

На хабре уже писали про Docker swarm mode (режим роя), который является новой фичей версии 1.12. Данная опция внесла небольшую путаницу в головы тех, кто знаком с отдельно стоящей реализацией Docker Swarm имевшей распространение ранее и не отличавшейся удобством настройки и использования. Однако, после добавления Swarm в коробку с Docker все стало намного проще, очевиднее и функциональнее.
Подробнее о том, как устроен новый кластер Docker контейнеров с точки зрения пользователя, а также о простом и удобном способе разворачивания сервисов Docker на произвольной инфраструктуре далее под катом.
Для начала, как я и обещал в предыдущей статье, с небольшой задержкой, но все же выпущен релиз Fabricio с поддержкой сервисов Docker. При этом по-прежнему сохраняется возможность работать с отдельными контейнерами, плюс, остались неизменными интерфейс пользователя и разработчика конфигурации, что значительно упрощает переход от конфигураций, основанных на отдельных контейнерах к отказоустойчивым и горизонтально масштабируемым сервисам.
Активация Docker swarm mode
В режиме swarm все ноды делятся на два типа: manager и worker. При этом полноценный кластер может обходиться без рабочих нод вообще, то есть менеджеры по-умолчанию являются также и рабочими.
Среди менеджеров всегда присутствует один, который на данный момент является лидером кластера. Все управляющие команды, которые выполняются на других менеджерах автоматически перенаправляются на него.
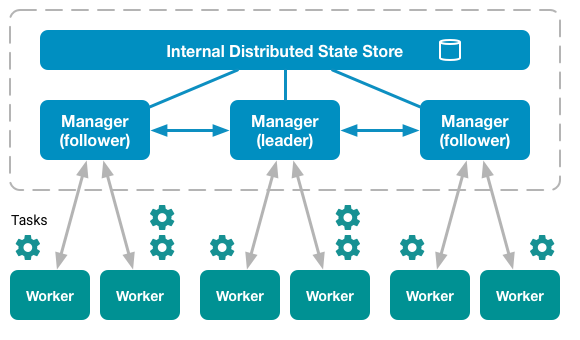
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
6pbqkymsgtnahkqyyw7pccwpz * docker-1 Ready Active Leader
avjehhultkslrlcrevaqc4h5f docker-2 Ready Active Reachable
cg1maoa11ep7h14f2xciwylf3 docker-3 Ready Active Reachable
Для включения режима swarm достаточно выбрать хост, который будет начальным лидером в будущем кластере, и выполнить на нем всего одну команду:
docker swarm init
После того, как «рой» инициализирован, он уже готов для запуска на нем любого количества сервисов. Правда, состояние такого кластера будет неконсистентным (консистентное состояние достигается при количестве менеджеров не менее 3). И конечно ни о каком масштабировании и отказоустойчивости в этом случае речи также быть не может. Для этого к кластеру нужно подключить еще хотя бы две управляющие ноды. Узнать о том, как это сделать, можно выполнив на лидере следующие команды:
$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join --token SWMTKN-1-1yptom678kg6hryfufjyv1ky7xc4tx73m8uu2vmzm1rb82fsas-c12oncaqr8heox5ed2jj50kjf 172.28.128.3:2377
$ docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-1yptom678kg6hryfufjyv1ky7xc4tx73m8uu2vmzm1rb82fsas-511vapm98iiz516oyf8j00alv 172.28.128.3:2377
Добавлять и удалять ноды можно в любой момент жизни кластера — это никаким серьезным образом не влияет на его работоспособность.
Создание сервиса
Создание сервиса в Docker принципиально не отличается от создания контейнера:
docker service create --name nginx --publish 8080:80 --replicas 2 nginx:stable-alpine
Отличия, как правило, заключаются в различном наборе опций. Например, у сервиса нет опции --volume, но есть опция --mount — эти опции позволяют подключать к контейнерам локальные ресурсы нод, но делают это по-разному.
Обновление сервиса
Здесь начинается самое большое отличие работы контейнеров от работы кластера контейнеров (сервиса). Обычно, чтобы обновить одиночный контейнер, приходится останавливать текущий и запускать новый. Это приводит хоть и к незначительному, но существующему времени простоя вашего сервиса (если вы не озаботились о том, чтобы обрабатывать такие ситуации при помощи других инструментов).
При использовании сервиса с количеством реплик не менее 2 простоя сервиса в большинстве случаев не присходит. Это достигается за счет того, что Docker обновляет контейнеры сервиса по очереди. То есть в один и тот же момент времени всегда есть хотя бы один работающий контейнер, который может обслужить запрос пользователя.
Для обновления (в том числе добавления и удаления) свойств сервиса, которые могут иметь несколько значений (например, --publish или --label), Docker предлагает использовать специальные опции, оканчивающиеся суффиксами -add и -rm:
# добавление в сервис новой метки
docker service update --label-add foo=bar nginx
Удаление некоторых опций, однако, менее тривиально и часто зависит от самой опции:
# метки удаляются по имени
docker service update --label-rm foo nginx
# порты удаляются по значению порта назначения (target port)
docker service update --publish-rm 80 nginx
Подробности о каждой опции можно узнать в описании команды docker service update.
Масштабирование и балансировка
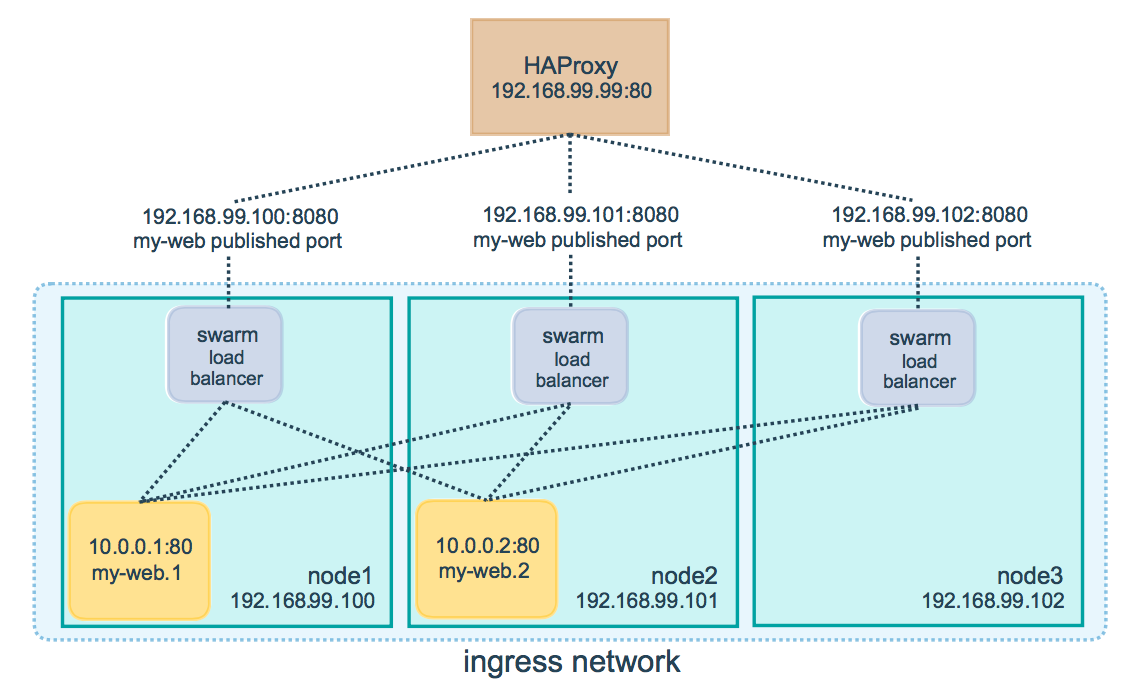
Для распределения запросов между имеющимися нодами Docker используется схема называемая ingress load balacing. Суть этого механизма заключается в том, что на какую бы из нод не пришел запрос пользователя, он сначала пройдет через внутренний механизм балансировки, а затем будет перенаправлен на ту ноду, которая в данный момент может обслужить такой запрос. То есть, любая нода способна обработать запрос к любому из сервисов кластера.
Масштабирование сервиса Docker достигается за счет указания необходимого количества реплик. В тот момент, когда вам необходимо увеличить (или уменьшить) количество нод, обслуживающих запросы от клиента, вы просто обновляете свойства сервиса с указанием нужного значения опции --replicas:
docker service update --replicas 3 nginx
В этом случае надо не забыть предварительно убедиться, что количество доступных нод не меньше, чем количество реплик, которые вы хотите использовать. Хотя ничего страшного не произойдет даже если нод меньше, чем реплик — просто некоторые ноды запустят у себя более одного контейнера одного и того же сервиса (в противном случае Docker будет стараться запускать реплики одного сервиса на разных нодах).
Отказоустойчивость

Отказоустойчивость сервиса гарантируется самим Docker. Это достигается в том числе за счет того, что в кластере могут одновременно работать несколько управляющих нод, которые могут в любой момент заменить вышедшего из строя лидера. Если говорить более подробно, то используется так называемый алгоритм поддержания распределенного консенсуса — Raft. Интересующимся рекомендую посмотреть эту замечательную визуальную демонстрацию: Raft в работе.
Автоматический деплой
Деплой новой версии приложения на боевые сервера всегда сопровождается риском того, что что-то пойдет не так. Именно поэтому считается плохой приметой выкатывать новую версию приложения перед выходными и праздниками. Причем, перед длительными праздниками, вроде новогодних каникул, любые изменения на боевой инфраструктуре прекращаются за неделю а то и за две до их начала.
Несмотря на то, что сервисы Docker предлагают вполне надежный способ запуска и обновления приложения, довольно часто быстрый откат к предыдущей версии затруднен по той или иной причине, что может служить причиной недоступности вашего сервиса пользователям в течении многих часов.
Самый надежный способ избежать проблем при обновлении приложения — автоматизация и тестирование. Именно для этого разрабатываются системы автоматического деплоя. Важной частью таких систем, как правило, является возможность быстрого обновления и отката к предыдущей версии на любой выбранной инфраструктуре.
Fabricio
Большинство инструментов для автоматизации деплоя предлагают описывать конфигурацию при помощи популярных языков разметки вроде XML или YAML. Некоторые идут дальше и разрабатывают свой собственный язык описания таких конфигураций (например, HCL или Puppet language). Я же не вижу необходимости идти ни по одному из этих путей по следующим причинам:
- XML/YAML никогда не сравнятся по возможностям расширения и использования с полноценными языками программирования, а стремление упростить конфигурирование через использование упрощенной разметки часто наоборот, лишь все усложняет Плюс, мало кто из программистов захочет программировать на XML/YAML, а ведь конфигурирование — это и есть частный случай программирования.
- Разработка своего собственного языка программирования — чрезвычайно сложный и утомительный процесс, чаше всего нестоящий затрачиваемых на него усилий.
Поэтому Fabricio для описания конфигураций использует обычный Python и часть надежных и проверенных временем библиотек (среди них небезизвестный Fabric).
Конечно, многие могут возразить по этому поводу, что мол не все разработчики и DevOps знают Python. Ну, во-первых, Python (так же как и Bash) входит в джентльменский набор скриптовых языков, которые должен знать каждый уважающий себя DevOps (ну или почти каждый). А во-вторых, как это не парадоксально, знать Python практически необязательно. В подтверждение своих слов привожу пример конфигурации сервиса основанного на Django для Fabricio:
from fabricio import tasks
from fabricio.apps.python.django import DjangoService
django = tasks.DockerTasks(
service=DjangoService(
name="django",
image="project/django",
options={
"publish": "8080:80",
"env": "DJANGO_SETTINGS_MODULE=my_settings",
"replicas": 3,
},
),
hosts=["user@manager1", "user@manager2", "user@manager3"],
)
Согласитесь, что этот пример не сложнее, чем аналогичное описание на YAML. Человек, владеющий хотя бы одним языком программирования, разберется в данном конфиге без особых проблем.
Но довольно лирики.
Процесс деплоя
Схематически процесс деплоя сервиса при помощи Fabricio выглядит так, как представлено на рисунке ниже (после выполнения команды fab django для описанного выше конфига):

Рассмотрим каждый пункт по порядку. Для начала, сразу хочу заметить, что представленная схема актуальна при включенном режиме параллельного выполнения (с указанной опцией --parallel). Отличие последовательного режима только в том, что все действия в нем выполняются строго последовательно.
Сразу после запуска команды деплоя последовательно начинают выполняться следующие шаги:
- pull, одновременно на всех нодах запускается процесс скачивания нового образа Docker. Замечу, что в конфигурации достаточно указать только адреса управляющих нод (менеджеров), при этом даже необязательно перечислять всех имеющихся менеджеров — неуказанные ноды будут автоматически обновлены самим Docker. Хотя ничто не мешает указать в конфигурации в том числе и воркеров (в некоторых случаях это бывает необходимо, например, при использовании SSH туннеля).
- migrate, следующий шаг — применение миграций. Важно, чтобы этот шаг одновременно выполнялся только на одной из текущих нод, поэтому Fabricio в этом случае использует специальный механизм, гарантирующий, что процесс миграции будет запущен только на одной ноде и выполнится только один раз.
- update, так как для обновления всех контейнеров сервиса команду update достаточно выполнить только один раз, то Fabricio на этом шаге также следит за тем, чтобы она не была выполнена дважды.
Каждую команду (pull, migrate, update) в случае необходимости можно выполнить отдельно. В процесс деплоя также можно включить дополнительные шаги (prepare, push, backup) как описано в этой более ранней обзорной статье про Fabricio.
Все команды Fabricio (кроме backup и restore) являются идемпотентными, то есть безопасными при повторном выполнении с теми же самыми параметрами.
$ fab --parallel nginx
[vagrant@172.28.128.3] Executing task 'nginx.pull'
[vagrant@172.28.128.4] Executing task 'nginx.pull'
[vagrant@172.28.128.5] Executing task 'nginx.pull'
[vagrant@172.28.128.5] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.4] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.3] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.3] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.3] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.3] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.3] out:
[vagrant@172.28.128.4] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.4] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.4] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.4] out:
[vagrant@172.28.128.5] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.5] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.5] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.5] out:
[vagrant@172.28.128.3] Executing task 'nginx.migrate'
[vagrant@172.28.128.4] Executing task 'nginx.migrate'
[vagrant@172.28.128.5] Executing task 'nginx.migrate'
[vagrant@172.28.128.5] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.4] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.3] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.3] Executing task 'nginx.update'
[vagrant@172.28.128.4] Executing task 'nginx.update'
[vagrant@172.28.128.5] Executing task 'nginx.update'
[vagrant@172.28.128.5] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.4] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.3] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.3] run: docker inspect --type container nginx_current
[vagrant@172.28.128.3] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.4] run: docker inspect --type container nginx_current
[vagrant@172.28.128.3] run: docker service inspect nginx
[vagrant@172.28.128.4] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.3] No changes detected, update skipped.
[vagrant@172.28.128.4] No changes detected, update skipped.
[vagrant@172.28.128.5] run: docker inspect --type container nginx_current
[vagrant@172.28.128.5] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.5] No changes detected, update skipped.
Done.
Disconnecting from vagrant@127.0.0.1:2222... done.
Disconnecting from vagrant@127.0.0.1:2200... done.
Disconnecting from vagrant@127.0.0.1:2201... done.
$ fab nginx
[vagrant@172.28.128.3] Executing task 'nginx.pull'
[vagrant@172.28.128.3] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.3] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.3] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.3] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.3] out:
[vagrant@172.28.128.4] Executing task 'nginx.pull'
[vagrant@172.28.128.4] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.4] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.4] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.4] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.4] out:
[vagrant@172.28.128.5] Executing task 'nginx.pull'
[vagrant@172.28.128.5] run: docker pull nginx:stable-alpine
[vagrant@172.28.128.5] out: stable-alpine: Pulling from library/nginx
[vagrant@172.28.128.5] out: Digest: sha256:ce50816e7216a66ff1e0d99e7d74891c4019952c9e38c690b3c5407f7af57555
[vagrant@172.28.128.5] out: Status: Image is up to date for nginx:stable-alpine
[vagrant@172.28.128.5] out:
[vagrant@172.28.128.3] Executing task 'nginx.migrate'
[vagrant@172.28.128.3] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.4] Executing task 'nginx.migrate'
[vagrant@172.28.128.4] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.5] Executing task 'nginx.migrate'
[vagrant@172.28.128.5] run: docker info 2>&1 | grep 'Is Manager:'
[vagrant@172.28.128.3] Executing task 'nginx.update'
[vagrant@172.28.128.3] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.3] run: docker inspect --type container nginx_current
[vagrant@172.28.128.3] run: docker service inspect nginx
[vagrant@172.28.128.3] No changes detected, update skipped.
[vagrant@172.28.128.4] Executing task 'nginx.update'
[vagrant@172.28.128.4] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.4] run: docker inspect --type container nginx_current
[vagrant@172.28.128.4] No changes detected, update skipped.
[vagrant@172.28.128.5] Executing task 'nginx.update'
[vagrant@172.28.128.5] run: docker inspect --type image nginx:stable-alpine
[vagrant@172.28.128.5] run: docker inspect --type container nginx_current
[vagrant@172.28.128.5] No changes detected, update skipped.
Done.
Disconnecting from vagrant@172.28.128.3... done.
Disconnecting from vagrant@172.28.128.5... done.
Disconnecting from vagrant@172.28.128.4... done.
Откат к предыдущей версии
Откат к предыдущей версии (команда fab django.rollback для ранее описанной конфигурации) во многом аналогичен процессу деплоя:
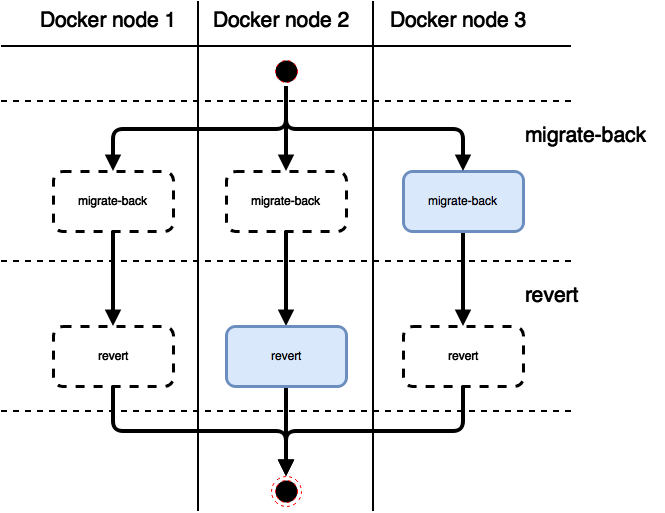
И откат миграций, и откат самого сервиса к предыдущему состоянию выполняются строго один раз на одной из менеджерских нод.
Заключение
За контейнерезацией будущее серверной разработки. Те, кто этого еще не осознал, скоро будут поставлены перед свершившимся фактом. Контейнеры — удобное, простое и мощное оружие в руках разработчиков и DevOps.
С выходом Docker 1.12 у сторонников Kubernetes практически не осталось аргументов в пользу использования последнего. Сервисы Docker не только обеспечивают все те же возможности, что и сервисы Kubernetes, но при этом обладают даже рядом преимуществ, благодаря простоте настройки на любой ОС (Linux, macOS, Windows) и отсутствию необходимости установки и запуска дополнительных компонентов (контейнеров).
Fabricio — инструмент, помогающий в разработке, тестировании и выкладке новых версий приложений на боевые и тестовые сервера при помощи Docker — теперь поддерживает разворачивание масштабируемых и отказоустойчивых сервисов. С различными вариантами использования Fabricio можно познакомиться на странице с примерами и рецептами (все примеры подробно описаны и автоматизированы при помощи Vagrant).
Подробно о Fabricio я надеюсь рассказать на мероприятии DevOpsDays в Москве. Приходите, будет о чем пообщаться и узнать много нового.
Комментарии (60)

antonksa
12.01.2017 18:24+1Спасибо! Планирую использовать фабрицио для деплоя текущего проекта.
Ждем новых плюшек. Еще раз спасибо, желаю уверенного развития тулзы.

KorP
12.01.2017 19:23Как раз сегодня с этим играюсь сижу.
Я пока в докере не очень, по этому вопрос есть. Увеличиваем кол-во реплик до Х, потом уменьшаем до У, в итоге имеем такую картину
http://take.ms/r5B66
Что собственно делать с теми, что в состоянии shutdown? Или они так и будут копиться до остановки самого сервиса?o_serega
12.01.2017 19:27они буду дропнуты после docker service rm, можно в ручную дропнуть на каждом хосте, но тут встает вопрос об консистентности данных, в строенной базе докера
KorP
12.01.2017 19:28А их кол-во (в состоянии shutdown) не сказывает на производительности? Ресурсы не кушает?
o_serega
12.01.2017 19:54Это просто стопнутый контейнер, в режиме шутдауна, вы по рессурсам будите терять только место на диске, для хранения самого верхнего слоя. Ну и виртуальный тюн интерфейс)

renskiy
12.01.2017 19:32Насколько я понял, на каждой ноде хранится какое-то количество «бэкапов», и при достижении их количества определенного значения они начинают ротироваться. Во всяком случае я не видел ситуации, когда на одной ноде их было бы больше 4-х для одного сервиса.

vektory79
12.01.2017 19:45Чего лично я не смог получить от swarm mode — поддержка сетевых плагинов. Так что ксли нужен кластерный дискавери, то ой...
VolCh
13.01.2017 09:52Объединить в одну тоннелями/vpn/роутерами. У нас так объединены два облака, две стойки в дата-центрах и две в главных офиса в трёх странах в две 10.0.0.0/16 подсети. Один-два белых IP для каждого «дата-центра», метки на докер-нодах и в ограниченях конфигураций запуска контов, чтобы логически локальный трафик не ходил в другую часть света.

shcoderAlex
13.01.2017 05:22Сразу прошу простить меня за вещи сказанные неправильно, если таковые будут.
У меня возникли проблему со swarm mode когда понадобилось охватить больше одного региона в aws. Т.е. как я понимаю swarm может висеть на одно из доступных интерфейсов. У инстанса на aws это внутренняя сеть. Соответственно между регионами\зонами внутренняя сеть разная. Как быть в такой ситуации?
kafeman
13.01.2017 07:14+1Прежде всего, я бы задался вопросом, а действительно ли вам это нужно. Например, разработчики Kubernetes где-то писали, что даже их «супер-пупер» облака спроектированы из расчета на применение внутри одного датацентра. Нужно несколько датацентров (в вашем случае: зон AWS) — создавайте несколько независимых кластеров. Как-то так…
o_serega
13.01.2017 13:10Сделайте туннель между двумя регионами тот же ipsec и заверните роуты для серых сетей, каждого региона, через этот туннель. Тут ругой момент, у сварм мода должно быть нечетное колличество мастеров для кворума и тут стает вопрос консистентности кластера. Надо решить будите ли вы все мастера держать в однмо регионе, а во втором только воркеры и разруливать по лайблам или какую-то часть мастеров деражть во втормо регионе, тогда вопрос что будет если отвалится связть между регинами, а она отвалиться.
Ну а вообще я бы для каждого региона свой бы кластер держал. И уже уровнем выше бы разруливал в каком регионе апать контейнер.
Вон у кубера пояфилась поодержка федиративного кластера, но пока я реальных отзывов как оно себя ведет — не видел.
hippoage
13.01.2017 10:11Понятно, что всё еще сыро, ребята из Docker Inc слишком увлекаются фичами и оставляют много багов по сторонам.
Но принципиально смущает ingress load balacing. По сути он обманывает внешний балансировщик. По идее HAProxy должен знать, что не нужно равномерно распределять трафик на 3 ноды, а нужно на 2 и куда запрос пришел, там и остался. Если запросы «тяжелые» и нагрузка относительно железа небольшая, то потенциально можно себе позволить гонять данные через лишние ноды и сеть, но далеко не для всех сценариев такое подходит. Есть механизм обхода этого? Т.е. выбрасывание портов на конкретной ноде только (ну и информирование о списке нодов через какой-нибудь service discovery можно уже внутри контейнера сделать).renskiy
13.01.2017 11:23Можно создать сервис с опцией --mode global, в этом случае Docker будет создавать по одному контейнеру на всех доступных нодах. В этом режиме количество реплик равно количеству нод. Возможно, что в этом случае внутренней балансировки не происходит, и ее полностью можно делегировать внешнему балансировщику.
o_serega
13.01.2017 13:13Если у меня кластер из пару десятков нод (как на данный момент), а для работы приложения мне надо только три экземпляра, зачем мне деражть 30 экземпляров данного приложения? мод глобал в этом случаи выглядит как адовый костыль

gudron
13.01.2017 12:301.12 вообще привнесла путаницу какую-то. Везде в интернете во всяеских статейках было написано что multi-host можно разворачивать через swarm + docker-compose. распределяя какой контейнер на какой ноде — через labels.
(https://docs.docker.com/compose/swarm/#/multiple-dependencies)
Выходит docker-compose последней версии и вот уже нельзя поднимать контейнеры в swarm-моде.
WARNING: The Docker Engine you're using is running in swarm mode.
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use the bundle feature of the Docker experimental build.
На замену дали некие бандлы… но они экспериментальные.
https://docs.docker.com/compose/bundles/
Тоесть выпилили одну возможность, но не доделали замену. И как сейчас нормальным образом на 1.12 поднять swarm-кластер с overlay-network, и при этом что бы все описание кластера было в удобном виде, в текстовом файле — не понятно.
Выполнять руками десятки команд service create — какой-то бред.o_serega
13.01.2017 13:20Вот вот, с swarm mode они внесли большую путаницу, назвали бы уже cluster mode или k8s mode (шутка), да и позабавило что их же инструментарий для оркестровки не поддерживает сварм мод.
Лично мое мнение, пока, сварм мод — больше на поиграться или в небольших дев и куа окружениях использовать.


stychos
14.01.2017 18:53Сворм хорош, но:
— пока нет вменяемой группировки сервисов (есть стеки в экспериментальном виде, но они практически ничего не умеют, даже маунт привязать);
— возникает оргоменнейшая жопоболь в случаях, когда надо, например, порезать доступ извне к публикуемым сервисам только для определённых адресов-подсетей на уровне айпитейблс - докер постоянно засовывается в начало прероутинга, приходится ваять костыли.

Nastradamus
19.01.2017 13:29А вот эти все Deploy заботятся хоть как-то о состоянии существующих tcp сессий? Или хипстеры не знают что это такое, как в случае с Kubernetes?
renskiy
19.01.2017 14:49Deploy системы об этом никак не заботятся, об этом, как вы верно заметили, заботится Kubernetes, или, как в данном случае, это должен делать сам Docker. То есть, оркестрация не входит в задачи инструментов для деплоя.
Nastradamus
19.01.2017 15:05Я про
Это достигается за счет того, что Docker обновляет контейнеры сервиса по очереди.
Это задача Docker Swarm или Kubernetes. Он должен понимать можно рвать сейчас tcp-сессии или нет. Например, как это сделано в haproxy или nginx.
o_serega
>>> С выходом Docker 1.12 у сторонников Kubernetes практически не осталось аргументов в пользу использования последнего. Сервисы Docker не только обеспечивают все те же возможности, что и сервисы Kubernetes
Не вовдите людей в заблуждение, попробуйте в swarm mode сделать аналог куберовского пода, это первое что в голову пришло.
Второе, docker run дает куда более большее колличество ручек, чем docker service create, отсюда классический swarm, который просто обвертка для апи докера, позволяет делать куда более гибкие вещи, вернемся к аналогу пода кубернетовского, у docker run есть ключики --ipc и --network, через которые можно шарить один неймспейс для нескольких контейнеров.
Ну это так, на вскидку, не вдаваясь в дебри
renskiy
Исходя из этого описания пода, я так понимаю, что это
не более чем логическаягруппа контейнеров со своими «namespaces and shared volumes». Так чего же из этого нет сейчас в Docker?o_serega
Под — это логическое объединение, технически — это два и более контейнеров, которые шарят общий неймспейс, если вы читали внимательно мой пост выше, я там написал, что в docker run есть для этог ручки, кои кубер, по факту, и дерагет. Я написал, что в docker service create этих ручек нет, первое что приходит на ум, после фразы
>>>Сервисы Docker не только обеспечивают все те же возможности, что и сервисы Kubernetes
Такое заявление можно сделать только, если глубоко не разберались с кубернетесом. А там возможностей на много больше есть, коих не даст docker swarm mode
Dreyk
оно пилится. в 1.13 docker service create уже умеет больше ручек из docker run, просто дайте им время)
o_serega
Это никто не отрицает, я уверен что рано или поздно, по функционалу, будет тяжело отличить кубер от докера с его сварм мод, но сейчас делат заявление, что «Сервисы Docker не только обеспечивают все те же возможности, что и сервисы Kubernetes», пока еще рано и вводит людей в заблуждение.
Dreyk
это да. фанаты всегда бегут впереди) я сам жду)
renskiy
--network сервису Docker задать можно. При помощи этой опции и задается отдельный namespace для контейнеров сервиса. IPC — видимо пока нет. Не использовал последнюю опцию. Можете рассказать какие преимущества дает это в работе с контейнерами? Когда это целесообразно применять?
o_serega
Из вашей же ссылки: After you create an overlay network in swarm mode, all manager nodes have access to the network.
Ключик нетворк в сервайс криат позволяет подключиться к уже созданной оверлейной сети, а не к сетевому неймспейсу другого контейнера. В сварм моде не сделаешь --network=container:<name|id> — reuse another container's network stack.
--IPC — был кейс года был нужен IPC неймспейс поделить хостовой с контейнером.
renskiy
В контексте сервисов это было бы странной фичей. В сервисе же мы не можем сказать точно где какой контейнер в данный момент работает. Нет, можем конечно, если обратимся к менеджеру с соответствующим запросом. Но ведь контейнер в любой момент может «переехать» на другой хост, и как в таком случае должен будет повести себя… кстати, вы хотите сервис к имеющемуся контейнеру подключить?
Опять же, хостов в кластере много, с каким именно хостом делить IPC namespace?
o_serega
--network=container:<name|id> Как раз в кубере под так и создается, все контейнеры, которые создают единый под, апаются на одной ноде, миграция происходит на уровне пода, т.е. мигрируют все контейнера, которые принадлежат этому поду.
Даже классический сварм (который не сварм мод) при использовании --network=container:<name|id> апапет эти контейнера на одной ноде.
--IPC можно заюзать не только для шаринга неймспейса хостового с контейнером, но и между контейнерами.
o_serega
Я это к тому, что сейчас, в режиме роя, у докера, сервис — это один контейнер с каким-то колличеством реплик, а на уровне кубера того же — это под с каким-то колличеством его реплик, а под — это один или несколько контейнеров объединенных между собой в единый неймспейс. Это все отсыл к той фразе, что докер сварм мод дает те же возможности, что и кубер)
renskiy
Pod — еще один уровень абстракции в дополнение к уже существующим (образ, контейнер, сервис). Но на самом деле его обязанности чрезвычайно размыты (pod — для него даже названия нормального не нашлось). Возможно необходимость в нем и была на каком-то этапе развития технологии Docker, но сейчас она (эта абстракция) стала совершенно ненужной и только вводит людей в заблуждение.
o_serega
С утверждением, что не нужно, можно и поспорить, но не думаю, что в этом будет какой-то смысл. Но это не отменяет того факта, что, пока, докер, с его сервисами, не дает те же возможности, что и кубер. Давайте отойдем от пода, те же хелчеки, у докера они только появились и то только в едином виде, у кубера их два вида, один для этапа старта контейнера, второй тип — уже для проверки работающего приложения.
https://kubernetes.io/docs/user-guide/walkthrough/k8s201/#health-checking
Ксли бы не фраза: «Сервисы Docker не только обеспечивают все те же возможности» я бы даже не отписывался в этом посте)
renskiy
И все-таки я считаю, что Docker обеспечивает «все те же возможности», может не «один в один», но основное уже точно реализовано. А может я просто фанат Docker )
o_serega
Да конецептуально они похожи, скажем так, докер делает почти кальку, но все же, пока, по возможностям докер не дает все то же, к чему и была основная моя притензия)
И да, я не отставиваю кубер, лично я остановился для своих нужд на docker+swarm (который стенделон)+consul+gobeetwen. Данная связка полностью покрывает потребности мои и разработчиков.
Спасибо за дискуссию! Было приятно пообщаться
asm0dey
автомасштабирование?
o_serega
Если, Вы, имели ввиду как кластер маштабируется — то докер хост с сварм агентом, который в консул сообщает о новом воркере.
asm0dey
Не, я имею ввиду что когда у меня утилизировано 80% мощности CPU или объёма RAM доступного контейнеру — надо создать ещё один инстанс.
o_serega
В этом вопросе все сложно, пока склонаяемся, что надо писать свое.
Пока опираемся на метрики, но скалирование происходит по факту в ручную, запуском docker-compose scale.
renskiy
В вопросе масштабирования довольно рискованно доверять автоматическим системам. Решение о введении в строй новых инстансов все равно должно приниматься человеком.
asm0dey
Я так не считаю. У меня работало и не сбоило.
o_serega
Есть разного рода приложения, если нужно после старта приложения какое-то время на наливку на него данных и прогревания кеша, тот же кластер хезелькаста, которому надо время.
Так что если в вашем конкретном случаи оно работало и не сбоило — это еще не показатель, что так будет всегда и у всех. Мы потому и думаем о своем шедулере со своими заморочками.
asm0dey
Ну так конкретно для хэзелкаста значит не включаем автомасштабирование :) Я же не говорю что надо в прод без тестирования.
asm0dey
.
asm0dey
Я не люблю велосипеды, предпочитаю использовать готовые решения.
o_serega
Готовые решения на то и готовые, что они пытаются покрыть максимально общие кейсы для всех, но редко покрывают специфические моменты, которые часто есть у разных компаний.
asm0dey
Видимо моя жизнь скучна — автомасштабироавние на компьют-нодах работает идеально, БД я в кубернетисе не кручу, ФС у меня — Ceph, железные.
vics001
Docker swarm самая сырая оркестрация из тех, что есть kubernetes, даже тот же rancher. Mой баг, который сделан во всех движках, кроме docker swarm, висит 4 месяца https://github.com/docker/docker/issues/26664. По моим оценкам docker надо пилить еще год минимум.
Используем docker swarm для production и CI/CD, самые большие проблемы с docker volume, эта логическая концепция абсолютно не проработана для работы с docker service.
renskiy
Ваш случай ( я про баг) довольно нетипичен для стандартных сценариев использования контейнеров. Конечно, это не повод не иметь возможности гибкого управления healthcheck, но думаю тут вопрос в приоритетизации задач.
Плюс, странно, что вы зная, что это вызовет проблемы, все же применили такое решение. Мне кажется, что в таких случаях стоит подумать о том, чтобы решать задачи длительных вычислений не в процессе инициализации контейнера, а, например, производить эти вычисления заранее, до старта контейнера. Либо делать это асинхронно, давая возможность healthcheck скрипту отдать вменяемый ответ на соответствующий запрос.
Насчёт volumes — вполне логично, что для распределённых систем реализация данной концепции не является простой штукой. И мое мнение в том, что надо избегать использования volumes для сервисов. Сервисы предназначены для stateless систем. А если состояние все-же нужно шарить между контейнерами сервиса, то для этого лучше использовать БД, которую запускать не как сервис, а как несколько обычных контейнеров на разных хостах.
vics001
В Healthcheck просто не хватает критического параметра, реакции на старт приложения. В Docker есть 3 состояния healthy, starting, unhealthy. Так вот управлять starting не возможно никак, если увеличиваешь интервал проверки страдает runtime check, который может стать слишком долгим для определенных задач, если уменьшаешь интервал, то страдает starting состояние, тупо процесс не успевает стартовать. Это абсолютное нормальное явление проверять http запрос каждую секунду и дать системе на старт 10 секунд.
Оправдать эти костыли никак нельзя, тем более в других системах такого нет.
Никто не говорит, что volume это просто, но в Кубернетес изначально есть persistent volume, а docker все пытается продать идею, что состояние не важно. Причем Docker Swarm выпустили абсолютно сырым в плане volume, невозможно создать сервис с volume с replicas > 1.
P.S. Docker купил http://infinit.sh/ и в принципе понятно, что будет с volume, когда будет в этом вопрос. Я оцениваю Docker может через год или 2 будет полноценной системой оркестрации.
Dreyk
по поводу volumes можно попробовать использовать плагины (экспериментальная фича 1.12, выходит из экспериментальной в 1.13) типа flocker
vektory79
С flocker теперь непонятно что будет: https://techcrunch.com/2016/12/22/clusterhq-hits-the-deadpool/
Хотя надежды есть: https://twitter.com/thenewstack/status/812016009163001856