

Прилетела мне недавно задача дополнить функционал одной довольно старой програмки (исходного кода программы нет). По сути нужно было просто сканить периодически БД, анализировать информацию и на основе этого совершать рассылки. Вся сложность оказалась в том, что приложение работает с БД c-tree, написанной аж в 1984 году.
Порывшись на сайте производителя данной БД нашёл некий odbc драйвер, однако у меня никак не получалось его подключить. Многочисленные гугления так же не помогли нормально сконнектиться с базой и доставать данные. Позже было решено связаться с техподдержкой и попросить помощи у разработчиков данной базы, однако ребята честно признались что уже прошло 34 года, всё поменялось 100500 раз, нормальных драйверов для подключения на такое старьё у них нет и небось уже тех программистов в живых тоже нету, которые писали сие чудо.
Порывшись в файлах БД и изучив структуру, я понял, что каждая таблица в БД сохраняется в два файла с расширением *.dat и *.idx. Файл idx хранит информацию по id, индексам и т.д. для более быстрого поиска информации в базе. Файл dat содержит саму информацию, которая хранится в табличках.
Решено было парсить эти файлики самостоятельно и как-то добывать эту информацию. В качестве языка использовался Go, т.к. весь остальной проект написан на нём.
Я опишу только самый интересные моменты, с которыми я столкнулся при обработке данных, которые в основном затрагивают не сам язык Go, а именно алгоритмы вычислений и магию математики.
С ходу понять что где в файлах нереально, так как нормальной кодировки там нет, данные записываются в какие-то определённые биты и изначально больше похоже на мусорку данных.

Вдохновляющую фразочку я получил от клиента с небольшим описанием, почему так:”**** was a MS-DOS application running on 8086 processors and memory was scarce”.
Логика работы была таковой: назначаю в программе какие-то новые данные, смотрю какие файлы изменялись и затем пытаюсь выщемить биты данных, которые поменяли значения.
В процессе разработки я понял следующие важные правила, которые мне помогли разобраться быстрее:
- начало и конец файла (размер всегда разный) зарезервированы под табличные данные
- длина строки в таблице занимает всегда одно и то же количество байт
- вычисления проводятся в 256ричной системе
Время в расписании
В приложении создаётся расписание с интервалом в 15 минут (Например 12:15 – 14:45). Потыкав в разное время, нашёл область памяти, которая отвечает за часы. Я считываю данные из файла побайтово. Для времени используется 2 байта данных.
Каждый байт может содержать значение от 0 до 255. При добавлении в расписание 15 минут в первый байт добавляется число 15. Плюсуем ещё 15 минут и в байте уже число 30 и т.д.
Например у нас следующие значения:
[0] [245]
Как только значение превышает 255, в следующий байт добавляется 1, а в текущий записывается остаток.
245 + 15 = 260
260 – 256 = 4
Итого имеем значение в файле:
[1] [4]
А теперь внимание! Очень интересная логика. Если это диапазон с 0 минут до 45 минут в часе, то в байты добавляется по 15 минут. НО! Если это последние 15 минут в часе (с 45 до 60), то в байты добавляется число 55.
Получается что 1 час всегда равен числу 100. Если у нас 15 часов 45 минут, то в файле мы увидим такие данные:
[6] [9]
А теперь включаем немного магии и переводим значения из байтов в целое число:
6 * 256 + 9 = 1545
Если разделить это число на 100, то целая часть будет равна часам, а дробная – минутам:
1545/100 = 15.45
Кодяра:
data, err := ioutil.ReadFile(defaultPath + scheduleFileName)
if err != nil {
log.Printf("[Error] File %s not found: %v", defaultPath+scheduleFileName, err)
}
timeOffset1 := 98
timeOffset2 := 99
timeSize := 1
//first 1613 bytes reserved for table
//one record use 1598 bytes
//last 1600 bytes reserved for end of table
for position := 1613; position < (len(data) - 1600); position += 1598 {
...
timeInBytesPart1 := data[(position + timeOffset2):(position + timeOffset2 + timeSize)]
timeInBytesPart2 := data[(position + timeOffset1):(position + timeOffset1 + timeSize)]
totalBytes := (int(timeInBytesPart1[0]) * 256) + int(timeInBytesPart2[0])
hours := totalBytes / 100
minutes := totalBytes - hours*100
...
}
Дата в расписании
Логика работы вычисления значения из байт для дат такая же как и во времени. Байт заполняется до 255, затем обнуляется, а в следующий байт добавляется 1 и т.д. Только для даты уже было выделено не два, а четыре байта памяти. Видимо разработчики решили, что их приложение может прожить ещё несколько миллионов лет. Получается, что максимальное число, которое мы можем получить равно:
[255] [255] [255] [256]
256 * 256 * 256 * 256 + 256 * 256 * 256 + 256 * 256 + 256 = 4311810304
Эталонная стартовая дата в приложении равна 31 декабря 1849. Конкретную дату считаю путём добавления дней. Я изначально знаю, что AddDate из пакета time имеет ограничение и не сможет скушать 4311810304 дней, однако на ближайшие лет 200 хватит).
Проанализировав приличное количество файлов я нашёл три варианта расположения дат в памяти:
- считывание байт, конкретного участка памяти, необходимо проводить слева направо
- считывание байт, конкретного участка памяти, необходимо проводить справа налево
- между каждым «полезным байтом» данных вставляется нулевой байт. Например [1] [0] [101] [0][100] [0] [28]
Мне так и не удалось понять, зачем использовалась разная логика для расположения данных, но принцип подсчёта даты везде одинаковый, главное правильно доставать данные.
Кодяра:
func getDate(data []uint8) time.Time {
startDate := time.Date(1849, 12, 31, 0, 00, 00, 0, time.UTC)
var result int
for i := 0; i < len(data)-1; i++ {
var sqr = 1
for j := 0; j < i; j++ {
sqr = sqr * 256
}
result = result + (int(data[i]) * sqr)
}
return startDate.AddDate(0, 0, result)
}
Расписание доступности
У сотрудников есть расписание доступности. В день можно назначить до трёх интервалов времени. Например:
8:00 – 13:00
14:00 – 16:30
17:00 – 19:00
Расписание может быть назначено на любой день недели. Мне необходимо было сгенерировать расписание на ближайшие 3 месяца.
Вот примерная схема хранения данных в файле:
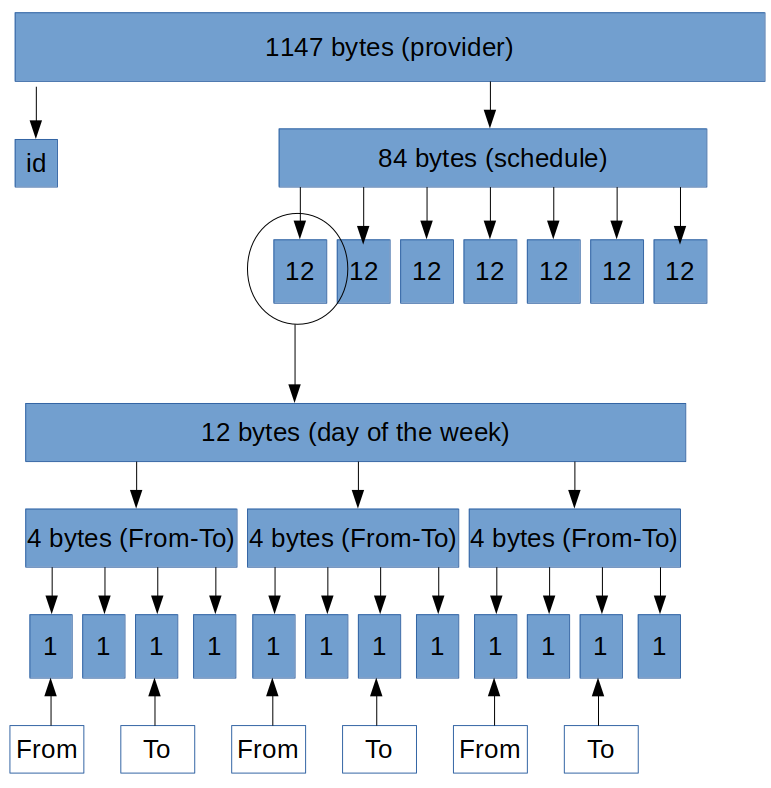
Я вырезаю из файла каждую запись по отдельности, затем смещаюсь на определённое количество байт в зависимости от дня недели и там уже обрабатываю время.
Кодяра:
type Schedule struct {
ProviderID string `json:"provider_id"`
Date time.Time `json:"date"`
DayStart string `json:"day_start"`
DayEnd string `json:"day_end"`
Breaks *ScheduleBreaks `json:"breaks"`
}
type SheduleBreaks []*cheduleBreak
type ScheduleBreak struct {
Start time.Time `json:"start"`
End time.Time `json:"end"`
}
func ScanSchedule(config Config) (schedules []Schedule, err error) {
dataFromFile, err := ioutil.ReadFile(config.DBPath + providersFileName)
if err != nil {
return schedules, err
}
scheduleOffset := 774
weeklyDayOffset := map[string]int{
"Sunday": 0,
"Monday": 12,
"Tuesday": 24,
"Wednesday": 36,
"Thursday": 48,
"Friday": 60,
"Saturday": 72,
}
//first 1158 bytes reserved for table
//one record with contact information use 1147 bytes
//last 4494 bytes reserved for end of table
for position := 1158; position < (len(dataFromFile) - 4494); position += 1147 {
id := getIDFromSliceByte(dataFromFile[position:(position + idSize)])
//if table border (id equal "255|255"), then finish parse file
if id == "255|255" {
break
}
position := position + scheduleOffset
date := time.Now()
//create schedule on 3 future month (90 days)
for dayNumber := 1; dayNumber < 90; dayNumber++ {
schedule := Schedule{}
offset := weeklyDayOffset[date.Weekday().String()]
from1, to1 := getScheduleTimeFromBytes((dataFromFile[(position + offset):(position + offset + 4)]), date)
from2, to2 := getScheduleTimeFromBytes((dataFromFile[(position + offset + 1):(position + offset + 4 + 1)]), date)
from3, to3 := getScheduleTimeFromBytes((dataFromFile[(position + offset + 2):(position + offset + 4 + 2)]), date)
//no schedule on this day
if from1.IsZero() {
continue
}
schedule.Date = time.Date(date.Year(), date.Month(), date.Day(), 0, 0, 0, 0, time.UTC)
schedule.DayStart = from1.Format(time.RFC3339)
switch {
case to3.IsZero() == false:
schedule.DayEnd = to3.Format(time.RFC3339)
case to2.IsZero() == false:
schedule.DayEnd = to2.Format(time.RFC3339)
case to1.IsZero() == false:
schedule.DayEnd = to1.Format(time.RFC3339)
}
if from2.IsZero() == false {
scheduleBreaks := ScheduleBreaks{}
scheduleBreak := ScheduleBreak{}
scheduleBreak.Start = to1
scheduleBreak.End = from2
scheduleBreaks = append(scheduleBreaks, &scheduleBreak)
if from3.IsZero() == false {
scheduleBreak.Start = to2
scheduleBreak.End = from3
scheduleBreaks = append(scheduleBreaks, &scheduleBreak)
}
schedule.Breaks = &scheduleBreaks
}
date = date.AddDate(0, 0, 1)
schedules = append(schedules, &schedule)
}
}
return schedules, err
}
//getScheduleTimeFromBytes calculate bytes in time range
func getScheduleTimeFromBytes(data []uint8, date time.Time) (from, to time.Time) {
totalTimeFrom := int(data[0])
totalTimeTo := int(data[3])
//no schedule
if totalTimeFrom == 0 && totalTimeTo == 0 {
return from, to
}
hoursFrom := totalTimeFrom / 4
hoursTo := totalTimeTo / 4
minutesFrom := (totalTimeFrom*25 - hoursFrom*100) * 6 / 10
minutesTo := (totalTimeTo*25 - hoursTo*100) * 6 / 10
from = time.Date(date.Year(), date.Month(), date.Day(), hoursFrom, minutesFrom, 0, 0, time.UTC)
to = time.Date(date.Year(), date.Month(), date.Day(), hoursTo, minutesTo, 0, 0, time.UTC)
return from, to
}
В целом хотелось просто поделиться знаниями о том, какими алгоритмами вычислений пользовались раньше.
Комментарии (51)

4eyes
20.03.2018 20:36+2вычисления проводятся в 256ричной системе
Очень режет глаз. Если не секрет, есть пара вопросов.
* программирование — это основная часть вашей профессиональной деятельности?
* если да, то есть ли базовые (академические) знания в C/C++, языке ассемблера, архитектуре ПК?
То, что вы так подробно описали про дату и время, сокращается до трёх предложений:
Время — 2-байтный int в формате HHMM
Дата — 4-байтный int, означающий число дней с (...).
Оба целых записываются в файл в порядке little-endian.khim
20.03.2018 21:20Да тут «не режет глаз»! Тут в качестве «открытий» преподносятся вещи, на которых и сегодня, по большому счёту, все операционки и весь интернет построен.
Статья на уровне: «мне тут потребовалось как-то починить автомобиль середины прошлого века, а ни один сервис его в починку не брал… я капот открыл — а там такая крутилка… и палка изогнутая, к ней поршни прикручены».
Кому это нужно? И зачем? Нет, я понимаю — для индувидуального развития оно, может, и неплохо. Но как-то уж очень много в последнее время на Хабре изобретателей велосипедов…
mxis Автор
20.03.2018 21:59В процессе решения задачи, я нашёл в нете с десяток форумов, где пытались распарсить файлики данной БД и понять как там всё это работает. Думаю эта статья будет полезна тем несчастным, которым придётся порыться в подобном Г
khim
20.03.2018 23:05Ну и зачем им вся эта «вода»? Описание формата, похожее на описание DBF было бы гораздо полезнее.
Как бы любой уважающий себя программист должен умерть вынуть структуру из файла, если её формат описан. То есть вот те три строки которые написал 4eyes — были бы весьма полезны, да. Но зачем же картинки рисовать, где показано как из отдельных байтов складывается струкураint16_t [7][3][2];? Это, как бы, должно быть достаточно очевидно читающему и так…
fukkit
21.03.2018 14:10+2вынуть структуру из файла, если её формат описан
Это ж рутина, тлен и — к индусам.
А вот в отсутствии знания получить и систематизировать опыт — весьма полезное умение. Имхо, автор — молодец. Надоест велосипедить — книжк почитать никогда не поздно.khim
21.03.2018 19:21
Тем не менее изобретению кривого велосипеда, это осуществляющего, посвящана почти вся статья. Специфики собственно c-tree — с гулькин нос, зато «вычисления в 256-ричной системе счисления» — на виду.вынуть структуру из файла, если её формат описан
Это ж рутина, тлен и — к индусам.
А ничего, что никакие «вычисления в 256-ричной систем» тут не нужны, а нужен разбор бинарных данных, для которого даже в стандарнтной библиотеке Go есть специальные компоненты, нет?
А вот в отсутствии знания получить и систематизировать опыт — весьма полезное умение.
Несомненно. До достаточно ли этого для того, чтобы писать статьи? Вы себе представляете статью на форуме краснодеревщиков от автора не знающего о том, что такое токарный станок и чем он отличается от фрезировального или на форуме любителей кройки и шитья от человека не знаючего чем потайной шов отличается от прямого смёточного шва?
Надоест велосипедить — книжк почитать никогда не поздно.
А после этого — и статью написать можно, да.
Задумайтесь вот над чем: я на Go не пишу, но, тем не менее, за 5 минут нашёл в стандартной библиотеке компонент посвящённый решению той задачи, которую тут навелосипедил автор статьи. Потому что я знаю какую задачу тут решают, знаю что для её решения должен быть компонент — и оп-па, он там таки есть.
Автор этого не сделал, несмотря на то, что у него, вроде как «весь остальной проект написан на нём». О чём это говорит?
Ну честное слово, домашняя работа пятикласника и аналитическая работа в политический журнал — разные жанры, они оцениваются по разному! Тут, правда, знаний чуть побольше, чем у пятикласника, да и Хабр — не вполне на уровне рецензируемых журналов, но… идея понятна, нет?
j_wayne
21.03.2018 17:07ИМХО для этого куда эффективнее задать вопрос на StackOverflow и ответить самому на него.
mxis Автор
20.03.2018 22:01На оба вопроса ответ — да.
Писака из меня не очень, согласен, но за критику спасибо, я учту
ZurgInq
21.03.2018 10:29+4У меня есть подозрение, что таких «базовых знаний» нет у подовляющего большинства веб программистов. И при этом формально, «программирование» — основная сфера профессиональной деятельности.

Yeah
20.03.2018 22:25Это она? http://www.faircom.com/v11-5-is-here
Пишут, что последняя версия выпущена в 2017-м. И есть какой-то web interface
mxis Автор
20.03.2018 22:28Всё верно. И интерфейс есть, и документации куча, и драйвера подключения… Только всё это к новым версиям, а не к такой старой, которой владею я.
4eyes
21.03.2018 14:41Писака нормальный, просто была интересна причина столь подробного изложения.
Было впечатление, что автор студент и только что открыл для себя порядок байт и представление целых чисел в памяти. В таком случае, вам есть что почитать, чтобы следующая подобная задача далась проще.
Или, что это не «оригинальное исследование», но вам хотелось разжевать представление целых для начинающих. В таком случае, любопытно, что вы не ограничились ссылками на википедию.
В любом случае, это не более, чем любопытство на тему: неужели разделение областей в программировании достигло той стадии, когда для успешной работы в какой-либо области, можно было не знать организации данных в памяти.
olegchir
21.03.2018 19:48> Было впечатление, что автор студент и только что открыл для себя порядок байт и представление целых чисел в памяти.
скорей всего, большинство современных веб-программистов ничего не знает ни о порядке байт, ни о представлении целых чисел в памяти — и это совершенно нормально. Для работы им это не нужно. Прямо скажем, это почти никому не нужно, кроме узкой касты системщиков.
Имхо просто супер, что автор самостоятельно открывает для себя целый новый мир. Может быть, кто-то такой же прочитает эту статью, подумает «а чем я хуже», и тоже рванётся это изучать.4eyes
21.03.2018 20:29Не хочу сказать, что это плохо, все когда-то были студентами, и действительно, для многих задач это не нужно. Это не хорошо, и не плохо, когда-то этот этап должен был настать. Для меня просто удивительно, что вот он уже тут.
Прямо скажем, это почти никому не нужно, кроме узкой касты системщиков.
- и геймдевщиков
- и сетевиков
- и десктопщиков
- и кодировщиков (видео, изображения)
- и бекендщиков (тех, кто получает данные по сети от мобильного приложения и от десктопа одновременно)
- и джаваскриптщиков*
* джаваскриптщикам это не нужно ровно до тех пор, пока они не начнут использовать какой-нибудь API, в котором timestamp — это int. С некоторых пор они обнаружат, что (time_stamp + 1 == time_stamp ), хотя (time_stamp * 2 != time_stamp ). Пример такого API — twitter.khim
21.03.2018 23:25На самом деле не нужно никаких API.
Простйший пример на JavaScript:
a = 9007199254740992; if (a + 1 === a) { // Пошли странные вещи }
Проблема в том, что вся шаткая пирамида надстроенная над этими байтами и битами — состоит из протекающих абстракций.
Так что обходиться без знания основ вы можете только до тех пор, пока результат разработки «тап-ляп и в продакшн» является нормой.
Однако мы потихоньку подбираемся к моменту, когда ошибки в софте будут непосредственно приводить к миллионным убыткам и потере человеческиз жизней.
Есть ощущение, что после этого старые отмазки что «вы заплатили за софт три копейки и, в случае чего, эти три копейки назад и получите» (что только и позволяет подходу «тап-ляп и в продакшн» существовать) — перестанут действовать. Как они не действуют во многих других областях (если от вашей банки с соком умрёт семья из трёх человек, то и производитель и продавец получат проблем куда на большую сумму, чем стоимость этой банки).
Возможно тогда подход «мне „всю эту фигню“ знать не нужно — мои ж поделки не всегда падают, а только через два раза на третий» станет несколько менее популярным.
Но, боюсь, подходы изменятся только когда люди пройдут через боль и кровь.

olartamonov
20.03.2018 22:46+2Каждый байт может содержать значение от 0 до 255
В статье содержится большое количество полезной информации.
ratijas
20.03.2018 22:56+1Ну come on, годная техническая статья новичка в области байтослерарства. Прокачается — будет что-то поинтереснее реверсить. Не стоит перебирать с сарказмом, так ведь и обломать можно.
olartamonov
21.03.2018 10:26+2От программиста обычно ожидается некоторая ясность мысли и умение обращаться с int16 без магии.

midday
21.03.2018 17:16+1Ой коммон. Этот чел даже уроки в школе прогуливал по переводу систем счисления. Он как-то в 4 байта умудрился запихать 4311810304. Как? Когда там 4294967296 комбинаций. 256^4. А из систем счисления переводят так:
255 * 256^3 + 255*256^2 + 255*256^1 + 255*256^0 = 4294967295
А за комменты снизу о деградации, карму слили мне. А пацану подняли. Вот она самодеградация хабра.4eyes
21.03.2018 21:12Думаю, это не деградация, а разделение труда.
Знаете, бывает глубокий экзистенциальный кризис, когда закрыл последний тег и задумался: в школе меня мучили алгеброй, в институте — вышкой, дискреткой, архитектурой ПК, а еще алгоритмами и структурами данных. И заставляли писать hello world в синем монстре Borland С-крест-крест. Оказалось, всё — тлен (кроме пчёл). Можно было идти работать после 9 класса и не тратить время в пустую.
Так вот сейчас, похоже, действительно можно работать после 9 класса. Без систем счисления и всего этого. И разрабатывать сайты при должном уровне опыта быстрее и качественнее тру-сишника. Говорю вам как один из любителей приплюснутого си, который написал для домашнего использования фронт-энд к консольной утилите на express js — я слабо пригоден к такой работе.
Да, в nvidia не возьмут, ну и пошла она, эта нвидия, как говорил один эксцентричный программист. Есть большие ниши, где нужны другие знания.khim
21.03.2018 23:37+1Так вот сейчас, похоже, действительно можно работать после 9 класса. Без систем счисления и всего этого. И разрабатывать сайты при должном уровне опыта быстрее и качественнее тру-сишника.
Тут скорее вопрос: а зачем вообще разрабатывать «по кругу» одни и те же сайты, умеющие, по большому счёту, то, что сайты умели ещё лет 20, от силы, 10 лет назад.
Вот что такого полезного научился за последние 10 лет делать Хабр, что оправдало бы несколько происшедших редизайнов?
У меня есть ощущение, что мы наблюдаем очередной дотком, когда люди выкидывают деньги на создание вещей, которые, в общем, никому особо и не нужны — что порождает повышенный спрос на программистов, такой, что даже те, кто решили «пойти работать после 9 класса забив на все основы» находят себе применение.

0xd34df00d
21.03.2018 23:47Так вот сейчас, похоже, действительно можно работать после 9 класса.
И, наверное, даже быть счастливее.
Была у меня возможность пойти работать, правда, после 11-го класса, правда, после физмат-школы и, правда, с этак 4-5 годами плюсов за спиной на тот момент, но я таки зачем-то пошёл в вуз. И вот пошёл, значит, и познакомился с математикой, с теорией групп там всякой, с прочей абстрактной алгеброй и понял, что я дно и тупой, писать тупой же код на плюсах при этом с течением времени стало уныло, и всё стало тленом. Потом я ещё стал углублять знакомство, познакомился с теорией типов, со всякими там идрисами, и писать на плюсах опердни стало совсем уныло, а от питона вообще скулы сводит и лучше увольте.
А мог бы сразу после 11-го класса зарабатывать под сотню килорублей, что для 2008 года было неплохо, и не париться с этим всем.
Apatic
22.03.2018 11:56зарабатывать под сотню килорублей, что для 2008 года было неплохо
Неплохо? Учитывая среднюю зп по России в 2008 году (17,5к) да, для одиннадцатиклассника «неплохо» :)0xd34df00d
22.03.2018 18:33География несколько дисконтирует эти цифры (я тогда в Дефолт-Сити жил), но да, это несколько осложняло правильный выбор.
Apatic
22.03.2018 18:58Да даже для Москвы) До сих пор средняя по Мск ниже, чем 100к. Понятно, что в IT зп выше, но все равно.
olartamonov
22.03.2018 21:52Так вот сейчас, похоже, действительно можно работать после 9 класса
Так и раньше можно было. Слесарь там, токарь второго разряда. Ну максимум в ПТУ немного подучиться.
Или вы считаете, что в 2018 году «делать вебсайты» — это что-то сильно более перспективное, чем точить болванки в 1988-м?
0xd34df00d
21.03.2018 23:42+1Ну, вообще говоря, не все байты восьмибитные.
MacIn
22.03.2018 00:22+1Сразу вспоминается старомодное «объем памяти — 2К восьмиразрядных слов» и т.п.

PastorGL
20.03.2018 23:25BTW, для разбора бинарных форматов существуют специализированные инструменты.
midday
21.03.2018 10:51-6Вот они современные программисты.
Грусть печаль. Вы в университете хоть учились?
Apatic
21.03.2018 12:56+24Ну прекратите. Что это за упражнения «кто больше унизит автора и скажет, что он недопрограммист»? К чему эта желчь? Комплексы что ли?
Я ставлю плюс статье просто хотя бы потому, что даже если это и вода и основы, то это техническая вода и технические основы. А не очередное пространное эссе-сочинение на тему «почему я не люблю HR» / «как нам обустроитьРоссиюIT» / «как я ненавижу 1С» / унылая статья ни о чем из корпоблога / etc, которыми нынче заполонен Хабр.
Человек столкнулся с технической проблемой и рассказал, как решил ее, выложил код и алгоритмы. Плохо решил ли, хорошо ли — все это можно сказать и обсудить корректно. Вместо этого ответ — потоки желчи и упражнения в «остроумии». Причем зачастую от людей, не разместивших ни одной статьи.Whuthering
21.03.2018 13:57+1Я понимаю и в целом поддерживаю ваше мнение, изложенное в комментарии (плюсик поставил), но также хочу отметить…
Причем зачастую от людей, не разместивших ни одной статьи.
… что "сперва добейся" и Ad Hominem в приличном обществе как-то не считаются нормальными доводами, которые стоит озвучивать.

Maccimo
21.03.2018 20:55Желчные комментарии лучше, чем отсутствие комментариев. Если бы не они, я бы эту статью и не увидел скорее всего. Сама статья воспринята читателями вполне положительно.
Главное, не быть излишне впечатлительным, иначе можно психануть и сжечь второй том.

MacIn
21.03.2018 20:18Очень интересная логика. Если это диапазон с 0 минут до 45 минут в часе, то в байты добавляется по 15 минут. НО! Если это последние 15 минут в часе (с 45 до 60), то в байты добавляется число 65.
Получается что 1 час всегда равен числу 100
Как ни силился, не смог понять, что имеется в виду. Гранулярность учета времени — 15 минут?
Первые 45 минут добавляется по 15 минут, т.е. по итогу будет то же — 45. Потом 65, что даст сумму 110, но тут сумма — всегда 100, как указано.4eyes
21.03.2018 20:30формат времени — HHMM, где HH — 2 цифры часов, MM — 2 цифры минут. 1145 = «11:45». 1145+20 = 1205.
MacIn
21.03.2018 20:51Ах, вот оно что… «Получается что 1 час всегда равен числу 100» мда…
Спасибо за перевод.khim
22.03.2018 00:01Могли бы в код посмотреть.
Там же ясно написано:
Откуда с одной стороны, становится ясно, что имел в виду автор, а с другой — как раз и порождает тот поток комментариев, что мы тут наблюдаем.hours := totalBytes / 100 minutes := totalBytes - hours*100
Почему, чёрт побери, не
hours := totalBytes / 100 minutes := totalBytes % 100
Это попытка «запутать противника»? До индусского кода — рукой подать. Я понимаю, если бы речь шла о каком-то экзотическом языке программирования, где остатка от деления нету… но в Go-то он есть! И в JavaScript есть. И в Basic есть… тогда зачем? И почему?
И так — почти вся статья…MacIn
22.03.2018 00:23Спасибо, но мне не очень интересно reverse-engineer'ить мысли автора и формат по коду. Я проглядел статью, чтобы получить представлеие о формате БД. Некоторе время назад приходилось разбираться с БД на основе b-tree из 90х, но там формат был сложнее — еще был файл блокировок.
Интересно, компилятор оптимизирует последовательные операции деления и получения остатка с учетом того, что div выдает сразу оба?MacIn
22.03.2018 00:29Да и то, что есть в этих кусках, есть и в статье:
Если разделить это число на 100, то целая часть будет равна часам, а дробная – минутам:
1545/100 = 15.45
Лично мне это не объяснило ни «Получается что 1 час всегда равен числу 100», ни про 65, ни комбинацию этих двух в одном абзаце.khim
22.03.2018 01:42Лично мне это не объяснило ни «Получается что 1 час всегда равен числу 100», ни про 65, ни комбинацию этих двух в одном абзаце.
«Мясник так видит»… чего вы хотите от человека, открывшего для себя «256-ричную систему счисления»? Хотя как описать тот формат, что в этом чуде изобрели строго формально — я даже не знаю… и главное, непонятно: зачем.
Потому что делить на 100 — как бы не сильно проще, чем делить на 60… есть подозрение что там у них общая процедура для времени и числ с десятичной фиксированной точкой… но так как этим всем автор статьи не игрался, то всё это осталось «за кадром»…
khim
22.03.2018 01:36Я проглядел статью, чтобы получить представлеие о формате БД.
А в статье и нет этой информации. Индексы (то есть, собственно, c-tree) проигнорированы, из строчек таблицы выцеплено крошечное подмножество… так-то, для того, для чего этот модуль делали — этого, наверное, и достаточно… но к более-менее полноценному описанию формата эта статья не подбирается даже и близко.
Akuma
Это как?
pda0
В качестве языка для современной программы, которая вычитала данные и которая ими потом пользовалась. (Т.е. старую DOS программу на go переписали.)
А вообще, «безумству храбрых поём мы песню». Т.е. вариант установить в виртуалку или DOSBox тот самый DOS, подцепиться к базе софтом того времени, склепать простенькую программу, которая сбросит все таблицы в csv даже не рассматривался. Ясно.
mxis Автор
Это не переписка старой программы, а надстройка с доп.функционалом над невероятно древнющим ПО, которое установлено в большом количестве мест и всех устраивает. Сканить базу приходится переодически
khim
Если вам для всего этого не приходится заводить эмулятор какого-нибудь Mac'а, на котором эмулируется PDP-11 (или, хуже того, PDP-10) то это так себе «древность». Вот компьютерное железо бывшее новинкой сразу после 2й мировой — это да.
mxis Автор
К счастью до такого не дошло)))