

Но зачем вообще понадобились технологии из области искусственного интеллекта, если еще лет двадцать назад мы прекрасно находили в поиске искомое? Чем «Королёв» отличается от прошлогоднего алгоритма «Палех», где также использовались нейронные сети? И как архитектура индекса влияет на качество ранжирования? Специально для читателей Хабра мы ответим на все эти вопросы. И начнем с самого начала.
От частоты слов до нейронных сетей
Интернет на заре своего существования сильно отличался от своего текущего состояния. И дело было не только в количестве пользователей и вебмастеров. Прежде всего, сайтов по каждой отдельной теме было так мало, что первым поисковым сервисам было достаточно вывести список всех страниц, содержащих искомое слово. А даже если сайтов и было много, то достаточно было посчитать количество употреблений слова в тексте, а не заниматься сложным ранжированием. Никакого бизнеса в интернете еще не было, поэтому накруткой никто не занимался.
Со временем сайтов, как и желающих манипулировать выдачей, стало заметно больше. И поисковые компании столкнулись с необходимостью не только искать страницы, но и выбирать среди них наиболее релевантные запросу пользователя. Технологии на рубеже веков еще не позволяли «понимать» тексты страниц и сравнивать их с интересами пользователей, поэтому сначала было найдено более простое решение. Поиск начал учитывать ссылки между сайтами. Чем больше ссылок, тем авторитетнее ресурс. А когда и их перестало хватать, то начал учитывать поведение людей. И именно пользователи Поиска теперь во многом определяют его качество.
В какой-то момент всех этих факторов накопилось настолько много, что человек перестал справляться с написанием формул ранжирования. Конечно, мы все еще могли взять лучших разработчиков, и они написали бы более-менее работающий поисковый алгоритм, но машина справлялась лучше. Поэтому в 2009 году Яндекс внедряет собственный метод машинного обучения Матрикснет, который и по сей день строит формулу ранжирования с учетом всех доступных факторов. Мы долгое время мечтали добавить к этим фактором тот, который отражал бы релевантность страницы не через косвенные признаки (ссылки, поведение, ...), а «понимая» ее контент. И с помощью нейронных сетей нам это удалось.
В самом начале мы говорили о факторе, который учитывает частоту слов в тексте документа. Это крайне примитивный способ определения соответствия страницы запросу. Современные вычислительные мощности позволяют использовать для этого нейронные сети, которые справляются с анализом естественной информации (текст, звук, изображения) лучше, чем любой другой метод машинного обучения. Проще говоря, именно нейросети позволяют машине перейти от поиска по словам к поиску по смыслу. И именно это мы и начали делать в алгоритме «Палех» в прошлом году.
Запрос + Заголовок
Более подробно о «Палехе» написано здесь, но в этом посте мы еще раз кратко напомним об этом подходе, потому что именно «Палех» лежит в основе «Королёва».
У нас есть запрос человека и заголовок страницы, которая претендует на попадание в топ выдачи. Нужно понять, насколько они соответствуют друг другу по смыслу. Для этого мы представляем текст запроса и текст заголовка в виде таких векторов, скалярное произведение которых было бы тем больше, чем релевантнее запросу документ с данным заголовком. Иначе говоря, мы с помощью накопленной поисковой статистики обучаем нейронную сеть таким образом, чтобы для близких по смыслу текстов она генерировала похожие вектора, а для семантически несвязанных запросов и заголовков вектора должны различаться.
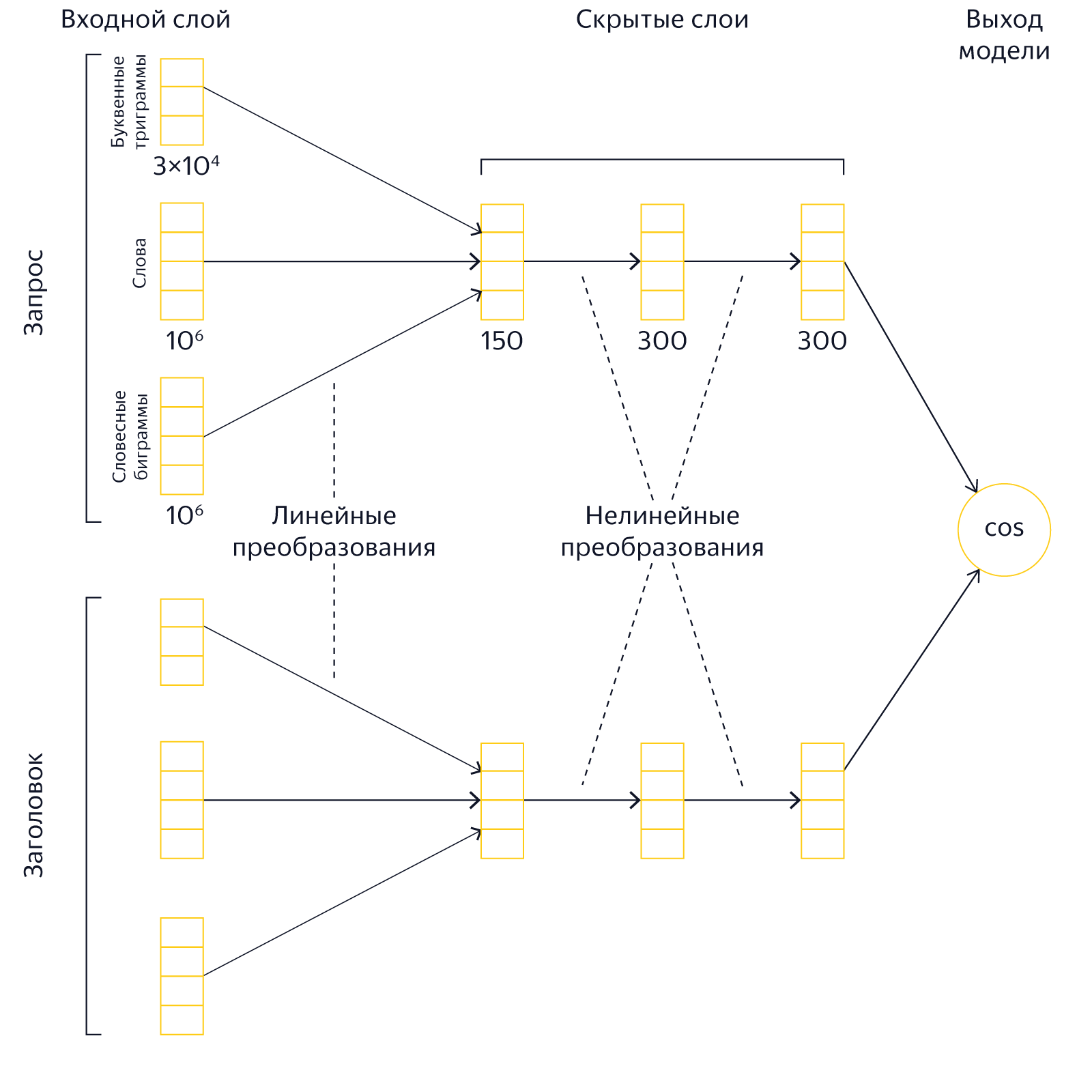
Как только человек вводит запрос в Яндексе, наши сервера в режиме реального времени преобразуют тексты в вектора и сравнивают их. Результаты этого сравнения используются поисковой машиной в качестве одного из факторов. Представляя текст запроса и текст заголовка страницы в виде семантических векторов, модель «Палеха» позволяет уловить достаточно сложные смысловые связи, которые иначе выявить трудно, что в свою очередь сказывается на качестве поиска.
«Палех» хорош, но у него был большой нереализованный потенциал. Но чтобы понять его, нам для начала нужно вспомнить о том, как именно устроен процесс ранжирования.
Стадии ранжирования
Поиск невероятно сложная штука: необходимо за доли секунды найти среди миллионов страниц наиболее релевантные запросу. Поэтому ранжирование в современных поисковых системах обычно осуществляется с помощью целого каскада ранкеров. Иными словами, поисковик использует нескольких стадий, на каждой из которых документы сортируются, после чего нижние документы отбрасываются, а верхушка, состоящая из лучших документов, передается на следующую стадию. На каждой последующей стадии применяются всё более тяжелые алгоритмы ранжирования. Это делается в первую очередь для экономии ресурсов поискового кластера: вычислительно тяжелые факторы и формулы вычисляются только для относительно небольшого количества лучших документов.

«Палех» – относительно тяжелый алгоритм. Нам нужно перемножить несколько матриц, чтобы получить вектора запроса и документа, а затем еще и их перемножить. Умножение матриц тратит драгоценное процессорное время, и мы не можем позволить себе выполнять эту операцию для слишком большого числа документов. Поэтому в «Палехе» мы применяли наши нейронные модели только на самых поздних стадиях ранжирования (L3) – приблизительно к 150 лучшим документам. С одной стороны, это неплохо. В большинстве случаев все документы, которые нужно показать в десятке, находятся где-то среди этих 150 документов, и нужно лишь правильно их отсортировать. С другой стороны, иногда хорошие документы все же теряются на ранних стадиях ранжирования и не попадают в топ. Это особенно характерно для сложных и низкочастотных запросов. Поэтому было очень заманчиво научиться использовать мощь нейросетевых моделей для ранжирования как можно большего числа документов. Но как это сделать?
Королёв: вычисления в обмен на память
Если нельзя сделать сложный алгоритм простым, то можно хотя бы перераспределить потребление ресурсов. И в данном случае мы можем выгодно обменять процессорное время на память. Вместо того, чтобы брать заголовок документа и во время исполнения запроса вычислять его семантический вектор, можно предвычислить этот вектор и сохранить его в поисковой базе. Другими словами, мы можем проделать существенную часть работы заранее, а именно — перемножить матрицы для документа и сохранить результат. Тогда во время выполнения запроса нам будет нужно только достать вектор документа из поискового индекса и выполнить скалярное умножение с вектором запроса. Это существенно быстрее, чем вычислять вектор динамически. Разумеется, при этом нам потребуется место для хранения предвычисленных векторов.

Подход на основе предвычисленных векторов позволил радикально увеличить глубину топа (L3, L2, L1), к которому применяются нейронные модели. Новые модели «Королёва» вычисляются на фантастическую глубину в 200 тыс. документов на запрос. Это позволило получить крайне полезный сигнал на ранних стадиях ранжирования.
Но и это еще не все. Успешный опыт предварительного вычисления векторов и их хранения в памяти расчистил перед нам дорогу к новой модели, о которой раньше мы могли только мечтать.
Королёв: запрос + документ
В «Палехе» на вход модели подавался только заголовок страницы. Обычно заголовок является важной частью документа, кратко описывающей его содержание. Тем не менее в теле страницы также содержится информация, которая чрезвычайно полезна для эффективного определения семантического соответствия документа запросу. Так почему же мы изначально ограничили себя заголовком? Дело в том, что на практике реализация полнотекстовых моделей сопряжена с рядом технических трудностей.
Во-первых, это дорого по памяти. Для применения нейронной модели к тексту во время выполнения запроса необходимо иметь этот текст «под рукой», то есть в оперативной памяти. И если положить в оперативку короткие тексты вроде заголовков было вполне реально на имеющихся в нашем распоряжении мощностях, то сделать это с полными текстами документов уже не получится.
Во-вторых, это дорого по CPU. Начальный этап расчета модели состоит в проецировании документа в первый скрытый слой нейронной модели. Для этого нам нужно сделать один проход по тексту. Фактически на данном этапе мы должны выполнить n*m умножений, где n – количество слов в документе, а m – размер первого слоя модели. Таким образом, количество процессорного времени, необходимого для применения модели, линейно зависит от длины текста. Это не проблема, когда речь идет о коротких заголовках. Но средняя длина тела документа существенно больше.
Всё это звучит так, будто внедрить модель с использованием полных текстов нельзя без радикального увеличения размера поискового кластера. Но мы обошлись без этого.
Ключом к решению проблемы стали те же самые предвычисленные вектора, которые мы уже испытали для модели на заголовках. На самом деле нам не нужен полный текст документа – достаточно хранить лишь относительно небольшой массив чисел с плавающей точкой. Мы можем взять полный текст документа на этапе его индексации, применить к нему череду операций, заключающихся в последовательном умножении нескольких матриц, и получить в результате веса в последнем внутреннем слое нашей нейронной модели. Причем размер слоя фиксирован и не зависит от размера документа. Более того, подобное перераспределение нагрузок с процессоров на память позволил нам по-новому взглянуть на архитектуру нейронной сети.
Королёв: архитектура слоев
В старых моделях «Палеха» имелось 3 скрытых слоя размером на 150, 300 и 300 нейронов. Такая архитектура была обусловлена необходимостью экономии вычислительных ресурсов: перемножать большие матрицы во время выполнения запроса дорого. Кроме того, для хранения самой модели также требуется оперативная память. Особенно сильно размер модели зависит от размера первого скрытого слоя, поэтому в «Палехе» он был относительно небольшим — 150 нейронов. Уменьшение первого скрытого слоя позволяет существенно уменьшать размер модели, но при этом снижает её выразительную способность.
В новых же моделях «Королёва» узким местом является лишь размер последнего скрытого слоя. При использовании предвычисленных векторов ресурсы тратятся только на хранение последнего слоя в индексе и на его скалярное умножение на вектор запроса. Таким образом, разумным шагом было бы придать новым моделям более «клиновидную» форму, когда первые скрытые слои увеличиваются, а последний слой наоборот уменьшается. Эксперименты показали, что можно получить хороший выигрыш по качеству, если сделать размеры скрытых слоев равными 500, 500 и 40 нейронам. В результате увеличения первых внутренних слоев выразительная сила модели заметно возросла, тогда как последний слой можно уменьшать до пары десятков нейронов почти без просадки качества.
Тем не менее, несмотря на всю нашу оптимизацию, столь глубокое применение нейронных сетей в поиске требует значительных вычислительных мощностей. И кто знает, сколько бы еще потребовалось времени на внедрение, если бы не другой проект, который позволил высвободить ресурсы для их применения, хотя решали мы с его помощью совсем другую проблему.
Королёв: дополнительный индекс
Когда мы получаем пользовательский запрос, то среди миллионов страниц индекса начинаем поэтапно выбирать лучшие страницы. Начинается все со стадии L0, которая фактически является фильтрующей. На ней отфильтровывается большая часть нерелеватных документов, а основным ранжированием занимаются уже другие стадии.
В классической модели поиска мы решаем эту задачу с помощью инвертированных индексов. По каждому слову хранятся все документы, в которых оно встречается, а когда приходит запрос, пытаемся эти документы пересечь. Основная проблема – частотные слова. Слово «Россия», например, может встречаться на каждой десятой странице. В результате мы должны пройти каждый десятый документ, чтобы не потерять ничего нужного. Но с другой стороны нас ждет пользователь, который только что ввел свой запрос и ожидает увидеть ответ в то же мгновение, поэтому фильтрующий этап жестко ограничен по времени. Мы не могли себе позволить обойти все документы для частотных слов и использовали разные эвристики: сортировали документы по некоторому значению индифферентной запросу релевантности или прекращали поиск, когда нам казалось, что нашлось достаточное количество хороших документов. В целом такой подход работал хорошо, но иногда терялись полезные документы.
С новым подходом все иначе. В его основе лежит гипотеза: если к запросу из нескольких слов взять не очень большой список из самых релевантных документов по каждому слову или словосочетанию, то среди них найдутся документы, релевантные одновременно всем словам. На практике это значит вот что. Для всех слов и популярных пар слов формируется дополнительный индекс со списком страниц и их предварительной релевантностью запросу. То есть мы выносим часть работы из этапа L0 на этап индексирования. Что нам это дает?
Жесткие ограничения вычислений по времени связаны с простым фактом – нельзя заставлять пользователя ждать. Но если эти вычисления можно произвести заранее и в офлайне (т.е. не в момент ввода запроса), то таких ограничений уже нет. Мы можем позволить машине обойти все документы из индекса, и ни одна страница не будет потеряна.
Полнота поиска – это важно. Но не менее важен тот факт, что ценой потребления оперативной памяти мы значительно разгрузили момент построения выдачи, высвободив вычислительные ресурсы для тяжелых нейросетевых моделей запрос+заголовок и запрос+документ. И не только для них.
Королёв: запрос + запрос
Когда мы начинали работать над новым поиском, у нас ещё не было уверенности в том, какое направление окажется наиболее перспективным. Поэтому мы выделили для исследований нейронных моделей две команды. До некоторых пор они работали независимо, развивая свои собственные идеи, и даже до некоторой степени конкурировали между собой. Одна из них работала над подходом с запросом и документом, о котором мы уже рассказали выше. Вторая же команда подошла к проблеме совсем с другой стороны.
Для любой страницы в интернете можно придумать более одного запроса. Тот же «ВКонтакте» можно искать с помощью запросов [вконтакте], [вконтакте вход] или [вконтакте социальная сеть]. Запросы разные, а смысл, который скрывается за ними, один. И это можно использовать. Коллеги из второй команды придумали сравнивать семантические вектора запроса, который только что ввел пользователь, и другого запроса, для которого мы точно знаем лучший ответ. И если вектора (а значит, смыслы запросов) оказываются достаточно близки, то и результаты поиска должны быть схожи.
В итоге оказалось, что оба подхода дают хорошие результаты, и наши команды объединили усилия. Это позволило достаточно быстро завершить исследования и внедрить новые модели в поиске Яндекса. К примеру, если сейчас ввести запрос [ленивая кошка из монголии], то именно нейронные сети помогают вытащить в топ информацию о мануле.
Что дальше?
«Королёв» – это не одна конкретно взятая модель, а целый комплект технологий более глубокого применения нейронных сетей в поиске Яндекса. Это еще один важный шаг в сторону будущего, в котором Поиск будет ориентироваться на семантическое соответствие запросов и страниц не хуже, чем человек. Или даже лучше.
Все вышеописанное уже работает, а некоторые другие идеи ждут своего часа. К примеру, мы бы хотели попробовать применить нейросети на стадии поиска L0, чтобы семантические вектора помогали нам находить документы, близкие по смыслу к запросу, но вовсе не содержащие слов запроса. Еще мы хотели добавить персонализацию (представьте себе еще один вектор, который будет соответствовать интересам человека). Но на все это требуется не только время и знания, но и память и вычислительные ресурсы, и здесь без нового дата-центра не обойтись. И у Яндекса такой уже есть. Но это уже другая история, о которой мы обязательно расскажем в ближайшем будущем. Следите за публикациями.
Комментарии (357)

sheknitrtch
22.08.2017 20:57+23Почему вы так не любите букву Ё? Ведь алгоритм назван не в честь жены короля, а в честь авиаконструктора. Сложно с первого раза правильно прочитать фразу:
… именно «Палех» лежит в основе «Королева».

BarakAdama Автор
22.08.2017 21:52+7Цитата и правда выглядит странно, но она же расположена далеко не в начале текста, и к этому моменту уже понятно, о чем идет речь. В общем, тут можно развязать длинный и никому не нужный филологический спор, поэтому я просто поставлю везде букву ё :)

StjarnornasFred
22.08.2017 23:54+16В русском языке 33 буквы, а не 32. Буква Ё — такая же буква, как и остальные. Заменять её другой буквой — всё равно что писать «карова», потому что «ну и так понятно».
BarakAdama Автор
22.08.2017 23:55+4Правила русского языка допускают замену буквы ё буквой е. http://www.gramota.ru/class/istiny/istiny_7_jo

Hardcoin
23.08.2017 01:11+13Потому что было проще добавить правило (=костыль), чем пропечатать эти точки в газетах. Но сейчас такой проблемы уже нет.

EgZvor
23.08.2017 09:05все разговорные языки — это куча костылей, а букву «ё» всё ещё неудобнее набирать, чем «е»
bopoh13
23.08.2017 15:43+4Вообще не аргумент.
Соверш(е|ё)нный, передохн(е|ё)м, узна(е|ё)м, приближ(е|ё)нных, вс(е|ё), н(е|ё)бо, бер(е|ё)т, в(е|ё)сел, гн(е|ё)т, л(е|ё)том, м(е|ё)л, н(е|ё)м, ос(е|ё)л, отс(е|ё)к, по(е|ё)м, сл(е|ё)з, съ(е|ё)м, пад(е|ё)ж
Теперь найдём предложения с этими словами и попытаемся быстро из контекста понять о чём речь. Неудобно разбираться в плохо оформленном исходнике!
Она плохо выглядит, зато хорошо звучит. ©
Она прекрасна!

inoyakaigor
23.08.2017 15:43Это потому, что раскладку делали по остаточному принципу абы как, а не по уму

sumanai
23.08.2017 16:14Потому что вкорячили русскую на уже существующую латинскую. Сама по себе раскладка не плоха, добавь в ней ещё один столбец с Ё и отдельной запятой.

Myosotis
23.08.2017 17:28+2А жители некоторых стран не ленятся печатать диакритические знаки (e, e, e, i, a). И мы ведь пишем "й", чем "ё" хуже?

solariserj
24.08.2017 18:43В румынском основа латинская с 6 диакритическими знаками на основе(s,t,a,i), в переписках спокойно могут использоваться только латинские буквы для упрощения, но статьи и более официальные документы, не использовать их считается моветоном и должны быть приведены в порядок.

sapman
23.08.2017 09:31+2а для Й такого правила почему-то не добавили, печатали хвостик сверху в газетах всегда
pestilent
25.08.2017 16:40Если досмотреть статью до конца, можно увидеть, что современные правила рекомендуют писать «ё» в именах собственных всегда.

odissey_nemo
23.08.2017 09:06Королёв только в молодости был авиаконструктором, оставшуюся жизнь он разрабатывал космические носители.




klikalka
22.08.2017 20:57+3Посмотрел, с удовольствием, трансляцию (вернее, большой часть из неё).
Спасибо вам огромное за то что вы делаете!)
Я понимаю что над системой поиска ещё работать и работать (в том плане что процесс разработки и усовершенствования, по сути, бесконечный), но лет 15 назад даже то что уже есть сейчас казалось просто фантастикой.
erwins22
22.08.2017 20:57+1Очень часто поиск в Яндексе выдает один и тот же документ размещенный на разных сайтах, в то время как у гугла выдается только один.
BarakAdama Автор
22.08.2017 21:04Можете присылать такие примеры. Вместе посмотрим.

asdoc
23.08.2017 15:06Я Вам прислал именно такой пример.
При этом этот один текст выдается не на сайте, где был опубликован впервые, а на сайтах, которые сделали копи-паст, подчас удалив или изменив ФИО автора.
asdoc
23.08.2017 17:34+1Вот еще пример. Немного утомительный, но иллюстративный.
(полные ссылки отправил личным сообщением)
Только что проверил (в очередной раз).
В запросе два ключевых слова по теме статьи, написанной в 1998г.
Первопубликация, оригинал — w.....article4.htm дата создания — ранее 23.04.1999г
Доказательства: От 14.02.2001г web.archive.org/.....article4.htm
От 23.04.1999г web.archive.org/....article4.htm
Т.е. по идее именно эта страница должна быть на первой позиции.
Но вместо нее на первой же позиции выдачи — копия — w.b..........01
Восьмая позиция еще один копипаст w.m..........54.htm
Вторая страница
седьмая ссылка — копипаст //lo..............ko.html
восьмая — копипаст //mi..................ko
девятая — копипаст //www.m................54.htm (причем повтор с первой страницы выдачи. Т.е. на второй странице выдачи та же ссылка, что и на первой странице)
десятая — копипаст //www.b............01 (аналогично — повтор ссылки с первой страницы)
Четвертая страница
четвертая ссылка — копипаст//e..................5
пятая страница — копипаст //d............1
девятая — копипаст //k..........80.html
десятая — копипаст //m.........9.html
Пятая страница
первая позиция — копипаст //s.................2.html
вторая — копипаст //l.............9.html
шестая — копипаст //y...........5.htm
седьмая — копипаст //d...........93
восьмая — копипаст //www.m...........73
Шестая страница
вторая позиция — копипаст //www.p..........C.pdf
третья — копипаст //b........z.html
пятая — копипаст //www.s...........76.0
шестая — копипаст //k...................73.html
седьмая — копипаст //www.k...............161
Седьмая страница
четвертая позиция — копипаст //e............................oz
И так далее…
А где же оригинал, первоисточник, первопубликация, не менявшая адрес с 1998г?
А его нет.
Просто нет.
Во всяком случае на 30 страницах выдачи. Т.е. среди 300 ссылок выдачи копипасты статьи более 30-ти раз, а оригинала нет.
Я, конечно, пишу хорошие статьи. Плохие не воруют.
Но если это поиск, то…asdoc
23.08.2017 21:47Т.е. 10% выдачи первых 30-ти страниц — копипасты одного моего текста.
Если это качество, если это «мы стараемся не ранжировать высоко сайты с вторичным контентом» (Яндекс), если это «найдется все», то…
А ведь как просто — выдать один раз первоисточник. А далее что-то еще, другое.
Вот тогда будет конкуренция качественных текстов, а не конкуренция оптимизаторов.
Тогда вебмастер на самом деле будет думать как сделать «сайт для людей», а не о том, как перехитрить робота.
Tiberiumk
24.08.2017 15:42Это на самом деле очень сложно сделать (чтобы работало всегда)
asdoc
24.08.2017 17:51В смысле? Сложно удалить из выдачи копии, оставив только источник? Сложно расставить копии под источником, согласно дате создания?
Сложно Вам? Сложно мне?
Согласен.
Сложно Яндексу?
Нет.
Этот механизм у Яндекса был и расставлял все корректно в 2009 — 2011 году, например.
Т.е. тут даже придумывать ничего не нужно. У Яндекса есть эта технология.
Но ему лень.
Не лень только врать про понижение сайтов со вторичным контентом, ибо понижает он источники, первопубликации, исходники.
В принципе, таким образом, Яндекс обманывает своих пользователей, подсовывая им в выдаче вместо оригинала — копию.
Это как вместо яблока дать муляж. Выглядит может быть и красивее, но не вкусно.
kryvichh
25.08.2017 13:54Яндекс, я б на вашем месте пригласил человека в офис и обговорил все детали на месте. Вам же лучше будет. :)
asdoc
26.08.2017 11:19Для Яндекса определить первопубликацию, источник — это вопрос индексации и сравнения двух — трех баз. И сделать это нужно однажды, ибо первопубликация всегда остается таковой — она привязана к дате и сайту.
Более половины, а м.б. 80% первоисточников тогда будут корректно определены.
В некоторых случаях, действительно, это сделать сложнее (наверно). Я не знаю как. Но в Яндексе вроде бы много светлых голов? Или нет?
asdoc
23.08.2017 22:27Тимур
Пример на «Очень часто поиск в Яндексе выдает один и тот же документ размещенный на разных сайтах» выслан.
А Вашей реакции нет.
asdoc
25.08.2017 12:45Тимур. Вот Вам дополнение (ссылки смотрите в личном сообщении).
Кроме того, что Яндекс не нашел первоисточник и ввел пользователей в заблуждение, выдав 30 копий, вместо одной первопубликации… Т.е. просто замусорив выдачу.
Яндекс и с поиском ответов не справился.
Только на моем сайте он не нашел по данной теме:
Еще четыре популярные статьи по этой теме
m...............cle56.htm
m...............pia.htm
m..............ikl371.htm
m.................tikl314.htm
четыре текста для специалистов
m................ikl307.htm
m.....................ioz15.htm
m.......................z14.htm
m.................oz16.htm
Расшифровку двух интервью
m.............tv13.htm
m...........tv7.htm
Расшифровки лекции и семинара
m.................le427.htm
m...................gia.htm
Подборку ответов на вопросы по этой теме
m...................tez.htm
m......................a.htm
Т.е. 14 релевантных запросу документа Яндекс на моем сайте не нашел и в выдачу не поставил.
Зато поставил 30 копий моей статьи m...........cle4.htm, забыв показать в выдаче ее как источник (первопубликацию) и вообще исключив источник из выдачи.
Так же в выдаче нет вот этого уважаемого журнала, где так же размещена статья по теме. lv........0932/
Или книги по той же теме books............lse
О каком качестве выдачи можно говорить в этом случае?
Множество документов не найдено.
Источники не найдены.
Выдача замусорена копиями (и не только моего текста).asdoc
25.08.2017 16:15-1Таким образом…
И «Найдется все» и «Зеркало Рунета» — это вранье. Введение потребителя в заблуждение. Яндексу было бы полезно изучить закон о «Защите прав потребителя».
И это не единственный закон, который Яндекс нарушает, показывая копии вместо источника и скрывая информацию (все эти страницы Яндексом проиндексированы, но в выдаче их нет, хотя они точно соответствуют тексту запроса).
asdoc
25.08.2017 19:35Итак, Тимур.
С тем, что Яндекс вводит в заблуждение пользователей, скрывая информацию мы разобрались.
С тем, что Яндекс — кривое «зеркало Рунета», показывающее копии вместо оригиналов тоже.
Что с этим делать пользователю — понятно. Ну его, такой сервис. Есть другие поисковые системы.
Что делать автору понятно тоже — прекратить писать, потратить время на что-то более полезное. Или вот сюда писать, например… Или Платону… Но Платону — это все равно, что в шредер — в пустоту.
Теперь о том, как Яндекс обманывает вебмастеров.
Есть два сайта. Со сравнимым ТИЦ (сотни, были тысячи), сравнимым (тысячи) количеством страниц с контентом, сравнимым (тысячи в сутки) количеством посетителей.
Оба сайта сделаны для людей, оба на 2012 год имели десятки тысяч посетителей в сутки.
Сайт А — метатеги прописаны верно. Сайт В — криво.
С тегом Н1 то же самое.
На А есть мобильная версия, В не адаптирован.
Ракламы на В больше.
Тег noindex на А расставлен корректно, на В — отсутствует.
Сайт А содержит 99% текстов «первопубликаций», т.е. впервые текст опубликован в Интернете именно на А.
У сайта В с этим похуже. Примерно 30% первопубликаций.
Страницы сайта А загружаются в 10 раз быстрее сайта В.
На сайте А битых ссылок нет (ни внешних, ни внутренних). У сайта В — есть.
У сайта А хорошая карта сайта, у В — плохая.
Сайт А обновляется чаще сайта В.
Сайт А на 5 лет старше сайта В.
По мелочи так же — у сайта А меньше грехов, чем у В.
У А есть он-лайн сервис. У В — нет.
Итого… Сайт А гораздо лучше соответствует всем рекомендациям Яндекса для вебмастеров, чем В.
Сайт В по множеству параметров не соответсвует.
Итого десятки параметров различны. (Здесь намек на танец Платона «алгоритм выдачи учитывает сотню параметров».)
Оба сайта «чисты», не под «фильтрами», по утверждению «Платона» и данным «Вебмастера».
Однако динамика падения посещаемости у обоих сайтов одинаковая. Выпадение страниц из Яндекс выдачи — одинаковое. Математический нонсенс, доказывающий, глюк алгоритма ранжирования и выдачи.
Т.е. Яндекс не учитывает в алгоритме выдачи свои же рекомендации. Т.е. заставляет вебмастеров тратить время впустую. Обманывает их. Заставляет гадать и дергаться, вместо того, чтобы «делать сайты для людей».
А потом пляшет вокруг с бубном «Матрикснета», рассказывая, что у него миллионы данных, а у вебмастера лишь тысячи в лучшем случае.
Но как сказал здесь один комментатор: "… математическое доказательство.
Есть утверждение, «...». Чтобы доказать, что утверждение неверно, достаточно 1 контрпримера!"
Контрпримеров только я уже прислал Вам, Тимур, несколько. Могу еще. Сколько нужно? 10, 100, 1000. У меня 5300 страниц на сайте А. Значит, несколько тысяч я Вам точно могу прислать.
Но как уже сказано выше для того, чтобы понять, что алгоритм работает криво достаточно одного примера. У Вас, Тимур, уже больше одного примера.
Так что в реальности эти пляски имеют цель скрыть ошибки и обман, рассказывая про фильтры для вторичных сайтов и прочее. В действительности же Яндекс, вероятно, внедряет какие-то иные фильтры, которые не имеют отношения к качеству «сайта для людей», а имеют отношения либо к деньгам, либо к благонадежности, либо к личным пристрастиям кого-то из Яндекса.
Иного объяснения нежеланию исправлять многолетнюю ошибку я не вижу.
Хотелось бы услышать от работников Яндекса объяснение — почему не исправлена ошибка, почему копипаст выше оригинала, почему Яндекс обманывает вебмастеров и читателей? В чем его выгода?
Я, правда, пойму, если это разумная стратегия.
Пока же это напоминает стратегию временщиков — «украл, выпил...» — дальше сами знаете, полагаю.
И если я делаю сайты «для людей», то Яндекс делает что-то иное и для чего-то другого.

foxyrus
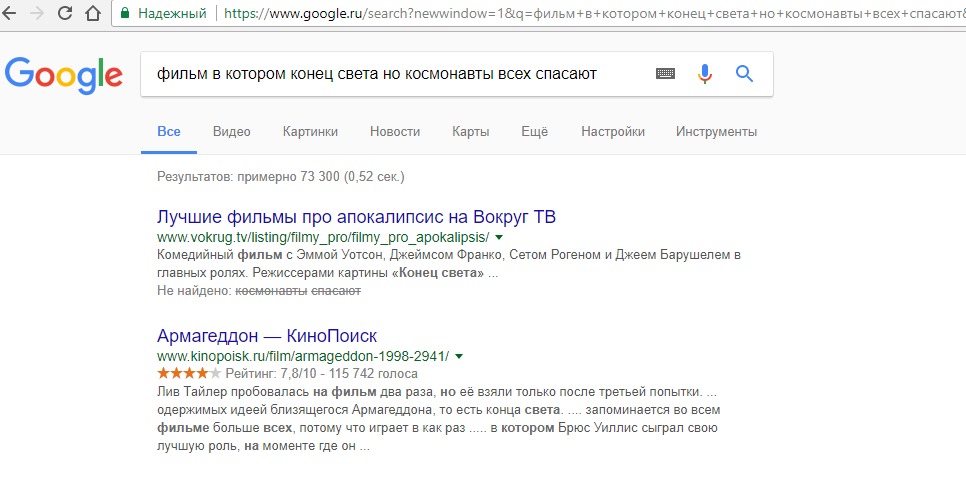
22.08.2017 21:14+3Хм
Сравнение выдачи Yandex и Google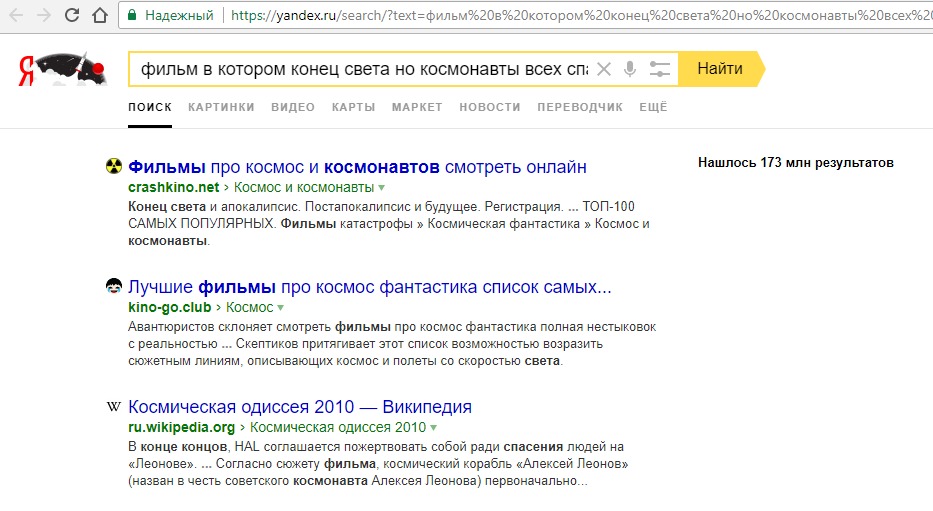
volanddd
22.08.2017 21:27+1А у меня так
foxyrus
22.08.2017 21:31Все равно не первая строчка
BarakAdama Автор
22.08.2017 21:33+1Поведение пользователей может влиять, если «смотреть онлайн» для них важнее, чем просто информация о фильме.
foxyrus
22.08.2017 21:35Я залогинен под своей учеткой и никогда не интересовался у Яндекс просмотром онлайн.
BarakAdama Автор
22.08.2017 21:36Поведение всех пользователей, их выбор.
foxyrus
22.08.2017 21:41+1Но а как же «нейронная сеть»? При чем тут поведение всех пользователей? Я ищу конкретный фильм не зная названия. Пример из вашей презентации.
BarakAdama Автор
22.08.2017 21:45Нейронные сети – один из факторов, который помогает найти неочевидные связи. Но поведение пользователей никто не отменял. Ведь нейронные сети на чем-то обучаются. И это реальная статистика поиска. К тому же для низкочастотных запросов, которые обычно пользуются небольшой популярностью, неожиданный трафик людей, которые и фильм-то на самом деле не ищут, а просто кликнули по ссылке, мог привести к подобному.

LoadRunner
23.08.2017 10:25А как же более релевантная поисковая выдача, основанная на поисковых запросах конкретного юзера? Гугл это делает (Большой Брат следит и всё такое).
BarakAdama Автор
23.08.2017 10:48Все это тоже есть.
micro-CMS
23.08.2017 20:57-3персональной выдачи НЕТ, только показ сайтов что раньше посещал. Вот набираю в 2х поисковиках «человек гугла который в твитттере пишет» — шишь, пишу «мюллер» — итог «гестапо». А я у Мюллера читаю всё, в переводе и иногда в оригинале, вхожу открыто и все аккаунты мои про СЕО. ИТОГО: ЯНДЕКС перенял у Мюллера ГУГЛА трепаться без понимания что и как происходит на СВОЕЙ кухне.
volanddd
22.08.2017 21:46Почитайте про алгоритм. Там нейросетка учится на толоконщиках и прочих школьниках… Большой минус кстати, но, зато, bigdata
BarakAdama Автор
22.08.2017 21:49+2Толока и профессиональные асессоры – это лишь часть. Добавьте к этому bigdata от миллионов обычных пользователей Поиска.
volanddd
22.08.2017 21:54а… отлично!!!
А то в презентации это не упомянули, что повергло меня в когнитивный диссонанс
Akser
23.08.2017 15:45+1не знай почему у вас справа пусто…
у меня все ОК
Заголовок спойлера
alexeymrkn
22.08.2017 21:29+7Это очень здорово, но удивило, что ссылка с вашего лендинга про новый алгоритм, которая ведёт на этот специфический вопрос выдаёт совсем не то, что обещает.
Скриншот с лендинга

Результат выдачи

Но самое забавное в другом:
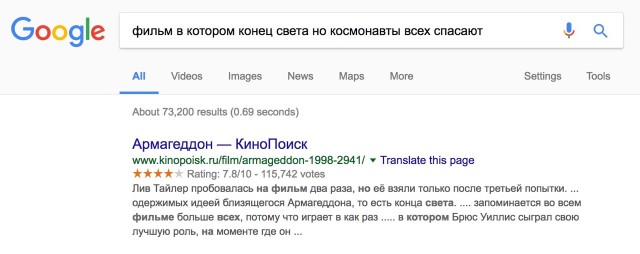
BarakAdama Автор
22.08.2017 21:42+1Он там тоже есть, но в данный момент начал «прыгать». Запрос изначально низкочастотный, и неожиданный трафик с лендинга мог привести к подобному.
bopoh13
24.08.2017 13:42Американский фильм вышёл не раньше середины 90-х. У молодого человека, которого играет актёр от 1960 до 1970 года рождения, сдают нервы от современных технологий, — он приходит домой и разбивает телефон, который зазвонил.
Как улучшить запрос? Не могу вспомнить название фильма.BarakAdama Автор
24.08.2017 15:54А что за фильм?

jetexe
24.08.2017 15:57спрашивает яндекс…
BarakAdama Автор
24.08.2017 16:10Яндексом меня еще никто не называл :)
bopoh13
24.08.2017 17:50Серьёзно: как улучшить запрос для нейронной сети, чтобы найти фильм?

vintage
23.08.2017 18:45+1alexeymrkn
23.08.2017 20:44Всё дело в мигающих звёздах.
.space__twinkling { z-index: 1; background-color: transparent; animation: move-twink-back 1s linear infinite; } @keyframes move-twink-back { 0% { background-position: 0 0 } 100% { background-position: -10000px 5000px } }vintage
24.08.2017 00:39+7Вот мы и дожили до того момента, когда для того, чтобы помигивать иногда пикселами, нам нужно два ядра на несколько гигагерц.
DROS
22.08.2017 21:51+14По моему это пошло, называть поисковый алгоритм именем Великого, с большой буквы, Человека. Да к тому же, работающий хрен знает как. Кстати, при чем тут Королев то? Я так и не понял.
Ну а поисковая выдача Яндекса, с каждым днем становится все хуже и хуже. Уж не знаю, учитывается ли там статистика мои запросов индивидуально или нет (хотя несколько лет назад твердили, что учитывается) — но если я ищу что-то конкретное по определенной теме, то в выдаче 95% результатов на первой странице будут одними и теми же, хотя я прекрасно знаю что ищу и уже конкретно пишу ключевую фразу в кавычках (и с "+", и без...). Но Яндексу видимо пофигу. А что до тех оставшихся 5% — так там может вылезти такое, что вообще не имеет никакого отношения к поиску.
Отдельно заслуживает внимания навязчивая простыня рекламы по любому обновлению любого сервиса Яндекса. Но это уже не относится к теме поста, а в общем и целом.BarakAdama Автор
22.08.2017 21:54+3Если Вы пришлете мне такие примеры, то мы посмотрим, что с ними не так.
DROS
22.08.2017 22:09Просто бросить в личку или оформить как некий тикет в баг.траке (ну или в ТП написать например)?

l_stoch
23.08.2017 15:07+2Тоже что-то пошло не так, ссылка на видео с музыкантами из Монголии) в любом случае, спасибо за статью)
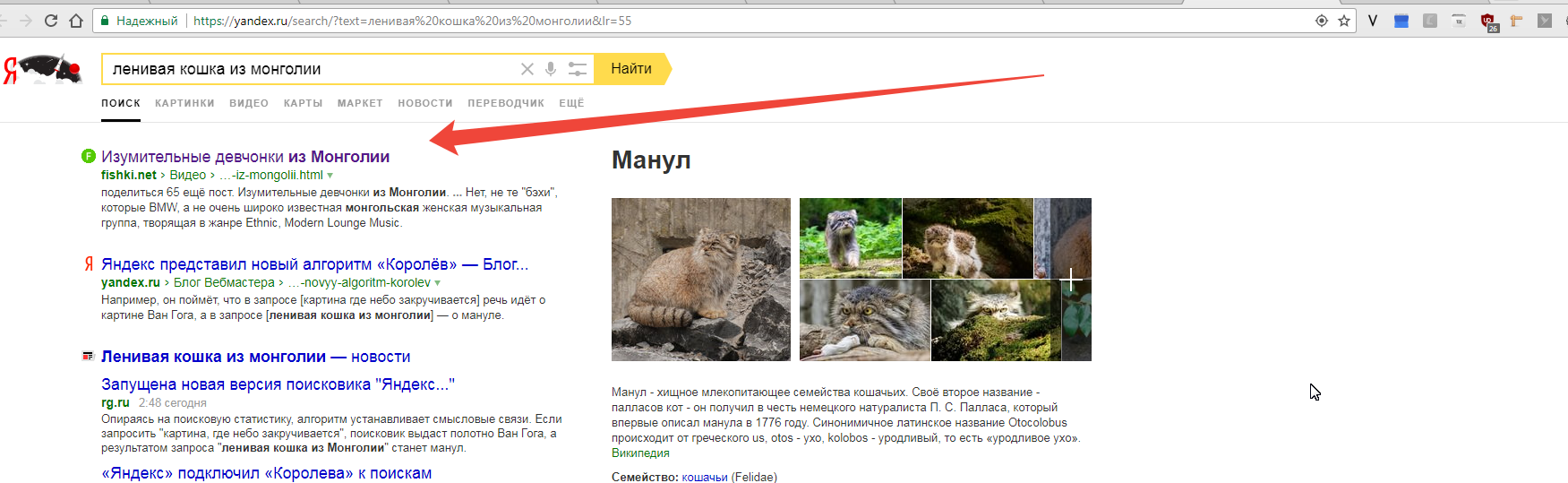
BarakAdama Автор
23.08.2017 15:08Низкочастотный запрос, на который вдруг пошел большой трафик пользователей, которые и кошку-то на самом деле не ищут. На такую неестественную ситуацию может быть разная реакция.
vintage
23.08.2017 18:50Вы хотите сказать, что сортируете по популярности вместо количества совпавших слов?
BarakAdama Автор
23.08.2017 18:58Нет. Факторов очень много. Учитывается все.
vintage
23.08.2017 19:20Почему у вас фактор "популярность" перекрывает фактор "число совпавших слов"?

sebres
23.08.2017 19:52Не зная внутрянку тех механизмов в Яндексе, могу предположить что фактор "популярность" гораздо менее прожорливый (по накладным расходам, как например LA, так и по времени исполнения запроса) чем фактор "число совпавших слов".
Если конечно запрос не повторялся и оно (пара слова/число) не "кэшируется"...vintage
23.08.2017 20:09В рамках конкретной выборки его всяко можно пересортировать как следует, а не как попало.
BarakAdama Автор
23.08.2017 22:20Я же рассказывал, что нет никакой готовой формулы. Форумы рождаются и постоянно меняются внутри Матрикснета.
vintage
24.08.2017 00:44Почему у вас Матрикснет генерирует такие формулы, где фактор "популярность" перекрывает фактор "число совпавших слов"?
BarakAdama Автор
24.08.2017 08:07+1Потому что зачастую искомый ответ не содержит слов из запроса, но прекрасно отвечает на вопрос пользователя. По мнению пользователя.
vintage
24.08.2017 08:28Если зачастую, значит вам не сложно будет привести пример?
BarakAdama Автор
24.08.2017 08:45[ирландское евангелие] для которого правильный ответ – это «келлская книга».
vintage
24.08.2017 09:04+1
Гугл нашёл и "ирландское" и "евангелие". В любом случае правильным ответом будет "возможно вы имели ввиду келлскую книгу?", а не поиск по совершенно другому запросу.

u007
23.08.2017 18:56В гугл тоже пошёл не меньший трафик, но он от этого не сломался, а только окреп — Армагеддон поднялся со второй до первой строчки. Может, он проиндексировал вашу статью?))
PS Если поисковику так легко «отравить» низкочастотный запрос, то понятно откуда берутся [перламутровые] и [почему путин краб]…BarakAdama Автор
23.08.2017 18:58Меньший. Далеко не все, кто посмотрел у нас, пошли проверять это у других.

ReinRaus
23.08.2017 19:14То есть Ваш поисковик не готов к резкому всплеску популярности запроса? Например появляется очередной "Pokemon GO" и начинается огромный поток запросов по нему. Какая будет реакция? Естестенна ли данная ситуация?
Q001
23.08.2017 19:32То есть Ваш поисковик не готов к резкому всплеску популярности запроса?
Здесь на этом сайте уже была у Яндекса статья про специальные алгоритмы для новостей.
asdoc
23.08.2017 19:23Я Вам прислал примеры в личку. И в ответ получил тишину.
BarakAdama Автор
23.08.2017 22:21Я их сейчас собираю. Мгновенно никто не разберется же в них.
tundrawolf_kiba
24.08.2017 00:25Ну как вы не понимаете — время фикса бага должно быть бесконечно малой величиной стремящейся к нулю. А время воспроизведения и ретестирования дефекта — должно быть отрицательным :-)
BarakAdama Автор
24.08.2017 08:08Но так не бывает в природе :(
asdoc
24.08.2017 15:31Если не считать того, что я написал «Платону» об этом много раз с примерами за последние 4 года. Результат — отрицательный. Т.е. ситуация не улучшилась, а ухудшилась.
4 года — это вроде достаточный срок для исправления лажи?
kryvichh
23.08.2017 15:24+3Есть такое. Если ищешь человека с редкой фамилией, то обязательно предложат другой вариант, даже если взять слово в кавычки. Я б посоветовал слова в кавычках не пытаться исправить орфографию или подменить на более релевантные с точки зрения алгоритма, а искать как есть.
Чтоб не быть голословным: поиск по имени "Альфи" в Яндексе выдаст кучу ссылок на фильм «Красавчик Алфи, или Чего хотят мужчины». Даже если закавычить это слово. Гугл же дает ссылку на актера Альфи Аллена. Я понимаю, что большинство русскоязычных пользователей Интернета орфографически безграмотны и наверное при запросе «Альфи» на самом деле они искали тот фильм. Но при добавлении кавычек хотелось бы, чтобы Яндекс искал именно заданное слово.
Еще хуже, когда ищешь слово на белорусском языке. Учитывая близость к русскому, начинается настоящая борьба с орфографическим анализатором поисковика.kryvichh
23.08.2017 15:45Еще пример: ищем по фамилии Джерико. И Яндекс и Гугл выдают ссылки с английскими названиями «Jericho». Но мне нужно именно русское название, ok, закавычиваю: «Джерико». Гугл тут же полностью меняет выдачу и дает страницы с нужным словом. Яндекс — нет, все по-старому. Возможно, я просто не умею готовить?
kryvichh
23.08.2017 16:22Контрпример, если искать по имени Джэми, то без кавычек дает ссылки на Джейми Фокса и Джейми Чона, а с кавычками — на Джэми Харриса и Джэми Уйс. То есть кавычки работают, но не всегда.
u007
23.08.2017 18:58Кавычки у них не работают. Точнее, они сами не знают, как они работают — суппорт признался. Чтобы кавычки работали как этого от них ждёшь, в кавычках должен быть весь запрос целиком, и ничего больше. И да, меня это тоже бесит, но такова селяви, бодаться с ними бесполезно. На запрос с кавычками сразу иду в гугл.

Am0ralist
24.08.2017 01:15в кавычках должен быть весь запрос целиком
ложь, п***ж и провокация.
нифига не помогает.
И выбор настройки «точно так, как в запросе» — не помогает.
Ну нельзя заставить яндекс искать то, что нужно тебе, нельзя.
u007
23.08.2017 23:21Чтобы найти Джерико на русском, подойдёт восклицательный знак: [! Джерико], или даже [! Джерико -Jericho]
Пару месяцев назад, кстати, был масштабный сбой, минус-слова не работали. Может, BarakAdama поделится инфой, что там тогда случилось? И почему так плохо всё с кавычками?
tundrawolf_kiba
22.08.2017 22:29+1Раз тут зашла речь о семантике — то сразу интересует вопрос — а в данном случае возможно ли использовать наработки ABBYY по Compreno?

ServPonomarev
23.08.2017 16:04Я отвечу — нет, совсем не тот уровень производительности. Или скорость, или качество.
isersh
22.08.2017 22:35+13Вспомнилось из старенького:
Яндекс — «Найдётся всё!»
Гугл — «А ничего и не терялось»…
:)
asdoc
22.08.2017 22:42+28Хвалиться — это, конечно, хорошо. Когда есть чем.
Качество поиска Яндекса ужасное. С каждым годом все хуже и хуже.
О каком «Королеве» можно говорить, если Яндекс банально не может отличить авторский текст от ворованного, первопубликацию от копии, текст специалиста от текста ничего не понимающего в теме компилятора?
Результат — повсеместное поощрение копипаста и воровских сайтов (они в выдаче на первых позициях), фактическая пессимизация оригинального контента (его просто нет в выдаче… совсем). (Что противоречит опубликованным Яндексом принципам. Т.е. Яндекс — врет.)
Результат — нерелевантная выдача, низкое качество поиска. (Это не очевидно только на первый взгляд, но если наплевать на качество и заигрывать с ворами в одном, то и все остальное сыпется.)
Результат — потеря доли поискового трафика по 5% в год.
И до сих пор никто не уволен. Ничего не исправлено. К любым обращениям Яндекс глух.
Смешно.
Еще несколько лет такого «качества» и Яндекс просто исчезнет.asdoc
22.08.2017 23:09+37Дополню, чтоб не голословно было…
Несколько лет назад я заметил значительное снижение заходов на мой сайт из Яндекса. С Гууглом при этом все было в порядке.
Начал разбираться.
Выяснилось, что вместо моих оригинальных текстов, моих первопубликаций, моих авторских текстов, в выдаче Яндекса сайты, которые своровали мои тексты, страницы копипастеров.
Рекорд был, когда я обнаружил, что мой текст, который я опубликовал на своем сайте впервые в 1998 году, Яндекс выдает на 70-ти сайтах-ворах.
Т.е. в выдаче я насчитал 70 копий моей статьи на чужих сайтах… А своего сайта в выдаче так и не нашел. Совсем.
Начал переписку с Яндексом.
Ответ — «работайте над сайтом», «пишите оригинальные тексты».
Мой ответ — «у меня размещено 5000 оригинальных хороших текстов, только в выдаче они показаны не на моем сайте, а на сайте вора-копипастера».
Ответ Яндекса — «мы не следим за авторскими правами».
И так 4 года.
Но Яндекс врет.
И вот почему.
1. Яндекс утверждает, что он «лишь зеркало Интернета»… ну так не кривое же зеркало. Значит, оригинал, первичная публикация должна быть в выдаче выше копипаста. И раньше, до 2012 года так и было.
2. Яндекс пишет на своей странице «Некачественные сайты»: «Мы стараемся не индексировать или не ранжировать высоко: Сайты, копирующие или переписывающие информацию с других ресурсов и не создающие оригинального контента.»
Яндекс пишет там же: «Сайты, которые содержат неоригинальный, вторичный… контент… Исключение из поиска страниц сайта, понижение в результатах поиска, аннулирование тИЦ»
И еще там же: «Создавайте сайты с оригинальным контентом или сервисом.» (Что я и делал с 1998г. и по сей день делаю).
Однако…
Что же по факту?
По факту десятки ресурсов, разместивших копии моих текстов в выдаче есть. Моего сайта нет.
Яндекс врет или не умеет работать?
Полтора года назад поставил эксперимент. Решил «вылизать» сайт в соответствии со всеми рекомендациями Яндекса.
1. Прописал правильно все метатеги.
2. Правильно проставил H1.
3. Удалил 80% рекламы.
4. Все ссылки, все, что не относится к сути страницы, тексту статьи, включая навигацию, закрыл в noindex.
5. Улучшил юзабилити — фон, границы, внутреннюю перелинковку, шрифт, расположение статьи на странице, добавил картинки, прикрепил интерактивный чат для пользователей для моментальных консультаций.
6. Оптимизировал код страниц, удалил все скрипты, которые было можно, ускорил загрузку страниц в 3-5 раз. (В 10 раз быстрее, чем у копипастеров, которые в выдаче вместо моей первопубликации оригинального текста).
7. Оптимизировал для мобильных устройств (Яндекс и Гуугл сейчас считают сайт оптимизированным. Замечаний в «Вебмастере» нет).
8. Добавил (за несколько лет, разумеется) около 1000 новых текстов, прописав все сначала в «Оригинальных текстах» Яндекса.
9. Исправил 99% входящих «битых» ссылок. (Замечу — никогда никакие СЕО-ссылки не покупал. Все ссылки на мой сайт «естественные».)
10. Убрал 100% внутренних битых ссылок и т.п. ошибок (404 и др.)
11. Исправил орфографию, форматирование и т.п. огрехи там, где были.
12. Сделал карту сайта.
13. Перенес сайт на самый быстрый сервер провайдера.
14. Убрал во фреймы часть рекламы и навигации, чтобы грузилось быстрее, чтобы робот работал со страницей быстрее и точнее индексировал (только сам контент, саму статью).
15. И еще много чего по мелочи. Осталось сделать еще на части сайта перелинковку.
Каков же результат?
Для сайта с 5000 оригинальными статьями, размещенными с 1998 по 2016 год, никогда не менявших URL, с общей посещаемостью в несколько тысяч человек в день от всех этих изменений, затронувших 99% страниц…
Результат… ноль!
А точнее — минус. За этот год в Яндекс-выдаче сайт упал еще вдвое. При этом в Гуугле не изменился.
Гуугл как выдавал мои оригиналы выше копипастов, так и выдает. Яндекс — наоборот. Как пособничал ворам-копипастерам, так и продолжает.
Предположил, что Яндекс просто «потерял» данные о первоисточниках. Может сгорела у него база или что еще…
Написал в поддержку алгоритм, как можно восстановить базу первопубликаций до 2005 примерно года с гарантией (позже чуть сложнее, но тоже можно).
В ответ — молчание.
Просто молчание. Это Яндексу не интересно. Не нужно. Он самый умный.
Отправил еще несколько предложений.
«В ответ тишина...», разумеется.
Несколько лет назад, общаясь с поддержкой, обратил их внимание, что выдача стала не релевантной. Для меня во всяком случае.
Мне пришлось уйти на Гуугл-поиск, потому что Гуугл 1-3-й ссылкой всегда выдавал мне то, что надо, а у Яндекса часто приходилось искать на 2-3-й странице выдачи… и не всегда с положительным результатом.
Написал Яндексу. С примерами. Объяснил, что так ищут многие…
300 писем за 4 года…
Но кто я такой? Ну автор какой-то, веб-мастер. А Яндекс — это же Яндекс — он умнее всех…
Еще в 2012 году я предположил, что доля Яндекса в поисковом сегменте будет падать. И она упала.
Яндекс обвиняет в этом кого угодно, кроме себя.
Но именно в 2012 году Яндекс решил, что первопубликация — это не главное. И начал менять алгоритмы выдачи.
Однако… именно из-за того, что Яндексу стало наплевать на пользователей, а с ним и на вебмастеров и авторов, создающих контент, он уже который год теряет посетителей. Примерно по 5% поискового трафика Рунета в год. А значит теряет доходы от продажи рекламы.
Если Яндексу наплевать на людей, то людям тоже становится не интересно пользоваться Яндексом.
Может, конечно, менеджеры и рапортуют, что продали в этом году на n-миллионов больше… Но в реальности — потеря доли = упущенная прибыль.
Итого. Яндекс обманывает вебмастеров и авторов, декларируя одно, а на деле делая совершенно противоположное.
Яндекс анонсирует свои АГС и пр., но копипастеры прекрасно это обходят и смеются над Яндексом.
Яндекс размахивает дубиной и крушит оригинальные сайты, расчищая дорогу ворам-копипастерам.
И… в результате, по «закону бумеранга» — Яндекс получает снижение доли на рынке, снижение возможных доходов, упускает свою прибыль… и продолжает исправно платить зарплату людям, которые великолепно раздувают щеки, но ничего не делают для улучшения работы поисковика.
Ладно. Яндекс не первый монстр, которого переживут авторские сайты. Такими темпами как сейчас, лет через 5 Яндекс превратится в маленькую конторку или вообще исчезнет с рынка. Подождем.
Придет иной поисковик, который уважает тех, кто создает контент и заберет оставшиеся проценты рынка из рук Яндекса, который вовсе и не пытается эти проценты удержать.
asdoc
22.08.2017 23:14+10Да, кстати… Для любого профессионала только «написать» хорошую аналитическую статью — 2 часа работы как минимум. Не говоря уже о том, что ее нужно предварительно обдумать. А перед этим еще и образование по теме получить. Например, как минимум, несколько лет в институте. А еще книжки полистать, чтоб ошибка не закралась, чтоб уточнить и память свою перепроверить.
А копипаст — это минут 10, полагаю, если с кофе и перекуром.
Но, конечно, сайт с копипастом гораздо ценнее для Яндекса, чем сайт с оригинальной первопубликацией.
volanddd
22.08.2017 23:17+2А сайт можно увидеть?
asdoc
22.08.2017 23:24+3Можно.
Пишите в личные сообщения, чтобы это не выглядело рекламой и не противоречило правилам habrahabr.BarakAdama Автор
22.08.2017 23:52+2И мне, пожалуйста, покажите.
asdoc
23.08.2017 00:50+3Написал Вам личное сообщение. Если не получите — напишите мне — продублирую.

defaultvoice
23.08.2017 16:21Укажите ссылку на него в своём профиле, пожалуйста (так вроде бы можно).
asdoc
23.08.2017 16:33У меня не один сайт, а много.
Если Вам интересен данный сайт с конкретными примерами — напишите в личку. Я отвечаю всем.
asdoc
23.08.2017 11:39+2Вот еще что важно.
Психология автора и то, что публично озвучивает Яндекс — интересные сайты для людей.
Автор это понимает так — написать интересный текст.
Но его интересный текст Яндекс показывает на сайте-копипастере.
Зачем тогда писать?
Тогда нужно изучать СЕО и соревноваться с оптимизаторами?
Или все-таки писать тексты?
Или размещать статьи с вечными ссылками, ибо за это платят?
Или все-таки делать интересный сайт с хорошими текстами?
Одна из частей моего эксперимента последнего года — написал около сотни хороших текстов (некоторые опубликованы и оплачены офф-лайн журналами).
Тексты по 5000-10000 знаков.
Работы (чистого времени) около 300 часов.
Результат — нулевой.
Или отрицательный, если учесть, что выдача в Яндексе за этот год уменьшилась еще вдвое.
Т.е. смысла создавать хороший контент нет никакого.
Infanty
23.08.2017 12:24+5Яндекс провёл IPO с этого момента главные показатели — это доходность компании, а не доля на рынке, хороший поиск и т.п. К тому моменту как помрёт поиск уже будут и уже есть Яндеск.Такси и Яндекс.Маркет которые так же можно выделить в отдельные компании провести снова IPO. А умрёт поиск — так это проблема акционеров, а не качества поиска. Yahoo когда-то тоже была крупной поисковой компанией, у которой сейчас уже нет поисковой технологии…
Т.е. это нормально для яндекса выдавать в топе сайты на которых он зарабатывает на рекламе или которые у него покупают контекст — они же провели IPO. На совете директоров обычно разбирают показатели прибыльности компании за год, а не сколько ворованных статей в выдаче — у нас нет закона по которому бы поисковик за это наказывался бы.asdoc
23.08.2017 12:43Вы полностью подтвердили мои предположения.
Вопрос в том, когда, наконец, акционеры поймут, что Яндекс их так банально собирается… подвести.Infanty
23.08.2017 12:50+1Если выручка компании будет расти — то никогда. Просто перепрофилируют бизнес как Yahoo которой принадлежит большой пакет акций Alibaba Group. Т.е. сегодня пекли пирожки, а завтра будем делать кирпичи — да покупатели и поставщики могут быть не довольны, но бизнес же приносит прибыль. Ну а если потонет — то бывает как с Myspace, не свезло )).
BarakAdama Автор
23.08.2017 12:59+1Интересная теория, но в реальности не так. Кроме общей прибыльности еще важно, чтобы пользователи искали в Яндексе, а не у конкурентов. Иначе они просто рекламу не увидят. И здесь без качества выдачи уже никак.
asdoc
23.08.2017 13:17+1Вы правы.
Теоретически, в идеале, если делать по умному.
И я об этом в техподдержку (и не только) писал много раз на протяжении последних 5-ти (!) лет.
А вот практически оказывается прав Infanty, ибо именно так как он пишет и происходит в реальности. А жаль.
Но это, конечно, в компетенции Яндекса и акционеров.
А пользователи просто выбирают иной магазин (сервис, поисковик).
Но мне было бы приятнее, если бы Яндекс искал так же хорошо, как и Гуугл.
Если качество будет хромать в поиске, то и в остальных сервисах корпорации оно начнет хромать тоже.
Это что в биологии, что в экономике — закон :)BarakAdama Автор
23.08.2017 13:24А что такое реальность? Частные примеры могут быть совершенно разными. Бывают страшные. Бывают наоборот примеры превосходства над всеми остальными. Когда речь идет о миллионах запросов, миллионах сайтов, миллионах пользователей, то тут точно по частным случаям нельзя делать общие выводы. Но это не отменяет, конечно же, необходимости каждый плохой случай разбирать.
asdoc
23.08.2017 13:45Тимур. Я же не спорю с Вашим постулатом, что «Кроме общей прибыльности еще важно, чтобы пользователи искали в Яндексе, а не у конкурентов. Иначе они просто рекламу не увидят. И здесь без качества выдачи уже никак.»
Я как раз «за». Двумя руками.
Проблема в том, что этот Ваш постулат никак не реализуется Яндексом.
(Простите, что Вам приходится «отдуваться» здесь за 2999 (если не ошибаюсь) остальных сотрудников компании :) )
Может я несколько эмоционален…
Возможно меня извинит 5 лет безуспешной переписки с Яндексом.
Ваш ответ «важно, чтобы пользователи искали в Яндексе,… И здесь без качества выдачи уже никак» вселяет некоторую осторожную надежду.
asdoc
23.08.2017 13:56+1Еще немножко дополню, почему важно первоисточник и определять и выдавать на первом месте.
Сейчас очень модно говорить «где пруф?» и требовать ссылку, собственно, на первоисточник.
А с Яндексом его найти невозможно.
И такой человек банально уходит из Яндекс-поиска.
Cubicmeter
23.08.2017 10:53+3Да, не только ваши оригиналы Яндекс полностью заменил копиями :)))
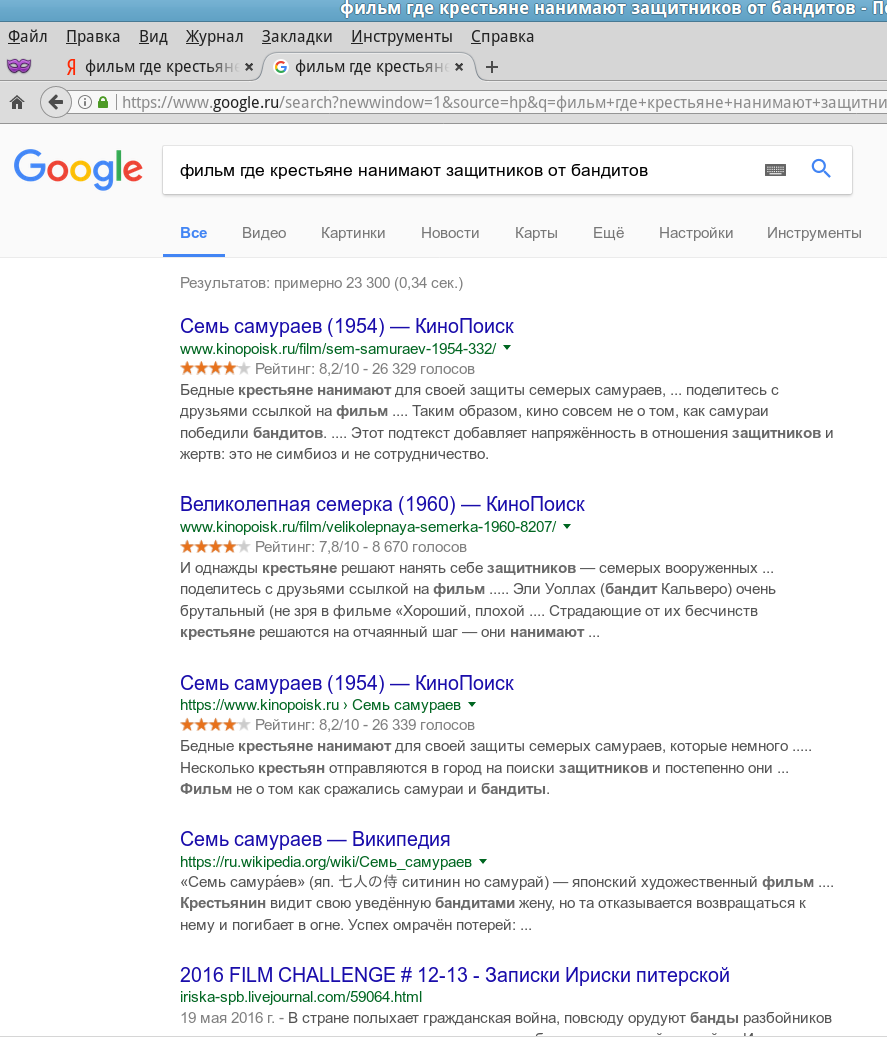
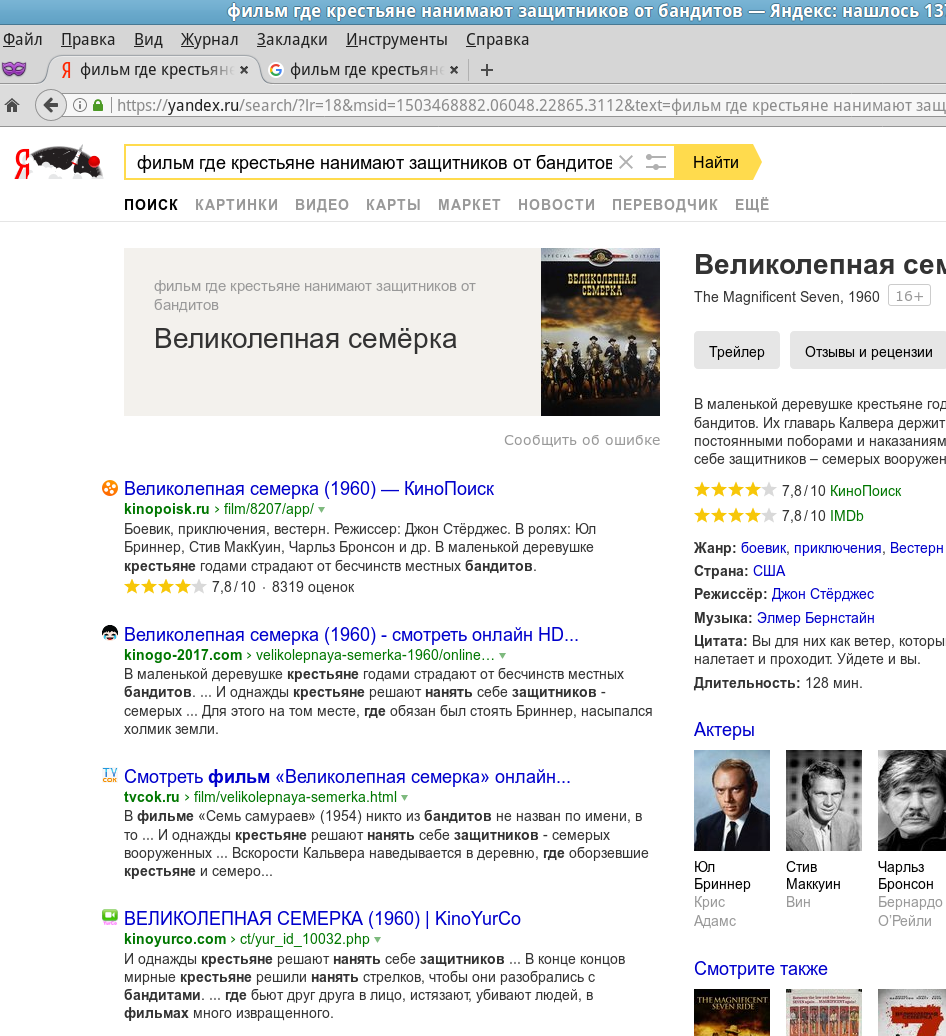
BarakAdama Автор
23.08.2017 10:54Кстати, здесь логику понять можно. Думаю, большинство пользователей искали именно этот фильм, а не японский оригинал.
asdoc
23.08.2017 12:02+4Я бы предпочел ответ Гуугла. Он позволил найти не только «этот фильм», но и исходник.
Т.е. ответ Гуугла содержит для меня в данном случае «бонус».

mngr
23.08.2017 15:22Да нет же, прямо из скриншота видно, что оригинал более известен — на Кинопоиске у него в три раза больше голосов, чем у римейка.
Q001
23.08.2017 15:28Несколько лет назад я заметил значительное снижение заходов на мой сайт из Яндекса. С Гууглом при этом все было в порядке.
У меня ровно обратная ситуация.
Сайт интернет-магазина, существует уже лет 10, накрутками через копирайтеров не пользуется, статей на сайте нет, только товары, SEO-ссылки не покупает.
Весной 2017 мы приняли решение что больше воооообще нам не нужен Гугль. Там даже на 3-ю страницу хрен пробьешься. Хотя мы и выполняли все рекомендации Гугля, работали над сайтом постоянно.
Основной трафик идет с Яндекса. Стабильно первая страница. Как правило 2-5 место в поисковой выдаче.
А где-то года 2 назад с Гугля шло больше.
А еще лет 5 назад с Гугля и Яндекса шло одинаково.
При том что суммарная посещаемость стабильная. Наблюдается незначительный рост с годами.
unknownUsername
24.08.2017 09:20Вы все наивны, как дети. Поиск яндекса — это устоявшаяся экосистема почти-монополиста, прикрываемого ФАС и Сбербанком. С одной стороны там сео и смм-щики, вбухивающие огромные деньги в контекстную рекламу, с другой стороны — все эти же товарищи, генерящие и выводящие в топ тонны дорвеев, сайтов с копипастой и прочего говна. Если бы поиск яндекса стал бы релевантным, как у гугла, то яндекс лишился бы вкусных доходов с лохов.
BarakAdama Автор
24.08.2017 09:21Странная теория, которая не учитывает отток пользователей при падении качества.
unknownUsername
24.08.2017 09:29Я потому и написал про почти-монополиста, что в силу определенных причин (все понимают каких именно) большого оттока пользователей не будет. А если сейчас еще подпишут пару-тройку очередных патриотичных законов и контр-санкций. Ребята, ваш менеджмент тащит вас на дно.
BarakAdama Автор
24.08.2017 09:35+2Каких? Какие именно причины мешают пользователю установить Chrome или купить Android и использовать дефолтный поиск не от Яндекса? Или сознательно перейти на конкурента. Что его остановит?
jetexe
24.08.2017 14:16что каждое третье приложение в сети поставить дефолтом поиск от Яндекса. Не каждый ниндзя сможет снять все галочки, а уж среднестатистический юзер и подавно
BarakAdama Автор
24.08.2017 15:46Вы преувеличиваете. Во-первых, это разработчики бесплатных приложений выбирают монетизироваться с помощью Яндекса и сами определяют способ предложения. Но мы накладываем ограничения. Запрещаем ставить тайно или прятать галочки.
Во-вторых, мы в этом не уникальны и даже не мы это придумали. И ниже примеры.
Примеры



jetexe
24.08.2017 16:12«а если все пойдут прыгать с крыши?»
Это я ещё за года простил «Яндекс.Бар» (черт знает может и мейлру прощу когда-нибудь перед смертью).
kmg4e
24.08.2017 16:09что каждое третье приложение в сети поставить дефолтом поиск от Яндекса.
У Гугля возможностей договориться с хозяевами приложений побольше будет.
Признайтесь, вы просто не любите все разработки российского происхождения.
;)jetexe
24.08.2017 16:22может и будут, однако установщики яндекс браузера встречаются значительно чаще (а яндекс.бар вообще как вирус был)
А обвинять меня в ненависти к российским разработкам, по меньшей мере глупоBarakAdama Автор
24.08.2017 16:43Яндекс.Бара не существует уже 5-6 лет.
Т.е. дело не в формате? Только в количестве?
Am0ralist
24.08.2017 17:03однако установщики яндекс браузера встречаются значительно чаще
В русскоязычном сегменте. Что логично.
jetexe
24.08.2017 17:24Яндекс.Бара не существует уже 5-6 лет.
Поэтому и пишу «был»
В русскоязычном сегменте. Что логично.
Не логично, гугл в русскоязычном сегменте тоже присутствует.
Т.е. дело не в формате? Только в количестве?
Формат мне тоже не нравится. Такой метод распространения — почти мошенничество (да на гугл это тоже распространяется)BarakAdama Автор
24.08.2017 17:30Зайду с другой стороны. Это мы требуем наличия галочек. И если мы уйдем, то место займут те, которые галочек не требуют. Станет ли от этого лучше или хуже пользователям? И если условия делать более жесткими, то разработчики бесплатных программ к ним и уйдут.
Как поступить?asdoc
24.08.2017 18:01Сделать хороший поиск. И все радостно будут его ставить :)
BarakAdama Автор
24.08.2017 18:15Мало сделать хороший продукт. Нужно обеспечить его распространение. Большинство пользователей используют тот поиск, который им уже поставили (через ОС, браузер или расширение – неважно). И довольны им.
asdoc
24.08.2017 20:10«Довольны» Яндексом те, кто Гуугл не попробовал использовать. На сегодняшний день.
А вот лет 10 назад Яндекс искал в Рунете лучше всех. Это факт.
Сейчас факт, что ищет плохо. Очень плохо.
Т.е. нет смысла пытаться найти что-то через Яндекс, ибо Гуугл сделает это корректнее.
Я примерно год (2013) тестировал обе системы по своим личным нуждам. А я ищу каждый день по много раз и по многим темам.
И Гуугл всегда давал более релевантный ответ. Т.е. 1-3 ссылка. Редко 1-10.
В Яндексе же редко на 1-3 странице(!) я находил адекватный моему запросу ответ.
Кстати, не помню, чтобы Гуугл когда-либо пытался предложить мне установить себя. Насколько помню, мне везде нужно было принудительно переключаться на него.
Что касается «большинства»… ну, большинство считало родимые пятна признаком ведьмачества, большинство радовалось сожжению очередной ведьмы, большинство считало, что Земля плоская и что Солнце вращается вокруг нее. А большинство пигмеев не имеет компьютеров вовсе. А большинство опытных пользователей не используют Яндекс-поиск. Есть и много других примеров про «большинство»…
Например, говорят, что сотрудники Яндекса тоже предпочитают использовать Гуугл-поиск.
Все это пляски с бубном, как и «поведение пользователя».
Если сайт пользователю не показывать, то и поведения не будет. А если сайта в выдаче нет, то и показа нет и поведения нет.
А если на сайте нет Метрики, то Яндекс не знает о поведении.
И так до бесконечности.
Зачем было ломать то, что построил Сегалович, непонятно.BarakAdama Автор
24.08.2017 20:38Вы пытаетесь свой личный опыт выдать за факт, применимый ко всем. И это ошибка.
asdoc
24.08.2017 21:41Про причины, почему лично я сменил поисковик? Так я пишу, что «лично я».
Про «большинство» — это не личный опыт. Это исторические факты.
Про «поведение пользователя» — правила математики.
Про то, что раньше Яндекс корректно ставил Источник выше копипаста — это факт. Так было в 2010 и 2011 году.
Падение доли Яндекса в поисковом сегменте Рунета — тоже факт. (Может, конечно, эти данные не верны, но они публиковались чуть ли не в РБК или Вестях. И Яндекс их не опровергал).
Что Яндекс плохо ищет? Так уже в этой ветке примеров нерелевантного поиска столь много, что пора прислушаться к пользователям, а не молиться на Матрикснет.
Так где ошибка? :)BarakAdama Автор
25.08.2017 08:05Все «факты» из исходного комментария – не факты :)
asdoc
25.08.2017 11:37Например этот?
«10 назад Яндекс искал в Рунете лучше всех. Это факт.»
:)
И тогда искал хуже?
Или «не факт» — это когда критика, а «факт», когда хвалят?BarakAdama Автор
25.08.2017 12:02Даже сотня примеров не показательна, когда речь идет о миллионах запросов. На них всегда можно найти сотню контрпримеров.
asdoc
25.08.2017 15:48Это прекрасная отговорка, Тимур. Я от работников Яндекса ее постоянно слышу.
Но для устранения ошибки эта отговорка не работает.
И отговорками релевантность не повышается.
В отличии от внимательного анализа и критичного отношения к своим возможным ошибкам.
Яндекс никто не обвиняет в ошибках.
А вот категорическое нежелание Яндекса замечать ошибки и реагировать на критику исправлением ошибки ему уважения не прибавляет.
И происходит потеря клиентов.BarakAdama Автор
25.08.2017 15:55Вы отвечаете на то, что я не говорил. Ошибки нужно анализировать и исправлять. Но общую картинку по ним не увидеть. Какой бы пример подобрать. Например, планета Земля. Если где-то горит лес и все вокруг окутано дымом, это не значит, что вся планета в огне :)
Am0ralist
25.08.2017 16:12Господи, да у вас кнопочка «точно так как в запросе» не работает.
А вы тут ложными аналогиями отмахиваться пытаетесь.
asdoc
25.08.2017 17:44Ок, Тимур. Тогда несколько простых вопросов.
Яндекс считает нормальным, то что в выдаче копипаст, а не источник?
То, что копипаст в выдаче выше первопубликации?
То, что эта ситуация не исправлена за 5 лет активной переписки с «Платоном»?
То, что в выдаче вместо разнообразной информации по теме несколько десятков копипастов, а статей, адекватных запросу просто нет? (Примеры выше и в личном сообщении.)
То, что в лекции Яндекса «Как писать хорошие тексты» одной из первых фраз идет «как написать хороший копиррайт»? (Т.е. как намусорить, ибо копиррайт это еще больший мусор, чем копипаст, поскольку просто содержит ошибки.)
Когда вместо копипастов в выдаче будут первопубликации?
asdoc
27.08.2017 15:39Тимур. Вы правы. Я не специалист по поиску. Я специалист по хорошим сайтам, по хорошим текстам. С 20-ти летним стажем.
Как сделать хороший поиск — виднее Яндексу.
Почему он не делает хороший поиск — мне непонятно.
Я предлагал Платону, а теперь уже и Вам несколько вариантов, как очевидно можно исправить ошибку, о которой здесь говорил не только я. Ошибку, которая противоречит правилам Яндекса и нарушает законы.
И Вы и Платон на это отмалчиваетесь.
Я предложил простой и понятный механизм для того, чтобы оригинал был в выдаче выше копипаста. Но молчание… Этот механизм Вам не нужен…
Я предложил Вам использовать мой сайт для тренировки Вашего алгоритма, чтобы не гадать, что откуда, насколько важно, интересно, полезно, для спецов, для неспецов, авторский, компиляторский, авторская ссылка, СЕО ссылка и т.д., а точно знать и настроить алгоритм тонко и качественно. Имея «инсайд», «правильный ответ» от меня.
И в ответ опять молчание.
Вывод. Хороший поиск Яндексу не нужен. А нужно что-то другое…
kmg4e
24.08.2017 20:58В Яндексе же редко на 1-3 странице(!) я находил адекватный моему запросу ответ.
Гугль раньше внедрил персональный поиск?asdoc
24.08.2017 21:47Может быть. Но тогда там сплошные гении, ибо я сам не знаю, что мне потребуется найти завтра и из какой области. Из физики, строительства, экономики, медицины, косметологии, арта, педагогики или философии. Или товара, причем на четырех языках и в нескольких странах :)
Но! Я хочу, чтобы Яндекс искал так же. Мне, как пользователю, выгодно, чтобы было две сильных системы. Это же элементарно.
sumanai
24.08.2017 21:05Кстати, не помню, чтобы Гуугл когда-либо пытался предложить мне установить себя.
Он предлагает зарегистрироваться и скачать хром. В этом плане отличий от Яндекса нет, впрочем как и от любой другой поисковой системы.asdoc
24.08.2017 21:43А я не качаю :)
Вам верю, но такого предложения не помню.
У меня, разумеется, стоят все броузеры, поскольку нужно тестировать сайты. Но для «личного использования» у меня Мозила :)
encyclopedist
25.08.2017 14:19Гугл очень агрессивно предлагал установить себя, а именно хром. Одно время на каждом сайте гугла при каждом посещении появлялась плашка с предложением срочно установить хром. Они успокоились, только когда получили почти монополистическое положение на рынку браузеров.
jetexe
24.08.2017 18:02Как поступить?
Попросите чтобы галочки по умолчанию не были нажаты.
И если мы уйдем, то место займут те, которые галочек не требуют
А легкие наркотики случаем вы не продаёте? а то ведь придут те которые будут тяжелыми торговать…
asdoc
24.08.2017 17:58Тимур. Эта теория очень похожа на правду. К сожалению.
А отток пользователей есть. Но по каким-то причинам он Яндекс не беспокоит.
(Т.е. люди уходят с Яндекс-поиска в другие системы. Это факт. Просто до последнего времени Яндекс получал приток новых клиентов, благодаря своему броузеру и прочему. Благодаря маркетингу. Но не качеству.)
Мне хотелось бы, чтобы Яндекс выдавал качество сравнимое с Гууглом. Но увы. Качество Яндекс-поиска настолько плохое, что мне пришлось прекратить им пользоваться.kmg4e
24.08.2017 18:25Возможно, в вашей области так.
В моей — часто и Гугль лажает.
Потому я их сочетаю в поиске.asdoc
24.08.2017 19:54Поверьте… у меня настолько много областей интересов в «поиске», что проще попробовать предположить, какой нет.
Ведь что бы принять решение — уйти или остаться достаточно десяток раз не найти нужный ответ быстро у поисковика А и тот же десяток раз найти у поисковика В… И вот уже везде по умолчанию переустановлен поисковик В.
А темы и области, поверьте, ну очень разные.kmg4e
24.08.2017 20:59Ведь что бы принять решение — уйти или остаться достаточно десяток раз не найти нужный ответ быстро у поисковика А и тот же десяток раз найти у поисковика В… И вот уже везде по умолчанию переустановлен поисковик В.
Когда в интернете есть 50 альтернативных поисков — да.
Когда их по сути по пальцам одной руки можно пересчитать — ваш вариант ухода не годится.asdoc
24.08.2017 21:49Мне такой способ сгодился. Потребности вернуться не ощущаю.
В остальном Вы правы.
SeTM
22.08.2017 23:53+1Критиковать это конечно хорошо, но
биллиasdoc, где факты, примеры?
Про исчезновение тоже интересно, учитывая, что в том месяце Яндекс был топ1 поиск в России.asdoc
23.08.2017 02:06+4Факты и примеры много раз отправлял в техподдержку Яндекса.
Вы из Яндекса? Могу здесь написать Вам номер тикета(ов). Это не ссылки. Это можно.
Что касается исчезновения, то 6 лет назад доля Яндекса в русскоязычном поиске была более 80%. Сейчас чуть более 50%. Это называется катастрофической потерей рынка.
Причина — нерелевантная выдача.
(Могу по памяти немного ошибиться в цифрах, но тенденция именно такая. Примерно по 5% потери каждый год.)inoyakaigor
23.08.2017 16:05+3Причина — нерелевантная выдача
Причина (основная) — гуглохром, который за эти годы занял первое место среди браузеров.
Правда, это не отменяет дерьмовости поиска Яндекса.
postfigs
22.08.2017 23:53+7Вот кстати, да! Обратил внимание уже давно. По телефону помогая кому-нибудь, что-то сделать на компьютере:
— Пиши в поиске "текст запроса".
— Открывай первую ссылку.
— Тыкай теперь туда-то.
— Эээ… ммм, у меня нет этого!
— Как так нет? А! Возле строки с запросом там такое жёлтенькое?
— Ага!
— Ну пиши тогда в поиске goo...
Hardcoin
23.08.2017 01:21-8Яндекс — не система учёта авторских прав. Если текст одинаковый, то с точки зрения пользователя нет большой разницы, с какого сайта его смотреть. Это только для автора текста важно.
asdoc
23.08.2017 02:13+11Это не так. Совсем не так. Первоисточник всегда лучше, чем нечто «второго сорта».
Если Вы немножко поразмыслите, то поймете, что первоисточник важен очень многим, начиная от журналистов, заканчивая обычным пользователем, который даже не постит ничего, а только «для себя» читает. Например, если я нашел статью на авторском сайте, то я могу автору задать вопрос. А если на сайте копипастера, то не только не могу, а могу напороться на неграмотный ответ.
Плюс Вы просто не в курсе публичных правил Яндекса.
Яндекс пишет на своей странице «Некачественные сайты»: «Мы стараемся не индексировать или не ранжировать высоко: Сайты, копирующие или переписывающие информацию с других ресурсов и не создающие оригинального контента.»
Яндекс пишет там же: «Сайты, которые содержат неоригинальный, вторичный… контент… Исключение из поиска страниц сайта, понижение в результатах поиска, аннулирование тИЦ»
И еще там же: «Создавайте сайты с оригинальным контентом или сервисом.»asdoc
23.08.2017 02:22+7Это я Вам говорю как человек, которому постоянно пишут читатели. Вот уже скоро как 20 лет пишут. Когда находят статью на моем сайте, а не у копипастера, где не только ссылки, где и фамилии часто нет.
Т.е. это совершенно обычные люди. Ваши, например, соседи. А может быть и родственники.
И Яндекс, выдавая копипаст, вместо моей первопубликации, этим людям приносит вред, ибо они ко мне обратиться не могут. А если ищут не через Яндекс, то находят мой текст не у воров-копипастеров, а на моем сайте и спокойно что-то могут спросить, если им нужно.asdoc
23.08.2017 02:35+5И вот еще…
По поводу…
«Если текст одинаковый, то с точки зрения пользователя нет большой разницы, с какого сайта его смотреть.»
Есть два сайта. А и В. С одинаковым текстом. На А больше рекламы, дольше загрузка (в разы), текст статьи перекрывается попапом и разбит в середине рекламным блоком.
На В — быстрая загрузка, начало текста чуть выше экрана монитора.
Какой сайт лучше «с точки зрения пользователя»? Где лучше прочитать «одинаковый текст»?
С точки зрения Яндекса — сайт А.
Это как раз вор-копипастер сделал сайт А через 7 лет, после того, как я опубликовал текст, используемый в сравнении на своем сайте (который быстрее и чище, который В).
Hardcoin
23.08.2017 13:40Про комментарии согласен. Если текст подразумевает вопросы, то найти автора очень полезно. Однако это не вопрос "воровства" текста (термин крайне неудачный, не думали выбрать более точный?), это вопрос права авторства. Присвоение авторства может повлечь наказание по УК РФ. Тем не менее, Яндекс не судебный орган. Если плохо работает — теряет долю рынка, вполне закономерно.
asdoc
24.08.2017 18:06Это вопрос поисковой выдачи. Источник выше копипаста. Простое правило. В 2009-2011 оно в Яндекс-выдаче работало исправно. И делало копипаст фактически бессмысленным. Но Яндекс отключил эту функцию. Зачем? «Когда-нибудь узнаем.»
fromgate
23.08.2017 22:27А вы пользуетесь сервисом от Яндекса «Оригинальные тексты»?
Он вроде направлен на то, чтобы избегать подобных ситуаций (правда, без гарантий).asdoc
23.08.2017 22:30+1Да. Пользуюсь.
Последние несколько сотен текстов специально до загрузки прописывал в «Оригинальных текстах».
Однако, значительная часть сайта была создана не только до появления «Оригинальных текстов», но и до появления Яндекса.

vladds
23.08.2017 03:12+5Дело не только в авторских правах, а в пользе для читателя.
Пример 1. Автор продолжает публикации по теме или корректирует старые (актуализирует). Тексты вроде бы те же самые, что и у копипастеров, но читатель получит больше пользы именно от авторского сайта.
Пример 2, более конкретный. На прежней работе публиковал тексты в корпоративном блоге. Особо удачные копировал себе кто попало, впрочем, мне не жалко. В копии текст тот же, что и в оригинале, но убирались внутренние ссылки, раскрывающие тему, а возможности обратной связи с автором не было. То есть, меньше пользы для читателя.
Пример 3. Наш авторский книжный магазин. В данный момент Яндекс не показывает нужные страницы по запросу «Все книги такого-то автора». Где-то в десятке висит «Литрес», где те же книги стоят 400 руб. вместо 150 и появляются на 3 месяца позже. Контент у «Литреса» — тот же, что на авторском сайте: заголовки, анонсы, обложки, отзывы.
Ссылка на сайт авторского магазина у Яндекса присутствует в топ-10, но почему-то на страницу с анонсом романа, который ещё не вышел, а не на «все книги...»
При этом Google показывает в топ-5 то, что нужно. И даёт ссылку на самую выгодную покупку: все книги напрямую от автора пакетом со скидкой.
С точки зрения пользователя, ищущего «все книги», очень большая разница: купить на авторском сайте все книги пакетом или ПО ТОЙ ЖЕ ЦЕНЕ взять одну книгу на «Литресе», накормив всех посредников… Контент тот же самый, но на авторском сайте пользы от него больше.asdoc
23.08.2017 08:13+4Спасибо за хороший пример.
Вы совершенно правы.
И, например, в 2011 году Яндекс четко выдавал сначала первопубликацию, а потом сайты с копиями. Что вполне себе «зеркало Рунета», ибо сначала текст публикуется, а потом копируется.
Особое спасибо за пример с магазином.
Я думал, что товары Яндекс ищет еще нормально, а оказывается и их стал искать криво.
Hardcoin
23.08.2017 13:48Полностью согласен. Если цена разная — разница для посетителя существенная. Если текст бесплатный — разница уже не так очевидна.
Q001
23.08.2017 19:03Яндекс — не система учёта авторских прав. Если текст одинаковый, то с точки зрения пользователя нет большой разницы, с какого сайта его смотреть. Это только для автора текста важно.
Не совсем так.
Напрямую — да, Яндексу все равно. Главное чтобы ищущий нашел хоть какую то копию, не обязательно оригинал. Тут это обидки только авторов.
Косвенно же — политика Яндекса и Гугля определяет то чем будет фактически наполнен интернет.
Появилась целая индустрия вторичных сайтов.
И вторичная индустрия накруток.
А это в свою очередь порождает второй круг проблем с которым уже приходится боротся Яндексу.asdoc
23.08.2017 19:29Совершенно верно. Разница только в том, что Гуугл сознательно с этим борется, а Яндекс способствует умножению подобного мусора.
Brim
23.08.2017 09:45+3Да вопрос скорее в другом. Зачем вообще работать над качеством поиска, если выдача по всем конкурентным запросам давно продажная?
Там уже по 5 рекламных позиций над поиском. Т.е. на первом экране у пользователя результатов выдачи нет вообще.
Только бабло.asdoc
23.08.2017 10:52+1И возникает вопрос — а зачем работать над сайтом, создавать оригинальный интересный контент, если через несколько месяцев он будет сворован и Яндекс в выдаче покажет именно сайт-вора, а не сайт-источник.
Авторам, тем кто создает контент — это вовсе не интересно.
А как видно из комментария vladds (выше), магазинам такой подход Яндекса не интересен тоже.
Т.о. дело не в авторском праве. Дело в неуважении к пользователю со стороны Яндекса.
И к автору, и к читателю.
Результат — люди уходят в другие системы поиска, более релевантные, уважительнее относящиеся к пользователю.
Это как с магазинами. Если в одном нахамили — поменять магазин.
a_pushkin
23.08.2017 17:10первопубликацию от копии
Тут вы прям в точку учитывая, что технологию описанную в статье разрабатывал майкрософт, а не яндекс, который даже ссылку на них поместить не удосужился
habrahabr.ru/company/yandex/blog/336094/#comment_10379076

ZOXEXIVO
22.08.2017 22:59+1Научите для начала вашего бота сканировать нормально SPA без костылей!

Viacheslav01
23.08.2017 17:43+3Вы свои модные СПА на медленном интеренете пробовали? Я бы вообще их запретил индексировать!
ZOXEXIVO
23.08.2017 17:45VueJs пробовали?
Viacheslav01
23.08.2017 20:55+2Я не пробовал, т.к. не занимаюсь веб разработкой. Зато когда под НГ из за аварии я остался с интернетом в 10 килобит, вполне прочувствовал на себе все эти хипстерские технологии. Когда вместо сайта у тебя белый экран ожидающий магии.
kmg4e
24.08.2017 21:53Ну дык зато после первичной загрузки, если разработчики сделали все корректно, должно работать шустро. Перезагрузка каждой страницы без SPA — это не быстро было бы.
sumanai
24.08.2017 22:38Перезагрузка каждой страницы без SPA — это не быстро было бы.
А вы проверяли?
В самой идее SPA нет ничего плохого, но порой её реализация настолько ужасна, что начинаешь её ненавидеть.kmg4e
24.08.2017 23:57Я пометил сразу — «если разработчики не лажанулись».
В теории у сайта на SPA, если вам нужно функционала больше, чем может вам дать одна страница и придется преходить на следующие — гораздо больше шансов быть более быстрым.
Viacheslav01
25.08.2017 00:07Без СПА этим можно пользоваться, с СПА и монструузным размером скриптов, пользоваться на медленном интернете нельзя!
crompton
25.08.2017 08:06Загрузить две-три страницы в 20 кб каждая или загрузить пару десятков скриптов общим весом в несколько мегов для просмотра тех же двух-трех страниц? У меня пару раз была такая же ситуация, как описана выше, только не 10, а аж 64Кбита — и все, ничего не работает, кроме сайтов, где можно было отключить ява-скрипт без ущерба контенту.
vintage
25.08.2017 09:38И SPA можно сделать в 40Кб и MPA можно обвешать скриптами/картинками/видосами/фреймами на мегабайты. Тут всё же дело в кривизне рук разработчика, а не в SPA. Что примечательно, самые тяжёлые страницы как правило — вполне себе статические лендинги, в которые лепят fullhd видео на несколько десятков мегабайт в качестве фона.

JustRamil
23.08.2017 01:50+1Это очень рискованно размещать такую статью на хабре, честь вам и хвала за то что вы не боитесь критики и смело смотрите в лицо аудитории. А по поводу ругающих ваш новый алгоритм поиска, могу сказать что вы еще только его выкатили и странно что кто нибудь вообще может что то говорить о нем. Поживем — увидим.
webtrium
23.08.2017 02:17Здравствуйте! Отличная масштабная презентация, очень порадовали исторические параллели! По поводу Яндекс карт и толокеров, которые проверяют актуальность размещения организаций. Сегодня при поиске ближайших организаций на карте (обучение английскому языку), наткнулся на несколько неактуальных ссылок, либо переадресация на хостера, либо сайт живой, но по адресу ничего не работает (предлагают открыть свою школу по франшизе :)) Если со вторым вариантом сложно автоматизировать проверку, то в первом — как вариант, можно было-бы проверять у кого хостится сайт и сравнивать известный урл организации с корневым урлом хостера. А в остальном хочу пожелать Вам успехов и эффективности в столь не легком деле. Сам принципиально ставлю яндекс браузер и пользуюсь нашим отечественным поисковиком ).
micro-CMS
23.08.2017 09:06-2С декабря сайт клиента падал с ТОП-10 до 45-го места сегодня. В Гугле же всё супер по 300 запросам ТОП-3. Так вот с ИИ "Короле/ёв" я надеюсь на АДЕКВАТ переиндексации ))))))))))
beezy92
23.08.2017 09:06-2Никогда не пользовался Яндексом. Рамблер — да, ДакДакГо — было дело, даже Бингом. Но Яндекс ни за что. Остался плохой осадок, когда он хочется установиться в компьютер любым способом. Напоминает спам.
BarakAdama Автор
23.08.2017 09:08Если будут плохие примеры, то можно смело присылать их мне. Мы достаточно жестко следим за партнерами. К слову, Яндекс не делает ничего такого, чего бы не делали другие поисковые системы.

Ti_Fix
23.08.2017 11:02+2К слову, Яндекс не делает ничего такого, чего бы не делали другие поисковые системы.
Пример: Яндекс постоянно требует «Сделайте Яндекс основным поисковиком и ищите быстрее». При этом он даже не пытается запомнить мой ответ на этот запрос (я залогинен под учетной записью Яндекс) и каждый раз при открытии страницы навязчиво требует «Сделайте Яндекс основным поисковиком и ищите быстрее». Не наблюдаю такого поведения у того же google, например.BarakAdama Автор
23.08.2017 11:23Такое?
Но ответ должен запоминаться на какое-то время, конечно же. Если опишите мне шаги для воспроизведения, то было бы здорово.
alex0nik
23.08.2017 13:52+2Тоже периодически выскакивают всевозможные раздражающие окна «сделайте поиск по умолчанию», «установите яндекс браузер». При этом пользуюсь почтой яндекса много лет, всегда авторизован.
Появилась «Дзен» лента. Сразу в яндекс баре, потом и на главной яндекса. Пользы в ней никакой, одни спамные заголовки статей сомнительного содержания, которые я не читаю. В баре нашел как отключить, а на главной яндекса похоже нельзя.
Еще был сильно раздражающий момент, когда яндекс почта без спроса! сменила интерфейс на новый с едкой для глаз зеленой темой. Вернуться на старый было нельзя, других менее броских тем еще не придумали. Контекстная реклама стала очень броской и огромной (в раза 2 больше и ярче чем темы писем). Знаю, что её можно отключить, но я не против рекламы, а против мешающей рекламы. Периодически перехожу по ней.
Когда вышли новые темы для почты, стало удобнее. Но в другой почтовик чуть не ушел…
Не могу того же написать про гугл, он не раздражает, качество поиска полностью устраивает. Почтой яндекса пока пользуюсь…
Ti_Fix
23.08.2017 16:51Все просто, открываем новую вкладку google chrome (в моем случае), переходим по адресу «yandex.ru» и получаем описанное выше сообщение.
BarakAdama Автор
23.08.2017 18:30И после перезагрузки оно появляется вновь? Даже при закрытии крестиком? Блокировщиков рекламы нет (они иногда мешают запоминать выбор)?
alex0nik
24.08.2017 09:04+2А в вашем понимании если оно появится не после перезагрузки страницы, а скажем каждую неделю, это нормальное поведение для пользователей, которые пользуются яндексом годами и не хотят ни браузер, ни поиска по умолчанию?
Вот такое окно увидел сегодня yadi.sk/i/ua1_Shy_3MH9hB, вчера его не было. И это еще не самое дерзкое, бывают четверть экрана ноутбука занимают в выдаче, насколько помню, в красном цвете.BarakAdama Автор
25.08.2017 09:22А что произошло после нажатия на «Нет»?
alex0nik
25.08.2017 09:48На какое-то время пропадает. Если не нажать «нет», появляется повторно.
Я яндекс поиском редко пользуюсь, раз в месяц может. В основном когда маркет нужен или сравнить региональную выдачу. Но как пользуюсь, вижу эти окна постоянно…
alex0nik
24.08.2017 09:12+1Вот, в «инкогнито» сразу наловил. Это еще не все, которые видел
yadi.sk/i/DFYlG3FJ3MHAJy
yadi.sk/i/Fz-kB9sY3MHAP6
Ti_Fix
25.08.2017 08:56Появляется почти всегда, блокировщик рекламы есть. А каким образом блокировщик рекламы может помешать Яндексу запомнить мой выбор?
Q001
23.08.2017 18:59+2Не наблюдаю такого поведения у того же google, например.
Может, просто потому что Гугль у вас уже сделан страницей по умолчанию?
Меня вот постоянно раздражает эта надпись Гугла:
Заголовок спойлера
sumanai
23.08.2017 20:54Я избавился от неё (и многих других всплывашек) с помощью куки с именем OGP и значением -265001:-270001:-4061155:-5061451:-5061492:-5061821:-873035776:
По умолчанию гугл создаёт её на ограниченный срок, оттого и повторяется это предложение. При помощи дополнения FF под названием Cookie Manager я перезаписываю эту куку на свою со сроком в 2038 год, а то гугл любит её затирать.
Конкретных кук у яндекса я не выяснял, знаю, что иногда механизм запоминания начинает тупить и переставать записывать новые, из-за чего очередное предложение появляется снова и снова. Нужно почистить куки, помогает.
bopoh13
23.08.2017 22:06Не самое сложное, что можно убрать
google.com,google.ru## div[aria-label="promo"]
loveorigami
23.08.2017 11:19Делает. Нерелевантный поиск. Примеров выше достаточно.
BarakAdama Автор
23.08.2017 11:20На любой пример всегда можно найти контрпример.
asdoc
23.08.2017 11:50Отправил Вам конкретный пример за «сегодня». Со ссылками и всем прочим.
BarakAdama Автор
23.08.2017 12:27+1Спасибо.
asdoc
23.08.2017 14:52Небольшое дополнение. Есть понятие «источник». Яндекс это называет «первопубликацией».
Важно, чтобы страница с источником, первопубликацией была на первом месте. Над любыми, самыми оптимизированными и распрекрасными копипастами.
Чтоб было понятно «откуда ноги растут».
Это занимает одну строчку и сильно улучшает релевантность поиска.
Ибо если выбирать, где видеть текст, то конечно в первоисточнике, а не в ксерокопии. :)
Этим, кстати, пример про «Великолепную семерку» очень показателен.
Т.е. Гуугл нашел дополнительный материал, не пытаясь угадать, «что ты имела ввиду».
А Яндекс, пытаясь угадать, выдал много копий, но меньше информации.
alex0nik
23.08.2017 14:25+1С контрпримерами у меня ассоциируется математическое доказательство.
Есть утверждение, «Яндекс научил ИИ понимать смысл документов». Чтобы доказать, что утверждение неверно, достаточно 1 контрпримера!
А вот чтобы доказать, что утверждение верно, нужно доказать что контрпримеров нет. При этом не играет роли, сколько есть миллионов примеров, подтверждающих утверждение.chersanya
23.08.2017 15:31+1Есть утверждение, «Яндекс научил ИИ понимать смысл документов». Чтобы доказать, что утверждение неверно, достаточно 1 контрпримера!
Вы просто неявно подразумеваете "всех документов", хотя по смыслу скорее подходит некоторых или что-то подобное.alex0nik
23.08.2017 15:51То, что в заголовке — маркетинг. Только это по смыслу подходит.
Из написанного и обсуждений в комментариях я понял, что яндекс не понимает смысла, он строит предположения. Причем, если речь о документах, в которых нет вхождений ключевых слов запроса, предположения строятся на основании поведения пользователей. Алгоритмы учатся не «понимать смысл» документов а более точно предполагать, что большинство пользователей хотели получить, набирая запрос.BarakAdama Автор
23.08.2017 15:53Любое «понимание» – это «предположение», подкрепленное чем-то весомым.
alex0nik
23.08.2017 15:55Да, но в контексте обсуждения понимание потребности пользователей, но не смысла документа.
asdoc
23.08.2017 19:03Тимур. Я прислал Вам плохие примеры. Может не очень «смело». Но в ответ от Вас тишина.
Мои примеры для Вас недостаточно «плохи»?
u007
23.08.2017 19:13+2Остался плохой осадок, когда он хочется установиться в компьютер любым способом. Напоминает спам.
При обновлении Аваста если не снять галочку шестым шрифтом внизу, установится гугл. И будет основным и поисковиком, и браузером. А Яндекс в последнее время исправился :)
Q001
23.08.2017 20:33Никогда не пользовался Яндексом. Рамблер — да, ДакДакГо — было дело, даже Бингом.
Это ж насколько нужно ненавидеть Яндекс, чтобы так мучать себя — пользуясь хреново работающими недопоисками.erwins22
23.08.2017 20:39Мое личное мнение
Рамблер в своем пике(200х) был лучшим…
Бинг — после него Яндекс кажется не таким уж и плохим, даже хорошим.
ДакДакГо дословный поиск, иногда самое оно.

coalesce
23.08.2017 09:24+9К сравнению Яндекса и Google
Запрос >
123
23.08.2017 17:50+3А сколько прошло лет от появления языка C#, до того, как Яндекс научился понимать запросы по нему? Я как раз тогда перешел на google.
scrapi
23.08.2017 09:32+2Пока не жу-жу
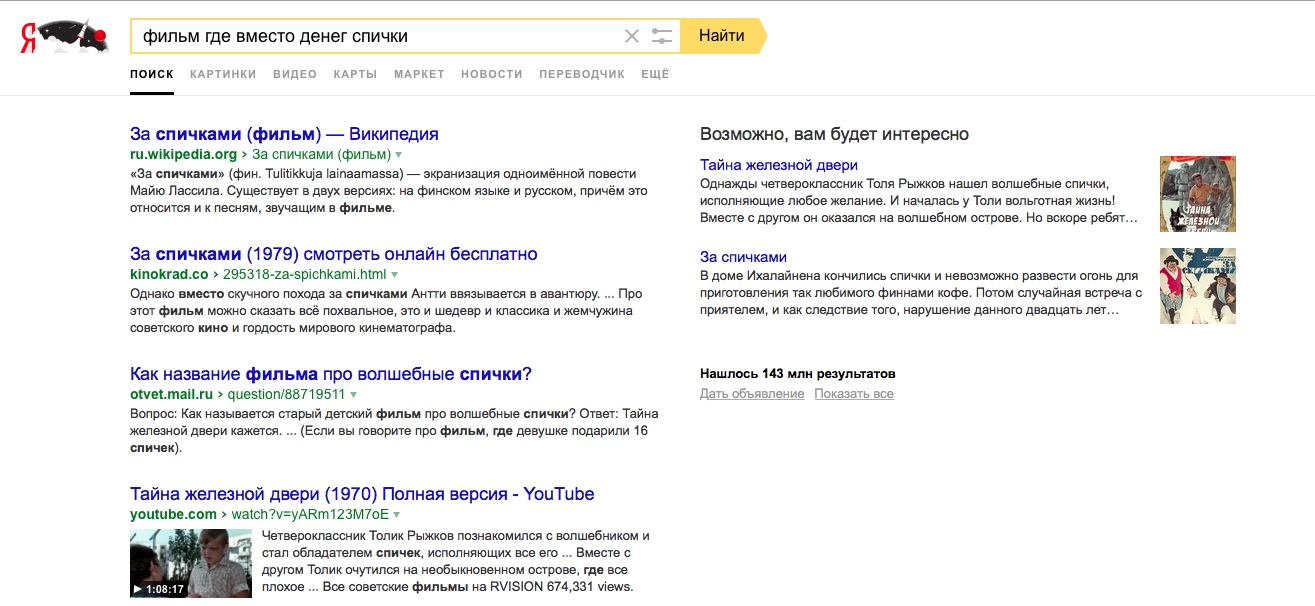
BarakAdama Автор
23.08.2017 09:35+1Спасибо. Примеры для обучения сетей всегда очень полезны.
u007
23.08.2017 19:16А работает ли обучение, если пользователь исправляет/уточняет запрос и ищет снова, и после 10-й попытки находит? Будет ли финальный клик по нужной ссылке привязан к предыдущим девяти запросам?
StrangerInTheKy
23.08.2017 10:04+6Попробовал запрос «лечение рака гомеопатией» в яндексе и гугле. [Тут должен быть жырный-жырный смайлик «троллфейс»]. Ну, гугл 10-й ссылкой дал ссылку на ЖЖ-пост, где в каментах написали, что гомеопатия рак не лечит. Яндекс ничего такого не нашел. Яндексу — двойка, Гуглу — двойка с плюсом ;)
Goodwinnew
23.08.2017 10:07+4да, нерелевантный поиск. да — в первой выдаче сайты копипасты идут подряд, оригинальный сайт может быть на 2-3 странице. т.е. сео-оптимизаторы научились обманывать поисковый алгоритм Яндекса. если новый алгоритм Королёв это дело исправит — будет хорошо.
asdoc
23.08.2017 10:56По какой-то причине Яндекс совершенно не собирается исправлять данную ситуацию.
Его это совсем не беспокоит.
awaik
23.08.2017 11:53+3Причина на самом деле давно предполагается в среде вебмастеров и оптимизаторов. По крайней мере обсуждая с людьми в теме мы пришли к следующим выводам.
Например, вы производитель оборудования для производства бетона в Питере, вам надо его продавать по все России.
Ищут через поиск.
Когда вбивают в яндексе (55% рынка), то люди видят:
— странные сайты ни о чем
— конечно же яндекс маркет с мышками и т.п.
И вы вынуждены подавать рекламу с ценой около 300 рублей за клик на всю России. То есть у вас вымогают деньги под прикрытием несовершенства алгоритма.
В тоже время в Гугле все норм.
Такой маркетинг вполне может иметь место — книжечки, фильмы, инфу для школьников — ищем более менее норм. Все производство и торговлю рушим поиск, пусть дают рекламу.
Тогда и рынок поиска можно удержать и денег побольше снять с тех, кто может платить.
Картинка https://hsto.org/web/afa/e85/bb7/afae85bb7ac4471fb563e235286f1253.jpgasdoc
23.08.2017 12:09+2Разделяю Ваше подозрение. Проблема в том, что такая тактика недальновидна и потеря доли поиска на протяжении пяти лет тому доказательство. А это банально «упущенная выгода». Огромных размеров, если перевести в валюту :)
В 12-13 году окончательно перешел на гуугл-поиск из-за большей релевантности.
А ведь еще в 9-10-м году Гуугл искал в рунете значительно хуже Яндекса.
BarakAdama Автор
23.08.2017 12:34А подскажите, пожалуйста, пример. Ввел [купить бетон] и вижу сайт про продажу бетона и не в рекламе.
awaik
23.08.2017 13:15+7ok, давайте поверю, что у вас про это не знали и потрачу время на подробный разбор для компании с миллиардами доходов и кучей спецов круче меня в разы на зарплате :)
Итак, есть два запроса:
1. [оборудование для производства бетона] — я привел в пример, картинка выдачи выше
2. [купить бетон] — вы привели в пример
В чем разница между этими запросами?
В том, что:
— запрос 2. [купить бетон] — регионален, то есть если я из питера, то хочу купить бетон в питере, чтобы мне его доставили сегодня-завтра. Выдача нужна из питера от производителей бетона.
— а вот запрос 1. [оборудование для производства бетона] — вне регионов. Если я хочу найти оборудование для производства бетона и ищу это в Питере, то мне подойдут не только питерские производители, но и из Москвы, Новосибирска и т.п.
Это большая и дорогая тематика, которая в яндексе, в органическом поиске, не работает в принципе. На выдаче не сайты — производители оборудования или дилеры, а всякие помойки и, конечно, яндекс маркет где нет бетонных заводов.
Получается, что если я что-то произвожу — оборудование, дома, заводы или оказываю промышленные услуги — то я могу попасть в выдачу только платно, через рекламу. При этом в Google все нормально, сайт производитель, по профильному запросу — на первых местах и пользователи находят то, что нужно сразу, не шарясь по рекламным сайтам.
Поэтому падение % ваших клиентов в этой тематике скорее всего ооооочень большое.
Я, как вебмастер, веду около 20 промышленных сайтов, и, с моей точки зрения, у вас это либо намеренная политика вымогания денег, либо вопиющая некомпетентность.asdoc
23.08.2017 19:12+1Я думаю, что Вы правы. И Тимур, вполне возможно, просто не знает. И в этом его личной вины нет. Ибо вполне могут существовать и фильтры, и алгоритмы о которых знают не все сотрудники.
Назовем, условно, эти алгоритмы «финансовым фильтром». Возможно есть и фильтр «благонадежности»…
И тут начинаются мантры и пляски с бубном про юзабилити, поведение пользователей и прочее. Под общей эгидой «мы Вас умнее»…

nanshakov
23.08.2017 11:24+1Видимо потери аудитории для Яндекса не так значительны, а релевантность выдачи для IT по сравнению с гуглом вообще никакая.
asdoc
23.08.2017 11:49В смысле?
5% в год — потеря доли поискового трафика.
Т.е. 5% упущенной выгоды в год.
Это «не так значительно»?
Возможно, но 20 раз по пять и будет 100.
А падение началось с 80.
И на сегодняшний день, если тенденция сохранится, то через 5 лет Яндексом будет пользоваться не более четверти рунета.BarakAdama Автор
23.08.2017 12:42Про 5% это не так, конечно же.
asdoc
23.08.2017 13:36К сожалению, Тимур, это именно так. И тенденция, и проценты. Это было в открытых источниках.
Я могу ошибаться в долях процентов (м.б. в проценте) или в статистике за последний год.
Каждый год доля Яндекса в поисковом сегменте уменьшается примерно на 5%.
Яндекс пока это не замечал, так как был рост количества пользователей.
Т.е. в % терял (или упускал выгоду), а «в человеках» прирост был.
Однако у Гуугла, к примеру, этот прирост «в человеках» был больше.
Результат — Гуугл прирастал большим количеством пользователей Рунета в то время как Яндекс их, в реальности терял. Т.е. до поры до времени Яндекс позволял себе не замечать, что его пользователи переходят в другие поисковые сервисы, ибо был банальный приток новых пользователей, перекрывавший отток.
В этом году, судя по публичным выступлениям Яндекса, наконец эта тенденция стала для него явной.
Чем быстрее это заметят акционеры, тем скорее и моя и Ваша идея «хороший поиск = хорошие доходы» реализуется.
Если не заметят, то как и написал Infanty, Яндекс-поиск перестанет существовать, как и Yahoo.BarakAdama Автор
23.08.2017 15:04Ни по данным ли.ру, ни по данным нашей метрики такого не видно. А больше публичных данных и не существует.
asdoc
23.08.2017 15:46Смотрите, пожалуйста, какая доля поискового трафика у Яндекса была в Рунете в 11-12 году и какая доля в % сейчас.
Если не ошибаюсь, то эта информация была даже в пресс-релизах Яндекса.
sebres
23.08.2017 15:55Может быть BarakAdama имел ввиду это:
Возможно, но 20 раз по пять и будет 100
[КО]Ибо 20 лет по -5% будет "только" лишь -62%.[/КО]
А серьезно если, то я сам Яндексом редко пользуюсь, как раз по вышеозвученной многими причине "не релевантная выдача", а то и вовсе неадекват.
Про айтишный же (а так-же инженерный, научный и т.д.) поиск я вовсе лучше промолчу… Как блин сегодня можно не индексировать специальные символы (ну или худо-бедно хоть какой-нибудь whitelist для парсеров и алгоритмов рассечения, стоп-листов и т.д. должен же быть).
П.С. Про "Королёв" — попробовал тоже, хмм (немного разочарован)… А оно точно AI как обещано ("по смыслу запроса, а не по ключевым словам")? Или оно ещё учится?
И прикрутили бы они возраст что-ли (если человек залогинен), чтобы ЦА значит с поправкой на возраст… (хотя бы парочке нейронов его скормите, а?).asdoc
23.08.2017 16:37Что касается математики, то, конечно, Вы с Тимуром правы. Если терять по 5% ноль не появится никогда, насколько я понимаю.
Но разговор, конечно, не об этом.
MInner
23.08.2017 11:25+3У вас, получается, для каждого нового запроса считается огромное matvec произведение в косинусной близости. Вопрос: используются ли какие-нибудь (какие?) хитрые методы препроцессинга этой матрицы векторов документов для быстрого расчета произведения с новым вектором, вроде Алгоритма Барнса-Хата (~ мультипольный метод) или других методов для аппроксимации A*x при факсированном A быстрее чем за n*d, или какие-нибудь алгоритмы поиска ближайших соседей, чтобы быстро отсекать заведомо ложные варианты? Спасибо.
alsafr
23.08.2017 19:33+2Отличный вопрос, спасибо. Да, нам нужно умножить вектор запроса на векторы сотен тысяч документов. Но это происходит параллельно на довольно большом числе отдельных машин (мы называем их «базовыми поисковыми машинами», или просто «базовыми»). Таким образом, на каждом отдельном «базовом» мы умножаем не сотни тысяч векторов, а на несколько порядков меньше. Препроцессинг же векторов документов тоже не бесплатен. Кроме того, документы, векторы которых нам нужно умножить на вектор запроса, обычно довольно похожи между собой — ведь эти документы не случайны, они нашлись на более ранних стадиях поиска по данному запросу. То есть заведомо плохие варианты уже отсечены ещё до умножения. Учитывая всё это, сильно схитрить не получится)
Novikofff
23.08.2017 12:43+1Нейросеть, обученная неправильно, будет выдавать неправильную информацию. Как вы будете бороться с попытками привязать (накрутить) определенные поисковые запросы конкретным сайтам?
BarakAdama Автор
23.08.2017 12:43У нас большой опыт борьбы с накрутками.
StrangerInTheKy
23.08.2017 13:06+2Ммм…
Вбил в поисковую строку «опровержения гомеопатии». Судя по результатам — пока «неуд».
Infanty
23.08.2017 12:44Т.е. как таковое у вас не понимание смысла документа — а построение гипотез о чём документ. Что как бы разные вещи. «Ленивая кошка из монголии — манул» — согласен. Но запрос: «ленивое пушистое маленькое домашнее как хеллоу-кити» — тоже должен быть Манул, ан нет. В таком варианте и при поиске положительных отзывов можно получить «положительный» отзыв на подобии: «этот напиток божественен как детский шампунь». Т.е. вектора — векторами но смысл слов в предложении они не разворачивают и получаются как я понял — ответы по приведённым примерам будут нерелеванты.
Ещё в 2009 году после Яндекс.Старт-а было предложение как это можно было попробовать сделать (алгоритм понимания смысла текста и запроса), но в тот момент Матрикснет удовлетворял нуждам компании и «домашний» проект не заинтересовал Яндекс. Хотя очень приятно побеседовали с ребятами из отдела поиска. Прочитал заголовок — думал Вы реализовали дополнительный интересный алгоритм (похожий на тот, что мы презентовали в 2009 году) в дополнение к нейронным сетям. Ан нет…volanddd
23.08.2017 12:52Здесь можно углубиться в понятие «смысл».
Яндекс использует для этого вектор в 300 значений, как я понял.
Получаем 300-мерное «плоское» пространство смыслов.
Мне кажется, оно может перекрыть существенную часть вариаций точного запроса и немного аллегорий.
Но, конечно, «смысл», формирующийся в нашем мозге — на порядки сложней, он включает много ассоциативных связей и цепочек и покрыть его полностью — необходим уже полноценный AI, который потребует на сегодня всей вычислительной мощности планеты (плюс\минус пару порядков)

Vaes
24.08.2017 18:03Я ничего не понял… «Матрикснет» получается не на основе нейронной сети? То есть «Палех», «Королёв» и все остальные алгоритмы на основе нейронных сетей это что-то типа дополнения к «Матрикснету»?
BarakAdama Автор
24.08.2017 18:11+1Матрикснет – это метод машинного обучения на основе метода градиентного бустинга. Он работает с факторами. Нейросети используются для получения некоторых из них.
hohlyander
23.08.2017 14:07+2У меня вот вопрос по коммерческим запросам. Я живу в Сыктывкаре, и здесь есть единственная клиника, занимающаяся лечением храпа. И у нее есть сайт, с собственным контентом.
Так вот, по запросу «лечение храпа» без приставки «сыктывкар» или «в сыктывкаре» этот сайт невозможно найти, он аж на 3 странице выдачи. Это же нелогично? Поисковик предлагает мне кучу статей и сайты разных клиник в других городах, но клинику в моем городе не показывает. Хотя клиника есть в яндекс.справочнике (и мой город определяется как Сыктывкар). И вот на этом примере такая же проблема у многих местных грузоперевозчиков, магазинов автозапчастей и т.п. — они не могут выбиться вперед среди жирных федеральных сайтов, даже если эти сайты в выдаче не полезны и вообще не в тему. Вот определение запроса по смыслу это очень круто, но если бы еще поиск отдавал предпочтение тому решению проблемы, которое ближе всего для меня, жителя Сыктывкара, тогда поиск был бы полезнее, я думаю.hohlyander
23.08.2017 14:41+2и опять же, сравнил с гуглом — он при таком же запросе «лечение храпа» выдал мне в первых позициях именно этот сайт, местной клиники. А дальше уже все остальное. Вот здесь логично работает.
Daniil1979
23.08.2017 14:58Вы лучше расскажите, почему у гугла нет претензий к числу поисковых запросов в сутки с одного ip, а у Вас есть, если это число больше 1 в сутки. И реклама вашего браузера достала.
BarakAdama Автор
23.08.2017 15:06+2Вы правда утверждаете, что мы не даем задавать больше 1 запроса в сутки с 1 ip?
Daniil1979
23.08.2017 15:59-1Когда я отправляю один запрос, а через пару минут пишу второй, то мне предлагают подтвердить, что я не робот. Соответственно, это выглядит как 1 запрос в сутки с 1 ip.
Так что Вы пестуйте и дальше свою паранойю, а я перейду к google.com.sebres
23.08.2017 16:07+1Справедливости ради у гугла тоже нередко вылазит (но я за корпоративным прокси, т.ч. вероятно поэтому)…
Выглядит так (просто поставь галочку), но иногда и твердоломная alnum-капча, где раз пять подбираешь пока разберешь...
Tiberiumk
24.08.2017 16:00Тоже относится к рекапче:
У меня месяца три назад рекапча ВСЕГДА начала спрашивать полную проверку (выбрать картинки и т.д), и с тех пор я не могу от этого избавиться.
Не зависит от моего браузера/ос/гугл аккаунта, просто постоянно требуется полное подтверждение.

maxdedepol
24.08.2017 17:07Не пользуюсь Яндексом, да и Google тоже редко. Но иногда требуется именно Google и последние полгода-год мне стало им очень проблематично пользоваться, не смотря на то, что я там залогинен и регулярно пользуюсь почтой (туда он пускает без проблем), в поиске Google постоянно подсовывает мне свою каптчу (просто поставить галочку никогда не выходит, всегда требует картинки разгадать). Два раза за это время я вообще не смог попасть на Google со своего IP (может я нетерпеливый и надо было больше 20-30 раз проходить картинки, не знаю) и приходилось использовать proxy, через него никакой каптчи, все ок.
kmg4e
24.08.2017 17:47А чем пользуетесь?
maxdedepol
24.08.2017 18:08Основной Qwant, для специализованных сразу иду на wikipedia/quora/stackexchange/github/youtube/pinterest.
erwins22
25.08.2017 18:53Прикольно. Qwant из 10 запросов правильный ответ оказался в 10 случаях на первых 3 позициях.
У гугла 9
У яндекса 7
dema
23.08.2017 15:04+1Офигеть! Я давно хотел узнать что за дерево растёт рядом, после прочтения о запросе «ленивой кошки из монголии» попробовал «дерево с боль» и выдало "… шими листьями и длинными стручками" и это было именно то дерево! :)
kryvichh
23.08.2017 15:14+5Поиск по «ленивая кошка из монголии» в Гугле дает ссылку на страницу Яндекса с поиском по фразе «ленивая кошка из монголии». До чего дошел прогресс! )
BarakAdama Автор
23.08.2017 15:22+8И это очень смешно)

harbr6762
23.08.2017 15:15Я не понимаю вот чего: вы пишете про «запрос, для которого мы точно знаем лучший ответ», но как можно точно это утверждать? Конечно, можно решить, что последний линк, по которому перешёл пользователя и является лучшим, но ведь это не всегда так. Пользователь мог не найти нужного ответа на свой и плюнуть. А мог открыть нужный линк в середине, а остальные посмотреть просто для очистки совести чтобы окончательно убедиться, что это не лучший или вообще не подходящий ему вариант. Можете объяснить?
BarakAdama Автор
23.08.2017 15:16Мы видим, что данный результат популярен у пользователей. Из чего делается вывод, что с высокой вероятностью этот результат отвечает на их запрос.
asdoc
23.08.2017 15:50Напоминает Средневековье. Там тоже были довольно четкие критерии для определения ведьм. И «данный результат» был очень «популярен у пользователей. Из чего делается вывод, что с высокой вероятностью этот результат отвечает на их запрос.»
И ведь точно — отвечает :(
derotckay
23.08.2017 15:16В основе узнавания о чем идет речь (особенное в контексте или ситуации) у человека лежат смысловые графемы предметов, понятий и явлений.
То есть услышав слово — «крокодил» человеческий мозг ищет смысловую графему, которая имеет эту кличку (кличка — это первый атрибут или окружение любой смысловой графемы). Затем он начинает перебирать визуальные образы, связанные с этой смысловой графемой. В «чистом виде» смысловую графему человек не видит, а видит её в одном из нарядов (визуальных образов), которые связаны с ней, то есть составляют её гардероб. Интуитивно это, почти сразу, стало понятно и разработчикам поисковых систем, которые уже давно включили в поисковую выдачу и возможность посмотреть соответствующие поисковому запросу картинки. И даже более того отсортировать их по типу. В текстовой выдаче никакой сортировки по типу еще до сих пор нет. Текстовые описания тоже относятся к гардеробу смысловой графемы, но эти наряды созданы уже не Природой (Богом), а человеком, и потому не так «красивы», а главное пользоваться ими (то есть понимать и узнавать смысловую графему в этих нарядах) намного труднее. Именно по этой причине для маленьких детей выпускают книжки с картинками, а для не очень умных взрослых — комиксы. Но текстовый гардероб смысловой графемы очень важен для организации её связей с другими смысловыми графемами.
Кроме названия и визуального и текстового гардеробов вокруг смысловой графемы у человека в процессе учебы и познания мира формируются еще несколько уровней описывающих её, например — действие. Крокодил — плывет, крокодил — идет, крокодил — нападает на добычу и т. д. Всего таких уровней обнаружено 7, хотя теоретически осмыслено и обосновано пока всего 5. Вместе вся эта информация о смысловой графеме есть её «виртуальный иероглиф». В отличии от «письменного иероглифа» «виртуальный иероглиф» не имеет единого начертания. Он сильно различается и у разных людей и в разных источниках информации, в данном случае о крокодиле. Едиными являются только смысловая графема и её кличка (название). Похожими часть нарядов из первого и второго гардеробов и уровни её описания.
Составить «виртуальный иероглиф» используя информацию взятую из любого источника: страница, весь сайт, весь Интернет — задача достаточно тривиальная, особенно если ограничиться первыми тремя уровнями описания смысловой графемы. Количественное и качественное сравнение «виртуальных иероглифов» тоже вполне выполнимая задача, хотя и достаточно трудоемкая. Но главное, что оба этих действия и составление виртуальных иероглифов по материалам размещенным на разных сайтах и сравнение этих иероглифов выполняется заранее, а не в момент обработки поискового запроса пользователя.
Пример использования на практике смысловой графемы: крокодил собран из кубиков ЛЕГО
И кстати в выдаче Яндекса (картинки) все крокодилы, в выдаче «другого» 21 не крокодилы, а 9 даже не из крокодиловой кожи...?
a_pushkin
23.08.2017 15:16+1Я где то год назад, сделал такую же точно модель на python + keras + Theano, пишется она в 200 строчек кода, ну не суть. Почему автор статьи не указал, что данная работа полностью основана на работе сотрудников майкросовт, а конкретно вот этой статье arxiv.org/pdf/1502.06922v3.pdf (доступ к статье из России заблокирован юзайте сами знаете что), как то не по божески получается. «Порадовало» пафосное название модели, уж в чем в чем, а в маркетинге Яндекс силен.
webtrium
23.08.2017 15:56+3Еще пример запроса для обучения: «фильм о поиске детьми своего отца путешественника на корабле»


kryvichh
23.08.2017 15:56Мне нравится в поиске Яндекса то, что по Ctrl — Стрелка вверх можно мгновенно перейти в строку поиска, и сделать новый запрос. В Гугле это не работает. Или может я не знаю горячей клавиши?
alex0nik
23.08.2017 16:10Home чем не угодила?
kryvichh
23.08.2017 16:12Не активирует строку поиска, просто крутит вверх.
alex0nik
23.08.2017 16:17Погуглив, нашел только для гугловского браузера:
Перейти к адресной строке Ctrl + l / Alt + d / F6
Выполнить поиск из любой области страницы Ctrl + k / Ctrl + ekryvichh
23.08.2017 16:47Да, есть такое. Но это запускает страницу с поиском заново. А если делал какие-то настройки в поиске, или чуть поисковую фразу подкрутить…
xLGSx
23.08.2017 16:17+1Запустили новый алгоритм, ничего толком не поменялось, поисковый спам остался на месте.
Объясняю красивый пример. Так случилось, что последние несколько лет я занимаюсь строительством, это не моя специальность и частенько приходится отправляться в интернет за ответами, даже для решения простых задач.
При вводе поисковых запросов по любому вопросу, будь то «технология заливки фундамента» или «сварка алюминия», почти 100% выдачи занимают веб страницы составленные под копирку — оглавление 4-7 пунктов, копипаста картинок, одно-два видео с ютуба и рерайт соседних статей из выдачи. Там точно не будет ни слова про то как правильно что-то сделать, выжимок из ГОСТов и нормативов или личного опыта, что привело к тому, что последнее время, вместо поиска в яндексе приходится либо искать ответы на ютубе, где уровень контента значительно лучше, либо в книгах соответствующей тематики, что очень огорчает, т.к. требует значительных затрат времени.
Техподдержка говорит что всё в порядке, выдача релевантна запросу, но выдача хлам, планируете это исправить?kryvichh
23.08.2017 16:51+3Ненавижу такие сайты. Не помешает кнопка «Убрать и никогда в жизни больше не показывать этот сайт и похожие на него».
dmitry_ch
23.08.2017 22:43Да, притом и в Яндексе, и в Гугле. Хотя бы просто «никогда не показывать мне в выдаче документы с этого сайта». Заодно сайты, получившие много живых кликом на «не показывать мне», можно было бы опускать в выдаче.
P.S. И еще бы галочку «никогда не сватать мне сервисы яндекса», а то я даже и не знаю, почему меня в сотый раз спрашивают, хочу ли я установить его в роли стартовой страницы, и не хочу ли я Я.Браузер" — будто бы после 99 ответов еще не понятно.
u007
23.08.2017 23:02У гугла был вроде эксперимент с кнопками (+1) в выдаче. Убрали почему-то.
kryvichh
24.08.2017 10:35Кнопку "+1" можно закликать роботами. У Яндекса есть кнопочка «Пожаловаться» рядом с каждой ссылкой, но это опять же не то. Жалобу будут рассматривать (сразу или кода наберется много), примут-не примут. А кнопка «Не показывать этот сайт» немедленно убирала бы сайт из любой последующей выдачи.
Возможно, такой персонализированный поисковый функционал стоит денег. Интересно, много ли было бы подписчиков платного поискового сервиса на основе Яндекса или Гугла, глубоко персонализированного, со множеством настроек? Я думаю, если бы они сделали цену $10 в год, они смогли бы набрать достаточно подписчиков и окупить затраты.
awaik
23.08.2017 16:52оффтоп :)
Тоже строю домик — вот тут www.allbeton.ru/wiki поиск по текстам строительных книг и тут же можно их скачать (почитать).
Меня удивляет почему нет подобного от гигантов индустрии, на том сайте это сделали энтузиасты, поиск по тексту распознанных книг djvu.
Вот бы у яндекса (или Google) был еще переключатель — ищу инженерную (программисткую, строительную, радиоэлектронную, ...) проф. инфу и они бы выдавали и искали по книгам и серьезным статьям только.
Это был бы прорыв мне кажется.
Ребята из Яндекса — дарю идею :)
Ndochp
23.08.2017 20:06Я добавляю "+форум -цена" и уже из сообщений форумов ухожу на релевантные сайты.
u007
23.08.2017 18:46применить нейросети на стадии поиска L0, чтобы семантические вектора помогали нам находить документы, близкие по смыслу к запросу, но вовсе не содержащие слов запроса
В гугле часто встречался с таким. Откапывает какие-то поросшие мхом архивы, где указанное слово не встречается вовсе (это вообще могут быть исходники на Си с минимумом комментариев) но неожиданно это оказывается именно тем, что я хотел. Причём в выдаче порой всего-то 10-20 документов, и можно проучиться, что подобный бред до меня никто не искал.volanddd
23.08.2017 22:06А можно пример-другой? Любопытно
u007
23.08.2017 22:53+1Да я бы рад с примерами, но где теперь найдёшь эту хистори… Последний раз я искал какой-нибудь хелп по тонкой настройке intel qsv энкодера в ffmpeg. Но там как тема новая, максимум что нашлось — пара форумов с вопросами без ответов. А потом вдруг откуда-то выползла отличнейшая ссылка на исходники одного из модулей, который отвечает за поддержку этого qsv, и первый же абзац — раздел констант, а имена констант соответствуют ключам командной строки, вот они все на блюдечке :)
До этого гуглил по текстам ошибок из логов jitsi — софтина для видеоконференций. В основном в выдаче были только дампы чужих логов, причём очень немного, ибо изделие глючное и непопулярное. Но помимо дампов также нашлась ссылка на архивы почтовой рассылки (mailing lists), где искомого текста в явном виде не было, но проблему обсуждали.
В следующий раз буду записывать)

nalgeon
23.08.2017 22:04+2BarakAdama, и сама фича классная, и рассказ отличный! Вы большие молодцы, спасибо, что так интересно и понятно пишете о сложных штуках.
Forxxx
23.08.2017 22:24Еще 1 интересный эффект яндекса

volanddd
23.08.2017 22:28А в чем эффект? Кто не в курсе?
kryvichh
24.08.2017 10:43Так ведь работает орфографический движок, который лучше знает что на самом деле хотел пользователь. )
В данном случае фамилия «Бозник» не внесена в базу орфографического анализатора. Я описывал эту проблему выше и давал примеры. Помогает знак "!" перед словом, но документы с иными формами этого слова поиск искать не будет.
Les-Tin
23.08.2017 22:25Я понимаю что оффтоп, но иначе я узнать не смогу. Ув. Яндекс, когда вы добавите возможность перенести омнибокс на мобильной версии вверх? Я понимаю, что некоторым это удобно, но это эгоизм чистой воды, некоторым люлям не удобно. О чём вы думали перенося омнибокс вниз не добавив возможность выбора, пожалуйста, ответьте мне. Я очень сильно надеюсь, что мой комментарий не будет удалён или проигнорирован, я хочу знать ответ. Планируете-ли вы дать выбор юзерам или вы поступите как эпл и сделаете по своему?
BarakAdama Автор
24.08.2017 08:54В браузере? Так он же там всегда был. С 2013 года.
u007
24.08.2017 12:26Да нет, в браузере он таки снизу.
Наверное в расчёте на тех, кто пишет одной рукой.
BarakAdama Автор
24.08.2017 12:43Да, я как раз и говорил, что он там всегда снизу был. Просто отзыв выглядел так, будто мы это недавно изменили.
Если отзывов будет много, то об этом можно будет подумать.
maxwolf
23.08.2017 22:25Правильно ли я понимаю, что вот этот тезис: «И если вектора (а значит, смыслы запросов) оказываются достаточно близки, то и результаты поиска должны быть схожи» на самом деле означает, что яндекс ищет не то, что мне нужно, а то, что он считает, что мне нужно? Как это выключить?
BarakAdama Автор
23.08.2017 22:26А какая разница между этими двумя вариантами?
Am0ralist
24.08.2017 01:36Разница в том, что яндекс показывает пользователю не то, что тому нужно. Очевидно же

porutchik
23.08.2017 22:28+1То есть мне не стоит покупать кроватку без бортиков? :-)
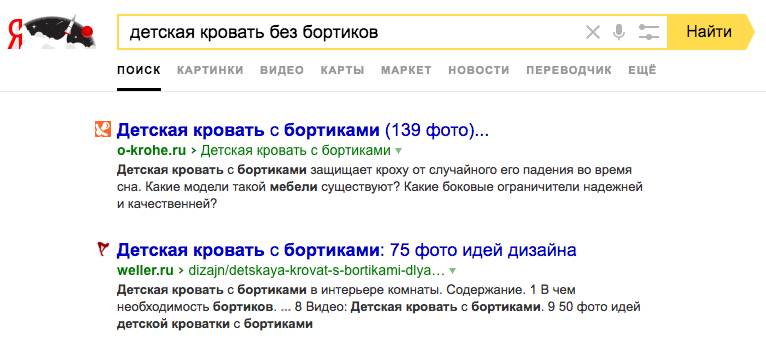
kmg4e
24.08.2017 08:10Здесь проблема скорее в том, что в случае детской кроватки без бортиков вообще не принято писать про отсутствие бортиков.
Это как с взрослыми кроватями.
Возможно, вам следовалось бы искать «кровать для подростка».
dmitry_ch
23.08.2017 22:36Может и не в тему, но стоит хоть раз что-то в яндексе поискать, как потом контекстную рекламу на эту тему смотреть — не пересмотреть. Как сказать Директу «горшочек, не вари!», не подскажете?
BarakAdama Автор
23.08.2017 22:41-1Там же крестик обычно есть с выбором причин.
dmitry_ch
23.08.2017 22:47+1И как долго мне щелкать на крестиках, пока перестает показываться? По моему опыту — очень не сразу крестик приносит эффект.
Более того, если на странице три рекламных блока, а я только что искать дрова для ноутбука Asus, то в этих блоках почти наверняка будет — угадаем! — правильно, реклама Asus (нечто «суперполезное» для меня, правда?)! Так вот мало что реклама нерелевантна (если я ищу дрова к буку, то у меня не радость, а проблема с моим буком Asus, если задуматься), так еще и непонятно, что делать-то: мне, как, в каждом блоке нажать крестик и выразить мысль, что мне не интересно, или одного хватить должно?u007
23.08.2017 23:12+1Просто попробуйте поискать пару раз что-то типа «британская короткошёрстная котёнок питомник купить москва» Cat Block на коленке. От рекламы это конечно не избавит, но выдача будет приятней >^_^<
maxdedepol
24.08.2017 17:44Яндекс.директ почти всё время мне предлагает «покупка/аренда частных самолетов/вертолетов/яхт». Я не пользуюсь яндексом кроме диска и маркета и то редко, никогда не интересовался ничем из вышеперечисленных, я даже нажимал крестик несколько раз, они пропадали на некоторое время, а потом вновь «самолеты/вертолеты/яхты». Мне, конечно, льстит, что яндекс почему то решил, что у меня столько денег, но с релевантностью явно проблемы, а крестик не помогает от силы никак.
Ugrum
25.08.2017 15:02В любой непонятной ситуации предлагай «самолёты/вертолёты/яхты». Авось и выстрелит.
mosinnik
24.08.2017 08:26+1Немного оффтоп, но про «улучшения» Яндекса.
Уже несколько писем за месяц-два ушло в ТП яндекса по поводу всяких всплывающих предложений, которые постоянно появляются вновь и вновь. А учитывая, что и на работе и дома на разных браузерах везде используется одна учетка, то это дико выбешивает (что и послужило причиной обращений в ТП). Собственно никаких изменений не происходит, только отписки «передано кому-то там»
Когда уже появится в настройках галочка «Отказаться от всех предложений», которая будет привязываться к почте и навсегда решит эту проблему?
P.S. из-за вашего [Яндекса] бездействия все это добро выпилилось с помощью блокеров, и о чудо, на главной странице исчезает полоса прокрутки, которая появляется из-за предложения установить Яндекс браузер на свои устройства (но зачем оно мне на ПК показывается?), бесполезный «Дзен», всякие надписи над футерами и предложения к поиску (я что первый раз зашел на страницу? у меня яндекс почта наверно уже 10 лет, зачем мне мне все это видеть при каждом рефреше страницы?)
P.S.S. а уж обновление погоды — это вообще тихий ужас (в ТП тоже написано письмо с пожеланиями) информация просто стала невоспринимаемой при беглом осмотре — теперь полностью отсутвует дизайн, который позволяет цепляться глазами за информацию (в основном это цвет в зависимости от температуры).
Я понимаю, что это просто бизнесс и перед начальством надо отчитываться о проделанной работе, новым фишкам, но бл@ть доколе? Вы же Яндекс (пока еще с большой буквы)

znsoft
24.08.2017 08:27может я не так задаю вопрос: «как поменять лампочки противотуманок на бампере (не круглые) elgrand atwe50», но нашло только про круглые фары и ни одной от эльгранда. возможно нужно просто открыть филиалы школы по поиску в яндексах.

simpleadmin
24.08.2017 09:24+4Решил давеча глянуть где находится Анаа.
Анаа
BarakAdama Автор
24.08.2017 09:34Странно. У меня после отказа от исправления опечатки нашел как раз Анаа. А вот на карте в справочнике ошибке. Уже зарепортил, спасибо.
simpleadmin
24.08.2017 09:42У меня после отказа от исправления опечатки нашел как раз Анаа.
Попробовал из другого браузера (под другим логином) и другого региона, результаты почти те же:
speller
24.08.2017 12:36Скажите, а волшебный алгоритм, который выкидывает страницы сайта из индекса — это этот же Королёв, или что-то другое? А то на нашем сайте одни и те же страницы то заносятся в индекс, то удаляются. Качели бесконечные.
rampeer
24.08.2017 13:07В чём его особенность, в чём «фишка» подхода? У него есть какая-то новизна, не по сравнению с предыдущей версией, а глобальная? Подобная нейросетевая архитектура, с двумя сетями, одна из которых кодирует запрос, а другая — информацию о документе — давно изучена и используется, например DSSM от Microsoft (Deep Structured Semantic Model). Добавили туда текст? Так тоже делали.
Кеширование векторов — это интересный, но типовой приём (например, ещё часто запихивают вектора документов в какой-нибудь индексатор типа ElasticSearch, чтобы потом быстро дёргать ближайших соседей к вектору — у вас наверняка свой продукт для этого). Серьёзно, вы и вправду раньше считали вектора всех документов заново на каждый чих?
Хитрая многоуровневая фильтрация и индексы? Да, это нужно. Это касается скорее оптимизации, не так ли?BarakAdama Автор
24.08.2017 13:08В посте про «Палех» как раз рассказывали про отличия от DSSM https://habrahabr.ru/company/yandex/blog/314222/

polyform
25.08.2017 08:07Нейронные сети это очень хорошо, конечно. Хочется пожелать успехов Яндексу (да и нам, улучшение поиска это же для нас) на этом поприще. Но уже не один год я ожидаю изменений в более прозаичной области. Если незалогиненным при включенном VPN (что системном, что оперовском) вбивать в адресную строку yandex.ru происходит редирект на yandex.ua. Вводишь yandex.kz попадаешь на yandex.kz, та же история с yandex.com.tr. И только yandex.ru недостижимая цель. Видимо, это непосильная задача даже для исскуственного интеллекта.) Но я не оставляю надежд, на подходе квантовые компьютеры — и, может, при их внедрении, я, набрав в адресной строке yandex.ru, попаду именно на этот домен.) Всем удачи!..
bookandre
27.08.2017 13:32Тем временем SEO-шники Шахов и Севальнев убеждены, что «Королёв» повлияет только на выдачу по низкочастотным запросам. А потому их бизнес в безопасности.


{kind=link}
{kind=link}
erwins22
Добавьте в результаты поиска как в гугле отсутствующие слова под строкой.