
При программировании на JavaScript часто возникает проблема выбора оптимального представления данных в программе: массивы, хеши, массивы хешей, хеши массивов и т.д. Одни и те же данные могут быть загружены в различные комбинации структур, но трудность выбора обычно заключается в том, как найти компромисс между простотой кода для доступа к этим данным, скоростью работы и количеством требуемой памяти.

В статье рассказано о моей попытке поиска универсального решения.
Пусть нам, например, необходимо отобразить некоторые данные из двух связанных таблиц:

Стандартный подход обычно состоит из следующих шагов:
Недостатки стандартного подхода мне видятся в следующем:
Нестандартный подход — получить таблицы по отдельности и связать их на клиенте. Иногда это можно сделать легко. Например, в приведенной выше структуре можно загрузить таблицу «departments» в хеш, и осуществлять доступ по «id». Но чаще этого сделать нельзя, и приходится пользоваться различными функциями поиска типа Array.find или Array.indexOf.
Работая над своим очередным проектом, и в очередной раз ломая голову над тем, как мне лучше организовать данные, чтобы избежать недостатков обоих подходов, я решил, что настало время разрубить этот узел раз и навсегда.
Подход, при котором сервер выдает нам нормализованные таблицы, а мы потом их связываем в JavaScript-коде, показался мне более привлекательным. Не хватало только инструмента, чтобы их легко связывать. Я отложил все дела и сел его писать.
Требования получились следующие:
Так появились Strelki.js, и пока единственный в нем класс — IndexedArray.
Итак, создадим новый IndexedArray:
Добавим в него данные:
Посмотрим, что внутри:
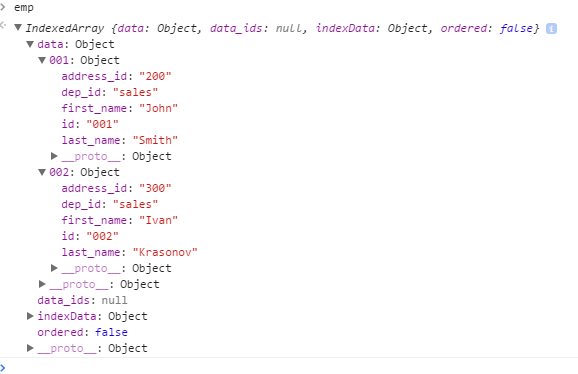
Под капотом IndexedArray представляет из себя хеш (this.data), куда сохраняются ссылки на объекты. В качестве ключа хеша используется поле «id» сохраняемого элемента, которое должно быть уникально. Так как многие современные серверные фреймворки также используют поле «id» подобным образом, то это ограничение не должно стать проблемой.
Кроме того, в IndexedArray имеется хеш this.indexData. Ключи этого хеша содержат название индексируемого поля, а значения — хеши с ids соответствующих элементов основного хеша. Пока индексов у нас нет, поэтому this.indexData пуст.
Добавим индекс:
Посмотрим this.indexData:
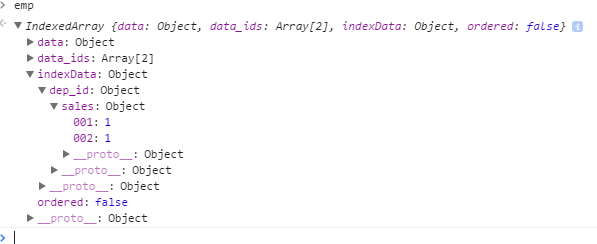
this.indexData теперь содержит ключ «dep_id», который содержит данные индекса в виде вложенных хешей.
Поищем что-нибудь по индексу:
В отличие от функций типа Array.find, индексный поиск не использует перебор данных, а только хеши, что позволяет добиться высокой скорости. Замеры, правда, я пока не делал, но должно работать быстро.
Добавим еще данных:
Найдем элементы по индексу, и сформируем из них новый IndexedArray:
Создадим и заполним еще один IndexedArray:
Для описания связи данного IndexedArray с любым другим служит объект следующего вида:
Присоединим adr к emp JOIN-ом:
Аналогичный оператор на SQL выглядел бы так:
Результат будет выглядеть так:
Как видим, связывание массивов превратилось из функций с циклами и переборами в простую декларацию связей.
IndexedArray не хранит копии объектов, а только лишь указатели на них (отсюда и название Strelki). Поэтому, если объект был помещен в IndexedArray методом put(), а затем изменен, информация в индексах может стать некорректной. Чтобы избежать этой ситуации необходимо удалить объект из IndexedArray методом del() перед изменением.
Связывание может осуществляться только по индексированному полю, либо по полю «id».
Некоторые методы объекта IndexedArray (например length()) требуют построения массива ключей «id». При этом массив ключей сохраняется в объекте для возможного повторного использования. При каждом изменении массива (методы put(), del(), и т.п.) массив ключей обнуляется. Поэтому чередование методов, которые создают и затем обнуляют массив ключей, может привести проблемам производительности на больших наборах данных.
StrelkiJS создан для облегчения написания основного проекта KidsTrack, о котором я писал на хабре ранее. Поэтому все решения о новом функционале пока диктуются потребностями родительского проекта. В ближайших планах — сделать более удобный доступ к колонкам в результатах JOIN-а,
Github: github.com/amaksr/Strelki.js
Песочница: www.izhforum.info/strelkijs
В статье рассказано о моей попытке поиска универсального решения.
Пусть нам, например, необходимо отобразить некоторые данные из двух связанных таблиц:
Стандартный подход обычно состоит из следующих шагов:
- На сервере написать SQL-запрос с JOIN-ом
- На сервере добавить для него функцию, возвращающую массив объектов, и сделать ее доступной через routes
- На клиенте добавить AJAX-вызов к серверу, и отрисовку полученного результата в таблицу
Недостатки стандартного подхода мне видятся в следующем:
- SQL-запрос и функция-обертка должны учитывать возможные коллизии имён колонок, т. е. нельзя просто сделать "SELECT *".
- Ответ сервера будет содержать большое количество дублирующихся записей из связанных таблиц. В нашем примере запись с ключем «sales» из таблицы departments будет передана два раза.
- При связи большого количества таблиц мы или получим длинные ключи, что приведет к увеличению бесполезного расхода памяти и трафика по передаче этих ключей, или имена колонок в SQL-запросе необходимо перечислять вручную, что приведет к дополнительным издержкам при внесении изменений в структуру БД.
- Количество функций API для получения данных из связанных таблиц может значительно превысить количество таблиц, что ведет к раздуванию кода, и, как следствие, издержкам.
Нестандартный подход — получить таблицы по отдельности и связать их на клиенте. Иногда это можно сделать легко. Например, в приведенной выше структуре можно загрузить таблицу «departments» в хеш, и осуществлять доступ по «id». Но чаще этого сделать нельзя, и приходится пользоваться различными функциями поиска типа Array.find или Array.indexOf.
Работая над своим очередным проектом, и в очередной раз ломая голову над тем, как мне лучше организовать данные, чтобы избежать недостатков обоих подходов, я решил, что настало время разрубить этот узел раз и навсегда.
Подход, при котором сервер выдает нам нормализованные таблицы, а мы потом их связываем в JavaScript-коде, показался мне более привлекательным. Не хватало только инструмента, чтобы их легко связывать. Я отложил все дела и сел его писать.
Требования получились следующие:
- Инструмент должен позволять мне создавать произвольные индексы на массив, и поддерживать их в актуальном состоянии.
- Инструмент должен уметь искать в массиве по индексам, по возможности без медленных операций перебора элементов.
- Интрумент должен уметь соединять массивы по индексированным полям в соответствии с неким объектом-декларацией, что-то типа оператора JOIN в SQL, но без парсинга запросов и всей мощи, предлагаемой SQL.
Так появились Strelki.js, и пока единственный в нем класс — IndexedArray.
Итак, создадим новый IndexedArray:
var emp = new StrelkiJS.IndexedArray();
Добавим в него данные:
emp.put({
id: "001",
first_name: "John",
last_name: "Smith",
dep_id: "sales",
address_id: "200"
});
emp.put({
id: "002",
first_name: "Ivan",
last_name: "Krasonov",
dep_id: "sales",
address_id: "300"
});
Посмотрим, что внутри:
Под капотом IndexedArray представляет из себя хеш (this.data), куда сохраняются ссылки на объекты. В качестве ключа хеша используется поле «id» сохраняемого элемента, которое должно быть уникально. Так как многие современные серверные фреймворки также используют поле «id» подобным образом, то это ограничение не должно стать проблемой.
Кроме того, в IndexedArray имеется хеш this.indexData. Ключи этого хеша содержат название индексируемого поля, а значения — хеши с ids соответствующих элементов основного хеша. Пока индексов у нас нет, поэтому this.indexData пуст.
Добавим индекс:
emp.createIndex("dep_id");
Посмотрим this.indexData:
this.indexData теперь содержит ключ «dep_id», который содержит данные индекса в виде вложенных хешей.
Поищем что-нибудь по индексу:
> emp.findIdsByIndex("dep_id","sales")
< ["001", "002"]
В отличие от функций типа Array.find, индексный поиск не использует перебор данных, а только хеши, что позволяет добиться высокой скорости. Замеры, правда, я пока не делал, но должно работать быстро.
Добавим еще данных:
emp.put({
id: "003",
first_name: "George",
last_name: "Clooney",
dep_id: "hr",
address_id: "400"
});
emp.put({
id: "004",
first_name: "Dev",
last_name: "Patel",
dep_id: "board",
address_id: "500"
});
Найдем элементы по индексу, и сформируем из них новый IndexedArray:
var sales_emp = emp.where("dep_id","sales");
Создадим и заполним еще один IndexedArray:
var adr = new StrelkiJS.IndexedArray();
adr.put({ id: "200", address: "New Orleans, Bourbon street, 100"});
adr.put({ id: "300", address: "Moscow, Rojdestvensko-Krasnopresnenskaya Naberejnaya"});
adr.put({ id: "500", address: "Bollywood, India"});
Связывание массивов
Для описания связи данного IndexedArray с любым другим служит объект следующего вида:
{
from_col: "address_id", // поле в данном IndexedArray
to_table: adr, // ссылка на связываемую таблицу
to_col: "id", // "id", или другое индексированное поле в связываемой таблице
type: "outer", // "outer" для LEFT OUTER JOIN, или null для INNER JOIN
join: // null или ссылка на массив точно таких же объектов описания связи, для построения вложенных JOIN-ов
}
Присоединим adr к emp JOIN-ом:
var res = emp.query([
{
from_col: "address_id", // name of the column in "emp" table
to_table: adr, // reference to another table
to_col: "id", // "id", or other indexed field in "adr" table
type: "outer", // "outer" for LEFT OUTER JOIN, or null for INNER JOIN
//join: [ // optional recursive nested joins of the same structure
// {
// from_col: ...,
// to_table: ...,
// to_col: ...,
// ...
// },
// ...
//],
}
])
Аналогичный оператор на SQL выглядел бы так:
SELECT ...
FROM emp
LEFT OUTER JOIN adr ON emp.address_id = adr.id
Результат будет выглядеть так:
[
[
{"id":"001","first_name":"John","last_name":"Smith","dep_id":"sales","address_id":"200"},
{"id":"200","address":"New Orleans, Bourbon street, 100"}
],
[
{"id":"002","first_name":"Ivan","last_name":"Krasonov","dep_id":"sales","address_id":"300"},
{"id":"300","address":"Moscow, Rojdestvensko-Krasnopresnenskaya Naberejnaya"}
],
[
{"id":"003","first_name":"George","last_name":"Clooney","dep_id":"hr","address_id":"400"},
null
],
[
{"id":"004","first_name":"Dev","last_name":"Patel","dep_id":"board","address_id":"500"},
{"id":"500","address":"Bollywood, India"}
]
]
Более сложный пример связывания 3-х таблиц
var dep = new StrelkiJS.IndexedArray();
dep.createIndex("address");
dep.put({id:"sales", name: "Sales", address_id: "100"});
dep.put({id:"it", name: "IT", address_id: "100"});
dep.put({id:"hr", name: "Human resource", address_id: "100"});
dep.put({id:"ops", name: "Operations", address_id: "100"});
dep.put({id:"warehouse", name: "Warehouse", address_id: "500"});
var emp = new StrelkiJS.IndexedArray();
emp.createIndex("dep_id");
emp.put({id:"001", first_name: "john", last_name: "smith", dep_id: "sales", address_id: "200"});
emp.put({id:"002", first_name: "Tiger", last_name: "Woods", dep_id: "sales", address_id: "300"});
emp.put({id:"003", first_name: "George", last_name: "Bush", dep_id: "sales", address_id: "400"});
emp.put({id:"004", first_name: "Vlad", last_name: "Putin", dep_id: "ops", address_id: "400"});
emp.put({id:"005", first_name: "Donald", last_name: "Trump", dep_id: "ops", address_id: "600"});
var userRoles = new StrelkiJS.IndexedArray();
userRoles.createIndex("emp_id");
userRoles.put({id:"601", emp_id: "001", role_id: "worker"});
userRoles.put({id:"602", emp_id: "001", role_id: "picker"});
userRoles.put({id:"603", emp_id: "001", role_id: "cashier"});
userRoles.put({id:"604", emp_id: "002", role_id: "cashier"});
var joinInfo = [
{
from_col: "id",
to_table: emp,
to_col: "dep_id",
type: "outer",
join: [{
from_col: "id",
to_table: userRoles,
to_col: "emp_id",
type: "outer",
}],
},
// {
// from_col: "id",
// to_table: assets,
// to_col: "dep_id",
// }
];
//var js1 = IndexedArray.IndexedArray.doLookups(dep.get("sales"),joinInfo);
var js = dep.where(null,null,function(el) { return el.id === "sales"}).query(joinInfo);
// result
[
[
{"id":"sales","name":"Sales","address_id":"100"},
{"id":"001","first_name":"john","last_name":"smith","dep_id":"sales","address_id":"200"},
{"id":"601","emp_id":"001","role_id":"worker"}
],
[
{"id":"sales","name":"Sales","address_id":"100"},
{"id":"001","first_name":"john","last_name":"smith","dep_id":"sales","address_id":"200"},
{"id":"602","emp_id":"001","role_id":"picker"}
],
[
{"id":"sales","name":"Sales","address_id":"100"},
{"id":"001","first_name":"john","last_name":"smith","dep_id":"sales","address_id":"200"},
{"id":"603","emp_id":"001","role_id":"cashier"}
],
[
{"id":"sales","name":"Sales","address_id":"100"},
{"id":"002","first_name":"Tiger","last_name":"Woods","dep_id":"sales","address_id":"300"},
{"id":"604","emp_id":"002","role_id":"cashier"}
],
[
{"id":"sales","name":"Sales","address_id":"100"},
{"id":"003","first_name":"George","last_name":"Bush","dep_id":"sales","address_id":"400"}
,null
]
]
Как видим, связывание массивов превратилось из функций с циклами и переборами в простую декларацию связей.
Ограничения
IndexedArray не хранит копии объектов, а только лишь указатели на них (отсюда и название Strelki). Поэтому, если объект был помещен в IndexedArray методом put(), а затем изменен, информация в индексах может стать некорректной. Чтобы избежать этой ситуации необходимо удалить объект из IndexedArray методом del() перед изменением.
Связывание может осуществляться только по индексированному полю, либо по полю «id».
Некоторые методы объекта IndexedArray (например length()) требуют построения массива ключей «id». При этом массив ключей сохраняется в объекте для возможного повторного использования. При каждом изменении массива (методы put(), del(), и т.п.) массив ключей обнуляется. Поэтому чередование методов, которые создают и затем обнуляют массив ключей, может привести проблемам производительности на больших наборах данных.
Планы
StrelkiJS создан для облегчения написания основного проекта KidsTrack, о котором я писал на хабре ранее. Поэтому все решения о новом функционале пока диктуются потребностями родительского проекта. В ближайших планах — сделать более удобный доступ к колонкам в результатах JOIN-а,
Где скачать
Github: github.com/amaksr/Strelki.js
Песочница: www.izhforum.info/strelkijs
Поделиться с друзьями
Комментарии (9)


koceg
20.05.2016 13:51IndexedArray
Всё-таки неправильно называть эту структуру массивом. IndexedCollection было бы лучше, на мой взгляд.
Для data я бы использовал Map, а для индексов — Set. Эти структуры как раз идеально подходят под эти задачи. Ну или хотя бы стоит создавать их через Object.create(null), а не {} чтобы не тянуть ненужный прототип.amaksr
20.05.2016 16:56Всё-таки неправильно называть эту структуру массивом. IndexedCollection было бы лучше, на мой взгляд.
Можно и так, но тут корень проблемы зародился в самом JavaScript-е, который использует одинаковый синтаксис доступа [] и для массивов, и для хешей.
Для data я бы использовал Map, а для индексов — Set. Эти структуры как раз идеально подходят под эти задачи.
Я не стал их использовать, так как они пока в статусе экспериментальных, и не поддерживаются некоторыми браузерами. В будущем можно будет поменять реализацию, так что на методах это никак не отразится.
Ну или хотя бы стоит создавать их через Object.create(null), а не {} чтобы не тянуть ненужный прототип.
Спасибо, исправлю в следующем коммите.koceg
20.05.2016 17:08Можно и так, но тут корень проблемы зародился в самом JavaScript-е, который использует одинаковый синтаксис доступа [] и для массивов, и для хешей.
И всё же это не повод смешивать понятия.
Я не стал их использовать, так как они пока в статусе экспериментальных, и не поддерживаются некоторыми браузерами.
Для этого существуют полифилы (причём очень маленькие). Зато будете идти в ногу со временем и вознаграждать пользователей современных браузеров дополнительной скоростью.

andrydl
20.05.2016 16:25Видно что человеку нечем заняться и у него масса свободного времени. Вместо того чтоб написать нормальный SQL запрос или хранимую процедуру, написать JS класс который на клиенте занимается тем, чем должен заниматься сервер. Запрос select * считается дурным тоном если в таблице более 2-3 -х полей, а при JOIN и подавно.
amaksr
20.05.2016 17:19Видно что человеку нечем заняться и у него масса свободного времени.
Да, пришлось отложить работу над основным проектом.
Вместо того чтоб написать нормальный SQL запрос или хранимую процедуру, написать JS класс который на клиенте занимается тем, чем должен заниматься сервер.
В статье я перечислил недостатки стандартного подхода, поэтому и решил перенести часть серверной логики на клиент. В моем приложении с 8-ю таблицами это позволило мне избавиться от нескольких API-интерфейсов на сервере, а так же от нескольких проблемных блоков кода с вложенными циклами на клиенте (вернее этот проблемный код теперь реализован классом IndexedArray). Общая сложность кода (сервер+клиент) уменьшилась, что и было целью.

boarder
20.05.2016 16:25amaksr
20.05.2016 19:13Функционал StrelkJS частично пересекается с datascripts, но есть и отличия.
Например datascripts хранит копии объектов, а Strelki — только указатели. Тут уж для каждого конкретного случая надо смотреть, нужа ли immutability (и сопутсвующие расходы памяти и быстродействия), или нет. Для чего-то лучше подойдет datascripts, а где-то можно обойтись и StrelkJS.
malinichev
Интересное! 100% поюзаю на выходных)