

Дорогой хабрачитатель, я хочу поделиться опытом по поводу прозрачного для приложения перехода с очереди PgQ на amqp. Возможно это покажется велосипедом, возможно какие-то мысли пригодятся. Статья предполагает знакомство с основами PgQ и rabbitmq.
Предпосылки
Так исторически сложилось, что в нашем проекте очень активно используется PgQ. При всех своих недостатках, у PgQ есть неоспоримое преимущество — транзакционность с базой данных, чем активно пользовался наш код. То есть, можно быть уверенным, что и в очередь событие попадет, и база обновится. Или ни того, ни другого не случится. И это преимущество должно быть перенесено на новый движок очередей.
Подробно описывать причины ухода с PgQ я тут не буду, это тема для другой статьи. Остановлюсь только конкретно на самом переходе.
Ход размышлений, pg_amqp
Гугление наводит на расширение для PostgreSQL — pg_amqp. Оно предоставляет хранимые процедуры в PostgreSQL для отправки в amqp. Расширение отлично работает на уровне логики приложения: откатив транзакцию в PostgreSQL — данные в amqp не попадут. А если закоммитим — попадут.
BEGIN;
INSERT INTO some_table (...) VALUES (...);
SELECT amqp.publish(broker_id, 'amqp.direct', 'foo', 'bar');
ROLLBACK; //Данные и в базу не вставились, и в amqp не отправились
На самом деле расширение не гарантирует то что сообщение попадет в amqp. Внутри всего лишь последовательный коммит транзакции сначала в PostgreSQL, а потом в amqp. И если пропадет соединение с amqp между двумя коммитами — сообщение пропадет. Несмотря на то что вероятность такого события маленькая, потерянные пакеты будут. А учитывая, что мы работаем с реальными деньгами и торговыми счетами, это недопустимо.
Для тех, кому потеря 0.01% пакетов допустима — остаток статьи можно не читать. Просто используйте pg_amqp, если хотите уйти с PgQ на amqp.
Начинаем строить велосипед
* Далее вместо абстрактного amqp будет конкретный rabbitmq.
Но ведь у нас остается PostgreSQL, внутри которого транзакции полноценные. И мы можем транзакционно вставлять все пакеты в какую-то таблицу, а потом как-то досылать в amqp то что туда не дошло.
Сказано — сделано.
Вся работа с PgQ у нас в приложении делалось с помощью одной хранимой процедуры, которую я мог свободно менять.
Я создал таблицу
amqp.message(
id bigint default nextval('amqp_message_id_sequence') primary key,
pid bigint,
queue varchar(128),
message text
)
и тригер, который при вставке в таблицу отправлял эти данные в amqp. А хранимку вставки в pgq заменил на вставку данных в эту таблицу. Overhead при этом только в отправке данных в amqp, так как в PgQ тоже при каждом событии происходит вставка в таблицу. Зачем нужен pid объясню позже.
Теперь сообщения есть и в таблице, и у получателя из rabbitmq. В таблицу сообщения пишутся гарантированно в рамках транзакции PostgreSQL, а в amqp отправляются почти все сообщения, с помощью pg_amqp. Но как понять какие сообщения пришли, а какие нет? И как держать эту таблицу во вменяемых размерах (желательно десятки или сотни строк), чтобы не потерять производительность?
Тут на помощь приходит сам rabbitmq. Ведь он умеет сообщения дублировать в несколько очередей

Так давайте одну очередь отдадим нашему бизнес-коду, а вторую будем использовать для подтверждения получения пакета?
Сказано — сделано. Создаем exchange, 2 очереди и досыльщик, который просто удаляет из таблицы amqp.message полученное сообщение.
В итоге, есть таблица, в которой хранятся только те сообщения, которые «в пути». Размер таблицы всегда небольшой, так как сообщения сразу же после вставки удаляются. Размер таблицы можно поставить на мониторинг. А бизнес-код нашего приложения теперь работает только с rabbitmq и ничего не знает о магии под капотом.
Вот как выглядит итоговая схема работы
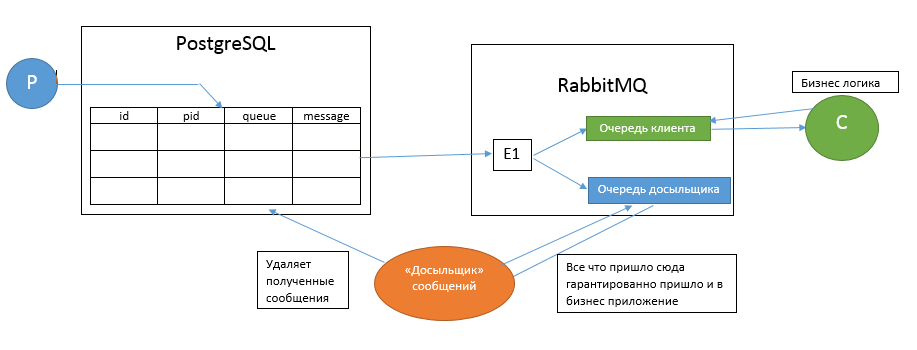
Но теперь появляется важный вопрос: а как понять, что какой-то пакет не пришел? Ведь строка в таблице amqp.message ещё не гарантирует, что сообщение пропало — оно может быть просто «в пути». Нам нужно быть в этом уверенным, чтобы досылать пакет, иначе мы можем создать дубль пакета, и кому-то зачислим 200$ вместо 100$ :) И в то же время определить, что пакет не пришел и дослать его нужно максимально быстро, чтобы минимально нарушать порядок следования пакетов в очереди.
Вот тут начинается основное шаманство
Все наши пакеты пронумерованы по возрастанию, но ведь система многопоточна, и пакеты не обязаны приходить в rabbitmq в том порядке, в котором они лежат в таблице. А вот в рамках одного процесса, который отправляет сообщения в amqp, они должны быть строго упорядочены. PostgreSQL предоставляет возможность посмотреть pid текущего процесса (pg_backend_pid()). И мы можем ожидать, что в рамках одного pg_backend_pid() пакеты будут строго упорядочены по возрастанию (напоминаю, что id пакета мы генерируем с помощью nextval). А следовательно, при получении пакета с id N, все пакеты от этого же pg_backend_pid с id ниже N являются не доставленными и их нужно дослать.
Итого, нам нужно сделать досыльщик очереди, который делает всего 2 вещи:
- Слушает очередь «Очередь досыльщика»
- Проверяет, нет ли в таблице amqp.message сообщений с текущим pid и id меньшим чем текущий. Если есть — досылает их (досылает опять таки транзакционно, через таблицу amqp.message)
- Удаляет из таблицы amqp.message сообщения по id
Профит! У нас все сообщения доходят до адресата, и при этом мы полностью избавились от PgQ. Код основного приложения практически не изменился.
Накладные расходы на все:
- Системная таблица amqp.message, в которую мы вставляем каждое сообщение, а потом удаляем
- Досыльщик, который удаляет строки из amqp.message и досылает сообщения
Обращу внимание на то, что логика досыльщика совершенно устойчива к падениям. Его в любой момент можно убить, он снова запустится и продолжит работу без каких-либо проблем.
Система не учитывает случай, когда процесс postgres отправил пакет в amqp, который не дошел, и больше пакеты не отправляет. Буду благодарен, если кто-то подскажет, как автоматически обработать эту ситуацию. Сейчас это решается просто мониторингом, но ни одного такого события пока не было. Вообще факт досылки сообщения — очень редкое событие. У нас используется pgbouncer, что уменьшает множество различных pg_backend_pid.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (34)

neolink
26.05.2015 14:02+2а что именно не нравилось в PgQ?

Ents Автор
26.05.2015 14:10Есть несколько причин
- Не мгновенная доставка сообщений
- Нет роутинга сообщений
- Постоянный поллинг базы, даже когда нет событий. То есть приложение генерирует нагрузку даже когда ничего не делает
- Сложно гибко добавлять консьюмеры. subconsumers как-то решают проблему, но не полностью. Могут появляться зобми-консьюмеры и т.д.
- Батчи. То есть если скрипт обработал 10 событий из батча и упал повторно обработчику снова придет весь батч. И что бы повторно не обработать те же события нужно где-то отдельно хранить какие из событий мы уже обработали

Ostrovski
26.05.2015 14:29-2Кажется сайт от этого быстрее работать не начал =)
Ents Автор
26.05.2015 14:32Какой сайт? С чего он должен начать быстрее работать?
Ostrovski
26.05.2015 14:36Постоянный поллинг базы, даже когда нет событий. То есть приложение генерирует нагрузку даже когда ничего не делает
— видимо не так уж влияет на общий перформанс.Ents Автор
26.05.2015 14:49На общую производительность это конечно не сильно влияет и на боевой системе не играет никакой роли. Но когда хотим создать отдельный контур для тестирования конкретной задачи это вырождается в дополнительные процессоры на каждую задачу

guyfawkes
26.05.2015 14:27+1А вы искали уже какие-то готовые решения этой же проблемы? Просто, как мне кажется, подобная бизнес-задача много где возникает.
Ostrovski
26.05.2015 14:30+1По моему опыту на тему PgQ достаточно трудно найти что-либо готовое. Собственно, это одна из причин, почему в нашем проекте мы тоже думаем отказаться от него.
guyfawkes
26.05.2015 14:33Подразумевал не решение с помощью PgQ, а в целом обеспечение целостности между БД и очередями и их обработкой
Ents Автор
26.05.2015 14:33Конечно искал. Ничего лучше pg_amqp не нашел. И именно исправлениям недостатков pg_amqp и посвящается эта статья
guyfawkes
26.05.2015 14:34:)
попробую перефразировать: есть PostgreSQL, есть amqp. Нужно обеспечить целостность. В опенсорсе уже что-то готовое, покрывающее эти нужды, есть?
Ents Автор
26.05.2015 15:04Нет, я ничего такого не нашел
Плюс есть ограничение на минимальное исправление логики основного приложения (у нас же переход с PgQ на amqp, а не просто обеспечение целостности PgQ+amqp). Следовательно переход должен осуществляться просто подменой хранимки в PostgreSQL или ещё чем-то простым

m0Ray
27.05.2015 10:07-1Я бы в таблицу добавил поле под наванием, например, status с умолчанием 0 и менял его следующим образом: 1 — предпринята попытка отправки сообщения, 2 — сообщение точно отправлено. И ещё поле timestamp-а, которое заполняется временной отметкой попытки посылки сообщения. А по крону работает скриптик, который выбирает все «просроченные» сообщения со статусом 1 и досылает.
У меня такая схема работает с очередями (только с применением ZeroMQ), пока вроде не глючило.Ents Автор
27.05.2015 10:161) Что значит «простроченное»? Секунда, 10 секунд, минута? Мы никак не можем прогнозировать время доставки сообщения. И дослать сообщение нужно максимально быстро, не дожидаясь некоторого времени «прострочки»
2) Как вы можете гарантировать что скриптик, который досылает, не сгенерирует дубли сообщений? Например, если упадет после отправки в ZeroMQ и перед пометкой о отправке в базе?
3) Крон подразумевает опять таки полинг базы, от которого хотелось избавиться. Время доставки сообщений у вас, очевидно, не realtime
m0Ray
27.05.2015 10:561) У меня «просрочкой» считается время в две минуты (120сек).
2) Код элементарный. if(отправлено) {db_update(...)} — что тут может упасть?
3) Нет, допустимый лаг доставки — порядка 5 минут.Ents Автор
27.05.2015 15:331) А вы уверены что у вас просто крон-скрипт на две минуты не «зависал»? Или что будет, если вы часы в системе на 2 минуты переставите?
2) Например, может упасть сеть между базой и вашим скриптом. Или вы банально можете захотеть перезагрузить базу данных/сервер

itcoder
27.05.2015 11:12Спасибо за статью, интересное решение, PgQ и правда довольно проблематичная очередь. Вопрос такой: Какую нагрузку выдерживает данная архитектура? если например высчитывать баланс одновременно 10 000 пользователей, получается что запросы сначала попадают в PgBouncer, какое то время висят в нем, ожидая очереди на запись, затем пишутся в Postgrgres, потому уже начинают срабатывать триггеры для отправки в amqp. На все уходят, хоть и не большие, но задержки. И еще интересно будет ли работать ваше решение по Round-robin схеме ?
Ents Автор
27.05.2015 18:10Лаг получается около 10-30мс. При одном потоке досыльщика, написанном на пхп пропускная способность получается ~1000 пакетов в секунду. Сейчас перепишу досыльщик на что-то более серьезное и выложу его на гитхаб

kefirfromperm
27.05.2015 17:10RabbitMQ не поддерживает распределенные транзакции?
Ents Автор
27.05.2015 18:11Насколько я знаю, нет. Если ошибаюсь — исправьте меня пожалуйста
kefirfromperm
27.05.2015 20:07+1Интернет сказал что нет. :)
Но если вам нужны распределенные транзакции, то почему вы выбрали RabbitMQ, а не одну из систем сообщений, которые поддерживают распределенные транзакции, такие как ActiveMQ, HornetQ?
kefirfromperm
27.05.2015 20:09+1ActiveMQ ещё и AMQP поддерживает до кучи.
Ents Автор
27.05.2015 21:33Вообще задача была — максимально безболезненный переход с PgQ на amqp. А использование честного менеджера транзакций (для двухфазного комита) потребовало бы существенного переписывания основного приложения (так как события в очередь будут отправляться уже не изнутри PostgreSQL, а из приложения).
Кстати ActiveMQ не поддерживает двухфазный комит, а только некий аналог, который может продуцировать дубли сообщений — activemq.apache.org/should-i-use-xa.html
kefirfromperm
28.05.2015 07:16Что-то я не понял, где по ссылке написано, что ActiveMQ не поддерживает XA? Написано, что лишь не поддерживает приостановку транзакций (XA Transaction suspend / resume semantics). И что XA-транзакции медленные, поэтому лучше сделать приложение нечувствительным к дублям и использоваться обычные.

mtyurin
27.05.2015 22:27+3вообще, решение не самое плохое, как могло показаться на первый взгляд.
замечания:
1) интересно было вспомнить про XactCallback внутри pg
2) страшно пускать древненький сишный, по цифрам бета, код pg_amqp *0.4.1* в бой, можно покрашить весь кластер начисто
3) вместо pid надо Session Id (комбинация pid и backend_start)
www.postgresql.org/docs/9.0/static/runtime-config-logging.html#GUC-LOG-LINE-PREFIX %c
4) очень не хорошо отклик базы вешать на еще один синхронный внешней сетевой вызов — потенциально это глобальный дедлок в системе, по мимо прыгающего латенси при коммите и простое центрального ресурса (коим база и является) если сеть лагает. в приведенном примере надо было тогда просто на клиенте после коммита в базу синхронно писать далее в раббит
5) проблема «повторного прихода события» не решается и в консумере rabbit а. если он упал в процессе обработки и не отметил событие как выполненное, клиент получит его еще раз (Message acknowledgment www.rabbitmq.com/tutorials/tutorial-two-python.html)
и 100 рублей превратятся в 200ти всё равно, так что трекать всё равно надо, и это не проблема pgq, а! ограничение реального мира
6) ну и большой вопрос, как быть когда раббит развалится (https://aphyr.com/posts/315-call-me-maybe-rabbitmq) и надо будет сводить концы с концами и что-то досылать в него ( тут и опять в том числе повторная доставка )
// примерно подобную штуку проектировал: pgq шный консумер перекладывал в раббит — лаг 1 секунда, но нет синхронных завязок внутри базы и страшного кода. но при этом я воспроинмал раббит уже просто как отрезок сетиEnts Автор
27.05.2015 23:07-2первое: спасибо, очень содержательный комментарий. По некоторым пунктам пришлось очень крепко задуматься и даже советоваться в нашими ДБА
А теперь по пунктам
1)
2) Там всего 600 строк кода, то есть по размеру как средняя задача. Его можно отревьювить и допилить. Или даже переписать под себя
3) да, верно. pid — зациклен, нужно добавить backend_start. Спасибо!
4) Дедлок — это 2 процесса ждут друг-друга. А у нас только pg ждет amqp. То есть дедлок невозможен, просто будут запросы в БД тормозить и упремся в количество соединений. Или я не прав?
5) Да, не решается. Но баг в одном месте системы — не повод допускать ещё один баг в другом месте :) То есть нам бы этого лучше по возможности избежать
6) Когда rabbitmq развалится мы будем просто наружу кидать exception и ролбечить, и пусть родительское сообщение разбирается что делать (например, ролбек транзакци и 500 ошибка пользователю). Сообщения теряются именно тогда, когда у нас на момент начала транзакции rabbitmq был доступен, а к концу транзакции пропал
Вариант с перекладывателем я обдумывал, но он сам по себе не транзакционен и не надежен. Будет или дубли порождать, или сообщения терять. Если нет груза существующего кода, тогда уж лучше использовать HornetQ и реализовать честные распределеные транзакции, как предложил kefirfromperm
mtyurin
28.05.2015 00:54+14) но вопрос мой открыт: приложение не хотели трогать совсем? такую же систему в целом можно было сделать, если просто с клиента писать еще и в раббит после записи в базу.
5) 100 рублей превращаются в 200ти всё равно, значит надо трекать всё равно повторное выполнение. значит дело не в конкретной «очереди» (pgq/rabbit/etc), а вообще так всё всегда везде.
6) вооот. опять получите повторно сообщения, так как те, которые исчезли при падении (из очереди досыльщика) и так и не успели удалится из таблицы, — все придут опять. у вас досыльщик и конечный консумер работаю же абсолютно независмо и асинхронно.
// тут еще момент: проблема с Message acknowledgment отдельно интересна для досыльщика, надо бы посмотреть, заложились ли вы на повторный приход «удаления»
«HornetQ» — уж лучше уж кастылить дальше)
мой вам совет итоговый — делать честного pgq-шнуго консумера с нормальным треканием обработки (там всё уже прилагется).
github.com/markokr/skytools/tree/master/sql/pgq_ext/functions
по моему, вы просто недоосвоили pgq-шные возможности.
Ents Автор
28.05.2015 10:544) В принципе да, можно было запрос к rabbitmq делать на уровне приложения, но таблицу message и досыльщик все равно должен остаться
5) я уже сказал :) одно место где дублируются пакеты — не повод создавать ещё одно место и создавать ещё больше дублей
6) не понял вас, поясните. Что значит сообщения исчезли из очереди? Я не рассматриваю ситуацию когда мы в раббит успешно закомитили, а сам ребит и где-то потерял. Пакеты могли потеряться только в дороге, при неуспешном комите в rabbit. Досыльщик досылает только то, что гарантированно не пришло в rabbitmq
По поводу недоосвоения pgq не комментирую :) тема статьи в механике перехода, а не в причинах, побудивших это сделать
mtyurin
29.05.2015 19:545) вы с этого начали, но проблему в итоге так и не решили
> отдельно хранить какие из событий мы уже обработали
6) а тут я вам показываю, что вам и пачкой могут повторы прилетать:
6.1) либо когда не сработал Message acknowledgment на очереди досыльщика (и он повторно будет досылать)
6.1) либо в случае аварии раббита (kill -9 и подобное, когда он потеряет события, которые были в его очереди), когда поле восстановления всё, что пропало из очереди досыльщика (но обработалось уже на продуктовом консумере) снова дошлется
Ents Автор
30.05.2015 07:126.1) Пометка ack делается только после успешного удаления/досылки. Досылка подразумевает удаление досылаемой строки из БД. При повторном получении пакета строки в БД уже не будет и досыльщик ничего не будет досылать
6.2) У rabbitmq есть режим, когда он сохраняет события на диске (delivery_mode=2). И в случае аварии они никуда не деваются. Соответственно заново не дошлются
mtyurin
31.05.2015 14:28по пункту 5 значит мы решили, что всё таки как-то не ровненько, и трекать надо бы, — хорошо.
далее:
6.1) вооот. тут то вы, как раз, через досылку _только_ после удаления, и реализовали, по сути, трекание событий досыльщика, — ОК
6.2) а тут вам надо внимательно почитать про «delivery_mode=2» и «персистентность» раббита (и например еще в связи с этим и про лаг acka по 200ms) — раббит fsync делает отложенно (для буфера из многих мессаджей), то что вы потеряете — вы даже не отследите
и
далее. это всё вам надо же держать еще горячие «реплики» (и базы и очередей), вы же не будете ждать пока железо новое подвезут/введут, так что проблема восстановления после аварий и потерь (fsync а по сети тем более нету, в раббите особенно) приобретает более общие рамки. и да, мы еще не рассматривали падение и восстановлени pg.
Ostrovski
Ждем код досыльщика на github!
Ents Автор
Досыльщик скоро будет выложен