

На протяжении многих лет одним из главных вопросов, связанных с приложениями на .NET, был вопрос производительности. Одна из самых первых статей на эту тему датирована еще 2001-м годом.
Тема не теряла актуальности более 10 лет, и в 2011 люди все еще задают вопросы в поисках лучшего инструмента для профилировки.
О том, что все это значит для современной .NET-разработки и какие инструменты для обеспечения максимальной производительности использует крупнейшее сообщество разработчиков в мире, мы решили поговорить с перфоманс-инженером Stack Overflow Марко Чеккони.
 Марко Чеккони, инженер Stack Overflow из Лондона. Много пишет о разработке софта, кодинге, архитектуре и командной работе.
Марко Чеккони, инженер Stack Overflow из Лондона. Много пишет о разработке софта, кодинге, архитектуре и командной работе.– Вы работаете в Stack Overflow, можете назвать основные «болевые точки» вашего проекта с точки зрения производительности?
– Их две: с одной стороны, нам надо быть очень-очень аккуратными при инстанцировании объектов и в работе со сборкой мусора, а с другой, нам нужно не меньше внимания уделять тому, как мы используем SQL-сервер, пишем SQL-запросы, строим таблицы и т.п.
На данный момент это два основных аспекта, которым мы уделяем максимальное внимание, и которые больше всего влияют на производительность.
– Ваше решение построено полностью на С#, или есть части на других языках, типа C++, Java, Python или других?
– Я бы сказал, что на 99% у нас С#. У нас, конечно, есть немного на C++ или С, но в строчках кода это совсем мало. Естественно, у нас есть TypeScript и JavaScript. JavaScript у нас на сервере используется для компиляции бандлов и минификации кода. Мы также пользуемся SQL, это другой язык. Вот и все.
– Можете приоткрыть завесу, почему вы решили разрабатывать проект на C#, а не на других языках и технологиях?
– Могу я зайду немного с другой стороны, отвечая на этот вопрос? Stack Overflow существует уже 8 лет. И за это время мы выросли, я не знаю, где-то со ста тысяч просмотров за день до миллиардов просмотров в месяц. И мы все еще используем C#. Так почему же мы не перешли на что-то другое? И ответ здесь не в какой-то нездоровой преданности Microsoft, дело в очень хорошей среде выполнения, которая соответствует всем нашим нуждам. И мы просто не видим причины тратить время и переключаться на что-то еще. На данный момент для нас все это работает более, чем хорошо.
– То есть на данный момент у вас есть дополнительные резервы для того, чтобы справиться с резким наплывом посетителей, если таковой случится?
– На данный момент мы работаем на 5% от максимальной мощности. Мы можем выдержать в 20 раз большую нагрузку. Ну, это будет, конечно, тяжело, мы бы не хотели работать на все 100% все время, но в настоящий момент у нас что-то между 5 и 10%.
– Стоит ли нам тогда вообще продолжать интервью? :) Судя по всему у вас нет никаких проблем с производительностью.
– О, нет, у нас множество проблем с производительностью. Но вы знаете, оптимизация производительности – это не то, чем вы занимаетесь только тогда, когда уже все умирает и постоянная нагрузка на процессор не падает ниже 80% в течение дней. Именно потому, что мы постоянно оптимизируемся, именно благодаря этому у нас нагрузка 5%, оптимизация – это постоянный и длительный процесс.
Запас прочности
– ОК, можете припомнить особенно серьезные проблемы? Может быть, какие-то события на рынке, в вашей истории, когда вы реально испытывали задержки и перебои в работе вашего решения?
– Нет, проблем такого масштаба у нас никогда не было. Причиной тому наш огромный запас прочности. Мы работаем, даже когда нас DDoSят. Конечно, никогда не следует быть слишком самоуверенным, но у меня сложилось впечатление, что при супермасштабной DDoS-атаке первым забьется наш Интернет-канал, а с этим мы уже практически ничего сделать не в состоянии. Есть определенные события, отражения которых мы видим в логах. Когда выпустили Pokemon-Go, у нас был очень большой рост на несколько дней. А выборы президента дали заметный спад, после выборов значительно сократилось количество посетителей. Мы можем отслеживать такие события, но эти скачки не превышают 100% от нормы.
– Давайте перейдем к выбору инструментов. Какой ваш любимый инструмент для нахождения «бутылочных горлышек» в коде?
У нас есть собственный инструмент, который называется МiniProfiler. Он опенсорсный, вы можете найти его на GitHub. Работает он на .NET и Ruby. Под .NET он работает оператором using. Using мы используем для определения блока кода, который мы хотим измерить. Если вы хотите измерить время вызова, вы можете упаковать это в using, таким образом создавая профиль исполнения запроса. Например, у нас есть таймер, который включается, когда мы начинаем обрабатывать запрос, и этот же самый таймер останавливается, когда обработка запроса заканчивается. Таймеры существуют для каждой БД, каждого запроса к БД, к движку ElasticSearch.
Таймеры установлены в разные блоки каждой страницы, поэтому мы можем сравнить и оценить скорости рендеринга списка вопросов со скоростью рендеринга нижнего или верхнего колонтитулов на главной странице. Этот инструмент вставляет результаты подсчетов в качестве комментариев в response headers. Девелопер видит на странице маленькое поле с данными в правом верхнем углу, которое содержит данные про времени рендеринга страницы, а при нажатии на это поле будет отображена подробная информация по каждому из процессов на странице.
Этот инструмент рассчитан на обнаружение конкретных проблем. Если при просмотре какой-то страницы возникает задержка, я точно вижу, почему она возникает. Также мы используем подмножество данных, которые мы собираем и храним вместе с логами, это позволяет создавать SQL-запросы и выводить статистику эффективности по каждой странице.
Еще один наш инструмент называется Bosun – это система сигнализации по временным рядам. Она осуществляет мониторинг указанных нами параметров, например, памяти, распределенных ресурсов, и поднимает тревогу при значительном изменении этих параметров.
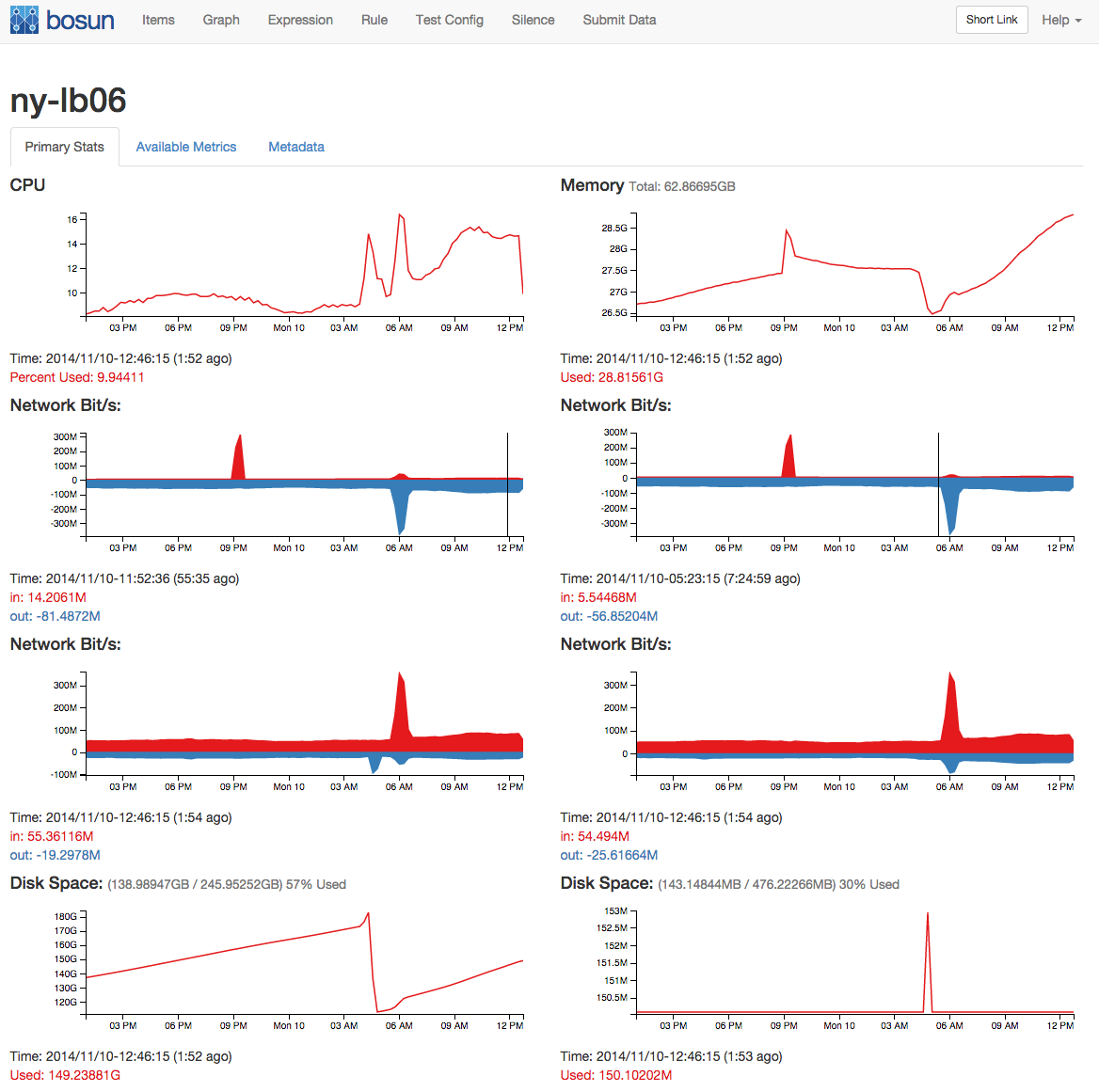
У нас есть еще одна система, которая мониторит каждый SQL-запрос, другими словами, она собирает статистику по работе БД. Благодаря этому мы точно знаем, какие запросы занимают большее время, не сделали ли мы что-то неправильно, и что вообще происходит.
Другая система все время отслеживает параметры работы сервера, такие как память и CPU. У нас есть возможность отслеживать все особые ситуации, которые происходят на всех наших серверах со всеми нашими проектами.
– Это похоже на Telegraf?

– Наш инструмент называется Opserver, мы сами его создали специально для решения этой задачи, и он с открытым исходным кодом.
– Каков ваш подход к оптимизации быстродействия. Что вы делаете с «медленным» кодом?
– Обычно «плохо пахнут» аllocations, которые не всегда просто найти – единственный способ это сделать это взять дамп памяти IIS и напрямую посмотреть, что там происходит и почему это занимает столько памяти, потому что allocation может случиться где угодно. Это может произойти как в нашем собственном коде, так и в вызванной библиотеке. Такое случается как в сторонних библиотеках, так и в библиотеке .NET. Например, StringBuilders стали добавлять одну allocation в конструкторе, и это совершенно точно весьма серьезно повлияло на работу нашей системы.
Иногда allocations происходят при использовании LINQ. LINQ ужасен для allocations. Иногда его оптимизируют, и он работает, а иногда нет, и всегда очень сложно сказать, будет ли все работать без проблем или нет. Это основное, за чем мы наблюдаем и что отслеживаем.
– Вы упомянули специальный инструмент, который вы используете в Stack Overflow. Можете ли вы сказать, как вы осуществляете бенчмаркинг?
– На самом деле, мы не так часто занимаемся бенчмаркингом. Основное для нас, это как себя ведет код, когда он поступает в продакшн. Продакшн – вот наш бенчмарк. Мы просто релизим код и смотрим, работает он или нет. И для того, чтобы вы понимали, почему это важно, просто подумайте про SQL-запросы. Допустим, вы создали плохо оптимизированный SQL-запрос. Вы не можете сразу определить конкретно этот запрос как источник проблем, потому что вы можете что-то заблокировать, а остальное будет работать штатно. Когда код в продакшене, вам не всегда очевидны связи между кодом и последствиями. В целом, всегда сложно создать максимально приближенное к реальности окружение для безопасного тестирования кода вне продакшена.
— Часто оптимизированный код выглядит куда красивее
– Чаще всего высокопроизводительный код оказывается весьма некрасивым и набитым различными хаками. Вы испытываете сложности в работе с оптимизированным кодом?
– Да, иногда оптимизация это хаки или уродливые вещи типа размотки цикла, но в большинстве случаев оптимизация – это не то, что ухудшает код. На самом деле, в большинстве случаев быстрый код оказывается гораздо красивее.
То, что я говорю может прозвучать глупо, но я уверяю вас, что это правда. Если вы напишете меньше кода, он будет работать быстрее. Вы в прямом смысле пишете меньше кода, поэтому он оказывается компактным. В одном и том же классе вы можете найти все от HTML, к сожалению, до SQL. И он очень компактен, все находится друг рядом с другом. Все это делает наш код более читаемым, потому что все у тебя под рукой, не нужно все время ссылаться на другие части кода.
– Разве более компактный код по факту не оказывается менее читаемым и поддерживаемым?
– Более компактный код действительно не обязательно становится более понятным и легким в обслуживании, но самодостаточность кода без внешних зависимостей действительно делает его более понятным и maintainable. Как мне кажется, основное в нашем коде – это зависимость только от себя самого. Допустим, вы пишете Mock-проект, очень-очень маленькую штуку, просто для тестирования кейса или что-то очень компактное, занимающее всего несколько сотен строк кода. Может быть, вы поднимаете Linkpad и загружаете вашу штуку туда, очень компактную, и все там.
Этот код должен быть для вас очень понятен. Там сотня строк кода, вы можете прочитать их все, держать их в голове, представлять, как она работает. И это то, к чему мы стремимся, каждая фича очень-очень компактная и автономная. Конечно, не всегда это получается, и код получается более сложным, но это неизбежно. Мне кажется, что в 90% случаях, когда я работаю, я не пишу сложный код. Я пишу очень-очень простые вещи с минимумом движущихся деталей, и это реально просто. Что же касается нашего разговора о производительности, я просто покажу вам примеры и то, как мы этого добились. Вы увидите, что код максимально простой и компактный, даром что очень эффективный.
– Проблемы с производительностью возникают не только в твоем собственном коде
– Я только что понял, что проблемы с производительностью возникают не только в твоем собственном коде. Есть еще среда, железо и библиотеки сторонних производителей. Вам приходится это использовать «как есть», или есть какие-то способы оптимизировать и это?
– Мы очень хорошо об этом знаем. Все наше железо разработано нами. Естественно, мы не проектируем материнские платы, но все требования разрабатываются специальным подразделением SRE: сколько оперативной памяти, каких производителей, какие модели и какие power strips мы хотим использовать. Все специфицировано нами, именно поэтому мы не пользуемся облачными сервисами, у нас собственный хостинг и мы все контролируем. Постройка машин, специально заточенных под наши задачи и требования – один из залогов нашей производительности.
Что касается библиотек сторонних разработчиков, да, нам знакома и эта проблема. Основные наши вопросы: что ты делаешь, какими инструментами пользуешься, например, библиотека, которую мы написали сами и опубликовали. В большинстве случаев наши требования сильно отличаются от стандартных. Мы постоянно переписываем библиотеки под себя. У нас есть собственный набор библиотек, например, клиент Redis, собственное решение protobuf, JMS serializer и т.п.
– Кстати, у вас есть собственная версия C#?
– У нас собственная версия Roslyn-based компилятора, в основном для компиляции razor-шаблонов, но единственное, для чего он используется – это локализация. Мы переделываем только то, что нам нужно, язык мы не расширяем. Язык Vanilla мы используем сам по себе. Основная причина, по которой мы не модифицируем язык – совместимость, это сразу ломает Visual Studio и все прочее, а мы этого не хотим.
– Звучит круто.
Учитывая все, что мы обсудили относительно оптимизации, есть ли определенные сигналы для девелопера, когда ему стоит начать оптимизировать код, или не начинать совсем?
– Постоянно оптимизируйте код. Производительность – это фича, недостаточная производительность – это баг.
– Философский вопрос – я верю, что IT это про деньги. Если кто-то спросит, сколько времени вы тратите на оптимизацию работы, сможете ему ответить конкретно, например, «40 часов»? За эти 40 часов вы можете внедрить фичу для пользователя или потратить на оптимизацию, нужда в которой некритична. Это своего рода компромисс.
– Я не согласен с вами. Если у вас баг в релизе, вы что, его не исправите?
– Конечно, исправлю.
– Вот именно. Это то же самое. Недостаток производительности – это баг, который нужно исправить. Все просто.
– А как тогда определить, что в производительность стала «багом»?
– Вы постоянно отслеживаете параметры производительности. Заметили, что производительность падает? Находите проблему и решаете ее. Естественно, никто не занимается оптимизацией только ради процесса. Мы делаем это так: отслеживаем параметры; видим, когда что-то сломалось или работает неправильно; фиксим проблему. В нашем конкретном случае все просто. Процесс починки – непрост, прост процесс принятия решения. Когда что-то работает неэффективно, например, страница вместо 20 миллисекунд грузится 2 секунды – вам нужно исправить это. Нельзя заставлять пользователя ждать 2 секунды. Может быть, некоторые компании могут себе это позволить. Мы – нет.
– Используете ли какие-либо способы оптимизации железа? Например, многопоточность, hyper-threading, вычисления на GPU?
– Используем. В одном случае мы использовали CUDA для требовательных параллельных вычислений. Мы вообще много используем параллельность, но в основном для таких задач, как build. Когда мы хотим обработать несколько файлов, мы используем параллельные вычисления и многопоточность везде, где это возможно. С точки зрения кода, мы стараемся использовать sync, чтобы избежать всех external weights, таких, как weights БД. Но я не уверен, что это можно назвать истинной многопоточностью. Дайте мне подумать…
В большинстве случаев лучшая стратегия для веб-сервера – это максимальная быстрота, не надо размазываться на разные ядра. Потому что мы постоянно конкурируем с определенным количеством запросов других пользователей. Лучший вариант использования CPU в этом случае, наверное, оставить распределение запросов по ядрам для IAS. В случае использования библиотек или приложений в backend это имеет больше смысла, так как там меньше запросов и лучше использовать больше ядер на запрос. На самом деле именно для этого создавалась CUDA. Мы заметили, что увеличение количества потоков увеличило и производительность, поэтому я сказал: «Давайте это попробуем». Другой разговор, что конкретно я отдам для этого.
– Я что-то слышал о значке «НЕ РОБОТ». Можете что-нибудь про это рассказать?
– Stack Overflow – пользовательское комьюнити для разработчиков, и мы награждаем разработчиков, присваивая им очки, которые называются «репутация», а также награждаем значками. Этим мы поощряем людей и стимулируем их заниматься тем, что мы считаем полезным для сообщества. Например, если вы задаете умный вопрос, вы получаете значок. Если хорошо отвечаете на умный вопрос – тоже получаете значок. Значком «НЕ РОБОТ» мы награждаем людей, которые приходят и общаются с некоторыми нашими спикерами, а также ходят на конференции.
В последнее время мы очень много комментируем и устраиваем много конференций. Мы также заметили, что люди стесняются задавать вопросы и не ходят на конференции, может быть, они интроверты, может быть, считают нас недосягаемыми, а может быть, что Stack Overflow – пришельцы из космоса. Поэтому мы и создали значок, чтобы мотивировать людей. Когда мы встречаемся в реале, вы получаете специальный код для активации значка. Значок очень редкий, и единственный способ получить его – встретиться с нами. Мы хотим их раздать в Хельсинки и Москве.
– Что бы вы посоветовали всем .NET и C# разработчикам?
– Делать то, что нравится и вдохновляет. Очень важно то, что разработка – это не просто работа. Разработка – это еще и креативный челлендж, потому что в отличие, например, от автослесаря, вы каждый день сталкиваетесь с чем-то новым. Это означает постоянно заниматься чем-то новым и постоянно учиться чему-то новому. Важно не только делать свою работу профессионально, но еще и со страстью. Развивайте свое увлечение работой, это постоянно толкает вас к дополнительным свершениям, а не просто к работе «от и до». Думайте над тем, что сделает вас счастливым, и делайте это.
Кстати, послушать Марко и получить значок «НЕ РОБОТ» можно будет 9 декабря на конференции «DotNext».
Вопросам производительности будут посвящены также следующие доклады:
? WinDbg Superpowers for .NET Developers
? А не зашкалит сервер от 100,000 запросов/сек?
? End-to-end JIT
? Модификация кода .NET в рантайме
Комментарии (27)

redmanmale
05.12.2016 20:27+4Понимаю, они крутые ребята, но тут прямо набор антипаттернов разработки.
Продакшн – вот наш бенчмарк. Мы просто релизим код и смотрим, работает он или нет.
Если вы напишете меньше кода, он будет работать быстрее. В одном и том же классе вы можете найти все от HTML, к сожалению, до SQL.

Flux
05.12.2016 22:34+8Дотошное следование паттернам и методологиям разработки совершенно не дает гарантии написания хорошего/производительного кода.
redmanmale
05.12.2016 22:46+1С этим не спорю, но.
Есть годами выработанные принципы, являющиеся не достаточным, но необходимым условием для написания производительного, но понятного и поддерживаемого кода. Они возникли не на пустом месте.
sentyaev
06.12.2016 01:00+5Есть годами выработанные принципы...
Обычно они выглядят так (из опыта):
Для каждого Service есть IService
Для каждого Repository есть IRepository
Для каждой Model есть ViewModel и маппинг один в один
Еще страшная конфигурация DI с фабриками
И обязательно все в разных проектах — модульность же.
При этом в проекте ни одного теста, но все говорят, что они скоро появятся и поэтому пишем так, чтобы была возможность тестирования.
Еще добавьте несколько солюшенов которые шарят библиотеки через nuget пакеты (обычно шарятся модели и интерфейсы), которые версионируются, т.к. делается все с прикидкой, что каждый проект может работать со своей версией пакета, но малейшее изменение влечет за собой то, что придется обновить все проекты (добавил поле — протощи его по всем слоям).
А еще микросервисы — они же позволят нам деплоить части проекта независимо.
Но… деплоится все одним большим куском, т.к. эти микросервисы шарят одни и те же модельки например, поэтому помимо того, что малейшее изменение мы протягиваем по слоям, теперь его еще нужно протянуть через микросервисы.
В итоге можно выбросить 9/10 кода, слить все в один проект и ничего не поменяется.
А если еще сверху написать хотябы по одному е2е тесту вообще праздник начнется.
Именно такие проекты я видел, где люди следовали «годами выработанным принципам» вместо того, чтобы решать задачи бизнеса.
Суть в том, что вам нужно выбрать из всего множества техник именно те, которые подходят вашему проекту. Сложность в том, что ни в одной книжке не пишут как определить, нужны вам эти техники или нет, подходит вам определенный паттерн или нет.
Razaz
06.12.2016 01:361. Тут все просто -> нет сайд эффектов и запрещено заменять навсегда, то без интерфейса, в противном случае по желанию.
2. Это вообще антипаттерн если есть EF.
3. Тут спорно: если вы не билдите вьюхи в том же MVC, то это очень спасает от случайных косяков. А еще если вы протащили энтити из EF — то вообще мастхэв для спокойного сна.
4. Если проект мелкий, то хоть в одной сборке все держите.
Большие проекты с top-down подходом к проектированию — совершенно другие требования.
За все время работы понял, что модульность заставляет писать нормально, думая головой что, где и на каком уровне надо делать. AspNet Core хороший пример, когда я могу взять только те компоненты, которые мне нужны.
5. А вы как, бинарниками шарите? То, что шарят модель — ну сами себе злобные буратины, которые верят в реюз моделей во всех слоях.
6. Независимость не единственный бонус. Например масштабирование определенных компонент, которые вынесены в отдельный сервис. Если неправильно готовить, то все будет какашкой :)
7. Поменяется. Как минимум internal сразу станет бесполезным, а цепкие ручонки полезут тыкать и вызывать все подряд.
Вам не свезло с проектами :) И задачи бизнеса это не только тяп ляп и в продакшен — это всю хрень еще поддерживать годами, следить за совместимостью на бинарном уровне и апи, развивать spi и учитывать, что неверное движение или лишний интерфейс в Nuget пакете — получите кучу головняков с велосипедами от клиентов.
redmanmale то же категоричен:
Даже большой проект != SO. Часть проблем встречается только при таких нагрузках и объемах, которые на тестовом стенде никогда не увидать. Например потестируйте коллизии гуидов.
Меньше кода — лучше локализация, меньше кол стэк и тд и тп. В определенных ситуациях это критично.
Иногда лучше цикл развернуть или по самому тупому закодить, но без лишних аллокаций и вызовов.
У нас есть код где каждый if критичен, например.sentyaev
06.12.2016 02:39Вам не свезло с проектами :)
Скорее не везло с архитекторами) Проекты как раз очень интересные были.
Не стоит строить фундамент для небоскреба пока от нас просят «хрущевку», т.к. при небольшом расширении на нее можно и 6-ой этаж достроить (в некоторых городах так делали). Ну а если уж решили расширяться… проще рядом построить.Razaz
06.12.2016 02:56Надо сразу резать скоуп проекта ;) Так как сайт или например процессинг — слегка разные весовые категории ;)
Во всем надо искать золотую середину — не надо все упрощать до состояния стола и табуретки, но и абстрагировать все подряд то же не надо.
Еще один фактор: есть проекты «конечные» — написал, сдал, забыл, а есть продукты, которые из года в год развиваются. Тут разный подход, но народ все равно кидается какашками друг в друга, не понимая, что каждый по своему прав :)

Alex_ME
07.12.2016 20:14А почему репозиторий с EF — анти-паттерн? Везде встречаю репозитории. Надо что, прямо с DbContext операции в сервисе производить? Такую сильную зависимость слоя логики от слоя доступа к данным сделать?
Razaz
07.12.2016 21:01+1Да, прямо с DbContext в сервисе, если используете EF. Какую сильную зависимость? EF и есть абстракция со встроенным абстрактным репозиторием. Причем это очень текучая абстракция.
А встречается часто, так как начитались книжек про паттерны и пихают куда ни попадя. Абстракция от абстракции. А уж если еще и автомаппер пихнуть(ведь общие модели со слоем данных нини), то просто сказка, а не код. Самый шик — выставить IQueryable из репозитория.
Alex_ME
07.12.2016 21:05С одной стороны, наличие доступного DbContext дает большую гибкость. С другой стороны, в репозитрии зачастую включает часто используемый код, чтобы не реализовывать его каждый раз в сервисах.
sentyaev
07.12.2016 21:49+1Если вы маппите Модель -> Таблица (один к ондому), то да, вы используете ORM не правильно, вернее не так как предполагали те, кто придумал ORM.
В итоге получаем Anemic Domain, и посути это эквивалентно паттеру Transaction Script (толко вместо хранимок пишем Linq)
репозитрии зачастую включает часто используемый код
и как следствие получаем эту проблемуAlex_ME
07.12.2016 21:54Если я правильно понимаю, то Rich Domain Model — это модель, которая содержит в себе какую-то бизнес-логику, что никак не связано с тем, как она маппится на таблицы. Вполне, мне кажется, можно иметь Rich Domain Model, которая маппится на таблицу 1-к-1 (или если используются свойства навигации — это уже нельзя считать 1-к-1?)
И различные методы репозитория, вроде Insert, Update мне кажется полезными. Хоть они и короткие, но все же не в одну строку. Мне тут видится дублирование кода.
P.S. Сам я просто хочу разобраться, потому что столько мнений, что голова кругомsentyaev
07.12.2016 22:31+1Зачем выдумывать? Давайте обратимся к Фаулеру.
Repository — выступает в роли посредника между слоем домена и слоем отображения данных, предоставляя интерфейс в виде коллекции для доступа к объектам домена.
Т.е. из репозитория вы уже получаете доменные объекты, и по идее в них должна быть инкапсулирована доменная логика, так что никакого повторяющегося кода не будет.
Razaz
07.12.2016 21:58Добавлю к сказанному sentyaev, что используя репозитори, зачастую, откидываются фичи EF. Например identity map на уровне контекста(либо это все шикарно утекает через всякие врапперы наверх).
Если это все не используется, то не проще использовать тот же Dapper или Linq.Net если уж так не хочется писать SQL запросы? Тут нет лишних абстракций — все, что надо, допиливаете сами и тут как раз паттерн репозиторий как раз в тему.

mphys
05.12.2016 22:46+1Мы просто релизим код и смотрим, работает он или нет.
Это как разработчики Galaxy Note,
— «Надо уменьшить толщину телефона, ведь так он более привлекателен для покупателя»
— «Но сэр, хрен его знает что будет с аккумулятором!»
— «Давайте просто зарелизим и посмотрим»elepner
05.12.2016 23:24+4Неправильная аналогия, считаю. У самсунга не было 20ти кратного запаса прочности. Нельзя так просто взять и отозвать over 9000 устройств, а откатить на предыдущую версию код можно.
questor
05.12.2016 23:55Значок очень редкий, и единственный способ получить его – встретиться с нами. Мы хотим их раздать в Хельсинки и Москве.
А почему именно в этих городах? Это города с наиболее крупным коммьюнити? (А где же Пекин, Нью-Йорк) Или наоборот, с наименее крупным, но наиболее перспективным?

ARG89
06.12.2016 11:16+1Интервью проводилось в контексте конференций DotNext, поэтому Марко назвал два соответствующих города.
Конечно, значок можно получить в любом другом месте, встретившись с представителями команды SO.


Got_Oxidus
06.12.2016 23:29– О, нет, у нас множество проблем с производительностью. Но вы знаете, оптимизация производительности – это не то, чем вы занимаетесь только тогда, когда уже все умирает и постоянная нагрузка на процессор не падает ниже 80% в течение дней. Именно потому, что мы постоянно оптимизируемся, именно благодаря этому у нас нагрузка 5%, оптимизация – это постоянный и длительный процесс
zodchiy
Если я правильно понял фразу, то запрос пользователя исполняется в sync-контексте? Понятное дело, где-то в глубине backend-а, работа с кэшем и БД идет в своих контекстах, но вот точка входа, контроллер используется без async? Или я неправильно понял фразу?
Alex_ME
«Увеличение количества потоков» — может, все-таки имелось ввиду async и это просто опечатка?
zodchiy
Так в оригинале, да ошибка.