
Я backend developer и очень часто на моих проектах не бывает выделенных админов (особенно в самом начале жизни продукта), поэтому я уже давно занимаюсь базовым администрированием серверов (начальная установка-настройка, бекапы, репликация, мониторинг и т.д.). Мне это очень нравится и я всё время узнаю что-то новое в этом направлении.
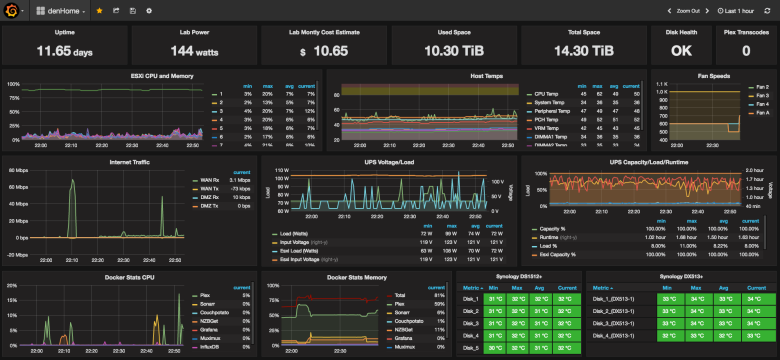
В большинстве случаев для проекта хватает одного сервера и мне как старшему разработчику (и просто ответственному человеку) всегда нужно было контролировать его ресурсы, чтобы понимать когда мы упрёмся в его ограничения. Для этих целей было достаточно munin.
Munin
Он легко устанавливается и имеет небольшие требования. Он написан на perl и использует кольцевую базу данных (RRDtool).
apt-get install munin munin-node
service munin-node start
Теперь munin-node будет собирать метрики системы и писать их в бд, а munin раз в 5 минут будет генерировать из этой бд html-отчёты и класть их в папку /var/cache/munin/www
Для удобного просмотра этих отчётов можно создать простой конфиг для nginx
server {
listen 80;
server_name munin.myserver.ru;
root /var/cache/munin/www;
index index.html;
}Собственно и всё. Уже можно смотреть любые графики использования процессора, памяти, жёсткого диска, сети и многого другого за день/неделю/месяц/год. Чаще всего меня интересовала нагрузка чтения/записи на жёсткий диск, потому что узким местом всегда была база данных.
Для мониторинга ресурсов сервера его всегда хватало, а для мониторинга доступности сервера использовался бесплатный сервис наподобие uptimerobot.com.
Я использую такую комбинацию для мониторинга своих домашних проектов на виртуальном сервере.
Если проект вырастает из одного сервера, тогда на втором сервере достаточно установить munin-node, а на первом — добавить в конфиге одну строчку для сбора метрик со второго сервера. Графики по обоим серверам будут раздельные, что не удобно для просмотра общей картины — на каком сервере заканчивается свободное место на диске, а на каком оперативная память. Эту ситуации можно исправить добавив в конфиг уже десяток строчек для агрегации одного графика с метриками с обоих серверов. Соответственно целесообразно это делать только для самых основных метрик. Если в конфиге сделать ошибку, то придётся долго читать в логах, что именно к ней привело и не найдя информации попытаться исправить ситуацию «методом тыка».
Стоит ли говорить, что для большего количества серверов это превращается в самый настоящий ад. Может это из-за того, что munin был разработан в 2003 году и изначально не был рассчитан на это.
Альтернативы munin для мониторинга нескольких серверов
Определил для себя необходимые качества, которыми должна обладать новая система мониторинга:
- количество метрик не меньше чем у munin (у него их около 30 базовых графиков и ещё около 200 плагинов в комплекте)
- возможность написания собственных плагинов на bash (у меня было два таких плагина)
- иметь небольшие требования к серверу
- возможность вывода метрик с разных серверов на одном графике без правки конфигов
- уведомления на почту, в slack и telegram
- Time Series Database более мощную чем RRDtool
- простая установка
- ничего лишнего
- бесплатно и с открытым исходным кодом
Я перечислю, всё что я рассматривал.
Cacti
Почти тоже самое, что munin только на php. В качестве базы данных можно использовать rrdtool как у munin или mysql. Первый релиз: 2001 год.
Ganglia
Почти тоже самое, что и предыдущие, написана на php, в качестве базы данных — rrdtool. Первый релиз: 1998 год.
Collectd
Ещё более простая система, чем предыдущие. Написан на c, в качестве базы данных — rrdtool. Первый релиз: 2005 год.

Graphite
Состоит из трёх компонент, написанных на python:
carbon собирает метрики их записывает их в бд
whisper — собственная rrdtool-подобная бд
graphite-web — интерфейс
Первый релиз: 2008 год.
Zabbix
Профессиональная система мониторинга, используется большинством админов. Есть практически всё, включая уведомления на почту (для slack и telegram можно написать простой bash-скрипт). Тяжёлая для пользователя и для сервера. Раньше приходилось пользоваться, впечатления, как будто вернулся с jira на mantis.
Ядро написано на c, веб интерфейс — на php. В качестве базы данных может использовать: MySQL, PostgreSQL, SQLite, Oracle или IBM DB2. Первый релиз: 2001 год.
Nagios
Достойная альтернатива Zabbix. Написан на с. Первый релиз: 1999 год.
Icinga
Форк Nagios. В качестве бд может использовать: MySQL, Oracle, and PostgreSQL. Первый релиз: 2009 год.
Небольшое отступление
Все вышеперечисленные системы достойны уважения. Они легко устанавливаются из пакетов в большинстве linux-дистрибутивов и уже давно используются в продакшене на многих серверах, поддерживаются, но очень слабо развиваются и имеют устаревший интерфейс.
В половине продуктов используются sql-базы данных, что является не оптимальным для хранения исторических данных (метрик). С одной стороны эти бд универсальны, а с другой — создают большую нагрузку на диски, а данные занимают больше места при хранении.
Для таких задач больше подходят современные бд временных рядов такие как ClickHouse.
Системы мониторинга нового поколения используют базы данных временных рядов, одни из них включают их в свой состав как неотделимую часть, другие используют как отдельную компоненту, а третью могут работать вообще без бд.
Netdata
Вообще не требует базы данных, но может выгружать метрики в Graphite, OpenTSDB, Prometheus, InfluxDB. Написана на c и python. Первый релиз: 2016 год.
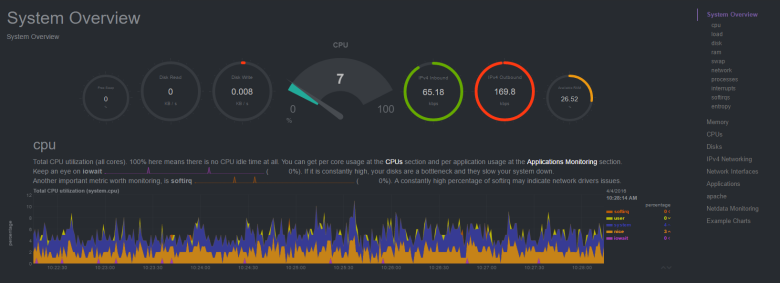
Prometheus
Состоит из трёх компонент, написанных на go:
prometheus — ядро, собственная встроенная база данных и веб-интерфейс.
node_exporter — агент, который может быть установлен на другой сервер и пересылать метрики в ядро, работает только с prometheus.
alertmanager — система уведомлений.
Первый релиз: 2014 год.
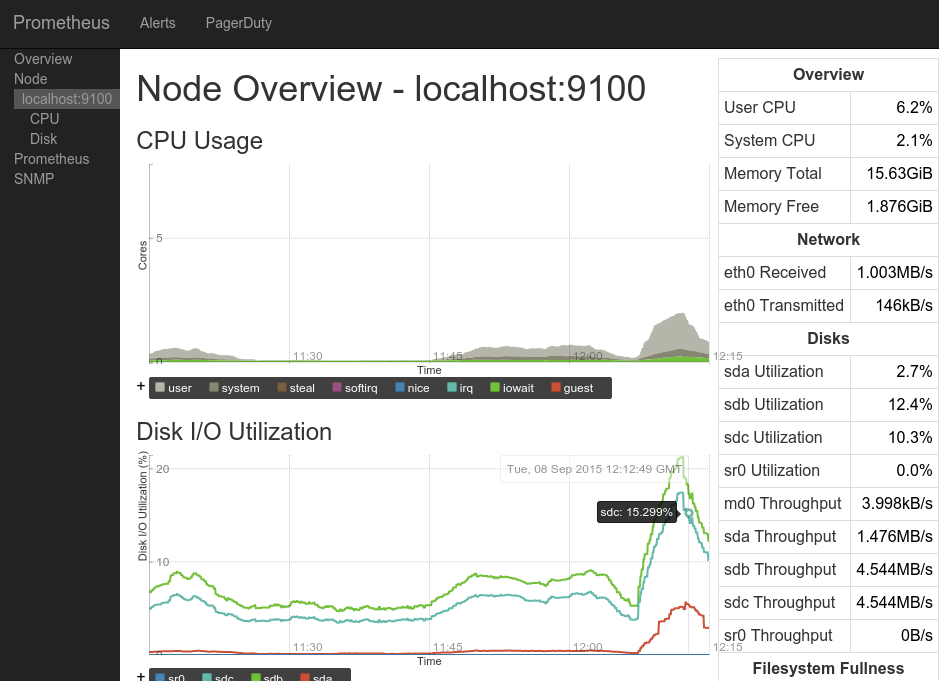
InfluxData (TICK Stack)
Состоит из четырёх компонент, написанных на go которые могут работать со сторонними продуктами:
telegraf — агент, который может быть установлен на другой сервер и пересылать метрики, а также логи в базы influxdb, elasticsearch, prometheus или graphite, а также в несколько серверов очередей.
influxdb — база данных, которая может принимать данные из telegraf, netdata или collectd.
chronograf — веб интерфейс для визуализации метрик из бд.
kapacitor — система уведомлений.
Первый релиз: 2013 год.
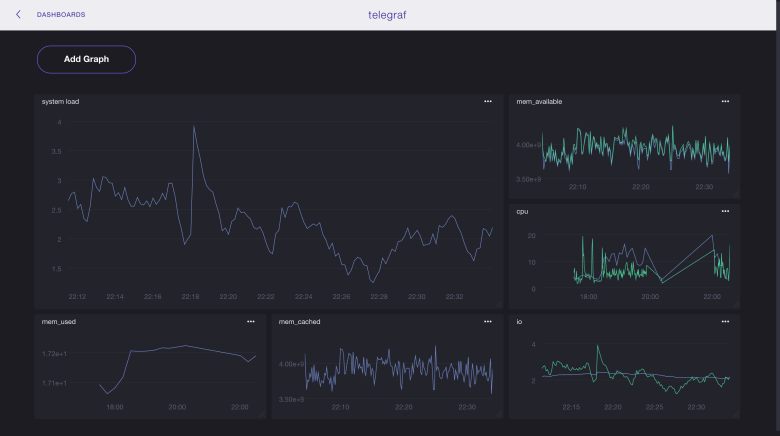
Отдельно хотелось бы упомянуть такой продукт, как grafana, она написана на go и позволяет визуализировать данные из influxdb, elasticsearch, clickhouse, prometheus, graphite, а также отправлять уведомления на почту, в slack и telegram.
Первый релиз: 2014 год.
Выбираем лучшее
В интернете и на Хабре, в том числе, полно примеров использования различных компонент из разных продуктов, чтобы получить то что надо именно тебе.
carbon (агент) -> whisper (бд) -> grafana (интерфейс)
netdata (в качестве агента) -> null / influxdb / elasticsearch / prometheus / graphite (в качестве бд) -> grafana (интерфейс)
node_exporter (агент) -> prometheus (в качестве бд) -> grafana (интерфейс)
collectd (агент) -> influxdb (бд) -> grafana (интерфейс)
zabbix (агент+сервер) -> mysql -> grafana (интерфейс)
telegraf (агент) -> elasticsearch (бд) -> kibana (интерфейс)
… и т.д.
Видел упоминание даже о такой связке:
… (агент) -> clickhouse (бд) -> grafana (интерфейс)
В большинстве случаев в качестве интерфейса использовалась grafana, даже если она была в связке с продуктом, который уже содержал собственный интерфейс (prometheus, graphite-web).
Поэтому (а также в силу её универсальности, простоты и удобства) в качестве интерфейса я остановился на grafana и приступил к выбору базы данных: prometheus отпал потому что не хотелось тянуть весь его функционал вместе с интерфейсом только из-за одной бд, graphite — бд предыдущего десятилетия, переработанная rrdtool-бд предыдущего столетия, ну и собственно я остановился на influxdb и как выяснилось — не один я сделал такой выбор.
Также для себя я решил выбрать telegraf, потому что он удовлетворял моим потребностям (большое количество метрик и возможность написания своих плагинов на bash), а также работает с разными бд, что может быть полезно в будущем.
Итоговая связка у меня получилась такая:
telegraf (агент) -> influxdb (бд) -> grafana (интерфейс+уведомления)
Все компоненты не содержат ничего лишнего и написаны на go. Единственное, чего я боялся — то что эта связку будет трудна в установке и настройке, но как вы сможете видеть ниже — это было зря.
Итак, короткая инструкция по установке TIG:
influxdb
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.2.2.x86_64.rpm && yum localinstall influxdb-1.2.2.x86_64.rpm #centos
wget https://dl.influxdata.com/influxdb/releases/influxdb_1.2.4_amd64.deb && dpkg -i influxdb_1.2.4_amd64.deb #ubuntu
systemctl start influxdb
systemctl enable influxdbТеперь можно делать запросы к базе (правда данных там ещё пока нет):
http://localhost:8086/query?q=select+*+from+telegraf..cputelegraf
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.2.1.x86_64.rpm && yum -y localinstall telegraf-1.2.1.x86_64.rpm #centos
wget https://dl.influxdata.com/telegraf/releases/telegraf_1.3.2-1_amd64.deb && dpkg -i telegraf_1.3.2-1_amd64.deb #ubuntu
#в случае установки на сервер отличный от того где находится influxdb необходимо в конфиге /etc/telegraf/telegraf.conf в секции [[outputs.influxdb]] поменять параметр urls = ["http://localhost:8086"]:
sed -i 's| urls = ["http://localhost:8086"]| urls = ["http://myserver.ru:8086"]|g' /etc/telegraf/telegraf.conf
systemctl start telegraf
systemctl enable telegrafTelegraf автоматически создаст базу в influxdb с именем «telegraf», логином «telegraf» и паролем «metricsmetricsmetricsmetrics».
grafana
yum install https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.3.2-1.x86_64.rpm #centos
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.3.2_amd64.deb && dpkg -i grafana_4.3.2_amd64.deb #ubuntu
systemctl start grafana-server
systemctl enable grafana-server
Интерфейс доступен по адресу
http://myserver.ru:3000. Логин: admin, пароль: admin.Изначально в интерфейсе ничего не будет, потому что графана ничего не знает о данных.
1) Нужно зайти в источники и указать influxdb (бд: telegraf)
2) Нужно создать свой дашборд с нужными метриками (уйдёт очень много времени) или импортировать уже готовый, например:
928 — позволяет видеть все метрики по выбранному хосту
914 — тоже самое
61 — позволяет метрики по выбранным хостам на одном графике
Grafana имеет отличный инструмент для импорта сторонних дашбордов (достаточно указать его номер), вы также можете создать свой дашборд и поделиться им с сообществом.
Вот список всех дашбордов, работающие с данными из influxdb, которые были собраны с помощью коллектора telegraf.
Акцент на безопасность
Все порты на ваших серверах должны быть открыты только с тех ip, которым вы доверяете либо в используемых продуктах должна быть включена авторизация и изменены пароли по-умолчанию (я делаю и то и другое).
influxdb
В influxdb по-умолчанию отключена авторизация и кто угодно может делать что угодно. По-этому если на сервере нет файервола, то крайне рекомендую включить авторизацию:
#Создаём базу и пользователей:
influx -execute 'CREATE DATABASE telegraf'
influx -execute 'CREATE USER admin WITH PASSWORD "password_for_admin" WITH ALL PRIVILEGES'
influx -execute 'CREATE USER telegraf WITH PASSWORD "password_for_telegraf"'
influx -execute 'CREATE USER grafana WITH PASSWORD "password_for_grafana"'
influx -execute 'GRANT WRITE ON "telegraf" TO "telegraf"' #чтобы telegraf мог писать метрики в бд
influx -execute 'GRANT READ ON "telegraf" TO "grafana"' #чтобы grafana могла читать метрики из бд
#в конфиге /etc/influxdb/influxdb.conf в секции [http] меняем параметр auth-enabled для включения авторизации:
sed -i 's| # auth-enabled = false| auth-enabled = true|g' /etc/influxdb/influxdb.conf
systemctl restart influxdbtelegraf
#в конфиге /etc/telegraf/telegraf.conf в секции [[outputs.influxdb]] меняем пароль на созданный в предыдущем пункте:
sed -i 's| # password = "metricsmetricsmetricsmetrics"| password = "password_for_telegraf"|g' /etc/telegraf/telegraf.conf
systemctl restart telegrafgrafana
В настройках источников, нужно указать для influxdb новый логин: «grafana» и пароль «password_for_grafana» из пункта выше.
Также в интерфейсе нужно сменить пароль по-умолчанию для пользователя admin.
Admin -> profile -> change passwordUpdate: добавил пункт к своим критериям «бесплатно и с открытым исходным кодом», забыл его указать с самого начала, а теперь мне советуют кучу платного/условно-бесплатного/триального/закрытого софта. Тут бы с бесплатным разобраться.
2) посмотрел на гитхабе топовые проекты
3) посмотрел, что есть на эту тему на хабре
4) погуглил какие системы сейчас в тренеде
Update2: сейчас группа энтузиастов создаёт таблицу в google docs, сравнивая различные системы мониторинга по ключевым параметрам (Language, Bytes/point, Clustering). Работа кипит, текущий срез под катом.

Update3: ещё одно сравнение Open-Source TSDB в Google Docs. Чуть более проработанное, но систем меньше AnyKey80lvl
P.S.: если я опустил какие-то моменты в описании настройки-установки, то пишите в комментариях и я обновлю статью. Опечатки — в личку.
P.P.S.: конечно этого никто не услышит (исходя из предыдущего опыта написания статей), но я всё равно должен попробовать: не задавайте вопросы в личку на хабре, вк, фб и т.д., а пишите комментарии здесь.
P.P.P.S.: размер статьи и потраченное на неё время сильно выбились из начального «бюджета», надеюсь, что результаты этой работы будут для кого-то полезны.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (102)

Dromok
19.06.2017 02:28+1На своем проекте, на более чем 10 машинах, использую munin и не испытываю никаких проблем. Легкая, не грузит сервер. И есть все метрики какие нужны прямо из коробки. Есть оповещение на почту если что-то нехорошее происходит на сервере. Имхо мне этого более чем достаточно и даже не планирую менять.
А вот на работе да, там везде zabbix + grafana и шлет алерты в слак.
razielvamp
19.06.2017 06:58А чем плох/недостаточен стандартный интерфейс Zabbix? Или grafana просто визуально красивее?
PS в zabbix раздражает узкая направленность на мониторинг серверов (например, чтобы мониторить web с внешки, приходится создавать фейковый сервер, чтобы вешать на него веб сценарии и триггеры с аляртами) и невозможность создавать хоть сколько-то динамические оповещения с использованием условий и регулярных выражений.


alexhouse
19.06.2017 05:02Многие, кто пользуются связкой Prometheus + Grafana, говорят о случаях когда grafana досит прометея.
Ветка обсуждения — https://github.com/prometheus/prometheus/issues/2238
freeseacher
19.06.2017 11:35Это довольно старое обсуждение, в более менее свежих версиях проблема ушла.

GHostly_FOX
19.06.2017 05:53Советую еще посмотреть в сторону Quest Software — Spotlight
Windows клиент для мониторинга серверов различного типа (Windows, Linux, Oracle и др.)
bormotov
19.06.2017 13:02потратил минуту на сайте Quest Software не нашел даже раздел где брать на посмотреть.
Только маркетинговое бла-бла-бла, как круто они умеют всё мониторить.GHostly_FOX
19.06.2017 13:31https://support.quest.com/spotlight-on-unix/9.0
https://www.quest.com/products/spotlight-on-sql-server-enterprise/
bormotov
19.06.2017 13:49то есть это SQL Server performance monitoring
GHostly_FOX
19.06.2017 14:27Не только… Он мониторит различные системы.
Вот например мониторинг сервера под управлением CentOS


Civil
19.06.2017 07:18+2Непонятны причины выбора. Даже более того, с учётом длительной истории проблем с influxdb и платной кластеризации, я бы не стал его ставить в Production.

banzayats
19.06.2017 09:44А можно подробнее о проблемах с InfluxDB?
В данный момент у нас работает связка Zabbix/MySQL. В следующей версии вроде бы обещали экспорт во внешние хранилища временных рядов (в том числе и InfluxDB) и хотелось бы заранее знать о подводных камнях.Civil
19.06.2017 10:10Ниже freeseacher хорошо описал основные текущие. К этому можно добавить разве что следующее:
1. Кластеризация и HA только в платной версии (в бесплатной предлагается писать в две базы параллельно и дальше получить проблемы с синхронизацией данных и пр.). Притом что когда кластеризация была в OpenSource она не работала, поэтому нет оснований верить в нее и сейчас.
2. Апдейты как хождение по минному полю — не знаешь что оторвет сейчас в целом по всему их стеку. Можно посмотреть баги телеграфа, в InfluxDB в каждом апдейте сопоставимый бардак.

mrobespierre
19.06.2017 07:34отличная статья, спасибо
отдельное спасибо за то, что не надо тащить docker вместе с тысячами его багов т.к. «контейнеры это безопасно»

evnp
19.06.2017 08:04Незаслуженно пропущен NetXMS. У каких-нибудь других систем мониторинга есть дерево объектов в духе первой картинки из https://habrahabr.ru/post/190360/?
Вообще из систем мониторинга нового поколения есть что-то для мониторинга+инвентаризации с разделением объектов мониторинга на группы (возможно вложенные и пересекающиеся)?



okondrashin
19.06.2017 08:33Спасибо за статью! Не рассматривали в качестве агента logstash (из ELK)?

NickyX3
19.06.2017 12:37Если не надо «рубить» данные, то сейчас в связке с ELK для многих применений хватает их же Beats.

freeseacher
19.06.2017 08:38+1Рекомендую рассмотреть довольно удобную связку prometheus + telegraf.
Преимущества такой связки становятся очевидны после некоторой эксплуатации. Дело в том, что influxdb довольно плохо себя ведет на значительных объемах метрик.
Когда колво серверов измеряется десятками influx справлятся на ура, но масштабирование за эти пределы для нее становится неприятным. Из-за
- Неоднозначного времени старта. Из-за механики хранения метрик на диске во время старта надо построить индекс в памяти. это может занять любое колличество времени. Его нет возможности предсказать и оно практически не зависит от характеристик сервера(есть мнение, что такое построение индекса упирается в производительность одного ядра). Есть надежда, что в релизе 1.3 у парней получится решить эту проблемму через использования дискового индекса.
- Предсказуеммости операции compact. Потребление диска предсказать так же почти невозможно. В настройках по уполчанию compact будет отложен на 4 часа после последней записанной точки в кусок. С одной стороны эта операция сама по себе может занять до 12 часов. С другой стороны в это время на диске метрики будут лежать в режиме не максимального сжатия. Для примера скажу, что полностью сжатый кусок занимает 25G, а не сжатый 457G. Прогнозировать утилизацию диска в такой ситуации на грани возможного.
Предложенная мною связка решает вопрос с хранением метрик.
- prometheus очень быстро стартует
- хранит метрики в раздельных файлах и
- очень бережно относится к диску я одно время проводил сравнение большую часть времени по использоемому месту идут нос к носу, бывает что prometheus потребляет на 3-5% больше диска.
Кроме этого prometheus умеет алертинг, в связке Influx+telegraf приходится добавлять capacitor, а его конфигурация не самое приятное занятие.
blind_oracle
19.06.2017 09:49+1Графана с некоторых пор умеет алерты, конденсатор не нужен.
Civil
19.06.2017 10:10К сожалению функциональности графаны хватает только на простые алерты, зачастую слишком простые.
freeseacher
19.06.2017 11:30Это увы не так. Когда серверов достаточно, выясняется что нужны templated дашборды и соответственно аварии по ним. Но графана с таких пока не умеет делать алярмы.
undro
19.06.2017 08:38+31,5к хостов, 100к элементов, 15к триггеров.
Для мониторинга крупных сетей альтернативы zabbix пока не встречал.
Подборка хорошая.
ky0
19.06.2017 09:39Поддерживаю. Завяление автора про то, что заббикс грузит сервер, имхо, крайне субьективно.
blind_oracle
19.06.2017 09:47+2Грузит не заббикс, а его бд, которую после энного объема итемов и values per second приходится партиционировать вручную и так далее. Когда (если?) заббикс перейдёт для хранения метрик на какую либо time series db ему должно сильно полегчать.
ky0
19.06.2017 10:00Согласен насчёт партиционирования, но лично у нас (в качестве базы используется постгрес) это происходит автоматически после единоразовой настройки. Существенной нагрузки на сервер с СУБД нет (300 vps), на текущем оборудовании, по приблизительным прикидкам, можно опрашивать на порядок больше элементов.

acmnu
19.06.2017 09:50Как вы его настраиваете на таких объемах? Неужили правите xml руками? Или используете какие-то сторонние генераторы конфигов?

Fox_exe
19.06.2017 11:29Есть такая вещь как «Шаблоны» и «Автообнаружение».
Шаблоны позволяют быстро добавлять новые узлы в мониторинг, а Автообнаружение вообще позволяет заббиксу автоматом подкючать нужные триггеры и прочее.
Может дажу карту сети построить…acmnu
19.06.2017 12:12Я знаю про шаблоны, но ими тоже надо управлять. На таком парке (1500 хостов) шаблонов будет тоже будь здоров.
Fox_exe
19.06.2017 16:19Само собой. Но по сути все эти 1500 хостов врятли сильно отличаются. Скажем 90% из них — просто виртуалки. Тогда и шаблон на всех будет один (Причем можно взять стандартный «Template Virt VMware Guest» / «Hypervisor»)
Ну и свитчи/камеры (SNMP + свой шалон для нестандартных девайсов)
Думаю, десятком можно обойтись. Для знакомого с Zabbix админа — дел на пару часов. (А вот новичек потратит пару недель, т.к. теже макросы и триггеры без готовых примеров понять сложновато)acmnu
19.06.2017 16:23Скажем 90% из них — просто виртуалки.
Сильное предположение. Т.е. просто виртуалки: стоят, воздух греют. А какая бизнес нагрузка на них? Везде apache+php? Тогда да, хватит пары шаблонов. А если все же вариативность повыше?
undro
19.06.2017 17:31Думаю не надо объяснять, что такое кол-во контента вносится не за 2 часа после установки. В свое время отказались от nagios, ввиду проблем с производительностью, с тех пор прошло года 3-4.
Разнообразия хватает: сервера, виртуалки, свичи, упсы, датчики, герконы, хотспоты и т.п. железки, в телекоме на 200-300к абонентов такого добра полно. Но это не мешает заливать их в мониторинг пакетно.
В крайний раз добавлял КТВ железки, это пара десятков EMR с пулом в 100-200 каналов и пара сотен всяких PBI, стримеров. Через API и pyzabbix, скриптом на питоне в 10 строк, залил за несколько часов. С max/min триггерами, действиями и графиками на каждый элемент данных (около 3к). Вариантов автоматизации в zabbix много.
Изначальный посыл был про производительность, которой мало что из списка может похвастаться. В zabbix даже если упрешься вертикально, развернуть прокси дело получаса.
undro
19.06.2017 13:27Что касается автоматизации наполнения, как уже писали, автообнаружение и шаблоны покрывают бОльшую часть задач, в остальных случаях есть внешние скрипты, параметры агента и Zabbix API.

stanislav-belichenko
19.06.2017 11:09А подскажите, правда ли, что лучше использовать не sql и им подобные базы данных? У меня скромные задачи, но и скромные возможности — может быть, есть какая-то «формула», по которой примерно можно оценить размер бедствия?
Civil
19.06.2017 12:21+1Всегда надо отталкиваться от задач. Если Time-Series это именно то что вы хотите и вы их хотите за какое-то значимое время, то SQL совсем не годится. Хотя бы потому что авторы заббикса оценивают размер одной точки в 90 байт, а в современных базах получается какое-то такое распределение:
1. *SQL-based базы и прочие попытки притянуть за уши решение — 80+ байт на точку.
1. Cassandra-based без кастомного сжатия — около 14 байт на точку
2. Graphite'овый Whisper и прочие RRD-подобные — 8-12 байт на точку
3. Более современные базы со сжатием — 2-6 байт на точку
Везде будут свои недостатки и преимущества, выбирать надо исходя из задач. Но я бы в 2017 году начал бы выбор с вопроса «почему не Prometheus?»
samsan
19.06.2017 08:43Cacti
Уведомлений «из коробки» найдено не было
Уведомления на почту есть из коробки.
ELazin
19.06.2017 09:58+3Порекламирую свою TSDB поажалуй — https://github.com/akumuli/Akumuli
Работает на запись примерно в 10 раз быстрее того же influx-а, на чтение — примерно на том же уровне (median), но более стабильно (три-сигма сильно ниже). Пока еще нет кластеризации и интеграции со всяким мониторингом вроде графаны и collectd. Send nudes^W pull-requests!

farcaller
19.06.2017 10:17Несколько раз спотыкался от influx при апдейтах, ушел на prometheus, доволен.
Плюсы:
- гибкий синтаксис запросов
- просто интегрировать метрики в свои сервисы (клиентские либы почти под всё)
- большой выбор механизмов обнаружения сервисов

Singaporian
19.06.2017 11:07Sensu. Почему он не участвовал?

morozovsk
19.06.2017 11:27+1Потому что я выбирал готовую систему мониторинга, которая будет делать «из коробки» всё что мне нужно, а Sensu — это «фреймворк для мониторинга». Об этом в частности упоминается в сравнении его с другими системами мониторинга
KraT_by
19.06.2017 11:19А кто-нибудь пробовал работать с monitorix или Acronis Monitoring? Есть положительные отзывы?

trapwalker
20.06.2017 02:12Monitorix пробовал, но сравнивать особо не с чем. Работает, настраивается несложно, графики довольно бедны по функциональности (простые картинки), их нельзя скроллить и масштабировать. Нельзя динамически включать разные метрики на одном графике, а хотелось бы. Буду искать замену. Используется в игровом проекте на начальных этапах. Нужно больше метрик.
Fox_exe
19.06.2017 11:24Обновите скриншотик для Zabbix (как бы уже давно версия 3.x выпущена и отлично работает. Да и с Grafana подружить можно, если хочется красивостей)
morozovsk
19.06.2017 11:49Я хотел скриншот интерфейса с графиками, но по запросу zabbix 3 в гуглокартинках находятся только скриншоты с таблицами, скриншоты с графиками старой версии либо интерфейс графаны прикрученный к заббикусу. Смотрел скриншоты из недавней статьи о выходе новой версии заббикса — та же проблема: маркетинговая картинка (а не скриншот), скриншоты с таблицами и один скриншот с одним графиком на весь экран что по-моему получается ещё менее показательно, чем скриншот от старой версии.
evnp
19.06.2017 11:57+2Спасибо за Netdata — любопытная система, очень многое действительно работает из коробки, кастомизируется судя по документации тоже неплохо — надо будет попробовать.

dmitriylyalyuev
19.06.2017 12:59А что из этого укладывается в парадигму Infrastructure As Code?
Ну кроме Nagios/Munin?
Grafana, на сколько я понимаю, мышкой все строить надо. Да и все остальное тоже?
zer0access
19.06.2017 14:22Sensu пытается быть таким решением. Я пытался его настроить в домашней сети, и оно даже заработало, но оказалось довольно тяжеловесным, т.к. потянуло ещё RabbitMQ и Redis. К тому же, это относительно новый продукт и он находится в активной разработке. Возможно, в будущем это будет довольно неплохое средство мониторинга.
freechibis
19.06.2017 16:10Для Grafana есть обертки вокруг API, например https://github.com/utkarshcmu/wizzy
Eugene_Burachevskiy
19.06.2017 17:20Связка из Node Exporter + Prometheus + Grafana спокойно разворачивается через CloudInit конфиг (допустим тем же терраформом).
Grafana позволяет один раз руками настроить все нужные датасорсы и дашборды, а потом автоматом делать их бэкап/рестор через curl

divanikus
19.06.2017 13:51+1По моему опыту в системах мониторинга все упирается в алерты. Ну т.е. можно сколько угодно любоваться красивыми графиками или динамичным дашбордом, но если алерты настроить сложно, если их много не по делу и т.п. — полезность системы резко падает. В этом плане в моем личном топе пока лидирует Zabbix, хотя веб-интерфейс там так себе, если честно.

nanshakov
19.06.2017 14:22Огромное спасибо автору за статью. Как раз работаем над стартапом и задумались над этим. У меня есть вопрос к читателям хабра. Сейчас наше ПО пишет логи в БД, мы их разбираем на стороне воркером и выводим, например, «статистику одного дня» и всякое разное. Проблема в том, что менять структуру лога — менять структуру бд — геморно. Какие решения есть и как можно загуглить это?

little-brother
19.06.2017 14:44Альтернатив несколько больше чем описано в обзоре (в частности нет PRTG и The Dude), что впрочем не остановило меня от написания еще одной с максимально упрощенным интерфейсом, возможностью опроса устройств несколькими методами (от SNMP до опроса портов) и просмотра истории сгруппированной по типам устройств/узлов.
Демка, следящая за стендовым оборудованием.

dqvsra
19.06.2017 15:03+1Для NodeJS мне понравилось работать с Keymetrics.IO, особенно потому что
эта система мониторинга является частью «process manager» PM2, тем более сейчас у них условия для бесплатного пользования стали более привлекательными: $0 per month 4 processes 1 user.
varnav
19.06.2017 15:12Лично у меня:
Observium — для сетевых устройств.
Munin — для локалхоста
Zabbix — для всего

serejk
19.06.2017 17:20По поводу Update2: может сразу на википедию вносить обзор (https://en.wikipedia.org/wiki/Time_series_database)? Частично он там уже есть. Ну или результат туда запостить — многим бы пригодился.
Civil
19.06.2017 17:26Там есть субъективные комментарии (последнее поле) которое ценны, но не факт что их Википедия примет. Наверное в перспективе можно, если придумать как таблицу оставить сортируемой и перенести все включая комментарии и заметки на полях.
morozovsk
19.06.2017 17:35Это не я делаю, а энтузиасты, я даже не знаю кто конкретно. Но по своему опыту скажу, что писать статью на википедии, это будет квест посложнее чем табличка в googledocs и даже на порядок сложнее, чем на хабре. Здесь общественность разрулит нужна статья или нет, а там очень жёсткая бюрократия: нужно знать кучу правил, уметь отстоять своё мнение, находить людей, которые могут поддержать тебя и твою статью. После нескольких статей — прямая дорога в политику. Если ты не следуешь правилам, то вся твоя работа по написанию статьи может быть в момент удалена, а это просто непередаваемые впечатления, гораздо более сильные, чем когда твоя статья получает минусы. Я зарёкся когда-либо ещё писать туда статьи. Прошу прощения за то что меня прорвало. 7 лет прошло, до сих пор не отпускает.
serejk
19.06.2017 18:27Да я понимаю, что не совсем по адресу написал, но не придумал сходу куда. Щас вспомнил, что там же чат есть вроде бы. Касаемо википедии — там не нужно новой статьи, там уже похожая таблица даже есть, со схожим набором полей. И по результатам стихийного обзора можно вынести туда все основное, чтобы оно не кануло в лету в недрах google docs:) не думаю, что модераторы википедии воспримут в штыки.
Civil
19.06.2017 21:08+1В принципе можно, вопрос с источниками данных. Для части строк в таблице были использованы источники вида «Эй, ты же автор? А сколько байт занимает точка у тебя?».

foxmuldercp
19.06.2017 18:48Ещё можно на Pandora fms посмотреть. легкая, простая, и новые хосты подключаются методом установки агента который из коробки есть кажется что в убунтах, что в дебианах, что в центосях каких


amarao
19.06.2017 21:25+1Про shinken ни слова, в одну кучу свалены perfdata и мониторинг. Я даже не могу дать фитбэка на обзор, т.к. не понимаю как можно вместе сравнивать nagios и graphana. Всё равно, что сравнивать blender и gcc.
morozovsk
19.06.2017 22:48Я старался, чтобы в этот обзор попало только то, что популярно или перспективно (исходя из моей субъективной оценки). За основу я брал Comparison of network monitoring systems и топ гитхаба. Но если бы я взял от туда в статью весь список, то у меня бы год ушёл или я бы получил ещё одну статью Обзор 51 системы мониторинга. Но у меня не стояло такой задачи, мне нужно было выбирать систему мониторинга на замену munin. Именно по-этому в обзор попал ganglia, потому что я её рассматривал как альтернативу, хотя судя по результатам опроса её вообще никто не использует (считаю это моим самым большим промахом, все остальные ответы на опрос были достаточно предсказуемы).
В данном обзоре я не сравниваю nagios и graphana. Я специально написал "Отдельно хотелось бы упомянуть такой продукт, как grafana". Если этот текст путает, то предложите свой вариант и я внесу изменения в статью.amarao
19.06.2017 23:28Давайте заменим «graphana» на collectd. Всё равно не понятно как вы сравниваете nagios и collectd. Они просто разные вещи делают. Они близки друг к другу по области применения, но совершенно не взаимозаменяемы. Скорее, дополняющие друг друга.

evnp
20.06.2017 08:41А что в принципе такого умеет collectd и не умеет nagios (давайте исключим разные плагины для сбора разных специфичных метрик)? Я бы разделил средства мониторинга на универсальные (zabbix, nagios со всеми ответвлениями, netxms и т.д. — они пытаются подгрести под себя все, включая инвентаризацию, чем собственно и хороши) и специализированные (а уж среди них сбор/визуализация метрик в духе collectd — кажется самое популярное направление, обработка логов наверное на втором месте). В этом смысле collectd никак не дополняет nagios, он представляет подмножество его возможностей, но при этом позволяет избежать избыточной сложности и снизить требования у ресурсам на мониторинг. Визуально результаты тоже, конечно, отличаются — но это уже по части «нефункциональных требований»

PRIHLOPer
20.06.2017 08:49Пользую Prometheus + Grafana.
Prometheus хорош своей модульностью, можно включить только то что нужно и прикрутить модули для сборки нужных метрик. Ну и там всё предельно просто по настройке и транспорту метрик с клиентов на сервер.

AnyKey80lvl
20.06.2017 10:08Вот еще одно сравнение Open-Source TSDB.в Google Docs.
Чуть более проработанный, мне кажется, но систем меньшеCivil
20.06.2017 11:15То что он более проработанный это к сожалению видимость. У него есть пара серьезных
недостатковособенностей:
- Параметры типа Write Performance/Query Perfromance сравниваются по заверениям авторов без учета разного железа и методик тестирования — то есть по фатку это профанация.
- Для показателей bytes per point нет источника, например непонятно откуда у Dalmatiner'а 1, когда авторы базы об этом ничего не говорят, если из тестов то тогда см п. 1, цифры в этом блоке профанация так как еще и осознанно на разных сетах данных
- Оценки типа Complexity, Functionality, Usability тоже даны примерно от балды по какой-то внутренней логике авторов, которая не очень то афишируется
- Нет упоминаний ни в каком виде что у всего raik-based cross-dc кластеризация платная, что по мне, например важно.
Поэтому я бы честно говоря не советовал бы использовать эту таблицу как источник информации, из-за того что она не учитывает разницу тестовых методик все цифры в ней являются профанацией и по факту бесполезны (не говоря о том, что например для Whisper'а есть более быстрые реализации на Go, чем указанное в таблице, но автор по какой-то причине не хочет их учитывать).AnyKey80lvl
20.06.2017 12:06Согласен! Но сравнивать эти системы по «полной программе» — гигантский труд.
А люди, которые занимаются мониторингом и сопутствующими темами, редко имеют много свободного времени :)Civil
20.06.2017 12:30Конечно, поэтому в таблице с бОльшим количеством систем нет никаких разделов о производительности, потому что какая бы цифра там не оказалась, она будет либо чушью, либо наглой ложью.
Фактически основная идея таблицы из Update2 в том чтобы собрать более честную и объективную информацию чем собрана в таблице из Update3 — то есть выкинуть по максимуму субъективные факторы, а взамен охватить большее количество систем.
Наверное единственное чего не хватает это лицензии, чтобы цель можно было бы считать достигнутой.

Hesed
20.06.2017 10:24+1Не упомянута OpenNMS [demo]. У меня мониторится порядка 2500 нод (сетевая инфраструктура, сервера), интерфейсов… ммм… много. Стек: Java + PostgreSQL + на выбор time-series database — RRD, JRD, NewTS. Относительно легко разбивается на шарды. Конфигурирование может добавить седых волос, но после настройки работает безупречно.
Methate
20.06.2017 14:55А где check-mk? Комбайн, который имеет в себе всё. И не надо парится с какими-либо связками…


stanislav-belichenko
Спасибо, интересно! А не встречали в ваших изысканиях подобную конфигурацию, но сразу и для *nix, и для win* наблюдаемых машин?
Wernisag
Icinga умеет, у неё есть клиенты для обеих систем + wmi + snmp. С развитием IoT скоро можно будет и чайник на кухне мониторить
banzayats
Могу посоветовать два решения для мониторинга nix/win:
Например агент Telegraf по умолчанию умеет снимать метрики из Windows Performance Counters. Вот пример из конфига: