

Всего 2 часа назад я дописал последний тест к новому типу связи для PHPixie ORM — Nested Set. Я долго думал использовать ли этот подход или же Closure Table для хранения деревьев в SQL базах. Но в результате Closure Table проиграл ввиду квазиквадратических размеров к которым растет таблица связей (при 20 нодах в худшем случае уже можно получить 190 записей). Так что следующей задачей стала оптимизация классического Nested Set подхода, и результат мне очень даже понравился.
Одной из главных проблем в использовании Nested Set является стоимость вставки ноды. Чем левее позиция вставки тем больше записей надо сдвинуть вправо. Например есть у нас вот такое дерево:
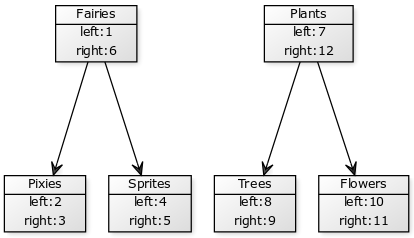
Допустим нам надо вставить подкатегорию Fay в Pixies, результат получится таким:
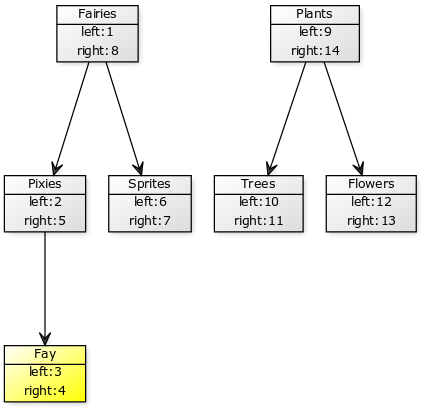
Как видим изменить придется все ноды в дереве. А теперь представьте что вы таким способом сохраняете дерево комментариев к статьям. Каждый раз когда кто-то добавляет новый комментарий у вас происходит апдейт кучи записей, кроме того надо обязательно делать это все в транзакции при чем желательно запретить изменения этих строк параллельными запросами. Если всего этого не сделать, то даже несколько активных пользователей комментирующих одновременно могут легко сломать всю индексацию. Да и производительность системы очевидно тоже сильно страдает.
Я нашел элегантный способ как решить эту проблему всего лишь чуть-чуть изменив стандартный Nested Set. Идея его проста, хотя имплементация заметно сложнее в некоторых местах. Ко всем нодам следует добавить идентификатор поддерева в котором они находятся, например id корня. В каждом поддереве нумерацию left и right начинаем сначала. Вышеприведенный пример с таким подходом выглядел бы вот так:
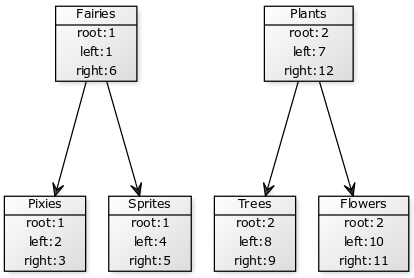
При вставке нам надо изменять только ноды находящиеся в том же поддереве:
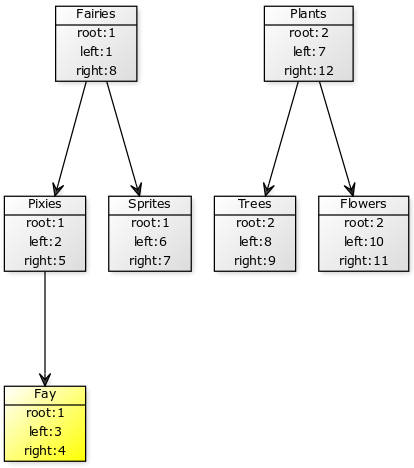
Как видим поддерево Plants не поменялось совсем. С практической точки зрения это на порядки уменьшает количество измененных строк в базе. Если изменения проходят в разных поддеревьях они совсем не мешают друг другу и даже если в одном из них сломается индексация этот никак не повлияет на другие.
За эти удобства приходится платить более сложным кодом. Легко ошибиться и забыть изменить поле root при переносе ноды в другое поддерево или выносе ее в корень, также немного усложняется процедура превращения записей в объектное дерево и т.д. Как раз по этому столько времени ушло на написание тестов для всех случаев.
Использование в PHPixie
Полная дока появится на сайте уже скоро, но вот маленький гайд для тех кто хочет использовать новую связь уже сейчас.
Во первых добавьте 4 INTEGER поля к таблице в которой хранятся элементы: left, right, rootId, depth (конечно-же имена полей полностью настраиваемыми, это лишь дефолтные). Затем добавьте связь в /bundes/app/assets/config/orm.php
return array(
'relationships' => array(
//....
array(
'model' => 'category' //имя модели,
'type' => 'nestedSet'
)
)
);
Дальше все просто:
$fairies->children->add($sprites);
$fairies->children->add($pixies);
//ну или так
$pixies->parent->set($fairies);
//поместить категорию в корень
$pixies->parent->remove();
//подгрузить все дерево с БД
//заметьте условие where('depth', 0),
//без него в результате мы бы получили все категории
//а не только те что сверху (то есть кучу дубликатов)
$categories = $orm->query('category')->where('depth', 0)->find(array('children'));
Кстати PHPixie сама будет следить за удалением сущностей и исправлять индексы.
Надеюсь новый функционал всем понравится, а тем кто не использует PHPixie может пригодится подход с оптимизацией.
Если интересны какие-то детали или просто хочется поболтать, заходите к нам в чат.
Комментарии (26)

Mendel
24.04.2016 11:19+1Тяжеловато как-то выглядит.
Лет пять назад я для себя «изобрел» NI.
Не помню подробности, но вроде просто отказался от того что нумерация идет подряд, и у «листа» (одиночного узла без потомков) разница между левым и правым могла быть и 100000. Плюс если таки было нужно двигать, то двигал я не строго в лево, но мог и вправо если это ближе… Если не ошибаюсь понадобилось лишь добавить уровень(относительно корня), чтобы сохранить старую функциональность.
А вообще НС хорошая штука, но не всегда нужна. Нужно думать зачем. Какие операции более частые и сравнивать цену операций. Я в большинстве задач ушел на более простые модели.

jigpuzzled
24.04.2016 12:37Я кстати тоже пробовал сохранять комментарии по другому, даже к neo4j добрался. Пока что лучше всего получилось с монгой =)

PaulZi
25.04.2016 11:12А я для себя пришёл к выводу, что лучше всего работать в связке Adjency List + Materialized Path. Работает очень шустро со всеми видами выборок (и вставок).

amakhrov
24.04.2016 12:02+1> Я долго думал использовать ли этот подход или же Closure Table для хранения деревьев в SQL базах
Вообще надо понимать, что в зависимости от характера использования иерархических данных хранить их можно по-разному. Например, для дешевой операции вставки — тривиальный adjacent list, для дешевого поиска — nested set.
Вот здесь есть шикарное описание разных способов хранения деревьев в реляционных БД.
stackoverflow.com/questions/4048151/what-are-the-options-for-storing-hierarchical-data-in-a-relational-database
Возможно, в примере с комментариями к статьям, приведенным автором, nested set — как раз не лучший вариант. По ссылке на SO предлагают Flat Table в этом случае.jigpuzzled
24.04.2016 12:08На самом деле я собирался сделать оба варианта, чтобы пользователь мог сам выбрать чем пользоваться. Но так как время у меня ограниченное хотелось начать с более общего подхода.
Кстати если активных пользователей так много что вставка происходит часто, то скорее всего читателей которые не комментирует еще на порядок больше. А в последнее время я в обще склоняюсь к тому чтобы хранить комментарии в монге для удобства.

franzose
24.04.2016 12:15А можно скрестить adjacency list и closure table. Работать будет очень быстро.
jigpuzzled
24.04.2016 12:28только в Closure Table в худшем случае количество записей равно: n!/(2*(n-2)!) что очень быстро растет, что довольно таки печально =(

MikeLP
24.04.2016 18:48+2Есть еще materialized path. Тоже неплохой способ хранить деревья.
jigpuzzled
24.04.2016 18:58он хорош, но только для деревьев которые не особо глубоки, а то все эти опереции с префиксами на стрингах начинают сильно тормозить. Правда как бонус путь можно сразу использовать для постройки УРЛов в рутере =)

boolive
25.04.2016 00:52Путь можно по колонкам разбить. С такой реализацией и быстро и довольно дешево редактировать. Ограничение по глубине можно обходить используя дополнительные таблицы.

babylon
25.04.2016 02:42Правда? Глубина это сколько метров? Кто мешает захэшировать путь? Не верю про тормоза. Откуда они берутся? От длины ключа? А «В Контакте» как работает? У нас на плоских индексах экономят зато все остальное тормозит:)) Что такое сдвиг правее?
jigpuzzled
25.04.2016 07:50Тормоза от LIKE запросов, которые необходимы при поиске детей ноды.

mjr27
25.04.2016 09:58+1LIKE «prefix%» через индекс же идет
jigpuzzled
25.04.2016 10:51Этот индекс все равно медленнее числовых, к тому же при поиске вверх (найти всех родителей) уже не помогает. Да и при собирании объектного дерева из таких записей приходится на каждой делать explode() а это тоже не дешево в большых количествах
Mendel
25.04.2016 11:22Так родители то в пути уже и прописаны. На то он и МП.
Братья через префикс%, Дяди — через префикс%. В общем то любые родственники одного уровня (двоюродные дедушки, и т.п.) через префикс%. А, ну да, это работает если к МП добавить еще поле уровень.
А других поисков по предкам я на своей практике и не припомню. Описанные дяди и двоюродные дедушки у меня встречались часто в различных менюшках, когда дерево было деревом страниц на сайте.
Вообще по моему опыту который в деревьях небольшой — НС имеет лишь одно преимущество перед НИ — простота. При этом не так много задач где они оба имеют преимущества над другими. Ну в НС количество потомков можно получить без запросов в отличии от интервалов. Но…
Вообще тут нужно реальные тесты делать, а не гадать. У меня к примеру большие сомнения что в реальной задаче хоть когда-то эксплоде будет узким местом. Его тяжесть довольно условна.
boolive
25.04.2016 10:39+1Не понимаю к чему ваши вопросы. Разбивая путь по колонкам имеем целочисленные колонки под идентификаторы родителей. Нужно выбрать всех детей какого-то объекта — делаем условие равенства на соответствующую колонку. Ограничение связано с максимальным количеством колонок у таблицы.
franzose
25.04.2016 15:05+1Плодить колонки это вообще жесть. Проще уж уровень записывать в одну колонку.
boolive
25.04.2016 15:52Не видно аргументации. Если вас пугает количество колонок, то знайте — это цена за скорость выборки, изменений и сравнительно простой реализации. Реализация может незначительно усложняться, чтобы нивелировать ограничение по глубине, сделать оптимальную индексацию.
PaulZi
25.04.2016 11:26У каждого алгоритма хранения деревьев свои ограничения:
AL — сложная выборка потомков и предков (join-ы и т. п.);
NS — годится только для маленьких деревьев, т. к. вставка в начало большого дерева займёт катастрофически много времени, кроме того выборка предков тоже не достаточно быстра;
NI — очень сложная реализация, необходимость тонкой настройки
MP — из недостатков разве что чуть более медленные операции на string полем
CT — как выше сказано — кол-во записей
В принципе проводя измерения производительности, выигрывала связка AL+MP, те методы которые медленно делались AL, выполнялись MP. У такого подхода практически нет слабых мест.
JhaoDa
jigpuzzled
Больше нигде в интернете его не встречал и не знаю ни одной библиотеки которая бы использовала такой подход
JhaoDa
Tree из DoctrineExtensions, например.
jigpuzzled
С того что я вижу, они сохраняют значение root но не делают отдельный отсчет left и right в поддеревьях. При вставке все равно приходится сдвигать все элементы правее от новой ноды. То есть для оптимизации оно не используется и несет разве что удобство при написании запросов:
AnToni00
Scope из Baum (реализация Nested Set для Laravel)
jigpuzzled
Проверил. Оно чуть по другому работает и идея там не в оптимизации а в немспесах