
3 ноября 2016 года на технологической конференции Adobe MAX компания Adobe представила очень интересную научно-техническую разработку, которая в будущем может превратиться в популярное программное приложение. Если описать изобретение вкратце, то это программа для семантического редактирования человеческой речи. При этом применяется не просто стандартный метод синтеза из собранных фонем (компиляционный синтез), но и вспомогательные методы, которые повышают реалистичность. Это интеллектуальный выбор трифонов и использование специафических характеристик голоса образца.
В результате пользователь пишет произвольный текст — а программа озвучивает его тем голосом, на который её натренировали. Можно быстро добавить в речь любые слова или вырезать ненужные.
На практике программа, представленная в рамках проекта VoCo, работает следующим образом. Сначала собирается база фонем для голоса конкретного человека на определённом языке. Для реалистичных результатов программе нужно минимум 20 минут речи человека. Чем больше — тем лучше. На базе собранных фонем (трифонов) программа затем может собирать словно из кирпичиков практически любые новые слова.
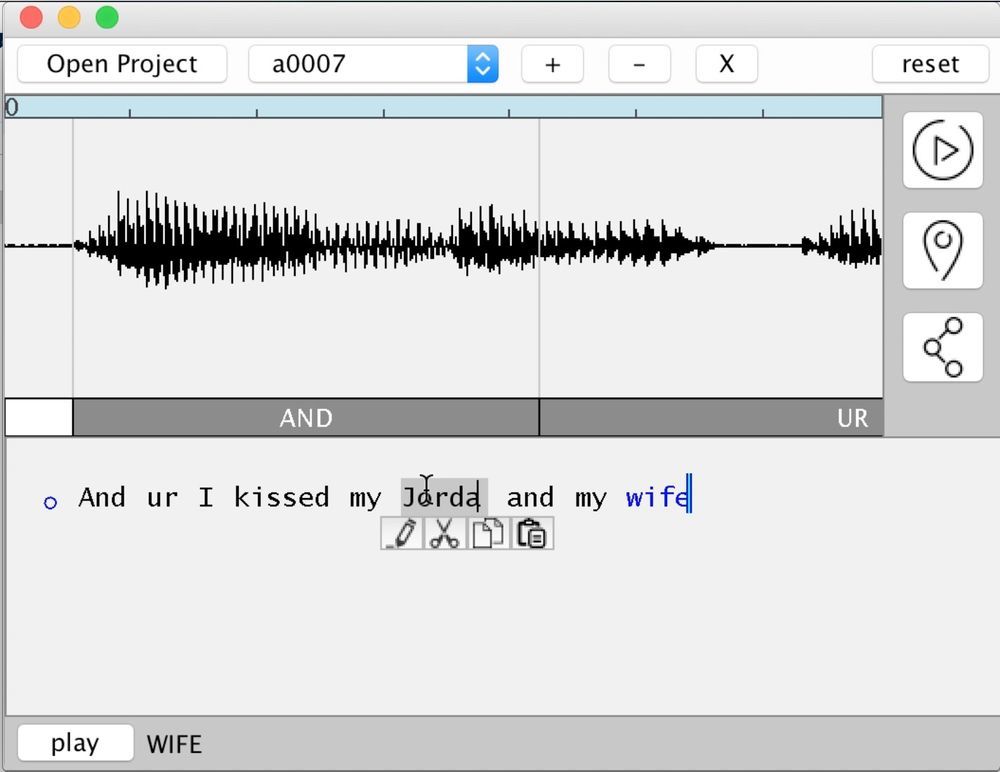
Фрагмент презентации VoCo на конференции MAX
В каком-то смысле работает VoCo напоминает работу контекстной кисти в «Фотошопе». Она тоже берёт фрагменты из разных мест картинки — и собирает из этих фрагментов новое изображение. Кусочек леса с фотографии леса, кусочек травы из другой картинки и девочка с третьей фотографии — и мы получаем совершенно новое фотореалистичное произведение с лесом, травой и девочкой на переднем плане. Если работа выполнена профессионально, то монтаж очень сложно определить. Так в советские времена стирали из истории людей, которые внезапно стали врагами народа. Был человек на фотографии — а теперь там пустота или другой человек.
Так и технология VoCo позволяет дополнять речь человека произвольными словами и фразами.
На конференции MAX презентацию провёл один из разработчиков Цзэюй Цзинь (Zeyu Jin). В опубликованной ранее научной работе он указан как сотрудник Принстонского университета, вместе с коллегой Адамом Финкельштейном (Adam Finkelstein). Технология разрабатывалась подразделением Adobe Research совместно с Принстонским университетом.
По задумке Adobe, технология поможет создателям контента для более простого редактирования аудидорожки: диалогов и закадрового текста, чтобы быстро исправить ошибку или внести изменения в сюжетную линию.
Adobe подчёркивает, что в данном случае уместнее говорить о «преобразовании голоса», чем о классическом голосовом синтезе. Целью голосового преобразования (voice conversion) является такое преобразование оригинального голоса, чтобы для слушателя он казался голосом другого человека по образцу голоса последнего.
Более подробно технические основы голосового преобразования описаны в вышеупомянутой научной работе, подготовленной совместно с Принстонским университетом. Её авторы показывают, что разработанная техника CUTE качественно превосходит другие методы голосовой конверсии. Альтернативные способы конверсии обычно основаны на параллельном анализе идентичных фраз источника и цели с последующим вычислением неких векторов преобразования в каком-либо адресном пространстве. После этого любой произвольный фрагмент голоса оригинала может быть преобразован с помощью полученных векторов. Но эти методы страдают от неприятных побочных эффектов — синтезированная таким образом речь получается глухой, невнятной.
Исследователям Adobe удалось преодолеть недостатки других техник с помощью гибридного метода CUTE. В названии зашифрованы четыре основные составляющие компоненты этой техники: компиляционный синтез (Concatenative synthesis); выбор единицы (Unit selection); предварительный отбор трифонов, то есть единиц из трёх фонем (Triphone pre-selection); использование свойств образца (Exemplar-based features).
Компиляционный синтез сводится к составлению сообщения из предварительно записанного словаря фонем. Это главный метод работы синтезаторов речи, которыми оснащаются различные устройства: от военных самолётов до бытовых устройств, в справочных службах операторов сотовой связи и др.
Как понятно из названия, разработанная гибридная техника сочетает в себе несколько методов синтеза речи и голосового преобразования.
В научной работе приводятся результаты сравнительных тестов с другими методами голосовой конверсии, в которых CUTE значительно превосходит конкурентов. При этом упоминаются некоторые его недостатки: он также как и все страдает от недостаточного количества фонем в базе при синтезе новых слов, из-за чего генерируются фонетически правильные, но не очень реалистичные результаты. Кроме того, он зависит от работы движка распознавания речи для корректной фонетической сегментации.
Пока неизвестно, собирается ли Adobe реализовать эту перспективную разработку в виде реального коммерческого продукта. Но уже сейчас можно сказать, что такая программа стала бы очень востребованной, при условии реалистичности синтеза голоса из фонем. Например, её могли бы использовать подкастеры для генерации подкастов из текста. Её можно использовать также для озвучивания аудиокниг, используя голос произвольного человека (например, собственной девушки). Такая технология наверняка найдёт применение в Голливуде для озвучки кадров в отсутствие актёра. Например, если с ним разорвали контракт или он умер посреди съёмок.
Комментарии (62)

nikitastaf1996
06.11.2016 17:46Скоро любое видео можно будет смотреть с озвучкой в реальном времени.Даже не ждать.

Anarions
06.11.2016 18:05+1Осталось прикрутить нейросеть распознающую эмоции в голосе-источнике, и накладывающую эти эмоции на переведённый результат.

Tabke
07.11.2016 12:54+3Более того, озвучка будет но русском, но с оригинальными голосами иностранных актёров.
tundrawolf_kiba
07.11.2016 13:37Вот тут встает интересный вопрос, станут ли анимешники смотреть аниме с русской озвучкой, но голосами сэйю, или продолжат смотреть с оригинальной озвучкой и сабами?


Loki3000
06.11.2016 19:30+1Даже имея текст перед глазами, мне с трудом удавалось разобрать что он бормочет. Тембр голоса может передает и верно, но читает так же как любая другая электронная читалка.
Anarions
07.11.2016 02:13Голос такой у человека-оригинала. Вполне внятно читает, один в один с человеком.

Meklon
07.11.2016 11:05+2Олично читает. Jordan как-то чуть промямлил, но three times произнес отлично на мой вкус.

gionet
06.11.2016 19:41+8В принципе, чего-то подобного давно ожидал… Недавно показали гугловский алгоритм, который читает почти так же как человек, даже вздыхает и паузы делает… Следом наверняка натаскают нейросеть на имитацию разных голосов и манеры речи.
Потом через год-другой эти технологии обработают напильником, и скоро можно будет, например, навигатор в машине заставить голосом Левитана объявлять повороты и названия населенных пунктов… Или голосом уже умерших актеров продублировать фильм. Эраст Гарин — король из золушки, мог бы читать сказки. Раневская читать рассказы Чехова и т.д.
Все предпосылки уже есть, технологии почти готовы.
Короче, ждём…
road_t
07.11.2016 09:59+2наконец получим навигацию настоящим голосом жириновского)
А уж если эту штуку петь научить… диджеи разного рода получат новый виток к развитию.

unxed
07.11.2016 13:58> Все предпосылки уже есть, технологии почти готовы.
Вот и с управляемым термоядерным синтезом так. Лет 50 уже)

fireSparrow
07.11.2016 16:00Интересно, как скоро голоса начнут законодательно защищаться?
Насколько я знаю, сейчас существует защита визуального образа (статья 152.1 ГК РФ) — визуальный образ человека нельзя использовать без согласия этого человека (или его родственников, если человек уже умер).
Для голоса пока ничего похожего не нагуглил.

Kirtis
06.11.2016 21:03-2Слишком опасная технология для выпуска её в качестве реального продукта. Очень много можно найти способов использовать её в противозаконных, преступных целях: любого человека можно скомпрометировать, всего лишь изменив пару слов в его речи. При этом регулировать распространение программ в эру интернета слишком проблематично, поэтому надеяться на то, что данная технология не попадёт в руки мошенников и других преступников, не приходится.
destroy
06.11.2016 21:07+4Все в порядке, эволюция сделает свое дело.

Alexufo
06.11.2016 22:19-5Я думаю у вас пройдет это глумление с возрастом.

aapazhe
07.11.2016 11:14+1В тринадцать лет нормально так думать.
Alexufo
07.11.2016 21:01Возраст как будто обозначает наличие мозгов.
Есть такая иерархия живых.
Живые это:
1) Я, дети
2) жена муж
3) мать отец
4) дед и бабка
5) дядя — тетя
Все, а дальше все те — на кого распространяется эволюция. То есть дураки. А раз они дураки то должны умирать по законам эволюции.
Нужно мне говорить, что это убеждение в эволюции среди дураков строится на религиозных убеждениях?
Я не говорю что программа топика — зло. Я имею ввиду что выражения про эволюци..( ляляля что то там. эволюция сделает свое дело) признаны доказать себе превосходство над теми кто не читает geektimes.

entze
06.11.2016 21:47"… и других..."
20 минут записей голоса любого человека найдётся в небезызвестном «пакете», И отредактированный могут сохранять туда же.

SBKarr
06.11.2016 22:15+3Мошенники и преступники и так живут неплохо, ведь суть их деятельности не в технологиях, а в знании процессов у человека в голове. В том числе в знании о том, как сделать так, чтобы человек не обратил внимания на различия в голосе. Компрометация и так успешно осуществляется с помощью единственной безвредной записи путём добавления собеседника и перестановки слов.
Реально беспокоится можно актёрам озвучания, когда к технологии приделают генератор эмоций. Очень много проходных текстов можно будет записывать и без человека. Они и сейчас не слишком довольны жизнью… https://www.google.ru/search?q=pf,fcnjdrf+frn%60hjd+jpdexfybz&ie=utf-8&oe=utf-8&gws_rd=cr&ei=eoAfWK3-EomksAHDi5nQBA#newwindow=1&tbm=nws&q=SAG-AFTRA
P.S. А база PRISM будет побольше базы из известного пакета, но почему первым всплывает именно он? Всё таки, АНБ и начали раньше, и размах покруче, и касается это граждан любой страны, а не одной конкретной…
SinsI
07.11.2016 08:11Генератор эмоций не нужен — эмоции можно брать из голоса озвучивающего.актёра.
Просто он один сможет выдавать все виды голосов — от самого низкого хриплого баса до тончайшего сопрано, так что вместо команды будет достаточно 1-2 профессионалов на все звуки.
General_Failure
07.11.2016 11:37Где-то я уже видел что-то похожее
Кажется, у Гоблина :)
Ну что ж, ждём новых переводов от VoCo-Гоблина
GeeSVe
06.11.2016 22:18+2Как и многие другие технологии и разработки — она может и будет использована не только во благо, но и во вред. Обязательно найдутся жулики, которые ей воспользуются. Просто надо будет знать, что не всему сказанному по телефону или ТВ можно верить. В общем-то, что в этом плохого?
jex
06.11.2016 23:49-1Теперь всех либиралов наконец-то поймают за руку! А то они всё гудят «голос не мой, не похож, бла бла бла».

alexvoz
07.11.2016 00:04+1За фотошоп можно было сказать тоже самое, подделка документов, фотографий с места преступлений и т.д. но массово сейчас как-то такое не наблюдается. Экспертиза почти всегда сможет отличить оригинал.
Alexufo
07.11.2016 21:25Вот фейк с пририсованными тачками к буку.
https://vimeo.com/146179080
Что скажет экспертиза?

agugnin
07.11.2016 11:12+1Тут есть и обратная сторона медали — всегда ситуацию можно будет обиграться так, что любая компрометирующая запись сможет быть подана как синтезированная поддлка, так что даже если что-то ляпнул, можно будет легче отмыться.
alexvoz
07.11.2016 12:31Так же, как и сейчас ссылаются на поддельные фото, видео и документы. Это не повод не развивать технологии )
unxed
07.11.2016 14:01Если технология в принципе реальна — рано или поздно появится open source аналог — не на гитхабе так в даркнетах. Как прикажете это дело ограничивать или регулировать? Лучше сразу включать мозг и придумывать, как обезопасить себя/близких от потенциально опасных применений.


kalmarius
06.11.2016 22:05+1… и сразу вспомнился момент из «Терминатора-2», когда Т800 разговаривал по телефону голосом Джона Коннора.
Скрытый текст
alexvoz
07.11.2016 00:12На таких конференциях представляли технологии деблюра (восстановление четкости в изначально размытой или смазанной фотографии), удаления людей по нескольким фото, для редактора анимаций показывали панель генерирования реалистической анимации с физикой — это из того, что я вспомнил. Но пока что то не вижу я в их продуктах таких функций. Так что и эта технология может отправится «на полку».

SOb_S
07.11.2016 07:36В их продуктах может и нет, но на рынке же есть. В Affinity Photo, к примеру, есть Stack и операции с ним – те самые увеличение чёткости и удаление объектов.
alexvoz
07.11.2016 12:40В бэта-версии для Win таких функций не обнаружил. Судя по видео работы программы удаление объектов работает по тому же принципу, что и заливка content-aware в photoshop, причем примерно такого же качества. Видео демонстрации кардинального увеличения четкости не нашел (как на Adobe Max 2011).
Понятно, что есть и будут появляться программные продукты с полезными уникальными функциями. Еще это все можно вручную делать, хоть и долго. Я к тому, что сама Adobe показывает какую то интересную функцию или технологию а потом нигде ее не использует.

Namynnuz
07.11.2016 20:25Вот прямо щас запустил фотошоп, скачал картинку с презентации и проделал все те же самые действия… Всё внимание на правый нижний угол: http://i.imgur.com/fI4GLc5.png
Было бы невероятно странно, если бы свёртка вдруг отказалась работать. В данном случае, вся сложность в автоматическом снятии с картинки корректного зерна, приведшего к искажению.
И нет, не обязательно результатом лабораторных изысканий становится коммерчески успешное приложение.Meklon
07.11.2016 22:05+1На самом деле давно пора добавить копеечные акселерометры в фотоаппараты. И тогда траектория смаза связанная с движением камеры во время экспозиции может быть скорректирована.
alexisneverlate
07.11.2016 11:28+2Следующий шаг — синтезирование речи тем же голосом, но на другом языке, что подойдет для переозвучки фильмов с сохранением голоса тех же актеров, ну и конечно перевод твоей речи на лету на другой язык.
Перспективы фантастические и немного пугающие.
Особенно пугает тем что может любой человек позвонить и разговаривать голосом любого человека — без видеосвязи уже будешь не верить.
Radmin
07.11.2016 11:41+1Особенно пугает тем что может любой человек позвонить и разговаривать голосом любого человека — без видеосвязи уже будешь не верить.
Можете уже начинать не верить даже с наличием видеосвязи… :)
https://geektimes.ru/post/273030/alexisneverlate
07.11.2016 11:52Да, но это реалистично (можно ведь лицо повернуть или еще что то сделать) будет мне кажется сложнее сделать чем голос т.е. какое то время хотя бы это даст шанс на проверку
safinaskar
07.11.2016 19:02+1SBKarr
07.11.2016 16:20-1На работе путём анализа видео установили, что это пропросту удобный GUI для уже существующей фичи в Adobe Audition. Оно берёт аналог звучания из образца и подставляет на место вставки. Например, слово wife в презентации было тупо скопировано с образца таким образом, что явно слышно падение интонации, характерное для конца утвердительного предложения в английском, хотя вставка была в середину. Проще говоря, система не умеет синтезировать речь, она умеет поставлять образцы звуков в соответствии с фонемами букв. Никакой хитрой начинки типа обученной нейросети там нет (или оно на совсем примитивном уровне), это просто адаптированный к речи интерфейс.
P.S. В сущности это действительно аналог say, если на вход подавать различные звуки для фонем помимо строки на чтение. Ничего больше.

4ebriking
08.11.2016 03:19анекдот на эту тему вспомнился:
Во время записи сложной фортепианной партии пианист всё время сбивался — то в одном месте, то в другом…
наконец звукорежиссер не выдержал: «слушай, да не мучайся ты… сыграй гамму»

alecv
08.11.2016 13:00Ямаховские Вокалоиды не дают спать Adobe
https://ru.wikipedia.org/wiki/Vocaloid



dfgwer
Проклятый прогресс, теперь звонки от родственников с просьбой срочно 100 штук закинуть станут реалистичнее.
Robotex
Ну так ты родственникам закидывай, а не на левые номера карт.
negodnik
Ничто не мешает сказать «У меня поменялся номер карты, запиши»
Robotex
Ну тогда ты сам себе злобный буратино :) Встреться лично и отдай. Или на старый номер перезвони.