
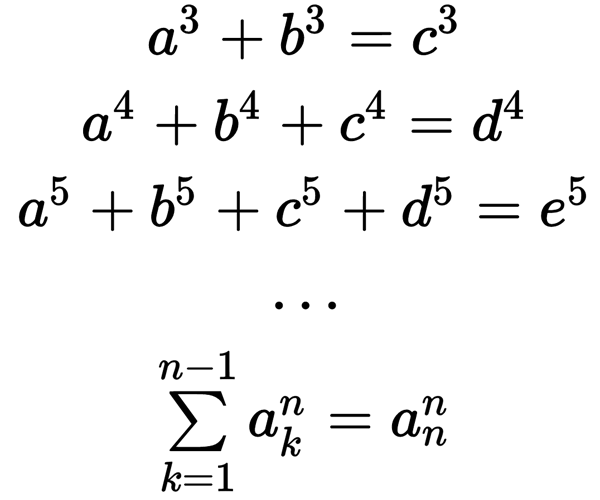
не имеют решения в натуральных числах.
Ну собственно так оно и было до 1966 года…
Пока Л. Ландер (L. J. Lander), Т. Паркин (T. R. Parkin) и Дж. Селфридж ( J. L. Selfridge) не нашли первый контрпример для n = 5. И сделали они это на суперкомпьютере того времени — CDC 6600, разработанного под командованием не безызвестного Сеймура Крэя (Seymour Roger Cray) и имел этот суперкомпьютер производительность аж 3 MFLOPS. Их научная работа выглядела так:

То есть простым перебором на суперкомпьютере они нашли числа степени 5, которые опровергали гипотезу Эйлера: 275 + 845 + 1105 + 1335 = 1445.
И всё бы ничего, но другой умный товарищ спросил: "интересно, а вот кто–нибудь из программистов может набросать код для супер–современного i5 по поиску еще таких совпадений?...".
Как вам уже понятно, предложение сработало как красная тряпка. Первое решение оказалось достаточно красивым и написанным с умом. Суть в том, что вначале считаем пятые степени для 1-N чисел, заносим их в таблицу и рекурсивно начинаем перебирать с самого низу четыре слагаемых пятых степеней, попутно ища в таблице сумму получившихся значений. Если нашли — вот оно и решение (индекс в таблице будет числом, степень которого мы нашли).
Вот этот первый вариант пользователя 2Alias:
#include <iostream>
#include <algorithm>
#include <stdlib.h>
#include <vector>
#include <unordered_map>
using namespace std;
typedef long long LL;
const int N = 250;
LL p5(int x)
{
int t = x * x;
return t * (LL) (t * x);
}
vector<LL> p;
std::unordered_map<LL, int> all;
int res[5];
void rec(int pr, LL sum, int n)
{
if (n == 4)
{
if (all.find(sum) != all.end())
{
cout << "Ok\n";
res[4] = all[sum];
for (int i = 0; i < 5; ++i)
cout << res[i] << " ";
cout << "\n";
exit(0);
}
return;
}
for (int i = pr + 1; i < N; ++i)
{
res[n] = i;
rec(i, sum + p[i], n + 1);
}
}
int main()
{
for (int i = 0; i < N; ++i)
{
p.push_back(p5(i));
all[p.back()] = i;
}
rec(1, 0, 0);
return 0;
}
И как оно обычно бывает, я подумал, а можно ли быстрее? Заодно у людей возник вопрос, а что будет если проверить в этом деле C#. Я в лоб переписал решение на C# и программа показала примерно такой же результат по времени. Уже интересно! Но оптимизировать всё же будем C++. Ведь потом всё легко перенести в C#.
Первое что пришло в голову — убрать рекурсию. Хорошо, просто введём 4 переменные и будем их перебирать с инкрементом старших при переполнении младших.
// N - до какого числа ищем 1 - N в степени 5
// powers - массив с посчитанными заранее степенями
// all = unordered_map< key=степень числа, value=само число>
uint32 ind0 = 0x02; // ищем начиная с 2
uint32 ind1 = 0x02;
uint32 ind2 = 0x02;
uint32 ind3 = 0x02;
uint64 sum = 0;
while (true)
{
sum = powers[ind0] + powers[ind1] + powers[ind2] + powers[ind3];
if (all.find(sum) != all.end())
{
// нашли совпадение - ура!!
foundVal = all[sum];
...
}
// следующий
++ind0;
if (ind0 < N)
{
continue;
}
else
{
ind0 = 0x02;
++ind1;
}
if (ind1 >= N)
{
ind1 = 0x02;
++ind2;
}
if (ind2 >= N)
{
ind2 = 0x02;
++ind3;
}
if (ind3 >= N)
{
break;
}
}
И тут же результат стал хуже. Ведь нам будут встречаться множество одинаковых сумм, большую часть которых рекурсивный алгоритм обходит. Допустим у нас числа от 1 до 3, переберём их:
111
112
113
121 < — уже было!
122
123
131 < — уже было!
132 < — уже было!
133
…
Значит придётся смотреть комбинаторику, но мне это не сильно помогло, так как достаточного объёма знаний по этой теме я не имею, пришлось выписывать примерно такой же пример на бумажку и подумать. И решение нашлось: при инкременте старших разрядов, не надо сбрасывать младшие на самый минимум, а присваивать значение старшего всем младшим — так мы отсечём лишнее.
Код увеличения индексов стал таким:
...
// следующий
++ind0;
if (ind0 < N)
{
continue;
}
else
{
ind0 = ++ind1;
}
if (ind1 >= N)
{
ind0 = ind1 = ++ind2;
}
if (ind2 >= N)
{
ind0 = ind1 = ind2 = ++ind3;
}
if (ind3 >= N)
{
break;
}
Ура! И уже сразу чуть быстрее. Но что нам говорит профайлер? Большую часть времени мы сидим в unordered_map.find…
Начинаю вспоминать алгоритмы поиска и разнообразные знания(вплоть до демосцены). А что если перед проверкой в unordered_map как-то быстро отсекать часть ненужного?
Так появился ещё один массив, уже битовый (bitset). Так как числа нам в него не занести (они слишком большие), придётся быстро делать хэш из степени, приводить его к количеству бит в массиве и отмечать там. Всё это надо делать при построении таблицы степеней. В процессе написания оказалось, что std::bitset немного медленнее простого массива и минимальной логики что я набросал. Ну да ладно, это ерунда. А в целом ускорение оказалось существенным, около двух раз.
Много экспериментируя с размером bitset'a и сложностью хэша стало понятно, что по большому счёту влияет только память, причём для разных N по-разному и большая степень фильтрации обращений к unordered_map.find лучше только до определённого предела.
Выглядеть это стало примерно так:
...
// тут теперь мы быстро фильтруем сумму по хэшу и битовой таблице
if (findBit(sum))
{
// и только потом проверяем в map, а проверять надо - ведь у нас коллизии из-за хэша
if (all.find(sum) != all.end())
{
// нашли!
}
}
// следующий
...
Дальше возникла проблема номер два. Первый пример из далёкого 1966 года имел максимальное число 1445 (61 917 364 224), а второй (2004 год) уже 853595 (4 531 548 087 264 753 520 490 799) — числа перестают влезать в 64 бита…
Идём самым простым путём: берём boost::multiprecision::uint128 — вот его нам хватит надолго! Это из-за того, что я пользуюсь MS CL, а он просто не поддерживает uint128, как все остальные компиляторы. Кстати, за время поиска решения проблемы uint128 и компиляторов я ещё узнал про шикарный сайт — Compiler Explorer. Прямо в онлайне можно скомпилировать код всеми популярными компиляторами разных версий и посмотреть во что они транслируют его(ассемблер), причём с разными флагами компиляции. MS CL тоже есть, но на бета сайте. И помимо С++ есть Rust, D и Go. Собственно, по коду и стало понятно, что MS CL совсем не понимает 128 составные целые, все компиляторы транслируют перемножение двух 64 битных в 128 битную структуру за три умножения, а MS CL — за четыре. Но вернёмся к коду.
С boost::multiprecision::uint128 производительность упала в 25 раз. И это как-то совсем неправильно, ведь в теории должно быть не более 3х раз. Забавно, что на столько же упала производительность C# версии с типом decimal (он хоть и не совсем целочисленный, но его мантисса 96бит). А предварительная фильтрация обращений к Dictionary (своеобразный аналог unordered_map из STL) — работает хорошо, ускорение очень заметно.
Ну значит сами понимаете — стало обидно. Столько уже сделано и всё зря. Значит будем изобретать велосипед! То есть простой тип данных uint128. По сути, нам же нужно только присваивание, сравнение, умножение и сложение. Не так и сложно, но процесс в начале пошёл не туда, так как сначала я взялся за умножение и дошло это до использования ассемблера. Тут не чем гордиться, лучше всего себя показали интринсики. Почему процесс пошёл не туда? А нам умножение-то и не важно. Ведь умножение участвует только на этапе просчёта таблицы степеней и в основном цикле не участвует. На всякий случай в исходниках остался файл с умножением на ассемблере — вдруг пригодится.
friend uint128 operator*(const uint128& s, const uint128& d)
{
// intristic use
uint64 h = 0;
uint64 l = 0;
uint64 h2 = 0;
l = _mulx_u64(d.l, s.l, &h);
h += _mulx_u64(d.l, s.h, &h2);
h += _mulx_u64(d.h, s.l, &h2);
return uint128( h, l);
}
Со своим uint128 производительность тоже, конечно, просела, но всего на 30% и это отлично! Радости полно, но профайлер не забываем. А что если совсем убрать unordered_map и сделать из самописного bitset'a подобие unordered_map'a? То есть после вычисления хэша суммы мы можем уже использовать это число как индекс в ещё одной таблице(unordered_map тогда не нужен совсем).
// вот так выглядит самописный map
boost::container::vector<CompValue*> setMap[ SEARCHBITSETSIZE * 8 ];
...
// ComValue просто контейнер для степени и числа
struct CompValue
{
...
mainType fivePower;
uint32 number;
};
// Поиск по битовому массиву и самописному map
inline uint32 findBit(mainType fivePower)
{
uint32 bitval = (((uint32)((fivePower >> 32) ^ fivePower)));
bitval = (((bitval >> 16) ^ bitval) & SEARCHBITSETSIZEMASK);
uint32 b = 1 << (bitval & 0x1F);
uint32 index = bitval >> 5;
if((bitseta[index] & b) > 0)
{
for (auto itm : setMap[bitval])
{
if (itm->fivePower == fivePower)
{
return itm->number;
}
}
}
return 0;
}
Так как проект совершенно несерьёзный и никакой полезной нагрузки не нёс, я сохранял все способы перебора, поиска и разных значений через жуткий набор дефайнов и mainType как раз один из них — это тип куда пишется степень числа, чтобы подменять его при смене только один раз в коде. Уже на этом этапе все тесты можно проводить с uint64, uint128 и boost::multiprecision::uint128 в зависимости от дефайнов — получается очень интересно.
И знаете, введение своего map'а — помогло! Но не на долго. Ведь понятно, что map не просто так придуман и используется везде, где только можно. Опыты — это, конечно, подтверждают. При определённом N (ближе к 1 000 000), когда все алгоритмы уже тормозят, голый map(без предварительного bitset'a) уже обходит самописный аналог и спасает только значительное увеличение битового массива и массива где хранятся наши значения степеней и чисел, а это огромное количество памяти. Примерный мультипликатор около N * 192, то есть для N = 1 000 000 нам нужно больше 200мб. А дальше ещё больше. К этому моменту ещё не пришло понимание, почему так падает скорость с ростом массива степеней, и я продолжил искать узкие места вместе с профайлером.
Пока происходило обдумывание, я сделал все испробованные способы переключаемыми. Ибо мало ли что.
Одна из последних оптимизаций оказалось простой, но действенной. Скорость C++ версии уже перевалила за 400 000 000 переборов в секунду для 64бит ( при N = 500 ), 300 000 000 переборов для 128 бит и всего 24 000 000 для 128 бит из boost, и влиять на скорость уже могло практически всё. Если перевести в Гб, то чтение получается около 20Гб в секунду. Ну может я где-то ошибся…
Вдруг стало понятно, что пересчитывать всю сумму на каждом проходе не надо и можно ввести промежуточную. Вместо трёх сложений будет одно. А пересчитывать промежуточную только при увеличении старших разрядов. Для больших типов это, конечно, сильнее заметно.
mainType sum = 0U, baseSum = 0U;
baseSum = powers[ind1] + powers[ind2] + powers[ind3];
while(true)
{
sum = baseSum + powers[ind0];
...
// refresh without ind0
baseSum = powers[ind1] + powers[ind2] + powers[ind3];
}
Тут уже задача начинала надоедать, так как быстрее уже не получалось и я занялся C# версией. Всё перенёс туда. Нашёл уже готовый, написанный другим человеком UInt128 — примерно такой же простой, как и мой для C++. Ну и, конечно, скорость сильно подскочила. Разница оказалась меньше чем в два раза по сравнению с 64 битами. И это у меня ещё VS2013, то есть не roslyn (может он быстрее?).
А вот самописный map проигрывает по всем статьям Dictionary. Видимо проверки границ массивов дают о себе знать, ибо увеличение памяти ничего не даёт.
Дальше уже пошла совсем ерунда, даже была попытка оптимизировать сложение интринсиками, но чисто C++ версия оказалась самой быстрой. У меня почему-то не получилось заставить инлайниться ассемблерный код.
И всё же постоянно не отпускало чувство, что я что-то не вижу. Почему при росте массива всё начинает тормозить? При N = 1 000 000 производительность падает в 30 раз. Приходит в голову кэш процессора. Даже попробовал интринсик prefetch, результата — ноль. Пришла мысль кэшировать часть перебираемого массива, но при 1 000 000 значений (по 20 байт) как-то глупо выглядит. И тут начинает вырисовываться полная картина.
Так как числа у нас 4, есть 4 индекса, которые берут значения из таблицы. Таблица у нас постоянно возрастающих значений и сумма всех четырёх степеней у нас постоянно возрастающая (до переключения старших индексов). И разность степеней становится всё больше и больше.
25 это 32, а 35 это уже 243. А что если искать прямо в том же массиве просчитанных степеней обычным линейным поиском, сначала выставляя начальное значение на самый большой индекс и сохраняя индекс последнего найденного меньшего значения чем наша сумма (следующая будет больше) и использовать этот сохранённый индекс как начальную точку при следующем поиске, ведь значения не будут сильно меняться… Бинго!
Что в итоге?
uint32 lastRangeIndex = 0;
// линейный поиск в массиве степеней
inline uint32 findInRange(mainType fivePower, uint32 startIndex)
{
while (startIndex < N)
{
lastRangeIndex = startIndex;
if (powers[startIndex] > fivePower)
{
return 0;
}
if (powers[startIndex] == fivePower)
{
return startIndex;
}
++startIndex;
}
return 0;
}
...
// главный цикл поиска
baseSum = powers[ind1] + powers[ind2] + powers[ind3];
while (true)
{
sum = baseSum + powers[ind0];
foundVal = findInRange( sum, lastRangeIndex);
if (foundVal > 0)
{
// нашли!
}
// следующий
++ind0;
if (ind0 < N)
{
continue;
}
else
{
ind0 = ++ind1;
}
if (ind1 >= N)
{
ind0 = ind1 = ++ind2;
}
if (ind2 >= N)
{
ind0 = ind1 = ind2 = ++ind3;
}
if (ind3 >= N)
{
break;
}
// сброс индекса на начальное значение при изменении старших индексов
lastRangeIndex = 0x02;
if (ind1 > lastRangeIndex)
{
lastRangeIndex = ind1;
}
if (ind2 > lastRangeIndex)
{
lastRangeIndex = ind2;
}
if (ind3 > lastRangeIndex)
{
lastRangeIndex = ind3;
}
// refresh without ind0
baseSum = powers[ind1] + powers[ind2] + powers[ind3];
}
Скорость на маленьких значениях N немного уступает самописному map, но как только растёт N — скорость работы даже начинает расти! Ведь промежутки между степенями больших N растут чем дальше, тем больше и линейный поиск работает всё меньше! Сложность получается лучше O(1).
Вот вам и потеря времени. А всё почему? Не надо бросаться грудью на амбразуру, посиди — подумай. Как оказалось, самый быстрый алгоритм — это линейный поиск и никакие map/bitset не нужны. Но, безусловно, это очень интересный опыт.
Хабр любит исходники и они есть у меня. В коммитах можете даже посмотреть историю «борьбы». Там лежат обе версии и C++, и C#, в котором этот трюк, конечно, так же отлично работает. Проекты хоть и вложены один в другой, но, конечно, никак не связаны.
Исходники ужасны, в начале находятся дефайны, где можно задать основное значение (uint64, uint128, boost::uin128/decimal(для C#), библиотеку можно переключать std/boost (boost::unordered_map оказался быстрее std::unordered_map примерно на 10%). Так же выбирается алгоритм поиска (правда сейчас вижу, что предварительный фильтр для unordered_map в версии C++ не пережил правок, но он есть в коммитах и в C# версии) unordered_map, самописный bitset и range (последний вариант).
Вот такая вот сказка и мне урок. А может и ещё кому будет интересно. Ведь много каких значений ещё не нашли…

* к/ф Сказка о потерянном времени, 1964г.
Комментарии (117)

4e1
14.12.2016 16:31можно было бы использовать GMP вместо буста, я как-то сравнивал скорость boost::rational<boost::multiprecision> с рациональными в GMP (mpq) — буст проигрывал в ~20 раз
crea7or
14.12.2016 16:34Вряд ли можно сделать проще и быстрее чем два int64. GMP серьёзная вещь и больше подойдёт для серьёзных же задач, а тут таковой не стояло.
Outtruder
14.12.2016 22:14А для быстрого поиска надо было использовать хэш таблицы. 256 элементов по младшему байту числа на первом уровне, а далее списком/массивом или ещё один уровень.
crea7or
14.12.2016 23:25Так у меня хэш таблица и есть один из вариантов. Ну только она самодельная, так как выросла их простого фильтра. Я её в статье map'ом обозвал почему-то. Только любой не линейный поиск упрётся в вылет данных из кэша процессора.

AnROm
14.12.2016 16:39-2Гипотеза Эйлера утверждает, что для любого натурального числа n>2 никакую n-ю степень натурального числа нельзя представить в виде суммы (n-1) n-х степеней других натуральных чисел.
Потребовалось несколько раз перечитать гипотезу, чтобы понять, что требуется. По прошествию нескольких лет после института начинаешь отвыкать от подобных формулировок.
Круто, что вы взялись за оптимизацию решения задачи.

PapaBubaDiop
14.12.2016 17:09+13для k=6 гипотеза Эйлера остаётся открытой
давайте, парни, хватит биткойны майнить

raacer
14.12.2016 17:55-8Простите за оффтоп, но зачем Вы каждую фигурную скобку пишете на отдельной строке? Неудобно читать, код размазан по странице и не умещается в поле зрения. И стайл гайды вроде такого не рекомендуют.

stychos
14.12.2016 18:22+1Я бы убивал за египетские скобки. Автор, может, тоже из идеалистов.
raacer
14.12.2016 18:30Почему?
stychos
14.12.2016 18:31Привычка - страшная штука.
raacer
14.12.2016 18:41+2Убивать из-за привычки — это как-то уж сильно круто… :)
Попробуйте взглянуть на свою привычку под другим углом. Как минимум, просто чтобы убедиться, что другие стили (а также их носители) тоже имеют право на существование.
lastRangeIndex = startIndex; if (powers[startIndex] > fivePower) { return 0; } if (powers[startIndex] == fivePower) { return startIndex; } ++startIndex;
last_range_index = start_index; if (powers[start_index] > five_power): return 0 if (powers[start_index] == five_power): return start_index start_index += 1stychos
14.12.2016 18:43+2А как же стайл-гайды, которые заставляют в любых случаях у if обозначать зону видимости? :-)
raacer
14.12.2016 18:50А она обозначена (точнее, не зона видимости, а блок). Отступами. Это Python :) Просто, чтобы взглянуть с другой стороны, без всех этих скобочек.
stychos
14.12.2016 18:53-3С такой точки зрения ассемблер или брейнфак намного красивее - вообще никаких тебе дурацких отступов и скобочек. А уайтспейс - вообще бог красивости в языках.
raacer
14.12.2016 19:00+3Вы не видите блоков?
stychos
14.12.2016 19:08-6Я не люблю, когда мне язык навязывает стиль, как это сделано в питоне. Хотя язык неплохой-то - просто, может, я люблю выравнивать код примерно как кто-то из одного древнего ролика про сисадминов любит выравнивать ярлычки на рабочем столе?
Если конкретнее, то я не любитель стайл-гайд упарывания, и выравниваю свой код так, как лично мне кажется эстетичным и понятным, в основном всё-таки мне его потом читать. И для сиоидного кода для меня это однозначно не египетские скобки, и полное отсутствие скобок в простых ветвлениях с одним оператором тела, где достаточно отбить отступом как в питоне.
Как-то на хабре проскальзывала уже статья об ущербности всех этих стилей и необходимости разработки универсальных бинарных форматов хранения кода, когда уже каждый будет настраивать редактор в то отображение, которое ему нравится. Я думаю, в этом что-то есть.raacer
14.12.2016 19:22+2Дело не в языке, а в логических блоках, которые определенный стиль определенного языка позволил подчеркнуть.
То, что Вы не любите делать отступы во вложенных блоках, или любите, но Вас нервирует, что язык Вам не позволил бы сделать иначе — это, как бы, просто намекает, но не является предметом поднятого мною вопроса: оформление логических блоков кода.stychos
14.12.2016 19:25+2Значит, я не понимаю сути Вашего вопроса - логические блоки я вижу во всех примерах, не слепой, но мне по душе больше фигурные скобочки на отдельных строчках. Если Вас смутила фраза «я бы убивал за египетские скобки» - ну что ж, за отсутствие иронии я бы тоже убивал.
raacer
14.12.2016 19:30+1Не смутила. И все же, что-то такое есть в вашей настойчивости… Я бы предпочел остерегаться Вас ))
Вы просто взгляните еще раз на приведенный мною пример, и обратите внимание, как расставлены пустые строки. Вот в этом суть: разделение логических блоков пустыми строками для упрощения восприятия кода. Как вариант.stychos
14.12.2016 19:32Вы считаете, что если люди используют не/египетские скобки, то они не используют при этом пустых строк?
raacer
14.12.2016 19:35+1Нет, не считаю. Но в данном случае, я считаю, почти пустых строк и так слишком много, и добавление новых пустых строк ничего не выделит и ясности не внесет. Ниже — пояснение, что именно не так: https://habrahabr.ru/post/317588/#comment_9964324
stychos
14.12.2016 19:45Вот как раз это пояснение для меня осталось абсолютно непонятным.
Что мешает писать так:
// some previous code // other // bunch // of // logical // tied // code if (expr) return val; else return val2; if(expr || expr2 && expr3) { // some // big // bunch // of // code return val; } return default_val;
Ах да, стайл-гайды же рекомендуют единую точку выхода. Ну я и говорю, что не люблю их. Мне важнее самому понимать, как написан мой код - иногда я даже специально выношу для логической связки части кода в области видимости без языковых конструкций - именно для читабельности, например так:
{ // some // long // code // for // the // first // operation } { // second // operation // logically // separated }
И одиночно стоящие фигурные скобки на пустых строчках меня совершенно не напрягают, а скорее наоборот, помогают быстро ориентироваться в структуре.raacer
14.12.2016 19:48+1Ничто не мешает. Вы возьмите тот пример и покажите как надо писать.
stychos
14.12.2016 20:03Если Вы про код автора, то я уже написал, что в таких случаях (когда у условия только один оператор тела) пишу «по-питоновски», без фигурных скобок. И стандарты, и компиляторы, и здравый (для меня) смысл это позволяют. От Вашего примера на питоне мало чем отличаться будет. В случаях, когда скобки необходимо вводить, то предпочитаю их всё-же переносить.
Для ясности, кусок кода «что в итоге» автора в предпочитаемой мною стилистике я бы оформил как-то так:
uint32 last_range_index = 0; // линейный поиск в массиве степеней inline uint32 find_in_range(main_t five_power, uint32 start_index) { while(start_index < N) { last_range_index = start_index; if(pows[start_index] > five_power) return 0; if(pows[start_index] == five_power) return start_index; start_index++; } return 0; } ... // главный цикл поиска base_sum = pows[i1] + pows[i2] + pows[i3]; while(true) { sum = base_sum + pows[i0]; founded_val = find_in_range(sum, last_range_index); if(founded_val > 0); // нашли! // next ++i0; if(i0 < N) continue; i0 = ++i1; if(i1 >= N) i0 = i1 = ++i2; if(i2 >= N) i0 = i1 = i2 = ++i3; if(i3 >= N) break; // сброс индекса на начальное значение при изменении старших индексов lastRangeiex = 0x02; if(i1 > last_range_index) last_range_index = i1; if(i2 > last_range_index) last_range_index = i2; if(i3 > last_range_index) last_range_index = i3; // refresh without i0 base_sum = pows[i1] + pows[i2] + pows[i3]; }raacer
14.12.2016 20:07Ну так если это мало чем будет отличаться от моего примера, что Вы пытаетесь доказать?
3aicheg
16.12.2016 03:29+3А потом кто-то возьмёт и добавит:
else do_something_else(); return val2;
И пол-дня будет разбираться, что за хрень происходит, потому что никак не ожидал от себя подобной детсадовской ошибки.lgorSL
16.12.2016 14:37Форматирование кода в ide лёгким нажатием клавиш расставит всё по своим местам.
encyclopedist
14.12.2016 18:43Второе — на каком языке?
raacer
14.12.2016 18:49Второе — Python. Но если перевести в C++ или C# в египетском стиле — получится то же самое, только со скобочками в пустых строках.
Впрочем, я нисколько не призываю нарушать общепринятый стандарт C#. Но изначально ведь, на сколько я понял, код был написан на C++… ;)encyclopedist
14.12.2016 19:02+2Вы заключаете условия на питоне в скобки?
А стиль автора — это один из общепринятых стилей C++. Называется Allman. Он вполне распространённый, и был стандартным стилем Microsoft ещё задолго до появления C#. Его преимущество — сразу видно какая скобка какой соответствует, сканируя взглядом только начала строк.
stychos
14.12.2016 19:11This, не люблю египетские скобки именно из-за того, что при глубоких вложенностях там очень легко потерять какую-нибудь, и воткнуть в итоге не туда, куда надо. Классическое же выравнивание и без подсветки даёт понять, что во что вложено.
raacer
14.12.2016 19:18+1Заключаю условие в скобки только иногда по ошибке, когда переключаюсь с другого языка :)
Но речь не о скобках в условиях, а о логических блоках, и о том, как можно уничтожить их простыми фигурными скобками с новой строки. Например, вот эти строки написаны одним визуальным блоком (то есть вместе, не путайте с блоком ЯП):
lastRangeIndex = startIndex; if (powers[startIndex] > fivePower)
А следующий за ним return как бы логически отделен. Хотя первая строка имеет гораздо меньше отношения к этому условию (почти никакого вообще), чем блок, следующий за if.
Он вполне распространённый, и был стандартным стилем Microsoft
Спасибо, это всё объясняет. Тем не менее, стоит взглянуть на данную проблему под другим углом, хотя бы просто для расширения кругозора, и чтобы не хотелось никого убивать :)
trapwalker
16.12.2016 02:54-1Но раз уж мы убрали смертную казнь за скобочки, я предлагаю просто подраться по поводу этих мерзких ненужных круглых скобок в питоне в условии. Спорить о гайдлайнах и тут же нарушать pep8… Хотя возможно я и не прав насчет pep8.
— Папа, а что это тут все дяди с синяками и некоторые убитые?
— Это хабр, сынок.
safinaskar
14.12.2016 21:56Стиль без фигурных скобок опасен. Именно из него произошел apple goto fail bug, ищите в инете
crea7or
14.12.2016 18:50+1Есть разные правила и именно это мне помогает быстрее понять код. Можно предположить, что границы объектов быстро определяются зрительными отделами и дальше разбирается код внутри уже отделённый чёткими границами(скобками). У других может быть по другому — вариативность устройства мозга огромна. Кому-то и одной скобки на новой строке в конце хватает.

Fil
14.12.2016 21:37+3Когда я перешел на новую работу, мне пришлось переучиваться и помещать скобку на новой отдельной строке. И теперь считаю, что так лучше.
1. Открывающая и закрывающая скобки расположены на одном уровне. Это довольно естественно. В GUI, перейдя курсором на закрывающую скобку, легче найти подсвеченную открывающую и глазами визуально выделить блок.
2. Кода влезает меньше, но он не такой плотный, опять же легче ориентироваться в нем. И меньшее количество умещенного кода на экране стимулирует разбивать большие функции.
3aicheg
15.12.2016 04:48+3А что, кто-то ещё пишет на С++, не перенося фигурную скобку на новую строку? Глянул щас сорцы нескольких опенсорсных библиотек (boost, OpenCV, VTK, OptiX и т. п.) — везде переносят.
Стайлгайдов, вообще-то, >1, и рекомендации порой сильно отличаются. Из широко известной в узких кругах книги про верёвку и ногу:
Выравнивайте скобки вертикально по левой границе.
Иногда поиск отсутствующей фигурной скобки превращается в крупную проблему. Если вы вынесете скобки туда, где их хорошо видно, то их отсутствие будет сразу же заметно:
while ( some_condition ) { // внутренний блок }
Я в самом деле не люблю так называемый стиль Кэрнигана и Ричи:
if (condition) { code(); }else{ more_code(); }
Здесь не только трудно проверить скобки на парность, но и отсутствие зрительного разделения за счет строк, содержащих лишь открытые скобки, ведет к ухудшению читаемости.
Честно, вот не понимаю, как это уродство без переноса скобки вообще могло появиться на свет — единственная теория, что мало было строк на первых терминалах и их пытались экономить всеми силами. Но вот как оно кому-то может нравиться сейчас, когда нет, вроде, никаких проблем уже давно с количеством строк на мониторе??..borisko
15.12.2016 11:45+1Честно, вот не понимаю, как это уродство без переноса скобки вообще могло появиться на свет — единственная теория, что мало было строк на первых терминалах и их пытались экономить всеми силами. Но вот как оно кому-то может нравиться сейчас, когда нет, вроде, никаких проблем уже давно с количеством строк на мониторе??..
Человек хорошо концентрируется на том коде, который у него перед глазами без использования прокрутки. Поэтому сохранять вертикальное место важно.3aicheg
15.12.2016 14:06Почему тогда они закрывающую всегда переносят? Тоже оставить на той же строке, ещё больше можно сэкономить.
raacer
15.12.2016 14:15-1Потому что она мешает редактировать тело блока: приходится постоянно двигать её при добавлении/удалении строк в конце блока. К тому же, можно легко ошибиться и оставить её где-то в середине блока.
zuborg
15.12.2016 14:21Я пользуюсь K&R style, и часто после закрывающей скобки ставлю дополнительную пустую строку — мне так проще группировать код по функциональности. Отдельная открывающая скобка занимает столько же места, сколько пустая строка — и для меня выглядит, что if() стоит одинаково отдельно от кода, что ниже, и от кода, что выше, т.е. строка с if() как бы сама по себе. Дело привычки, наверное, но мне ломает встроенный парсер ).
В любом случае, отступы прекрасно помогают (опять же, лично для меня) выделять уровни кода, дополнительная строка с открывающей скобкой мне ни к чему от слова «вообще».
masai
15.12.2016 17:04+1Почему тогда они закрывающую всегда переносят? Тоже оставить на той же строке, ещё больше можно сэкономить.
Вы в полушаге от синтаксиса Python. :)
3aicheg
15.12.2016 17:45Вот только не надо сюда за уши притягивать Питон — в С++ отступы не несут никакой семантической нагрузки, как бы упоротые адепты египетских скобок не пытались убедить в этом всех подряд, и себя, в том числе :) Поэтому «да какая разница, где скобки, мы всё разобьём на блоки отступами, и будет щасте» — не аргумент, рано или поздно вы облажаетесь с расставлением отступов, и компилятор вам об этом ни слова не скажет.
masai
15.12.2016 18:31+1Вообще, это шутка была. А если серьезно, то я довольно много пишу на Python и с ошибками в отступах если и сталкивался, то не помню когда. Точно так же можно ошибиться с расстановкой фигурных скобок. Для решения таких проблем как раз и придуманы тесты. Которые, кстати, стоит писать независимо от языка.
raacer
15.12.2016 13:52Стайлгайдов, вообще-то, >1, и рекомендации порой сильно отличаются.
Не спорю. Мне просто не удалось сразу таких нагуглить. Всё, что я нашел навскидку — по C++, Java, JS — всё предлагало оставлять скобку на той же строке. Видимо, не там искал. Наверное, надо было сразу на MSDN идти.
Честно, вот не понимаю, как это уродство без переноса скобки вообще могло появиться на свет
Очень просто. Есть люди, которым проще воспринимать код со скобками на отдельной строке, на что выше уже обратил внимание crea7or. А есть люди, которым проще воспринимать плотный код, разбитый на логические блоки. Например такой, как antonkrechetov показал ниже, или как stychos показал выше (там могут быть проблемы из-за отсутствия скобок, я лично так не пишу, но это другая тема). И, представьте себе, есть более одного способа не страдать из-за того, что открывающая и закрывающая скобки не находятся в одной колонке — например, не писать слишком длинный код и аккуратно расставлять отступы.
Открыл первый попавшийся из перечисленных Вами оупенсорсных исходников, и сразу же обнаружил там функцию на три экрана. Инлайн-функции, видимо, отменили. Да, если писать в таком стиле, то определенно стоит выносить скобки на отдельные строки, совершенно согласен.zuborg
15.12.2016 14:11+1Не спорю. Мне просто не удалось сразу таких нагуглить
В Go Вы обязаны использовать camel style (K&R) — иначе код не скомпилируется вообще (компилятор считает, что каждая строка заканчивается ';', а компиляция конструкций вида if(..); {… } не предусмотрена). Многие из-за этого сильно ругают Go, кстати ;)raacer
15.12.2016 14:21Супер! Только я писал, что не удалось нагуглить гайд со скобками на отдельных строках, а Вы указали на противоположный стиль, вшитый в язык.
И, кстати, «camel style» — этоПроИмена, а не скобки, на сколько я знаю.
raacer
15.12.2016 14:38Кому интересно — подробный ответ на мой вопрос есть в статье на Вики, в виде описания восьми (Карл!) способов расставить скобочки. Там же имеется подробное обоснование стиля Оллмана.
https://en.wikipedia.org/wiki/Indent_style
Пойду напишу что-нибудь на питоне для успокоения… :)
darkslave
15.12.2016 15:39+1По-моему, уродство с переносом скобок – это архаизм.
Во времена, когда отсутствовали IDE, перенос скобок помог бы быстро отследить незакрытые блоки и исправить ошибку. Но сейчас же, IDE с валидатором кода уведомит программиста, где он опечатался.
Перенос скобки, лично для меня, прерывает поток чтения и интерпретации кода.
То, что майкрософт ввела перенос скобок в стайл гайд целого языка, это вообще не показатель и не аргумент.
kdekaluga
20.12.2016 17:25Лично у меня вызывает больше понимания именно такой стиль, когда открывающаяся скобка занимает свою отдельную строку, но тот же самый гугл, например, считает, что надо иначе:
https://google.github.io/styleguide/cppguide.html
Однако, раньше у них было строгое требование — «помещайте открывающуюся скобку в конце строки и никак иначе», сейчас же уже менее строго — «сами решайте, но проект лучше читаем, когда в нем единый стиль» (при этом весь код примеров форматирован K&R).

TheCalligrapher
16.12.2016 05:52-1В коде, написанном на С- и С++-подобных языках всенепременнейше рекомендуется писать открывающую фигурную скобку на отдельной строчке: это создает визуальное вертикальное разделение между предшествующим такой скобке кодом (зачастую: заголовок цикла,
ifс условием и т.п.) и собственно телом compound statement. Наличие такого вертикального разделения астрономически повышает читаемость кода.
Вопрос "вертикального размазывания кода" уже давно не актуален. Код должен содержать огромное количество грамотно расставленного вертикального спейсинга. Преимущества в удобочитаемости кода легко затмевают потери в количестве умещающихся на экране строк.
За "египетские скобки" в современном коде надо бить по рукам так же, как и за явное приведение результата malloc в C.


vitalick27
14.12.2016 17:56+2Интересная статья!
PS: Как же легко программисту бросить вызов интересной задачей)
PSS: Понимаю что извращение, но под рукой есть только оракл, запустил на нем вычисления)zuborg
14.12.2016 18:21+1crea7or
14.12.2016 18:39Вот это класс — шикарный проект!
jknight
15.12.2016 10:03Малость оффтоп, но… Как-то в универе устроили на этом сайте конкурс — кто больше всех задач за неделю нарешает, поедет в любую мат/физ/cs школу на выбор. Поехал участник, нарешавший 81 задачу. У меня 69 было. Вот вроде и давно было, а чувства к этому проекту тееееплые..:)
raacer
14.12.2016 18:17+1А не могли бы Вы выложить результаты тестов для каких-то эталонных значений? Например, сколько будет затрачено времени, чтобы найти следующие равенства:
275 + 845 + 1105 + 1335 = 1445
1277 + 2587 + 2667 + 4137 + 4307 + 4397 + 5257 = 5687crea7or
14.12.2016 18:38Для N=150, UInt128, boost и 27 + 84 + 110 + 133 = 144 (в пятой)
SEARCHRANGE: 0.068 сек. (210 000 i/ms)
SEARCHMAPUSE: 0.141 сек. (78 000 i/ms)
SEARCHBITSETVECTOR: 0.047 сек ( 277 000 i/ms)
Там считается и показывается скорость перебора: i/ms это количество переборов за миллисекунду — это более правильный замер.
N = 86000, UInt128, boost скорость будет такая:
SEARCHRANGE: 250 000 i/ms
SEARCHMAPUSE: 33 000 i/ms
SEARCHBITSETVECTOR: 81 000 i/ms
N = 1000000, UInt128, boost скорость будет такая:
SEARCHRANGE: 330 000 i/ms
SEARCHMAPUSE: 10 000 i/ms
SEARCHBITSETVECTOR: 16 500 i/ms
До полного подсчёта остальных я так и не дошёл.raacer
14.12.2016 18:46Там считается и показывается скорость перебора: i/ms это количество переборов за миллисекунду — это более правильный замер.
Вам важна скорость молотилки, или скорость получения результата? Если первое — то да, более правильный. Мне же интересно, за какое время ваша программа нашла результат, а не как быстро она перебирала числа.
Я правильно понял, что в седьмой степени ничего найти не удалось?encyclopedist
14.12.2016 19:06+1за какое время ваша программа нашла результат
Это плохая метрика для этой задачи. Потому что в такой метрике победит программа которая сразу проверит именно это решение.
raacer
14.12.2016 19:26+1Плохая, но для начала пойдёт. Даже такая плохая мне лично кажется интереснее, чем скорость перебора. Автор сосредоточился на скорости выполнения цикла, мне же лично интересен алгоритм, способ найти те числа, которые никто другой еще не нашел. Ведь именно в этом был изначальный вопрос: «по поиску еще таких совпадений»

Deosis
16.12.2016 11:41На одном из соревнований по спортивному программированию была задача: определить сколько натуральных чисел меньше введенного (ввод ограничен миллиардом) удовлетворяют некоторому условию.
Проблема в том, что честный подсчет не укладывается в лимит времени.
Предполагаемый способ решения: подсчитать список таких чисел заранее (их оказалось немного), забить в табличку и отправить на проверку вариант, который ищет по табличке.
ПС. Сколько потеряно времени на обсуждение скобочек.
zuborg
16.12.2016 21:07До полного подсчёта остальных я так и не дошёл
В смысле, не дошли до следующих совпадений, таких как
54^5+168^5+220^5+266^5=288^5
?crea7or
16.12.2016 21:29+1Это не следующее значение, это то же самое: 27^5 + 84^5 + 110^5 + 133^5 — только в два раза больше.
Следующее это: 55^5 + 3183^5 + 28969^5 + 85282^5 = 85359^5.
knotri
14.12.2016 18:34Всброшу интересную задачу. (Сам еще не решил)
Есть бесконечное поле в клеточку — между точками клеточек резистор в 1 Ом.
Какое будет сопротивление между точками
A(0,0) и B(2,1)galaxy
14.12.2016 20:15+1Ответ
raacer
14.12.2016 20:37+1Как и следовало ожидать — формулы с интегралами. При чем тут программирование? :) Это же математическая, а не алгоритмическая задача.
Effolkronium
14.12.2016 20:36-1Интересно было бы переписать это на компайл-тайм выполнения на С++ с помощью constexpr. Тогда в рантайме оно бы просто выводило результат
Effolkronium
14.12.2016 20:57+1Код оставляет желать лучшего. Гора магических чисел и непонятных переменных
crea7or
14.12.2016 21:02Там только буфер для самописного map'a отдельно определяется — чтобы можно было подстроить/посмотреть.
crea7or
14.12.2016 21:00+2Кому интересно, вот тут ещё набор идей по улучшению перебора чтобы не смотреть всё подряд.
lgorSL
15.12.2016 01:44+1Странно, что Вы это не использовали. Можно было бы использовать инты и для больших значений — просто забить на переполнение, а всё подошедшее проверять честным расчётом на uint128. Вероятность случайных совпадений очень мала, поэтому "честные" проверки не займут много времени.
raacer
15.12.2016 02:22Я вот сделал по такому принципу, только на питоне. У меня код работает в 30-200 раз медленнее на малых числах, чем у товарища crea7or, но даже не в этом дело. Всё упирается в сложность алгоритма ( O(N^k) ?). Достаточно увеличить степень на единицу, чтобы все оптимизации пошли прахом. Тут бы заменить полный перебор каким-то более умным алгоритмом — было бы гораздо интереснее.
crea7or
15.12.2016 03:41А я его только -только нашёл. Вот тут самый быстрый алгоритм (c++ second version), но до N=10000 ему уже надо 6гб памяти(он там по double переполняется находя неправильно решение 2615 и его ещё надо править, я им там написал про это как раз).

antonkrechetov
15.12.2016 08:44+4Глянул вариант от 2Alias и решил попробовать свои силы — реализовать алгоритм для тех же 250 чисел с теми же отсечениями.
Получилось вот что (C++11)#include <iostream> #include <algorithm> #include <chrono> using std::cout; using std::endl; using work_num = long long; using index_num = unsigned int; constexpr index_num elements_count = 250; inline work_num pow5(index_num n) { const work_num pow2 = n * n; return pow2 * pow2 * n; } int main() { auto start = std::chrono::steady_clock::now(); work_num powers[elements_count]; for (index_num i = 0; i < elements_count; ++i) { powers[i] = pow5(i); } // a^5 + b^5 + c^5 + d^5 = e^5 for (index_num a = 1; a < elements_count; ++a) { for (index_num b = a + 1; b < elements_count; ++b) { for (index_num c = b + 1; c < elements_count; ++c) { for (index_num d = c + 1; d < elements_count; ++d) { work_num sum = powers[a] + powers[b] + powers[c] + powers[d]; if (std::binary_search(powers, powers + elements_count, sum)) { work_num* e_ptr = std::lower_bound(powers, powers + elements_count, sum); auto end = std::chrono::steady_clock::now(); cout << a << " " << b << " " << c << " " << d << " " << (e_ptr - powers) << endl; cout << "Time: " << std::chrono::duration<double, std::milli>(end - start).count() << "ms" << endl; exit(0); } } } } } auto end = std::chrono::steady_clock::now(); cout << "Time: " << std::chrono::duration<double, std::milli>(end - start).count() << "ms" << endl; }SKolotienko
15.12.2016 15:36+1Всё ждал в конце этой захватывающей истории, «А потом я заметил, что работаю под Debug и переключился на Release» :)
ProgrammerAlias
21.12.2016 01:49+1Я 2Alias. Для значений не влезающих в 64 бита, можно искать решения в 64-х битном беззнаковом типе unsigned long long (какбы по модулю 2^64) а когда решение по модулю 2^64 найдено, проверять действительно ли это решение.
Ещё не стоит забывать что это алгоритм почтичто «в лоб», мне думается, что можно придумать гораздо более быстрые варианты.
Когда я терял своё время с этой задачей, мне думались варианты с отсечениями решений по разным модулям. Часть чисел просто не может быть пятой степенью по определённом модулю. т.е. для некоторого числа M и некоторых Y, 0 < Y < M, не существует такого X, что X^5 % M == Y. Для решения уравнения a^5+b^5+c^5+d^4=e^5, можно эффективно перебирарать e, затем a, b, c, а уже d искать в хеш-таблице.ProgrammerAlias
21.12.2016 02:06Как-то я неправильно воспроизвёл идею оптимизации с модулями, или может я её и тогда не додумал. Но написал как-то бред, с температурой сижу.
crea7or
21.12.2016 03:38на rosettacode как раз по модулю 30 и отсекают всё «ненужное». 11 секунд на перебор до N=1000. И, например, дальше отсекать нечётные суммы уже практически не имеет смысла. Выигрыш около 0.2 сек.
zuborg
21.12.2016 13:405-я степень по модулю 30 может иметь все возможные остатки — от 0 до 29 включительно. Проверкой по модулю 30 нельзя отсечь ни числа, не являющимися суммой двух пятых степеней (сумма двух пятых степеней может иметь любой остаток по модулю 30), так и ни отсечь одно из слагаемых этой суммы (например, большее число может иметь тоже любой остаток по модулю 30, независимо от значения остатка суммы).
crea7or
21.12.2016 16:18По модулю 30 двигается pivot, так как число и его степень по модулю 30 равны. Получается в ~30 раз меньше проверок.
Вот их код:
// go straight to the first appropriate x3, mod 30 if (int err30 = (x0 + x1 + x2 + x3 - rs) % 30) x3 += 30 - err30; if (x3 >= x2) break; auto sum = s2 + pow5[x3];
rs это pivot в массиве степеней.zuborg
21.12.2016 18:24Что-то я не понял этот код. Они ссылаются на код С, но в С трюк mod-30 используется по другому — там перебирается четыре числа, и проверка 5-го происходит с фильтрацией по остатку mod 30.
А в коде C++ перебираются 3 числа (x0, x1, x2) и затем почему-то делается сдвиг x3 для коррекции остатка, хотя без фиксации пятого числа это не имеет смысла — какой бы остаток mod 30 не был у x3 — всегда найдется 5-я степень с таким же остатком mod 30, как и суммы x0^5+x1^5+x2^5+x3^5, без этой коррекции.
И в чем смысл этого rs, мне совсем не понятно.crea7or
21.12.2016 19:16rs это pivot в массиве степеней. Так как мы перебираем только вверх, то и искать в массиве степеней надо только вверх. То есть не надо каждый цикл начинать сначала и бегать с нуля или ещё каким способом чтобы дойти до индекса суммы. В коде на С перебираются уникальные суммы, а в коде на C++ перебираются уникальные сочетания.
В C, например, при 1 2 2 1 и 1 1 2 2 — не появляются в переборе ( 1 2 2 1 будет пропущен), сумма слагаемых ведь от перестановки не меняется (не появится и 1 1 2 2 — так как начинается с 1 2 3 4). А С++ код не будет проверять и 1 2 2 1 — там не появляется одинаковых чисел совсем. То есть 1 2 3 4, 1 2 3 5, 1 2 4 5. 1 3 4 5 и т.д. Из за этого там количество циклов катастрофически меньше. Но мне не очень понятно почему они так сделали. В принципе встречаются равенства со степенями где есть одинаковые слагаемые.
Добавление rs по модулю 30 двигает этот rs к позиции на которой может быть степень числа. То есть он прыгает только по значениям которые могут быть для такой суммы. Суть примерно как у проверки на чётность. Из проверки исключаются все заранее невалидные.zuborg
21.12.2016 21:54Пропуск равных слагаемых уменьшит кол-во итераций, но никак не катастрофически.
В коде C++ есть стока
if (pow5[rs] == sum)
Т.е. rs используется для поиска e в уравнении a^5+b^5+c^5+d^5=e^5
Но без фиксации d не получится зафиксировать остаток mod30 для е, и наоборот — пока мы не знаем остаток mod30 для e — мы не знаем какой будет остаток mod30 для d. Мне кажется, что C++ код неправильно использует остаток mod30.crea7or
22.12.2016 00:40Я так понимаю, что вы про x3 пишете, но в том примере он уже сложен в общую сумму: auto sum = s2 + pow5[x3];
zuborg
22.12.2016 12:39Верно, а дальше rs инкрементируется пока rs^5 не достигнет суммы (или превысит её).
Моё замечание касается вставки
if (int err30 = (x0 + x1 + x2 + x3 - rs) % 30) x3 += 30 - err30;
до того, как начнется подбираться rs — он участвует в вычислении err30, но значение rs в этот момент не зависит от того, какой окажется итоговая сумма.
Deosis
21.12.2016 07:18Дельное замечание. Самая простая оптимизация: считать с шагом 2, так как возведение в степень не меняет чётность. Это позволит ускорить перебор в 2 раза. Что гораздо лучше, чем
(boost::unordered_map оказался быстрее std::unordered_map примерно на 10%)
zuborg
21.12.2016 13:31Допустим, Вы рассматриваете число, потенциально являющееся суммой двух пятых степеней. Если Вы будете перебирать большее из чисел с шагом два (и проверять разницу на предмет того, является ли она пятой степенью), то можете пропустить решение.
crea7or
21.12.2016 16:35Проверка чётности возможна только внутри последнего цикла, когда уже посчитана проверяемая сумма. А там чем меньше операций — тем быстрее, ибо остаётся только сравнить. А тут ещё одно сравнение появляется.


denismaster
Вероятно, у вас опечатка, ибо в C# есть Dictionary, а не Directory)
А статья довольно интересная)
crea7or
Точно! Писал уже ночью и напутал.