

Однажды вечером, перечитывая Джеффри Фридла, я осознал, что даже несмотря на всем доступную документацию, существует множество приемов заточенных под себя. Все люди слишком разные. И приемы, которые очевидны для одних, могут быть неочевидны для других и выглядеть какой-то магией для третьих. Кстати, несколько подобных моментов я уже описывал здесь.
Командная строка для администратора или пользователя — это не только инструмент, которым можно сделать все, но и инструмент, который кастомизируется под себя любимого бесконечно долго. Недавно пробегал перевод на тему удобных приемов в CLI. Но у меня сложилось впечатление, что сам переводчик мало пользовался советами, из-за чего важные нюансы могли быть упущены.
Под катом — дюжина приемов в командной строке — из личного опыта.
Маленькое отступление — в реале я использую множество приемов, в которых могут случайно встретиться имена реальных серверов или юзеров, что может попасть под NDA, поэтому я не мог копи-пастить и специально переписал и максимально упростил все примеры в статье — и если вам покажется, что какой-то прием в данном контексте совершенно бесполезен — возможно это как раз по этой причине. Но в любом случае делитесь вашими идеями в комментариях!
1. Разбиение строки при помощи variable expansions
Часто используют cut или даже awk, чтобы просто получить значение какого-то одного столбца.
Но в простых случаях более чем достаточно просто отрезать у переменной лишнее при помощи #, ##, % и %% (bash variable expansions) — с их помощью можно отрезать ненужное по паттерну. Пример ниже показывает, как из строки «username:homedir:shell» можно получить только третий столбец (shell) при помощи cut или при помощи variable expansions (мы используем маску *: и команду ##, что означает отрезать слева все символы до последнего найденного двоеточия):
$ STRING="username:homedir:shell"
$ echo "$STRING"|cut -d ":" -f 3
shell
$ echo "${STRING##*:}"
shellВторой вариант не запускает еще один процесс (cut), и вообще не использует пайпы, что должно работать гораздо быстрее. А если подобный скрипт выполнить в bash-подсистеме на windows, где пайпы еле шевелятся, разница в скорости будет огромна.
Давайте посмотрим пример на Ubuntu — крутим нашу команду в цикле 1000 раз
$ cat test.sh
#!/usr/bin/env bash
STRING="Name:Date:Shell"
echo "using cut"
time for A in {1..1000}
do
cut -d ":" -f 3 > /dev/null <<<"$STRING"
done
echo "using ##"
time for A in {1..1000}
do
echo "${STRING##*:}" > /dev/null
done
Результат выполнения
Разница — в несколько десятков раз!$ ./test.sh
using cut
real 0m0.950s
user 0m0.012s
sys 0m0.232s
using ##
real 0m0.011s
user 0m0.008s
sys 0m0.004s
Конечно, пример выше — слишком искусственный. В реальной жизни мы будем обрабатывать реальный файл. А в этом случае из него нужно читать. И для cut мы просто перенаправим файлик /etc/passwd. А в случае использования ##, нам придется создать цикл с использованием read. Итак, кто победит в этом варианте?
$ cat test.sh
#!/usr/bin/env bash
echo "using cut"
time for count in {1..1000}
do
cut -d ":" -f 7 </etc/passwd > /dev/null
done
echo "using ##"
time for count in {1..1000}
do
while read
do
echo "${REPLY##*:}" > /dev/null
done </etc/passwd
done
Результат выполнения
$ ./test.sh
$ ./test.sh
using cut
real 0m0.827s
user 0m0.004s
sys 0m0.208s
using ##
real 0m0.613s
user 0m0.436s
sys 0m0.172s
2. Автокомплит в bash с использованием TAB
Пакет bash-completion сейчас идет в поставке практически всех дистрибутивов, включить его можно или в /etc/bash.bashrc или /etc/profile.d/bash_completion.sh, но чаще всего он уже включен из коробки. В общем автокомплит по TAB — это один из тех удобных моментов, с которыми новичок знакомится в первую очередь.
А вот то, что не все активно используют, и на мой взгляд совершенно зря, так это то что автокомплит работает не только с именами файлов, а также с алиасами, именами переменных, а если копнуть в скрипты автокомплита, которые собственно являются тоже шелл скриптами, можно даже дописать автокомплит для вашего скрипта или приложения. Но вернемся к алиасам.
Алиасам не нужно прописывать PATH, не нужно создавать отдельные исполняемый файл — они комфортно могут лежать в .profile или .bashrc.
В *nix обычно используется lowercase для файлов и каталогов, поэтому мне показалось удобным использовать алиасы с использованием uppercase — тогда автокомплит
$ alias TAsteriskLog="tail -f /var/log/asteriks.log"
$ alias TMailLog="tail -f /var/log/mail.log"
$ TA[tab]steriksLog
$ TM[tab]ailLog3. Автокомплит в bash с использованием TAB — 2
Для более сложных случаев, часто пишутся скрипты и кладутся например в $HOME/bin.
Но есть же функции.
Им опять же не нужен PATH, и для них тоже работает автокомплит.
Поместим функцию LastLogin в .profile (не забудьте перегрузить .profile):
function LastLogin {
STRING=$(last | head -n 1 | tr -s " " " ")
USER=$(echo "$STRING"|cut -d " " -f 1)
IP=$(echo "$STRING"|cut -d " " -f 3)
SHELL=$( grep "$USER" /etc/passwd | cut -d ":" -f 7)
echo "User: $USER, IP: $IP, SHELL=$SHELL"
}(На самом деле тут не так важно, что я написал внутри функции, это исключительно наглядный многострочный пример, который было бы не так удобно запихивать в alias)
Затем в консоли:
$ L[tab]astLogin
User: saboteur, IP: 10.0.2.2, SHELL=/bin/bash4. Sensitive data
Если перед командой поставить пробел, она не попадет в bash history, следовательно если в командной строке нужно ввести пароль открытым текстом, лучше такую команду исключить из истории — на примере ниже, echo «hello 2» в истории не появляется:
$ echo "hello"
hello
$ history 2
2011 echo "hello"
2012 history 2
$ echo "my password secretmegakey"
my password secretmegakey
$ history 2
2011 echo "hello"
2012 history 2Заголовок спойлера
Поведение с пробелом контролируется следующей опцией:
export HISTCONTROL=ignoreboth
export HISTCONTROL=ignoreboth
В скриптах, которые например нужно выложить в git или раскладывать их через ansible, можно сделать external bash file который будет лежать только на целевой машине, с правами 600, добавленный в .gitignore и содержать нужные пароли только для конкретного окружения, а в основной скрипт вызываться через source:
secret.sh
PASSWORD=LOVESEXGOD
myapp.sh
. ~/secret.sh
sqlplus -l user/"$PASSWORD"@database:port/sid @mysqfile.sqlНо это также небезопасно — как заметил Tanriol, такой пароль можно будет увидеть в списке процессов, где отображается вся командная строка со всеми аргументами, поэтому лучше, чтобы приложение умело читать пароль из нужного файла самостоятельно.
Например, безопасный ssh не имеет опции, которая позволяет передать ему пароль в командной строке. А небезопасный wget — поддерживает опцию --password, и если на данной машине работают другие пользователи, они могут увидеть в списке процессов все параметры вашего wget, пока он запущен.
И наконец самый правильный вариант — шифровать данные (пароли сертификатов, пароли для доступа к удаленным системам, пароли от SQL) используя openssl и мастер ключ.
openssl поддерживает все необходимые опции, чтобы использовать его для шифрования паролей прямо в скриптах. Пример шифрования и дешифрования:
Файл secret.key хранит только одну строку:
$ echo "secretpassword" > secret.key; chmod 600 secret.keyШифруем нашу строку алгоритмом aes-256-cbc, c использованием случайной соли:
$ echo "string_to_encrypt" | openssl enc -pass file:secret.key -e -aes-256-cbc -a
U2FsdGVkX194R0GmFKCL/krYCugS655yLhf8aQyKNcUnBs30AE5lHN5MXPjjSFMLТакую строку можно смело вставлять в скрипт или в конфигурационный файл какого-либо, который безопасно положить в .git — без secret.key его расшифровать будет сложно.
Перед использованием дешифровать в первоначальный вид можно той же командой, заменив только опцию -e на -d:
$ echo 'U2FsdGVkX194R0GmFKCL/krYCugS655yLhf8aQyKNcUnBs30AE5lHN5MXPjjSFML' | openssl enc -pass file:secret.key -d -aes-256-cbc -a
string_to_encryptТакже можно, чтобы приложение самостоятельно умело расшифровывать данные из конфигов, останется только согласовать, чтобы и ваш скрипт и приложение пользовались тем же secret.key и тем же алгоритмом.
5. Просмотр логов и grep
Часто можно использовать что-то вроде
tail -f application.log | grep -i errorИли даже так
tail -f application.log | grep -i -P "(error|warning|failure)"Но не забывайте про опцию -v, которая выводит наоборот — строки, которые НЕ соответствуют шаблону — это позволяет вывести не только строку с проблемой, но и в случае exception все остальные строки, которые к нему относятся вот таким образом (исключаем все строки, в которых есть info, выводим все остальные):
tail -f application.log | grep -v -i "info"Дополнительные нюансы:
Не забывайте использовать -P, так как по умолчанию grep использует basic regular expression, а не PCRE, и вы можете столкнуться с тем, что просто так группы не работают.
Не забывайте и про другие популярные опции "--line-buffered", "-i".
Если вы знаете регулярные выражения, то при помощи --only-matching, можно значительно улучшить вывод. Но в принципе это редко используется в случае разового использования. Зато очень рекомендую почитать мануал по grep, если вы пишете алиас/функцию/скрипт для многоразового использования.
6. Уменьшение размера лог файлов
В обычном состоянии, если приложение запущено и пишет в лог файл, его нельзя удалять. Поскольку в *nix, открытый файловый дескриптор связан уже не с именем файла, а с iNode. Следовательно о том, что файл удален в каталоге, приложение никак не узнает, и будет писать в ранее открытый дескриптор. Затем, когда приложение остановится и закроет дескриптор, данные удалятся с файловой системы.
Поэтому очистку файла следует делать либо так (очистится весь файл):
> application.logЛибо так (файл будет урезан до указанного размера):
truncate --size=1M application.logНо команда выше именно урежет, что означает, что в файле останутся старые данные, а свежие как раз и будут урезаны.
Поэтому можно делать вот так, сохраняя последние 1000 строк:
echo "$(tail -n 1000 application.log)" > application.logСпасибо Himura за оптимизацию.
P.S. В данном примере мы не рассматриваем самый правильный способ — когда приложение само следит за своим лог-файлом пользуясь, например, log4j, или своим велосипедом или rotatelogs.
7. watch следит за тобой!
Бывает ситуация, когда ждешь какого-то события. Например, пока подключится пользователь (жмешь who несколько десятков раз), или кто-то скопирует по ftp файл (жмешь ls десятки раз).
Можно использовать
watch <команда>По умолчанию, команда будет выполняться каждые 2 секунды с очисткой экрана, пока не нажать Ctrl+C. Частоту выполнения можно изменить опцией при запуске.
Очень полезно, когда работаешь на одном сервере
8. Последовательности в bash
Есть удобная возможность создавать диапазоны значений, например вместо такого:
for srv in 1 2 3; do echo "server${srv}";done
server1
server2
server3использовать вот такое:
for srv in server{1..3}; do echo "$srv";done
server1
server2
server3А еще можно использовать команду seq, чтобы форматировать вывод. Например выравниваем ширину автоматически:
for srv in $(seq -w 1 10); do echo "server${srv}";done
server01
server02
server03
server04
server05
server06
server07
server08
server09
server10А вот еще один пример конструкции с фигурными скобками, которая позволит массово переименовать файлы. Для получения имени файла без расширения используем basename:
for file in *.txt; do name=$(basename "$file" .txt);mv $name{.txt,.lst}; doneА можно еще короче, с использованием %:
for file in *.txt; do mv ${file%.txt}{.txt,.lst}; doneДля переименования файлов лучше использовать утилиту «rename»
Или вот пример для создания структуры каталогов под новый java проект:
mkdir -p project/src/{main,test}/{java,resources}Получим
project/
!--- src/
|--- main/
| |-- java/
| !-- resources/
!--- test/
|-- java/
!-- resources/9. tail, несколько файлов и несколько юзеров
Ранее упоминался multitail, который может следить за несколькими файлами сразу. Но он не поставляется из-под коробки, а права для установки есть не всегда.
Но с этим вполне может справиться и обычный tail:
tail -f /var/logs/*.logКстати, вернемся на минуту к алиасам с «tail -f».
Бывает, что на сервере, где крутится некое приложение, лазят разные тестировщики, разработчики и все смотрят лог приложения через tail -f. Даже на продакшене несколько саппортеров
При перезапуске приложения, остаются висящие «tail -f», которые могут висеть несколько дней или даже месяцев. Это не то, чтобы проблема, но не аккуратненько.
Полезно будет сделать алиас, который получает PID вашего приложения из PID файла, и автоматически завершит tail при завершении процесса:
alias TFapplog='tail -f --pid=$(cat /opt/app/tmp/app.pid) /opt/app/logs/app.log'И добавить этот алиас во все профайлы. Даже если все ушли домой, забыв остановить свой tail, он автоматически завершится при рестарте приложения.
10. создание файла нужного размера
Часто пользуются dd
dd if=/dev/zero of=out.txt bs=1M count=10Но я рекомендую использовать fallocate:
fallocate -l 10M file.txtНа файловых системах, которые поддерживают аллокацию места (xfs, ext4, Btrfs...), данная команда будет выполнена мгновенно, в отличие от dd.
11. xargs
Всего два момента, которые полезны, если мы обрабатываем очень большой список.
Первое — список может просто не влезть в командную строку.
Но мы можем ограничить обработку аргументов через опцию -n:
$ # создаем файл из 5 строк
for string in string{1..5}; do echo $string >> file.lst; done
$ cat file.lst
string1
string2
string3
string4
string5
saboteur@ubuntu:~$ cat file.lst | xargs -n 2
string1 string2
string3 string4
string5Второе — команда может выполняться слишком долго, ибо мы запустили ее выполняться в один поток. А если у нас несколько ядер, то полезно запускать xargs в три потока, каждый будет обрабатывать по 2 аргумента:
cat file | xargs -n 2 -P 3Если мы хотим запустить на все доступные ядра, то можно даже использовать nproc, скрипт автоматически определит количество доступных ядер на текущей машине:
cat file | xargs -n 2 -P $(nproc)12. sleep? while? read!
Вместо sleep или бесконечного цикла while, я пишу read, что позволяет одной командой сделать паузу, которую можно в любой момент прервать:
read -p "Press any key to continue " -n 1Или добавить таймаут, который также можно в любой момент прервать и продолжить выполнение:
read -p "Press any key to continue (autocontinue in 30 seconds) " -t 30 -n 1Можно усложнить конструкцию до полноценной обработки:
REPLY=""
until [ "$REPLY" = "y" ]; do
# executing some command
read "Press 'y' to continue or 'n' to break, any other key to repeat this step" -n 1
if [ "$REPLY" = 'n' ]; then exit 1; fi
done
На этом я прощаюсь, и буду благодарен за участие в опросе.
И конечно — жду разумной критики и новых приемов от вас!
P.S. Update:
1. все переменные заключены в кавычки — так надо!
2. `` заменен на $() — так правильно!
3. исправлено несколько опечаток, и даже парочка ошибок.
Всем, кто со мной спорит — несмотря на мою воинственность, я действительно стараюсь услышать и разобраться =), поэтому огромное спасибо+ следующим комментаторам: khim, Tanriol, Himura, bolk, firegurafiku, а также dangerous3, RPG, ALexhha, IRyston, McAaron
warlock13
1) Статья — супер, но если бы мог, то поставил бы минус за bash-центричность: скрипты с шапкой "#!/bin/bash" (по крайней мере у меня) вызывают омерзение, правда к большому сожалению read с таймаутом в линксовом sh нету (во фряшном есть); и вместо того, чтобы разбираться с автокомплитом в bash, не лучше ли перейти на zsh и разбираться уже там с автокомплитом?.
2) В разделе про dd стоило бы упомянуть вариант создания файла с "дыркой" — не всегда при создании файла нужного размера требуется обязательно аллоцировать реальное место.
saboteur_kiev Автор
К сожалению, я регулярно встречаюсь с ограничением на установку дополнительного софта в продакшене, поэтому не имею возможности везде навязывать шелл, отличный от уже установленных. Кроме того, я собственно и не работал в zsh, поэтому не думаю, что смогу рассказать как правильно в нем оптимизировать автокомплит — я немного акцентировал, что данная статья — личный опыт, а не перевод.
Вы можете написать свою статью, или хотя бы подробный комменнтарий, как это можно сделать в zsh — это будет полезно для всех.
bolk
Проблема в том, что bash не везде установлен.
saboteur_kiev Автор
Добавил в заголовки приемов для bash, что это для bash.
Кстати, а можете подсказать в каких современных Линуксах не встречается баш из-коробки, если не считать ембеддед варианты?
bolk
Ребята рассказывали о каких-то линуксах, где ksh, кажется, не помню точно, но баша нет там. Название не запомнил.
saboteur_kiev Автор
Хм. Ну тогда делаем так:
#!/usr/bin/env kshзапускаем — все работает и в ksh
using cut
real 0m0.70s
user 0m0.02s
sys 0m0.12s
using ##
real 0m0.01s
user 0m0.01s
sys 0m0.00s
bolk
Понятно, что многое будет. Но башизмы потому так и называются, что не обещается, что они будут работать в других шелах.
frantic16
Башизм — это когда в скрипте шебанг #!/bin/sh, а дальше конструкции, работающие только в bash, а не скрипт на баше в явном виде.
bolk
Нет.
broken
Извините, что встрял в разговор со своим оффтопом, но если вы тесты подряд запускали, то второй может быть всегда быстрее из-за того, что первы грузанул все данные в кэш, и во втором уже всегда кэш-хит.
saboteur_kiev Автор
Какой кеш — там же просто обработка одной и той же маленькой строки 1000 раз, грузить просто нечего.
broken
А, ну если там одна маленькая строчка, то ок.
redfs
g4xd
Не совсем. Везде есть sh, но не все что верно для bash верно и для него
bolk
Возможно. Но мало ли какие дистры существуют, не удивлюсь.
saboteur_kiev Автор
Поэтому и пишем
#!/user/bin/env bashnixel
Не знаю, можно ли считать alpine linux эмбеддед, но в нем есть только sh. Сам alpine часто используется в докер-образах.
saboteur_kiev Автор
Не сталкивался, но википедия говорит, что изначально цель alpine linux — максимально легкий, нетребовательный и защищенный дистрибутив, который в основном используется для embedded.
Подозреваю, что когда проект начинался (лет 8-9 назад), докера еще не было, и то, что легковесный дистрибутив кроме embedded хорошо пойдет для контейнеров и виртуалок не подозревали.
urtow
Зачастую приходится работать с чистым sh (4.3 который), когда один и тот же скрипт должен запускаться на любом Linux, FreeBSD и Solaris до кучи.
Но как правило, bash есть на любом linux сервере или его туда можно поставить. Но ключевое тут — все же linux
Ivan_Popov
grayich
Статья не совсем корректно названа, т.к. присутствуют башизмы.
begemoth3663
+1.
мало того — там где классический truncate можно было успешно использовать, вытащили модный fallocate...
saboteur_kiev Автор
Но между truncate и fallocate есть разница — truncate создает sparse файл, fallocate — сразу аллоцирует блоки. По скорости разница невелика, но говорить «классический truncate» — не совсем правильно.
Правильно будет «что требуется в конкретном данном случае».
P.S. Понятно, что и для sparse и для fallocate, это должно поддерживаться файловой системе.
navrotski
хде? ))
saboteur_kiev Автор
Где-то в комментариях в этой статье.
physics
Коммент понравился — юмор программиста! Где-то там… в глубине души )))
bolk
У меня во втором тесте результат такой:
real 0m3.442s
user 0m1.220s
sys 0m1.942s
using
real 0m5.629s
user 0m4.194s
sys 0m1.364s
Результат противоположный, плюс можно выкинуть cat, который вы совершенно зря используете. А вместо echo $STRING | cmd используйте лучше cmd <<<"$STRING".
saboteur_kiev Автор
Да, "<<<" в данном случае выгоднее, но не так наглядно. Но тем не менее у меня все равно результат не отличается:
$ cat test.sh
#!/bin/bash
STRING="Name:Date:Shell"
echo "using cut"
time for A in {1..1000}
do
cut -d ":" -f 3 > /dev/null <<<$STRING
done
echo "using ##"
time for A in {1..1000}
do
echo ${STRING##*:} > /dev/null
done
bolk
«Мак» у меня.
foxb
Первый раз
Второй
CentOS 6
saboteur_kiev Автор
Ладно еще с Мак — он не совсем Линукс.
Но у меня однозначный результат в Ubuntu, FreeBSD, Windows и
[saboteur@tt test]$ uname -a
Linux tt.com.ua 2.6.32-358.14.1.el6.x86_64 #1 SMP Tue Jul 16 23:51:20 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
[saboteur@tt test]$ cat /etc/redhat-release
CentOS release 6.4 (Final)
[saboteur@tt test]$ ./test.sh
using cut
real 0m1.064s
user 0m0.075s
sys 0m0.198s
using ##
real 0m0.030s
user 0m0.022s
sys 0m0.007s
khim
Причём тут Мак вообще?
saboteur_kiev Автор
Посмотрите комментарием выше?
khim
Читаем заголовок статьи:
И? Причём тут Мак? «Вы слышали Карузо?!» – «Нет. Мне Рабинович по телефону напел».?Если вы прочитаете инструкцию для управления современным мерседесом и сядете за руль Форд T — то вас будет ждать масса «приятных» открытий.
Userspace в Mac (как и большинстве проприетарных Unix'ов) — совершенно не радует новизной. Даже python на вышедшей месяц назад macOS High Sierra — двухгодичной давности, а bash — так и вовсе 3.2.57 (притом что bash 4 вышел почти 8 лет назад).
Am0ralist
а вы пробовали ветку комментариев прочитать до того, как встревать с своим ценным комментарием, да еще и минусами автору, который как раз таки разбирался с другим человеком, почему поведение странное?
saboteur_kiev Автор
Так вы посмотрите комментарием выше, а именно habrahabr.ru/post/340544/#comment_10485274?
Зачем мне отвечать не на мои слова?
Dreyk
просто ставить надо все из homebrew
GNU bash, version 4.4.12(1)-release (x86_64-apple-darwin16.3.0)ogost
За первый пункт отдельное спасибо.
emanation
по-больше идей можно почерпнуть из tldp.org/LDP/abs/html/refcards.html
saboteur_kiev Автор
Если все начнут черпать идеи оттуда, на Хабре не будет статей про баш!
evilbot
Пункт 4 не везде работает, надо отдельно настраивать. Надо настраивать переменные окружения
HISTCONTROL и HISTIGNORE. В CentOS Minimal это по умолчанию не сделано.Sirikid
Вот это приемы здорового человека!
firegurafiku
К сожалению, местами ваша статья тоже учит людей плохому, как и многие другие статьи о шелл-программировании.
КДПВ. То, что там написано, не поддаётся никакой критике:
Кто-то так в жизни пишет скрипты? А что если:
*раскрывается в слишком длинную последовательность, которая не поместится в лимит командной строки?Более правильно так:
Разбиение строки. Как быть в случае, когда нужны все поля, или какое-то поле из середины? В этом случае
${##}не поможет, но вполне можно разбить строку в массив средствами Bash:Последовательности. В приведённом простом примере совсем не обязательно использовать
seq, достаточно добавить ведущих нулей в оператор{..}. Не стоит также забывать про кавычки, хотя тут их отсутствие не несёт угрозы.Кавычки!. Не знаю, почему, но вы почти нигде не квотируете строки. Как насчёт файлов с пробелами в имени?
Коварная команда
test. Увидел у вас вот такой фрагмент кода:Что будет, если пользователь введёт '--help' или ещё что-то, начинающееся с дефиса? В баше (по крайней мере, новых версиях) не произойдёт ничего страшного, но в древних шеллах команда test может перепутать операнд с опцией и выдать сообщение об ошибке. Думаю, лучше так:
saboteur_kiev Автор
1. Простите, вы действительно сейчас взяли и раскритиковали вводный скриншот к статье?
Надеюсь, что вы действительно прочитали вводную в статье, а именно вот это:
khim
вы научили людей двум вещам:
1. Пароль лучше класть в отдельный файл
2. При использовании данных из этого файла можно ссылаться на переменную как $PASSWORD — без забот и кавычек
И никакие ссылки на другие статьи не помогут. Раз в примере так написано — значит так и надо делать!
Нет, не нужно. Нужно просто всегда следовать «правилам хорошего тона».
0xd34df00d
К слову о примерах и статьях. Есть линтер для шелл-скриптов. Можно рекомендовать новичкам.
На хаскеле, что самое приятное.firegurafiku
Ну да, взял и раскритиковал. Вы же эту команду не специально в картинку спрятали, чтобы её было сложнее раскритиковать?
Вы хотите сказать, что забесплатно переменные можно не квотировать?
Если от упрощения примеров они становятся более хрупкими и менее корректными — не надо так упрощать. Программировать на шелл-языках сложно — пожалуйста, не внушайте людям, что это легко.
Окей, какого-то одного, но не обязательно же последнего? Давайте вытащим средний элемент: в примере с
cutнужно будет поменять одну цифру, с${##}уже придётся извратиться.Да, с
--helpя недоглядел. Но пользователь всё ещё может ввести просто дефис.Каждый, конечно, волен сам выбирать свою судьбу, но, как мне кажется, лучше уж честный скрипт на Bash (которому бонусом доступны массивы, хеш-таблицы,
$(...)и регулярные выражения) с минимальным использованием внешних утилит, чем "портабельный" скрипт на *sh, который на эту самую портабельность никем никогда не проверялся.Нельзя по-отдельности объяснить составляющие концепции и ожидать, что они сами сольются в монолитное знание. В каждом примере обязательно нужно использовать всевозможные защиты от якобы несущественных проблем, либо говорить "Этот пример работает неправильно в таких-то случаях". В противном случае получается, что вы именно что "учите плохому".
saboteur_kiev Автор
Почему же нельзя не квотировать переменные в примере, типа:
Переменная как-то не так сработает в этом примере?
Давайте еще раз посмотрим на код:
until [ "$REPLY" = «y» ]; do
# executing some command
read «Press 'y' to continue or 'n' to break, any other key to repeat this step» -n 1
if [ "$REPLY" = 'n' ]; then exit 1; fi
done
firegurafiku
Прежде всего, в качестве примера отсутствующего квотирования я приводил совсем другой фрагмент кода. Но и этот не без недостатков:
echoможет иметь параметры, поэтому еслиSTRINGначинается с дефиса — все может пойти не так, как задумывалось;echo "$STRING"у вас любое количество идущих подряд пробелов станет одним пробелом.Можете мне сколько угодно говорить, что это всё глупости и просто не нужно иметь на машине имен пользователей и файловых путей с пробелами, вот только не всегда входные данные приходят в корректном виде. Их надо фильтровать и вообще обращаться с ними трепетно.
Вы уверены, что "
test - = n" на всякой машине (в том числе в FreeBSD, OpenSolaris, QNX) отработает именно так, как у вас? Некоторые вариантыtestвполне могут воспринять дефис как окончание списка флагов и выдать сообщение об ошибке. Я вам не найду конкретную версию системы, где на этот баг можно нарваться, но я не с потолка это взял, а подсмотрел в./configure-скриптах. Что бы ни говорили про Autotools, но её авторы понимали в портируемости кода.Согласен: примеры должны быть просты и доносить основную мысль, но также приучать людей к тому, что такие вещи как квотирование переменных должны "соскальзывать с кончиков пальцев". По-большому счёту, с этих несчастных кавычек и начинается понимание шелл-скриптинга.
saboteur_kiev Автор
Простите, но ОТКУДА в моем примере дефисы? Вы же видите скрипт целиком? В нем в STRING задается с одним конкретным значением, в котором есть все необходимое для демонстрации, как работает конкретная команда.
Ни дефисов ни подряд идущих пробелов там нет. Скрипт рабочий как минимум на всех доступных мне операционкам.
Я понимаю, если в скрипте допущена ошибка, но IMHO вы сейчас придираетесь к несуществующим выдумкам. Я понимаю что такое перфекционизм, но в данном случае он явно излишен.
firegurafiku
Если входные данные подразумеваются неизменными, то просто напишите вместо этого всего скрипта
echo "shell"— зачем же так сложно, как у вас, делать? Или всё-таки, сущность примера состоит в том, что входные данные можно варьировать без потери работоспособности?К тому же, основные претензии были вот к этим двум командам:
Я вижу, что вы отредактировали статью и добавили кавычки.
О чём мы тогда спорим-то?
saboteur_kiev Автор
Я просто боюсь, что если я снова в следующий раз напишу в каком-нибудь примере «press any key to continue», вы набежите, и начнете доказывать, что это неверно, потому что shift не сработает, numlock не сработает, через Alt можно ввести несуществующий символ, клавиша на мышке может сместить фокусировку с консоли, а Power вообще может сломать ОС.
Если хотите, посмотрите пожалуйста мою другую статью — там как раз есть парочка примеров посложнее, мне будет приятно, если вы подскажете упущенные моменты.
Kot_Dymok
Если не ошибаюсь, это только если в настройках значится
xenm
«встретиться имена реальных серверов или юзеров». Какой то странный отмаз для NDA.
saboteur_kiev Автор
Совершенно не странный.
Служба безопасности не лазит по инету и не выискивает конкретный участок кода — это задача нереальная. Зато вот взять ключевые слова, в которые как раз и входят названия серверов, домена, приложений, опций — за что можно зацепиться, и гуглится по популярным ресурсам. Найдут — будут разбираться, и масштаб разборок может оказаться совершенно несопоставимым с реальной угрозой. Просто потому, что в вопросе могут быть замешаны деньги и политика.
Давайте приведу потенциальный пример, как могут развиваться события:
Разработчик работает в аутсорсе. Устраивается в проект, подписывает NDA, по которому обязуется не выкладывать из того, что пишется в проекте. Однажды выкладывает на публичный ресурс кусок текста, с названием внутреннего сервера.
Реальной технической угрозы — никакой.
Но подпадает под NDA? Подпадает.
Служба безопасности компании-заказчика это однажды находит, передает специалистам.
Специалисты смотрят — ну вроде как технически не страшно, передают дело юристам со своим описанием.
Юристы смотрят ага, нарушение NDA, можем вкатить компании-исполнителю штраф в 1-5%, согласно нашему договору.
1% от ОБЩЕГО договора между компаниями — может составлять несколько годовых зарплат менеджера, а то и всего проекта — зависит от размера компаний, поэтому просто так такие случаи бесследно проходить не будут.
Итого — зачем рисковать? =)
Aristarkh
Но ведь можно в кусках кода заменить имена реальных пользователей, например, на такие как vasya, petya, user1, user2, server1, server2. И добавить фразу: «Любое совпадение с именами реальных серверов или юзеров случайны». Разве это будет попадать под NDA?
saboteur_kiev Автор
Мы конечно можем подискутировать, что подпадает под NDA, а что нет.
Но я действительно совершенно не хочу спорить об этом с юристами =)
Поэтому проще переписать с нуля, вдобавок проверить, что пример рабочий, а не требует конкретных имен файлов/серверов/юзеров для выполнения — ведь неприятно, когда копируешь кусок кода из статьи к себе, чтобы проверить — а он просто не выполняется.
dangerous3
В первом пункте ошибка:
$ echo ${STRING##:*}shell
Нужно:
echo ${STRING##*:}saboteur_kiev Автор
Спасибо, это опечатка (в других местах все было указано правильно).
P.S. такое лучше в личку.
Borz
и это не третью "колонку", а всё, что после указанной маски (в вашем примере — двоеточие)
проверьте на таком тексте:
STRING="username:homedir:shell:other:mazer:pazer"arheops
Может я, конечно, фиговый админ(20+ лет опыта), но меня как-то жизнь научила перед массовым удалением и переименованием файлов убедится, что результат будет именно такой.
Потому обычно используются for циклы, сначала с echo префиксом. А башевские встроенные регекспы классная вещь, но иногда срабатывает не совсем так, как ожидает уставший мозг.
Пример про сохранение части лога в переменной(памяти) вообще порадовал.
110d46fcd978c24f306cd7fa2
Вместо последнего примера в (8) рекомендую
man rename:Tanriol
Вероятно, здесь стоит упомянуть, что передача пароля в аргументе командной строки — вообще не очень хорошая идея, поскольку он будет светиться в
/proc/$pid/cmdlinesaboteur_kiev Автор
Это ценное замечание, даже добавлю в статью — спасибо!
RPG
Если не можете выиграть битву, поменяйте поле:
В последнее время cut работает хорошо. Не так давно в GNU coreutils cut работал так, что его обгонял awk.
saboteur_kiev Автор
Да что же я делаю не так?? Под рукой не нашел ни одной машины, на которой у меня cut работал бы быстрее, чем башизмы. Перепробовал CentOS, Ubuntu, RHEL, FreeBSD и Windows (cygwin).
#!/usr/bin/env ksh
# prepare data
for A in {1..1000}; do
STRING+=«Name$RANDOM Date$RANDOM Shell$RANDOM»$'\n'
done
echo «using cut»
time for A in {1..1000}
do
cut -d ":" -f 3 > /dev/null <<<$STRING
done
echo «using ##»
time while read
do
echo ${REPLY##*:}
done <<<"$STRING" > /dev/null
echo «using read»
time while read a b c
do
echo $c
done <<<"$STRING" > /dev/null
RPG
Дело в подготовке данных (вы вызываете cut 1000 раз, а я один раз но для 1000 строк).
saboteur_kiev Автор
Oops, тут я что-то завтыкал =).
Правда я в уме держал реальный пример — чтение из разных конфигов, где я считываю значение переменных, и я видимо подсознательно не смог их все запихнуть в один файл/поток.
RPG
Если позволяет формат конфигов — то не знаю ничего быстрее чем
source config.cfg, всё что было внутри конфига превратится в переменные баша. Такой способ используется повсеместно в initscripts. Все эти ifcfg-eth0 в RHEL по крайней мере — по сути шелл-скрипты.Ещё один способ, который годится для перегона нестандартного формата конфига —
eval "$(sed ... config.ini)". Сед приводит конфиг в башеподобному виду, eval превращает в переменные.Обычно так делают студенты домашку, так как им показали ограниченный набор базовых команд.
VAR1=$(cat file.cfg | grep var | cut -f2 | sed 's/"//')… и так десять раз
saboteur_kiev Автор
К сожалению, конфиги у меня текстовые, но не башевские, а для java приложения. На баше я их «оркеструю» своим велосипедом.
a1111exe
А как же
find? Много бывает полезных применений. Совсем недавно нужно было посчитать количество файлов на уровне каждой директории рекурсивно от текущей:find -type f -printf "%h\n" | sort | uniq -c | sort -npowerman
А не полезней ли запускать
tail -F, чтобы он продолжал следить за логом приложения и после его перезапуска или ротации лога?saboteur_kiev Автор
А это уже зависит от того, что вам нужно =)
У меня, например, проблема бывает в том, что люди просто забывают о своих запущенных под screen процессах, и они там могут месяцами висеть, никому не нужные.
mike_y_k
Радует и сама статья и развернувшаяся полемика…
Таких материалов и побольше — полку прибудет ;)…
k0ldbl00d
Пффф! Вот тоже мнгновенно:
dd if=/dev/zero of=path/to/filename.txt bs=1 count=0 seek=1Gkhim
А теперь попробуйте на ваш «мгновенно аллоцированный» файл напустить mkswap+swapon — и вы увидите, о чём говорит автор.
k0ldbl00d
Автор не конкретизировал для чего ему создавать пустой файл. В моём случае (пустой «образ» для iSCSI-target) этот способ вполне годится.
apotokin
Не всегда так можно делать. Например, вот это не сработает.
mkswap path/to/filename.txt
swapon path/to/filename.txt
dude_sam
Я правильно понял, что read с опцией таймера вернёт exit код больше 0?
saboteur_kiev Автор
почему же? read корректно завершится и в случае ввода от пользователя и в случае завершения таймаута.
iig
У меня такое впечатление, что статью писали 2 человека, и/или второпях. Немного "секретов" bash, немного coreutils, совсем немного openssl. Утверждение про экономию времени очень спорное.
Это не разбиение строки. Это Remove matching prefix pattern (ц) man bash.
создание файла нужного размера — это операция, занимающая много времени? Не уверен, что эта задача насколько востребована, что ее оптимизация сэкономит больше времени, чем потрачено на чтение комментариев.
Урезание логов — готовый антипаттерн, как он относится к экономии времени?
Sensitive data — шифрование с помощью openssl не экономит время. И еще я где-то читал, что плохо организованное шифрование не улучгает, а ухудшает безопасность.
khim
Так что тут уже разница не между «выиграли несколько секунд или проиграли», а между «смогли обойтись без остановки всей системы или нет».
iig
Не приходилось ;)
Если задача ставится именно так: "добавить_руками_прямо_сейчас_своп_на_очень_загруженной_системе_иначе_беда" — это рулетка, либо повезет, либо нет. Система уже скорее мертва, чем жива. Процессу (процессам) не хватило памяти, они начали писать в swap, все в ожидании Input/Output. Если такая ситуация наступила — ваша система плохо сконфигурирована, и все равно очень скоро будете либо добавлять память, либо настраивать (и перезагружать).
saboteur_kiev Автор
А например такая задача:
Для демонстрации работы fdisk в учебном классе, выдавать рутовые права не нужно, ибо чревато.
Но для каждого ученика мы создадим по файлику, размером пару гигабайт, внутри которых они будут играться с разделами.
Задачка простейшая, но зачем ждать несколько минут на каждый созданный гигабайт, если это делается за секунды?
iig
Хм. С такой задачей IRL, наверное, сталкиваются чуть реже чем никогда. В 21 веке, зная про виртуализацию, не выдать каждому студенту по песочнице ?
saboteur_kiev Автор
Песочница песочнице рознь.
1. Даже со всеми заготовленными образами и автоматическим разворачиванием, на 30 студентов разворачивать полноценные виртуалки — уже нужны не каждый сервер потянет просто их запустить.
2. Во время лекции, совершенно не будет времени сидеть и восстанавливать Линукс (даже из образа), если студент неудачно выполнил fdisk/mkfs/rm -rf.
3. Разворачивать каждому по своей индивидуальной виртуалке для 15-минутной темы, или просто сделать 30 файлов — неужели вы берете с собой зерноуборочный комбайн, если нужно срезать букетик полевых цветов?
iig
Как вопрос для собеседования "а как вы будете создавать файл размером в 2гб и почему именно так?" — вполне годный.
knstqq
> cat file | xargs -n 2 -P `nproc`
Мне кажется, что всегда следует писать $(...) вместо ``. $() могут вкладываться друг в друга рекурсивно.
А ещё легче читать, потому что понятно, где начало, где конец, в отличии от `, которая выглядит симметрично.
khim
Важнее всего то, что "$("$()")" выглядит именно так — без единого бекслеша. А его аналог с ` будет выглядеть примеро как "`\\"\\\\`\\\\`\\"`" от чего в глазах рябит и ошибку сделать — раз плюнуть.
saboteur_kiev Автор
Честно говоря, если нужно делать вложение, я бы вообще предпочел переписать участок кода с использованием CMD=`` — это будет читаться еще лучше, чем вкладывать $() в $().
khim
У нас скрипты в репозитории часто начинаются с присваивания:
Чтобы весь каталог со скриптом можно было положить куда угодно и не думать об этом.Вы действительно предлагаете вот это переписывать? Как? И зачем?
saboteur_kiev Автор
Ну насчет всегда — можно поспорить.
Это больше стилистический момент, поскольку официально — оба метода равноправны, и `` не является deprecated или obsolete.
Лично мне проще читать ``, поскольку $ у меня связано больше с переменными, а $(()) с вычислениями.
khim
У нас с этим проще. Использовать надо $() — и всё. То есть это — даже не обсуждается.
saboteur_kiev Автор
Уже обновляю статью =)
P.S. Ссылку не смог открыть — гитхаб закрыт, но догадываюсь что там...saboteur_kiev Автор
Хм, почитал. Не могу сказать, что я готов следовать всем рекомендациям по ссылке.
Вроде как сейчас комфортнее писать #!/usr/bin/env bash для максимальной совместимости?
Тут все очень зависит. У меня есть простой скрипт, который деплоит приложение, состоящее из нескольких частей. Скрипт гораздо больше, чем 100 строк, но он именно удобная обертка для различных управляющих команд. Да, тут стоит probably, но все равно…
Если у скрипта не стоит расширение, то во многих редакторах автоматически не включится подсветка. Я предпочитаю ставить расширение всегда, иначе есть проблемы с запуском подобных скриптов под той же виндой, где нет бита executable, и поведение ОС зависит именно от расширения. То есть тут strongly disagree.
Это настолько forbidden, что на многих линуксах, по дефолту SUID/SGID просто не работает на скриптах, поэтому даже особого смысла упоминать нет.
Рекомендует использовать lower_case с подчерком для имен переменных, оставив uppercase только для environment переменных.
Не знаю, общемировая практика — использовать uppercase в шелл-переменных всегда. Код действительно будет более читабелен, особенно учитывая множество консольных команд и функций, которые идут в lowercase.
Я пока что предпочитаю все проверить, использовать кавычки, но остаться с более совместимым [, чем использовать [[.
Но тут возможно я уже устарел…
Несколько странный совет. Учитывая, что шелл — это не компилируемый язык, расположить функции где-либо еще сложно, ибо их нужно объявить до того, как использовать. Но если функций много, их лучше вынести в отдельный файл, и делать обычный инклюд через source — читабельность значительно повышается, и можно использовать одну функцию в разных скриптах тоже полезно.
В общем достаточно много не понравилось…
khim
Если вы хотите поддерживать клоны BSD — то да. Но у Гугла нет такой задачи.
Ну это, как бы, правилами тоже разрешено.
Не знаю чего там говорит «общемировая практика», но во всех autofconf-скриптах, которые я видел полно «локальных» переменных типа as_myself, as_bourne_compatible и т.п., которые только внутри скрипта используются. А переменные записанные большими буквами — экспортируются и импортируются. Это не Гугл придумал.
Перед ними знак доллара не стоит, так что спутать тяжело.
Подход Гугла во многом честнее: написание переносимых скриптов — это отдельное искусство, так что если у вас нет специальной задачи сделать скрипт, который будет работать «на любом утюге», лучше использовать все возможности bash'а, чем мучиться — и всё равно получить нечто, что на FreeBSD не работает.
Да, но можно завести пару функций — и поиспользовать из. Завести ещё несколько — и сделать ещё что-то. А потом, в конце — уже основной скрипт. Если нарушить одно из первых правил и напичать большой скрипт — удивление читателя гаранитровано!
Если не собираетесь конрибудить свои скрипты в Хром или Андрод — можете использовать свои правила.
Но если работаете в большом проекте — что-то подобное придётся составить, потому что иначе люди элементарные ошибки будут постоянно делать. А то насоздаёт кто-нибудь переменных из функции — а ты потом сиди, ломай голову, почему вызов двух функций в оном порядке работает, а если переставить их местами — уже нет.
saboteur_kiev Автор
Да, плюс вам за этот комментарий — наверное моя основная проблема — что я пытаюсь делать совместимое сам не знаю с чем.
Основная цель у меня была — совместимость скрипта под bash и ksh, которые были стандартом в местах, где работал. Но вроде как отличия минимальные (помню только какие-то delayed evaluation в ksh, но их использовать себе дороже). А я под эту цель часто пытался запихнуть ненужной совместимости с чем-то еще.
warlock13
Выкиньте эти редакторы, не издевайтесь на собой — их писали криворуки.
Расширение — только для того чтобы отдать файл правильной программе, программа должна смотреть на контент.
saboteur_kiev Автор
Я вас перецитирую:
Выкиньте эту операционную систему (windows, я так понимаю?), не издевайтесь над собой — ее писали криворуки.
Расширение вообще не нужно, опреациона должна сама смотреть на контент/заголовок, как это делается в unix/linux.
P.S. Скрипт, особенно библиотека, может вообще не содержать никакого #!, как тогда будет вести себя ваш умный редактор? Анализировать весь файл, и открываться полчаса, чтобы мне в скрипте поправить через vi один символ?
Не нужно обзывать кого-то криворуким за то, что он использует популярный способ, тем более, что вы сейчас наступили одновременно на мой любимый FAR и vi сразу.
iig
Собственно, гадание по магическим байтам с помощью libmagic — это красиво. Но гадание по расширению быстрее.
warlock13
Нет, ОС (и их встроенные файловые менеджеры) этим как раз отличаются — одни смотрят на расширения больше, другие меньше — что ж тут такого? Равно и невстроенные файловые менеджеры — естественно, они смотрят на расширение. Это программы, работающие с файлом "снаружи". Но когда файл "ушёл" к программе, которая предназначена для работы с файлом "изнутри", программа должна смотреть именно на контент, а на особенности названия файла (а расширение — это часть названия, даже в Windows, где она более особенная часть) если и смотреть, то в самую последнню очередь и только если действительно надо. Если этого не придерживаться, то легко можно получить ситуацию, когда абсолютно валидный файл не открывается какой-то программой, которая умеет с ним работать, но не может, потому что файл называется, не так, как она (программа!) хочет. Собственно поэтому так и не делают, и вы можете назвать файл с matroska video внутри video.avi и открыть его любой программой, и ни одна даже не пикнет.
Так в обсуждаем списке рекомендаций библиотеки-то как раз рекомендовалось называть с суффиксом .sh, если в скрипте шапки нету — ему тоже логично такой суффикс придать.
Но если скрипт имеет шебанг, нет никаких причин проставлять расширение. А если ваш редактор не может открыть такой скрипт с подсветкой — повторю — выкиньте такой редактор, это ненормальное поведение.
saboteur_kiev Автор
Простите, вы видимо не догадались, что я писал свое сообщение с сарказмом.
В линукс — операционка вообще не смотрит на расширение. Она смотрит на права доступа и на заголовок файла внутри.
Я совершенно не собираюсь выкидывать редактор, который служит верой и правдой десятки лет только потому, что вы считаете что он не должен зависеть от расширения. При этом мне это совершенно не важно, а вот все остальное, что этот редактор умеет — мне очень важно. Поэтому ваш совет — плохой, не несет никакого полезного конструктива.
Ipeacocks
> tail -f application.log | grep -i -P "(error|warning|failure)"
Можно вместо grep в єтом случае использовать egrep, например
tail -f application.log | egrep «error|warning|failure»
Хотя да, разница небольшая.
ALexhha
Несколько замечаний
стоит так же учитывать, что второй вариант менее универсален. И часто вы упираетесь в производительность в bash скриптах?Лично мне запомнить синтаксис bash variable expansions намного сложнее, чем cut/awk. Так как для меня совсем не интуитивно, что команда ${STRING##*:} извлечет 3й столбец
только надо учитывать, что флаг -P доступен далеко не везде. Например в том же alpine его нет
форма `some command` уже давно как deprecated и вместо нее советуют использовать $(some command)
P.S.
если кто не сталкивался, то по bash есть довольно таки хороший ресурс — wiki.bash-hackers.org/syntax/pe Так сказать краткая вижимка известного Advanced Bash-Scripting Guide
saboteur_kiev Автор
Вот прямо сейчас сильно уперся в том, что тот же баш-скрипт под Windows работает в несколько десятков раз медленнее, что занимает несколько минут для обработки жалких 10 файлов, общим размером в 10 кбайт. Да и даже под Линуксом, он выполняется не мгновенно. После перехода на удаление по маске — секунды.
Ну он не извлечет третий столбец, это относится именно к примеру из статьи. Наверное сейчас немного перепишу этот абзац, много замечаний к формулировке. С другой стороны — скрипт я пишу один раз, могу и посидеть в гугле лишних 10 минут, зато потом выполнять я его буду сотни и сотни раз.
Вот с этим я не согласен. Официально она никак не deprecated и не obsolete.
Отличается от $() только возможностью вложенности без лишнего экранирования, и стилистикой.
Ну или приведите официальный источник, где `` указывается как deprecated — я не нашел…
ALexhha
Вот тут — pubs.opengroup.org/onlinepubs/9699919799/xrat/V4_xcu_chap02.html#tag_23_02_06_03
они конечно не написали дословно deprecated, но тем не менее явно рекомендуют не использовать `` — «Because of these inconsistent behaviors, the backquoted variety of command substitution is not recommended for new applications».
Вообще мне понравился один комментарий на SO насчет этого момента
Так же в некоторых специфичных ситуациях поведение будет отличаться, например
saboteur_kiev Автор
cygwin, который идет вместе с git
Да, в такой рекомендации оно понятно. Проще использовать $(), чем разбираться с экранированием и разборкой специфичных случаев. Приму к практике.
По поводу echo — поведение и должно отличаться согласно синтаксису:
When the old-style backquote form of substitution is used, backslash
retains its literal meaning except when followed by $, `, or \. The
first backquote not preceded by a backslash terminates the command sub?
stitution. When using the $(command) form, all characters between the
parentheses make up the command; none are treated specially.
Поэтому в ``, обратный слеш нужно дублировать:
ALexhha
да, я в курсе. Просто указал на момент, что не всегда можно просто заменить `` на $(). Это тоже стоит учитывать.
saboteur_kiev Автор
В рабочей среде, к сожалению нет возможности ставить пользователям софт, кроме утвержденного списка, добавить в этот список что-то с нашей стороны — практически нет возможности…
ALexhha
JFYI, попросил знакомого запустить на Win 10, WSL
c пайпами на windows все очень печально
younghacker
Как раз таки разрабочики ssh позаботились о том чтобы неискушённый пользователь не мог показать пароль всем процессам в системе. А разработчик sshpass ликвидировал это досадное недоразумение:
Между тем для правильного приготовления ssh придуманы ключи.
saboteur_kiev Автор
IMHO мы имели ввиду одно и тоже, нет?
IRyston
Результат в статье подправьте.
Должно выводиться
server1
server2
server3
saboteur_kiev Автор
Спасибо поправил. Но опечатки лучше в личку.
McAaron
Таки, комментарий про cat vs. read:
$ ./test
using cut
real 0m1,099s
user 0m0,579s
sys 0m1,338s
using ##
real 0m2,246s
user 0m1,739s
sys 0m0,505s
$
saboteur_kiev Автор
У вас тоже Mac?
Плиз, можете описать ОС и где она запускается? Вы не первый с подобным результатом, но я уже перепробовал на всех доступных мне вариантах ОС (около 4 линуксов, 2 юникса и bash for windows — у меня cut в десятки раз медленнее работает).
urtow
На маке стоит BSD реализация, можете попробовать на нем. По идее результаты должны совпадать
saboteur_kiev Автор
Нет, это выше в ветке мне постили похожие результаты с Мака, поэтому я и думал что у вас тоже Мак.
А для FreeBSD я уже приводил свои результаты — у меня показывает, что cut дольше в десятки раз.
urtow
Изначально ветка не моя, попробую дома с маком.
Но у меня может быть не родной bash, я мог впихнуть туда через homebrew GNU версию
urtow
Не то, чтобы быстрее
use cut
real 0m3.738s
user 0m1.661s
sys 0m1.237s
use ##
real 0m4.127s
user 0m3.067s
sys 0m1.037s
Mac OS Sierra 10.12.6 (16G29), MacBook Air (13-inch, Early 2014)
saboteur_kiev Автор
Про Mac Os уже несколько человек сказали, что там скорость выполнения наоборот, и подсказали почему =)
McAaron
Fedora Core 26. kernel-4.13.5-200.fc26.x86_64
$ cat /proc/cpuinfo
…
vendor_id: GenuineIntel
cpu family: 6
model: 23
model name: Intel® Core(TM)2 Quad CPU Q9550 @ 2.83GHz
stepping: 10
microcode: 0xa0b
cpu MHz: 2833.279
cache size: 6144 KB
physical id: 0
siblings: 4
core id: 3
cpu cores: 4
apicid: 3
initial apicid: 3
fpu: yes
fpu_exception: yes
cpuid level: 13
wp: yes
flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx lm constant_tsc arch_perfmon pebs bts rep_good nopl cpuid aperfmperf pni dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm sse4_1 xsave lahf_lm tpr_shadow vnmi flexpriority dtherm
bugs:
bogomips: 5665.79
clflush size: 64
cache_alignment: 64
address sizes: 36 bits physical, 48 bits virtual
…
McAaron
> Автокомплит в bash…
В полуоси был двухпанельник fc, так вот из под него можно было по нескольким первым буквам вызвать из истории все команды, которые начинались с этих букв, и выбрать из них нужную. Например, набрав «tra» и стрелочку (емнип), получим вывод типа
1. tracepath a.b.c.d
2. tracepath b.c.d.e
3. translate
4. tracepath c.d.e.f
После чего набираем число и ентер. Круто экономит мозги на предмет хранения ключей и опций.
В bash такое есть?
saboteur_kiev Автор
сравнивать двухпанельник и консоль — не есть гуд, но
1. Попробуйте Ctrl+R, с поиском по командам и так далее
2. История команд есть в двухпанельнике mc.
3. А на винде, я вообще могу прямо из bash запустить например двухпанельник FAR, и там будет очень много «такого» =)
fogx
Кстати, двухпанельник FAR уже есть и под линукс, и под мак.
github.com/elfmz/far2l
McAaron
Под линукс есть mc. Если бы у фара было то-то такое крутое, чего не в mc, он бы попал в дистрибутивы.
saboteur_kiev Автор
У FAR-а просто дохрена крутого. Просто он изначально написан не под Линукс, а портирование — дело весьма непростое, и неблагодарное.
McAaron
Дело не в двухпанельнике — я его упомянул как родителя конкретного консольного сеанса, а в интерфейсе командной строки, который этот самый сеанс из-под fc предоставляет. mc тоже предоставляет командную строку, вот только ни у баш, ни у него найти быстро, т.е. в два-три нажатия клавиш — это еще тот геморрой.
Насчет виндовса не знаю — я ее с выхода варп-коннекта как повседневную среду не использовал — не было таких задач, которые нельзя было порешать на полуоси, а потом и в линуксе. А вот задач, котороые нельзя было порешать в виндах или их решение было сопряжено с геморроем, было много.
saboteur_kiev Автор
В FAR отличная синергия с командной строкой, включая продвинутую поддержку истории, плюс взаимодействие с файловой системой.
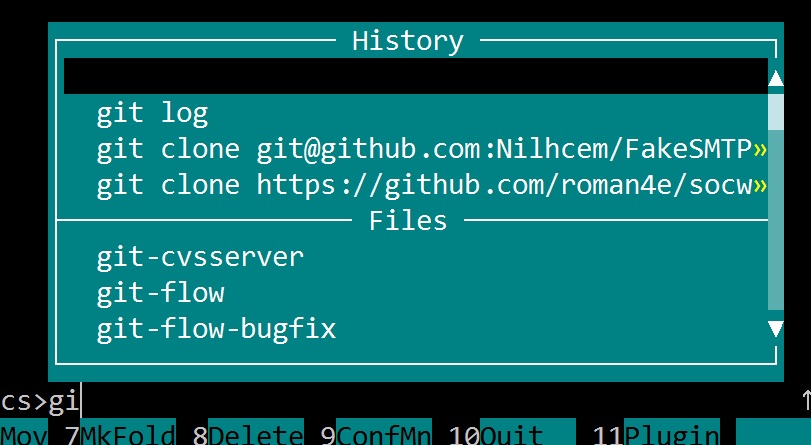
При включении опции просмотра истории, при наборе любой команды, автоматом предлагается автодополнение из истории, вот я ввожу «gi» и получаю:
McAaron
Это, без соменния, была бы ценная фишка, если бы перечень выходил таки не в окно, а в консоль (в буфер терминала), чтобы он был пронумерован (возможность выбора вводом порядкового номера) и в нем были только команды.
nlykl
В bash нет, но можно настроить в zsh.
saboteur_kiev Автор
Почему нет? Ctrl+R в баше есть
McAaron
Можно это сделать проще:
$ rename .txt .lst *.txt
saboteur_kiev Автор
Я упоминал rename в статье. Суть не в ренейме а в возможности применения конструкции {} для формирования двух аргументов, например для какого-то конвертера из .jpg в .png
ov7a
Что-то в третьем примере вы не используете наработки из первого.
Self_Perfection
Можно же лучше. Деаллоцировать начало лога, превратив в sparse. Как-то так:
Himura
А тут есть какой-то скрытый смысл в разбиении команды на две? (при том что вторая выполнится независимо от первой, лучше наверно
;заменить на&&)Или можно переписать вот так без вреда для здоровья?
Для статистики, мне больше всего понравилось вот это ))
Довольно изощрённо, но элегантно.
Ну и про издевательства над переменными при выводе не знал
saboteur_kiev Автор
1. Почему; лучше заменить на &&?
Это никак не меняет того, что это будет две команды, просто меняется условие выполнения второй команды, но их все равно остается две.
2. echo "`tail -n 1000 application.log`" > application.log
Можно и так, но меня уже убедили, что лучше будет echo "$(tail -n 1000 application.log)" > application.log
3. спасибо =)
Himura
при && вторая команда не будет выполняться если упадет первая. Когда вторая зависит от первой, лучше применять &&. например, если application.log не существует, он будет ошибочно создан пустым в оригинальном примере
saboteur_kiev Автор
Так как изначальная цель — сократить размер файла, то в любом случае — будет он обрезан или создан пустым — уже не столь важно.
Но в принципе конечно годное замечание, спасибо!
oklas
если опасаться того, что пароль при запуске программы:
то такую команду тоже нельзя запускать:
тогда также и нельзя допускать вероятность чтения такого файла и права доступа должны быть установлены до записи в файл или в момент записи, поэтому:
или
saboteur_kiev Автор
Почему нельзя?
echo это внутренняя команда (несмотря на существование /bin/echo, приоритетом будет внутренняя команда). Поэтому как отдельный процесс она не запускается и ее не будет видно в списке процессов — смело можно делать echo «secretpassword».
Если у вас есть подозрение, что на этом же сервере сидит злоумышленник и ждет момента прочитать secret.key, пока на нем пару милисекунд есть права для чтения — лучше сразу поменять сервер =)
oklas
Про
echoпо всей видимости вы правы, даже для программыechoлежащей в текущей папке необходимо указать путь./для её запуска. Есть всё же возможнотсь иechoзаставить работать по другому, например при помощиaliasно это может быть только по ошибке/фиче сделаной кем-то из самих админов но это не будем рассматривать. Но всё же такой подход необходимо если не использовать то знать обязательно. Так как в следующий момент это окажется неechoа другая команда.А по поводу:
Пока что разделямый хостинг не отменили. И вот пока он существует, все команды управления на нём выполняются в среде где сидит такой злоумышленник. Так-же и на хостинге/облаке и т.п., где часть выполняемых задач являются предоставляемым сервисом. Тоесть такой VPS и т.п., где клиент-владелец может например из панели устанавливать скажем софт. То клиент-владелец этого VPS и есть этот злоумышленник. Если имеются данные (не только пароли) которые к клиенту не должны попасть то их необходимо защищать подобным образом.
saboteur_kiev Автор
В случае тех страшных вещей про злоумышленников-владельцев VPS предоставляющих shared sites, нужно не скриптами защиту повышать, а переходом на VPS, или даже поискать коллокейшн или уже на свои собственные сервера и датацентры.
Ибо владелец VPS, может просто зайти под рутом и посмотреть данные прямо у вас в файле, или даже не пароли, а сразу нужные ему данные в базе вашего проекта, а не ждать пока вы запустите процесс с небезопасным аргументом.
oklas
я не про владельцев разделяемого хостинга а про клиентов, когда сосед может наблюдать за действиями соседа. Аналогично и на рабочем сервере обычный пользователь, может наблюдать за некоторыми действиями админа или другого пользователя.
Сейчас получается что вы вроде как формируете такой сценарий где нет злоумышленника под задачу где есть злоумышленник. Это есть изменение условий задачи. Если в вашей задаче нет злоумышленника то и защищать не нужно — это хорошая задача. В реальности имеется вероятность что есть злоумышленник. Это могут быть дыры в сайте или человеческий фактор, и т.п. не важно как он появился и какие у него цели — он должен быть лишён малейшей вероятной возможности получить доступ к данным.
oklas
Всё же следует учитывать то что на
echoможет быть установленaliasнапример с целью логгирования или ещё за какой надобностью. Хотя бы даже и временныйalias. Так что скрипты и действия должны быть написаны и выполняться с учётом того чтоechoможет не являться встроенной командой.saboteur_kiev Автор
Alias — тоже внутренняя команда шелла.
Скрипты и действия должны выполняться с учетом того, что вы контролируете ваше окружение. Если же вы пишете скрипты, которые будут выполняться неизвестно в каких условиях, то echo будет далеко не единственной вашей проблемой.
Как это уже говорилось выше, лучше пользоваться ssh ключами, сертификатами и другими способами авторизации, которая вообще не предполагает передачу именно пароля прямым текстом через аргументы или пайпы.
oklas
Конечно лучше. Но исходная задача была использование
echoс приватными данными. Её нужно выполнять как в моём примере.Проконтролировать окружение — это не значит что вы как старший админ гарантируете что по вашей инструкции никто не должен ставить
aliasнаecho(вы или другой ведь могли отменить это, когда востребовано, забыв что есть чувствительный к этому код). Гарантировать окружение это значит перед выполнением командыechoс приватными данными скрипт должен проверить а не установлен лиaliasнаecho. Тогда это будет гарантия. Возможно скорее всего такойaliasбыл востребован и написан правильно, но теперьechoявляется программой. Проще всё же в таком случае просто сразу считатьechoпрограммой.saboteur_kiev Автор
Возможно, ваш скрипт в таком случае, должен также проверить, какой именно шелл его выполняет, а точно ли этот шелл взят из репозитория, а точно ли этот репозиторий не скомпроментирован и так далее.
Обычный пользователь не может прописать алиас другому обычному пользователю. Поэтому если вы даете программу тому, кто не умеет настраивать безопасное окружение, не стоит надеяться, что вы предусмотрите подобные моменты в скриптах — это как раз неправильный путь.
Есть ожидаемое поведение, в котором echo — внутренняя команда. На это можно рассчитывать, если ваше окружение настраивает адекватный админ.
Если писать приложение, которое требует безопасности, с рассчетом, что его будет настраивать криворукий и жутко любопытный пользователь — боюсь, что скрипты вообще лучше не трогать, так как он и туда залезет =)
oklas
Не "возможно", а именно всё это обязательно делается при установке и настройке ос. Какой именно шелл а также версия прочих компиляторов, инструментов и библиотек проверяется/указывается при развёртывании. И отпечатки к при доступе к репозиторию контролируются. Да всё это необходимо делать. Более того для всего кода пишутся тесты и выполняются в среде аналогичной рабочей. А вот
aliasне проверяется так как является правильным рабочим инструментом с "ожидаемым поведением" так-же как иecho.Вот конкретно установка
aliasнаecho— и написание чувствительного к этому кода — грабли. Код чувствительный к этому писать нельзя или можно надеяться что никогда не будет установлен alias — с этим вроде всё ясно.oklas
...
crower
И всё-таки о кавычках.
Конструкция «mv "$name{.txt,.lst}"» не работает.
Во-первых, находясь в кавычках brace expansion не разворачивается и во-вторых, то, что закавычено, воспринимается одним параметром и в результате mv возвращает "missing destination file operand after (подставленная переменная){.txt,.lst}.".
«mv $name{.txt,.lst}» работает если в имени нет пробелов, а «mv "$name"{.txt,.lst}» должно работать и с пробелами.
По поводу первого замечания в мане написано: "A correctly-formed brace expansion must contain unquoted opening and closing braces, and at least one unquoted comma or a valid sequence expression. Any incorrectly formed brace expansion is left unchanged."
saboteur_kiev Автор
Да, именно поэтому там просто пример, как можно использовать brace expansion, а для переименовывания рекомендуется использовать утилиту rename.
saboteur_kiev Автор
Небольшое обновление статьи и дополнение в самом конце.