
Дано

Про ГИС ЖКХ уже была подробная статья в блоге группы ЛАНИТ на Хабре. Если в двух словах ГИС ЖКХ – это первый в России федеральный портал о всей информации в ЖКХ, который запущен почти во всех регионах (в 2019 году присоединятся Москва, Питер и Севастополь). За последние три месяца в систему было загружено более 12 ТБ данных о домах, лицевых счетах, фактах оплаты и много-много еще чего, а всего в PostgreSQL сейчас лежит уже более 24 ТБ.
Проект архитектурно разделен на подсистемы. Каждой подсистеме выделена отдельная база данных. Всего таких баз сейчас около 60, они размещены на 11 виртуальных серверах. Некоторые подсистемы нагружены сильнее других, и у них базы по объему могут занимать 3-6 терабайт.
ЦУП, у нас проблема
Теперь немного подробнее расскажу о проблеме. Начну издалека: у нас код приложения и код миграций базы данных (под миграцией я понимаю перевод базы данных из одной ревизии в другую с выполнением всех необходимых SQL скриптов для этого) хранятся вместе в системе контроля версий. Это возможно благодаря использованию Liquibase (подробнее про Liquibase на проекте можно узнать из доклада Миши Балаяна на TechGuruDay в ЛАНИТ).
Теперь давайте представим себе выпуск версии. Когда данных всего пара терабайт или меньше и все таблицы в пределах сотни гигабайт, изменения (миграции) любых данных или изменения структуры в любых таблицах проходят быстро (обычно).
А теперь представим, что у нас данных уже пара десятков терабайт и появилось несколько таблиц по терабайту и больше (возможно, разбитых на партиции). В новой версии нам нужно провести миграцию по одной из этих таблиц или еще хуже сразу по всем. И при этом время регламентных работ увеличивать нельзя. И при этом такую же миграцию нужно провести и на тестовых базах данных, где железо слабее. И при этом нужно понять заранее, сколько в сумме все миграции по времени займут. Здесь и начинается проблема.
Сперва мы попробовали советы из официальной документации PostgreSQL (удаление индексов и FK перед массовой миграцией, пересоздание таблиц с нуля, использование copy, динамическое изменение конфига). Это дало эффект, но нам хотелось еще быстрее и удобнее (тут, конечно, дело субъективное – кому как удобно :–)). В результате мы реализовали параллельное выполнение массовых миграций, что увеличило скорость на многих кейсах в разы (а иногда и на порядок). Хотя на самом деле запускается параллельно несколько процессов, внутри команды у нас прижилось слово “многопоточка”.
«Многопоточка»

Основная идея такого подхода заключается в разделении большой таблицы на непересекающиеся диапазоны (например, функцией ntile) и выполнение SQL скрипта не сразу по всем данным, а параллельно по нескольким диапазонам. Каждый параллельный процесс забирает себе один диапазон, блокирует его и начинает выполнять SQL скрипт только для данных из этого диапазона. Как только скрипт отработал, мы опять ищем незаблокированный и еще не обработанный диапазон и повторяем операцию. Важно выбрать правильный ключ для разделения. Это должно быть проиндексированное поле с уникальными значениями. Если такого поля нет, можно использовать служебное поле ctid.
Первая версия «многопоточки» была реализована с помощью вспомогательной таблицы с диапазонами и функции взятия следующего диапазона. Требуемый SQL скрипт подставлялся в анонимную функцию и запускался в требуемом количестве сессий, обеспечивая параллельное выполнение.
-- Таблица UPDATE_INFO_STEPS используется для реализации обновления/заполнения
-- больших таблиц, выполнения сложных запросов обновления/заполнения
CREATE TABLE UPDATE_INFO_STEPS (
BEGIN_GUID varchar(36),
END_GUID varchar(36) NOT NULL,
STEP_NO int,
STATUS char(1),
BEGIN_UPD timestamp,
END_UPD timestamp,
ROWS_UPDATED int,
ROWS_UPDATED_TEXT varchar(30),
DISCR varchar(10)
);
ALTER TABLE UPDATE_INFO_STEPS ADD PRIMARY KEY(discr, step_no);
-- Функция FUNC_UPDATE_INFO_STEPS реализует ключевой функционал.
-- Возможность "брать" следующий интервал, если текущий занят.
CREATE OR REPLACE FUNCTION func_update_info_steps(
pStep_no int,
pDiscr varchar(10)
) RETURNS text AS
$BODY$
DECLARE
lResult text;
BEGIN
SELECT
'SUCCESS' INTO lResult
FROM
update_info_steps
WHERE
step_no = pStep_no
AND discr = pDiscr
AND status = 'N'
FOR UPDATE NOWAIT;
UPDATE
UPDATE_INFO_STEPS
SET
status = 'A',
begin_upd = now()
WHERE
step_no = pStep_no
AND discr = pDiscr
AND status = 'N';
return lResult;
EXCEPTION WHEN lock_not_available THEN
SELECT
'ERROR' INTO lResult;
return lResult;
END;
$BODY$
LANGUAGE PLPGSQL VOLATILE;
-- Пример использования (1 процесс на 1 сессию)
-- Шаг 1. Заполняем служебную таблицу интервалами для обработки.
DO
LANGUAGE PLPGSQL
$$
DECLARE
-- Указать количество обрабатываемых записей за одну итерацию
l_count int := 10000;
-- Подставить идентификатор
l_discr VARCHAR(10) := '<discr>';
BEGIN
INSERT INTO UPDATE_INFO_STEPS (
BEGIN_GUID, END_GUID, STEP_NO, STATUS,
DISCR
)
SELECT
min(guid) BEGIN_GUID,
max(guid) END_GUID,
RES2.STEP STEP_NO,
'N' :: char(1) STATUS,
l_discr DISCR
FROM
(
SELECT
guid,
floor(
(ROWNUM - 1) / l_count
) + 1 AS STEP
FROM
(
-- Подставить название колонки
SELECT
<column> AS GUID,
-- Подставить название колонки
row_number() over (
ORDER BY
<column>
) AS ROWNUM
FROM
-- Подставить схему и название таблицы
<schema>.<table_name>
ORDER BY
1 --
) RES1
) RES2
GROUP BY
RES2.step;
END;
$$;
-- Шаг 2. Используя служебную таблицу, выполняем скрипт UPDATE.
DO
LANGUAGE PLPGSQL
$$
DECLARE
cur record;
vCount int;
vCount_text varchar(30);
vCurStatus char(1);
vCurUpdDate date;
-- Подставить идентификатор
l_discr varchar(10) := '<discr>';
l_upd_res varchar(100);
BEGIN
FOR cur IN (
SELECT
*
FROM
UPDATE_INFO_STEPS
WHERE
status = 'N'
AND DISCR = l_discr
ORDER BY
step_no
) LOOP
vCount := 0;
-- Внутренняя транзакция обязательна!
SELECT
result INTO l_upd_res
FROM
dblink(
'<parameters>',
'SELECT FUNC_UPDATE_INFO_STEPS(' || cur.step_no
|| ','''
|| l_discr
|| ''')'
) AS T (result text);
IF l_upd_res = 'SUCCESS' THEN
-- Основной скрипт. В данной секции необходимо выполнять
-- требуемые действия по обновлению, вставке и тп.
-- Обязательное требование - использовать интервал
-- cur.begin_guid - cur.end_guid и dblink на "самого себя".
-- Указан примерный скрипт.
SELECT
dblink(
'<parameters>',
'UPDATE FOO set level = 42
WHERE id BETWEEN ''' || cur.begin_guid
|| ''' AND '''
|| cur.end_guid
|| ''''
) INTO vCount_text;
-- Конец основного скрипта.
SELECT
dblink(
'<parameters>',
'update UPDATE_INFO_STEPS
SET status = ''P'', end_upd = now(),
rows_updated_text = ''' || vCount_text || '''
WHERE step_no = ' || cur.step_no || '
AND discr = ''' || l_discr || ''''
) INTO l_upd_res;
END IF;
END LOOP;
END;
$$;
-- Мониторинг выполнения.
SELECT
SUM(CASE status WHEN 'P' THEN 1 ELSE 0 END) done,
SUM(CASE status WHEN 'A' THEN 1 ELSE 0 END) processing,
SUM(CASE status WHEN 'N' THEN 1 ELSE 0 END) LEFT_,
round(
SUM(CASE status WHEN 'P' THEN 1 ELSE 0 END):: numeric / COUNT(*)* 100 :: numeric,
2
) done_proc
FROM
UPDATE_INFO_STEPS
WHERE
discr = '<discr>';
Такой подход хоть и работал быстро, но требовал очень большого числа действий руками. И если деплой проходил в 3 часа ночи, ДБА должен был отловить момент выполнения «многопоточного» скрипта в Liquibase (который его выполнял, по сути, в одном процессе) и запустить руками еще несколько процессов для ускорения.
«МноGOпоточка 2.0»
Предыдущая версия «многопоточки» была неудобной в использовании. Поэтому мы сделали приложение на Go, которое автоматизирует процесс (можно сделать и на Python, например, да и на многих других языках).
Сперва мы разбиваем данные в изменяемой таблице на диапазоны. После этого во вспомогательную таблицу задач добавляем информацию о скрипте – его имя (уникальный идентификатор, например, имя задачи в Jira) и количество одновременно запускаемых процессов. Затем во вспомогательную таблицу скриптов добавляем текст SQL миграции, разбитый на диапазоны.
-- В целевой БД необходимо создать объекты, в которых будет храниться
-- конфигурация многопоточного обновления (pg_parallel_task)
-- и логи задания (pg_parallel_task_statements).
CREATE TABLE IF NOT EXISTS public.pg_parallel_task (
name text primary key, threads_count int not null DEFAULT 10,
comment text
);
COMMENT ON table public.pg_parallel_task
IS 'Задание параллельного выполнения';
COMMENT ON COLUMN public.pg_parallel_task.name
IS 'Уникальный идентификатор';
COMMENT ON COLUMN public.pg_parallel_task.threads_count
IS 'Количество одновременных потоков обработки. По умолчанию 10';
COMMENT ON COLUMN public.pg_parallel_task.comment
IS 'Комментарий';
CREATE TABLE IF NOT EXISTS public.pg_parallel_task_statements (
statement_id bigserial primary key,
task_name text not null references public.pg_parallel_task (name),
sql_statement text not null,
status text not null check (
status in (
'new', 'in progress', 'ok', 'error'
)
) DEFAULT 'new',
start_time timestamp without time zone,
elapsed_sec float(8),
rows_affected bigint,
err text
);
COMMENT ON table public.pg_parallel_task_statements
IS 'Операторы параллельного выполнения';
COMMENT ON COLUMN public.pg_parallel_task_statements.sql_statement
IS 'Полный текст выполняемого запроса';
COMMENT ON COLUMN public.pg_parallel_task_statements.status
IS 'Статус обработки текущего оператора. Один из new|in progress|ok|error';
COMMENT ON COLUMN public.pg_parallel_task_statements.start_time
IS 'Время начала выполнения текущего оператора';
COMMENT ON COLUMN public.pg_parallel_task_statements.elapsed_sec
IS 'Для выполненных операторов, затраченное время в секундах';
COMMENT ON COLUMN public.pg_parallel_task_statements.rows_affected
IS 'Для выполненных операторов, количество затронутных строк';
COMMENT ON COLUMN public.pg_parallel_task_statements.err
IS 'Для выполненных операторов, текст ошибки. NULL, если выполнение успешно.';
-- Основной скрипт
INSERT INTO PUBLIC.pg_parallel_task (NAME, threads_count)
VALUES ('JIRA-001', 10);
INSERT INTO PUBLIC.pg_parallel_task_statements (task_name, sql_statement)
SELECT
'JIRA-001' task_name,
FORMAT(
'UPDATE FOO SET level = 42 where id >= ''%s'' and id <= ''%s''',
MIN(d.id),
MAX(d.id)
) sql_statement
FROM
(
SELECT
id,
NTILE(10) OVER (
ORDER BY
id
) part
FROM
foo
) d
GROUP BY
d.part;
-- Конец основного скрипта
При деплое происходит вызов приложения на Go, которое считывает конфигурацию задачи и скрипты по этой задаче из вспомогательных таблиц и автоматически запускает скрипты с заданным числом параллельных процессов (worker’ов). После выполнения управление передается обратно в Liquibase.
<changeSet id="JIRA-001" author="soldatov">
<executeCommand os="Linux, Mac OS X" executable="./pgpar.sh">
<arg value="testdatabase"/><arg value="JIRA-001"/>
</executeCommand>
</changeSet>Приложение состоит из трех основных абстракций:
- task – загружает в память параметры миграции, количество процессов и все диапазоны, запускает “многопоточку” и поднимает Web–сервер для отслеживания прогресса выполнения;
- statement – представляет собой один диапазон выполняемой операции, также отвечает за изменение статуса выполнения диапазона, запись времени выполнения диапазона, количество строк в диапазоне и т.д.;
- worker – представляет собой один поток выполнения.
В методе task.do создается канал, в который отправляются все statements операции. На этом канале запускается указанное число worker’ов. Внутри worker’ов бесконечный цикл, он мультиплексирует на двух каналах: по которому получает statements и выполняет их, и пустой канал как сигнализатор? что надо завершиться. Как только пустой канал будет закрыт, worker завершит работу – это случается при ошибке в одном из worker’ов. Т.к. каналы в Go это thread–safe структура, то закрытием одного канала мы можем отменить все worker’ы разом. Когда statement в канале закончится, worker просто выйдет из цикла, и уменьшит общий для всех worker'ов счетчик. Так как task всегда знает, сколько worker’ов по нему работает, он просто ждет, когда этот счетчик обнулится и после этого завершается сам.
Плюшки
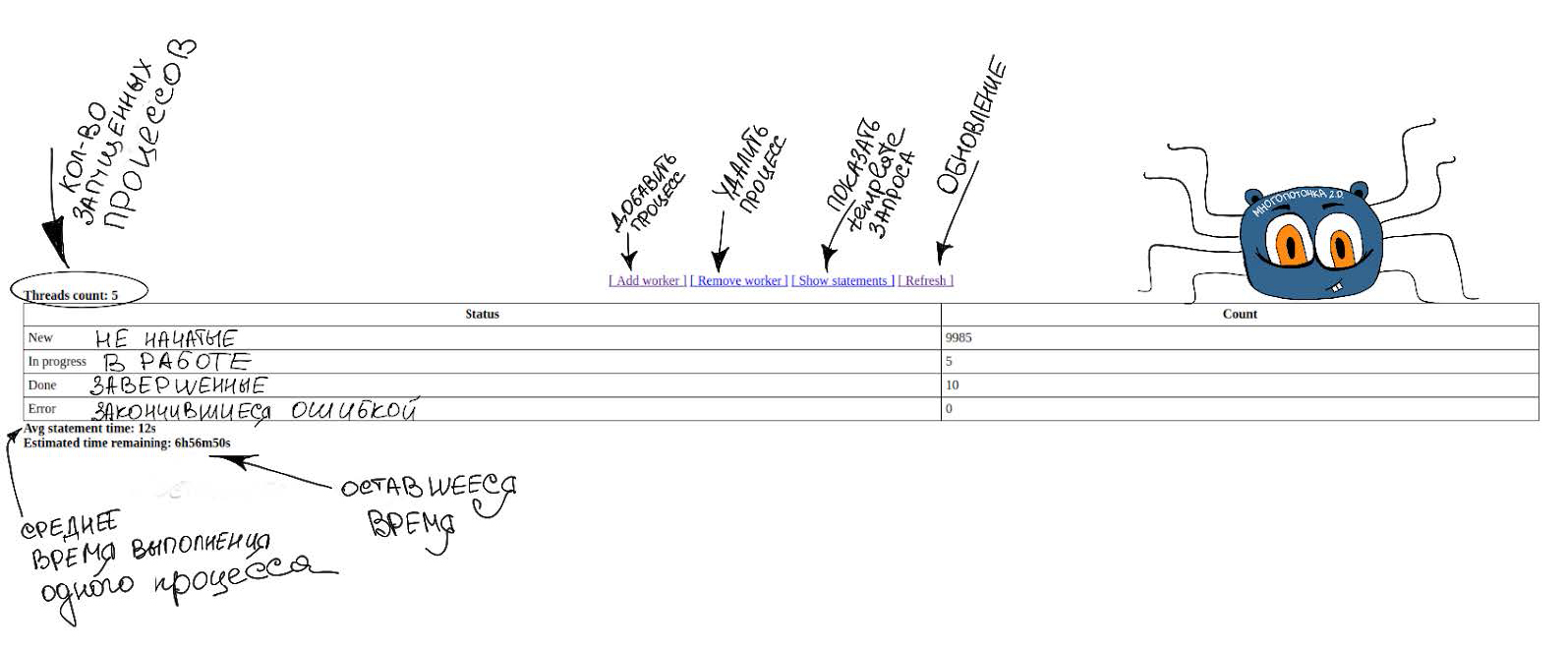
За счет такой реализации «многопоточки» появилось несколько интересных фич:
- Интеграция с Liquibase (вызываем с помощью тега executeCommand).
- простой веб–интерфейс, который появляется при запуске “многопоточки” и содержит всю информацию о ходе ее выполнения.
- Прогресс–бар (мы знаем, сколько обрабатывается один диапазон, сколько запущено параллельных процессов и сколько диапазонов еще осталось обработать – значит можем подсчитать время завершения).
- Динамическое изменение параллельных процессов (пока это мы делаем руками, но в дальнейшем хотим автоматизировать).
- Логирование информации по ходу выполнения многопоточных скриптов для возможности дальнейшего анализа.
- Можно выполнять блокирующие операции типа update, почти ничего не блокируя (если разбить табличку на очень маленькие диапазоны, все скрипты будут выполняться почти мгновенно).
- Есть обертка для вызова “многопоточки” прямо из БД.
Не плюшки
Основным недостатком является необходимость один раз пройти фулсканом по табличке для разбиения ее на диапазоны, если в качестве ключа используется текстовое поле, дата или uid. Если ключом для разбиения выбрано поле с последовательно увеличивающимися плотными значениями, то такой проблемы нет (мы заранее можем указать все диапазоны, просто задав требуемый шаг).
Ускоряемся в семь раз (тест на pgbench таблице)

Напоследок приведу пример сравнения по скорости выполнения операции UPDATE 500 000 000 строк без использования «многопоточки» и с ней. Простой UPDATE выполнялся 49 минут, тогда как «многопоточка» завершилась за семь минут.
SELECT count(1) FROM pgbench_accounts;
count
-------
500000000
(1 row)
SELECT pg_size_pretty(pg_total_relation_size('pgbench_accounts'));
pg_size_pretty
----------------
62 Gb
(1 row)
UPDATE pgbench_accounts
SET abalance = 42;
-- Время выполнения 49 минут
vacuum full analyze verbose pgbench_accounts;
INSERT INTO public.pg_parallel_tASk (name, threads_count) values ('JIRA-002', 25);
INSERT INTO public.pg_parallel_tASk_statements (tASk_name, sql_statement)
SELECT 'JIRA-002' tASk_name,
FORMAT('UPDATE pgbench_accounts
SET abalance = 42
WHERE aid >= ''%s'' AND aid <= ''%s'';',
MIN(d.aid), MAX(d.aid)) sql_statement
FROM (SELECT aid, ntile(25) over (order by aid) part
FROM pgbench_accounts) d
GROUP BY d.part;
-- Время выполнения 10 минут
-- Можно дробить по ctid, но получится неравномерно и нужно чтобы эту таблицу никто не изменял в процесе многопоточки
INSERT INTO public.pg_parallel_tASk_statements (tASk_name, sql_statement)
SELECT 'JIRA-002-ctid' tASk_name,
FORMAT('UPDATE pgbench_accounts
SET abalance = 45
WHERE (ctid::text::point)[0]::text > ''%s'' AND (ctid::text::point)[0]::text <= ''%s'';',
(d.min_ctid), (d.max_ctid)) sql_statement
FROM (
WITH max_ctid AS (
SELECT MAX((ctid::text::point)[0]::int) FROM pgbench_accounts)
SELECT generate_series - (SELECT max / 25 FROM max_ctid) AS min_ctid, generate_series AS max_ctid
FROM generate_series((SELECT max / 25 FROM max_ctid), (SELECT max FROM max_ctid), (SELECT max / 25 FROM max_ctid))) d;
-- Время выполнения 9 мин
./pgpar-linux-amd64 jdbc:postgresql://localhost:5432 soldatov password testdatabase JIRA-002
-- Время выполнения 7 минутP.S. Вам это надо, если:

Все инструменты хороши для определенных задач, и вот несколько таких для «многопоточки».
- UPDATE таблиц > 100 000 строк.
- UPDATE со сложной логикой, которую можно распараллелить (например, вызов функций для вычисления чего-либо).
- UPDATE без локов. За счет дробления на очень маленькие диапазоны и запуска небольшого числа процессов можно добиться мгновенной обработки каждого диапазона. Таким образом, блокировка тоже будет почти мгновенной.
- Параллельное выполнение changeSet’ов в Liquibase (например, VACUUM).
- Создание и заполнение данными новых полей в таблице.
- Сложные отчеты.
<changeSet author="soldatov" id="JIRA-002-01">
<sql>
<![CDATA[
INSERT INTO public.pg_parallel_task (name, threads_count)
VALUES ('JIRA-002', 5);
INSERT INTO public.pg_parallel_task_statements (task_name, sql_statement)
SELECT
'JIRA-002' task_name,
FORMAT(
'UPDATE pgbench_accounts
SET abalance = 42
WHERE filler IS NULL
AND aid >= ''%s'' AND aid <= ''%s'';',
MIN(d.aid),
MAX(d.aid)
) sql_statement
FROM
(
SELECT
aid,
ntile(10000) over (
order by
aid
) part
FROM
pgbench_accounts
WHERE
filler IS NULL
) d
GROUP BY
d.part;
]]>
</sql>
</changeSet>
<changeSet author="soldatov" id="JIRA-002-02">
<executeCommand os="Linux, Mac OS X" executable="./pgpar.sh">
<arg value="pgconfdb"/><arg value="JIRA-002"/>
</executeCommand>
</changeSet>
<changeSet author="soldatov" id="JIRA-003-01">
<sql>
<![CDATA[
INSERT INTO pg_parallel_task (name, threads_count)
VALUES ('JIRA-003', 2);
INSERT INTO pg_parallel_task_statements (task_name, sql_statement)
SELECT
'JIRA-003' task_name,
'VACUUM FULL ANALYZE pgbench_accounts;' sql_statement;
INSERT INTO pg_parallel_task_statements (task_name, sql_statement)
SELECT
'JIRA-003' task_name,
'VACUUM FULL ANALYZE pgbench_branches;' sql_statement;
]]>
</sql>
</changeSet>
<changeSet author="soldatov" id="JIRA-003-02">
<executeCommand os="Linux, Mac OS X" executable="./pgpar.sh">
<arg value="testdatabase"/><arg value="JIRA-003"/>
</executeCommand>
</changeSet>
-- SQL part
ALTER TABLE pgbench_accounts ADD COLUMN account_number text;
INSERT INTO public.pg_parallel_task (name, threads_count) VALUES ('JIRA-004', 5);
INSERT INTO public.pg_parallel_task_statements (task_name, sql_statement)
SELECT 'JIRA-004' task_name,
FORMAT('UPDATE pgbench_accounts
SET account_number = aid::text || filler
WHERE aid >= ''%s'' AND aid <= ''%s'';',
MIN(d.aid), MAX(d.aid)) sql_statement
FROM (SELECT aid,
ntile(50000) over (order by device_version_guid) part
FROM pgbench_accounts) d
GROUP BY d.part;
SELECT * FROM func_run_parallel_task('testdatabase','JIRA-004');
Комментарии (12)

apapacy
20.03.2018 20:03Как вы работаете с транзакциями при миграции?
Что происходит если один из процессов завершился с ошибкой, с откатом состояния к прошлому варианту, а остальные успешно?
sebres
20.03.2018 21:40А как вы думаете, что случится при миграции а то и откате (после ошибки) одной
большой, нет"гиганской" транзакцией, т.е. если без штук типа ихней "многопоточки"…
Даже умолчим про autovacuum, immutable states, пересбор индексов/статистик и т.п. прелести и сопутствующие эффекты на такой длинной транзакции и огромной базе...
Так мигрировать на горячую не есть камильфо...
Хотя если нужно таки всё неразрывно под DDL, то обычно морозят states (PITR, снапшоты и т.п.), многопоточно сливают изменения в новые таблички, а потом апдейтят/сливают bulk-ом в одной транзакции, и если все без остановки (aka hot), то сверху накатывают изменения из states(point_after — point_before), WAL по PITR и т.п… А так вообще очень сильно зависит от ситуации/требований (например, я утрирую, всё много сильно сложнее, если миграция базы длится неделю и размер diff-а для последующего обновления настолько огромен, что время накатывания оного снова приближается к той же неделе).
Ну и бэкапы никто еще не отменял...

EasyGrow Автор
21.03.2018 00:28Обычно, все процессы выполняются в своей отдельной транзакции. Соответственно, если один диапазон завершается с ошибкой, он помечается необработанным и в лог сохраняется описание ошибки, а «многопоточка» прерывается для анализа.
Дальше все зависит от выполняемой задачи, на сколько нам критично мигрировать все данные без ошибки. Часто можно пропустить диапазон с ошибкой и дождаться завершения миграции, затем точечно разобраться с ошибками и после их устранения перезапустить «многопоточку». При перезапусках «многопоточки» работу будут взяты только еще необработанные диапазоны. Например, такой сценарий возможен при миграции полей «заранее», когда приложение их еще не видит у себя.
Есть также вариант с созданием резервной копии таблицы до миграции, если нам нужна возможность откатиться к состоянию до «многопоточки». Дальше делаем или rename или восстанавливаем из нее данные.
В крайних случаях можно переключиться на стендбай с запаздыванием, где «многопоточки» еще не было или восстановиться из бэкапа и донакатить WALы.
Тут еще могут быть и другие варианты проведения миграции и восстановления, зависит от сценариев. На проде у нас критичных случаев, когда бы понадобились варианты 2 или 3 не было.apapacy
21.03.2018 03:01Ясно. Есть еще один вопрос если можно. Какая у Вас пиковая нагрузка по запросам в секунду select/insert на один инстанс PostgresSQL и какие ресурсы на один инстанс (количество ядер и оперативная память)?
EasyGrow Автор
21.03.2018 10:54Ядер более ста, оперативки не очень много (хватает, чтобы все индексы при построении влезали в maintenance_work_mem, например), данные распределены между SSD и SAS дисками в зависимости от профиля нагрузки. Подробно детали по нагрузке и конфигурации раскрыть не могу, к сожалению.
sebres
20.03.2018 23:16+1Немного оффтоп: а зачем так мигрировать вообще? В смысле, вы про "прозрачную миграцию" что-нибудь слышали?
Т.е. собственно процесс "миграции" происходит постепенно (on-the-fly, application-assisted), используя новые классы данных и небольшой background сценарий вызовов сверху:
типаwhile not ready: get(oldset) + set/alter-update(newset) + del(oldset).
Т.е. чтение реализуется в виде:
dataset GetSomeEntry(...) { // read dataset (from new-table) ... // if does not exists - try to read from old-table GetSomeEntry_MIG(...) ... // read child items: if (dataset.version < version.current) { //... use old api ... } else { //... use new api ... } ... }
Если язык реализации приложения — скриптовый, то оно инжектами/обёртками на стадии загрузки приложения легко реализуется...
Запись только новым API, в новом формате (в новые таблицы/структуры).
А остальное (типа выборки и т.д.) оборачивается view (если необходимо) и/или сливом bulk-ом в materialized/temporary-table в новом формате.
А так всё последовательно в два шага, например:
правкой всех forign constraint/trigger, переименованием таблицы
sometableвsometable_mig, созданием новойsometable_new, c начальным identity равнымmax(sometable_mig.id)и вьюхойsometable:
create view sometable as -- simulate new table using old table: select ... from sometable_mig union all select * from sometable_new
Ну или наоборот табличкой
sometableи viewsometable_migview, зависит от условий, например сколько в кодовой базе обращений кsometableне "обернутых" переменными, и/или соотношение insert/delete к select/join (хотя постгрес умеет updatable view и подобные конструкции позволяющие прозрачную миграцию)...
- по полному завершению процесса "миграции" (хоть через неделю — месяц), вторым шагом, удалением view
sometable, пустой таблицыsometable_mig, и конечным переименованием таблицыsometable_newвsometable.
И накатывания "чистой" кодовой базы, уже без инъекций типа
if (dataset.version < version.current) {...}
Transparent migration позволяет выкатить обновление приложения без миграции, полностью перелопатить просто гигантские базы, практически совсем без отрыва (т.е. hot), без длинных транзакций, с одним WAL (без плясок с бубном вокруг репликации, не трогая ее вовсе) и на 90% используя новый (готовый) API приложения (ну и обернутый практически теми же тестами, что и основной функционал).
Shurikh
21.03.2018 01:56Если есть логика в базе с джойнами/вьюхами/запросами сложнее, чем чтение атомарного значения по PK, при такой схеме миграции рано или поздно где-нибудь в нагруженном месте выстрелит запрос, у которого после очередного юниона съедет план настолько, что он не только сам перестанет возвращать данные за требуемое время, но ещё и всё остальное положит при достаточной нагрузке.
sebres
21.03.2018 11:08Да запросто… было так… лет десять назад.
Кстати, насчет "съедет план", у union как правило он много стабильнее (даже через вью).
Я даже ранее какой-нибудь "поехавший" на OR-IN план union-ами лечил.
Т.е. когда вот это вот:
select * from MT t ... where t.somefield in (select x.field1 from XT x where $criteria1) or t.otherfield in (select x.field2 from XT x where $criteria2) -- ready, 5172 ms
заменялось на:
select * from MT t ... where t.somefield in (select x.field1 from XT x where $criteria1) union all select * from MT t ... where t.otherfield in (select x.field2 from XT x where $criteria2) -- ready, 31 ms
Оно еще как-то понятно.
Но когда такое же случалось, просто на большой выборке с OR по нескольким полям (1 к 1, без full-scan, сложных join и т.д.)…
Какого спрашивается.
EasyGrow Автор
21.03.2018 11:11+1Сейчас работаем над переводом выпусков в онлайн. Для этого будем создавать слой АПИ на уровне БД (хранимки, версионные схемы, вьюхи). «Многопоточку» и в таком подходе вполне успешно можно применять будет.
dpogibenko
Поздравляю, вы переизобрели спринг-батч :)
EasyGrow Автор
К сожалению, Java я не знаю, поэтому если где-то неправильно понял особенности фреймворка, извиняюсь заранее.
На первый взгляд выглядит так, что оба фреймворка решают похожие по смыслу задачи, но немного в разных областях (мы больше интегрируемся с базой данных и Liquibase, в то время как Spring Batch ближе к коду приложения). Поэтому оба имеют право на жизнь и процветание :)
В разных языках программирования есть библиотеки/пакеты/модули, выполняющие одни и те же функции.
dpogibenko
В любом случае, советую почитать про архитектуру Spring Batch, думаю, что многие идеи вы сможете позаимствовать для вашей «многопоточки».