

Миграция центров обработки данных (далее ЦОД) задача нетривиальная и трудоемкая, хотя при наличии выстроенных и протестированных процессов достаточно легко исполнимая. Летом прошлого года мне довелось работать над миграцией двух ЦОД, а так как я занимаюсь в основном SAN, то и речь пойдет о том, как мигрировать их.
В source ЦОД у заказчика были СХД от компаний IBM и NetApp, а в destination — EMC VNX. Задачей было быстро и с минимальным downtime мигрировать все хосты как физические, так и виртуальные на новое место. Миграция данных и хостов должна была выполняться c минимизацией времени простоя — заказчиком выступала очень крупная компания, и каждая минута была критична. Оптимальным решением было использование технологий от компании EMC – VPLEX и RecoverPoint.
После длительных размышлений была выработана следующая схема миграции:
Encapsulation
1. Хост выключается;
2. Зонинг на свичах меняется с XIVах на VPLEX;
3. На VPLEX создаются необходимые Storage group;
4. На destinaion side делается то же самое;
5. Создается пара в RecoverPoint;
6. Запускается асинхронная репликация;
7. Хост включается.
Migration
1. Хост выключается;
2. Репликация останавливается, включается direct access на destination side;
3. Хост физически перевозится в новый ЦОД;
4. Хост включается.
В случае если все сделано правильно, хост даже не должен заметить, что его перевезли в другое место, останется только средствами ОС подключить необходимые луны.
Как мы можем видеть — план не особо сложен, однако во время его выполнения пришлось столкнуться со множеством подводных камней, как, например, неконсистентные данные в destination ЦОД. В рамках данной статьи я постараюсь дать подробную инструкцию по самой миграции, а также рабочую процедуру, которая поможет избежать наших ошибок. Итак, поехали!
Хочу заметить, что данную процедуру я пишу на примерах XIV и VNX, но она применима к любым системам.
Encapsulation
Презентуем volumes из XIV на VPLX. Мы должны подключится к XIV, найти все volumes, которые использует наш мигрируемый хост, и замапить их на VPLEX. Думаю, с этим сложностей не возникнет. Само собой, у вас должен быть настроен зонинг, чтобы XIV видел VPLEX.
Определяем volumes на VPLEX. Лучше всего для этого пользоваться CLI.
cd /clusters/cluster-1/storage-elements/storage-arrays/<IBM-XIV-SerialNumber1>
cd /clusters/cluster-1/storage-elements/storage-arrays/<IBM-XIV-SerialNumber2>
cd /clusters/cluster-1/storage-elements/storage-volumes/
claim --storage-volumes VPD83T2:<WWN_Volume> --name <Name_Volume>
Создаем virtual volumes на VPLEX source.
Заходим в Provision Storage -> Storage array:
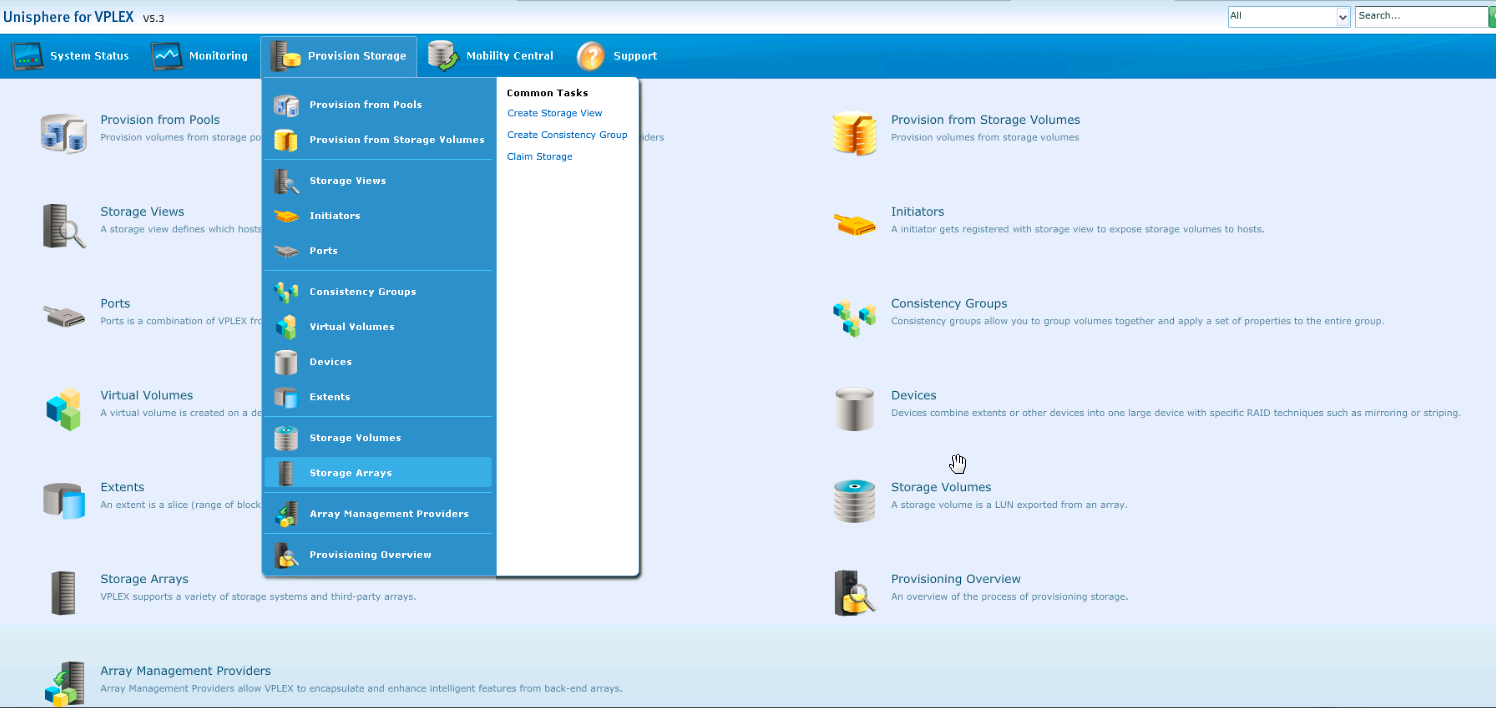
Затем на вкладке «Storage Volumes» проверяем, что все наши луны презентованы (находятся в статусее Claimed)

Переходим в «Extents» и нажимаем «Create», выбираем все LUN от нашего хоста и добавляем их.

Переходим в «Devices”. Нам нужно будет создать устройство, ассоциированное с нашими Extents. Нажимаем „Create“, после чего нам нужно указать тип устройства, в нашем случае нам нужно 1:1 Mapping:

Добавляем все Extents, созданные на предыдущем этапе, отключаемавтоматическое создание virtual volumes:
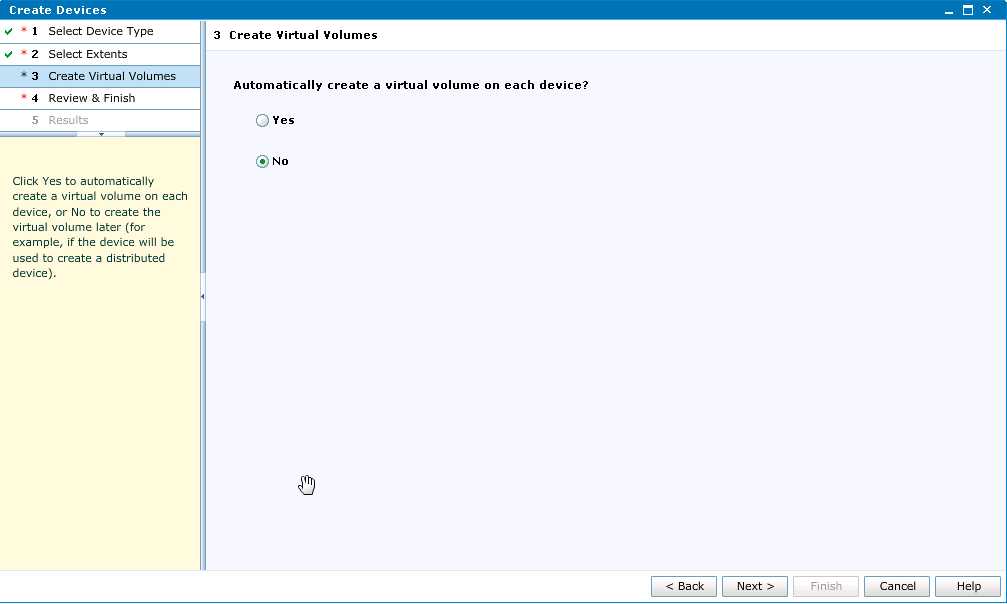
Теперь нам нужно создать virtual volumes, для чего заходим в соответствующий пункт меню и нажимаем Create from Devices, выбираем все устройства, которые мы создали на предыдущем этапе.

После добавления обратите внимание, что наши новые virtual volumes пока находятся в статусе Unexported:
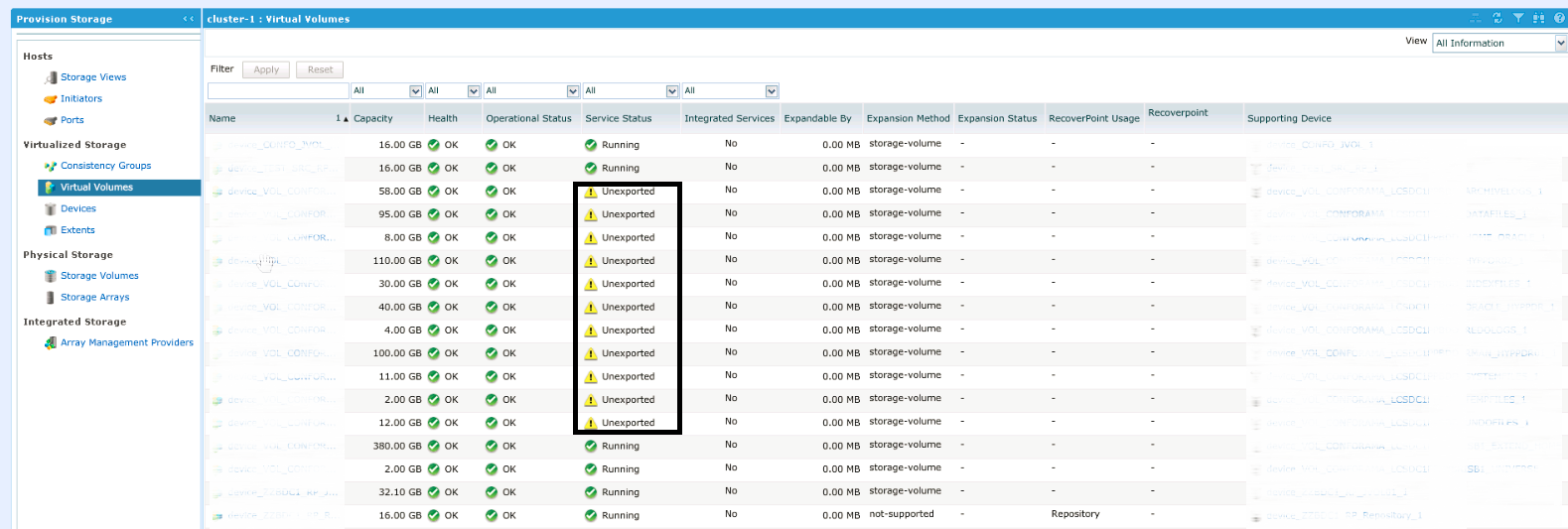
Ну а теперь займемся зонингом, как вы понимаете, в настоящий момент все наши луны презентованы не хосту, а VPLEX, и нам нужно перенастроить зонинг так, чтобы хост видел данные луны., Сделать это мы должны на обеих фабриках. Итак:
SAN01
alishow | grep <ServerName>
zonecreate "<ServerName>_VPLEX","<AliasServerName>;VPLEX_1E1_A0_FC00"
cfgadd "CFG_20160128_07h05FR_SCH","<ServerName>_VPLEX_1E1_A0_FC00"
zonecreate "<ServerName>_VPLEX_1E1_B0_FC00","<AliasServerName>;VPLEX_1E1_B0_FC00"
cfgadd "CFG_20160128_07h05FR_SCH ","<ServerName>_VPLEX_1E1_B0_FC00"
cfgsave
cfgenable CFG_20160128_07h05FR_SCH
cfgactvshow | grep <ServerName>
То же самое делаем для второй фабрики SAN02.
Теперь мы должны создать на VPLEX новый хост и презентовать ему луны. Возвращаемся в админку VPLEX и заходим в Initiators. Если зонинг настроен правильно, мы должны увидеть два незарегистрированных инициатора:

Еще раз проверяем WWN и смело нажимаем Register. На следующем шаге мы задаем имя нашего нового инциатора (я обычно задаю *имя хоcта_номер HBA*), тип хоста в нашем случае это default.
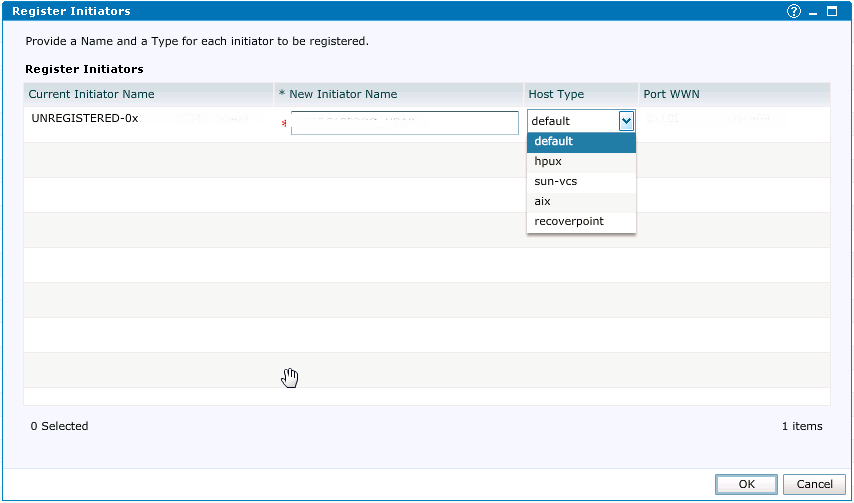
Такой же шаг выполняем для второго инициатора. Все, наш хост сейчас видит VPLEX, осталось только презентовать ему LUNы.
Заходим в пункт Storage View и нажимаем Create, задаем имя Storage View (обычно это имя хоста), добавляем инициаторы:
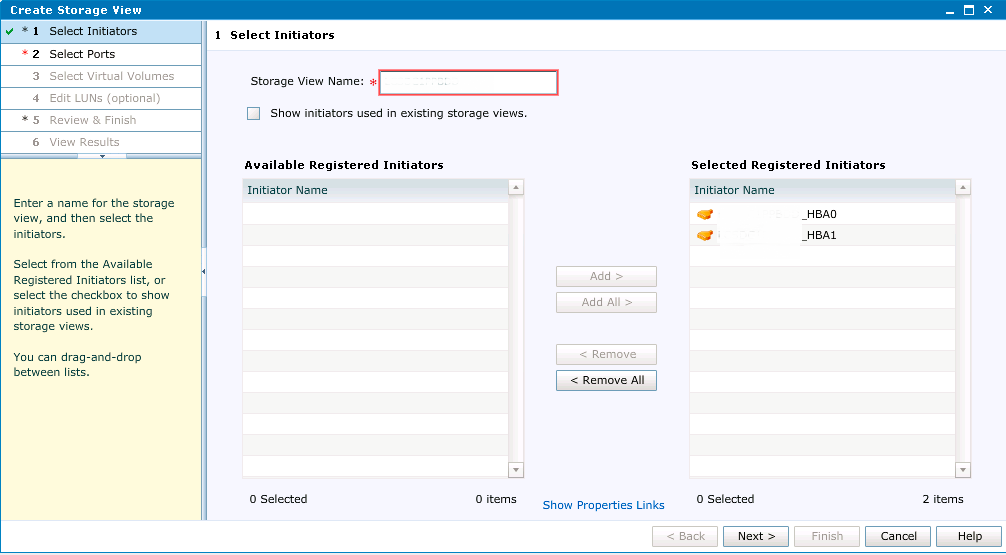
На следующем шаге мы должны ассоциировать инициаторы со свободными портами на стороне VPLEX. Для начала необходимо удостовериться, что все порты выбраны: A0-FC00, A0-FC01, B0-FC00, и B0-FC01. Если их нет, проверяем еще раз правильность настройки зонинга и выполняем рескан FC на хосте.
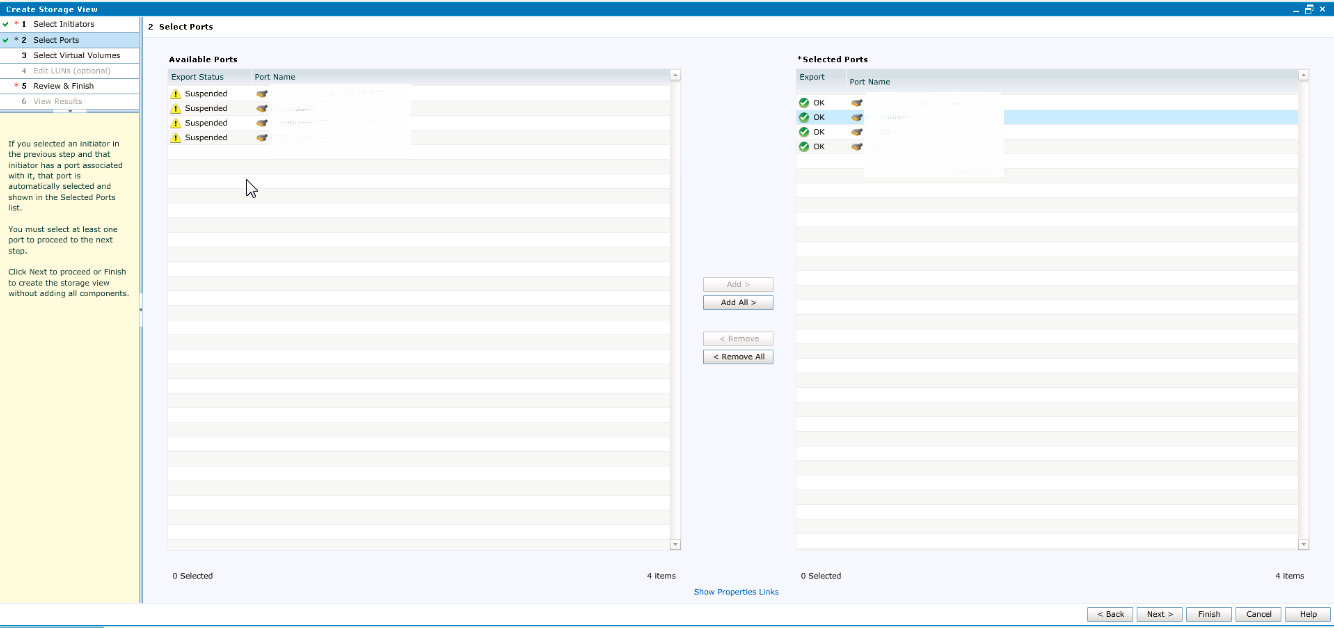
На следующем шаге выбираем все volumes, которые мы создали для нашего сервера, затем указываем номера LUNов. С этим шагом будьте особенно внимательны: номера LUN должны совпадать с номерами, которые у нас были на XIV. Выбираем Manually enter LUN numbers и назначем номера соответвенно.
Еще раз все проверяем и нажимаем Close. После данного этапа на хосте можно подключить обратно все ранее использованные диски, в идеале хост не должен заметить, что сейчас он работает со Storage через VPLEX. Надо заметить, что, хотя мы и добавили новое звено в цепь, проблем с производительностью наблюдаться не должно, latency, конечно, может незначительно просесть, но только незначительно. Но, я думаю, это тема отдельной статьи, я проводил исследования в этой области и, если результаты будут интересны, я с радостью ими поделюсь.
Настройку на source стороне мы почти завершили, теперь займемся destination. Начнем мы с того, что еще раз зайдем на XIV и перепишем точный размер наших лунов, размер рекомендую брать в блоках.
Заходим на VNX, далее Storage -> LUNs -> Create LUN.
Проверяем настройки LUNа, в нашем случае Storage Pool должен быть Pool Open, LUN должен быть Thin, копируем и вставляем размер и задаем имя. Каких-либо требований к имени нет, потому руководствуемся принятыми в организации правилами.
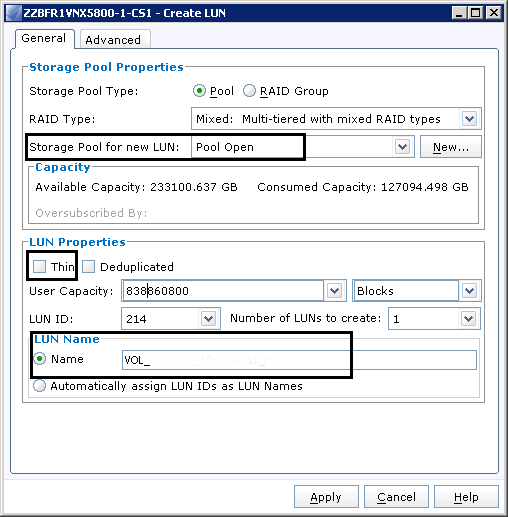
Я предполагаю, что VPLEX у ваш уже подключен, зонинг настроен и Storage Group на VNX созданы. Поэтому после создания LUNов просто добавляем их в соответствующую VPLEX Storage Group.
Следующим шагом мы должны будем презентовать LUNы от VNXа к VPLEX. Можно, конечно, это делать вручную, но я для этих целей пользуюсь небольшим скриптом от EMC. Скачиваем полезную утилитку от EMC — NavisphereCLI и создаем простой BAT файл:
REM remplacer FR1 par le nom du premier VNX.
REM remplacer FR2 par le nom du deuxieme VNX.
REM remplacer 0.0.0.0 IP VNX.
REM remplacer 0.0.0.0 IP VNX.
REM user/user: service/password
rem naviseccli -AddUserSecurity -user sysadmin -password sysadmin -scope 0
del c:\R1.txt
del c:\R2.txt
"C:\EMC\NavisphereCLI\NaviSECCLI.exe" -h 0.0.0.0 getlun -uid -name > c:\R1.txt
"C:\EMC\NavisphereCLI\NaviSECCLI.exe" -h 0.0.0.0 getlun -uid -name > c:\R2.txt
Само собой, в скрипте нам нужно поправить пути. Результатом работы скрипта будут два файла R1 и R2 (так как в нашем случае локации две).
Возвращаемся на VPLEX и мапим наши LUNы. Идем в Provision Storage -> Array Management, выбираем наш VNX и нажимаем Rediscover Array:
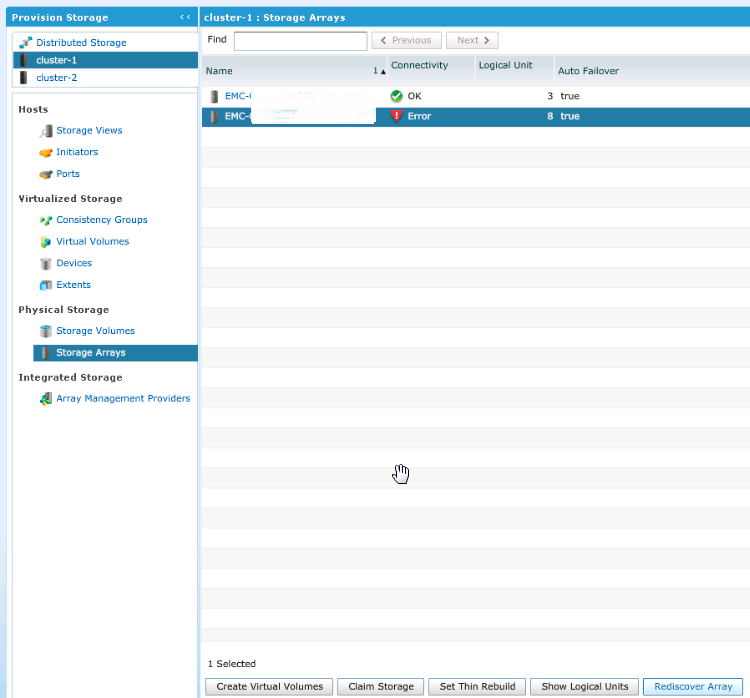
После этой процедуры опять же выбираем наш VNX и нажимаем Claim Storage. Далее выбираем пункт Use a Name Mapping File:

Как, наверное, уже понятно, далее нам нужно будет указать файл, который мы сгенерировали с помощью скрипта. Далее мы должны увидеть все LUNы, которые были созданы на VNX. Даем им новое имя (я рекомендую дать имя по аналогии с source), и после всех этих процедур мы видим, что луны презентованы:
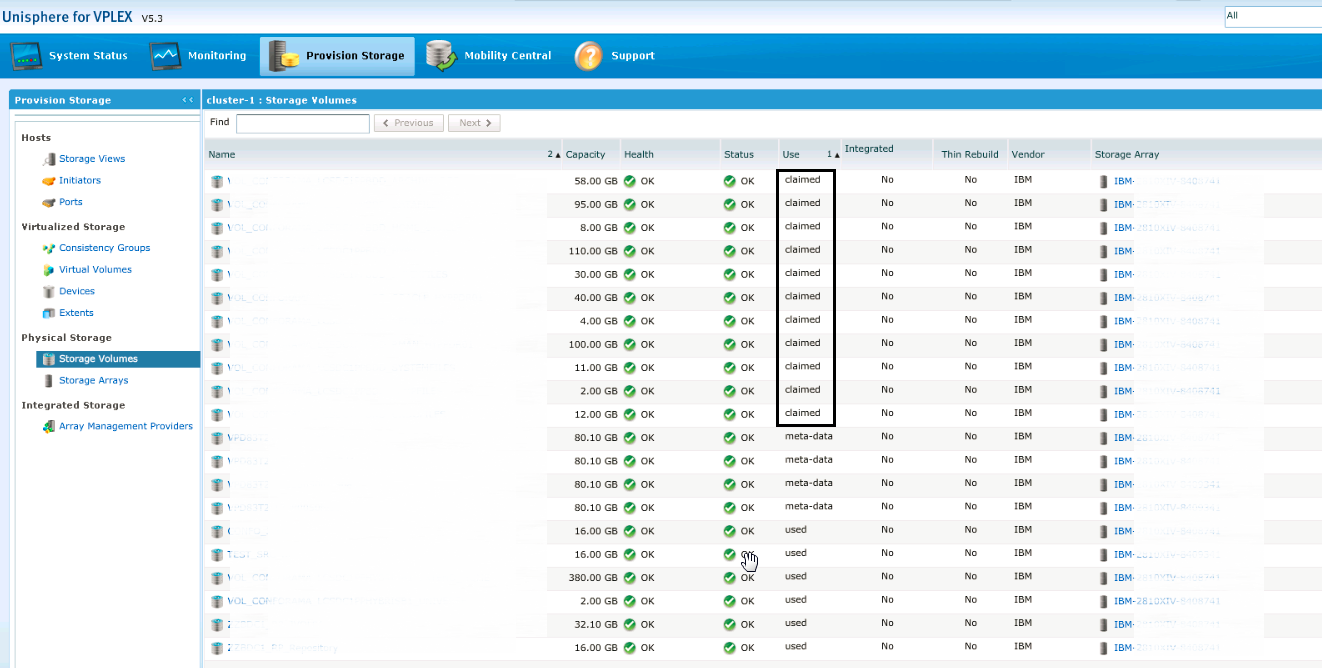
Теперь нам нужно создать Extents, Devices, Virtual Volumes и Storage Group. Все это делается по аналогии с source side и трудности не представляет. По аналогии же создаются зонинг и инициаторы. После всех этих действий distination side уже готова принять наш хост, нам осталось только настроить репликацию.
Для работы RecoverPoint нужен volume под журналы, так называемый JVOL, создаем его на обоих сторонах и добавляем к Storage Group, которую мы создали на предыдущих этапах.
Итак, репликация. Открываем RecoverPoint и смело идем в Protection — > Protect Volumes:
Ищем Consistency group нашего source VPLEX, в поле RPA cluster выбираем source site и выделям все LUNы, которые будут реплицироваться:
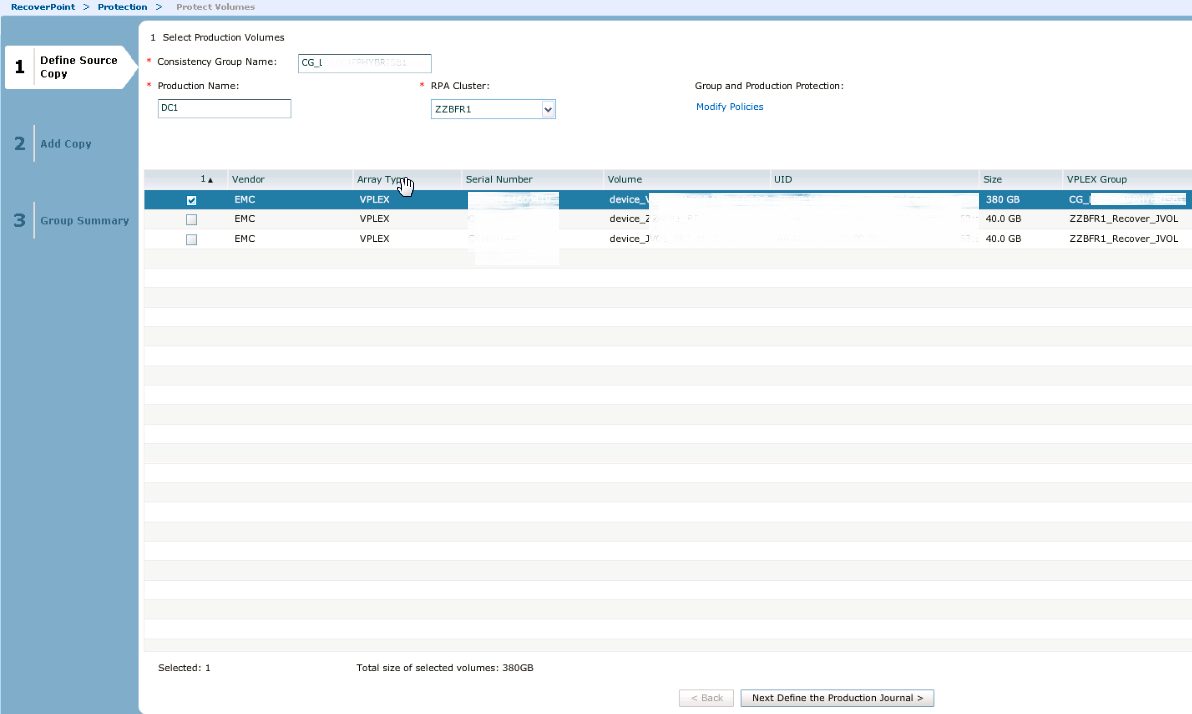
На следующем этапе выбираем наш JVOL. Далее нам нужно уже будет указать имя пары (любое в соответствии с принятыми правилами), RPA cluster уже выбираем Destination и выбираем Detination volumes:
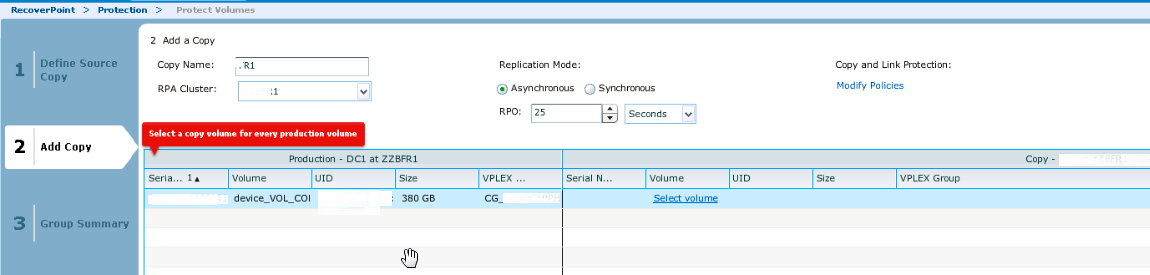
Далее нам нужно указать destination JVOL. Нам покажут простенькую картинку с нашей репликацией, после появления которой нажимаем Add a copy.
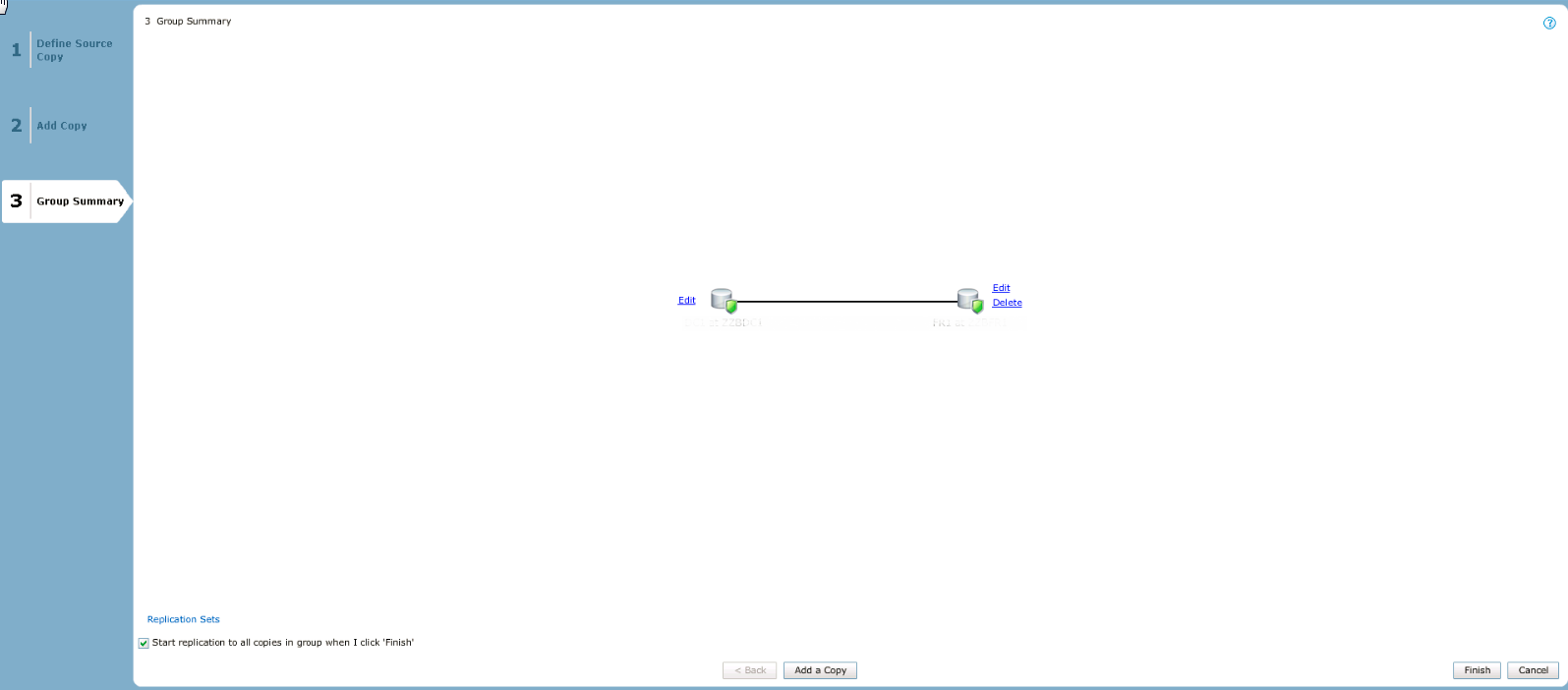
Нажмем по названию нашей CG группы и увидим красивый интерактивный статус синхронизации:
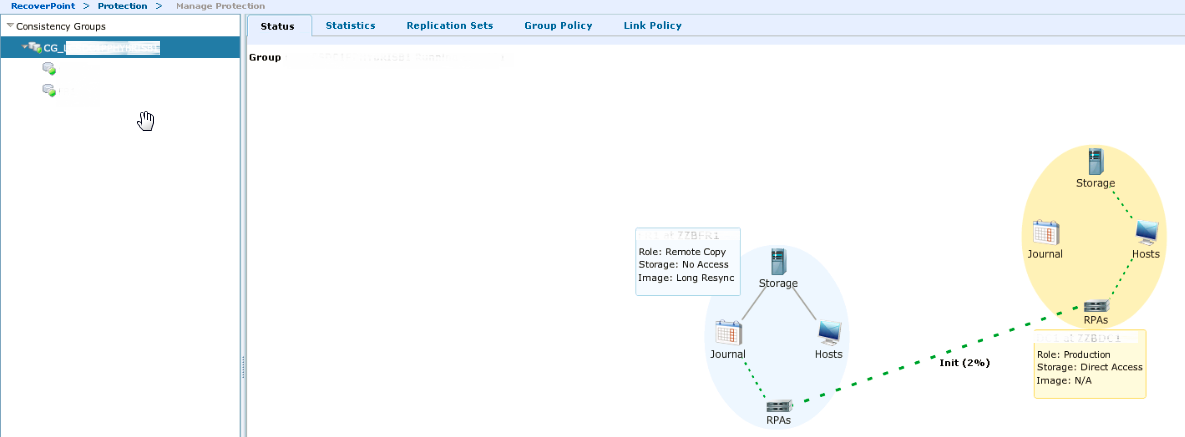
Дожидаемся когда данные среплицируются. После этого мы будем наблюдать следующий статус:
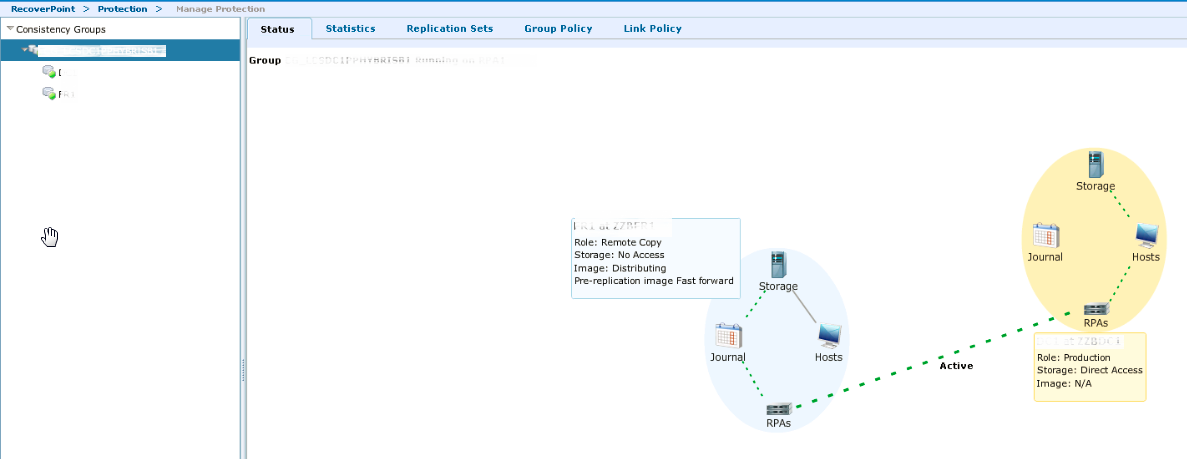
На данном этапе у нас все готово, чтобы уже физически переместить хост в новый дата-центр. Но здесь есть нюанс: обязательно сначала выключаем хост, затем останавливаем репликацию.
Допустим хост уже в пути,, нам нужно разорвать пару и включить для хоста прямой доступ. Если мы ничего не напутали с зонингом, то после включения хост даже не будет догадываться о своем новом месторасположении.
Возвращаемся в RecoverPoint, проходим по Protection -> Manage Protection, находим нашу CG группу и жмем кнопку Pause Transfer:

Затем запускаем тестирование кнопкой Test Copy, выбираем нашу destination сторону и нажимаем Next select an image
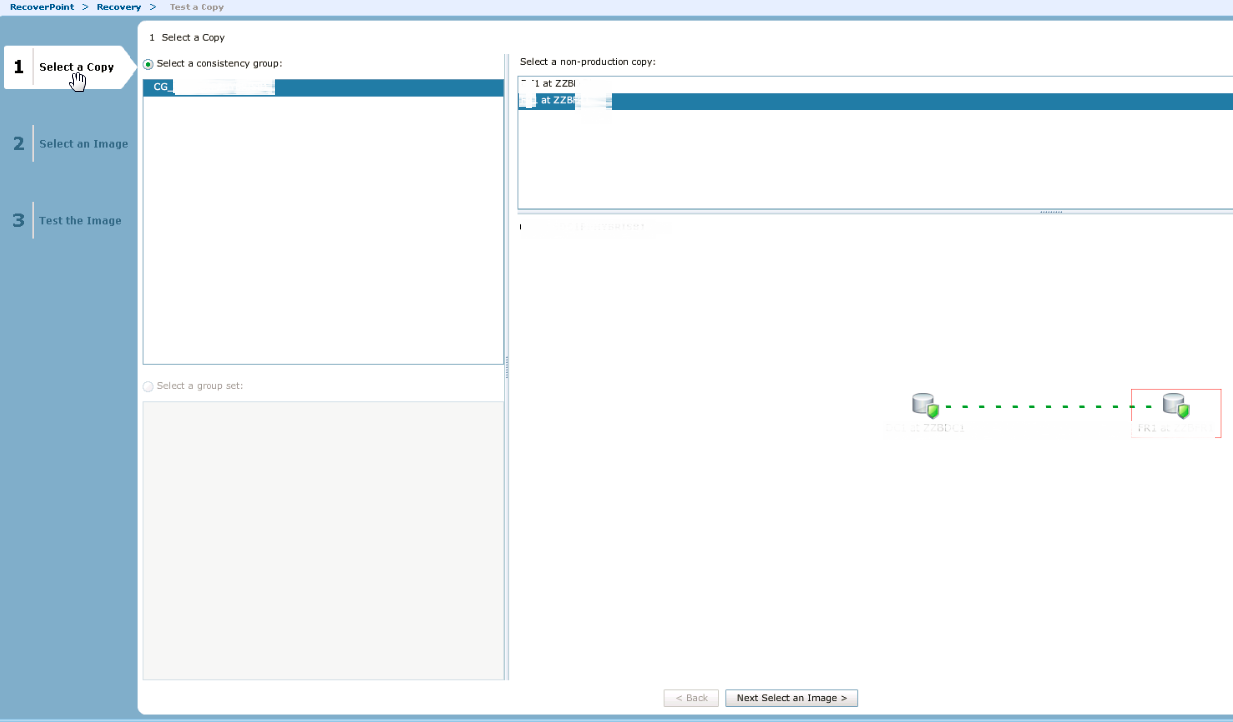
В следующем окне оставляем все по умолчанию, на Warning смело отвечаем YES. Ждем, когда копия протестируется, и нажимаем Enable Direct Access.
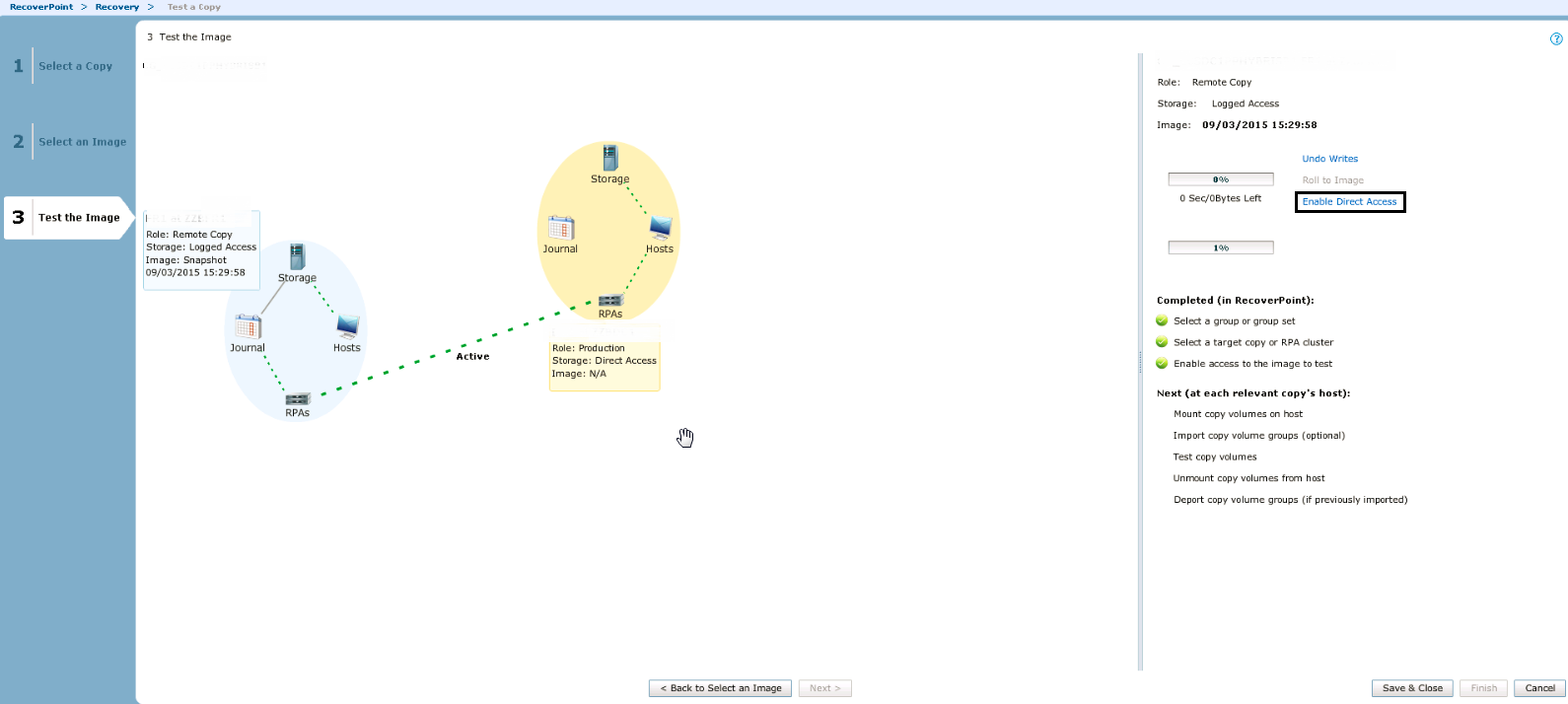
По сути на этом все. Опять же если не напутали с настройками зонинга и инициаторов, хост должен увидеть все свои LUNы c консистентными данными. Если у вас будут какие-либо вопросы и дополнения по статье, я с радостью на них отвечу. Всем легких миграций!
Комментарии (21)

k3lmiir
29.01.2016 15:41Синхронная репликация в данном случае была не нужна. Были хосты к которым было подключено LUNов на 28ТБ c часто изменяемыми данными, только один такой хост положил бы канал. В целом схема была такая — кастомер присылает список хостов и даты их физической миграции, мы заводим пары в RP и реплицируем данные, в дату перевозки репликацию останавливаем. Синхронная репликация даже пары таких хостов забила бы канал, в случае же с асинхронной мы могли балансировать нагрузку.
А насчет использования RP, в случае c двумя VPLEX для миграции пришлось бы строить geo cluster, данный вариант был предложен, но кастомер остановился на варианте с RP.
ximik13
29.01.2016 16:01EMC уже отказалось от Geo конфигурации для VPLEX см. тут
Вместо него рекомендуют пользовать MetroPoint на базе интеграции все с тем же RecoverPoint.
По прежнему не совсем понятно для чего используется в приведенной схеме VPLEX на второй площадке (там где стоят VNX)?
С первой площадкой все более или менее ясно. На площадке сплиттер для RP живет на VPLEX-е, а к VPLEX-у подключены массивы «сторонних» вендоров. На второй площадке есть EMC VNX и сплиттер RP можно было поставить прямо на него. Почему был выбран другой вариант?k3lmiir
29.01.2016 16:05Имеено по той же причине что и в первом DC — в планах использование СХД и других вендоров (уже используется IBM XIV)
ximik13
29.01.2016 16:28Ну и в порядке бреда. Вспоминая старую байку про то, что самый быстрый способ передачи данных это фура груженная под завязку дисками CD-ROM и движущаяся по дороге со скоростью 100км\ч…
А не рассматривался вариант поставить временно СХД (или несколько) из второго ЦОДа в первый. И провести миграцию всех нужных сервисов средствами самого VPLEX, что было бы в разы быстрее, чем асинхронная репликация терабайтов данных? А затем единоразово перевезти эту СХД во второй ЦОД вместе с исходными хостами (а возможно и единственным кластером VPLEX Local)?
AlexanderCam
31.01.2016 01:39Как пользователь VPLEX (2 года мучаюсь), сочувствую людям, которым впарили этот хлам, потому что:
1. До сих пор у VPLEX нет интеграции с VNX и PowerPath
2. При большом количестве объектов управление тупит очень сильно (решение не предназначено для больших окружений, хотя парни из lufthansa как-то живут, хотел бы посмотреть как)
3. При проблемах с производительностью на одном из подлежащих массивах страдают все клиенты со всех подлежащих массивов
4. Отвратительный мониторинг (в официальных курсах написано следующее: используйте Excel для парсинга csv файлов, если хотите посмотреть исторические данные по производительности)
Мы тоже мигрировали большой объем данных (сотни ТБ), но использовали для этого LVM, а не VPLEX. Данный подход хорош тем, что в будущем, при помощи LVM, перепрыгнуть на новый СХД будет на много проще без использования костылей ввиде VPLEX и RP.
VPLEX это решение одной фичи — active-active на два ЦОДа, не более.ximik13
01.02.2016 10:07До сих пор у VPLEX нет интеграции с VNX и PowerPath
Можете более подробно развернуть, что имелось в виду под интеграцией?
Ну и не совсем понятно как может помочь LVM на дистанциях асинхронной репликации.AlexanderCam
01.02.2016 12:27Под интеграцией понимается, что PowerPath должен показывать имена Storage Group и томов, как он это делает для VNX и VMAX, но не делает для VPLEX. Хотя в то же время утилита networker inquire показывает имена девайсов на VPLEX (обнаружили случайно).
В результате взаимодействие с администраторами серверов очень сильно усложнилось. Так же нет специальных политик и оптимизации под VPLEX/
LVM от Symantec решает эти задачи.ximik13
01.02.2016 13:09По поводу имен томов нет возможности проверить. Но в Release Notes на PP 6.0 от сентября 2015 года в разделе «New features» написано дословно следующее:
EMC VPLEX GeoSynchrony 5.3 support
Support for EMC VPLEX GeoSynchrony 5.3. VPLEX devices are managed by the vplex class.
Т.е. отдельный класс устройств «VPLEX» и оптимизация под них присутствует.
По прежнему не понимаю, как при помощи LVM может быть решена задача по асинхронной миграции данных, описанная в данной статье?
iscsi
01.02.2016 13:22IMO это можно сделать так:
1) Убрать I/O;
2) Синхронизировать данные;
3) Добавить в VG новый PV;
4) Сделать pvmove;
5) Убрать старый PV из VG;
6) Вернуть I/O.iscsi
01.02.2016 13:26OR не убирая I/O с помощью LVM mirror, как написал AlexanderCam ниже.
ximik13
01.02.2016 13:52В рамках описанной автором проблемы, ваше решение скорее всего не подойдет из-за слишком большого времени простоя при «узком» канале между ЦОД-ами. Т.е. нужно будет очень продолжительное время держать сервисы выключенными.
Решение уважаемого AlexanderCam тоже скорее всего не подойдет, т.к. синхронная репликация между ЦОД-ами, по словам автора k3lmiir, не возможна все из-за той же недостаточной ширины канала. А без этого «условно» синхронизация томов между ЦОД-ами не закончится ни когда (без остановки ввода\вывода с хостов). Плюс не уверен, что легко можно найти способ управления скоростью синхронизации при настройке LVM mirror. А забитый на 100% канал между ЦОД-ами, как я понял, то же заказчика никак не устраивал.
iscsi
31.01.2016 14:32Как пользователь VPLEX (2 года мучаюсь), сочувствую людям, которым впарили этот хлам, потому что:
Мы только собираемся принять участие в этом празднике жизни. Для Active-Active есть всего два варианта, которые можно будет масштабировать еще, как минимум, 5 лет: EMC VPLEX и IBM SVC.
1. До сих пор у VPLEX нет интеграции с VNX и PowerPath
Какая интеграция имеется ввиду, SMI-S provider?
PowerPath/VE доступен для VPLEX Metro.
2. При большом количестве объектов управление тупит очень сильно (решение не предназначено для больших окружений, хотя парни из lufthansa как-то живут, хотел бы посмотреть как)
vipr/ucs director
3. При проблемах с производительностью на одном из подлежащих массивах страдают все клиенты со всех подлежащих массивов
LUN «растянут» на все подлежащие массивы? Если да, то тут все очевидно.
4. Отвратительный мониторинг (в официальных курсах написано следующее: используйте Excel для парсинга csv файлов, если хотите посмотреть исторические данные по производительности)
Согласен.
Данный подход хорош тем, что в будущем, при помощи LVM, перепрыгнуть на новый СХД будет на много проще без использования костылей ввиде VPLEX и RP.
Имеется ввиду pvmove?k3lmiir
31.01.2016 16:57Как пользователь VPLEX (2 года мучаюсь), сочувствую людям, которым впарили этот хлам
В нашем случае пришлось работать с тем что было, так как, к сожалению, дизайн писали не мы.iscsi
31.01.2016 19:55Вы промазали веткой, как и я :)
А чем лично вас VPLEX не устраивает/в каком месте он мог бы быть лучше?
AlexanderCam
01.02.2016 12:40Мы только собираемся принять участие в этом празднике жизни. Для Active-Active есть всего два варианта, которые можно будет масштабировать еще, как минимум, 5 лет: EMC VPLEX и IBM SVC.
Уж лучше VPLEX, чем SVC :)
Вообще я рекомендую использовать VPLEX, только для тех приложений и сервисов, которым это реально надо, а не для всего и всех.
Какая интеграция имеется ввиду, SMI-S provider?
PowerPath/VE доступен для VPLEX Metro.
См. выше. ответил.
vipr
тоже упоси вас господь этим ужасом пользоваться. Я надеюсь в будущих версиях они с ним что-то сделают.
Имеется ввиду pvmove?
Просто делается зеркало для теукщих томов с новыми, а после того как синхронизация заканчивается — отрываем старые и все. Даунтайм был только для тех хостов, где LVM не стоял.
LUN «растянут» на все подлежащие массивы? Если да, то тут все очевидно.
В том-то и дело, что без растянутых LUN'ов. К сожалению очень сложно воспроизвести данный случай поэтому мы пока просто перейдем на 4-Egine конфигурацию для изоляции мощных потребителей на своих директорах.AlexanderCam
01.02.2016 12:49vipr
1. Это стоимость ViPR. И звучит это примерно так — мы тут спецом сделали дерьмовое управление и интеграцию, чтобы стрясти с вас ещё кучу бабла. А поверьте мне, когда у вас будет пару десятков массивов и петабайт, то стоимость ViPR вас крайне удивит…
2. Не буду заниматься рекламой, но есть прекрасный вендор СХД, который предоставляет такой софт бесплатно.iscsi
01.02.2016 13:172. Не буду заниматься рекламой, но есть прекрасный вендор СХД, который предоставляет такой софт бесплатно.
А он такой ровно один, но у него есть другие проблемы :)
ximik13
Все замечательно. Но есть несколько вопросов.
1) Зачем в данной схеме RP, если на обоих площадках есть VPLEX?
2) Канал между площадками не позволяет организовать синхронную репликацию? И собрать VPLEX в Metro конфигурацию?
3) Если синхронная репликация между площадками невозможна, то для каких целей куплен VPLEX на обе площадки?