

Зачем они нужны?
Для того чтобы понять зачем нужны нейронные сети, нужно разобраться с тем, что они из себя представляют.
Искусственные нейронные сети — это совокупность искусственных нейронов, которые выполняют роль сумматоров.
Искусственные нейронные сети нужны для решения сложных задач, например: прогнозирование, распознавание образов. Так же они применяются в области машинного обучения и искусственного интеллекта, вы можете встраивать их в свои игры.
Главная особенность нейронных сетей — они способны обучаться.
Искусственный нейрон
Перед тем как переходить к строению нейронных сетей, нужно разобраться с их единицей — нейронами.

За входы обозначены x1, x2. На них поступают данные, либо в вещественном виде, либо в целом. Очень часто приходится проводить нормализацию входных данных. Для этого достаточно:
Количество входов зависит от задачи.
Так же мы имеем веса: w1, w2. В них и заключается суть нейронных сетей, через них проходит обучение. О нём чуть позднее.
Перед началом обработки данных, входы умножаются на соответствующие им веса. Т.е x1 * w1, x2 * w2. Далее результаты произведений поступают на нейрон и суммируются. (x1 * w1) + (x2 * w2)
Например: x1 = 1; x2 = 3; w1 = 0; w2 = -1;
(1 * 0) + (3 * (-1) ) = -3
Усвоим для себя, что количество весов должно соответствовать количеству входов.
Далее результат суммирования поступает в блок нелинейного преобразования. В нём должна находиться функция активации.
Функция активации
Функции активации нужны для нормализации выходных данных. Допустим ответ -3 нам ни о чём не говорит, и мы хотели бы преобразовать его к 1 или 0.
Для такого имеется функция единого скачка. Когда в нейроне заряд превысил какой-то порог, то нейрон выдаёт 1. Если заряд ниже порога, то нейрон выдаст 0. Например, T — порог. Он равен 0. Результат суммирования -3. -3 < 0, значит и ответ нейрона 0. Если заряд был бы больше, например равный 0.5 или 1 или 124124, то нейрон выдал бы 1.
Порог устанавливается по вашему желанию, так как нейронная сеть всё равно подстроиться под него.
Когда нам необходимо преобразовать данные для большего выбора варианта, то нам необходимо преобразовать суммированный результат в вид от 0 до 1.
Для такого у нас имеется логистическая функция.
Или:
a — степень крутизны на графике функции.
net — результат суммирования
В нашем случае -3 преобразуется в 0.9525741268224334
В таком случае мы можем просклонять такой ответ к хорошему результату.
Практика
Представим себе такую задачу. Мы хотели бы получить подсказку от нейронной сети, встречаться ли нам с девушкой или нет. Мы имеем такие входные данные:
Рост девушки, (в метрах)
На сколько она красива, (1% — 100%)
Есть ли ум, ( 1/0 )
Умеет ли готовить. (1/0)
Допустим установим все эти входы такими числами: 1.66, 100%, 1, 1
4 входа — 4 веса. t(порог) = 400
Установим сейчас веса без обучения, как степень важности параметра:
1, 5,5, 4.
Умножаем входы на соответствующие им по номеру веса: (1.66 * 1) + (100 * 5) + (1 * 5) + (1 * 4) = 1.66 + 500 + 5 + 4 = 510.66 > 400, значит встречаться с девушкой можно, так как нейрон выдаст 1.
Теперь попробуем проверить через логистическую функцию. 1 / (1 + exp(-510.66)) = 1.0
В данном случае мы тоже получили 1, значит встречаться можно. Но здесь у нас больше вариантов, ибо тут мы можем распределить ответы НС так:
net => 0.80, встречаться можно.
net < 0.80 && net != 0.5, нужно ещё подумать.
net <= 0.5, встречаться не нужно.
Надеюсь вам было понятно.
Типы нейронных сетей
Теперь нужно понять строение нейронных сетей. Они разделяются на однослойные и многослойные, с прямыми связями и обратными связями.

Единственное, что объединяет ОНС и МНС — это то, что входные нейроны не обрабатывают, лишь передают сигналы на обработку.
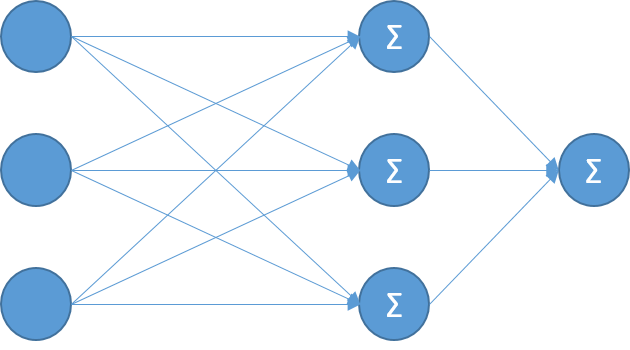
Однослойные НС
В таких НС данные с входных слоёв передаются сразу на выходные нейроны, которые обрабатывают сигналы.

В данном примере три входных нейрона(x1, x2, x3), три выходных нейрона(out1, out2, out3).
В таком случае, получается, три связи у каждого выходного нейрона.
out1: w1, w2, w3. out2: w1, w2, w3. out3: w1, w2, w3.
Каждая связь может иметь разное значение.
Как нейрон обрабатывает сигнал — я писал выше.
Многослойные НС
Такие НС работают гораздо сложнее, но и способны они на большее.
Главная их отличительная особенность — они имеют скрытые(обрабатывающие) слои.
Названы они так, из-за того, что мы не видим какие сигналы они передают на выходы.
Сигналы они обрабатывают, часто имеют логистическую функцию активации, но можно и пороговую (единый скачок). С количеством слоёв и нейронов в них вам нужно разобраться самим, ибо для этого формул нет.
Сети с прямыми связями
Сети с прямыми связями могут быть однослойные и многослойные, вы уже видели их на рисунках выше. Таким образом связи из входов направляются к выходному слою или к скрытому слою и т.д к выходному.
Такие сети способны на прогнозирование, линейную интерполяцию, распознавание образов, не редко на классификацию и многое другое.
Сети с обратными связями
Данные сети имеют как прямые связи, так и обратные.

Такие нейронные сети могут иметь разное количество слоёв, или могут быть вообще однослойными. Но главная их особенность — они имеют ассоциативную (кратковременную) память. На таких нейронных сетях вы можете сделать чат-ботов. Так же они могут применяться в управлении, решать задачи классификации и многое другое.
Персептрон
Персептрон — нейронная сеть рецептор. Он имеет входной слой(S), обрабатывающие слои(A),
выходной слой®.
Нейроны S слоя входные. Они могут находиться в состоянии возбуждения(1), либо в состоянии покоя(-1 или 0). Конечно же, никто не запрещает вам использовать и другие числа. Так же вы можете их нормализовать, например 1 / num, где num — ваше число.
Прежде чем попасть в A слой, сигналы с S слоя должны пройти по весам SA, значения которых могут быть в пределах от -1 до 1 в вещественном виде. Далее, сигналы поступают в A слой, суммируются, проходят через функцию активации. Далее, сигналы которые идут по AR весам. Здесь они могут иметь уже любые значения, которые установятся обучением.
В нейронах R слоя сигналы так же обрабатываются, проходят через функцию активации и вы получайте ответ.
Обучение
Вот мы и перешли к самой важной, но и в то же время очень сложной части. Обучение нейронной сети — это процесс, при котором изменяются весовые коэффициенты. Собственно, благодаря этим весовым коэффициентам и работают нейронные сети.
Правило Хебба №1
Данное правило действует чаще всего с однослойными персептронами, входные сигналы которых равны 1, -1 или 0. С остальными числами у вас оно работать не будет.
Работает оно просто:
1. Если нейронная сеть выдаёт правильный результат, то весовые коэффициенты не изменяются.
2. Если нейронная сеть ошиблась и не дала правильный ответ(распознала неверно), то весовые коэффициенты уменьшаются.
3. Если нейронная сеть ошиблась и отвергла правильный ответ, то весовые коэффициенты увеличиваются.
Правило Хебба №2
Данное правило работает со всеми числами. По-другому оно называется delta правилом. Оно имеет две формулы, в которых нужно разобраться, так как delta правило присутствует в методах обучения для многослойных нейронных сетей.
Для delta формулы нам необходимо знать ошибку сети. Чаще всего, ошибка — это разность правильного и неправильного ответов.
Где d — правильный ответ, b — ответ сети.
Теперь рассмотрим саму формулу:
w(t + 1) — новый весовой коэффициент.
w — старый весовой коэффициент
err — ошибка(разность правильного ответа и ответа сети)
n — скорость обучения
xi — значение которое пришло на i-ый вход
Я думаю, что вам не совсем понятна скорость обучения и как её искать. Ищется она в диапазоне чисел от 0 до 1, очень часто ставят 0.001, 0.0001 или 1.
Метод обратного распространения ошибки
Это самый лучший метод обучения сетей, который используется как с многослойными, так и однослойными сетями. Чем-то он может напомнить вам delta правило, ибо формула та же.
В данном случае, нам необходимо создать счётчик ошибок. Если показатель счётчика равен 0 — значит нейронная сеть обучена. Конечно же, в данном случае нам необходимо иметь обучающую подборку.
Алгоритм такого обучение следующий:
1. Инициализация весов случайными значениями.
2. Выбрать обучающие данные, подать на входы сети.
3. Вычислить выход сети.
4. Вычислить разность между правильным ответом и неправильным.
5. Корректируем веса для минимизации ошибки.
6. Повторяем 2 и 5 шаг, пока ошибка не достигнет 0 или приемлемого уровня.
Практика
Вот теперь мы практикуем свои знания. Сейчас мы попробуем сделать однослойный персептрон, который будет работать с методом обратного распространения ошибки.
Пусть он строит логическую таблицу функций 'AND' и 'OR'. Кто знаком с алгеброй логики, тот поймёт.

Начнём описывать эту сеть через ООП. Мы видим, что у нас два входных нейрона, две связи, один выходной нейрон.
public class NeuralNetwork {
static double enters[] = new double[2]; // создаём входы
static double out; // храним выход сети
static double[] weights = {0,0}; // весовые коэффициенты
Теперь нам необходимо создать матрицу готовых ответов и входов для таблицы AND.
static double tableOfLearn[][] = {
{0,0,0},
{1,0,0},
{0,1,0},
{1,1,1}
};
Создаём обработку входных данных. Здесь не так всё сложно. Если вы помните, то входные данные умножающие на соответствующие им по индексу веса и результаты произведений суммируются. Воспользуемся пороговой функцией. Если выход > 0.1, то НС даёт 1.
public static void summator(){
out = 0; обнуляем выход
for ( int i = 0; i < enters.length; i++ )
out+=enters[i]*weights[i]; // вход * вес, суммируем.
if ( out > 0.1 ) out=1; else out=0; // функция активации
}
Теперь пишем обучение сети. Метод обратного распространения ошибки. Создали счётчик ошибок, запускаем цикл. Копируем в входы НС входные данные из обучающей таблицы. Запускаем обработчик, получаем ошибку. Дальше используем delta правило.
public static void train(){
double gError = 0; // создаём счётчик ошибок
int it = 0; // количество итераций
do {
gError = 0; // обнуляем счётчик
it++; // увеличиваем на 1 итерации
for ( int i = 0; i < tableOfLearn.length; i++ ){
enters = java.util.Arrays.copyOf(tableOfLearn[i],
tableOfLearn[i].length - 1); // копируем в входы обучающие входы
summator(); // суммируем
double error = tableOfLearn[i][2] - out; // получаем ошибку
gError+=Math.abs(error); // суммируем ошибку в модуле
for ( int j = 0; j < enters.length; j++ )
weights[j]+=0.1*error*enters[j]; // старый вес + скорость * ошибку * i-ый вход
}
} while(gError!=0); // пока gError не равно 0, выполняем код
}
Теперь мы запускаем тестер НС. Включаем обучение; НС обучилась; проверяем её работу.
train();
for ( int p = 0; p < tableOfLearn.length; p++ ){
enters = java.util.Arrays.copyOf(tableOfLearn[p],
tableOfLearn[p].length - 1);
summator();
System.out.println(out);
}
Включаем тестирование при запуске программы.
public static void main(String[] args) {
new NeuralNetwork().test();
}
Вот такой результат мы получаем:

Так же, есть видео на YouTube: www.youtube.com/watch?v=mGXdwlrV1TI
Заключение
Конечно, многое может быть вам было не понятно. На сайте я буду писать множество статей о создании разных проектов с НС, поэтому объяснять о них я буду не один раз. Я надеюсь, что кому-то эта статья понравится. Спасибо за внимание, удачного кода и послушного ИИ.
Комментарии (62)

lair
30.01.2017 23:39+2Начнём описывать это сеть через ООП.
Зачем?

EmeraldSoft
30.01.2017 23:45-8Просто, почему бы и нет?
lair
30.01.2017 23:47+10Потому что это неэффективно в практическом применении.
(не говоря о том, что это у вас, прямо скажем, весьма ложненькое ООП)
EmeraldSoft
30.01.2017 23:56-8Если людям не нравится — они обычно меняют.
lair
30.01.2017 23:58+3Для этого надо понимать, как и куда менять. А для этого надо понимать, что в сети важно, а что нет.

Coffin
31.01.2017 10:17-4Предложите свое видение без ООП :) Всем будет интересно.
Iora
31.01.2017 10:51Слово «матрицы» вам о чем-нибудь говорит?
Coffin
31.01.2017 10:53-4Следуй за белым кроликом?
Синяя или красная?
Нео
Тринити
или вы про другие?Iora
31.01.2017 10:57Про математические.
Coffin
31.01.2017 10:58Именно о них и думаю, когда говорят слово матрицы.
Но какое это имеет отношение к моему комментарию о том, что бы человек написал свое видение без ооп?Iora
31.01.2017 11:15-3Но какое это имеет отношение к моему комментарию о том, что бы человек написал свое видение без ооп?
Прямое. Но если вы задаете такие вопросы, если у вас они впринципе возникают, то очевидно, что вы имеете весьма смутное представление о нейронных сетях.Coffin
31.01.2017 11:20-1Если вы не заметили или не хотели заметить или еще какие-то причины, то я вопросов не задавал.
Я лишь предложил автору коммента про «зачем ООП» предложить примеры без применения ООП, а то как он себе видит код.
Просто вы не умеет читать то, что пишут люди, а читаете то, что хотите прочитать :) Предлагаю провести «аудит весов» вашей нейронной сети серого вещества.Iora
31.01.2017 11:23-2Вы молодец, всегда можете оправдать свое невежество просчетами оппонента.
Coffin
31.01.2017 11:29Спасибо.
Я указал вам правильный путь, следуйте ему и все будет хорошо :)Iora
31.01.2017 11:36-2С моей стороны остается только пожелать вам изучить наконец теорию нейронных сетей. Тогда, возможно, вы осознаете, что есть иные методологии кроме ООП, которые могут неплохо подайти для реализации ИНС.
Coffin
31.01.2017 11:38+1Я еще раз вам советую читать то, что пишут, а не то, что хотите прочитать.
Я ни разу не сказал, что для НС надо писать только на ООП, вы это не хотите понимать.

Serj_By
02.02.2017 13:18+1Рискуя отхватить немало минусов, вступлюсь все же за автора. Несмотря на то, что ООП действительно «весьма ложненькое», и матрицы действительно быстрее, статья все же entry level'а, так как описывает самые основы нейронных сетей, и на этом уровне neuron1.weight1 все же доступней для восприятия чем w [0] [0]. Чисто мое личное мнение.
Iora
02.02.2017 13:45и на этом уровне neuron1.weight1 все же доступней для восприятия чем w [0] [0]
Если человек не понимает матриц, что он вообще забыл в нейронных сетях?
статья все же entry level'а
Что не означает, что нужно учить неправильно. В любой литературе (приличной) по сетям матричная форма дается сразу, что как бы намекает, что именно так и надо делать. А то появятся гениальные товарищи, которые каждый отдельноый нейрон самостоятельным объектом делать будут, и будут оправдываться тем, что это типа для начинающих.
Чисто мое личное мнение.
Вы в праве его иметь, ничего лично к вам не имею.
lair
31.01.2017 11:54+6Как-то так:
% input layer % adding bias a1 = [ones(m, 1) X]; % hidden layer z2 = a1 * Theta1'; a2 = sigmoid(z2); % adding bias a2 = [ones(size(z2, 1), 1) a2]; % output layer z3 = a2 * Theta2'; a3 = sigmoid(z3); % prediction [a, p] = max(a3'); p = p';
(
a— входы,z— результаты суммирования,p— выход)
Ну и да, это не какое-то "мое видение", это задачка по учебнику.
lair
30.01.2017 23:57+1Мне, кстати, отдельно интересно, чем приведенная вами сеть функционально отличается от логистической регрессии.

Dimchansky
31.01.2017 14:53А разве есть разница между нейронной сетью с одним нейроном и логистической регрессией?


ProgrammerMicrosoft
31.01.2017 04:44Автору огромное спасибо за статью :)

theWaR_13
31.01.2017 09:01+2Нда… Кажется только на хабре могут заминусовать сообщение с благодарностью автору.


GeMir
31.01.2017 08:54+5О LaTeX автор не слышал?
«Для этого достаточно: 1/number» —?
«выходной слой®» — ??
В целом очень похоже на школьный реферат по теме из категории «мне бы на троечку».
bromzh
31.01.2017 09:15+4Начнём описывать эту сеть через ООП.
static, static, staticНет автор, это не ООП, а обычный процедурный стиль.
rkfg
31.01.2017 09:58+8Мне было бы более интересно почитать про практическое применение нейросетей, но без сурового матана. Вот таких материалов реально мало. Я нашёл хорошее объяснение с примерами и кодом на Deeplearning4j, да и сама библиотека производит приятное впечатление — как и сам язык Java, она ориентирована на инженеров, а не на учёных, позволяет решать практические задачи с минимумом усилий. Освещены свёрточные и рекуррентные сети, есть объяснения с картинками, а не со «страшными» формулами, есть код. Тем не менее, этого маловато для полномасштабного применения, и хотелось бы в таком же стиле продолжения.
Например, я довольно долго пытался обучить чат-бота на LSTM по аналогии разработки Google. Параметры сети выглядят не сильно сложными, всё влезает на 8 Гб видеопамяти, обучающих данных достаточно (чатлоги конференции за 6 лет на 150 Мб). Строился словарь из наиболее часто встречающихся 10 тыс. слов и пунктуации, далее слова заменялись на числа. Я объединил реплики, идущие подряд от одного и того же ника, и в качестве предсказываемого результата подавал следующий блок реплик, после чего второй становился первым, а вторым брался следующий блок. Диалог, понятно, далеко не всегда получался, но ничего лучше у меня нет. Однако, оценочный score модели вёл себя не так, как должен, независимо от learning rate — болтался возле одного значения и никак не конвержился к нулю. Тестовая выдача тоже не сильно коррелировала с ожидаемой и выглядела плохо на фоне того, что получилось у гугла. Truncated backprop несколько улучшил ситуацию, как и снижение размера минибатча, но в целом, желаемого результата достигнуть не удалось.
Потом был ещё эксперимент с увеличением размера выборки обучения, но там вылезли свои проблемы, score уходил в минус, и объяснений, что это значит и как с этим бороться, я не нашёл. Проблема могла быть как в формировании исходных данных с учётом маскирования неиспользуемых элементов, так и в неверно выбранном подходе в принципе. В seq2seq примерах нашёл только посимвольное предсказание с очень большой обучающей выборкой, по 1000 символов на минибатч, у меня же были слова, а не буквы, и выборки были по слов 20-30 максимум, а чаще намного меньше. В примере гугла и того меньше, реплики по слов 5-10 порой. Как это влияет на способность сети к обучению? Мне неизвестно.
Не отрицаю, что возможно, после изучения всей линейной алгебры, лежащей в основе этой научной области, у меня получилось бы намного лучше. Но я заметил, что в целом даже у специалистов подходы практикуются довольно эмпирические — попробовали, обнаружили какие-то свойства, которые не всегда получается объяснить (например, переворачивание входного предложения задом наперёд даёт более устойчивую связь с предсказываемым). А современные библиотеки и фреймворки предоставляют достаточно абстрактный уровень, чтобы разработчику необязательно было досконально знать, как там перемножаются матрицы. Ему надо знать, какие бывают типы сетей, какие у них свойства, как прикинуть размер скрытых слоёв в зависимости от объёма входных данных (как по ширине, так и по времени, кстати, тоже не особо освещённая тема — в примерах ставится некое магическое число нейронов, которое никак не мотивируется), как выбрать learning rate, minibatch size, как выбрать функцию активации, какой взять апдейтер, какой оптимизатор для конкретной задачи (и какими практическими свойствами они все отличаются, по формулам мало понятно, для чего они более применимы), как распараллелить работу на кластер, если он есть и т.п.
Вот про это всё в научно-популярном, нематематическом стиле, с картинками и примерами на живом и популярном языке программирования я бы почитал с превеликим удовольствием. А про биологические аналогии, которые к современным нейросетям мало какое отношение имеют писано-переписано уже везде. Равно как и полно материала «для начинающих», после которого неясно, куда двигаться.
Coffin
31.01.2017 10:22Думаю проблема обучения чат-ботов в том, что все ожидают что-то вроде:
Реплика 1
Ответ на реплику 1
Реплика 2
Ответ на реплику 2
А в реальной же жизни это
Реплика 1
Ответа на реплику 2
Реплика 2
продолжение ответа на реплику 1
Ответ на реплику 1 и реплику 2
Реплика 3 и 4
Ответ на 4 и 1
Ответ на 1 и 2
Ответ на 3 и 4rkfg
31.01.2017 10:26Да, всё так, на обычных логах построить внятную и логичную беседу не получится. Просто это и не было моей целью, хватило бы и частично релевантного смешного бреда, всё же делалось это для развлечения. Меня бы даже устроил оверфиттинг, пусть бы выдавал хотя бы реплику из обучающей выборки в ответ на предыдущую. Но не получилось сделать ничего. Может, надо было обучать сильно дольше, я оставлял на несколько часов, но визуально в Web UI средний скор не сходился вообще никуда, так что не уверен, что был смысл продолжать. С нейросетями вообще ни в чём нельзя быть уверенным на 100%, так уж они устроены.
Vjatcheslav3345
02.02.2017 12:38Да, всё так, на обычных логах построить внятную и логичную беседу не получится.
Может быть стоит обучающие веса нейронов избирательно формировать на основе дополнительных (к тем, что сейчас используются) данных — например, попробовать для дополнительного анализа модели языка из распознавания речи, распознавания текстов, поиска логики в тексте или речи.
Тогда ситуация
Реальные репликив реальной же жизни это
Реплика 1
Ответа на реплику 2
Реплика 2
продолжение ответа на реплику 1
Ответ на реплику 1 и реплику 2
Реплика 3 и 4
Ответ на 4 и 1
Ответ на 1 и 2
Ответ на 3 и 4rkfg
02.02.2017 13:20Это уже совсем другой уровень, мне будет сложновато. Как я уже говорил, цели построить что-то разумное и логичное не было, достаточно смутного улавливания контекста и ответа примерно в том же русле. Чем больше будет бреда, тем смешнее, именно это и надо. Пока у меня есть рабочий бот на цепях Маркова, где в качестве первого слова цепи выбирается случайное из реплики собеседника, сравнительно длинное, от 5 символов. Но одного слова часто мало, поэтому и хочется более умного выделения контекста.
Я думаю, применение word2vec дало бы какие-то интересные результаты. Но я пока до него не добрался, только общий смысл полистал. Основная для меня проблема в том, что неясно, то ли я косячу где-то фундаментально, неверно формирую данные и т.п., или просто надо обучать сильно дольше. Как-то не хочется неделю гонять программу, чтобы в итоге остаться там же, где и был.

Akon32
31.01.2017 10:37я довольно долго пытался обучить чат-бота
Чтобы бот сносно вёл диалоги, ему нужна какая-то модель мира. Если вы пытаетесь обучить для беседы нейронную сеть, то такая модель должна появиться в нейросети в процессе обучения. Вероятно, в чат-логах недостаточно данных для построения адекватной модели (хотя я не знаю, может гигабайтов или терабайтов разноплановых чат-логов будет достаточно).
Я объединил реплики, идущие подряд от одного и того же ника, и в качестве предсказываемого результата подавал следующий блок реплик, после чего второй становился первым, а вторым брался следующий блок.
Насколько я понял по описанию, объём контекста беседы легко мог быть выбран неправильно (скорее, он должен быть динамическим), так что нейросеть не могла сделать никаких выводов о том, что следует говорить.
rkfg
31.01.2017 11:13Меня бы устроил оверфиттинг для начала, пусть бы выдавала фиксированные уже виденные ею реплики в ответ на известный же вход. А так да, объём данных конечно же имеет значение, но и информации по оценке необходимого объёма в зависимости от количества label'ов тоже не встречал. Понятно, что чем больше, тем лучше, и если число примеров меньше числа лейблов, то это приведёт только к оверфиттингу и вообще плохо, но сколько будет достаточно, скажем, для 10к слов?
Кроме того, я мог неверно воспринимать понятие score. Я знаю, что это не evaluation, которое выводится по тестовой, не обучающей выборке, а скорее взвешенная разность между выходом сети и желаемым значением на текущей итерации, измеренная в попугаях. Примеры в deeplearning4j показывают сходимость score к нулю, у меня он болтался в районе 80-100. Насколько это плохо, не знаю. Learning rate тоже подбирается с трудом, скажем, на 1e-3 он может через пару итераций увести score на десятки тысяч и в бесконечность, а на 1e-4 вообще не оказывать заметного влияния. Зато через 200 итераций скор проваливается в минус и остаётся там. Как это интерпретировать, мне тоже не очень ясно.
FedyuninV
31.01.2017 15:11+1А что за пример в переворачиванием? Не осталось ли ссылки на статью с этим?
P.S. Тот самый случай, когда один комментарий гораздо лучше всей статьи.rkfg
31.01.2017 15:25+1Вот тут неоднократно упоминается, что переворачивание текста привело к улучшению предсказания. Видимо, это связано с тем, что в первых словах содержится больше всего смысла, и градиент от них должен идти в конце последовательности, чтобы иметь максимальную силу. Рекуррентные сети обучаются не только в «пространстве», но и во «времени» (в пределах одной последовательности), поэтому, очевидно, самые «старые» элементы будут иметь наименьший вес, они будут как бы частично перезаписаны новыми коррекциями весов от более поздних элементов последовательности. Так что если самые важные слова переместить в конец, они окажут наибольшее значение при генерации ответа сети. Интересно, что, скорее всего, этот эффект сработает не для всех языков — в японском наиболее значимые слова часто идут ближе к концу. Возможно, это даже оказывает влияние на культуру народа, когда прямолинейность и быстрый переход к делу считается неприличным, полагается сначала походить вокруг да около. Но это мои догадки вилами по воде, конечно.

mwizard
31.01.2017 10:59+2И ни слова про bias. Разбирайтесь лучше с базовой структурой сетей, автор.
EmeraldSoft
04.02.2017 21:12-2Я с ней давно разобрался. В этой статье хотелось рассказать самое главное, в следующий раз обязательно расскажу. Спасибо.

aso
31.01.2017 11:082. Если нейронная сеть ошиблась и не дала правильный ответ(распознала неверно), то весовые коэффициенты уменьшаются.
«Ложное срабатывание», ака «ошибка второго рода»?
3. Если нейронная сеть ошиблась и отвергла правильный ответ, то весовые коэффициенты увеличиваются.
Пропуск цели, ошибка первого рода.
С подсчётом слоёв не всё так однозначно — паходу «входной слой» не все не всегда учитывают — собственно нередко это вовсе не нейроны, а непосредственно входные датчики.
С другой стороны — сеть Хопфилда — имеет «просто» один слой, без входного — зато связь нейронов друг с другом вида «все со всеми».

mopsicus
31.01.2017 11:14Статья полугодичной давности, тоже простыми словами, тоже про девушек, но более понятная, как мне кажется.
alex87is
31.01.2017 12:55-4Статья понравилась :) Спасибо. Ясно-понятно. Не без небольших грехов, но люблю когда в статьи так сказать вкладывают душу — красиво оформляют и тп. Давно хотел прочитать такую, но все ленился))) А тут на работе выплася свободный часик и и хорошая статья! Хорошее утро!)
Чем больше читаю про Машинное обучение, тем больше понимаю, что самое «крутое» в этом — название))

Landgraph
31.01.2017 14:31Гм… Автор, спасибо за статью! Я так понимаю, что с того момента, как я последний раз делал доклад на эту тему в мои бородатые школьные годы (начало нулевых) ничего принципиально не изменилось?
В то время всё сильно буксовало из-за недостаточной вычислительной мощности, конкретно я тогда занимался направлением распараллеливания вычислений дабы повысить параллелизм работы этих «нейронов»…
А я-то думал… Но с другой стороны это и хорошо, можно смело «возвращаться» =)rkfg
31.01.2017 15:11+1Случился синергетический эффект. С одной стороны, выросли вычислительные мощности, видеокарты, ускоряющие обучение нейросети на порядок в сравнении с топовым процессором, есть практически в каждом доме, что уж говорить о корпорациях с CUDA-кластерами. С другой стороны, интернет, который раньше был сильно меньше и медленнее, обеспечивает эти сети огромными корпусами данных на любой вкус, будь то книги, субтитры к фильмам, твиты или ревью. Только обработай для подачи на вход и вперёд. И конечно, после первого бума и забытия нейросетей появились оригинальные алгоритмы типа LSTM (помоложе) и конволюционных сетей (постарше). Их комбинация позволяет получать, например, описание изображения текстом.
masai
31.01.2017 18:56Вообще, изменилось много чего. Просто большинство таких статей опирается на те же источники, что и раньше. А так, на практике однослойные перцептроны не используются. А значит и правило Хебба становится неактуальным, приходится вместо него использовать методы оптимизации посерьезнее: Adam, RMSProp и так далее. Они появились сравнительно недавно. Во всех статьях для начинающих любят писать про сигмоиду, но реально гораздо лучше использовать ReLU или softmax. Сети стали намного глубже, обычные методы оптимизации уже не справляются, поэтому вводят одинаковые веса для разных связей. Сейчас вообще очень много чего делают на сверточных сетях. Вместо многослойных сетей используют довольно кучерявые архитектуры с обратным связями. Много внимания уделяют проблеме переобученности, вводят dropout и другие подобные методики борьбы с ней.
В общем, очень много чего изменилось. Не судите о современном состоянии дел по таким вводным статьям.
RegisterWindowClassExA
31.01.2017 20:55Эммм… Тема градиентного спуска не раскрыта… У алгоритмов обучения ведь есть свой мат. модель.
Т.е. статья хорошая :) Отличная :) Но всем не угодишь. Кто-то вот пишет, что матан ему мешает. А мне наоборот без матана ничего не ясно в процессе обучения нейросети.
Нейронная сеть — это функция многих переменных. Иногда выход у неё тоже представляет собой несколько переменных. Для подбора коэффициентов таких функций используют метод градиентного спуска. Коэффициенты при переменной изменяются в положительном или отрицательном направлении частной производной функции от данной переменной. Это приводит к увеличению или уменьшению влияния этой переменной на значение функции. Сам метод обратного распространения ошибки построен по этому принципу.
В Вашем примере нужно классифицировать девушку на слишком высокую и слишком низкую. Например, тупая уродливая 500-метровая великанша пройдёт Ваш тест, с ней можно встречаться!
В общем, статья зачётная, спасибо :)

Timoschenko
31.01.2017 20:55Большое спасибо!
Мне нравится как вы все разжевываете. Я не математик, но это интересно и мне тоже. И иногда для простого человека некоторые вещи из математики трудно понять.
А у вас все понятно расписано.
Жду продолжение!
Melman898
31.01.2017 20:56чем то ТАУ это все напоминает…
сумматоры, веса…RegisterWindowClassExA
05.02.2017 08:44Ну, насколько я помню, нейронные сети это одна из составных частей ТАУ, точнее, современных методов ТАУ. А если Вы говорите о классической ТАУ, с передаточными функциями и т.п., то это очень сильно переработанная теория линейных дифференциальных уравнений. Т.е. связи между классической ТАУ и нейронными сетями нет. Но вообще нейронные сети применяются в управлении.

ehots
31.01.2017 20:57а может какой нибудь эксперт по нейронным сетям дать оценку статье и сказать стоит ли опираться на нее новичкам?
Iora
01.02.2017 12:20+2Не стоит. Если хотите адекватную теорию, то могу посоветовать Саймон Хайкин «Нейронные Сети: Полный курс», но ее лучше читать уже когда есть некоторые знания, она очень теоретическая. Также можно взять Галушкин А.И. «Нейронные сети: основы теории». Она весьма математическая, но подпйдет новичкам. Галушкин, кстати, автор метода обратного распространения ошибки, который активно в нейронных сетях используется. Научно-популярно есть Уоссермен «Нейрокомпьютерная техника». Есть курс Эндрю Ына (Andrew Ng) на Coursera «Machine Learning». Пример из курса приводился выше.
Crypt0r
04.02.2017 21:05+1Доступно написано, и это один из самых важных подходов. Создается впечатление, что некоторые комментаторы пытаются «выпендриться» (вот сейчас отхвачу).
Автор правильно делает, что не уподобляется стилю «зубрежных» учебников, где как под копирку сначала дается сухое определение изучаемого предмета, затем также сухо сама суть. Посмотрите не современные методы преподавания: людей учат понимать а не зубрить. Еще в школе мне попался учебник по английскому, написанный на… английском, — это Raymond Murphy, «English Grammar in Use». В книге нет определений как в школьных книгах, вообще! Читателя попросту подводят к пониманию предмета. Школьная литература и рядом с этой книгой не стояла, и это при том, повторю, что эта книга по английскому на английском.
inker
В этом месяце ещё не было.
noonv
Но автор, всё-таки, в предпоследний день успел :)