

Привет, Хабр! Некоторое время назад меня заинтересовал вопрос: как эффективнее всего читать данные с диска (при условии, что у вас .Net)? Задача чтения кучи файлов встречается во множестве программ, которые при самом старте начинают вычитывать конфигурации, некоторые самостоятельно подгружают модули и т.д.
В интернете я не нашел подобных сравнений (если не считать тюнинга под определенные конфигурации).
Результаты можно посмотреть на Github: SSD, HDD.
Способы чтения и алгоритм тестирования
Есть несколько основных способов:
- ScenarioReadAllAsParallel — читать с помощью ReadAllText на ThreadPool;
- ScenarioSyncAsParallel — читать с помощью Stream'ов синхронно на Thread Pool;
- ScenarioNewThread — читать с помощью Stream'ов синхронно и на отдельном потоке для каждого чтения, время на запуск нового потока тоже учитывается;
- ScenarioAsync2 — читать с помощью Stream'ов асинхронно (т.е. async/await, если файловая система долго отвечает, то параллельно может запуститься множество операций);
- ScenarioAsync — асинхронное чтение, однако и старт происходит тоже во много потоков (а не последовательно на одном и том же потоке Main, как в предыдущем тесте);
- ScenarioAsyncWithMaxParallelCount — читать с помощью Stream'ов асинхронно (т.е. async/await), но не больше, чем в N параллельных операций.
Тестировал я все на SSD и HDD (в первом случае был компьютер с Xeon 24 cores и 16 Гб памяти и Intel SSD, во втором — Mac Mini MGEM2LL/A с Core i5, 4 Гб RAM и HDD 5400-rpm). Системы такие, чтобы по результатам можно было бы понять, как лучше вести себя на относительно современных системах и на не очень новых.
Проект можно посмотреть здесь, он представляет собой один главный исполняемый файл TestsHost и кучу проектов с названиями Scenario*. Каждый тест это:
- Запуск exe-файла, который посчитает чистое время.
- Раз в секунду проверяется нагрузка на процессор, потребление оперативной памяти, нагрузка на диск и еще ряд производных параметров (с помощью Performance Counters).
- Результат запоминается, тест повторяется несколько раз. Итоговый результат работы — это среднее время, без учета самых больших и самых малых значений.
Подготовка к тесту более хитрая. Итак, перед запуском:
- Определяемся с размером файлов и с их числом (я выбрал такие, чтобы суммарный объем был больше, чем объем RAM, чтобы подавить влияние дискового кеша);
- Ищем на компьютере файлы заданного размера (а заодно игнорируем недоступные файлы и еще ряд спецпапок, про которые написано ниже);
- Запускаем один из тестов на наборе файлов, игнорируем результат. Все это нужно для того, чтобы сбросить кеш ОС, убрать влияние от предыдущих тестов и просто прогреть систему.
И не забываем про обработку ошибок:
- Программа выдаст код возврата 0 только в случае, если все файлы были прочитаны.
- Иногда весь тест падает, если вдруг система начинает активно читать файл. Вздыхаем и перезапускаем еще раз, добавляя файл (или папку) в игнорируемые. Так как я использовал каталоги Windows & Program Files как хороший источник файлов, наиболее реалистично размазанный по диску, некоторые файлы могли быть ненадолго заблокированы.
- Иногда один Performance Counter мог выдать ошибку, так как процесс, например, уже начал завершаться. В этом случае игнорируются все счетчики за эту секунду.
- На больших файлах некоторые тесты стабильно выдавали Out Of Memory исключения. Их я убрал из результатов.
И плюс стандартные моменты про нагрузочное тестирование:
- Компиляция — в режиме Release в MSVS. Запуск идет как отдельное приложение, без отладчика и пр. Нет какого-то тюнинга, ведь суть проверок именно в том — как в обыкновенном ПО читать файлы быстрее.
- Антивирус отключен, обновление системы остановлено, активные программы остановлены тоже. Больше никаких тюнингов не было, по той же причине.
- Каждый тест — это запуск отдельного процесса. Overhead получился в рамках погрешности (т.е. jit, траты на старт процесса и пр.), а потому я оставил именно такую изоляцию.
- Некоторые Performance Counters выдавали нулевой результат всегда для HDD/SSD. Так как набор счетчиков вшит в программу, я их оставил.
- Все программы запускались как x64, попытка сделать swap означала неэффективность по памяти и сразу же уходила вниз в статистике из-за большого времени работы.
- Thread Priority и пр. тюнинги не использовались, так как не было попыток выжать именно максимум (который будет сильно зависеть от намного большего числа факторов).
- Технологии: .Net 4.6, x64
Результаты
Как я уже написал в шапке, результаты есть на Github: SSD, HDD.
SSD диск
Минимальный размер файла (байты): 2, максимальный размер (байты): 25720320, средний размер (байты): 40953.1175
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.2260000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.5080000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.1120000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.1540000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.2510000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.5240000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.5970000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.7610000 |
| ScenarioSyncAsParallel |
00:00:00.9340000 |
| ScenarioReadAllAsParallel |
00:00:00.3360000 |
| ScenarioAsync |
00:00:00.8150000 |
| ScenarioAsync2 |
00:00:00.0710000 |
| ScenarioNewThread |
00:00:00.6320000 |
Итак, при чтении множества мелких файлов два победителя — асинхронные операции. На деле в обоих случаях .Net использовал 31 поток.
По сути обе программы различались наличием или отсутствием ActionBlock для ScenarioAsyncWithMaxParallelCount32 (с ограничением), в итоге получилось, что чтение лучше не ограничивать, тогда будет использоваться больше памяти (в моем случае в 1,5 раза), а ограничение будет просто на уровне стандартных настроек (т.к. Thread Pool зависит от числа ядер и т.д.)
Минимальный размер файла (байты): 1001, максимальный размер (байты): 25720320, средний размер (байты): 42907.8608
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.4070000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.2210000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.1240000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.2430000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.3180000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.5100000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.7270000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.8190000 |
| ScenarioSyncAsParallel |
00:00:00.7590000 |
| ScenarioReadAllAsParallel |
00:00:00.3120000 |
| ScenarioAsync |
00:00:00.5080000 |
| ScenarioAsync2 |
00:00:00.0670000 |
| ScenarioNewThread |
00:00:00.6090000 |
Увеличив минимальный размер файла, я получил:
- В лидерах остался запуск программы с числом потоков, близким к числу ядер процессоров.
- В ряде тестов один из потоков постоянно ждал освобождение блокировки (см. Performance Counter «Concurrent Queue Length»).
- Синхронный способ чтение с диска все еще в аутсайдерах.
Минимальный размер файла (байты): 10007, максимальный размер (байты): 62 444 171, средний размер (байты): 205102.2773
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.6830000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.5440000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.6620000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.8690000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.5630000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.2050000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.1600000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.4890000 |
| ScenarioSyncAsParallel |
00:00:00.7090000 |
| ScenarioReadAllAsParallel |
00:00:00.9320000 |
| ScenarioAsync |
00:00:00.7160000 |
| ScenarioAsync2 |
00:00:00.6530000 |
| ScenarioNewThread |
00:00:00.4290000 |
И последний тест для SSD: файлы от 10 Кб, их число меньше, однако сами они больше. И как результат:
- Если не ограничивать число потоков, то время чтения становится ближе к синхронным операциям
- Ограничивать уже желательнее как (число ядер) * [2.5 — 5.5]
HDD диск
Если с SSD все было более-менее хорошо, здесь у меня участились падения, так что часть результатов с упавшими программами я исключил.
Минимальный размер файла (байты): 1001, максимальный размер (байты): 54989002, средний размер (байты): 210818,0652
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.3410000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.3050000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.2470000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.1290000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.1810000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.1940000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.4010000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.5170000 |
| ScenarioSyncAsParallel |
00:00:00.3120000 |
| ScenarioReadAllAsParallel |
00:00:00.5190000 |
| ScenarioAsync |
00:00:00.4370000 |
| ScenarioAsync2 |
00:00:00.5990000 |
| ScenarioNewThread |
00:00:00.5300000 |
Для мелких файлов в лидерах опять асинхронное чтение. Однако и синхронная работа тоже показала неплохой результат. Ответ кроется в нагрузке на диск, а именно — в ограничении параллельных чтений. При попытке принудительно начать читать во много потоков система упирается в большую очередь на чтение. В итоге вместо параллельной работы время тратится на попытки параллельно обслужить много запросов.
Минимальный размер файла (байты): 1001, максимальный размер (байты): 54989002, средний размер (байты): 208913,2665
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.6880000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.2160000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.5870000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.5700000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.5070000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.4060000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.4800000 |
| ScenarioSyncAsParallel |
00:00:00.4680000 |
| ScenarioReadAllAsParallel |
00:00:00.4680000 |
| ScenarioAsync |
00:00:00.3780000 |
| ScenarioAsync2 |
00:00:00.5390000 |
| ScenarioNewThread |
00:00:00.6730000 |
Для среднего размера файлов асинхронное чтение продолжало показывать лучший результат, разве что число потоков желательно ограничивать еще меньшим значением.
Минимальный размер файла (байты): 10008, максимальный размер (байты): 138634176, средний размер (байты): 429888,6019
| Сценарий |
Время |
| ScenarioAsyncWithMaxParallelCount4 |
00:00:00.5230000 |
| ScenarioAsyncWithMaxParallelCount8 |
00:00:00.4110000 |
| ScenarioAsyncWithMaxParallelCount16 |
00:00:00.4790000 |
| ScenarioAsyncWithMaxParallelCount24 |
00:00:00.3870000 |
| ScenarioAsyncWithMaxParallelCount32 |
00:00:00.4530000 |
| ScenarioAsyncWithMaxParallelCount64 |
00:00:00.5060000 |
| ScenarioAsyncWithMaxParallelCount128 |
00:00:00.5810000 |
| ScenarioAsyncWithMaxParallelCount256 |
00:00:00.5540000 |
| ScenarioReadAllAsParallel |
00:00:00.5850000 |
| ScenarioAsync |
00:00:00.5530000 |
| ScenarioAsync2 |
00:00:00.4440000 |
Опять в лидерах асинхронное чтение с ограничением на число параллельных операций. Причем, рекомендуемое число потоков стало еще меньше. А параллельное синхронное чтение стабильно стало показывать Out Of Memory.
При большем увеличении размера файла сценарии без ограничения на число параллельных чтений чаще падали с Out Of Memory. Так как результат не был стабильным от запуска к запуску, подобное тестирование я уже счел нецелесообразным.
Итог
Какой же результат можно почерпнуть из этих тестов?
- Почти во всех случаях асинхронное чтение, по сравнению с синхронным, давало лучший результат по скорости.
- При росте размера файла целесообразно ограничивать число потоков, так как иначе чтение будет медленным, плюс повысится риск OOM.
- Во всех случаях не было радикально большого прироста в производительности, максимум — в 2-3 раза. А потому возможно, что переписывать старое legacy приложение на асинхронное чтение не стоит.
- Однако для новых программ async доступ к файлам как минимум уменьшит вероятность падений и увеличит скорость.
Комментарии (17)

szKarlen
27.06.2017 11:33+3Я все ждал, когда же в статье будет сравнение RandomAccess и SequentialScan, но его нет :(
Кстати, размеры буферов для чтения тоже влияют на производительность.
Сравнение количества потоков и используемого API (синхронное против асинхронного) лишь показывает, что мы в итоге упремся в ограничение роста производительности, т.е. закон Амдала. (кстати, тесты с 64/128/256 потоками наглядно это демонстрируют).

gurux13
27.06.2017 13:211. ScenarioAsync2 00:00:00.0670000 в SSD для Минимальный размер файла (байты): 1001 почему не жирное?
2. Сравнение миллисекунд — неблагодарное дело. Было бы здорово, если бы тесты работали хотя бы секунду, а то и десяток.
3. OOM не должно быть ни при каком раскладе. Вы складируете всё прочитанное в память? Тогда на время повлияет уборка мусора. Может быть, стоит складировать всё время в один и тот же byte[], если не ReadAllText?
4. Для больших файлов, разбросанных по диску (видео, например), последовательное чтение должно быть существенно быстрее на HDD, в предположении о дефрагментированном харде.
5. Использование существующих файлов на харде — плохая идея, имхо. Доступы к ним со стороны системы непредсказуемы. Лучше создать некоторую тестовую папку с таким набором файлов, который Вам интересен. Минус в том, что они все создаются примерно одновременно и вряд ли оказываются размазанными. Но, с другой стороны, в реальных условиях программа тоже устанавливается за ограниченное время.
imanushin
27.06.2017 13:46- Моя промашка, абсолютно согласен, спасибо!
- "Сравнение миллисекунд" — да, согласен. Результаты у меня стабильно воспроизводились, потому я оставил именно миллисекунды.
- И всё-таки, он получался. По моим предположениям (субъективным), всё это было от большого числа запущенных операций (и большого размера файлов), т.е. все объекты были действительно достижимы. Вы правы, для избежания подобного поведения стоило как минимум обрабатывать файлы блоками (например, используя Microsoft.IO.RecyclableMemoryStream. Здесь же моя идея была следующая: сравнить скорость, используя простую логику чтения (т.е. ту, которую чаще всего будет использовать разработчик при стандартных задачах чтения с диска). Я уверен, что при разработке IO-bound приложений используется немало оптимизаций, все они за рамками моих замеров
- Я запускал дефрагментацию заранее на HDD. Если есть силы и время — Вы можете запустить тест на своем компьютере, для этого достаточно сделать git pull и запустить проект TestHost. У меня теория не воспроизвелась.
- Возможно. Моё основное предположение — сделать замер скорости чтения случайного набора файлов. Т.е. когда они обновляются в разное время, а значит дефрагментация может постепенно разнести их по диску.
FramePS2
27.06.2017 19:07+2В асинхронных тестах вы открываете файл с помощью вызова File.OpenRead(), а этот вызов создаёт FileStream в синхронном режиме. В итоге тестируется работа ThreadPool, а не асинхронного ввода-вывода. Попробуйте повторить асинхронные тесты, создав явно FileStream с параметром useAsync = true.
kayan
27.06.2017 23:19+2Если вы не знакомы с BenchmarkDotNet — самое время познакомиться. Скорее всего, при общей простоте использования, он более грамотно замерит "миллисекунды". И — нет, я не Андрей Акиньшин. :)
imanushin
28.06.2017 00:06+1Да, я полностью согласен, однако я начал делать все замеры в марте 2016 года, когда BenchmarkDotNet от DreamWalker 'а была менее популярна.
Сейчас я бы основывал свои проверки именно на ней.

Fahrain
28.06.2017 14:04У меня вот похуже задача сейчас есть… Надо не просто много файлов быстро прочитать, а перебрать содержимое папки со подпапками, причем внутри более миллиона файлов. Процесс занимает более получаса.
Задача в том, чтобы найти новые файлы (которых еще нет в базе) и посчитать для них хеши по алгоритму. Но всё упирается именно в задачу перебора всех файлов в папке, чтобы найти именно новые
Ogoun
28.06.2017 20:47Можно сделать отдельный каталог для появления новых файлов, из которого скрипт будет переносить в каталоги с кучей файлов попутно отмечая в базе.

Varim
28.06.2017 21:48найти новые файлы
Чем плох FileSystemWatcher?Fahrain
29.06.2017 02:24+1Так мне не надо в реальном времени-то! Просто иногда запускаю процесс, который перебирает файлы и добавляет в базу новые, но далеко не каждый день это требуется делать.
Ну даже если использовать FileSystemWatcher — мне это не особо поможет, т.к. программа же все равно не будет знать о том, что между ее запусками какие-то файлы в папке поменяли/добавили. Т.е. мы опять возвращаемся к тому, что надо перебрать весь список файлов во всех подпапках папки, а этот процесс занимает более получаса — причем без чтения содержимого файлов! Фактически, мне нужно имя, путь и размер файла. При этом я уже и так отказался от использования FileInfo, оказалось, что для определения размера быстрее всего — открыть файл на чтение, как-то так:
using (var file = new FileStream(fn, FileMode.Open, FileAccess.Read, FileShare.ReadWrite)) { return file.Length; }
Судя по коду FileInfo, она запрашивает больше данных о файле и сильнее грузит жесткий диск в итоге, что при миллионе+ файлов уже в разы замедляет процесс скана.Varim
29.06.2017 09:24+2Программа Everything очень быстро ищет файлы, читая лог файловой системы. То есть прочитать лог быстрее, чем найти файлы в каталоге. Может вам стоит посмотреть в сторону работы с логом ($LogFile, $UsnJrnl of NTFS).
Fahrain
29.06.2017 11:49Ну, видимо это единственный вариант. Хотя это будет тот еще квест :)
Ну и тут может возникнуть другая проблема — размер MTF у меня 10,12 Гб…
P.S.: Я так и не нашел в .net других функций, которые бы не базировались бы в итоге на findfirst/findnext со всеми вытекающими из этого проблемами.imanushin
29.06.2017 15:37Кстати, если хочешь сделать совсем четко и реактивно, то использую Filter Driver. Вот ссылка на хабр.
И картинка оттуда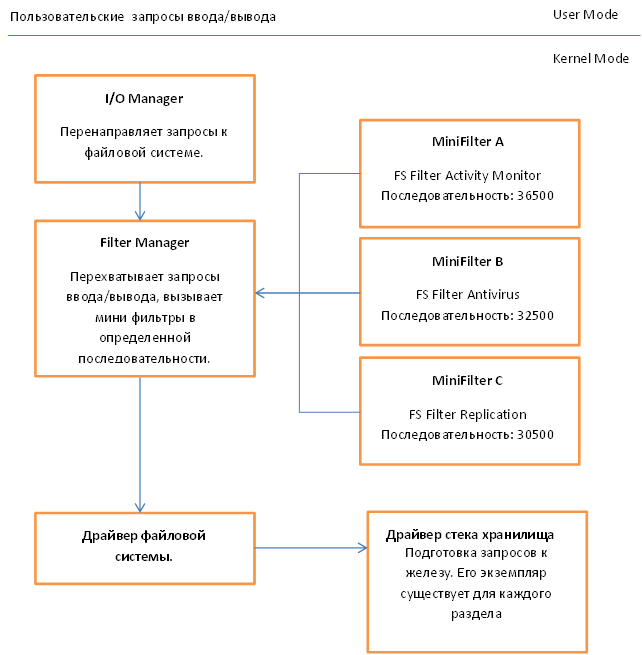
Fahrain
29.06.2017 15:39+2Ну это опять больше для риалтайма нужно… Да и тут C# уже не поможет и надо будет на C++ делать, со всеми вытекающими проблемами
KvanTTT
По-моему целесообразно убрать лидирующие нули в таблицах и отображать время в миллисекундах.
imanushin
Согласен, исправлю чуть позже