
Во время рабочей недели со всех сервисов СБИС в облаке к нам поступает в сутки более 11 млрд записей, хранятся они 3 дня, общий объем занимаемого при этом места не превышает 32 Тб. Все это обрабатывает 8 серверов с PostgreSQL 9.6. Каждый сервер имеет 24 ядра, RAM 16Гб и 4 SSD диска по 1Тб.

Кому это надо?
Наши сервисы написаны на 40% Python, 50% C++, 9% SQL, 1% Javascript. Сервисов более 200. Часто требуется оперативно разбираться в проблемах различного рода — разбор зарегистрированных ошибок или логических. Иногда нужен просто мониторинг работы, проверка, все ли идет по задуманному сценарию. Все это у нас могут выполнять разнородные группы: разработчики, тестировщики, администраторы серверов, в каких-то случаях и руководство. Поэтому нужен понятный инструмент для всех этих групп. Мы создали свою систему логирования, а правильнее сказать систему трассирования http-запросов к нашим web-сервисам. Она не является универсальным решением для логирования вообще, но для нашей модели работы подходит неплохо. Кроме собственно просмотра логов, у нас есть иные применения собранных данных – об этом следующий раздел.
Иные применения логов
Наши http-запросы к web-сервисам могут для удобства анализа представляться в виде дерева вызовов. Упрощенно это дерево можно изобразить так:
Запрос к сервису А
|- Поток-обработчик номер 1
| |- SQL запрос к базе X
| |- Внутренний подзапрос 1
| | |- Запрос к Redis Y
| | |- Синхронный http-запрос на сервис B
| |- Внутренний подзапрос 2
| | |- SQL запрос к базе X
| | |- Синхронный http-запрос на сервис C
|- Поток номер 2
|- Асинхронный запрос на сервис W
Screen отчета см. рис. 1, представляющего такое дерево, говорит красноречивее. На каждом узле показывается, сколько времени заняло его исполнение, сколько процентов это составляет от родителя. По ним можно поискать узкие места в запросе. По ссылкам можно посмотреть логи субзапросов на другие сервисы. Отчет довольно удобный, строится почти моментально. Бывают, конечно, исключения, когда деревья вызова содержат миллионы записей (ну да, есть и такие). Тут процесс происходит подольше, но до 5 млн записей в дереве результат получить можно. Этот отчет мы называем «профилирование одного вызова», ибо чаще всего он используется для целей профилирования работы.
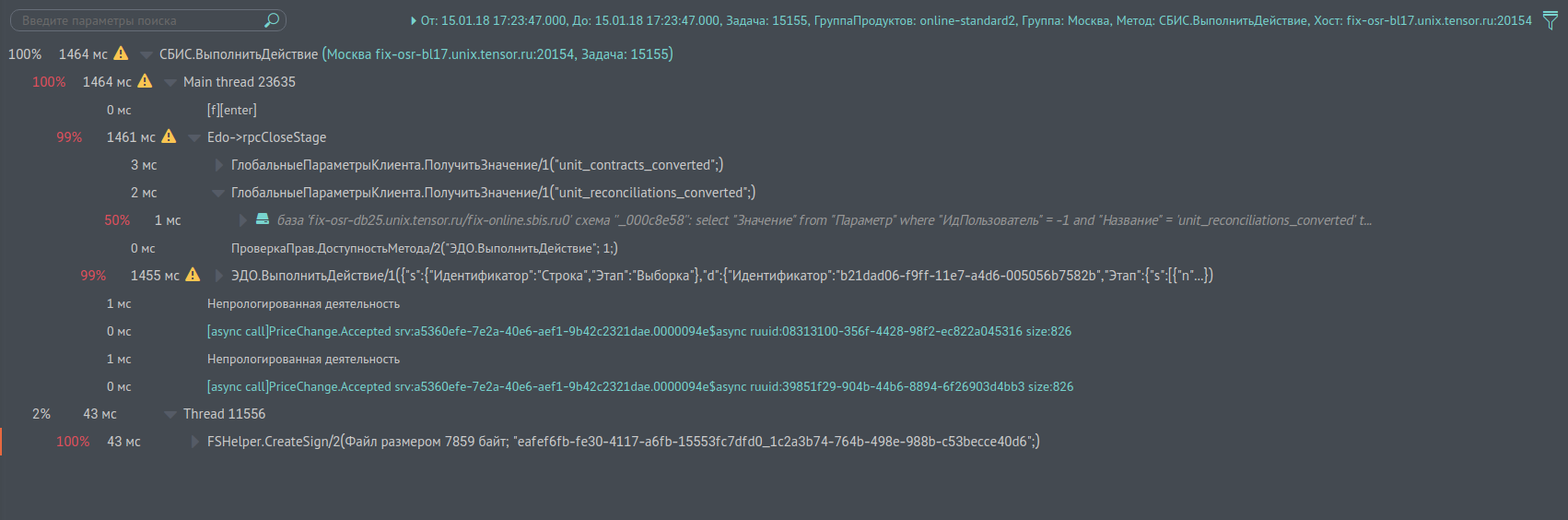
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Рис. 1. Профилирование одного вызова
Иногда возникает потребность выполнить профилирование типового запроса по статистической выборке однотипных вызовов, а не по одному вызову. Для этого у нас существует отчет, который объединяет такие вызовы в одно дерево, показывая его узлы и листья в виде квадратов с площадью в % от времени родительского вызова. См. screen на рис. 2
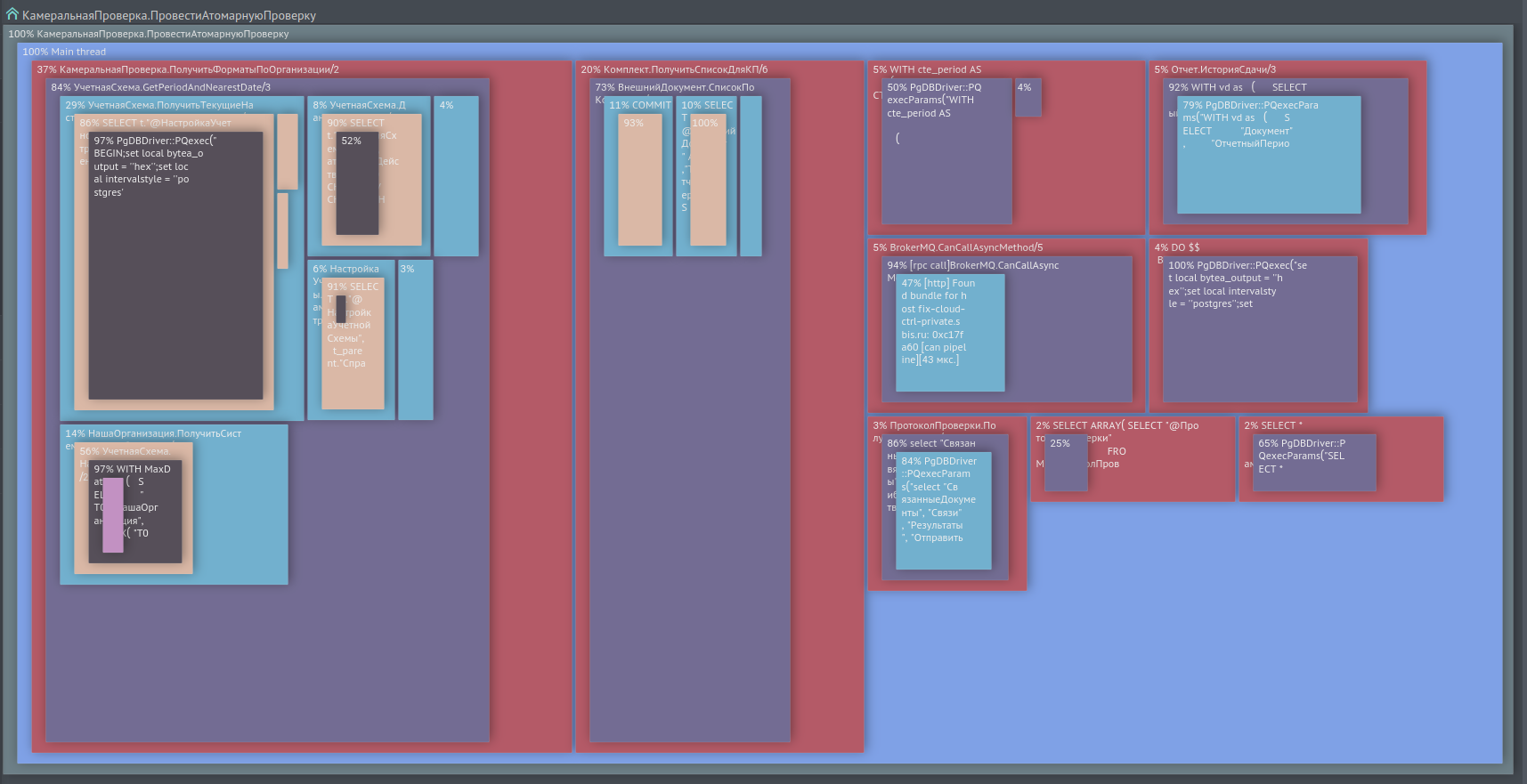
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Рис. 2. Профилирование по нескольким типовым вызовам
Есть отчет позволяющий отлавливать наличие сетевых задержек. Это когда сервис A послал запрос другому сервису B, ответ был получен за 100ms, а сам запрос на сервисе B исполнялся 10ms, а 90ms где-то пропали. Это пропавшее время мы называем «лагом». Screen отчета по лагам приведен ниже на рис. 3.
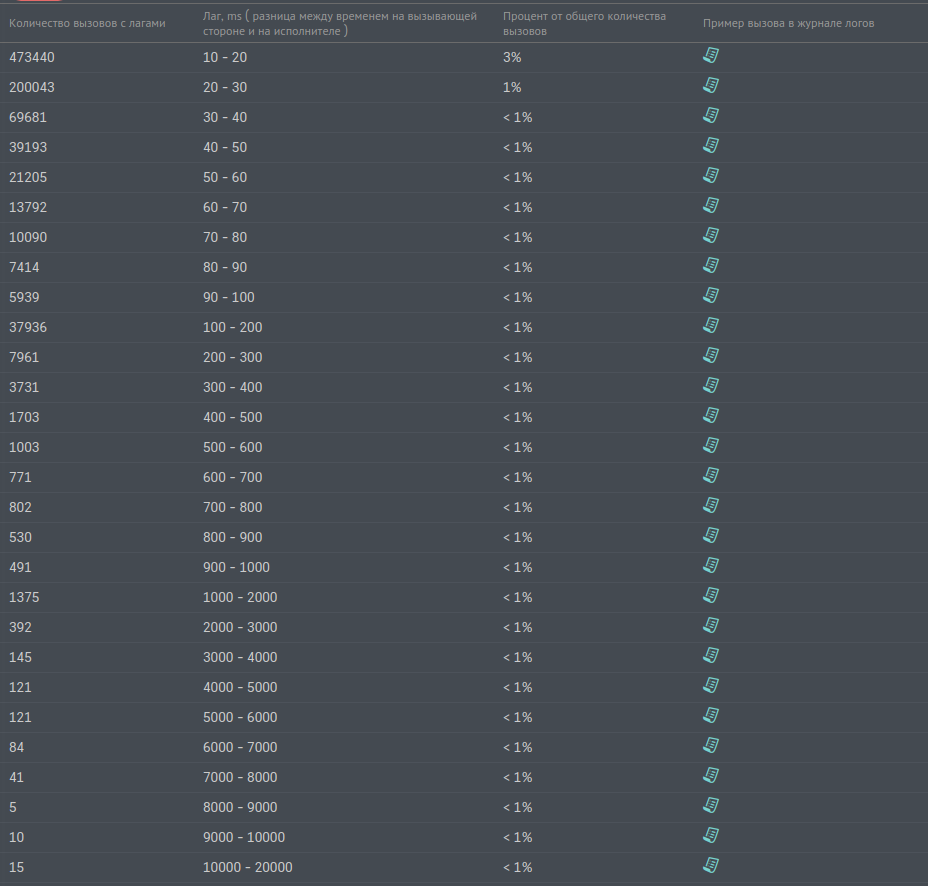
Рис. 3. Отчет по лагам
Кроме этих отчетов по логам, мы пользуемся и другими, но они не такие массовые, как приведенные отчеты.
Как оно все работает
Наши web-сервисы складываются из равноправных независимых узлов. Каждый узел сервиса состоит из управляющего процесса и нескольких рабочих процессов. Управляющий процесс принимает http-запросы клиента и помещает их в очередь на ожидание обработки, а также отсылает ответы клиенту. Рабочие процессы забирают запросы из очереди управляющего процесса и выполняют реальную обработку. Могут обратиться в базу данных PostgreSQL, к другому web-сервису, или в Redis, или еще куда-нибудь.
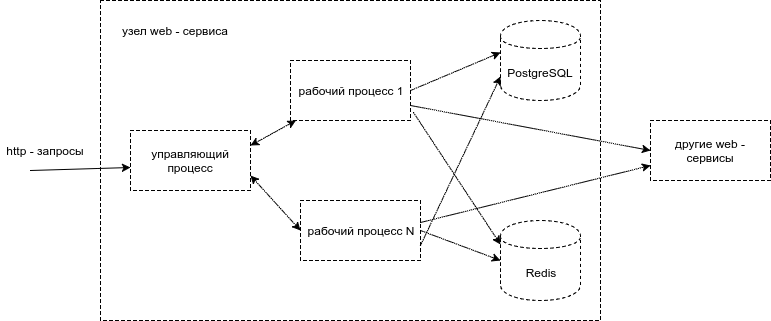
Рис. 4. Архитектура узла web-сервиса на уровне процессов
Каждый запрос к сервису имеет следующий набор атрибутов, которые мы должны записать в логи:
- уникальное имя запроса, мы его зовем «метод сервиса»
- узел сервиса, куда в итоге поступил запрос
- IP инициатора запроса
- идентификатор пользовательской сессии
- UUID каскада запросов (каскад запросов – это когда один запрос снаружи к сервису порождает серию запросов к другим сервисам)
- номер запроса на узле сервиса — при перезагрузке сервиса номера запросов сбрасываются
- номер рабочего процесса, обработавшего запрос
Внутри запроса происходят различные события: обращения в PostgreSQL, Redis, СlickHouse, RabbitMQ, в другие сервисы, вызовы внутренних методов сервиса. Мы регистрируем эти события со следующими атрибутами:
- дата и время возникновения события с точностью до миллисекунд
- текст события — это важнейшая часть, в нее записывается все, что не укладывается в другие атрибуты: текст SQL запроса, команда обращения в Redis, параметры вызова с другого сервиса, параметры асинхронного вызова через RabbitMQ, и т.п.
- длительность события в миллисекундах
- номер потока, в котором возникло событие
- тики процессора — нужны для определения последовательности событий, имеющих одинаковые дату и время, точность-то до миллисекунд
- вид события: обычное, предупреждение или ошибка
Таким образом, структура данных выглядит в первом приближении как на рисунке внизу.
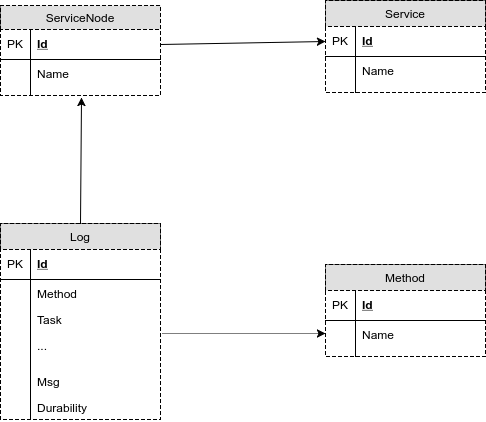
Рис.5. Первый вариант структуры базы для хранения логов
Здесь на рисунке:
Service — таблица с названиями сервисов, их там немного, несколько сотен
ServiceNode — таблица с узлами сервисов, в ней несколько тысяч записей, с одним сервисом может быть связано несколько узлов
Method — таблица с именами методов, их тоже несколько тысяч
Log — Log — собственно, основная таблица, куда пишутся данные запроса и его события. Таблица намеренно денормализована, чтобы не терять время на join на большие таблицы в запросах и не держать лишние индексы. Например, атрибуты запроса можно было бы вынести в отдельную таблицу, но тогда усложнилась бы логика добавления и извлечения данных. Можно было бы вынести UUID и Идентификатор пользовательской сессии, но пришлось бы иметь на каждое такое вынесенное поле индекс в новой таблице по полю, индекс по внешнему ключу в таблице Log и ненужный первичный ключ в новой таблице.
Web-сервисы отсылают логи по http, через nginx (для балансировки). Узлы сервиса логов их обрабатывают и записывают в базу. Схема приведена ниже.

Рис. 6. Схема отсылки логов на сервис логов
На рис.7 показан screen, как выглядят наши логи запроса на узел fix-osr-bl17.unix.tensor.ru сервиса «Москва». Запрос называется «СБИС.ВыполнитьДействие», его номер 15155. UUID приводить не буду, он выведен над названием запроса. Первой идет запись с сообщением вида «[m][start]Edo>EDOCertCheckAttorney» — это фиксация события начала вызова внутреннего метода сервиса без аргументов. Следующим за ним сразу идет начало второго субвызова «[m][start]Документ.Входящий/1(234394;)» c одним аргументом со значением 234394. Потом выполняется вызов c узла кэширующего сервиса, об этом говорит строка «[rpc call]… и т.д.

Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Рис. 7. Screen экрана логов по методу «CБИС.ВыполнитьДействие» на узле «fix-osr-bl17.unix.tensor.ru»
За полтора года существования эта схема базы данных и сервиса не претерпела серьезных изменений. С какими проблемами нам пришлось столкнуться? Изначально мы писали в одну базу и с первых же дней столкнулись с тем, что:
- Писать в базу обычным способом через INSERT у нас не получится, и мы перешли только на инструкции COPY.
- Удалять устаревшие данные обычным способом через DELETE нереально, и мы перешли на TRUNCATE. Эта инструкция действует достаточно быстро на всю таблицу целиком, усекая файл почти до нулевого размера. Однако нам пришлось завести на каждый день месяца свою таблицу-секцию, чтобы удалялись только неактуальные данные. С TRUNCATE все равно есть один неприятный момент – если сервер PostgreSQL решил запустить над табличкой процесс autovacuum to prevent wraparound, то TRUNCATE не исполнится, пока autovacuum to prevent wraparound не закончится, а работать он может довольно долго. Поэтому перед чисткой этот процесс мы прибиваем.
- Журнал транзакций нам не нужен — и мы стали создавать таблицы через CREATE UNLOGGED.
- Синхронная запись на диск не нужна — и мы сделали fsync=off и full_page_writes=off, это допустимо, выходы баз из строя из-за дисков, конечно, были, но они крайне редки.
Эти операции достаточно неплохо разогнали сервер PostgreSQL. Мы пробовали еще менять параметры synchronous_commit и commit_delay, но в нашем случае они заметно не повлияли на производительность.
С учетом дробления таблиц на секции данных для каждого дня месяца новая схема базы теперь выглядела так:
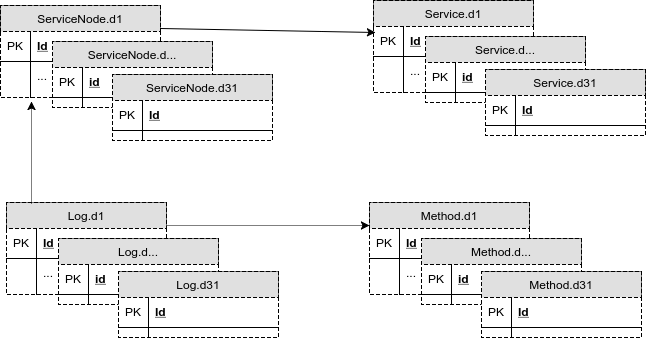
Рис. 8. Схема базы с таблицами на каждый день месяца
С течением времени, при постоянно растущих объемах логов, мы уже не могли хранить данные в одной базе. И первый прототип сервиса логов переделали на распределенный вариант. Теперь каждый узел сервиса логов писал в одну из нескольких баз, выбирая базу для записи по алгоритму «round-robin». Это было достаточно удобно. Статистически каждая база получала одинаковую нагрузку, нагрузка масштабировалась горизонтально, объемы данных на базах совпадали с точностью до Гб. Вместо одного сервера PostgreSQL для логов теперь трудилось 5. Схема для узлов сервиса логов выглядела так:
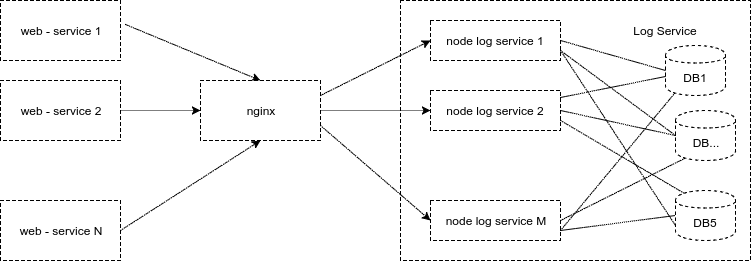
Рис. 9. Схема работы сервиса логов с несколькими базами данных
Из схемы видно, что каждый узел сервиса держит соединения с несколькими базами. У такой схемы, конечно, есть недостатки. Если из строя выходила база или она начинала «тупить», то работать переставал весь сервис, т.к. все равнялись по самому последнему, ну и при добавлении нового узла сервиса возрастало число соединений на сервер PostgreSQL.
Одновременная запись в одну таблицу через большое число соединений вызывает большее число блокировок, что замедляет процесс записи. C увеличением числа соединений на базу можно бороться, используя pgBouncer в режиме TRANSACTON MODE. Однако чудес не бывает, и в этом случае несколько возрастает время на выполнение запроса, т.к. все-таки работа идет через дополнительное звено. Ну и при TRANSACTON MODE слишком часто переключаются соединения с базой, что тоже не лучшим образом отражается на работе.
На этом варианте мы проработали еще год, и, наконец, перешли к схеме, в которой один узел сервиса работает ровно с одной базой, напрямую, без pgBouncer. Это оказалось эффективнее в 2 раза, а к тому времени мы добавили еще 3 базы, и у нас их стало 8. На таком количество и живем по сей день.
От такой схемы мы получили еще небольшие плюсы. Число соединений к базе не растет при добавлении нового узла. Если база начинает тупить, то nginx распределяет нагрузку на другие узлы сервиса.
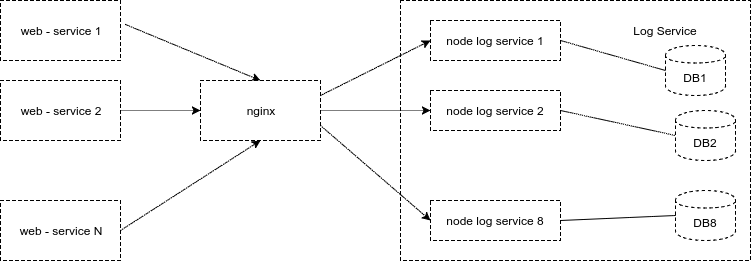
Рис. 10. Текущая схема сервиса логов: один узел — одна база
Дополнительно для лучшей работы сервера PostrgeSQL, а он у нас работает на Centos 7, мы поставили планировщик deadline. И еще уменьшили размер «грязного»(dirty) кэша. Это параметр vm.dirty_background_bytes, в нем задается размер кэша, при достижении которого система начинает фоновый процесс сброса его на диск. Если объем его слишком большой, на диск прилетает пиковая нагрузка – параметр нужно подобрать так, чтобы она сгладилась.
Кроме проблем с производительностью, есть острая проблема нехватки места хранения. Сейчас мы обходимся 32-мя Тб. Этого хватает на 3-е суток. Однако иногда бывают пиковые всплески записи логов в несколько раз, и место заканчивается раньше. Как с этим бороться, не увеличивая места? Мы сформулировали для себя задачу так: нам нужно, чтобы оставались хоть какие-то логи, пусть и в ущерб их подробности.
В соответствии с этим мы разбили таблицу логов за день на три таблицы. Первая хранит данные за период с 0 часов до 8-ми, вторая с 8-ми до 16-ти, третья с 16-ти до 24-х. Каждую из этих таблиц дополнительно разбили еще на три секции. Секции соответствуют трем уровням важности логов. Первый уровень хранит основную информацию о факте запроса, его длительности, без подробностей, и факты ошибок, возникшие при запросе. Второй уровень хранит информацию о субвызовах и SQL-запросах. Третий уровень хранит все, что не входит в первые два. Если узел сервиса логов понимает, что свободного места на запись остается менее 15%, он начинает очистку самой старой секции с третьим уровнем. И так до тех пор, пока не останется достаточно места для записи. Если больше секцией третьего уровня нет, а места все еще не хватает, то начинается очистка секций второго уровня, ну и в самом крайнем случае первого, но такого еще не было.
До этого речь шла про запись логов, но запись-то делают для того, чтобы потом читать. В общем-то, для чтения в зависимости от периода времени вычисляются нужные секции таблицы и подставляются в запрос. Текущий механизм PostgreSQL работы с секциями нерабочий и неудобный, мы им не пользуемся. Как выглядит результат запроса к логам, мы показывали на рис. 7. Основные требования к запросу:
- он должен быть быстрым, насколько это возможно
- по результату запроса должна быть навигация
Удовлетворить оба требования на 100% невозможно, но их можно реализовать для 80% запросов. Это мы и сделали. Получилось около 20 профилей запросов, укладывающихся в 11 индексов по таблице Log. Индексы, к сожалению, замедляют добавление записей и крадут место. В нашем варианте эти индексы забирают место сравнимое с местом под данные.
Мы никогда не выбираем данные за весь период времени указанный пользователем для получения логов, это было бы слишком неэффективно. Во многих случаях достаточно показа первой или последней страницы запроса. В более редких случаях пользователи могут выполнять навигацию к следующим страницам. Рассмотрим алгоритм выбора логов на примере. Пусть у нас запросили данных за период длиной в 1 час с выводом 500 записей на одной странице:
Сначала мы пробуем построить запрос за период длиной в 1 ms, обращаясь в параллель ко всем базам логов. После получения результата со всех баз мы объединяем запрос, сортируя его данные по времени. Если 500 записей не набралось, то сдвигаемся на 1ms, увеличиваем период в 2 раза и повторяем процедуру до тех пор, пока не наберем нужные 500 записей для показа.
Чаще всего этого простого алгоритма достаточно для быстрого получения данных. Но если у вас условия фильтрации таковы, что за весь период могут быть выбраны миллионы записей, а среди них вам нужно лишь несколько, например, вы в поле «Msg» события логов ищете определенную, редко встречаемую строку, то результат будет отдан не быстро.
Все ли так радужно? Увы не все… Можно сконструировать запрос так, что результат не получите долгое время, и завалите такими запросами сервера баз данных настолько, что они будут не в состоянии работать. Так как это используется внутри компании, то умышленный завал исключаем – таких людей мы легко вычисляем, остается только случайный завал. От случайного мы защищаемся таймаутом на запрос, через команду PostgreSQL «SET LOCAL statement_timeout TO ...» На суммарное время всех запросов к одной базе дается время 1200 секунд. На первый запрос к базе выставляется таймаут 1200 с, на второй – 1200 за вычетом потраченного времени на первый запрос, и т. д. Если не удалось уложиться, то возвращается ошибка с просьбой сузить условия фильтрации.
Попытки уйти на другие системы хранения логов
Мы делали серьезную попытку уйти на хранение логов в ClickHouse. Работали с движком MergeTree. Предварительные тесты прошли отлично, мы выкатили систему в предпродакшн. Вопросы со скоростью записи тут вообще не стояли – выигрыш по месту хранения был до 7 раз. Два узла ClickHouse обрабатывали данные, на каждом было 20 ядер и 64 Гб памяти. К слову сказать, PostgreSQL в предпродакшн у нас был чуть поскромнее в требованиях — 8 ядер и 32 Гб памяти на сервер. Но как бы то ни было, уменьшение объема хранения в ClickHouse подкупало, мы были готовы даже простить некоторую деградацию запросов на чтение к ClickHouse по сравнению с PostgreSQL.
Как только число запросов к серверу ClickHouse на выбор данных становилось больше определенного числа, они резко замедлялись. Победить это мы не смогли. От ClickHouse пришлось отказаться. Возможно, причина замедления запросов на чтение была в том, что на таблице ClickHouse можно создать только один индекс. Многие профили запросов к логам не укладывались в этот индекс и чтение данных замедлялось.
Кроме ClickHouse делали еще прицел на ElasticSearch, заливали в него данные из одной базы логов PostgreSQL с продакшн ( ~4Тб ), он по месту хранения дал выигрыш по отношению к PostgreSQL около 15%, это маловато для того, чтобы сломя голову переводить логи на хранение в Elastic.
Автор: Алексей Терентьев
Комментарии (18)

tensor_sbis Автор
22.01.2018 16:56Elastic стал продвигаться примерно с 12 го года, мы же первую версию логов делали в начале 12 — го. Делали как прототип, а потом оказалось, что с него не так то просто слезть, когда у тебя уже все налажено и работает. У нас используется GrayLog2 для сбора логов с nginx, так что мы можем примерно сравнивать его и нашу систему.

Naglec
22.01.2018 17:14Т.е. фактически, вы рассказываете про свою систему и совершенно не факт, что оно удобнее/производительнее/дешевле, чем Elastic. Просто у вас так «исторически сложилось».
Мне кажется интереснее было бы сравнить ваше решение и какие-то другие, а не просто почитать про «исторически сложившееся».
Sleuthhound
22.01.2018 21:38Мне кажется интереснее было бы сравнить ваше решение и какие-то другие, а не просто почитать про «исторически сложившееся».
Почему не интересно?
К примеру на HL++ был доклад о БД в VK.com, как они взяли и переписали с нуля свою старую самописную БД на новую, узкоспециализированную и заточенную только под них. У них это свои исторические костыли, но тем не менее очень интересные и было любопытно послушать как они это делали.
Так и тут, пусть своя система, возможно не такая быстрая и не такая компактная как могло бы быть, но она работает и работает на Pg, что тоже показатель, причем очень неплохой в пользу PostgreSQL. Вроде написали, что были попытки уйти на ClickHouse и Elastic, но не получилось, не срослось, это тоже показатель.Shaz
22.01.2018 23:39Переписали с нуля и отключили все, что можно было отключить — это немного разные вещи. А так да, костыли и велосипеды в лучших традициях.
tensor_sbis Автор
23.01.2018 09:52Да, фактически для логов мы Postgres не используем как SQL базу. Но меня, например, поразило, что он существенно менее требователен к памяти, чем Elastic и ClickHouse.
tensor_sbis Автор
23.01.2018 09:44С Elastic нам все понравилось, он тратит меньше IOPs на запись, несколько побыстрее отдает ответ, но как написано в статье, не устроило, что он выигрыш по месту хранения дал маленький. Это основная причина почему мы на него пока стремимся перейти.
tensor_sbis Автор
23.01.2018 09:55Ошибся в сообщении, последнюю строку надо читать как: «Это основная причина почему мы на него пока НЕ стремимся перейти».
Shaz
23.01.2018 11:00Забавно это выходит. Работает быстрее, диски грузит меньше. Но из-за того что 32Тб текста это в любом случае 32Тб текста — оно «нинужно».
P.S. вобщем-то понятно почем декстопный СБИС рассыпается при любом удобном случае. Там видать с БД тоже работали как захочется а не как надо)tensor_sbis Автор
23.01.2018 15:01Там конечно не 32 Тб текста. 32Тб это данные + индексы. Индексы это где-то 50%. Т.е. на данные 16Тб. Из них текст составляет около 40% от других данных, т.е. на него тратится < 8Тб. Без текста трассировка была бы бесполезна, поиск по части текста довольно распространенное явление.

Olegas
23.01.2018 18:56И все равно не ясно почему не стремиться к системе, которая потребояет меньше дорогих ресурсов…
tensor_sbis Автор
24.01.2018 09:34В чем же меньше-то? Памяти и CPU подавай больше для того же Elastic, а размер для места хранения примерно одинаковый.
Olegas
24.01.2018 09:58Странно, но, кажется, в тексте статьи этого не сказано…
tensor_sbis Автор
25.01.2018 10:51Да, не написал, но в сравнении с CPU и RAM, место хранения все таки дороже стоит, поэтому сделал упор на нем.
tensor_sbis Автор
23.01.2018 10:19Насчет удобства в сравнении с другими системами — наша очевидно удобнее в плане интерфейса чем GrayLog2. Имею счастье пользоваться обеими.И наша существенно сильнее заточена на нашу специфику.
Olegas
23.01.2018 18:56Что мешает использовать свой интерфейс?
tensor_sbis Автор
24.01.2018 09:36Отсутствие серьезного выигрыша по месту хранения, устроило бы >50%. На самом деле мы еще не оставили до конца опыты с ClickHouse, но с ним мы все-таки несколько в тупике.
Shaz
24.01.2018 10:36Я вот не понимаю за счет какой магии вы хотите выиграть 50% от объема. Пишите тогда в файлики на zfs с дедупликацией, вдруг сработает.
Naglec
А PostgreSQL не сложнее поддерживать, чем Elastic? Перед разработкой решения на PostgreSQL каким образом принималось решение о хранилище?