
Нет, мы не собираемся витийствовать о том, что не бывает хороших и плохих слов, а есть наша оценка оных. Также мы не будем говорить об истоках и функциях русской брани, не будем обсуждать моральную сторону вопроса, как и искать причинно-следственные связи ее употребления. Мы проведем небольшое исследование обсценной лексики на материалах русскоязычных соц. медиа, сделаем ряд замеров и расчетов на большой выборке из интернет-источников.
Мат. часть
В качестве материала был обработан двухмесячный поток русскоязычного сегмента соц. медиа, собранный системой Brand-Analytics в период с начала ноября 2014 года по начало января 2015 (почему был выбран этот период, станет понятно в конце статьи). Было обработано около 45 миллиардов слов (ставим тег Big Data). Обработка заключалась в построении частотных словарей (униграммы и биграммы) за каждый день и построении языковых моделей — инструмент SRILM (ставим тег Text Mining).
Таким образом, можно было посмотреть динамику любого слова или словосочетания за этот период. Посмотрели разное и многое. Что-то понравилось, что-то нет. Например, на рисунке 1 показаны частотности личных местоимений и предлогов:
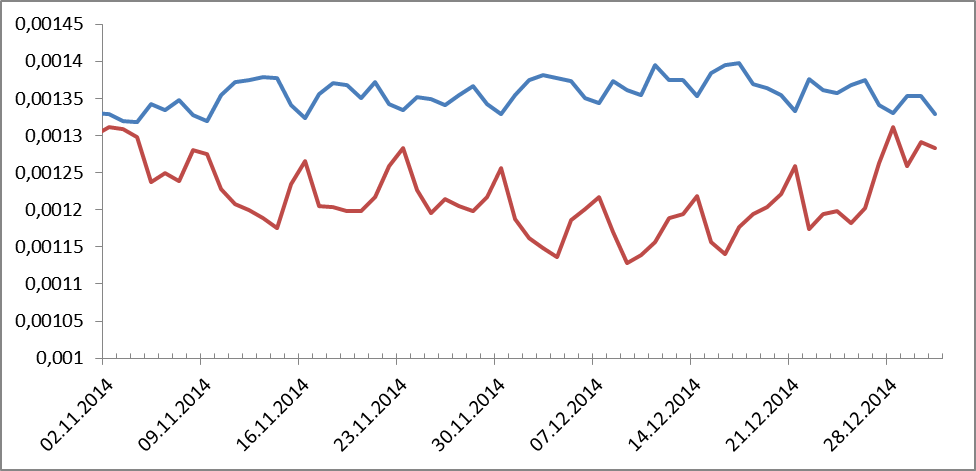
Рисунок 1. Динамика частотных распределений для предлогов (сини цвет) и личных местоимений (красный цвет).
Оказались в противофазе. Неожиданно, правда? А пики – как вы догадываетесь – выходные. А что говорили о деньгах? Смотрим:
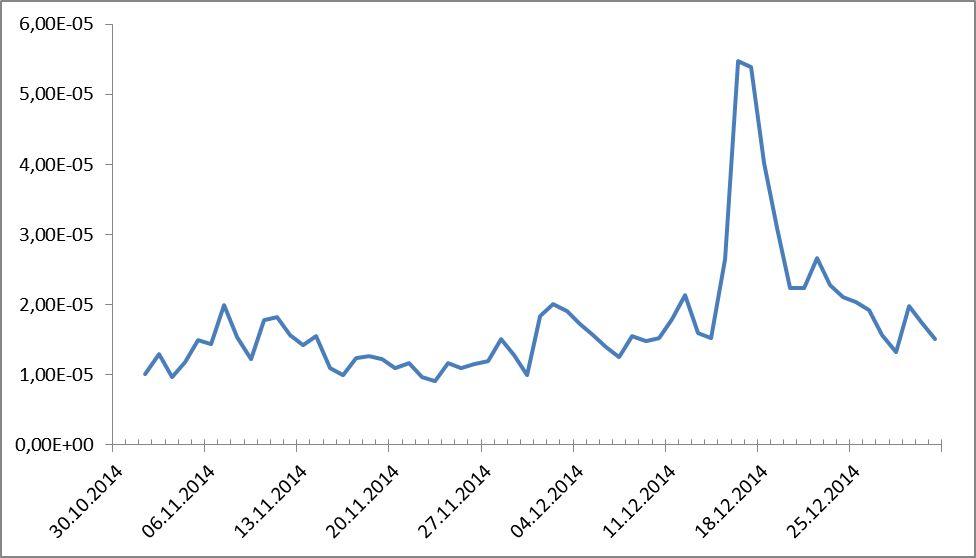
Рисунок 2. Динамика частотных распределений для названий денежных единиц.
Тут вроде бы вопросов не должно быть, все помнят 18 декабря 2014-го. Но если кто-то подзабыл, то напомним:
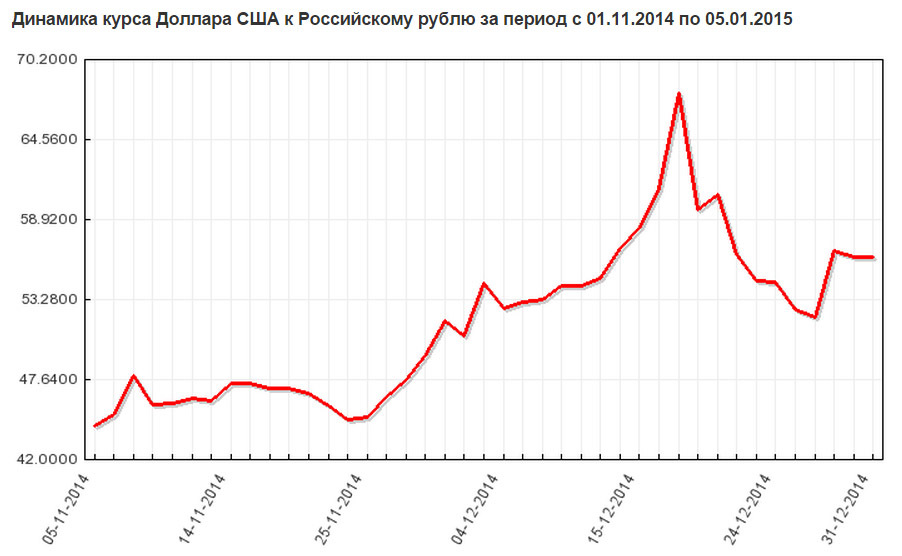
Но это тема отдельной публикации. Ну и как же не посмотреть то, что нельзя произносить при дамах, а уж тем более писать на уважаемом хабре! Да, их — наши, русские, четыре
Ок, сказано – сделано. Взяли наш фильтр русской обсценной лексики. А там аж более пятисот уникальных слов с морфотипами. Нагенерили всех словоформ. Получилось что-то около 8650. Ого, однако, не хилое словообразование….
Теперь эксперимент и картинки
Чтобы нас не забанили за нецензурщину, да и плюс, как говориться, «при дамах попрошу не выражаться», сделаем так: условно объединим их (к слову о местоименной анафоре: лексику, не дам) по морфологическому признаку и обзовем группами из неизменяемых составляющих их букв (ну, все же эти слова знают, пояснять не надо?):
- Группа Б
- Группа Х
- Группа Е
- И группа П
Дополним еще двумя:
- Группа Г (да-да, однокоренное с говядиной), потом будет ясно зачем.
- И группа О, в смысле остальное на буквы Му*, Пид*, и пр.
Примечание. Мы учитывали все словоформы, в том числе неграмотно написанные (замена букв: пля), удлинение ударных гласных (*ляяя) и наиболее частотные ошибки, сами знаете какие. Эвфемизмы не учитывали, т.е. всякие блин, хрен, трах – нормальные себе слова.
Сразу скажем, что нашлось из этих 8650 слов по всему частотному распределению около тысячи. Во-первых, частотные словари обрезались: учитывались 95% от суммы частотного распределения (т.е. хвост обрезался — чего с собой весь хлам тащить), что позволяло сократить до 30-50% объема словаря, но при этом только 5% объема исходного материала), а во вторых, многие словоформы и правда получились экзотичны.
Примечание (если кому-то интересно). Частотность исследуемой нами лексики начинается с конца второй тысячи ранжированной по частоте выдачи (из почти 12 млн. токенов).
Итак, строим и смотрим графики. График первый – абсолютное количество найденных слов по группам:
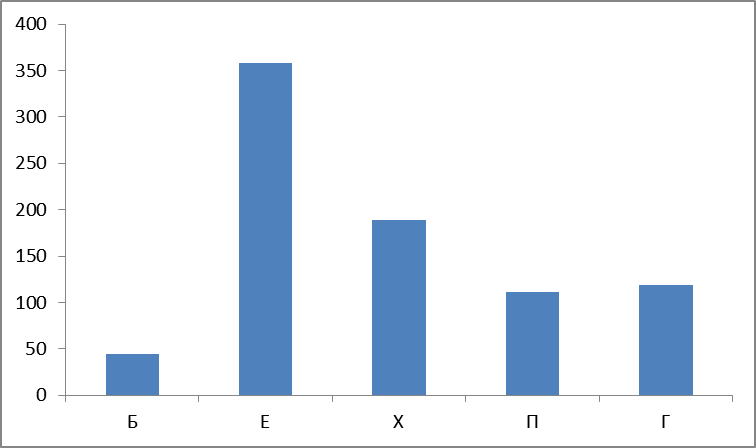
Рисунок 4. Абсолютное количество найденных слов по группам.
А в частотном выражении (точнее, мы оперируем обратными или нормированными частотами)? А вот график два:
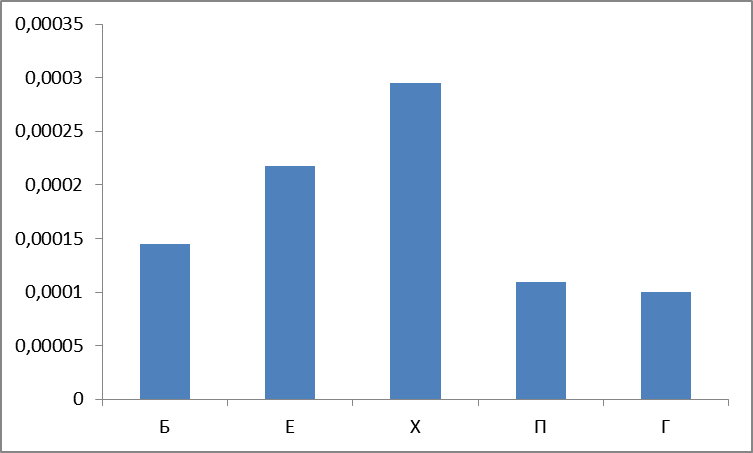
Рисунок 5. Сумма нормированных частот найденных слов по группам.
А теперь среднее: сумма частот нормированная на абсолютное количество:

Рисунок 6. Среднее нормированных частот найденных слов по группам.
Вот и первый сюрприз: считается, что наиболее частотные группы П,Х,Е («очень частотная «сексуальная» триада» ) — ан нет, группа Б лидирует, причем с большим отрывом.
А зачем мы везде группу Г за собой тащим? А вот зачем: на всех графиках видно, что сумма П+Х+Б+Е и в абсолютном, и в относительном значениях однозначно больше группы Г. То есть, как и ожидалось, наш мат
Что еще можно посмотреть? А давайте посчитаем дисперсию?
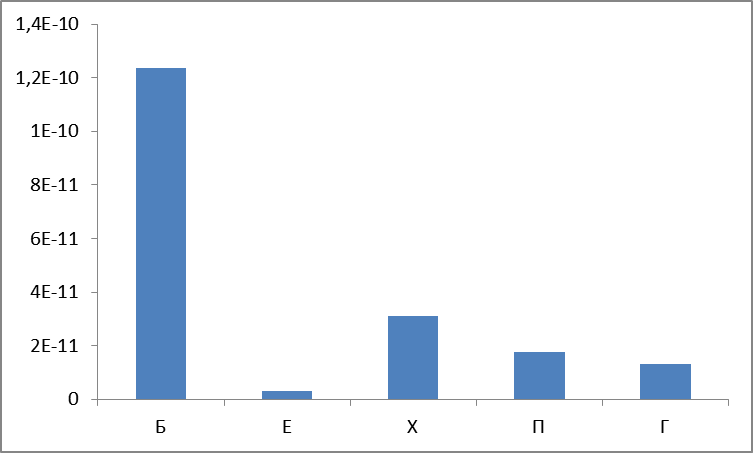
Рисунок 7. Дисперсия по группам.
В общем, не удивительно, что наиболее частотная группа имеет наибольшую дисперсию (следствие пресловутого закона Ципфа). Группа Е оказалась наиболее стабильна, ибо ее распределение наиболее равномерно и сосредоточено не в крайних областях.
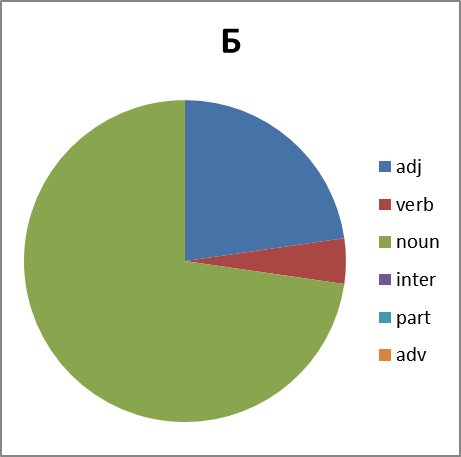
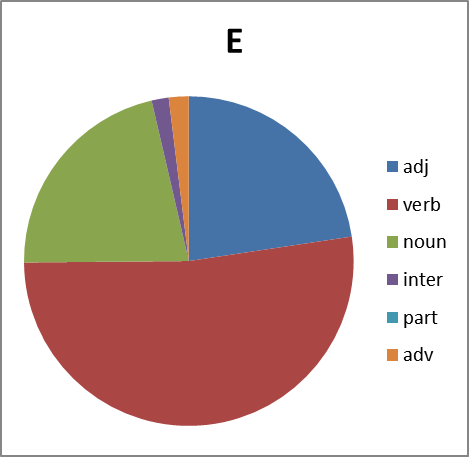
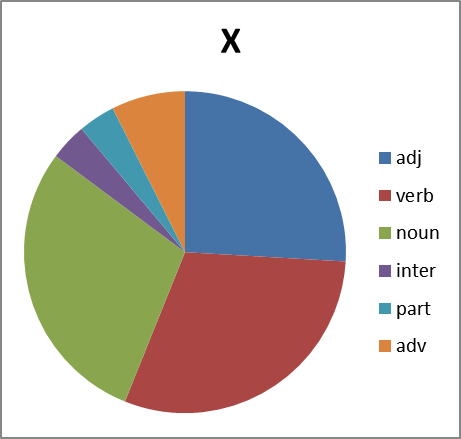
Хорошо. Смотрим дальше. Интересно, а каково распределение по частям речи. Тут вопрос не простой. Потому что вне контекста не всегда возможно однозначно определить часть речи обсценной лексики. Зачастую существительное употребляется как междометие, наречие или даже частица (отрицание в группе Х, например). Поэтому строим круговые диаграммы с некоторой долей ошибки. Тем не менее:
 |
 |
 |
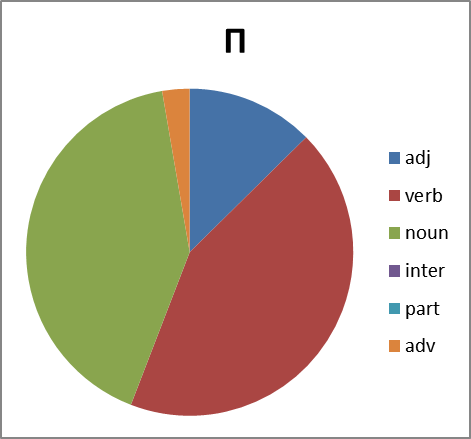 |
Рисунок 8. Распределение слов каждой группы по частям речи. Сокращения: adj -прилагательные, verb — глаголы, noun — существительные, inter — междометия, part — частицы, adv -наречия.
Какие мы можем сделать выводы, глядя на все это? Группа Б существенно отстает в вариативности от групп Х,Е и П. И по непонятным нам причинам почти не образует глаголов. Зато группа Х просто пестрит. Но анализ сего явления оставим профессионалам в этой области…
Ну а теперь самое интересное: а какова же динамика употреблений исследуемого объекта в указанный период, т.е. в период кризиса конца 2014, перешедшего в перманентный? А тут становится еще интереснее:
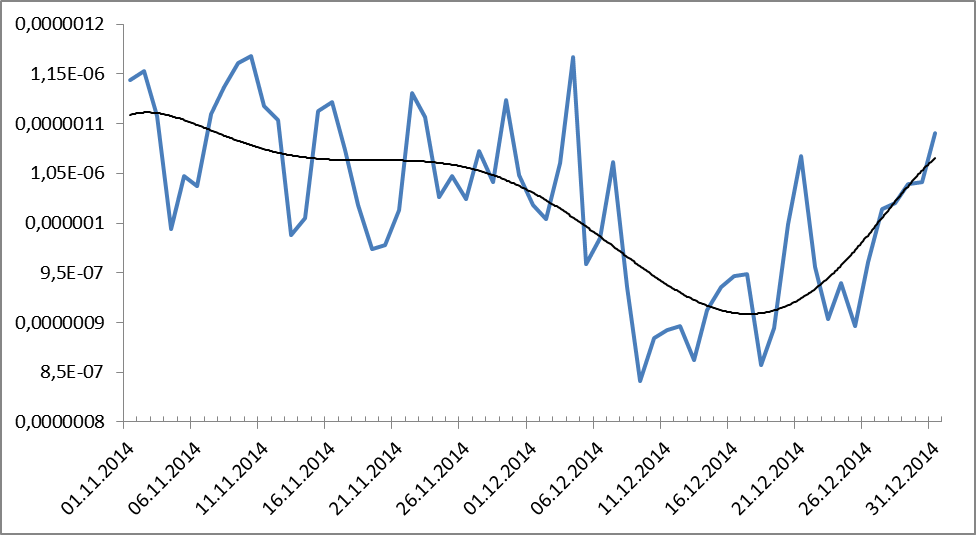
Рисунок 9. Динамика частотного распределения обсценной лексики за период с 1.11.2014 по 31.12.2014. Черным показана линия тренда (полиномиальная, 9-ой степени).
Что же это получается? В кризис употребление обсценной лексики падает? Получается, да.
Сделаем промежуточные выводы:
- обсценная лексика имеет сильное словообразование (у некоторых лексем может быть по нескольку морфотипов). Это говорит о том, что при ее употреблении должна повышаться энтропия текста, его сложность;
- в период кризиса, вроде бы, эмоциональность должна расти, употребление эмотивных слов увеличиваться, но мы наблюдаем обратную картину.
Может, где-то ошибка? Как бы проверить? А давайте посмотрим динамику сложности текста, его perplexity? Тяжко, конечно, с такими объемами работать, но что делать. Посчитали, получили:

Рисунок 10. Динамика распределения перплексити за период с 01.11.2014 по 31.12.2014. Черным показана линия тренда (полиномиальная, 9-ой степени).
Примечание. Большое значение перплексити возникает вследствие того, что из-за больших объемов мы использовали сильное сглаживание и накладывали частотные ограничения. Считали на униграммах и биграммах.
Опять сюрприз: а сложность-то тоже падает. Получается, думали-то мы верно: эмоциональность связана со сложностью. Но ошиблись на «пи пополам» в предположении, что в кризис эмоции должны «зашкаливать» — ровно наоборот.
Может быть, это связно с изменением количества публикаций в кризис? Тогда вот еще один график количества словоупотреблений:
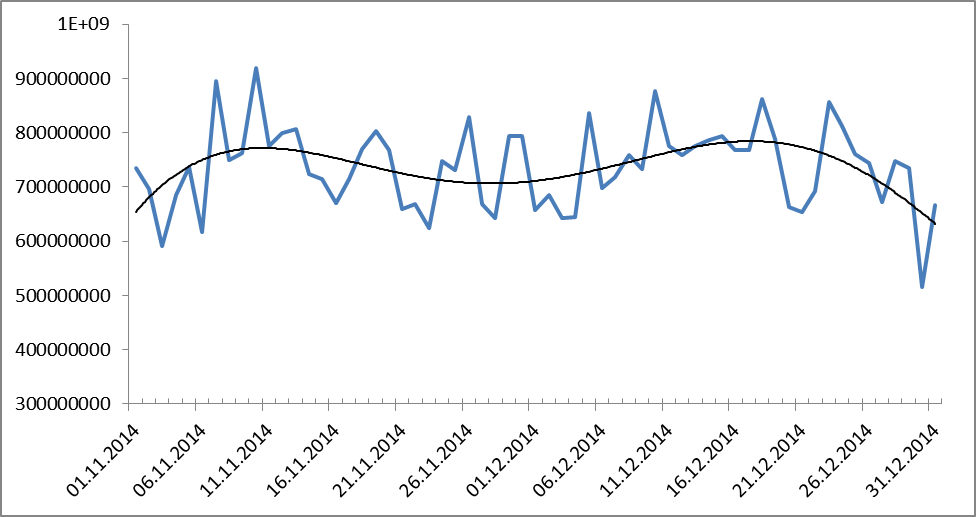
Рисунок 10. Динамика словоупотребления за период с 1.11.2014 по 31.12.2014. Черным показана линия тренда (полиномиальная, 9-ой степени).
Остается, наверно, посчитать корреляцию (perplexity vs обсценная лексика):
— коэффициент корреляции ~ 0,51, что, вроде бы, не ах как много.
Но все относительно: корреляция перплексити с предлогами ~ -0,04, а с личными местоимениями -0,06.
Выводы
Даже не знаем, что и вывести. Для серьезного анализа данных мало (всего один кризис), а померить что-то еще – это отдельная статья. Может быть так: делайте выводы сами — употреблять или не употреблять. Возможно, это как-то повлияет на экономический кризис…
Спасибо за прочтение!
Комментарии (43)


Neftedollar
29.03.2016 17:49+2Спасибо! Очень интересно!
Не ожидал, что у группы П такое большое кол-во глагольных форм.



reji
29.03.2016 18:12+5Интересно поставить звукозаписывающее устройство в комнату к админам, и посмотреть на корреляцию с релизом, факапами, кол-ву закрытых задач и других "нестандартных решений".

stigory
30.03.2016 05:10+2Судя по моему опыту, когда в админскую заглядывает милый пушистый зверек, то не то что матов не слышно, разговаривать перестают. Слышно обычно только пыхтение и злобное шипение.
Но, когда зверек уходит, вот тогда держись. Накопленное прорывается.

acidnik
29.03.2016 19:27+5А почему, б*я, совсем нет слов на Б — междометий?

Ohar
29.03.2016 20:18+1Тоже интересно. Мне кажется, они что-то с определением частей речи напутали.
lingvolab
29.03.2016 21:49+1Более-менее точно можно определить только глаголы и прилагательные, существительные могут выступать как междометия, а иногда и как частицы или наречия. Для этого нужен контекст. Согласен, "б*я" — чаще всего междометие.

TheGodfather
29.03.2016 20:12+1Было бы интересно посмотреть графики для динамики на более длинном периоде, два месяца — не очень показательно. Год или два — вот это да.
lingvolab
29.03.2016 22:05+1На таких объемах — 45 млрд. слов — показательно. Ошибки сглаживаются. Другое дело, что причины такого поведения кривых не очень понятны. А на более длинном периоде — согласен, можно посмотреть с привязкой к разным событиям, поискать корреляцию с разного сорта лексикой.

Slavenkof
29.03.2016 20:13+1А у меня вот такой вопрос. Известно, что обсценная лексика обладает следующим свойством: междометия и существительные омонимичны (т.е. пишутся одинаково). Например:
1) «Б, как страшно-то!» «Вот и все, П...»
2) «Я тут свою б навещал...» «П нагрянул неожиданно и бесповоротно»
В первом случае мы имеем дело с междометиями, а во втором с существительными.
Насколько хорошо автоматика справляется с определением части речи в таких случаях?lingvolab
29.03.2016 21:59+1На таких объемах (до 100 сообщений в секунду) мы не включали pos-tagger — затратно для такой задачи, т.е. части речи проставляли вручную по результату. А вообще, это зависит от того, на каком материале систему обучить. Обычно у междометий высокая точность определения — около 99%.

webmasterx
30.03.2016 05:00+1Не совсем понял рисунок 9. Вы строили график употребления слова из групп по отношению ко всем остальным словам в этот же день?
lingvolab
30.03.2016 10:36+2Нет, это изменение сложности текста в указанный период по всем сообщениям (по всем словам, не только из группы). Оказалось, что это коррелирует с динамкой изменения обсценной лексики.
mwambanatanga
30.03.2016 10:37+1Группа Б существенно отстает в вариативности от групп Х, Е и П. И по непонятным нам причинам почти не образует глаголов.
А какие могут быть глаголы в группе Б? Я так сходу ни одного не могу придумать. Существительное (одушевлённое, женского рода) — да. Междометие — да. И, пожалуй, всё…

elingur
30.03.2016 15:46+1Интересно вот что: если представить соц.медиа как некий живой организм, то а можно как-то прогнозировать (диагностировать) его поведение (отклонения) на какие-либо события, и наоборот, по его поведению предсказывать возможные события (например, в экономике)?
lingvolab
30.03.2016 16:29+1О том и речь! За экономику не ручаюсь, но прогнозировать что-то можно. Пока, скажем, это первая попытка найти связи между эмоциями и событиями.

kretuk
31.03.2016 11:11Как известно, связи, при желании, можно найти чего угодно и с чем угодно.
lingvolab
31.03.2016 11:14+1Можно. Но на больших данных ошибки нивелируются, а закономерности всплывают. Вопрос в другом: их не всегда можно объяснить, да и связаны эти закономерности могут быть с чем-то совершенно другим. Но игнорировать их уже нельзя.
Gryphon88
30.03.2016 16:10+1Мне кажется, интересная задача оценить встречаемость и сложность по отраслям (новостные ленты, политика, экономика, религия, технические науки, материнство и детство, отношения и семья), по посещаемости и по обязательности регистрации.
lingvolab
30.03.2016 16:25А с какой целью? Для классификации сообщений по отраслям? Можно, но это не очень точный алгоритм. Тут скорее нужно искать корреляции лексики/сложности по отраслям к описываемым событиям. Но пока не очень понятно, как — параметров получается очень много.
Gryphon88
31.03.2016 01:23Лично мне интересны следующие вопросы (ожидает подтверждение/опровержение для утверждений):
- Российскую политику и экономику (почти) невозможно обсуждать без использования обсценной лексики. Предположительно, лидирует группа П
- Официальные новостные ленты модерируются активнее, чем либеральные
- Матерятся в основном анонимусы
- На женских форумах матерятся не меньше, чем на мужских. Или меньше, но сложнее.
- На технических ресурсах матершина реже, но сложнее.
- С ростом популярности ресурса растёт частота, но падает сложность. При падении популярности — процесс обратный.
Про возраст тоже очень интересно. Я ожидаю параболу в осях сложность/возраст, если от 12 до 50 брать.
С регионами будет сложно, советую вооружиться двухтомничком "Энциклопедия русского мата", там учитываются региональные особенности. Как в той шутке, "а у нас, в Новгороде, говорят через Ярослав" (про самый популярный глагол группы Е)
lingvolab
31.03.2016 09:28+1Ну это больше социологические вопросы. Наиболее интересен шестой пункт, т.к. менее всего очевиден.
Мы не учитываем региональные особенности, но учитываем наиболее частотные употребления: Я вместо Е имеется.
Собираемся посмотреть распределение по регионам, по полу и по возрасту. Надеюсь, публикуем в скором времени.

LoadRunner
30.03.2016 17:52+1А данные были без привязки к чему-либо? Интересно было бы увидеть распределение групп по возрасту употребляющих.
lingvolab
30.03.2016 17:54+1Да-да, в процессе. Собираемся сделать распределение по возрасту, полу и регионам.
hdfan2
31.03.2016 09:22+1Вспомнился анекдот в тему (и, кстати, вопрос: учитываются ли указанный тип слов?)
Урок русского языка. Учительница дает задание:
(У) — Дети, назовите несколько слов на букву "х".
Вовочка тянет руку. (У), зная Вовочкин словарный запас, слова ему не дает.
(У) — Ну, давай ты, Леша.
(Л) — Хвостики!!!
(У) — Молодец! Ну, давай ты, Оля.
(О) — Хомутики!!!
(У) — Очень хорошо! Теперь назовите слова на букву "р".
Вовочка отчаянно тянет руку. (У), не вспомнив ни одного плохого слова на "р", дает слово Вовочке.
(В, выбегая из класса) — Хвостики! Хомутики! Расп3.14здяи!!! Я из-за вас чуть не обоссался!!!
l7l
А с динамикой употребления обсценной лексики во время до кризиса и во время кризиса все ясно: до кризиса мы переживаем, волнуемся, пишем сообщения в духе «Лишь бы Х не случилось...», «Б, вот-вот все П накроется!», «Е как страшно-то!» и так далее) А как кризис наступит там слов много не надо, достаточно одного емкого П. Или продолжительного Е.