
Код на https://github.com/alex4321/word2vec-nlc. Написан с применением gensim. Применялась эта модель (работающая с английским языком) GoogleNews-vectors-negative300.bin.gz.
Например — исходная фраза — I have a dog, результат векторизации — (да, явно есть мусор) —
{'SheldenWilliams_@': 0.5255231261253357, "have't": 0.5583386421203613, 'personnaly': 0.5540199875831604, 'havent': 0.597449541091919, 'happening_Truver': 0.5273309946060181, 'Durcinka': 0.5368120670318604, 'wouldnt': 0.5314139723777771, 'whine_nag': 0.5264301300048828, "I'v": 0.532825231552124, 'dogs': 0.5436486601829529, 'i_realy': 0.5310240983963013, "'ve": 0.549283504486084, 'theyd': 0.5327804684638977, 'coz_i': 0.5257705450057983, 'love_veronica_Mars': 0.5656633973121643, 'LOVE_YOU_ALL': 0.5473299622535706, 'JeremyShockey_@': 0.5405183434486389, 'i_havnt': 0.5311092138290405, 've': 0.5290054678916931, 'Reputable_breeders': 0.5303832292556763, 'samantharonson_@': 0.542853593826294, 'hadnt': 0.5852461457252502, 'Er_um': 0.5257833003997803, 'couldve': 0.529604434967041, 'that.I': 0.5449035167694092, 'ive': 0.5347827672958374, "were'nt": 0.5263391733169556, 'i_havent': 0.545918345451355, "havn't": 0.6071761846542358, 'wouldve': 0.556045651435852}. Для I have a computer —
{'psn': 0.5582104325294495, '•_vaibhav_sir': 0.5425109267234802, 'theyve': 0.5318623781204224, 'love_veronica_Mars': 0.564369261264801, 'receive_MacMall_Exclusive': 0.5217918157577515, 'havnt': 0.517998456954956, 'gfx_card': 0.5196627378463745, 'macbook_pro': 0.5703814029693604, 'droid_x': 0.5607396364212036, 'dell_laptop': 0.5578193664550781, "'ve": 0.5209441184997559, 'Arrendondo_cook': 0.5448468923568726, "I'v": 0.5355654358863831, 'lenovo': 0.5266544222831726, 'reinstall_XP': 0.537743091583252, 'wifi_adapter': 0.5497201085090637, 'havent': 0.5768314003944397, 'LOVE_YOU_ALL': 0.5329291820526123, 'haha_i': 0.5369561314582825, 'computers': 0.5202767252922058, 'automaticly': 0.523144543170929, 'hadnt': 0.5282260775566101, 'ive': 0.5156651735305786, 'google_docs': 0.5261930227279663, 'google_chrome': 0.5319492816925049, 'i_havent': 0.5323601961135864, "havn't": 0.593987226486206, 'mainframes_minicomputers': 0.5255732536315918, 'Ive': 0.518458902835846, 'cect_u##_china': 0.5316625237464905}
для классификации применяется следующий алгоритм:
- перед векторизацией из набора слов (как примеров, так и пользовательского ввода) отрезаются слишком общеупотребительные
- векторизация предусмотренных примеров (в вектора example_i)
- на основании полученных в прошлом шаге координат — рассчитывается центр соответствующего классу кластера
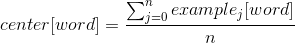
- векторизуется пользовательский ввод
- получаем записи вида [(class_name, length(input_vector — class_center)]
полученный массив сортируется по расстоянию между центром кластера и пользовательским вводом (таким образом — первым оказывается класс, ближайший к вектору пользовательского ввода)
При тестировании с такими данными:
Классы —
{
'computer': ['I have a computer', 'You have a laptop'],
'dog': ['I have a dog', 'Have you a dog?']
}Ввод — 'Do you had a dog?'
Получается следующий список:
dog 3.204362832876183 0
computer 3.577504792988848 0
Т.е. удается определить, что введенное ближе к классу dog, чем к computer.
P.S. про работу с русским языком — это я к тому, что технически — не проблема собрать модель word2vec, работающую с ним. Вообще, даже нашлось несколько — но показались мне мелковатыми (хотя, возможно — подходящими для практического применения)
Комментарии (5)

Mugik
04.07.2016 23:09Word2vec это просто нейронная сеть на skip грамах. Возьмём предложение «Моя собака не умеет играть в компьютерные игры», обучим нейронную сеть. К какому кластеру отнести к собакам или к компьютерам?
TF-IDF как уже советовали или в сторону тематического моделирования и LDA.
То что мы имеем сейчас судя по результатам точность модели нулевая, отклонение 3 десятых погрешность.

ServPonomarev
05.07.2016 10:34На тему word2Vec в качестве классификатора. Я недавно проводил масштабный эксперимент, получил удивительно хорошие результаты .
Краткая суть подхода в следующем. Для классификации документа мы определяем набор затронутых в нём тем. Темы определяются как кластеры в пространстве Word2Vec. Практически идентично, как и описано в данной заметке. Но потом делается следующий шаг. Пространство тем само превращается в пространство признаков и уже в этом пространстве происходит классификация по kMeans. Грубо говоря, мы по всей выборке вычисляем среднее удельное количество тем-кластеров на документ, что нам даёт моменты — мат ожидание и дисперсию среднего удельного количества тем на документ. Тогда, взяв исследуемый образец, мы нормируем его относительно средних моментов — и уже отнормированные вектора сравниваем. Нормировка позволяет хорошо разделять документы частых тематик и уменьшает влияние размера документа на результаты.
brickerino
Какова длина ваших текстов? Линейность для word2vec репрезентаций сохраняется до разумного предела, и скорее распространяется на семантику, типа того же (queen, king, man, woman) примера. Для длинных текстов это не будет работать, потому что это не теоретическое свойство, а просто приятность, которая вдруг обнаружилась на практике.
Также вам скорее всего нужно отфильтровывать больше стоп-слов, а не только два. Например, 'have' может иметь очень широкий контекст, и скорее всего не будет иметь разумной репрезентации, а word2vec учится как раз на контекстах слов.
alex4321
Это да, 2 стоп слова — это я к этому конкретному показометру. Конечно, в «рабочих» данных их будет больше, но они пока не подготовлены.
Что до размера — пока рассчёт на относительно малую длину. Как пример — https://github.com/watson-developer-cloud/conversation-simple/blob/master/training/car_intents.csv. К тому же — часть можно и выкинуть, как не несущие важной (для классификации) нагрузки.
p.s. как я понимаю — в случае длинных текстов копать в сторону doc2vec?
brickerino
Про doc2vec я не читал, к сожалению, и не могу сказать, что внутри, но по abstract похоже, что да. Из предыдущих техник могу посоветовать TF/IDF + классификатор, TF/IDF + SVD + классификатор, TD/IDF + LDA + классификатор. Ну и возможно (скорее всего) рекуррентные нейронки типа LSTM, GRU заработают, но тут бубен нужен.