
Всем доброго времени суток! Я студент, для дипломной работы выбрал тему «информационные нейронные сети» (ИНС). Задачи, где требуется работать с числами, решались достаточно легко. И я решил усложнить систему, добавив обработку слов. Таким образом, я поставил перед собой задачу разработать «робота-собеседника», который мог бы общаться на какую-нибудь определённую тему.
Так как тема общения с роботом довольно обширна, диалог в целом я не оцениваю (привет товарищу Тьюрингу), рассматривается лишь адекватность ответа «собеседника» на реплику человека.
Далее будем называть вопросом предложение, поступающее на вход ИНС, и ответом предложение, полученное на её выходе.
Архитектура 1. Двухслойная нейронная сеть прямого распространения с одним скрытым слоем
Так как нейронные сети работают только с числами, необходимо закодировать слова. Для простоты из рассмотрения исключены знаки препинания, с заглавной буквы пишутся только имена собственные.
Каждое слово кодируется двумя целыми числами, начиная с единицы (ноль отвечает за отсутствие слова) — номером категории и номером слова в этой категории. Предполагалось в «категории» хранить слова, близкие по смыслу или типу (цвета, имена, например).
Таблица 1
| |
Категория 1 |
Категория 2 |
Категория 3 |
Категория 4 |
| 1 2 3 4 5 6 7 |
ты твой тебя твои тебе тобой я |
хорошо прекрасно замечательно превосходно хороший хорошим хорошие |
плохо ужасно отвратительно плохой плохие |
привет здравствуй приветствую приветик здорова |
Для нейронной сети данные нормализуются, приводятся к диапазону . Номер категории и слова — на максимальное значение номера категории или слова во всех категориях. Предложение переводится в вещественный вектор фиксированной длины, недостающие элементы заполняются нулями.
Каждое предложение (вопрос и ответ) может состоять максимум из десяти слов. Таким образом получается сеть с 20 входами и 20 выходами.
Необходимое число связей в сети для запоминания N примеров рассчитывалось по формуле
где m — число входов, n — число выходов, N — число примеров.
Число связей в сети с одним скрытым слоем, состоящим из H нейронов
откуда требуемое число скрытых нейронов
Для , получается соответствие
В результате получаем зависимость числа скрытых нейронов от количества примеров:
Структура обучаемой сети представлена на рисунке 1.
Рисунок 1. Простейшая ИНС для запоминания предложений
Реализована сеть в MATLAB, обучение — метод обратного распространения ошибки. Обучающая выборка содержит 32 предложения…
Большего и не потребовалось…
ИНС не могла запомнить более 15 предложений, что демонстрирует следующий график (рисунок 2). Ошибка вычисляется как модуль разности между текущим выходом НС и требуемым.
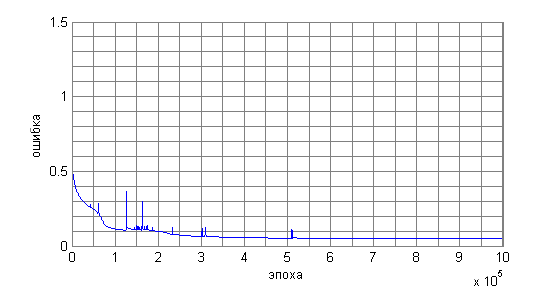
Рисунок 2. Ошибка НС при обучении на 32 примерах
Пример диалога (все вопросы из обучающей выборки):
|
|
В результате тестирования для различного количества примеров стало понятно, что даже обучающую выборку ИНС запоминает с большим трудом (что видно из рисунка 2). Даже за миллион эпох ошибка не смогла уменьшиться до требуемого значения.
Архитектура 2. Двухслойная нейронная сеть прямого распространения
Следующий способ закодировать слова для ИНС — one-hot-кодировка[4]. Суть её в следующем: пусть в словаре имеется слов, упорядоченных по алфавиту. Каждое слово такого словаря кодируется вектором длины , содержащим единицу на месте, соответствующем номеру слова в словаре и нули на других местах.
Для экспериментов был создан словарь из слов и обучающий набор из 95 предложений. На вход НС подавалось шесть слов и ответ также рассматривался из шести слов.
Число нейронов в скрытом слое определялось по зависимости числа связей от числа примеров, которые сеть может выучить без ошибок.
|
|
По результатам видно, что теперь система может запоминать большее количество слов. Почти победа… но возникает другая проблема — определение синонимов и похожих слов[4].
Архитектура 3. Двухслойная нейронная сеть прямого распространения
с одним скрытым слоем и word2vec-кодировка
Для решения проблемы похожести слов и синонимов решил попробовать word2vec[4], который позволяет нужным образом закодировать слова.
Для экспериментов по работе сети использовался словарь word2vec векторов длины , обученный на тренировочной базе нейронной сети.
На вход нейронной сети подаётся шесть слов (вектор длины 300) и предлагается получить ответ, также состоящий из шести слов. При обратном кодировании вектор предложения разделяется на шесть векторов слов, для каждого из которых в словаре ищется максимально возможное соответствие по косинусу угла между векторами и :
Но даже при такой реализации word2vec не делает нужных связей между словами с точки зрения русского языка. Для создания словаря, в котором именно синонимы будут находиться максимально рядом был сформирован корпус обучения с сгруппированными синонимами, по возможности сочетающиеся по смыслу друг с другом:
| МНЕ МОЙ МЕНЯ Я МОЁ МОИХ ТЫ ТЕБЯ ТЕБЕ ТВОИ ТВОЙ ТВОЁ ТОБОЙ НЕ НЕТ НА У С И ДА ДО О ЧЁМ А ТОЖЕ ДАЖЕ ТОЛЬКО ЭТО КТО ЧТО ТАКОЙ РОДИЛСЯ РОЖДЕНИЯ РОБОТ РОБОТАМ РОБОТЫ РОБОТОВ РОБОТАМИ |
В результате такого представления отпадает необходимость запоминать множество синонимов, на которые можно давать одинаковый ответ (типа «привет», «здравствуйте», «приветствую»). Например, в обучающей выборке участвовала только «здравствуй — привет», остальные ответы получены из-за большой косинусной близости «здравствуй», «привет» и «приветствую».
|
|
Однако вместе с этим, из-за большой близости синонимов в ответе (беседа=беседую=беседовал=…, я=меня=моё=мне=…) они чаще всего путаются при незначительной переформулировке вопроса («Как ты учишься?» Вместо «Как ты учишься у человека?»).
Злоключение
Как видите, при попытке использовать ИНС для общения с человеком, у меня получилось «две блондинки»: одна не может запомнить больше 15 предложений, а вторая много знает, но ничего не понимает.
Судя по описаниям как на Хабрахабре, так и на других сайтах, с такой проблемой сталкиваются не все. Поэтому возникает вопрос: где собака зарыта? Какой подход нужно использовать для получения ИНС, способной запоминать и понимать хотя бы 100 – 200 фраз?
Кто сталкивался с подобными вопросами, прошу ваших советов и предложений.
Список литературы
- Как понять LSTM-сети
- Разработка: Chatbot на нейронных сетях
- Разработка: Библиотека машинного обучения Google TensorFlow – первые впечатления и сравнение с собственной реализацией
- Разработка: Классификация предложений с помощью нейронных сетей без предварительной обработки
- Разработка: Русский нейросетевой чатбот
Комментарии (18)

Iora
16.02.2017 18:32+3«информационные нейронные сети» (ИНС)
А бывают «не-информационные»? А как же понятие «искусственные нейронные сети» (ИНС)?
Roman_Kh
16.02.2017 19:26+1Вы все примеры приводите с feed-forward сетями, а в списке литературы у вас фигурируют LSTM-сети. Попробуйте их — результат станет лучше.
daiver19
16.02.2017 21:20+3Детский сад какой-то. Не хочу никого обидеть, но если человек кодирует слова числами и приводит их к диапазону 0,1, то он как очень, очень плохо знакомился с литературой.
А вообще задача мне кажется весьма сложной для НС. Я бы смотрел в сторону sequence2sequence моделей, которые что-то вроде вход — LSTM — hidden — LSTM — выход. Эмбеддинг скорее всего тоже надо. Ну и тренировать на сотнях тысяч диалогов.olegas5
16.02.2017 22:08Так тот вариант всего лишь пробный был. Вот как закодировать синонимичность в словах, именно синонимичность, а не факт, что эти слова чаще всего стоят рядом.
daiver19
16.02.2017 22:46+1Синонимичность неплохо должна быть уловлена эмбеддингом (в случае если она вообще релевантна задаче)

SADKO
17.02.2017 11:53де собака зарыта? Какой подход нужно использовать для получения ИНС, способной запоминать и понимать хотя бы 100 – 200 фраз?
Собака в том, что эта задача не для ИНС в чистом виде, а для Марковских цепей, например…
… у каждой из технологий ткн. «искусственного интеллекта» есть конкретные специфики применения, а попытка реализации чат-бота на ИНС это как сайты на ассемблере делать, в принципе возможно, но один хрен придётся реализовывать всю технологическую цепочку. ИНС на это в принципе способна, вопрос лишь в размерах и времени обучения, но без гарантий что «понимание» обученной сети будет именно тем, что вам требуется…

ConceptDesigner
17.02.2017 11:58А зачем использовать нейронные сети при моделировании цепочек? НС подходят для классификационных задач. Для моделирования цепочек лучше использовать скрытые Марковские модели, например, или Conditional random fields (к сожалению, не знаю, как это по-русски). Также не совсем понятно, как можно синтезировать связный текст без привлечения синтаксического и морфологического анализа.
erwins22
17.02.2017 12:42syntaxNet
позволяет преобразовать текст в в иерархическую структуру и назад выделяя морфологические виды слов
Yane
17.02.2017 16:20300-мерные входные данные и всего 95 обучащюих пар?
Делать самостоятельно маленький текстовый корпус, когда есть готовые и большие?
Взять для работы с последовательностями прямую сеть вместо полагающейся рекуррентной?
Матлаб, а не ставший стандартным в этой области питон (theano/tensorflow etc)?
Необычно.
Но даже при такой реализации word2vec не делает нужных связей между словами с точки зрения русского языка.
Вот классическая реализация ворд2век. Она хорошо выискивает связи. Например, vec(“Madrid”) — vec(“Spain”) + vec(“France”) выдаст ~ vec(“Paris”)
ИНС не могла запомнить более 15 предложений
Обычно стремятся избежать, чтоб нейросеть запоминала обучающие примеры (переобучение). Заставляют генерализовать. Если хочется, чтобы модель быстро запоминала маппинг «вопрос»-«ответ», то это не к обычным нейросетям. Возможно, стоит глянуть one-shot learning.olegas5
17.02.2017 17:12-1После этих опытов да, потихоньку перехожу на Python TensorFlow/Keras.
По поводу обучения word2vec: возможно, на большом корпусе он будет лучше работать. А если нужных мне слов в этом корпусе нет? Всё же придётся добавлять самому.
Для диалога в целом: если делать робота с собственными мозгами, базу реплик, даже готовую, как минимум, прочесть придётся.
За one-short learning спасибо. Посмотрю, что этот метод может.
А вообще, хорошо бы и все примеры запомнить, и обобщить достаточно неплохо.

vladshow
17.02.2017 22:08Можете попробовать библиотеку RecurrentJS https://github.com/karpathy/recurrentjs с реализацией рекуррентной нейронной сети на JavaScript. В репозитории есть демо пример character_demo.html использования библиотеки для генерации текстов посимвольно. В своем приложении ChatBot https://play.google.com/store/apps/details?id=svlab.chatbot2 для режима рекуррентная нейронная сеть я использовал эту библиотеку с небольшими изменениями демо примера. Вместо посимвольного кодирования я использовал кодирование по словам. Также использовал библиотеку Az.js https://github.com/deNULL/Az.js/tree/master в качестве морфологического анализатора. Почитать про алгоритм чат бота на основе рекуррентной нейронной сети можно в статье https://habrahabr.ru/post/304284/ или elibrary.ru/item.asp?id=27405153

ilyaplot
Сложилось впечатление, что я открыл хорошо оформленный вопрос на stackoverflow.