
Примечание переводчика: это перевод заметки Ивана Пепельняка (Ivan Pepelnjak) о реальности и маркетинге вокруг SD-WAN. Название заметки «Software-defined WAN: Well-orchestrated duct tape?» происходит от следующего авторского твита:
@ecbanks everything can be solved with a right combination of NAT, GRE and PBR ;) Duct tapes of networking.
— Ivan Pepelnjak (@ioshints) 2 декабря 2010
Один из Программно-Определяемых Евангелистов объявил 2015 год Годом SD-WAN, и моя лента подкастов полна стартапов рассказывающих о прелестях их продукта в сравнении с бардаком традиционных маршрутизаторов. Здесь нужно задуматься: является ли SD-WAN действительно чем-то новым, или это старая песня на новый лад?
Прочтите первым делом
Не поймите этот пост неправильно. Я не против SD-WAN; в действительности, мне нравятся некоторые из тех идей, что я видел, а также простая и унифицированная архитектура некоторых продуктов.
Мне, однако, претит вся эта шумиха, замаскированная под техническую дискуссию, и я думаю, сетевым инженерам (в противопоставление маркетологам или менеджерам) следует подходить к SD-WAN как к любой другой технологии, стараться понять, как она действительно работает, каковы реальные проблемы и решения.
Что такое SD-WAN?
За неимением определения от серьёзного заведения, давайте обратимся к описанию с сайта Open Networking User Group (сообщество пользователей открытых сетей — прим. переводчика). Судя по их диаграммам, похоже, что SD-WAN — это что-то, что позволяет использовать публичный Интернет параллельно частной WAN для снижения затрат.
Постойте, что? Мы же годами делали именно это, и большинство наших заказчиков давно ушли от MPLS/VPN, используя такие решения как IPsec, DMVPN или даже MPLS/VPN-over-GRE-over-IPsec.
Гуру маркетинга, работающие на разработчиков SD-WAN, быстро вам объяснят, что то что они делают в корне отлично от описанного: то, что мы делали в прошлом — это гибридные WAN, а новинка — программно-определяема, использует центральный контроллер, и следовательно может не использовать сложного множества протоколов вроде IKE, IPsec, GRE, NHRP, NBAR, IP SLA, PBR и протоколов маршрутизации BGP или OSPF. Всё это заменяется неким проприетарным «секретным соусом» — своим у каждого стартапа (да, точно, эта мысль сразу успокаивает).
SD-WAN под капотом
В своей простейшей форме, SD-WAN (как его рекламируют многие стартапы) позволяет вам использовать две транспортных WAN для оптимальной передачи данных между конечными точками (end-to-end transport).
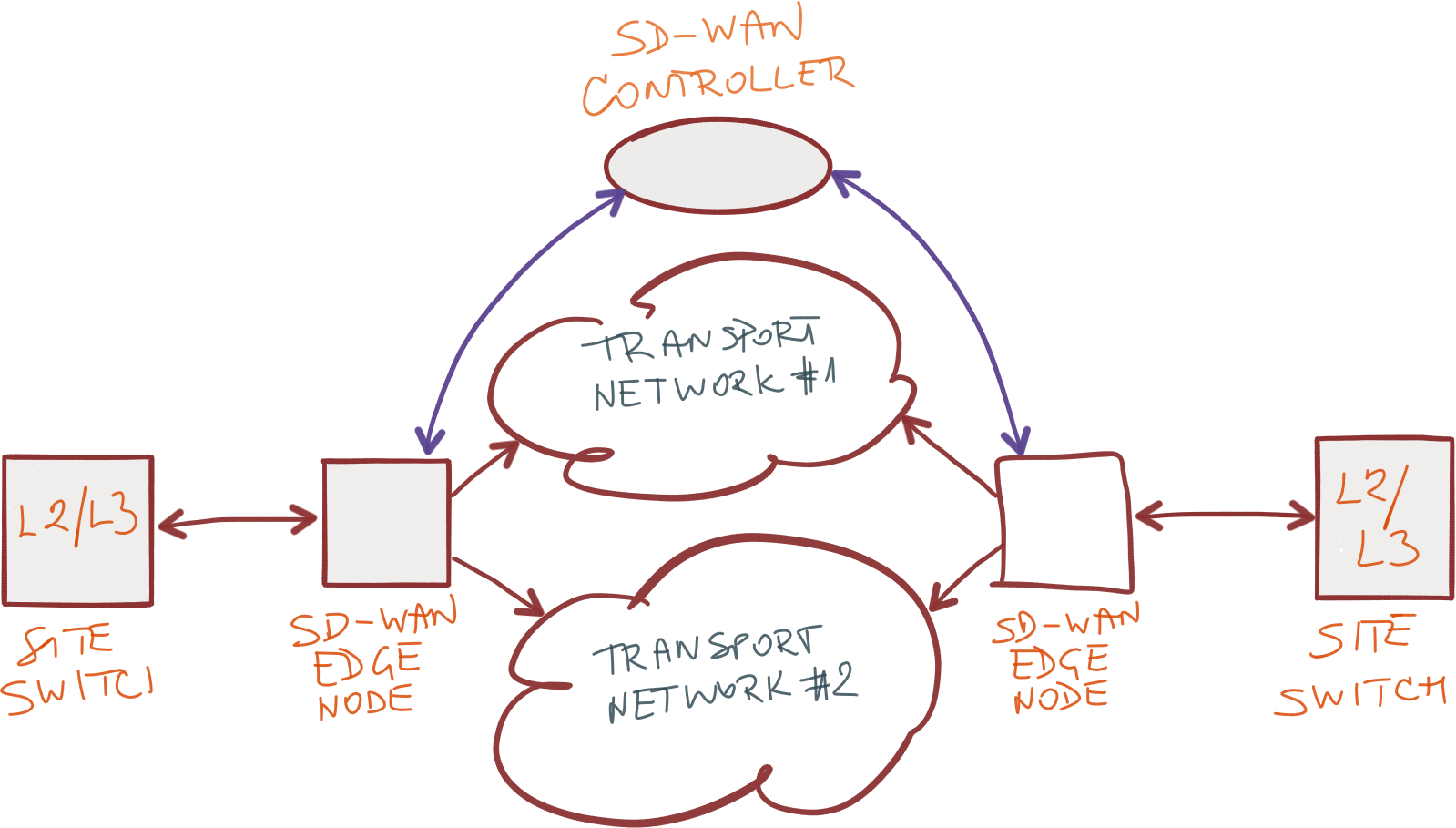
Давайте рассмотрим, что нужно сделать, чтобы это заработало.
Поскольку вы не можете сообщать (advertise) непубличные диапазоны адресов, используемые на ваших площадках, в транспортные сети (по крайней мере — не в публичный Интернет), каждое решение SD-WAN строит свою виртуальную (overlay) сеть. Не принципиально, что они там используют: GRE, VXLAN, IPsec tunnel mode или иную технологию инкапсуляции.
Некоторым заказчикам нужна прямая связность между всеми площадками, что требует полносвязной топологии туннелей или мульти-туннельной технологии вроде DMVPN. Детали не важны, и, в большинстве случаев, туннели устанавливаются автоматически (подобно тому, что делает Open vSwitch или реализации VXLAN).
И вы не хотите передавать ваш внутренний трафик через Интернет без шифрования, не так ли? Каждое решение SD-WAN должно решить задачу шифрования трафика (подсказка: для этого есть стандартное решение, называется IPsec) и проблему распространения ключей (т.е. IKE — в мультивендорном мире).
Прежде чем вы сможете начать использовать вашу виртуальную сеть SD-WAN, должны быть собраны сведения о топологии вашей сети. Давайте сейчас забудем про проблему интеграции пограничных устройств SD-WAN с традиционной L2/L3-сетью на площадке и сконцентрируемся на том, что происходит в облаке SD-WAN.
Когда пограничная нода SD-WAN включается, она должна подключится к контроллеру и зарегистрировать на нём свой внешний (WAN) IP-адрес. В сетях на базе стандартных протоколов для этого используют NHRP.
Далее, контроллеру нужно получить информацию о локальных префиксах доступных на каждой площадке. Используете ли вы протокол маршрутизации, REST API или некий проприетарный протокол для обмена префиксами не имеет большого значения… если только вас не заботит взаимодействие с продуктами других производителей, которого мы долго не увидим в мире SD-WAN.
Весело слушать людей, которые раньше пропагандировали преимущества мульти-вендорных сетей, рассказывающих про преимущества слабодокументированных проприетарных решений «потому что они гораздо лучше протоколов маршрутизации.»
После сбора информации о префиксах каждой площадки, контроллер решает, какие маршруты использовать и передаёт префиксы вместе с соответствующими адресами шлюзов транспортной сети (transport network next hops) на пограничные ноды SD-WAN. Не знаю что может быть более похожим на описание работы BGP Route Reflector (ну, разве что кроме той мелочи, что почти все разработчики SD-WAN используют проприетарные механизмы, но я думаю это уже ясно).
В идеальном случае, каждая площадка достижима с любой другой более чем через один аплинк, из которых должен быть выбран лучший. Выбор производится по метрикам достижимости или путём более сложных измерений — то что делают такие известные инструменты как BFD или IP SLA.
Наконец, когда качество линков известно, пользовательский трафик должен быть рассортирован по классам приложений (т.е. NBAR) и передан на целевую ноду SD-WAN через один из аплинков на основании предварительно заданной политики (правда, похоже на Policy Based Routing?)
Некоторые решения SD-WAN идут дальше простого PBR и реализуют интеллектуальное управление загрузкой, повтор передачи пакетов, или даже прямую коррекцию ошибок, чтобы наиболее эффективно задействовать доступную пропускную способность при сохранении допустимого качества end-to-end. В этих технологиях нет ничего нового: они много лет доступны в устройствах WAN-оптимизации (вы, может, помните людей, которые любили поболтать о том, насколько они плохи).
Выводы
В каждом решении SD-WAN приходится изобретать все велосипеды гибридных WAN — туннелирование, шифрование, обмен ключами, регистрацию нод, обмен маршрутной информацией, измерение качества канала, распознавание приложений и передачу пакетов на основе политик — по этому не нужно говорить о какой-то революционности этих решений (на ум сразу приходит RFC 1925, разделы 2.11 и 2.5).
Существует, однако, фундаментальная разница между мешаниной традиционных протоколов, насильно втиснутых в архитектуру гибридных WAN и SD-WAN — архитекторы продуктов SD-WAN не имеют проблем с унаследованными реализациями, не должны повторно использовать код, который был разработан для решения совсем иных задач, могут не использовать не оптимальные для задачи протоколы (например, зачем кому-либо использовать OSPF в DMVPN, если очевидно, что BGP гораздо лучше масштабируется?). Отдельные компоненты которые они используют, чтобы изобрести эти велосипеды, весьма хорошо прилажены друг к другу, потому что они изначально разрабатывались для совместного использования.
Архитектура большинства продуктов SD-WAN за счёт этого гораздо проще и легче конфигурируется, чем традиционные гибридные сети. Однако не следует забывать, что большинство из них использует проприетарные протоколы, что приводит к vendor lock-in.
dsx
А если использовать публичные диапазоны адресов, проблема сразу перестаёт существовать? Тогда зачем использовать непубличные адреса в таких случаях?
askbow Автор
Возможно, потому что публичных адресов (в IPv4) мало (в сравнении с числом устройств), поэтому внутри (корпоративных) сетей часто используют непубличные адреса RFC1918.
Если у организации достаточно публичных адресов для покрытия всех их нужд (в плане обмена данными между различными устройствами на разных площадках, в офисах, филиалах и что там ещё бывает), тогда действительно, такой задачи как сокрытие внутренней сети для техники туннелирования не стоит (хотя могут быть другие).
Возможно, кто-то именно так и поступает прямо сейчас.
dsx
Но ведь на смену устаревшему IPv4 уже пришёл IPv6. Адреса дают всем без разбору, только попроси. Зачем мучаться?
askbow Автор
Никто же и не мучается, вроде =)
С IPv6 есть проблема малой распространённости: люди не спешат внедрять, потому что мало кто внедряет (да, замкнутый круг). Прирост числа префиксов меньше 5000 в год и только-только достигло 23000 (ок.9000 автономных систем). Для сравнения, IPv4 Интернет, до выделения последней /8, рос примерно на 40000 в год, сейчас достиг >550000 префиксов (ок.50000 автономных систем).
[источник цифр: http://bgp.potaroo.net/v6/v6rpt.html ]
Т.е. если вы хотите какой-то значительной связности с другими людьми, то кроме IPv6 всё ещё необходимо поддерживать и IPv4. А значит, (в большинстве случаев) поддерживать непубличные адреса на площадках.
Другой аспект — наличие legacy устройств и приложений. Таких которые не поддерживают и, вероятно, никогда уже не будут поддерживать IPv6. Но им, зачем-то, нужна связь с такими же устройствами/приложениями в других офисах. Можно, конечно, пробовать применять трансляторы адресов и какие-нибудь прокси на уровне приложений. Но это сложнее (и костыльнее), чем, скажем, пробросить GRE между площадками.
Но даже после полного перехода на IPv6, механизмы туннелирования, скорее всего, останутся на своём месте просто по тому, что они решают и другие задачи, кроме маскировки «серой» сети.
dsx
IPv6 мало распространена среди пользователей домашнего интернета, в большинстве случаев это действительно так. Но я ни разу не слышал историй, чтобы кто-то очень хотел IPv6 транзит и не смог получить. Хотя такое, наверное, тоже возможно
Ну и на мой вкус гонять IPv4 внутри IPv6 для всякого легаси менее костыльно и более future proof. Туннели тут ортогональны, и лечить ими вездесущие «сеточки на 10» только откладывать решение реальной проблемы на будущее.
askbow Автор
Совершенно согласен. Все откладывают решение этой проблемы «на как-нибудь потом».
Интересно, какое число автономных систем в IPv6 станет критическим, после чего лавинообразно в него включится большинство существующих сетей?
dsx
Гугл рапортует, что 21.8% трафика в США пришло по IPv6. ? всех пользователей интернета в определённом регионе — это уже критическая масса для какой-то компании или ещё нет? Конечно, у этой ? есть и IPv4, но, видимо, по вселенскому заговору они приоретизируют IPv6.