
Прошлая статья про SDR и GNU Radio показала, что тема интересна сообществу. Учитывая, что про пакет GNU Radio информации на русском языке почти нет, да и на английском не всё понятно, я решил описать свои опыты с GNU Radio.
Про SDR и GNU Radio я уже писал в предыдущей статье. Напомню, моя цель показать, как перехватывать и даже излучать радио сигнал для управления устройствами умного дома (да и вообще IoT). Считаю важным привлечь внимание к безопасности в IoT. Но до этого нам ещё далеко… Для начала разобраться бы с GNU Radio!
SDR-приёмник есть не у всех, и мне показалось, что будет полезным показать, что можно сделать с GNU Radio с тем, что есть у каждого — а именно с микрофоном вашего ПК и наушниками.
Под катом несколько интересных экзерсисов со звуком.
Звуки вокруг
Итак, начнём с простого: изучения спектра звуков вокруг. Будем считать, что установку пакета GNU Radio или запуск подготовленного образа Ubuntu/Windows с GNU Radio вы произвели. Если нет, то на сайте GNU Radio скачайте образ на базе Ubuntu.
Начнем с создания простого проекта захвата звука с микрофона. Для этого добавим блок Audio Source, выставим samp_rate 48000 (многие карты работатю на 44100 Гц, а не на 48000 Гц).
$ pactl list short sinks
0 alsa_output.pci-0000_00_03.0.hdmi-stereo module-alsa-card.c s16le 2ch 44100Hz SUSPENDED
1 alsa_output.pci-0000_00_1b.0.analog-stereo module-alsa-card.c s16le 2ch 44100Hz SUSPENDEDВообще числа 48 кГц и 44.1 кГц — дань прошлому. Они связаны с количеством кадров в секунду и строками развёртки в древних системах записи видео, потом с форматом CD. В наши дни эти значения так и осталось стандартами.
Вернёмся к нашей схеме GNU Radio. К Audio Source подключим WX FFT. Не забываем QT GUI заменить на WX GUI в top_block, а так же изменить тип входа на Float. А теперь будем бегать по квартире, издавая разные звуки. Школьная физика нам много рассказала о том, что мы увидим, но все это забыто, да и своими глазами увидеть всегда интересней, чем просто прочесть в учебнике.
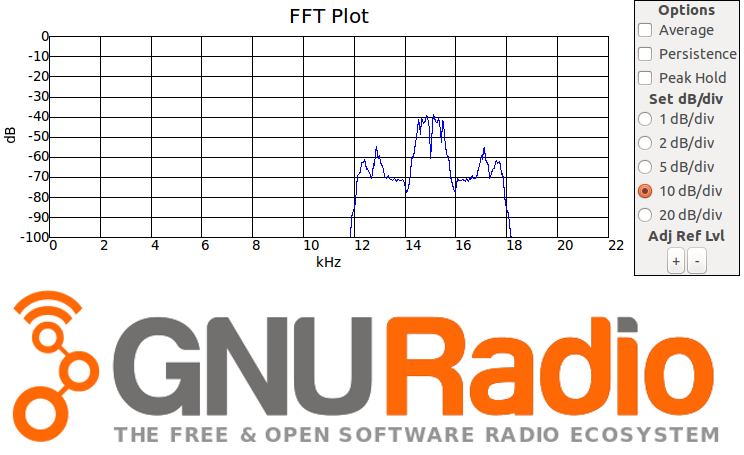
Первое, что мы увидим — ничего не видно! Вся значимая часть спектра сосредоточена в первых 2 или 3 кГц. Ну, ок, давайте добавим между источником и WX FFT новый блок: Rational Resampler — он позволит изменить Sample Rate, оставив только нужную часть спектра. Для удобства заведём новый блок Variable (переменную), назовём resamp и зададим значение, например, 15. В блок ресемплера в поле Decimation впишем имя этой переменной. Теперь на WX FFT будет подаваться сигнал с Sample Rate равным samp_rate/resamp, т.е. в этом блоке в поле Sample Rate нужно вставить именно это выражение. Теперь наш сигнал будет простираться до 1.5 кГц, что уже лучше. Ну, теперь всё видно!
Итак, начните с ноты ля 440 Гц. Проверим свой голос на
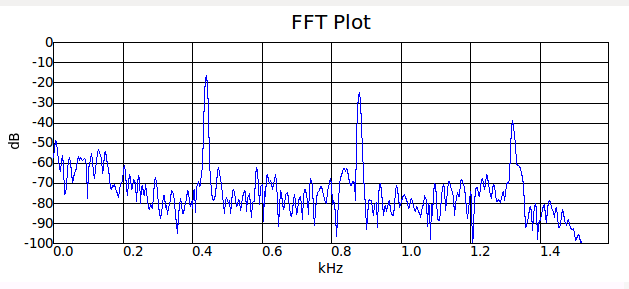
А вот ля малой октавы. Всё как по учебнику — пиков стало в 2 раза больше, низший пик стал в 2 раза ниже (220 Гц)
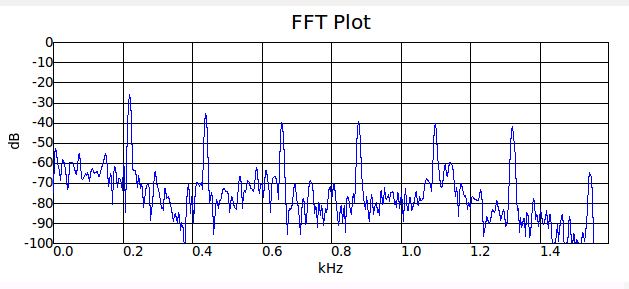
Кратные частоты присутствуют не случайно. Ведь в случае пианино/гитары/… (струнных) звук извлекается колебанием струны. А у струны два закреплённых конца, т.е. могут излучаться только моды с длинной волны ?/2 = L*n, где n=1,2,3…
Аналогично с голосом. Связки позволяют менять характеристики гортани, которая выступает резонатором (да простят меня любители анатомии за неточности названий). Опять же, стенки закреплены, там у колебаний узловые точки, т.е. опять же та же формула для возбуждаемых мод.
А теперь хлопнем:
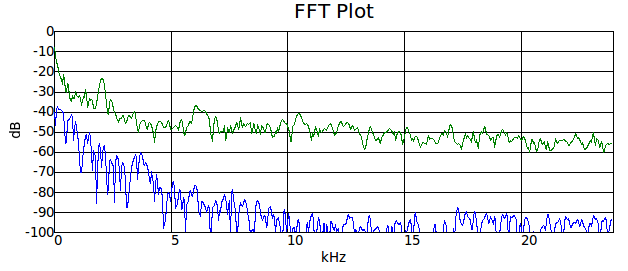
(синее — спектр «тишины», зелёное — спектр хлопка)
Ой, тут прямо все частоты видны (обратите внимание на шкалу частот и уровень сигнала в сравнении с графиками выше!). Логично, ведь хлопок — это кратковременное повышение давления (очень резкое), т.е. почти ?-функция, а её спектр содержит все частоты.
Это кстати можно использовать. Кто помнит из 90-ых такие брелоки для поиска ключей, которые на свист начинали звуки издавать? Удобная штука была. Так вот они на хлопок тоже реагировали, т.к. в звуке хлопка есть в том числе и частота, соответствующая свисту.
Спектр алфавита
А теперь давайте послушаем себя. Произносите разные буквы алфавита и смотрите на спектр (лучше без ресемплинга, чтоб видеть, какие частоты используются в диапазоне 0-20 кГц). Человек использует несколько видов генерации звуков: губные (начинаются с размыкания губ, что создаёт много частот сразу), гортанные, зубные, язычные и носовые. Особенно интересно выглядят шипящие и свистящие (это гортанные и зубные) — их спектр очень широк и в основном располагается в спектре > 2.5 кГц (у звука «с» даже > 5 кГц). Это объясняет, почему слова с этим звуком плохо слышны по телефону (в былые времена полоса пропускания была на уровне 3 кГц или даже ниже — попробуйте добавить Low Pass фильтр и направить результат в Audio Sink с наушниками — результат будет напоминать старый добрый проводной телефон).
У кого есть дети, послушайте их — они сильно звонче, их голос содержит много высоких частот. Именно поэтому их голос по телефону всегда странный, а понять их частенько просто невозможно (искажения голоса сильно больше, чем у взрослого).
Кстати, я попробовал выдавить из себя самую высокую ноту. Ну, выше 700 Гц я не взял. Сын взял 1200 Гц! Я такой ограниченности от себя не ожидал — это же меньше 5% слышимого мной спектра. Почувствовал себя ущербным…
Поговорим с дельфинами
Ну ок, мы не можем так высоко звучать, так воспользуемся этой полосой для другого. Теперь попробуем сделать передачу голоса по ультразвуку. Поставим Low Pass фильтр (низких частот) после блока Audio Source, умножим на косинус 15 кГц (тем самым перенесём наш сигнал на 15 кГц выше) и отправим в динамик (он так себе с этим справляется). Но такой файл можно записать, используя File Sink. Проиграв такой файл, сторонний слушатель разобрать, что там сказано, не сможет. Шпионская игра на уровне 2 класса.
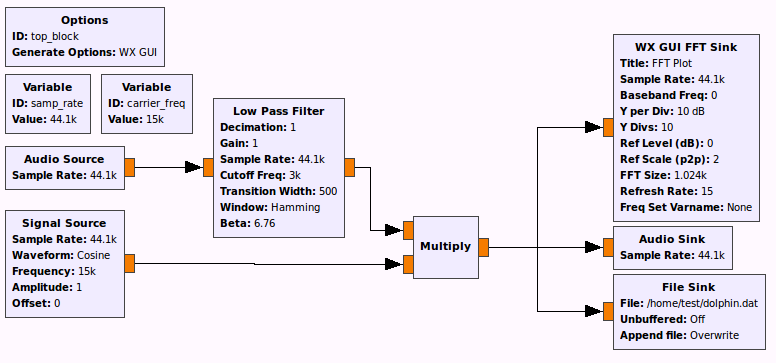
А теперь произведём обратное — восстановим закодированный сигнал. Обычный микрофон ноута плоховато воспринимает высокие частоты, а вот из файла — легко (для наших-то тестов достаточно). Голос после восстановления весьма неплохо воспринимается.
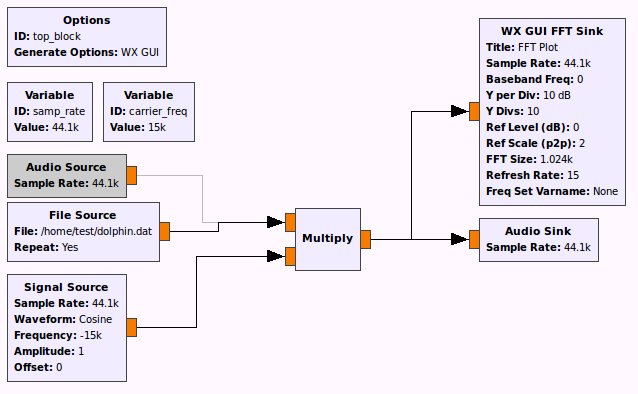
Примерно таким способом можно даже данные передавать: вот пример сетевого интерфейса на базе ультразвуковой передачи.
Данный пример показывает, что с GNU Radio и звуковой картой можно делать уже немало!
Обзор блоков GNU Radio
В GNU Radio очень много разных блоков, и разобраться в них не просто. Причём самое сложное — понять, что тут вообще есть. Ниже я приведу лишь наиболее популярные блоки, используемые «в быту».
Математические операции:
Add — сложение двух сигналов
Mulitly — перемножение двух сигналов (например, для АМ)
Add Const — прибавить (вычесть) константу (например, при демодуляции АМ убрать DC-составляющую)
Multiply Const — умножение сигнала на константу (для усиления, например)
Char/Integer/Float/Complex to Char/Integer/Float/Complex — преобразование типов данных
Источники:
Constant Source — источник, выдающий всегда одно и то же значение
Signal Source — источник, выдающий синусоидальный сигнал (для синтетического сигнала)
Audio Source/Sink — захват со звуковой карты или вывод в неё
File Source/Sink — чтение из файла (используйте Throttle для ограничения скорости чтения до нужного Sample Rate) и запись в файл
Wav File Source/Sink — чтение/запись WAV-файла
TCP/UDP Source/Sink — возможность стыковать проект с сетевым ПО посредством TCP или UDP сокетов
osmocom Source/Sink — приём данных от RTL-SDR или HackRF One или передача (для HackRF One)
Vector Source — источник последовательности чисел
Фильтры и модуляция:
Low/High/Band Pass Filter — низкочастотный/высокочастотный/полосовой фильтры
Frequency Xlating FIR Filter — совмещает сдвиг частоты и Low Pass фильтр для выделения нужной полосы частот
AM/FM/GFSK/… Mod/Demod — различные модуляторы и демодуляторы
Семплинг:
Rational Resampler — позволяет преобразовать входящую последовательность отсчётов из одного Sample Rate в другой путём децимации и интерполяции (используется для «подгона» под нужный Sample Rate)
Throttle — ограничение скорости подачи отсчётов до нужного Sample Rate (если в проекте нед ни одного блока, ограничивающего скорость обработки)
Delay — задерживает поток на нужное число отсчётов
UI:
WX GUI FFT Sink — графический вывод спектра сигнала
WX GUI Waterfall Sink — вывод спектральной мощности в режиме «водопада» (по оси X — частота, по Y — время, Z (цвет) — амплитуда). Полезно для поиска частоты излучения редко передающего источника в заданном диапазоне
WX GUI Constellation Sink — вывод фазовой диаграммы сигнала (разность фаз между колебаниями действительной и мнимой частей сигнала)
WX GUI Scope Sink — осциллограф
Разное:
Variable — переменная, позволяет использовать переменные вместо чисел в множестве блоков
Selector — мультиплексор, в сочетании с WX Slider позволит «на лету» переключать входы и выходы
Pack/Unpack K bits — преобразует из байтов 0/1 в последовательность из K бит и наоборот из байта в последовательность байт 0/1, соответствующую битам (удобно для кодирования/декодирования пакетов — байты 0/1 можно умножать на несущую, например)
Что ещё нужно знать о GNU Radio Companion (GRC)?
Все блоки в GRC, имеющие входы или выходы, требуют определения типа данных. Тип выхода одного блока должен быть таким же, как и входной тип связанного с ним блока. Выходные данные из одного блока можно передать в несколько блоков (т.е. нарисовать несколько связей). Но в один вход может входить только один поток!
Большинство блоков имеют минимальную документацию во вкладке в окне настроек, а так же в сносках к параметрам. Хотя обычно этого недостаточно. Немного устаревшая дока есть тут.
Все параметры у блоков могут быть выражениями Python. Т.е. вместо числа можно подставить формулу с участием переменных, определённых блоками Variable.
Часто хочется «покрутить» параметры проекта путём изменения значений переменных. Для этого используйте WX Slider или аналогичный компонент UI, используя его имя вместо нужной переменной. После запуска проекта в UI появится слайдер. Это удобно для перестройки частоты или параметров фильтров.
Ошибки в типе связей или в параметрах блока подсвечиваются красным. Они так же блокируют запуск проекта (в настройках блока, подсвеченного красным можно прочесть о проблеме). Есть run-time ошибки, которые проявляются уже при запуске проекта — лог внизу окна GRC подскажет, в чём проблема.
Некоторые блоки требуют целого числа в качестве параметра. Подстановка формулы может привести к несоответствию типов. Используйте Python-овскую функцию int() для преобразования к целому.
Для отключения блока используйте Disable/Enable. Это позволит не удалять блок, а просто исключить его из проекта на время с сохранением всех введённых параметров.
Все схемы в GRC преобразуются в скрипты на Python, что позволяет их потом изменять, а так же автоматизировать какие-то процессы минуя GRC.
Часто удобно сохранить звук/радио сигнал в файл для дальнейшего анализа. Для этого используйте блок File sink. Обратите внимание, что при чтении файла нужно помнить использованный формат данных при записи (тип числа), а так же Sample Rate. Рекомендую включать эти значения в имя файла помимо описания самого записываемого сигнала — это позволит не забыть, как его считать потом.
При проигрывании из файла обязательно используйте блок Throttle для ограничения скорости считывания. Это не требуется, если в схеме есть другой блок, который физически ограничивает скорость чтения данных. Например, блок Audio Sink итак ограничивает скорость подаваемых ему данных указанным в его настройках Sample Rate.
Для поиска нужного блока используйте значок лупы в панели инструментов. Двойной клик по названию в списке доступных блоком добавит блок в проект. Вместо этого можно перетащить его из списка в нужное место в проекте.
Старайтесь удобно располагать блоки в проекте. Это ни на что не влияет, кроме читабельности.
Надеюсь, данная статья побудит кого-то на эксперименты со звуком.
Комментарии (9)

aivs
03.05.2016 00:53Я имел ввиду еще более простой вариант, распознавать отдельные буквы.

KonstantinSamsonov
03.05.2016 01:40+2Вообще буквы это распознанные мозгом фонемы как таковых букв в устной речи нет, тут вопрос упирается в частотную девиацию основного тона от носителя к носителю, выразительности артикуляции и наличия частотного словаря фонем + правила фонетики для подстановки букв при уверенном распознавании фонемы ну и словарь желательно чтобы проверять орфографию тоже автоматически. И это желательно сделать для многих тонов и темпов речи
Ну это всё актуально если мы в студии и не нужно фильтровать шум, второго собеседника, фоновую музыку, чьё-то пение и проезжающий рядом автомобиль.
Та же самая Siri, как она не проста в использовании тем не менее потребовалось более 40 лет и работы нескольких институтов + вложения в несколько миллиардов долларов чтобы получить коммерчески значимый результат.
Попробуйте записать любое слово несколько раз, а за тем найдите зоны корреляции в двоичном файле (плавающим окном) или в Фурье образе будет много разочарований… ах да, то что записано ещё раз можно в записи найти и посмотреть подстрочную расшифровку, но нам нужна как раз машинная расшифровка, а не специально обученные люди )))

K_One
03.05.2016 01:32IoT и GNU radio, хороший подход. Однако шифровать будут, ко времени привязываться, и много чего еще, но после такого IoT будет больше похож на вымершие LXBOX, чем на компактные устройства.

PoltoS
03.05.2016 01:40Именно про шифрование и пойдёт речь, когда будет показано подручными средствами, что большинство устройств от китайской розетки до почти родного nooLite не имеют шифрования, а значит управляющие команды для них очень легко можно подделывать в эфире.
Сейчас ни один протокол, претендующий на звание технологии переднего фронта IoT, не может обойтись без шифрования. Например, в Z-Wave оно уже давно есть (лет 9 точно), но производители откровенно ленятся его внедрять. Z-Wave Альянс это понял, и новая версия (называется S2) будет иметь peer-to-peer шифрование на уровне протокола. Т.е. сразу, по умолчанию, да ещё и без общего сетевого ключа, как было в прошлой версии.
Аналогично и к контроллерам начинают предъявлять более строгие требования по безопасности. Взломать контроллер всегда интересней — одно место управления сразу всем.PoltoS
03.05.2016 10:21+1del
опять не в ту ветку… глючное приложение TM при ответе на последний коммент отвечает на предпоследний…
aivs
Так понимаю распознавать буквы это не большая проблема? Если в качестве выходного блока можно запускать программы, то можно сделать простую систему голосового управления.
PoltoS
Ну распознавание речи делается явно не по спектру, а скорее свёрткой с известными паттернами и выявлением наиболее подходящего.
Здесь была идея предложить лично оценить спектр излучаемых человеком звуков, а так же изучить пакет GNU Radio на базе этих данных.
Хотя можно дописать блок распознавания одного из слов из списка. Думаю, в базовом варианте даже корреляция справится с выделением наиболее похожего.