCJ – соревнование по программированию для алгоритмистов (в подавляющем большинстве случаев это призёры финала ACM ICPC)
Не преувеличивайте, начальные этапы под силу любому практикующему программисту, знакомому с базовыми алгоритмами.
Полуфинал-финал — другое дело, туда действительно попадают в основном только профессиональные спортсмены.

Woit
06.01.2016 07:57+1Мне кажется, что исследованы либо близкие к идеальным случаи, либо наборы кода относительно небольшого объема.
Например, в проекте с >300к строк кода опытный программист, если он уважает коллег и заботится о своем коде, в разных модулях/подпрограммах/библиотеках может быть разный стиль кодирования, такой, который лучше всего подходит по контексту.
Ну а проекты с >1кк исходников, которые могу сопровождать несколько человек, говорить даже не буду. Воистину garbage in — garbage out

Equin0x
08.01.2016 00:51С другой стороны, можно будет легко подделать «почерк», вставив хорошо узнаваемый чужой кусок.
DeOhrenelli
Не все так плохо.
1 — Большая часть используемой информации недоступна в стрипнутом бинарнике
2 — Даже оптимизация (обычный -О3) снижает точность аттрибуции на 20%
3 — Хорошая обфускация не исследована вовсе
4 — Все исследования производились на коде, который явно писал только один программист (а не группа)
5 — Слабая точность не позволяет использовать результаты в суде
Короче говоря, много шума из ничего, обычное современное «давайте засунем в рандом форест че найдем и посмотрим на результаты которые хоть чуть чуть лучше случайных», что и дает, как и любой матметод, результат по принципу garbage in — garbage out.
ilmirus
Согласен с вами.
И даже по поводу деанонимизации по исходному коду у меня один вопрос:
Любой достаточно большой опен-сорс проект (достаточно — это когда один человек не в состоянии охватить весь проект полностью) имеет стайл-гайд, кучу контрибьюторов и, что более важно, несколько единиц или десятков мейнтейнеров. Можно ли как-то отличить мой код от кода некоего мейнтейнера Томаса, если учесть, что он, как и некий Бернард, был моим ревьювером? И всё это шлифовалось Томасом во время коммита в транк. Причем всё, начиная от именования и до типа применяемого цикла.
Goodkat
EvilsInterrupt
Ога. Как же. Поймаете Вы вирусописателя по бинарю )))
Уверяю Вас, разве что пионера сможете, да и то не факт. А уж опытного малварщика так сказать со стажем тут Вам ничего не светит ;)
nochkin
Да и с пионерами тоже не особо. Пионер зачастую чужой код использует. Или даже разный код из разных источников.
teecat
для поимки — вряд ли. а вот отфильтровывать их новые произведения может быть
grossws
Обычно git blame/hg annotate/svn blame более чем достаточно ,)
ilmirus
Хех, gcc:trunk:r219682. Удачи вычислить изменения, сделанные неким Ilmir Usmanov. Ибо bulk-commit, конечно, зло, но без него разработка GCC сильно бы замедлилась.
uvelichitel
Open_source кажется совсем другая история. Source ведь open и доступен, более того в серьезных проектах(да всех на github) сохраняется история issue, request, commit, revue, accept. Так что персональная ответственность за код вполне прозрачна
icoz
Интересно, а не взламывают ли аккаунты на гитхаб, чтобы туда свой левый репозиторий подложить?
solver
В целом, если есть возможность с узить круг поиска, то надо ее использовать. Именно для для этого такие методы и исследуют.
Про суд очень слабый аргумент. Если сделаете какую нибудь бяку, то будут желающие вас найти из безо всяких судов.
К тому же, ректальный криптоанализ еще никто не отменял. Вполнее могут появиться улики и для суда.
DeOhrenelli
Конечно надо, только у метода столько недостатков, что его практическое использование практически невозможно вообразить, что собственно и имелось в виду.
А искать конечно будут. Только без ордера у них будет на порядок меньше возможностей.
il--ya
Для выдачи ордера достаточно обоснованных подозрений, что этот метод, типа, даёт (хотя я сильно сомневаюсь, что это на самом деле так). Подозреваю, они именно так собираются монетизировать свою «разработку» — подрабатывать экспертами в расследовании киберпреступлений.
Maccimo
Если есть возможность сузить круг, то нужно приложить все усилия к уничтожению этой возможности.
В противном случае нас ждёт международная охота на ведьм, контрибутящих в неудобные политикам опенсорс-проекты.
kovalexius
Согласен!
Andrey_Perelygin
Отчасти с вами не соглашусь.
Подобный алгоритм вполне может себя показать при комбинации с другими методами и пусть не найти нужного кодера на 100%, но существенно сузить область поиска.
По поводу доказательной базе в суде… На мой субъективный взгляд, найди власти %COUNTRY_NAME% с помощью подобной технологии настоящего создателя Bitcoin — ни про какой суд речи даже идти не будет. В конце концов закроют за цп или за связь с бенладеном
DeOhrenelli
Зависит от %COUNTRY_NAME% :)
Mitch
Или пришлют вестника крылатой демократии.
monah_tuk
Теперь мне понятен стиль libstdc++: пишут как пишут, а потом прогоняют через что-то, что делает код таким, будто его писал робот — что бы не догадались, кто что писал :)
l2k
Забавно, если эта статья (прочитав соседнюю статью про взломы в кино) будет использоваться в будущем киношниками ))