
В этот раз мы решили разнообразить поток технических интервью реальным хардором и подготовили материал на основе доклада Руслана cheremin Черемина (Deutsche Bank) про анализ работы пары Escape Analysis и Scalar Replacement, сделанный им на JPoint 2016 в апреле минувшего года.
Видеозапись доклада перед вами:
А под катом мы выложили полную текстовую расшифровку с отдельными слайдами.
Начнем с небольшого лирического отступления, касающегося терминологии.
Escape-анализ — это техника анализа кода, которая позволяет статически (во время компиляции) определить область достижимости для ссылки какого-то объекта. Грубо говоря, есть инструкция, которая аллоцирует объект, и в ходе анализа мы пытаемся понять, может ли иная инструкция каким-то образом получить ссылку на созданный объект.
Escape-анализ — это не оптимизация сама по себе, это просто анализ, но его результаты могут использоваться для последующих оптимизаций. Обычно, конечно, нас интересует достижимость не с точностью до инструкции, а что-то вроде «достижим ли объект, созданный в некотором методе — вне этого метода». И в рамках задачи оптимизации нас больше всего интересуют ситуации, где ответ будет «нет, вне метода объект не достижим».
Скаляризация (Scalar Replacement). Скаляризация — это замена объекта, который существует только внутри метода, локальными переменными. Мы берем объект (по факту его еще нет — он будет создан при выполнении программы) и говорим, что нам его создавать не нужно: мы можем все его поля положить в локальные переменные, трансформировать код так, чтобы он обращался к этим полям, а аллокацию из кода стереть.
Мне нравится метафора, что EA/SR это такой статический garbage collector. Обычный (динамический) GC выполняется в рантайме, сканирует граф объектов и выполняет reachability analysis — находит уже не достижимые объекты и освобождает занятую ими память. Пара «escape-анализ — скаляризация» делает то же самое во время JIT-компиляции. Escape-анализ также смотрит на код и говорит: «Созданный здесь объект после этой инструкции уже ниоткуда не достижим, соответственно при определенных условиях мы можем его вообще не создавать».
Пара Escape Analysis и Scalar Replacement появилась в Java уже довольно давно, в 2009-м, сначала как экспериментальная опция, а с 2010 была включена по умолчанию.
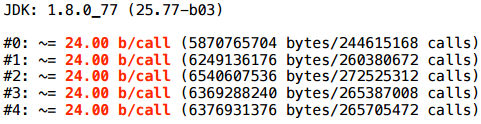
Есть ли результаты? В узких кругах в Deutsche Bank ходит реальный фрагмент графика загрузки garbage collector-а, сделанный в 2010 году. Картинка иллюстрирует, что иногда для оптимизации можно вообще ничего не делать, а просто дождаться очередного апдейта Java.
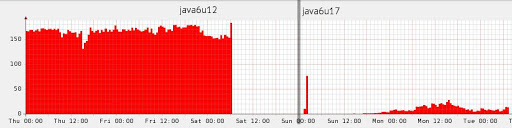
Источник: dolzhenko.blogspot.ru
Конечно, так бывает очень редко, это исключительный случай. В более реалистичных примерах по разным данным в среднестатистическом приложении escape-анализ способен устранить порядка 15% аллокаций, ну, а если сильно повезет — то до 70%.
Когда этот инструмент вышел в 2010 году, я был, честно говоря, очень им вдохновлен. Я тогда как раз только закончил проект, где было много околонаучных вычислений, в частности, мы активно жонглировали всякими векторами. И у нас было очень много объектов, которые живут от предыдущей инструкции до следующей. Когда я на это смотрел, у меня в голове возникала крамольная мысль, что на С здесь было бы лучше. И прочитав про эту оптимизацию, я понял, что она могла бы решить подобные проблемы. Однако у Sun в релизе был очень скромный пример ее работы, поэтому я ждал какого-то более обширного описания (в каких ситуациях она работает, в каких — нет; что нужно, чтобы это работало). И ждал я довольно долго.
К сожалению, за 7 лет я нашел упоминания лишь о трех случаях применения, один из которых был примером самого Sun. Проблемой всех примеров было то, что в статьях приводился кусок кода с комментарием: «вот так оно работает». А если я переставлю инструкции — не сломается ли скаляризация от этого? А если вместо ArrayList я возьму LinkedList, будет ли это работать? Мне это было непонятно. В итоге я решил, что я так и не дождусь чужих исследований, т.е. эту работу придется сделать самому.
Что я хотел получить? В первую очередь, я хотел какое-то интуитивное понимание. Понятно, JIT-компиляция вообще — это очень сложная штука, и она зависит от многих вещей. Чтобы понимать ее в деталях, надо работать в Oracle. Такой задачи у меня не было. Мне необходимо какое-то интуитивное понимание, чтобы я смотрел на код и мог оценить, что вот здесь — почти наверняка да, а тут — почти наверняка нет, а вот тут — возможно (надо исследовать, может удастся добиться, чтобы эта конкретная аллокация скаляризовалась). А для этого нужен какой-то набор примеров, на которых можно посмотреть, когда работает, когда не работает. И фреймворк, чтобы было легко писать эти примеры.
Прежде чем мы перейдем к самим экспериментам — еще небольшое теоретическое отступление. Важно понимать, что escape-анализ и скаляризация — это лишь часть большого набора оптимизаций, который есть в серверном компиляторе. В очень общих чертах процесс оптимизации C2 представлен на рисунке.
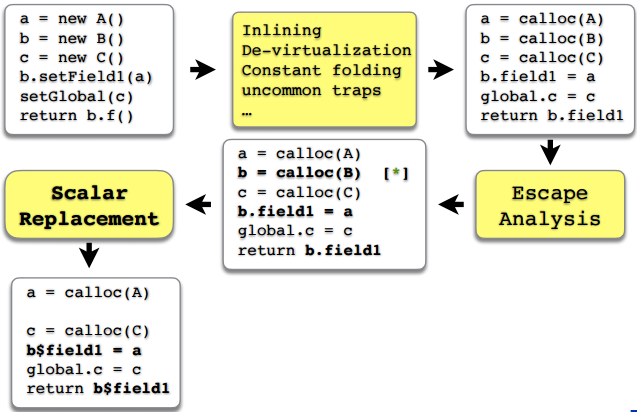
Важно здесь то, что еще до escape-анализа за дело берутся другие инструменты оптимизации. Например — инлайнинг, девиртуализация, сворачивание констант и выделение частых или не частых маршрутов (на самом деле их гораздо больше, но здесь я указал те, которые чаще всего влияют на escape-анализ). И чтобы, по результатам escape-анализа, какие-то объекты скаляризовались, необходимо, чтобы хорошо отработали все предыдущие звенья цепи, предыдущие оптимизации, до escape-анализа и скаляризации. И что-то сломаться, не получиться может на любом этапе, но, как мы увидим, чаще всего что-то ломается как раз-таки еще до escape-анализа. И лишь в некоторых случаях именно сам escape-анализ не справляется с задачей.

Несколько лет назад, пытаясь экспериментировать со скаляризацией, я в основном опирался на
Если результат теста нас удивляет, есть ключики PrintCompilation и PrintInlining, позволяющие получить больше информации. Есть еще третий ключик, LogCompilation, который выдает все то же самое, только гораздо больше, и в xml формате — его выдачу можно скормить утилитке JITWatch, которая вам все представит в красивом UI.
Логичен вопрос: почему бы не использовать JMH? JMH действительно может это делать. У него есть профайлер,

И поначалу и я пытался зайти с этой стороны. Но дело в том, что JMH в первую очередь заточен на перформанс, который меня не очень интересует. Меня не интересует, сколько времени у меня ушло на итерацию; меня интересует, сработала ли там конкретная оптимизация, иными словами, мне нужен триггерный ответ. А здесь очень много информации, которую я сходу не нашел, как убрать. И в итоге для себя решил, что если я хочу сегодня в течение получаса получить результат, то проще написать самому. Поэтому у меня есть свой «велосипед». Но если кто-то хочет продолжать эти эксперименты или делать какие-то свои, я очень рекомендую взять стандартный инструмент, поскольку стандартный обычно лучше.
Начнем с простого теста: похожего на пример в релизе Sun.
У нас есть простенький класс Vector2D. Мы создаем три случайных вектора с помощью рандома и выполняем с ними некую операцию (складываем и вычисляем скалярное произведение). Если мы запустим это в современной JVM, сколько объектов здесь будет создано?
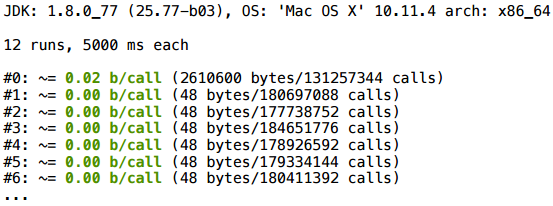
В результате в начале что-то аллоцируется (пока еще не прошла компиляция), ну а дальше все очень чистенько — 0 байт на вызов.
Это канонический пример, так что ничего удивительного в том, что он работает.
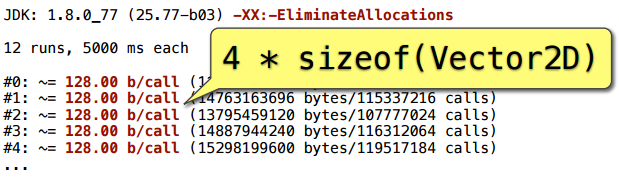
Для контроля добавляем ключ, отключающий стирание аллокаций — и мы получаем 128 байт на вызов. Это как раз четыре объекта Vector2D: три явно создались, и еще один появился в ходе сложения.
Добавим цикл в предыдущий пример.
Мы заводим вектор-аккумулятор, к которому будем добавлять вектора внутри цикла.

В этом сценарии все тоже хорошо (для любого значения
На этот раз сделаем умножение на константу — на double, а полученный результат запишем в ту же самую переменную. На самом деле это тот же аккумулятор, только здесь мы умножаем вектор на какое-то число.

Неожиданно, но здесь скаляризация не сработала (2080 байт = 32* (SIZE + 1)).
Прежде чем выяснять почему, рассмотрим еще пару примеров.
Более простой пример: у нас нет цикла, есть условный переход. Мы случайным образом выбираем координату и создаем Vector2D.

И здесь скаляризация не помогает: все время создается один вектор — те самые 32 байта.
Попробуем немного изменить этот пример. Я просто внесу создание вектора внутрь обеих веток:

И здесь все отлично скаляризуется.
Начинает вырисовываться картина — что здесь происходит?
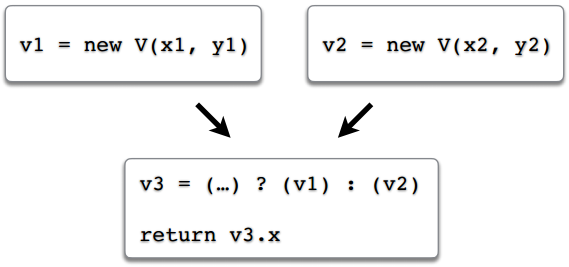
Представим, что у нас есть поток исполнения в программе. Есть одна ветвь, в которой мы создали объект v1, и вторая ветвь, в которой создали объект v2. В третью переменную, v3, мы записываем ссылку либо на первый объект, либо на второй, в зависимости от того, по какому маршруту пошло выполнение. В конце мы возвращаем какое-то поле через ссылку v3. Предположим, что произошла скаляризация и поля v1.x, v1.y, v2.x, v2.y превратились в локальные переменные, допустим, v1$x, v1$y, v2$x, v2$y. А что делать со ссылкой v3? А точнее: во что должно превратиться обращение к полю v3.x?
Это вопрос. В каких-то простых примерах, как здесь, или в примере 1.4, решение интуитивно понятно: если этот код, это все, что у нас есть — то нужно просто return внести внутрь условия, будет два return-а, по одному на каждую ветку, и каждый будет возвращать свое значение. Но случаи бывают более сложные, и в итоге разработчики JVM решили, что они просто не будут оптимизировать этот сценарий, т.к. в общем случае сделать это — разобраться, поле какого объекта нужно использовать — оказалось слишком сложно (см например баг JDK-6853701, или соответствующие комментарии в исходном коде JVM).
Подводя итог этому примеру, скаляризации не будет, если:
Если вы хотите увеличить шансы на скаляризацию, то одна ссылка должна указывать на один объект. Даже если она всегда указывает на один объект, но в разных сценариях исполнения это могут быть разные объекты — даже это сбивает с толку escape-анализ.
Это класс из commons.lang, идея которого состоит в том, что вы equals-ы можете генерировать таким вот образом, добавляя поля вашего класса в Builder. Честно говоря, я сам его не использую, мне просто нужен был пример какого-то Builder-а, и он попался под руку. Реальный пример обычно лучше, чем синтетический.
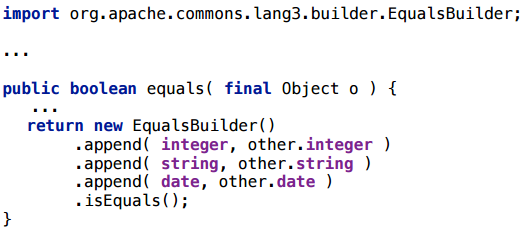
Конечно, было бы хорошо, если бы эта штука скаляризовалась, потому что создавать объекты на каждый вызов equals — не очень хорошая идея.
Я написал простой кусок кода — только два int-а, выписанных явно (но даже если бы там были указаны поля, сути это бы не изменило).

Вполне ожидаемо, эта ситуация скаляризуется.
Немного изменим пример: вместо двух int-ов поставим две строки.

В результате скаляризация не работает.
Не будем пока лезть в метод .append(...). Для начала у нас есть ключи, которые хотя бы вкратце рассказывают, что происходит в компиляторе.
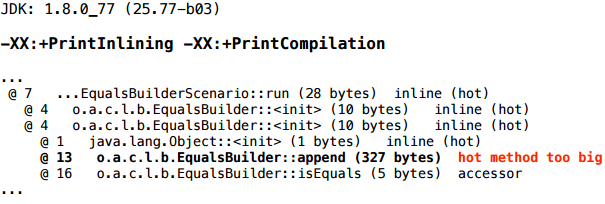
Выясняется, что метод append не заинлайнился, соответственно, escape-анализ не может понять: вот эта ссылка на builder, которая ушла внутрь метода .append() как this — что там с ней происходит, внутри метода? Это неизвестно (потому что внутрь метода .append компилятор не заглядывает — JIT не делает меж-процедурную оптимизацию). Может, ее там в глобальную переменную присвоили. И в подобных ситуациях escape-анализ сдается.
Что означает диагностика «hot method too big»? Она означает, что метод — горячий, т.е. вызывался достаточно много раз, и размер его байткода больше, чем некий предел, порог инлайнинга (предел именно для частых методов). Этот предел — он задается ключом FreqInlineSize, и по-умолчанию он 325. А в диагностике мы видим 327 — то есть мы промахнулись всего на 2 байта.
Вот содержимое метода — легко поверить, что там есть 327 байт:
Как мы можем проверить нашу гипотезу? Мы можем добавить ключ FreqInlineSize, и увеличить порог инлайнинга, допустим, до 328:
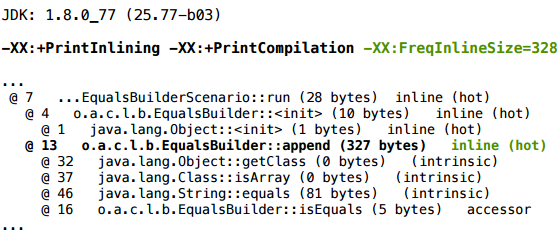
В профиле компиляции мы видим, что .append() теперь инлайнится, и все отлично скаляризуется:
Уточню: когда я здесь (и далее) меняю флаги JVM, параметры JIT-компиляции, я делаю это не для того, чтобы исправить ситуацию, а чтобы проверить гипотезу. Я бы не рекомендовал играться с параметрами JIT-компиляции, поскольку они подобраны специально обученными людьми. Вы, конечно, можете попробовать, но эффект сложно предсказать — каждый такой параметр влияет не на один конкретный метод, в котором захотелось что-то скаляризовать, а на всю программу в целом.
Пишите методы покороче. В частности, в примере с .append() есть большая простыня, которая работает с массивами — пытается сделать сравнение массивов. Если ее просто вынести в отдельный метод, то все отлично инлайнится и скаляризуется (я пробовал). Это такой черный (хотя может и белый) ход для этой эвристики инлайнинга: метод в 328 байт не инлайнится, но он же, разбитый на два метода по 200 байт — отлично инлайнится, потому что каждый метод по отдельности пролезает под порогом.
Рассмотрим возвращение из метода кортежа (tuple) — нескольких значений за раз.
Возьмем какой-нибудь простой объект, типа Pair, и совсем тривиальный пример: мы возвращаем пару строк, случайно выбранных из какого-то заранее заполненного пула. Чтобы компилятор вообще не выкинул этот код, я внесу некий побочный эффект: что-то с этими строками типа посчитаю, и верну результат.

Этот сценарий — скаляризуется. И это вполне рабочий пример, им можно пользоваться: если метод будет горячий и заинлайнится, такие multi-value return отлично скаляризуются.
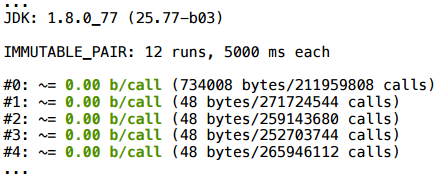
Немного изменим пример: при каких-то обстоятельствах вернем null.
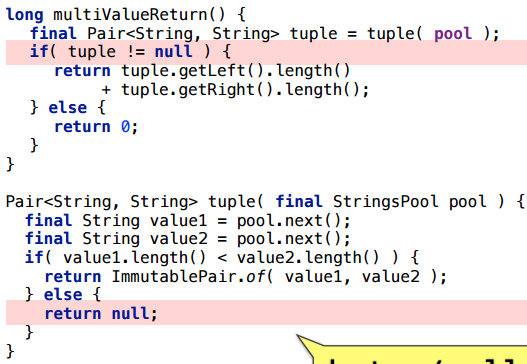
Как видно, аллокация останется (среднее количество байт на вызов не целое, потому что иногда возвращается null, который ничего не стоит).
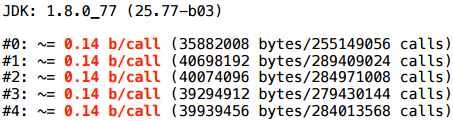
Более сложный пример: у нас есть интерфейс-Pair и 2 реализации этого интерфейса. В зависимости от искусственного условия, возвращаем либо ту реализацию, либо другую.
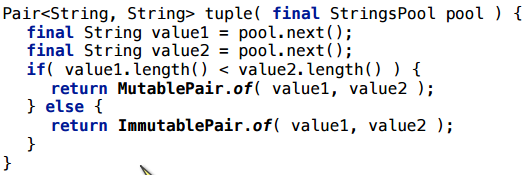
Здесь тоже остается аллокация:
Честно говоря, изначально я был уверен, что дело было именно в разных типах, и долго в это верил, пока не сделал следующий пример с одинаковыми типами, который также не скаляризуется.
Что здесь происходит? Ну, если мы попробуем ручками заинлайнить все методы, то увидим тот же сценарий с merge points (=ссылка может прийти двумя путями), что и в самом первом нашем эксперименте:

Будьте проще: меньше веток — меньше вероятность запутать escape-анализ
Еще один частый паттерн и очень часто появляющийся промежуточный объект, создания которого хотелось бы избежать.
Вот очень простой сценарий с итерацией по коллекции. Мы создаем коллекцию один раз, мы не пересоздаем ее на каждую итерацию, но мы пересоздаем итератор: на каждом запуске метода мы бежим по коллекции итератором, считаем некий побочный эффект (просто чтобы компилятор не выкинул этот кусок).

Рассмотрим этот сценарий для разных коллекций. Допустим, сначала для ArrayList-а
Для ArrayList-а итератор действительно скаляризуется (размер SIZE здесь взят условный: как правило, это стабильно работает для широкого спектра SIZE). Для LinkedList это тоже работает. Я не буду долго перебирать все варианты — вот сводная таблица тех коллекций, что я попробовал:
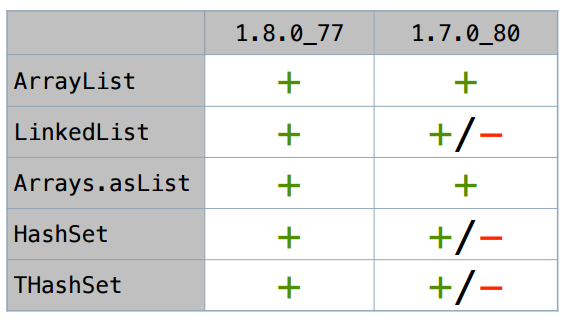
В Java 8 все эти итераторы (по крайней мере в простых сценариях) скаляризуются.
Но в самом свежем апдейте Java 7 все хитрее. Давайте мы на нее пристальнее посмотрим (все знают, что 1.7 уже end of life, 1.7.0_80 это последний апдейт, который есть).
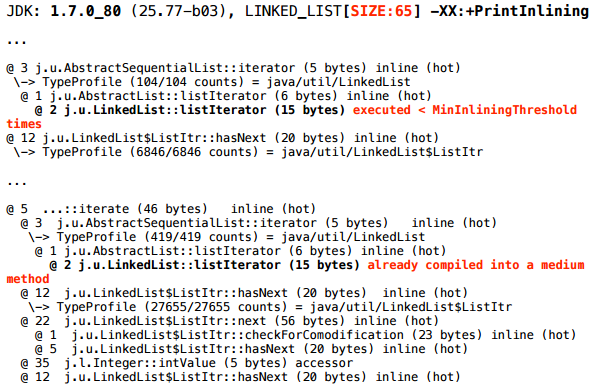
Для LinkedList с размером 2 все хорошо:
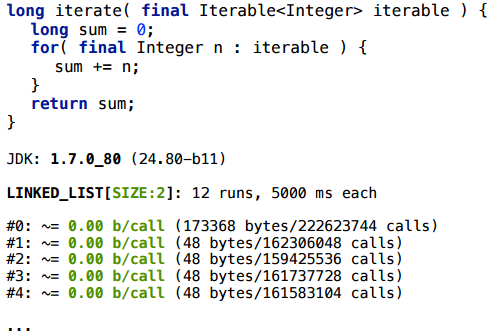
А вот для LinkedList с размером 65 — нет.
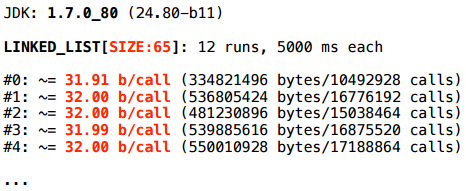
Что происходит?
Берем волшебные ключики, и для размера 2 мы получаем такой кусок лога инлайнинга:
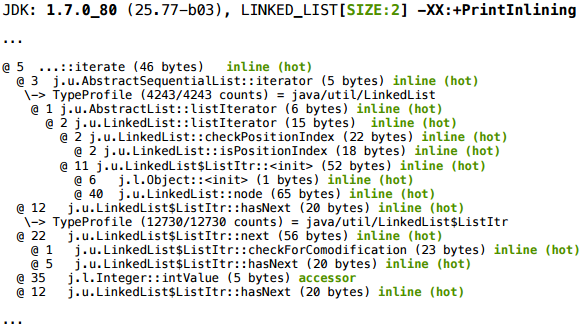
А для размера 65:
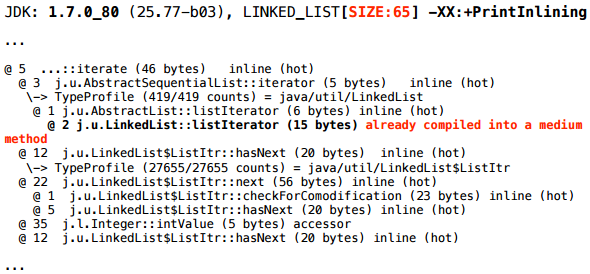
Ближе к началу того же лога можно найти еще вот такой дополнительный фрагмент картинки:
Происходит следующее: в самом начале метод, который мы профилируем, пошел на компиляцию — JIT поставил его в очередь. JIT работает асинхронно, т.е. у него есть очередь, туда скидываются задачи на компиляцию, а он в отдельном потоке (или даже нескольких потоках) с какой-то скоростью выгребает их из очереди, и компилирует. То есть между моментом, когда ему поставили задачу, и тем моментом, когда новый код будет оптимизирован, проходит некоторое время.
И вот наш метод
Да, а что именно означают диагностики:

Они означают, что, оценивая размер уже скомпилированных методов, мы смотрим на их машинный код, а не байт-код (т.к. это более адекватная метрика). И эти две эвристики — по размеру байт-кода и машинного кода — не обязательно согласованы. Метод из всего пяти байт-кодов может вызывать несколько других методов, которые будут вклеены, и увеличат размер его машинного кода выше порогов. С этой рассогласованностью ничего нельзя сделать кардинально, только подстраивать более-менее пороги разных эвристик, ну и надеяться, что в среднем все будет более-менее хорошо.
Пороги — в частности, InlineSmallCode — отличаются в разных версиях. В 8-ке InlineSmallCode вдвое больше, поэтому в Java 8 этот сценарий отрабатывает успешно: методы инлайнятся и итератор скаляризуется — а в 7-ке нет.
В этом примере важно, что он неустойчив. Вам должно (не)повезти, чтобы задачи на компиляцию пошли в таком порядке. Если бы на момент второй перекомпиляции метод
Мы можем проверить эту нашу гипотезу: поиграться с порогами. И действительно, при их подгонке скаляризация начинает срабатывать:
Есть отдельный интересный вариант коллекции — обертка вокруг массива, Arrays.asList(). Хотелось бы, чтобы эта обертка ничего не стоила, чтобы JIT ее скаляризовал.
Я начну здесь с довольно странного сценария — сделаю из массива список, а потом по списку пойду, как будто по массиву, индексом:
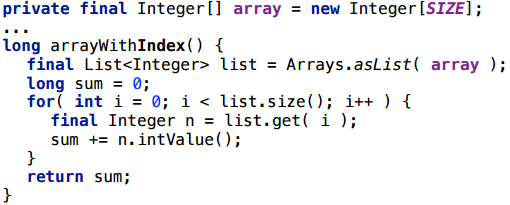
Здесь все работает, создание обертки скаляризуется.
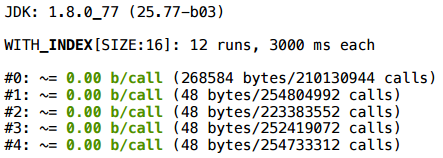
А теперь вернемся к итератору — нет же особого смысла оборачивать массив в список, чтобы потом ходить по списку, как по массиву:
Увы, даже в самой свежей версии java аллокация остается.
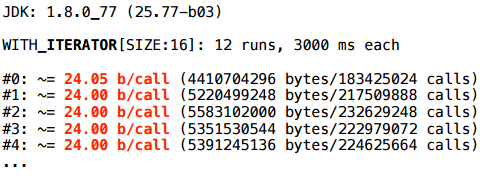
При этом в PrintInlining мы ничего особенного не видим.
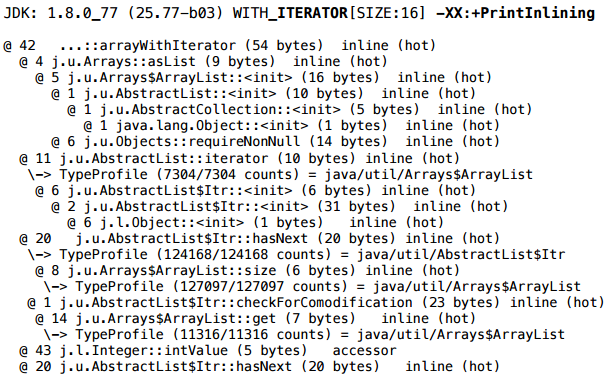
Но если посмотреть внимательнее, то заметно, что итератор в Arrays$ArrayList не свой — его реализация унаследована целиком от AbstractList-а:

И AbstractList$Itr — это внутренний класс, не-статический внутренний класс. И вот то, что он не-статический — почему-то мешает скаляризации. Если переписать класс итератора (то есть скопировать весь класс Arrays$ArrayList к себе, и модифицировать), сделать итератор «отвязанным» — в итератор передается массив, и итератор не содержит больше ссылки на объект списка — тогда в этом сценарии будет успешно скаляризоваться как аллокация итератора, так и аллокация самой обертки Arrays$ArrayList.

Это довольно загадочный случай, и, похоже, что это баг в JIT-е, но на сей день мораль такова: вложенные объекты сбивают скаляризацию с толку.
У нас есть еще сколько-то таких вот коллекций-синглетонов, и все они, и их итераторы, успешно скаляризуются и в актуальной, и в предыдущей версиях java, кроме упомянутого выше Arrays.asList.

Вложенные объекты не очень хорошо скаляризуются.
Сразу уточню — на скаляризацию массивов переменного размера (т.е. размера, который JIT не сумеет предсказать) даже не надейтесь. Мы работаем с массивами постоянной длины.
Рассмотрим такой пример: мы берем массив, туда что-то записываем по ячейкам, потом оттуда что-то вычитываем.

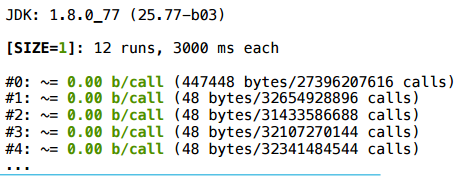
Для размера 1 — все нормально.
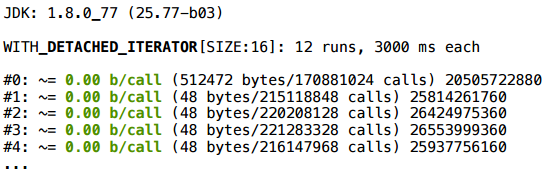
А для размера 2 — ничего не получается.
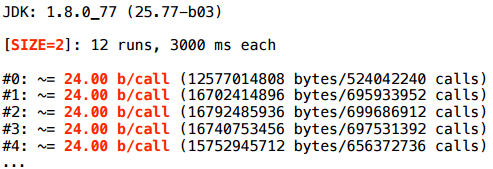
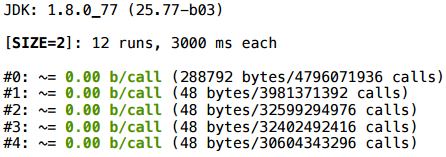
Попробуем немного другой доступ: возьмем тот же размер 2 и просто напросто развернем (unroll) цикл ручками — возьмем и обратимся по явному индексу:

В этом случае, как ни странно, скаляризация сработает.
Не буду долго рассуждать — ниже приведена сводная табличка. Этот случай с развернутым вручную циклом скаляризуется вплоть до размера 64. Если есть какой-то переменный индекс, размеры 1 и 2 еще кое-как скаляризуются, дальше — нет.
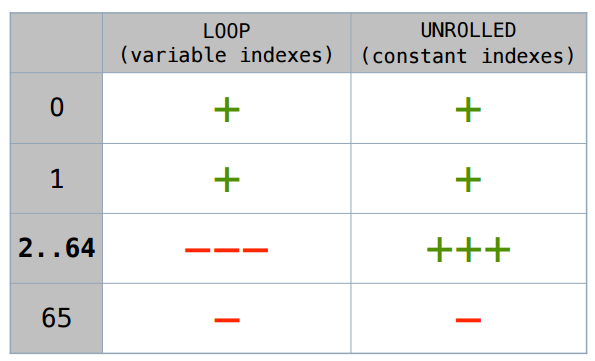
Как мне кто-то в блоге написал, в «JVM для всего есть свой ключик». Этот верхний порог (-XX:EliminateAllocationArraySizeLimit = 64) также можно задавать, хотя, мне кажется, в этом нет смысла. В предельном случае будет 64 дополнительных локальных переменных, что слишком много.
Точно такой же код, только с массивом примитивных типов — int-ом, short-ом…

Все работает точно в тех же случаях, что и для объектов.
Почему не получается скаляризовать массив, по которому проходим циклом? Потому что непонятно, какой именно индекс скрывается за i. Если у вас есть в коде обращение типа array[2], то JIT может превратить это в локальную переменную типа array$2. А во что превратить array[i]? Нужно знать, чему именно равна i. В каких-то частных случаях, в случае коротких массивов JIT может это «угадать», в общем случае — нет.
В библиотеке guava есть такой замечательный метод, как
Здесь у меня пример, где expression генерируется случайно. И интересно: как зависит скаляризация массива vararg в этом примере от того, с какой вероятностью expression становится false?

Для начала возьмем вероятность провала — 10-7:
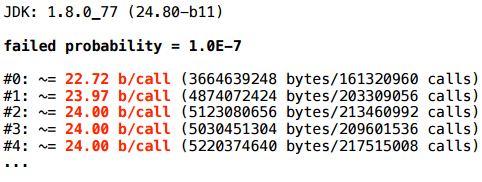
Здесь скаляризация не очень удается.
При уменьшении вероятности до 10-9, поначалу все, вроде, идет в хорошую сторону, но потом все-таки скаляризация отваливается.
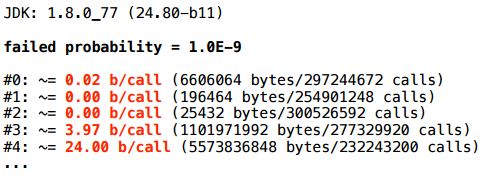
Если же вероятность совсем маленькая, мы более-менее стабильно приходим сюда:
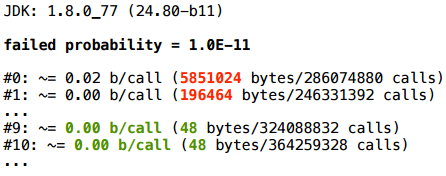
… к устойчивой скаляризации.
Получается, что такой паттерн — с checkArguments, или аналогичным vararg — можно использовать, можно рассчитывать на скаляризацию, но только если вы действительно ожидаете, что expression никогда не будет false. В случае с checkArguments, если expression оказывается false, то это вообще-то означает, что мы наступили на какой-то баг в своем коде. И если у нас нет багов, то, по крайней мере в горячем коде, этот false никогда не возникает, и вся эта конструкция с vararg в идеале ничего не будет нам стоить, с точки зрения аллокации.
Что не очень радует: скаляризация иногда хрупкая и не стабильная (особенно в несвежих JVM). Иногда все зависит от того, в каком порядке задачи пошли на компиляцию, и это конечно огорчает. Нужно понимать ограничения и всегда полезно тестировать важные сценарии. Если в критичном по перформансу коде есть расчет на какую-то скаляризацию, это обязательно нужно протестировать.
Напоследок — краткая сводка рекомендаций:
Если вы дочитали до конца и вам хочется еще – в апреле мы проводим JPoint 2017 (7-8 апреля) в Москве и JBreak 2017 (4 апреля) в Новосибирске. Предварительные программы обеих конференций уже готовы, много докладов опубликовано – есть на что посмотреть, поэтому рекомендую.
Видеозапись доклада перед вами:
А под катом мы выложили полную текстовую расшифровку с отдельными слайдами.
Начнем с небольшого лирического отступления, касающегося терминологии.
Escape-анализ и его место в оптимизации
Escape-анализ — это техника анализа кода, которая позволяет статически (во время компиляции) определить область достижимости для ссылки какого-то объекта. Грубо говоря, есть инструкция, которая аллоцирует объект, и в ходе анализа мы пытаемся понять, может ли иная инструкция каким-то образом получить ссылку на созданный объект.
Escape-анализ — это не оптимизация сама по себе, это просто анализ, но его результаты могут использоваться для последующих оптимизаций. Обычно, конечно, нас интересует достижимость не с точностью до инструкции, а что-то вроде «достижим ли объект, созданный в некотором методе — вне этого метода». И в рамках задачи оптимизации нас больше всего интересуют ситуации, где ответ будет «нет, вне метода объект не достижим».
Скаляризация (Scalar Replacement). Скаляризация — это замена объекта, который существует только внутри метода, локальными переменными. Мы берем объект (по факту его еще нет — он будет создан при выполнении программы) и говорим, что нам его создавать не нужно: мы можем все его поля положить в локальные переменные, трансформировать код так, чтобы он обращался к этим полям, а аллокацию из кода стереть.
Мне нравится метафора, что EA/SR это такой статический garbage collector. Обычный (динамический) GC выполняется в рантайме, сканирует граф объектов и выполняет reachability analysis — находит уже не достижимые объекты и освобождает занятую ими память. Пара «escape-анализ — скаляризация» делает то же самое во время JIT-компиляции. Escape-анализ также смотрит на код и говорит: «Созданный здесь объект после этой инструкции уже ниоткуда не достижим, соответственно при определенных условиях мы можем его вообще не создавать».
Пара Escape Analysis и Scalar Replacement появилась в Java уже довольно давно, в 2009-м, сначала как экспериментальная опция, а с 2010 была включена по умолчанию.
Есть ли результаты? В узких кругах в Deutsche Bank ходит реальный фрагмент графика загрузки garbage collector-а, сделанный в 2010 году. Картинка иллюстрирует, что иногда для оптимизации можно вообще ничего не делать, а просто дождаться очередного апдейта Java.
Источник: dolzhenko.blogspot.ru
Конечно, так бывает очень редко, это исключительный случай. В более реалистичных примерах по разным данным в среднестатистическом приложении escape-анализ способен устранить порядка 15% аллокаций, ну, а если сильно повезет — то до 70%.
Когда этот инструмент вышел в 2010 году, я был, честно говоря, очень им вдохновлен. Я тогда как раз только закончил проект, где было много околонаучных вычислений, в частности, мы активно жонглировали всякими векторами. И у нас было очень много объектов, которые живут от предыдущей инструкции до следующей. Когда я на это смотрел, у меня в голове возникала крамольная мысль, что на С здесь было бы лучше. И прочитав про эту оптимизацию, я понял, что она могла бы решить подобные проблемы. Однако у Sun в релизе был очень скромный пример ее работы, поэтому я ждал какого-то более обширного описания (в каких ситуациях она работает, в каких — нет; что нужно, чтобы это работало). И ждал я довольно долго.
К сожалению, за 7 лет я нашел упоминания лишь о трех случаях применения, один из которых был примером самого Sun. Проблемой всех примеров было то, что в статьях приводился кусок кода с комментарием: «вот так оно работает». А если я переставлю инструкции — не сломается ли скаляризация от этого? А если вместо ArrayList я возьму LinkedList, будет ли это работать? Мне это было непонятно. В итоге я решил, что я так и не дождусь чужих исследований, т.е. эту работу придется сделать самому.
Путь экспериментов
Что я хотел получить? В первую очередь, я хотел какое-то интуитивное понимание. Понятно, JIT-компиляция вообще — это очень сложная штука, и она зависит от многих вещей. Чтобы понимать ее в деталях, надо работать в Oracle. Такой задачи у меня не было. Мне необходимо какое-то интуитивное понимание, чтобы я смотрел на код и мог оценить, что вот здесь — почти наверняка да, а тут — почти наверняка нет, а вот тут — возможно (надо исследовать, может удастся добиться, чтобы эта конкретная аллокация скаляризовалась). А для этого нужен какой-то набор примеров, на которых можно посмотреть, когда работает, когда не работает. И фреймворк, чтобы было легко писать эти примеры.
Моя задача была экспериментальной: допустим, у меня есть JDK на компьютере — какую информацию о принципах работы escape-анализа я могу вытащить, не обращаясь с вопросами к авторитетам? То есть это такой естественнонаучный подход: у нас есть почти черный ящик, в который мы «тыкаем» и смотрим, как он будет работать.
Прежде чем мы перейдем к самим экспериментам — еще небольшое теоретическое отступление. Важно понимать, что escape-анализ и скаляризация — это лишь часть большого набора оптимизаций, который есть в серверном компиляторе. В очень общих чертах процесс оптимизации C2 представлен на рисунке.
Важно здесь то, что еще до escape-анализа за дело берутся другие инструменты оптимизации. Например — инлайнинг, девиртуализация, сворачивание констант и выделение частых или не частых маршрутов (на самом деле их гораздо больше, но здесь я указал те, которые чаще всего влияют на escape-анализ). И чтобы, по результатам escape-анализа, какие-то объекты скаляризовались, необходимо, чтобы хорошо отработали все предыдущие звенья цепи, предыдущие оптимизации, до escape-анализа и скаляризации. И что-то сломаться, не получиться может на любом этапе, но, как мы увидим, чаще всего что-то ломается как раз-таки еще до escape-анализа. И лишь в некоторых случаях именно сам escape-анализ не справляется с задачей.
Инструментарий
Несколько лет назад, пытаясь экспериментировать со скаляризацией, я в основном опирался на
GarbageCollectorMXBean.getCollectionCount(). Это довольно грубая метрика. Но теперь у нас есть более ясная мерика — ThreadMBean.getThreadAllocatedBytes(threadId), который прямо по ID потока говорит, сколько байт было аллоцировано этим конкретным потоком. Для экспериментирования больше ничего и не надо, однако первую, старую, метрику я использовал поначалу, чтобы сверять результаты. Еще один способ контроля — отключить скаляризацию соответствующим ключом (-XX:-EliminateAllocations) и посмотреть, действительно ли наблюдаемый эффект определяется escape-анализом.Если результат теста нас удивляет, есть ключики PrintCompilation и PrintInlining, позволяющие получить больше информации. Есть еще третий ключик, LogCompilation, который выдает все то же самое, только гораздо больше, и в xml формате — его выдачу можно скормить утилитке JITWatch, которая вам все представит в красивом UI.
Логичен вопрос: почему бы не использовать JMH? JMH действительно может это делать. У него есть профайлер,
-prof gc, который выводит те же аллокации, и даже нормированные на одну итерацию. И поначалу и я пытался зайти с этой стороны. Но дело в том, что JMH в первую очередь заточен на перформанс, который меня не очень интересует. Меня не интересует, сколько времени у меня ушло на итерацию; меня интересует, сработала ли там конкретная оптимизация, иными словами, мне нужен триггерный ответ. А здесь очень много информации, которую я сходу не нашел, как убрать. И в итоге для себя решил, что если я хочу сегодня в течение получаса получить результат, то проще написать самому. Поэтому у меня есть свой «велосипед». Но если кто-то хочет продолжать эти эксперименты или делать какие-то свои, я очень рекомендую взять стандартный инструмент, поскольку стандартный обычно лучше.
Часть 1. Основы
Пример 1.1. Basic
Начнем с простого теста: похожего на пример в релизе Sun.

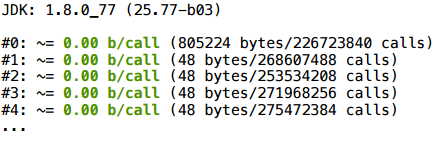
У нас есть простенький класс Vector2D. Мы создаем три случайных вектора с помощью рандома и выполняем с ними некую операцию (складываем и вычисляем скалярное произведение). Если мы запустим это в современной JVM, сколько объектов здесь будет создано?
В результате в начале что-то аллоцируется (пока еще не прошла компиляция), ну а дальше все очень чистенько — 0 байт на вызов.
Это канонический пример, так что ничего удивительного в том, что он работает.
Для контроля добавляем ключ, отключающий стирание аллокаций — и мы получаем 128 байт на вызов. Это как раз четыре объекта Vector2D: три явно создались, и еще один появился в ходе сложения.
Пример 1.2. Loop accumulate
Добавим цикл в предыдущий пример.
Мы заводим вектор-аккумулятор, к которому будем добавлять вектора внутри цикла.
В этом сценарии все тоже хорошо (для любого значения
SIZE, который я исследовал).Пример 1.3. Replace in loop
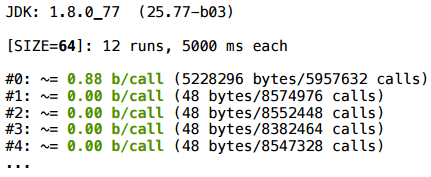
На этот раз сделаем умножение на константу — на double, а полученный результат запишем в ту же самую переменную. На самом деле это тот же аккумулятор, только здесь мы умножаем вектор на какое-то число.
Неожиданно, но здесь скаляризация не сработала (2080 байт = 32* (SIZE + 1)).
Прежде чем выяснять почему, рассмотрим еще пару примеров.
Пример 1.4. Control flow
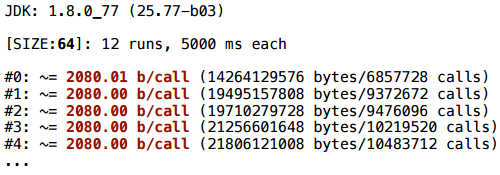
Более простой пример: у нас нет цикла, есть условный переход. Мы случайным образом выбираем координату и создаем Vector2D.
И здесь скаляризация не помогает: все время создается один вектор — те самые 32 байта.
Пример 1.5. Control flow
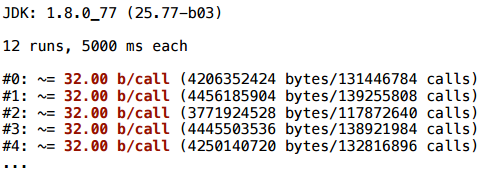
Попробуем немного изменить этот пример. Я просто внесу создание вектора внутрь обеих веток:
И здесь все отлично скаляризуется.
Начинает вырисовываться картина — что здесь происходит?
«Merge points»
Представим, что у нас есть поток исполнения в программе. Есть одна ветвь, в которой мы создали объект v1, и вторая ветвь, в которой создали объект v2. В третью переменную, v3, мы записываем ссылку либо на первый объект, либо на второй, в зависимости от того, по какому маршруту пошло выполнение. В конце мы возвращаем какое-то поле через ссылку v3. Предположим, что произошла скаляризация и поля v1.x, v1.y, v2.x, v2.y превратились в локальные переменные, допустим, v1$x, v1$y, v2$x, v2$y. А что делать со ссылкой v3? А точнее: во что должно превратиться обращение к полю v3.x?
Это вопрос. В каких-то простых примерах, как здесь, или в примере 1.4, решение интуитивно понятно: если этот код, это все, что у нас есть — то нужно просто return внести внутрь условия, будет два return-а, по одному на каждую ветку, и каждый будет возвращать свое значение. Но случаи бывают более сложные, и в итоге разработчики JVM решили, что они просто не будут оптимизировать этот сценарий, т.к. в общем случае сделать это — разобраться, поле какого объекта нужно использовать — оказалось слишком сложно (см например баг JDK-6853701, или соответствующие комментарии в исходном коде JVM).
Подводя итог этому примеру, скаляризации не будет, если:
- ссылочная переменная может указывать более чем на один объект;
- даже если такое может случиться в разных сценариях исполнения.
Если вы хотите увеличить шансы на скаляризацию, то одна ссылка должна указывать на один объект. Даже если она всегда указывает на один объект, но в разных сценариях исполнения это могут быть разные объекты — даже это сбивает с толку escape-анализ.
Часть 2. EqualsBuilder
Это класс из commons.lang, идея которого состоит в том, что вы equals-ы можете генерировать таким вот образом, добавляя поля вашего класса в Builder. Честно говоря, я сам его не использую, мне просто нужен был пример какого-то Builder-а, и он попался под руку. Реальный пример обычно лучше, чем синтетический.
Конечно, было бы хорошо, если бы эта штука скаляризовалась, потому что создавать объекты на каждый вызов equals — не очень хорошая идея.
Пример 2.1. EqualsBuilder
Я написал простой кусок кода — только два int-а, выписанных явно (но даже если бы там были указаны поля, сути это бы не изменило).
Вполне ожидаемо, эта ситуация скаляризуется.
Пример 2.2. EqualsBuilder
Немного изменим пример: вместо двух int-ов поставим две строки.
В результате скаляризация не работает.
Не будем пока лезть в метод .append(...). Для начала у нас есть ключи, которые хотя бы вкратце рассказывают, что происходит в компиляторе.
Выясняется, что метод append не заинлайнился, соответственно, escape-анализ не может понять: вот эта ссылка на builder, которая ушла внутрь метода .append() как this — что там с ней происходит, внутри метода? Это неизвестно (потому что внутрь метода .append компилятор не заглядывает — JIT не делает меж-процедурную оптимизацию). Может, ее там в глобальную переменную присвоили. И в подобных ситуациях escape-анализ сдается.
Что означает диагностика «hot method too big»? Она означает, что метод — горячий, т.е. вызывался достаточно много раз, и размер его байткода больше, чем некий предел, порог инлайнинга (предел именно для частых методов). Этот предел — он задается ключом FreqInlineSize, и по-умолчанию он 325. А в диагностике мы видим 327 — то есть мы промахнулись всего на 2 байта.
Вот содержимое метода — легко поверить, что там есть 327 байт:
Как мы можем проверить нашу гипотезу? Мы можем добавить ключ FreqInlineSize, и увеличить порог инлайнинга, допустим, до 328:
В профиле компиляции мы видим, что .append() теперь инлайнится, и все отлично скаляризуется:
Уточню: когда я здесь (и далее) меняю флаги JVM, параметры JIT-компиляции, я делаю это не для того, чтобы исправить ситуацию, а чтобы проверить гипотезу. Я бы не рекомендовал играться с параметрами JIT-компиляции, поскольку они подобраны специально обученными людьми. Вы, конечно, можете попробовать, но эффект сложно предсказать — каждый такой параметр влияет не на один конкретный метод, в котором захотелось что-то скаляризовать, а на всю программу в целом.
Вывод 2.
- Инлайнинг — лучший друг адаптивных рантаймов
- а краткость ему очень сильно помогает.
Пишите методы покороче. В частности, в примере с .append() есть большая простыня, которая работает с массивами — пытается сделать сравнение массивов. Если ее просто вынести в отдельный метод, то все отлично инлайнится и скаляризуется (я пробовал). Это такой черный (хотя может и белый) ход для этой эвристики инлайнинга: метод в 328 байт не инлайнится, но он же, разбитый на два метода по 200 байт — отлично инлайнится, потому что каждый метод по отдельности пролезает под порогом.
Часть 3. Multi-values return
Рассмотрим возвращение из метода кортежа (tuple) — нескольких значений за раз.
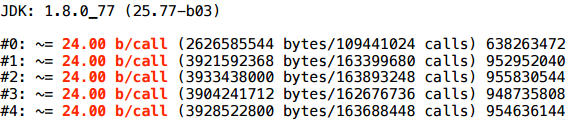
Возьмем какой-нибудь простой объект, типа Pair, и совсем тривиальный пример: мы возвращаем пару строк, случайно выбранных из какого-то заранее заполненного пула. Чтобы компилятор вообще не выкинул этот код, я внесу некий побочный эффект: что-то с этими строками типа посчитаю, и верну результат.
Этот сценарий — скаляризуется. И это вполне рабочий пример, им можно пользоваться: если метод будет горячий и заинлайнится, такие multi-value return отлично скаляризуются.
Пример 3.1. value or null
Немного изменим пример: при каких-то обстоятельствах вернем null.
Как видно, аллокация останется (среднее количество байт на вызов не целое, потому что иногда возвращается null, который ничего не стоит).
Пример 3.2. Mixed types?
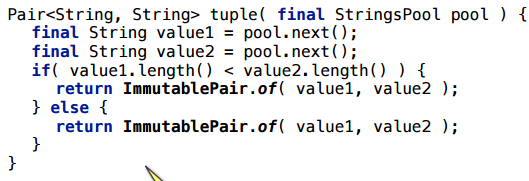
Более сложный пример: у нас есть интерфейс-Pair и 2 реализации этого интерфейса. В зависимости от искусственного условия, возвращаем либо ту реализацию, либо другую.
Здесь тоже остается аллокация:
Честно говоря, изначально я был уверен, что дело было именно в разных типах, и долго в это верил, пока не сделал следующий пример с одинаковыми типами, который также не скаляризуется.
Что здесь происходит? Ну, если мы попробуем ручками заинлайнить все методы, то увидим тот же сценарий с merge points (=ссылка может прийти двумя путями), что и в самом первом нашем эксперименте:
Вывод 3:
Будьте проще: меньше веток — меньше вероятность запутать escape-анализ
Пример 4. Итераторы
Еще один частый паттерн и очень часто появляющийся промежуточный объект, создания которого хотелось бы избежать.
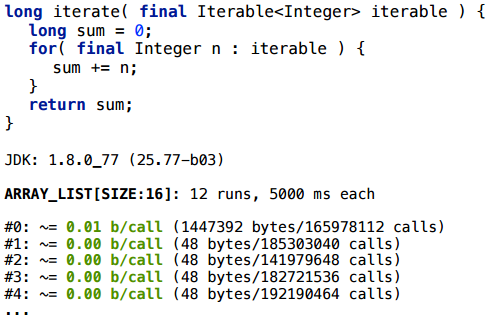
Вот очень простой сценарий с итерацией по коллекции. Мы создаем коллекцию один раз, мы не пересоздаем ее на каждую итерацию, но мы пересоздаем итератор: на каждом запуске метода мы бежим по коллекции итератором, считаем некий побочный эффект (просто чтобы компилятор не выкинул этот кусок).
Рассмотрим этот сценарий для разных коллекций. Допустим, сначала для ArrayList-а
Пример 4.1. ArrayList.iterator
Для ArrayList-а итератор действительно скаляризуется (размер SIZE здесь взят условный: как правило, это стабильно работает для широкого спектра SIZE). Для LinkedList это тоже работает. Я не буду долго перебирать все варианты — вот сводная таблица тех коллекций, что я попробовал:
В Java 8 все эти итераторы (по крайней мере в простых сценариях) скаляризуются.
Но в самом свежем апдейте Java 7 все хитрее. Давайте мы на нее пристальнее посмотрим (все знают, что 1.7 уже end of life, 1.7.0_80 это последний апдейт, который есть).
Для LinkedList с размером 2 все хорошо:
А вот для LinkedList с размером 65 — нет.
Что происходит?
Берем волшебные ключики, и для размера 2 мы получаем такой кусок лога инлайнинга:
А для размера 65:
Ближе к началу того же лога можно найти еще вот такой дополнительный фрагмент картинки:
Происходит следующее: в самом начале метод, который мы профилируем, пошел на компиляцию — JIT поставил его в очередь. JIT работает асинхронно, т.е. у него есть очередь, туда скидываются задачи на компиляцию, а он в отдельном потоке (или даже нескольких потоках) с какой-то скоростью выгребает их из очереди, и компилирует. То есть между моментом, когда ему поставили задачу, и тем моментом, когда новый код будет оптимизирован, проходит некоторое время.
И вот наш метод
iterate() пошел первый раз на компиляцию, в ходе которой обнаружилось, что метод LinkedList.listIterator() внутри него еще слишком мало выполнялся. Не наработал еще на то, чтобы его заинлайнить (MinInliningThreshold = 250 вызовов). Когда же, еще через некоторое время, вызов iterate() пошел на перекомпиляцию — обнаружилось, что скомпилированный (машинный) код LinkedList.listIterator() слишком большой. Да, а что именно означают диагностики:
Они означают, что, оценивая размер уже скомпилированных методов, мы смотрим на их машинный код, а не байт-код (т.к. это более адекватная метрика). И эти две эвристики — по размеру байт-кода и машинного кода — не обязательно согласованы. Метод из всего пяти байт-кодов может вызывать несколько других методов, которые будут вклеены, и увеличат размер его машинного кода выше порогов. С этой рассогласованностью ничего нельзя сделать кардинально, только подстраивать более-менее пороги разных эвристик, ну и надеяться, что в среднем все будет более-менее хорошо.
Пороги — в частности, InlineSmallCode — отличаются в разных версиях. В 8-ке InlineSmallCode вдвое больше, поэтому в Java 8 этот сценарий отрабатывает успешно: методы инлайнятся и итератор скаляризуется — а в 7-ке нет.
В этом примере важно, что он неустойчив. Вам должно (не)повезти, чтобы задачи на компиляцию пошли в таком порядке. Если бы на момент второй перекомпиляции метод
LinkedList.listIterator() еще не был бы скомпилирован независимо — у него еще не было бы машинного кода, и он бы прошел по критерию размера байт-кода и успешно заинлайнился бы. Именно поэтому результат и зависит от размера списка — от количества итераций внутри цикла зависит то, насколько быстро разные методы будут отправляться на компиляцию.Мы можем проверить эту нашу гипотезу: поиграться с порогами. И действительно, при их подгонке скаляризация начинает срабатывать:
Вывод 4:
- JVM первой свежести лучше, чем не первой свежести;
- -XX:+PrintInlining — очень хорошая диагностика, одна из основных, позволяющих понять, что происходит при скаляризации;
- тестируйте на реальных данных — я имею в виду, что не надо тестировать на размере 2, если вы ожидаете 150. Тестируйте на 150 и вы можете увидеть отличия;
- ArrayList опять обставил LinkedList!
Динамические рантаймы — это рулетка. JIT-компиляции свойственна недетерминированность, это неизбежно. В свежих версиях (8-ке) параметры эвристик чуть лучше согласованы друг с другом, но недетерминированности это не отменяет, просто ее сложнее поймать.
Пример 4.4. Arrays.asList()
Есть отдельный интересный вариант коллекции — обертка вокруг массива, Arrays.asList(). Хотелось бы, чтобы эта обертка ничего не стоила, чтобы JIT ее скаляризовал.
Я начну здесь с довольно странного сценария — сделаю из массива список, а потом по списку пойду, как будто по массиву, индексом:
Здесь все работает, создание обертки скаляризуется.
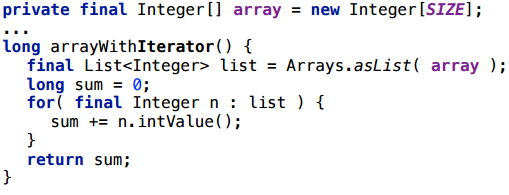
А теперь вернемся к итератору — нет же особого смысла оборачивать массив в список, чтобы потом ходить по списку, как по массиву:
Увы, даже в самой свежей версии java аллокация остается.
При этом в PrintInlining мы ничего особенного не видим.
Но если посмотреть внимательнее, то заметно, что итератор в Arrays$ArrayList не свой — его реализация унаследована целиком от AbstractList-а:
И AbstractList$Itr — это внутренний класс, не-статический внутренний класс. И вот то, что он не-статический — почему-то мешает скаляризации. Если переписать класс итератора (то есть скопировать весь класс Arrays$ArrayList к себе, и модифицировать), сделать итератор «отвязанным» — в итератор передается массив, и итератор не содержит больше ссылки на объект списка — тогда в этом сценарии будет успешно скаляризоваться как аллокация итератора, так и аллокация самой обертки Arrays$ArrayList.
Это довольно загадочный случай, и, похоже, что это баг в JIT-е, но на сей день мораль такова: вложенные объекты сбивают скаляризацию с толку.
Пример 4.4. Collections.*
У нас есть еще сколько-то таких вот коллекций-синглетонов, и все они, и их итераторы, успешно скаляризуются и в актуальной, и в предыдущей версиях java, кроме упомянутого выше Arrays.asList.
Вывод 4.4.
Вложенные объекты не очень хорошо скаляризуются.
- итерация по оберткам из Collections.* скаляризуется
- …Кроме Arrays.asList();
- вложенные объекты не скаляризуются (в том числе inner classes);
- -XX:+PrintInlining продолжает помогать в беде.
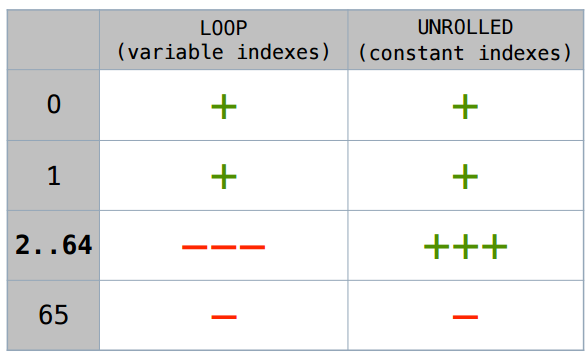
Пример 5. Constant size arrays
Сразу уточню — на скаляризацию массивов переменного размера (т.е. размера, который JIT не сумеет предсказать) даже не надейтесь. Мы работаем с массивами постоянной длины.
Пример 5.1. Variable index
Рассмотрим такой пример: мы берем массив, туда что-то записываем по ячейкам, потом оттуда что-то вычитываем.
Для размера 1 — все нормально.
А для размера 2 — ничего не получается.
Пример 5.2. Constant index
Попробуем немного другой доступ: возьмем тот же размер 2 и просто напросто развернем (unroll) цикл ручками — возьмем и обратимся по явному индексу:
В этом случае, как ни странно, скаляризация сработает.
Не буду долго рассуждать — ниже приведена сводная табличка. Этот случай с развернутым вручную циклом скаляризуется вплоть до размера 64. Если есть какой-то переменный индекс, размеры 1 и 2 еще кое-как скаляризуются, дальше — нет.
Как мне кто-то в блоге написал, в «JVM для всего есть свой ключик». Этот верхний порог (-XX:EliminateAllocationArraySizeLimit = 64) также можно задавать, хотя, мне кажется, в этом нет смысла. В предельном случае будет 64 дополнительных локальных переменных, что слишком много.
Пример 5.3. Primitive arrays
Точно такой же код, только с массивом примитивных типов — int-ом, short-ом…
Все работает точно в тех же случаях, что и для объектов.
Почему не получается скаляризовать массив, по которому проходим циклом? Потому что непонятно, какой именно индекс скрывается за i. Если у вас есть в коде обращение типа array[2], то JIT может превратить это в локальную переменную типа array$2. А во что превратить array[i]? Нужно знать, чему именно равна i. В каких-то частных случаях, в случае коротких массивов JIT может это «угадать», в общем случае — нет.
Пример 5.4. Preconditions
В библиотеке guava есть такой замечательный метод, как
checkArguments(expression, errorMessageTemplate, args...), который проверяет выражение expression, и выбрасывает исключение с форматированным сообщением если expression == false. У него последний аргумент — vararg, и это интересный пример, как продолжение темы с массивами. И весь этот массив аргументов нам реально нужен, реально используется внутри checkArguments только если expressions == false, если проверка провалилась. Здесь у меня пример, где expression генерируется случайно. И интересно: как зависит скаляризация массива vararg в этом примере от того, с какой вероятностью expression становится false?
Для начала возьмем вероятность провала — 10-7:
Здесь скаляризация не очень удается.
При уменьшении вероятности до 10-9, поначалу все, вроде, идет в хорошую сторону, но потом все-таки скаляризация отваливается.
Если же вероятность совсем маленькая, мы более-менее стабильно приходим сюда:
… к устойчивой скаляризации.
Получается, что такой паттерн — с checkArguments, или аналогичным vararg — можно использовать, можно рассчитывать на скаляризацию, но только если вы действительно ожидаете, что expression никогда не будет false. В случае с checkArguments, если expression оказывается false, то это вообще-то означает, что мы наступили на какой-то баг в своем коде. И если у нас нет багов, то, по крайней мере в горячем коде, этот false никогда не возникает, и вся эта конструкция с vararg в идеале ничего не будет нам стоить, с точки зрения аллокации.
Итог
- Скаляризуется многое из того, что хотелось бы (хотя здесь далеко не все примеры);
- что не скаляризуется, можно понять и простить (т.е. не всегда можно простить разработчика за это, но можно понять, почему это вышло: ментальную модель какую-то вполне реально создать, не слишком сложную); иногда исправить
- в свежих JVM скаляризация работает лучше.
Что не очень радует: скаляризация иногда хрупкая и не стабильная (особенно в несвежих JVM). Иногда все зависит от того, в каком порядке задачи пошли на компиляцию, и это конечно огорчает. Нужно понимать ограничения и всегда полезно тестировать важные сценарии. Если в критичном по перформансу коде есть расчет на какую-то скаляризацию, это обязательно нужно протестировать.
Напоследок — краткая сводка рекомендаций:
- самая свежая JVM;
- короткие методы (проверяем инлайнинг);
- меньше реального полиморфизма (вы можете оперировать интерфейсами, если реализация у него на самом деле 1; 2-3 — тоже неплохо, но, чем больше, тем сложнее);
- одна ссылка указывает на один объект;
- не использовать null — это все опять про простоту;
- не использовать вложенные объекты — это, конечно, ограничение неприятное, но с ним приходится жить;
- важные сценарии нужно тестировать.
Если вы дочитали до конца и вам хочется еще – в апреле мы проводим JPoint 2017 (7-8 апреля) в Москве и JBreak 2017 (4 апреля) в Новосибирске. Предварительные программы обеих конференций уже готовы, много докладов опубликовано – есть на что посмотреть, поэтому рекомендую.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Поделиться с друзьями
leotsarev
В последнем примере. Не знаю, как в Java, но в C# помогает унести редко используемую часть метода в отдельный метод. Тогда checkexpression устроится, а хелпер, бросающий exception, нет (что нам и нужно). Это более менее стандартный паттерн, хорошо виден по стектрейсам стандартных библиотек.
sunless
JIT заменит холодную часть метода на uncommon trap. В случае, если мы таки попали в редкую часть метода — управление свалится в интерпретатор, а в бэкграунде запиститься замещающая компиляция. Для хотспота я бы не стал разбивать код на хелпер методы, чтобы "помочь JITу".
cheremin
Смотря для чего "помогает". Вынесение редких кусков кода в отдельный метод — это и в джаве стандартный прием. Он помогает и с логической точки зрения — основная задача отделена от вспомогательных, и часто помогает JIT-у, потому что часто выполняющийся метод становится короче, и с большей вероятностью вклеивается. Но не в этом случае
Нет, это не то, что нам нужно, ровно наоборот: с точки зрения escape-анализа если ссылка уходит в невклеенный метод — это значит, что она "убегает" за границы анализа, т.е. доступна неопределенному кругу лиц. И значит никакой скаляризации, точка.
… Кроме случая, когда холодная ветка кода прямо совсем уж холодная — вообще ни разу не вызывалась за время сбора профиля. Тогда JIT может спекулятивно предположить, что этот кусок никогда и не будет вызываться, и скомпилировать метод вообще без этого куска, вставив охранную проверку, uncommon trap, со ссылкой на полную версию метода в интерпретируемом режиме, и рекомпиляцию. Именно это здесь и происходит, когда вероятность попадания на исключение пренебрежимо мала.
Если же вероятность попадания в редкую ветку все-таки не нулевая — то выносить ее в отдельный метод с точки зрения скаляризации как раз-таки хуже, потому что редкий метод скорее всего не будет вклеен. Здесь я разбирал такое на примере HashMap