
Мы продолжаем серию материалов, посвященных Security Operations Center, и представляем вашему вниманию второй выпуск.
Сегодняшняя статья посвящена «магическим девяткам» доступности и готовности сервисов. Мы расскажем, из чего складываются сервисные показатели облачного SOC с точки зрения «железа» и ПО, какими средствами они контролируются в Solar JSOC.
Основная цель сервиса Solar JSOC – выявление и оперативный анализ инцидентов информационной безопасности у заказчиков. Это создает пять основных условий для его доступности[1]:
Именно эти пять постулатов легли в основу используемой нами нашей системы мониторинга, которая использует аналогичное количество уровней.
Здесь я хотел бы привести схему подключения типового заказчика, использованную мной в первой статье:

Использование данной схемы разделяет процесс контроля доступности на следующие подсистемы:
Мониторинг этих показателей полностью осуществляется либо через Zabbix, либо внутренними средствами ArcSight. По каждому показателю собирается статистика и настроены триггеры на заданные пороговые значения: warning – 20 % от максимального значения, critical – 2?5 % от максимального значения. В целом все достаточно стандартно, поэтому не будем тратить время на подробное описание и двинемся дальше.
Использование этой модели предоставляет возможность оперативно получать информацию о внешних и внутренних проблемах в работе сервиса и потенциально «узких» местах с точки зрения инфраструктуры. Но указанные выше параметры не дают нам представления о полноте имеющейся у нас информации, необходимых типов событий, собираемых с инфраструктуры заказчика, и уверенности, что мы видим все, что требуется для выявления и реагирования на инцидент.
Это приводит нас ко второй задаче – необходимости контроля параметров информации, поступающей к нам от систем-источников: полноты, актуальности, корректности ее парсинга. В случае SIEM-системы критичность приобретают следующие параметры:
Очевидно, что задача контролировать поступающие данные и анализировать их на полноту и целостность – это, в первую очередь, задача самого SIEM. К сожалению, «из коробки» не всегда можно получить приемлемые результаты. Существуют определенные ограничения:
Но на фоне изложенных выше ограничений, в ArcSight существуют качественные механизмы контроля самого контента:
Но, как уже отмечалось в предыдущей статье, HP ArcSight – это, в первую очередь, framework. И мы, создавая Solar JSOC, дорабатывали свою модель контроля поступающей информации.
Во-первых, мы поменяли логику определения источника. Под каждый тип источника определили категории важных для нас событий и выделили из них наиболее частотные, наличие которых можно взять за основу.
К примеру, для Windows можно написать такой «маппинг»:
ArcSight позволяет достаточно просто делать такой маппинг через конфигурационные файлы.
Раньше событие статуса источника выглядело так (на примере Windows):
Теперь же в JSOC по каждой нашей категории событий свой статус:
Для каждого нового источника проводится длительное динамическое профилирование по объему и количеству событий, поступающих с него в ArcSight. Как правило, единицей измерения профиля является 1 час, длительность профилирования составляет 1 месяц. Основная цель профилирования – определить средние и максимальные значения количества событий от источников в разные промежутки времени (рабочий день, ночь, выходные и т.д.).
После того, как профиль построен, можно оценивать полноту поступающей информации. Например, с помощью таких правил:
Таким образом, реализованное «длинное» динамическое профилирование позволяет нам оперативно отслеживать проблемы в передаче данных и контролировать целостность поступающей к нам информации.
Во-вторых, мы доработали стандартные правила и дашборды по мониторингу источников. Добавили информацию о заказчиках и два отдельных профиля по трекингу статусов для коннекторов и подключенных устройств. Все правила в итоге заведены в единую структуру генерации инцидентов, и по каждому из них (так же, как и при мониторинге системных компонент) создается кейс.
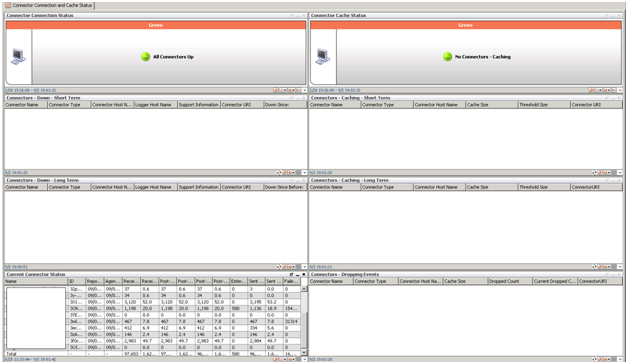
Получилось примерно следующее: рядом два дашборда с одного и того же ESM (один стандартный, другой наш). В стандартном мониторинге проблем нет. А наша версия отражает проблемы с подключением коннектора к источникам, отсутствие событий определенной категории и увеличенный поток событий от одного из устройств.

Остается одна маленькая, но важная проблема: часть событий аудита на целевых системах возникает очень редко. Например, добавление пользователя в группу доменных администраторов в Active Directory или события по изменению конфигурации сетевого устройства (собираются посредством tacacs-server Cisco ACS) и т.д. При этом сам факт появления такого события зачастую уже является инцидентом ИБ даже без дополнительного построения сложных цепочек корреляции событий.
В данном случае нам приходится прибегать к скриптотехнике: по согласованию с заказчиком мы эмулируем тестовое событие на целевой системе с некоторой частотностью и тем самым убеждаемся, что случайные ошибки в работе с аудитом не станут причиной не выявления инцидента.
Стоит отметить, что, несмотря на высокий уровень контроля за событиями, построенный в рамках описанной выше модели, мы, тем не менее, на регулярной основе проводим боевые испытания системы аудита и нашей команды разбора инцидентов. Методология такова: заказчик самостоятельно (или с нашей помощью) выполняет набор действий на источниках, подключенных к Solar JSOC, вызывая срабатывание различных сценариев (брутфорс на системе, изменение ACL на МЭ, запуск сессии удаленного администрирования, сканирование сети и пр.). Мы, во-первых, фиксируем факт получения всей исходной информации в Solar JSOC, во-вторых, лишний раз подтверждаем корректность работы корреляционных правил, ну, и наконец, проверяем реакцию и уровень анализа инцидента первой линией команды Solar JSOC.
Не менее важным показателем сервиса является выполнение SLA. Поэтому очень важно обеспечить максимальное быстродействие системы при построении отчетов, каналов, репортов при разборе инцидента инженером мониторинга или аналитиком.
В данном случае, как правило, достаточно определить набор операций и отчетов, необходимых для расследования самых критичных или частотных инцидентов, и проводить измерения времени их выполнения на средневзвешенном кейсе заказчика. Информацию о скорости выполнения мы берем сразу из двух источников.
Первый ? отчеты и операции, выполняемые по расписанию и демонстрирующие нам «эталонные» показатели быстродействия. В данном случае мы сделали два типа отчетов, которые выполняются по расписанию: отчет по заведомо пустому фильтру и отчет по типовым событиям (тот самый мониторинг источников) с суммированием по полям. По результатам работы этих отчетов мы собираем статистику и смотрим динамику изменений:

Второй ? информация по времени выполнения сотрудниками текущих отчетов.
В рамках компенсирующей меры большую часть информации, необходимой для разбора инцидента (информацию о хосте, пользователе, статистику по прокси, доменным операциям, последним аутентификациям, сессиям), мы вывели в листы, использование которых значительно ускоряет работу первой линии по разбору кейсов. По нашему опыту, редко когда приходится строить каналы с глубиной поиска более трех дней.
При наличии большого количества заказчиков и нескольких инсталляций SIEM-системы возникает необходимость работать с единым окном при разборе инцидентов. Стандартный кейс-менеджмент ArcSight не удовлетворял всем нашим пожеланиям, поэтому было решено перейти на внешнюю тикет-систему, и мы выбрали Kayako.
Благодаря такому переходу количество ошибок по неправильной доставке уведомлений сошло на нет. Все маршруты уведомлений и эскалаций строятся автоматически, к заявке имеют доступ на редактирование одновременно и инженер первой линии, и аналитик.
Так же удалось избежать проблем с путаницами в инсталляциях, когда их стало больше 4: внутри каждого кейса в Kayako сразу присутствует гиперссылка на нужный ArcSight ESM.
Подробнее о схеме построения кейс-менеджмента, фичах, к которым мы пришли, будет рассказано в одной из следующих статей.
А пока вернемся к вопросам доступности.
Одним из важнейших моментов в предоставлении сервиса является своевременный разбор поступающих кейсов вне зависимости от их количества и времени суток.
В рамках JSOC мы разработали следующие механизмы для решения данных вопросов:
Данные методы позволили нам гарантированно соблюдать метрики SLA и оперативно разбирать любое количество инцидентов, зарегистрированных у наших заказчиков.
На этом я заканчиваю вторую статью из серии. Следующая будет посвящена системе кейс-менеджмента, которую мы используем при предоставлении сервисов.
Сегодняшняя статья посвящена «магическим девяткам» доступности и готовности сервисов. Мы расскажем, из чего складываются сервисные показатели облачного SOC с точки зрения «железа» и ПО, какими средствами они контролируются в Solar JSOC.
Основная цель сервиса Solar JSOC – выявление и оперативный анализ инцидентов информационной безопасности у заказчиков. Это создает пять основных условий для его доступности[1]:
- Платформа сбора и обработки информации, коллекторы сбора на площадках, каналы передачи данных должны быть доступны и работоспособны с максимально возможным показателем. Если информацию о событиях и инцидентах нечем собирать и обрабатывать, если ей некуда поступать, ни о каком выявлении инцидентов речи идти не может.
- Информация с источников событий ИБ должна быть максимально полной: нам необходимо получать все требуемые события аудита, на основании которых построены сценарии по выявлению инцидентов. Полнота должна отражать как необходимый перечень типов событий (начало/конец соединения, аутентификация и пр.), так и нужные для расследования поля внутри единичного события (адресация, зоны, процессы, параметры события).
- В момент фиксации инцидента техническими средствами процесс сбора и анализа информации должен быть максимально оперативным.
- Безотказная регистрация в системе кейс-менеджмента и гарантированный маршрут доставки оповещения до нужного заказчика.
- Круглосуточный бесшовный разбор инцидентов в рамках гарантированного SLA.
Именно эти пять постулатов легли в основу используемой нами нашей системы мониторинга, которая использует аналогичное количество уровней.
Уровень 1. Инфраструктура Solar JSOC
Здесь я хотел бы привести схему подключения типового заказчика, использованную мной в первой статье:
Использование данной схемы разделяет процесс контроля доступности на следующие подсистемы:
- Сетевую доступность компонент:
- доступность ядра SIEM-системы для возможности работы с системой инженеров мониторинга;
- работоспособность канала между площадками ядра Solar JSOC и клиентом: наличие сетевой связности между серверами коннекторов и ядром системы;
- связь между серверами коннекторов и ключевыми источниками клиента, которые подключены для сбора событий;
- наличие доступа с ядра SIEM-системы к дополнительным серверам обработки и анализа событий, а также системе кейс-менеджмента.
- Анализ состояния сетевых компонент:
- количество ошибок обработки пакетов на сетевом оборудовании;
- информация по качеству работы site-2-site туннеля между площадками (состояние сессии, процент потерь и т.д.);
- утилизация сетевых интерфейсов на всем промежуточном оборудовании;
- нагрузка на интернет-канал, создаваемая передачей трафика.
- Показатели производительности уровня аппаратной части и ОС:
- загрузка и производительность процессоров;
- использование и распределение оперативной памяти;
- наличие свободного места в файловых разделах (системного, продуктивного и раздела для бэкапирования);
- общие показатели производительности дисковой подсистемы.
- Мониторинг состояния ключевых системных и прикладных служб на уровне ОС:
- Контроль на наличие ошибок системных журналов:
- сетевое оборудование и межсетевые экраны;
- средства виртуализации;
- ОС на компонентах ядра и серверах коннекторов.
- Мониторинг журналов коннекторов и ядра ArcSight на наличие ошибок.
- Контроль за производительностью базы данных ArcSight (параметры записи/чтения).
Мониторинг этих показателей полностью осуществляется либо через Zabbix, либо внутренними средствами ArcSight. По каждому показателю собирается статистика и настроены триггеры на заданные пороговые значения: warning – 20 % от максимального значения, critical – 2?5 % от максимального значения. В целом все достаточно стандартно, поэтому не будем тратить время на подробное описание и двинемся дальше.
Использование этой модели предоставляет возможность оперативно получать информацию о внешних и внутренних проблемах в работе сервиса и потенциально «узких» местах с точки зрения инфраструктуры. Но указанные выше параметры не дают нам представления о полноте имеющейся у нас информации, необходимых типов событий, собираемых с инфраструктуры заказчика, и уверенности, что мы видим все, что требуется для выявления и реагирования на инцидент.
Уровень 2. Полнота информации от источников
Это приводит нас ко второй задаче – необходимости контроля параметров информации, поступающей к нам от систем-источников: полноты, актуальности, корректности ее парсинга. В случае SIEM-системы критичность приобретают следующие параметры:
- контроль не только состояния источников, но и поступающих типов событий;
- выявление и предотвращение ошибок парсинга: необходимо четкое понимание корректной обработки события для успешной работы корреляционных правил;
- стремление к получению событий в режиме real-time с минимальными потерями.
Очевидно, что задача контролировать поступающие данные и анализировать их на полноту и целостность – это, в первую очередь, задача самого SIEM. К сожалению, «из коробки» не всегда можно получить приемлемые результаты. Существуют определенные ограничения:
- «Из коробки» не учитывается возможность подключения к одной SIEM-системе нескольких заказчиков.
Поэтому хоть ArcSight и обладает достаточно качественным механизмом определения состояния подключенных систем (в случае падения коннекторов, проблем с доступностью конечных источников или наличии кэша на коннекторе работают встроенные корреляционные правила + визуализация), все «коробочные» правила и дашборды не подходят для задач облачного SOC.
- Ограниченный функционал по определению отсутствия информации с источника событий по принципу «не было ни одного события за последние N часов».
Первая сложность (или особенность, кому как больше нравится) в том, что контроль идет по источнику целиком (Microsoft Windows, Websense Proxy, McAfee ePolicy) и различные типы событий никак не учитываются. Вторая сложность – решение «из коробки» не позволяет осуществлять контроль за событиями, исходя из их нормального количества и отклонения от профиля.
Как пример рассмотрим сбор событий с межсетевого экрана Cisco ASA с требуемым уровнем аудита. Одной из наиболее важных задач при контроле данного оборудования является выявление и обработка VPN-сессий удаленного доступа, терминируемых межсетевым экраном. При этом в общем потоке событий они составляют менее 1%. Их отсутствие (например, в силу изменения настроек аудита) в общем объеме событий может просто остаться незамеченным.
Но на фоне изложенных выше ограничений, в ArcSight существуют качественные механизмы контроля самого контента:
- Наличие встроенного механизма разбора событий и оценки успешности его нормализации.
Данный механизм сигнализирует о том, что полученное событие не было успешно распарсено коннектором в силу несовпадения формата.
Это событие называется «Unparsed Event», и уведомление о нем может быть доставлено как по почте, так и посредством создания кейса непосредственно в консоли ArcSight. Этот механизм помогает успешно решать задачу номер 2 – по формированию представления о полноте получаемой информации.
- Механизм контроля меток времени поступающих событий и времени ArcSight.
Вместе с определением кэширования событий на коннекторе это практически готовое решение задачи по оперативности сбора и анализа информации. Кроме того, попутно выявляются факты неправильной настройки времени на устройствах.
Но, как уже отмечалось в предыдущей статье, HP ArcSight – это, в первую очередь, framework. И мы, создавая Solar JSOC, дорабатывали свою модель контроля поступающей информации.
Во-первых, мы поменяли логику определения источника. Под каждый тип источника определили категории важных для нас событий и выделили из них наиболее частотные, наличие которых можно взять за основу.
К примеру, для Windows можно написать такой «маппинг»:
4624,Logon/Logoff:Logon
4768,Account Logon:Kerberos Ticket Events
4663,Object Access:File System
4688,Detailed Tracking:Process Creation
4689,Detailed Tracking:Process Termination
4672,Logon/Logoff:Special Logon
5140,Object Access:File Share
и т. д.
Для Cisco ASA такой:
602303,602304,713228,713050,VPN Connection
302013-302016,SessionStatistic
106023,AccessDenied
и т. д.
ArcSight позволяет достаточно просто делать такой маппинг через конфигурационные файлы.
Раньше событие статуса источника выглядело так (на примере Windows):
| Timestamp | CustomerName | ConnectorName | EventName | DeviceName | EventCount | DeviceVendor | DeviceProduct |
| 28 Jun 2016 15:23:36 MSK | Solar Security | Solar_Windows Srv Connector | Status — OK | ex-hub1 — 10.199.*.* | 164152 | Microsoft | Microsoft Windows |
Теперь же в JSOC по каждой нашей категории событий свой статус:
| Timestamp | CustomerName | ConnectorName | EventName | DeviceName | EventCount | DeviceVendor | DeviceProduct |
| 28 Jun 2016 15:23:36 MSK | Solar Security | Solar_Windows Srv Connector | Status — OK | ex-hub1 — 10.199.*.* | 35423 | Microsoft | Object Access:File Share |
| 28 Jun 2016 15:23:36 MSK | Solar Security | Solar_Windows Srv Connector | Status — OK | ex-hub1 — 10.199.*.* | 7576 | Microsoft | Logon/Logoff:Logon |
| 28 Jun 2016 15:23:36 MSK | Solar Security | Solar_Windows Srv Connector | Status — OK | ex-hub1 — 10.199.*.* | 1530 | Microsoft | Detailed Tracking:Process Creation |
Для каждого нового источника проводится длительное динамическое профилирование по объему и количеству событий, поступающих с него в ArcSight. Как правило, единицей измерения профиля является 1 час, длительность профилирования составляет 1 месяц. Основная цель профилирования – определить средние и максимальные значения количества событий от источников в разные промежутки времени (рабочий день, ночь, выходные и т.д.).
После того, как профиль построен, можно оценивать полноту поступающей информации. Например, с помощью таких правил:
- Отсутствие событий определяется не по заданному интервалу, а по сравнению с профилем, который учитывает, должны ли быть события от данного источника в этот промежуток времени.
- В случае если число событий за последний час на 20 % меньше/больше, чем baseline по аналогичным интервалам в нашем профиле, это считается отклонением и, следовательно, поводом детальнее разобраться в ситуации.
- Если появляются новые типы событий от новых источников, мы автоматически определяем это по отсутствию заполненного профиля. Такое может возникнуть, если заказчик, например, изменил уровень настройки аудита на источнике, или «завернул» новую «железку» на UDP Syslog в сторону сервера коннекторов.
Таким образом, реализованное «длинное» динамическое профилирование позволяет нам оперативно отслеживать проблемы в передаче данных и контролировать целостность поступающей к нам информации.
Во-вторых, мы доработали стандартные правила и дашборды по мониторингу источников. Добавили информацию о заказчиках и два отдельных профиля по трекингу статусов для коннекторов и подключенных устройств. Все правила в итоге заведены в единую структуру генерации инцидентов, и по каждому из них (так же, как и при мониторинге системных компонент) создается кейс.
Получилось примерно следующее: рядом два дашборда с одного и того же ESM (один стандартный, другой наш). В стандартном мониторинге проблем нет. А наша версия отражает проблемы с подключением коннектора к источникам, отсутствие событий определенной категории и увеличенный поток событий от одного из устройств.
Остается одна маленькая, но важная проблема: часть событий аудита на целевых системах возникает очень редко. Например, добавление пользователя в группу доменных администраторов в Active Directory или события по изменению конфигурации сетевого устройства (собираются посредством tacacs-server Cisco ACS) и т.д. При этом сам факт появления такого события зачастую уже является инцидентом ИБ даже без дополнительного построения сложных цепочек корреляции событий.
В данном случае нам приходится прибегать к скриптотехнике: по согласованию с заказчиком мы эмулируем тестовое событие на целевой системе с некоторой частотностью и тем самым убеждаемся, что случайные ошибки в работе с аудитом не станут причиной не выявления инцидента.
Стоит отметить, что, несмотря на высокий уровень контроля за событиями, построенный в рамках описанной выше модели, мы, тем не менее, на регулярной основе проводим боевые испытания системы аудита и нашей команды разбора инцидентов. Методология такова: заказчик самостоятельно (или с нашей помощью) выполняет набор действий на источниках, подключенных к Solar JSOC, вызывая срабатывание различных сценариев (брутфорс на системе, изменение ACL на МЭ, запуск сессии удаленного администрирования, сканирование сети и пр.). Мы, во-первых, фиксируем факт получения всей исходной информации в Solar JSOC, во-вторых, лишний раз подтверждаем корректность работы корреляционных правил, ну, и наконец, проверяем реакцию и уровень анализа инцидента первой линией команды Solar JSOC.
Уровень 3. Быстродействие
Не менее важным показателем сервиса является выполнение SLA. Поэтому очень важно обеспечить максимальное быстродействие системы при построении отчетов, каналов, репортов при разборе инцидента инженером мониторинга или аналитиком.
В данном случае, как правило, достаточно определить набор операций и отчетов, необходимых для расследования самых критичных или частотных инцидентов, и проводить измерения времени их выполнения на средневзвешенном кейсе заказчика. Информацию о скорости выполнения мы берем сразу из двух источников.
Первый ? отчеты и операции, выполняемые по расписанию и демонстрирующие нам «эталонные» показатели быстродействия. В данном случае мы сделали два типа отчетов, которые выполняются по расписанию: отчет по заведомо пустому фильтру и отчет по типовым событиям (тот самый мониторинг источников) с суммированием по полям. По результатам работы этих отчетов мы собираем статистику и смотрим динамику изменений:
Второй ? информация по времени выполнения сотрудниками текущих отчетов.
В рамках компенсирующей меры большую часть информации, необходимой для разбора инцидента (информацию о хосте, пользователе, статистику по прокси, доменным операциям, последним аутентификациям, сессиям), мы вывели в листы, использование которых значительно ускоряет работу первой линии по разбору кейсов. По нашему опыту, редко когда приходится строить каналы с глубиной поиска более трех дней.
Уровень 4. Кейс-менеджмент и оповещение заказчика
При наличии большого количества заказчиков и нескольких инсталляций SIEM-системы возникает необходимость работать с единым окном при разборе инцидентов. Стандартный кейс-менеджмент ArcSight не удовлетворял всем нашим пожеланиям, поэтому было решено перейти на внешнюю тикет-систему, и мы выбрали Kayako.
Благодаря такому переходу количество ошибок по неправильной доставке уведомлений сошло на нет. Все маршруты уведомлений и эскалаций строятся автоматически, к заявке имеют доступ на редактирование одновременно и инженер первой линии, и аналитик.
Так же удалось избежать проблем с путаницами в инсталляциях, когда их стало больше 4: внутри каждого кейса в Kayako сразу присутствует гиперссылка на нужный ArcSight ESM.
Подробнее о схеме построения кейс-менеджмента, фичах, к которым мы пришли, будет рассказано в одной из следующих статей.
А пока вернемся к вопросам доступности.
Уровень 5. Люди и SLA
Одним из важнейших моментов в предоставлении сервиса является своевременный разбор поступающих кейсов вне зависимости от их количества и времени суток.
В рамках JSOC мы разработали следующие механизмы для решения данных вопросов:
- При введении круглосуточной смены существует буферная зона по времени утром и вечером – пересменок с 9 до 10 утра и с 8 до 9 вечера. Это этап, когда ночная и дневная смены пересекаются. Предыдущая смена закрывает те кейсы, которые возникли до пересменка, передает актуальную информацию по заказчику, указывает на важные моменты, произошедшие в их смену (например, атака на заказчика, необходимость в регулярном мониторинге определенных хостов и т.п.). Новая смена включается в работу и начинает разбирать кейсы, приходящие в пересменок.
- Для нештатных ситуаций с большим количеством инцидентов существуют резервы. Днем это вторая линия мониторинга и аналитики. Ночью в смене находится один инженер мониторинга, а второй всегда ждет «на низком старте», готовый подключиться к разбору кейсов в течение 15 минут. Помимо этого существует дежурный аналитик, который владеет информацией по всем заказчикам и подключается к разбору в случае эскалации по критичности, экспертизе или количеству инцидентов. Или по всему одновременно.
Данные методы позволили нам гарантированно соблюдать метрики SLA и оперативно разбирать любое количество инцидентов, зарегистрированных у наших заказчиков.
На этом я заканчиваю вторую статью из серии. Следующая будет посвящена системе кейс-менеджмента, которую мы используем при предоставлении сервисов.
- ^Далее я буду использовать именно этот термин, хотя многие наверняка упрекнут меня в неправильном употреблении устоявшихся терминов. С точки зрения ГОСТ Р 53480-2009 существует понятие «готовность», понятие «доступность» отсутствует. Также существует IEC 60050, в котором используются несколько понятий: accessibility, availability, capability. Но в рамках данной статьи для простоты и экономии времени я буду использовать лишь один «устоявшийся» термин – доступность. Возможно, он не совсем технически корректен, но, на мой взгляд, лучше всего отражает задачи бизнеса.
Поделиться с друзьями