
Что обычно делает python-программист, когда его отправляют воевать с ошибкой?
Сначала он лезет в sentry. Здесь можно найти время, сервер, подробности сообщения об ошибке, traceback и, может быть, какой-нибудь полезный контекст. Затем, если этих данных недостаточно, программист идет c бутылкой к админам. Те залезают на сервер, ищут это сообщение в файловых логах, и, может быть, находят его и некоторые предшествующие ошибке записи, которые в редких случаях могут помочь в расследовании.
А что делать, если в логах только loglevel=ERROR, а ошибка настолько крута, что ее локализация требует сопоставления логики поведения нескольких различных демонов, которые запущены на десятке серверов?
Решение — централизованное хранилище логов. В самом простом случае — syslog (за 5 лет, что был развернут в rutube, не использовался ни разу), для более сложных целей — ELK. Скажу честно, "ластик" — крут, и позволяет быстро крутить разнообразную аналитику, но вы интерфейс Kibana видели? Этой штуке так же далеко до консольных less/grep, как винде до линукса. Поэтому мы решили сделать свой велосипед, без Java и Node.js, зато с sphinxsearch и Python.
В общем-то, основные претензии к ELK заключаются в том, что Kibana — это совсем не инструмент навигации по логам. Не то, чтобы совсем пользоваться невозможно, но как замена grep/less — не годится.

Так что чуть ли не основным требованием к "велосипеду" была минималистичная верстка, избавиться от вечно зависающего построенного на "вражеских" технологиях Logstash, ну и ElasticSearch тоже заодно выкинуть.
Часть первая: отправка
Чтобы логи хранить, их надо куда-то отправлять. В тот же ElasticSearch можно писать напрямую, но гораздо веселее через RabbitMQ — на то он и брокер сообщений. Взяв за основу python-logstash, мы "докрутили" к нему корректную обработку недоступности RabbitMQ и несколько "загрузчиков". В пакете logcollect поддерживается автонастройка для Celery, Django и "родного" python logging. При этом к корневому логгеру добавляется обработчик, отправляющий все логи в формате JSON в RabbitMQ.
Да, чуть не забыл. Пример:
from logcollect.boot import default_config
default_config(
# RabbitMQ URI
'amqp://guest:guest@127.0.0.1/',
# идентификаторы для подсистем или еще чего-нибудь похожего
# по-сути добавляется в каждое сообщение отдельным ключем
activity_identity={'subsystem': 'backend'},
# префикс для RabbitMQ routing key.
routing_key='site')Часть вторая, маленькая: маршрутизация
Для предварительной фильтрации логов мы воспользовались функционалом RabbitMQ: используется topic-exchange, который отправляет в очередь на обработку только сообщения, соответствующие определенному шаблону. К примеру, sql-запросы Django проекта "site" будут обрабатываться, только если для соответствующей очереди задан routing key site.django.db.backends, а "поймать" все логи от django можно с помощью routing key site.django.#. Это позволяет балансировать между объемом хранимых данных и полнотой охвата логируемых сообщений.
Часть третья, асинхронная: сохранение
Первоначально, буква "A" в ALCO означала "асинхронный", однако быстро выяснилось, что использование asyncio-based решений тут ни к чему: всё упиралось в скорость фильтрации сообщений питоновским процессом. Оно и понятно: librabbitmq позволяет получать из "кролика" сразу пачку сообщений, каждое из которых надо разобрать, вырезать ненужные поля, переименовать недопустимые, для некоторых полей сохранить новые значения в Redis, сгенерировать на основе метки времени id для sphinxsearch, а еще сформировать INSERT-запрос.
В последствии, правда, оказалось, что "асинхронный" — это всё-таки про нас: для того, чтобы эффективнее расходовать процессорное время, round-trip INSERT-запроса между питоном и sphinxsearch выполняется в отдельном потоке, с синхронизацией через родные очереди питона.
Новые колонки сохраняются в БД, после чего становится доступным ряд настроек их отображения и хранения:
- отображение а-ля list-filter, например для фильтрации по levelname,
- индексирование как отдельного поля, к примеру, для celery task_id,
- режим контекста сообщения — очень помогает для отображения traceback,
- исключение из индексации и из списка колонок.
Часть четвертая, фронтендовая
С технической точки зрения рассказывать особо нечего (bootstrap + backbone.js + django + rest_framework), поэтому приведу лишь пару скриншотов.

Логи можно фильтровать по датам, значениям определенных колонок из списка, по произвольным значениям, а также выполнять полнотекстовый поиск по самим сообщениям. Кроме того, опционально можно посмотреть записи, соседствующие с найденными полнотекстовым поиском (привет, less).
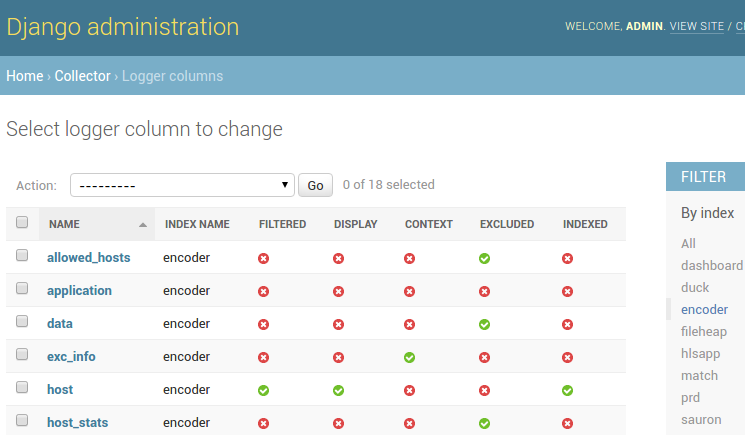
Отображение колонок настраивается через админку, как и настройки индексов routing_key или период хранения данных.
Заметки о производительности
К сожалению, похвастаться молниеносной загрузкой страницы мы пока не можем: sphinxsearch так устроен, что любая фильтрация по атрибутам требует fullscan всего индекса, поэтому быстро работает только полнотекстовый поиск (считай, grep). Зато он — мегабыстр! Но мы не сдаемся, и упорно пытаемся производительность фильтрации.
К примеру, первичные ключи специально генерируются на основе метки времени, т.к. sphinxsearch умеет "быстро" выгребать данные по диапазону id. Начиная с некоторого объема индекса, выигрыш по производительности дает индексация отдельных колонок: несмотря на низкую мощность (cardinality), за счет того, что используется полнотекстовый индекс, обработка запроса занимает условно 20 секунд против минуты в случае фильтрации по json-атрибутам. Также в запросе указывается распределенный индекс, соответствующий диапазону запрашиваемых дат: таким образом, данные за весь месяц не читаются, если требуются логи за "вчера".
Скорость вставки в RT-индекс со времен вот этой статьи в блоге sphinxsearch значительно возросла: на персоналке удалось достичь (как бы не соврать...) 8000 row/s на инсертах по 1000 записей, при одновременном получении записей из очереди RabbitMQ и обработке в python-процессах. А еще alco умеет вставлять записи в каждый индекс в несколько потоков, хотя до полноценного шардирования sphinxsearch по машинам мы не доросли: интересных логов в продакшне не настолько много, чтобы это стало критичным.
Маленький фокус с конфигом
Внимательный читатель заметит (с), что конфигурация sphinxsearch у нас явно не статическая ;-) В общем-то это не секрет, и в документации написано, что sphinx.conf вполне может быть исполняемым файлом, если в его начале стоит "shebang". Так что наш скрипт конфига написан на питоне, он ходит по http к админке alco и печатает в stdout конфиг сфинкса, сгенерированный с помощью шаблонизатора django, попутно создавая отсутствующие директории и удаляя уже не используемые индексы.
Если кого-нибудь заинтересовал наш "велосипед", подробнее про alco можно почитать на github. Чтобы попробовать, достаточно sphinxsearch, RabbitMQ, MySQL и Redis. Ну и, конечно, будем рады баг-репортам и пулл-реквестам.
Комментарии (18)

nolar
06.05.2016 02:14+1А почему не Graylog (который тоже на ElasticSearch, но без Kibana, и специально для логов)? Чем не подошёл?

tumbler
06.05.2016 09:52-1ELK использовался в продакшне, скажем так, «у соседей напротив» для аналитики качества сервиса, так что имелась возможность поспрашивать что да как. А Graylog попросту ненагуглили. Так что скорее всего и на него посмотрим, хотя конечно жалко свой велосипед выбрасывать :)

Sheh
06.05.2016 14:20Не выбрасывайте. У Graylog точно так же неудобно читать логи. Интерфейс там аналогичный, больше подходит для аналитики
А может и ребята из Graylog подумают над улучшением своего интерфейса, посмотрев на вашу фичу. Штука крутая.

Deepwalker
06.05.2016 14:59Там у Sentry апдейт вышел кстати. Как раз про логи.
tumbler
06.05.2016 17:20Хм, что-то я не нашел про это у них на сайте. Можете линк скинуть?
Deepwalker
06.05.2016 17:25Не вот прям про логи, а более общая фича.
http://blog.getsentry.com/2016/05/04/breadcrumbs.html

kt97679
06.05.2016 18:10+1Напишите, пожалуйста, какие нагрузочные тесты вы проводили на вашей системе. Можете ли вы оценить какие ресурсы потребуются, чтобы обрабатывать 400к логов в секунду с трафиком порядка 130 мб/с и хранением данных за последние 7 дней?
tumbler
06.05.2016 18:43Нагрузочные тесты проводились на персоналке, причем 90% CPU было задействовано python-процессами разбора логов.
Но давайте посчитаем :)
RabbitMQ: В статье авторов RabbitMQ описывается достижение 60К messages per second с одного двухпроцессорного сервера, так что прикидочно понадобится кластер из 8 серверов RabbitMQ.
SphinxSearch: авторы sphinxsearch пару лет назад добились сферической скорости вставки в вакууме порядка 5K строк в секунду, но это в пересчете на ядро, да и на персоналке у нас вышло быстрее. Взяв в расчет 10К инсертов в секунду, получим 40 ядер sphinxsearch, каждое ядро льет данные в свой индекс. Это 5 слабеньких таких серверов поиска.
Python(ALCO): имея примерную производительность процессов питона в 2К сообщений в секунду с одного ядра, получим 200 ядер, или 25 машин на только на предобработку данных.
Хранение: среднюю длину сообщения у нас не подскажу, а вот сфинкс на диске хранит примерно 350 байт на строку лога (в среднем). За 7 дней набегает 85ТБ индексированных данных. 5 серверов сфинкса плавно превращаются в дисковые полки, но это не самое неприятное.
Поиск: в синтетических 60млн записей full-scan фильтрация выполнялась примерно за 40 секунд (прочитать с диска все данные, отфильтровать, отобразить), это примерно 500МБайт/c в пересчете на 350-байтовые записи. В наихудшем случае с 85ТБ "поднять" всё с диска — это какие-то дикие цифры, примерно как дважды сходить пообедать, пока 40 индексов будут считываться со скоростью 500МБайт/c — в результате получим только первую страницу результатов. За второй можно приходить на следующий день :)
Не уверен, что существуют настолько большие инсталляции sphinxsearch, но тем не менее: полнотекстовый поиск теоретически должен успевать отрабатывать за обозримое время.
Кстати, можете поделиться, что Вам хотелось бы искать в этой огромной куче логов? Быть может, разбив на много-много независимых установок, Вы получите приемлемый по производительности инструмент?
kt97679
06.05.2016 18:51Большое спасибо за развернутый ответ.
Я давно и безуспешно пытаюсь построить инфрастркутуру для логирования на базе ELK, вот здесь детали:
https://habrahabr.ru/post/282866/#comment_8881108
https://habrahabr.ru/company/uteam/blog/278729/#comment_8799489
https://habrahabr.ru/post/275815/#comment_8751947
Задача была поставлена именно искать по всем логам всех сервисов, чтобы в случае проблем можно было по session_id проследить как шел запрос и где именно возникли неполадки.
trong
06.05.2016 20:57На мой взгляд для ситуации «по session_id проследить как шел запрос и где именно возникли неполадки» это скорее про tracing system, типа того же Zipkin:
Sheh
10.05.2016 09:25чтобы в случае проблем можно было по session_id проследить как шел запрос и где именно возникли неполадки.
Эту информацию должно генерировать само приложение. Восстанавливать дерево вызовов по логам — жопа. Это неправильно.
Вам нужно искать решение из области Application performance management
И пусть вас не смущает слово performance. Там есть не только это.
Например, для Java приложений море коммерческих и свободных инструментов, которые позволяют посмотреть дерево вызовов для бизнес-транзакций. Легко понять, в каком месте бизнес-операция заняла больше всего времени.
lega
08.05.2016 07:05первичные ключи специально генерируются на основе метки времени, т.к. sphinxsearch умеет «быстро» выгребать данные по диапазону id. Начиная с некоторого объема индекса, выигрыш по производительности дает индексация отдельных колонок
Расскажите как вы сделали первичный индекс и индексацию отдельных колонок, в сфинксе такого раньше не было.tumbler
10.05.2016 09:12index project_20160509 { type = rt path = /data/sphinx/project/20160509/ rt_field = logline rt_field = js rt_field = logger rt_attr_string = logline rt_attr_json = js }
В варианте "из коробки" индекс состоит из двух полей — logline (само сообщение от логгера) и js — это словарь с данными от python logging, переданными AMQPHandler. При этом запрос
SELECT * FROM project WHERE js.logger = 'django.db.backends'
выполняется путем full-scan по атрибуту js.
В случае, когда поле logger вынесено отдельно в конфиг сфинкса, как в примере выше, запрос трансформируется вот в такой:
SELECT * FROM project WHERE MATCH('@logger "django.db.backends"')
При этом сначала по полнотекстовому индексу выбираются документы, соответствующие выбранному логгеру, а потом уже осуществляется их дополнительная фильтрация по остальным атрибутам json, указанным в запросе (если таковые имеются).
На селективной выборке и некотором довольно большом объеме это дает выигрыш относительно первого варианта, хотя приходится в charset_table добавлять символы, обычно считающиеся разделителями слов.
xonix
Тема весьма интересная. Хотя я и не доконца понял вашу мотивацию, т.е. вообще постановку вопроса. Если не понравился интерфейс Kibana — не проще ли было просто доработать её или создать свой веб-интерфейс? Подозреваю, что реальным мотиватором был избыток молодецкого задора :-) Также зря отказались от Elasticsearch, очень уж хороший продукт.
Также, по-моему, у вас в описании неточность
Logstash написан на Ruby, который запускается на JRuby, т.е. на JVM. А вот Kibana, да — на node.js.
Ну а вообще, респект, конечно!
gtbear
что то я уже запутался в версиях кибаны, 2я была на руби с сервером, 3ю они сделали без сервера и полностью на JS, а 4я вроде как с бэкендом на яве. когда там node.js появился? а то я до сих пор с 3ей уходить не хочу.
tumbler
Спасибо за уточнение, исправлю :)
Конечно, доля задора определенно была, и не маленькая. Однако всё-таки мы проводили эксперименты с ELK в связке с RabbitMQ. За двое суток синтетических тестов Logstash воткнул дважды намертво, похоже что вместе с ElasticSearch. Кроме того, скорость вставки на одной машине была подозрительно низкой, так что для планируемой нагрузки потребовался бы небольшой кластер. Кластер для логов, представляете! А еще дисковое пространство уменьшалось ну очень быстро…
Итого, вкупе с отсутствием знаний технологий, используемых внутри всех частей стека, и опыта эксплуатации, мы решили все-таки попробовать сделать своё.
Небольшое уточнение: это было примерно год назад, плюс дальше чем quickstart по настройке всего в сборе мы не копали. Так что вполне возможно, что у кого-то сбор логов работает быстро, эффективно и без глюков.
Thermal_Burn
Кластер для логов кстати вещь далеко зряшная. У самого развёрнут кластер с Грейлогом, так как в случае аварии потерять логи недопустимо. Производительность кстати при работе в кластере возрастает очень заметно, 500 гиговая база порхает как бабочка.
jeiz
Elasticsearch может и хороший продукт, но очень уж требовательный к памяти. А проблемы с logstash сильно огорчают