
Кейсы практического применения Больших данных
в компаниях финансового сектора
 Зачем эта статья?
Зачем эта статья?В данном обзоре рассматриваются случаи внедрения и применения Больших данных в реальной жизни на примере «живых» проектов. По некоторым, особенно интересным, во всех смыслах, кейсам осмелюсь дать свои комментарии.
Диапазон рассмотренных кейсов ограничивается примерами, представленными в открытом доступе на сайте компании Cloudera.
Что такое «Большие данные»
 Есть в технических кругах шутка, что «Большие данные» это данные, для обработки которых недостаточно Excel 2010 на мощном ноутбуке. То есть если для решения задачи вам надо оперировать 1 миллионом строк на листе и более или 16 тысяч столбцов и более, то поздравляем, ваша данные относятся к разряду «Больших».
Есть в технических кругах шутка, что «Большие данные» это данные, для обработки которых недостаточно Excel 2010 на мощном ноутбуке. То есть если для решения задачи вам надо оперировать 1 миллионом строк на листе и более или 16 тысяч столбцов и более, то поздравляем, ваша данные относятся к разряду «Больших».Среди множества более строгих определений приведем, например следующее: «Большие данные» — наборы данных, которые настолько объемны и сложны, что использование традиционных средств обработки невозможно. Термин обычно характеризует данные, над которыми применяются методы предиктивной аналитики или иные методы извлечения ценности из данных и редко соотносится только с объемом данных.
Определение Wikipedia: Больши?е да?нные (англ. big data) — обозначение структурированных и неструктурированных данных огромных объёмов и значительного многообразия, эффективно обрабатываемых горизонтально масштабируемыми (англ. scale-out) программными инструментами, появившимися в конце 2000-х годов и альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Аналитика Больших данных
То есть чтобы получить эффект от данных, их необходимо определенным образом обработать, проанализировать и выделить из этих данных ценную информацию, желательно предиктивного свойства (то есть другими словами попытаться заглянуть и предсказать будущее).
Анализ и выделение ценной информации из данных или просто «Аналитика Больших данных» реализуется посредством аналитических моделей.
Качество моделей или качество выявления зависимостей в имеющихся данных во много определяется количеством и разнообразием данных, на которых та или иная модель работает или «обучается»
Инфраструктура Больших данных. Технологическая платформа хранения и обработки данных
Если игнорировать исключения, то основное правило Аналитики Больших данных – тем больше и разнообразнее данные, тем лучше качество моделей. Количество переходит в качество. Остро встает вопрос роста технологических мощностей для хранения и обработки большого количества данных. Соответствующие мощности обеспечиваются сочетанием вычислительных кластеров и графических ускорителей GPU.
Инфраструктура Больших данных. Сбор и подготовка данных
Согласно книге «Big Data: A Revolution That Will Transform How We Live, Work, and Think» by Viktor Mayer-Schonberger, до 80% всех трудозатрат при реализации проектов Больших данных приходятся на инфраструктурные задачи по обеспечению технологической платформы, платформы, сбору и преобразованию данных, контролю качества данных. И лишь 20% — непосредственно на саму Аналитику, моделирование и машинное обучение.
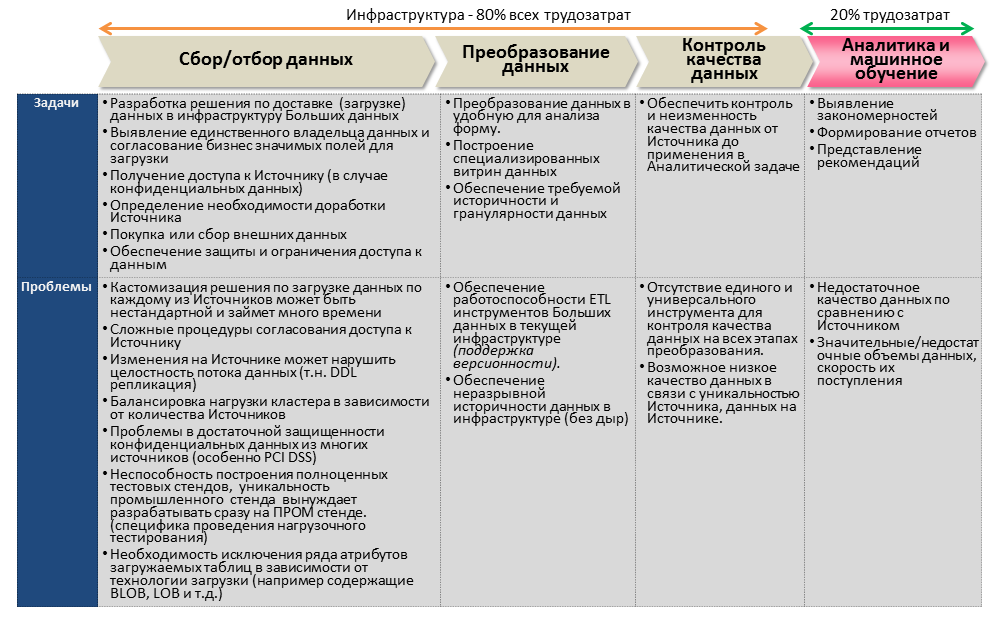
Сами кейсы применения Больших данных в компаниях финансового сектора


1. Intercontinental Exchange (ICE),
New York Stock Exchange (NYSE) – биржа
Ссылка на кейс
Ссылка на компанию
Описание компании
ICE – предоставляет крупнейшую площадку для торговли фьючерсами, акциями и опционами, предоставляет услуги клиринга и услуги по работе с данными. NYSE
Тема проекта: #Инфраструктура, #Комплаенс, #Управление данными.
Цель проекта:
Биржа генерирует в процессе своей работы огромные наборы данных, использование этих данных критично для оптимизации и удовлетворения постоянно растущих требований рынка и клиентов. Однажды наступил момент, когда существующая инфраструктура DataLake не позволяла своевременную обработку новых и существующих данных, была проблема разделения данных (data silos).
По итогам проекта:
Обновленная технологическая платформа (Cloudera Enterprise DataHub) обеспечивает внутренним и внешним пользователям доступ к более чем 20 петабайт данным в реальном времени (30 терабайт добавляется ежедневно), улучшив тем самым процесс мониторинг рыночной ситуации и контроль за соблюдением правил торговли ее членами (Compliance). Legacy база данных была заменена продуктом CDH Apache Impala, что позволило подписчикам на данные анализировать содержимое DataLake.
Комментарий:
Тема кейса интересная и несомненно востребованная. Множество площадок генерирует потоки данных в реальном времени, нуждающиеся в оперативной аналитике.
Кейс исключительно инфраструктурный, про аналитику не говорится ни слова. В описании кейса ничего не сказано о сроках проекта, сложностях по переходу на новые технологии. В целом интересно было бы изучить детали и познакомиться с участниками.

2. Cartao Elo – компания по выпуску и обслуживанию пластиковых карт в Бразилии
Ссылка на кейс
Ссылка на компанию
Описание компании:
Cartao Elo – компания, владеющая 11% от всех выпущенных пластиковых платежных карт в Бразилии, с количеством более одного миллиона транзакций в день.
Тема проекта: #Инфраструктура, #Маркетинг, #Развитие бизнеса.
Цель проекта:
Компания поставила цель вывести взаимоотношение с клиентом на уровень персонализированных предложений. Даже иметь возможность предугадывать пожелания клиентов на коротком промежутке времени, чтобы успеть предложить дополнительный продукт или услугу. Требуется наличие аналитической платформы способной обрабатывать в реальном времени данные из таких источников как данные геолокации о местоположении клиентов с его мобильных устройств, данных о погоде, пробках, социальных сетей, истории транзакций по платежным картам, маркетинговые кампании магазинов и ресторанов.
По итогам проекта:
Компания внедрила DataLake на платформе Cloudera, в котором, помимо данных о транзакциях, хранится прочая «неструктурированная» информация из социальных сетей, геолокаций мобильных устройств клиентов, погоды и пробках на дорогах. В DataLake хранится 7 тБ информации, и ежедневно добавляется до 10 гБ. Предоставляются персонализированные продуктовые предложения клиентам.
Комментарий:
Персональные продуктовые предложения – тема очень востребованная особенно на Российском рынке финансовых услуг ее многие разрабатывают. Непонятно как проекту удалось обеспечить обработку данных о транзакциях (да и социальных сетей и геолокации) в режиме real-time. Данные из основной системы учета транзакций должны мгновенно попасть в DataLake, в кейсе об этом скромно умалчивают, хотя это очень непросто, учитывая их объемы и требования к защите данных карточек. Также не раскрыта тема «этики больших данных», когда человеку предлагают продукт, он на основании этого предложения понимает что за ним «следят» и интуитивно отказывается от продукта просто из раздражения. А то может и вовсе сменить кредитку. Вывод, скорей всего в DataLake хранится 95% данных о транзакциях, 5% данные социальных сетей и т.д. и на основании этих данных строятся модели. В продуктовые предложения в реальном времени лично я не верю.

3. Банк Mandiri. Крупнейший банк Индонезии
Ссылка на кейс
Ссылка на компанию
Описание компании:
Bank Mandiri – крупнейший Банк в Индонезии.
Тема проекта: #Инфраструктура, #Маркетинг, #Развитие бизнеса.
Цель проекта:
Реализовать конкурентное преимущество за счет внедрения технологического решения, формирующего основанные на данных персонализированные продуктовые предложения клиентам. По итогам внедрения уменьшить общие расходы на IT инфраструктуру.
По итогам проекта:
Как написано в кейсе, после внедрения data-driven аналитического решения Cloudera расходы на IT инфраструктуру были снижены на 99%!.. Клиенты получают адресные продуктовые предложения, что позволяет повысить результаты cross sell и upsell кампаний продаж. Расходы на кампании значительно уменьшены, за счет более адресного моделирования. Масштаб больших данных решения – 13тБ.
Комментарий:
Кейс как бы намекает, что по итогам внедрения, компания полностью отказалась от инфраструктуры реляционных БД для моделирования продуктовых предложений. Даже уменьшил IT расходы аж на 99%.
Источниками данных для технологического решения по прежнему остаются 27 реляционных БД, профайлы клиентов, данные о транзакциях по пластиковым картам и (как ожидаемо) данные социальных сетей.

4. MasterCard. Международная платежная система
Ссылка на кейс
Ссылка на компанию
Описание компании:
MasterCard зарабатывает не только как платёжная система, объединяющая 22 тысячи финансовых учреждений в 210 странах мира, но и как поставщик данных для оценки финансовыми организациями (участниками платежной системы) кредитных рисков контрагентов (мерчантов) при рассмотрении их заявок на услуги эквайринга.
Тема проекта: #Мошенничество, #Управление данными.
Цель проекта:
Помочь своим клиентам, финансовым организациям выявлять контрагентов, ранее бывших неплатежеспособными и пытающихся вернуться в платежную систему через изменение своей identity (название, адрес или иные характеристики). У MasterCard создана для этих целей база данных MATCH (MasterCard Alert to Control High-risk Merchants). В этой БД хранится история о «сотнях миллионов» неблагонадежных организаций (fraudulent businesses) Участники платежной системы MasterCard (компании — эквайеры) ежемесячно делают до миллиона запросов к БД MATCH.
Конкурентное преимущество данного продукта определяется требованиями к небольшому времени ожидания результатов запроса и качеством обнаружения предмета запроса. С ростом объемов и сложности исторических данных, существующая реляционная СУБД перестала удовлетворять этим требованиям на фоне увеличения количества и качества клиентских запросов.
По итогам проекта:
Была внедрена платформа распределенного хранения и обработки данных (CDH), обеспечивающая динамическое масштабирование и управление загрузкой и сложностью алгоритмов поиска.
Комментарий:
Кейс интересный и практически востребован. Хорошо и продумано упоминается важная и трудоемкая составляющая по обеспечению инфраструктуры разграничения доступа и безопасности. Ничего не сказано про сроки перехода на новую платформу. В целом очень практически востребованный кейс.

5. Experian. Одно из трех крупнейших Кредитных бюро мира
Ссылка на кейс
Ссылка на компанию
Описание компании:
Experian – одна из трех крупнейших мировых компаний (т.н. «Большой тройки») кредитных бюро. Хранит и обрабатывает информацию о кредитной истории на ~1 миллиард заемщиков (физических и юридических лиц). Только в США кредитные досье на 235 млн. физических и 25 млн. юридических лиц.
Помимо услуг непосредственно кредитного скоринга, компания продает организациям услуги маркетинговой поддержки, онлайн доступа к кредитной истории заемщиков и защиту от мошенничества (fraud) и «identity theft».
Конкурентное преимущество услуг по маркетинговой поддержке (Experian Marketing Services, EMS) основано на основном активе компании – накопленных данных и физических и юридических заемщиках. EMS.
Тема проекта: #Инфраструктура, #Маркетинг, #Развитие бизнеса.
Цель проекта:
EMS помогает маркетологам получить уникальный доступ к своей целевой аудитории моделируя ее с использованием накопленных географических, демографических и социальных данных. Правильно применить при моделировании маркетинговых кампаний накопленные (большие) данные о заемщиках, включая такие real time данные как «последние совершенные покупки», «активность в социальных сетях» и т.д.
Для накопления и применения таких данных требуется технологическая платформа позволяющая быстро обработать, сохранить и провести анализ этих разнообразных данных.
По итогам проекта:
После нескольких месяцев исследований, выбор был сделан на платформенной разработке — Cross Channel Identity Resolution (CCIR) engine, основанной на технологии Hbase, нереляционной распределенной базе данных. Experian загружает данные в CCIR движок посредством ETL скриптов из многочисленных in-house мейнфрейм серверов и реляционных СУБД, таких как IBM DB2, Oracle, SQL Server, Sybase IQ.
На момент написания кейса, в Hive хранилось более 5 млрд строк данных, с перспективой 10-ти кратного роста в ближайшем будущем.
Комментарий:
Очень подкупает конкретика кейса, что большая редкость:
— количество нодов кластера (35),
— сроки внедрения проекта (<6 месяцев),
— архитектура решения представлена лаконично и грамотно:
Hadoop компоненты: HBase, Hive, Hue, MapReduce, Pig
Серверы кластера: HP DL380 (более чем коммодити)
Data Warehouse: IBM DB2
Data Marts: Oracle, SQL Server, Sybase IQ
— характеристики нагрузки (обрабатывается 100 млн. записей в час, рост производительности на 500%).
п.с.
Заставляет улыбнуться совет «быть терпеливым и много тренироваться» прежде чем приступать к промышленным разработкам решений на Hadoop/Hbase!
Очень удачно представленный кейс! Рекомендую к прочтению отдельно. Особенно много скрыто между строк для людей в теме!

6. Western Union. Лидер рынка международных денежных переводов
Ссылка на кейс
Ссылка на компанию
Описание компании:
Western Union – крупнейший оператор рынка международных денежных переводов. Изначально компания предоставляла услуги телеграфа (изобретатель азбуки Морзе – Самюэль Морзе стоял у истоков ее основания).
В рамках транзакций денежных переводов, компания получает данные как об отправителях, так и о получателях. В среднем, компания осуществляет 29 переводов в секунду, общим объемом 82 миллиарда долларов (по данным на 2013 год).
Тема проекта: #Инфраструктура. #Маркетинг, #Развитие бизнеса
Цель проекта:
За годы работы компания накопила большие объемы транзакционной информации, которые она планирует применять для повышения качества своего продукта и укрепления своего конкурентного преимущества на рынке.
Внедрить платформу по консолидации и обработке структурированных и неструктурированных данных из множества источников (Cloudera Enterprise Data Hub). Неструктурированные данные включают, в том числе такие экзотические для России, источники (по мнению автора) как «click stream data» (данные о серфинги клиента при открытии веб-сайта компании), «sentiment data» (natural language processing – анализ логов взаимодействия человека и чат-бота, данные опросов клиентов (surveys) о качестве продукта и обслуживания, данные социальных сетей и т.д.).
По итогам проекта:
Хаб данных создан и наполняется структурированными и неструктурированными данными через потоковую загрузку (Apache Flume), пакетную загрузку (Apache Sqoop) и старый добрый ETL (Informatica Big Data Edition).
Хаб данных (data hub) является тем самым репозиторием данных о клиенте, позволяя создавать выверенные и точные продуктовые предложения, например в Сан-Франциско, WU формирует отдельные целевые продуктовые предложения для представителей
— китайской культуры для клиентов отделений местного Чайна-таун,
— выходцев из Филиппин проживающих в районе Daly City
— Латиноамериканцев и мексиканцев из Mission District
Например, отправка предложения увязана с выгодным курсом обмена валют в странах происхождения для этих национальных групп по отношению к американскому доллару
Комментарий:
Упоминаются характеристики кластера – 64 ноды с перспективой увеличения до 100 нод (ноды – Cisco Unified Computing System Server), объем данных — 100тБ.
Отдельный акцент сделан на обеспечении безопасности и разграничения доступа пользователям (Apache Sentry и Kerberos). Что говорит о продуманной реализации и реальном практическом применении итогов работ.
В целом предположу, что в настоящее время проект не работает на полную мощность, идет фаза накопления данных и даже есть отдельные попытки разработки и применения аналитических моделей, но в целом возможности грамотно и системно применять при разработке моделей неструктурированные данные сильно преувеличены.

7. Transamerica. Группа компаний по страхованию жизни и управлению активами
Ссылка на кейс
Ссылка на компанию
Описание компании:
Transamerica – группа страховых и инвестиционных компаний. С головным офисом в Сан-Франциско.
Тема проекта: #Инфраструктура, #Маркетинг, #Развитие бизнеса
Цель проекта:
Ввиду разнообразия бизнесов, данные по клиенту могут присутствовать в учетных системах различных компаний группы, что иногда усложняет их аналитическую обработку.
Реализовать маркетинговую аналитическую платформу (Enterprise Marketing & Analytics Platform, EMAP), которая сможет хранить как собственные клиентские данные всех компаний группы так и данные о клиентах от сторонних поставщиков (например, все те же социальные сети). На базе этой EPAM платформы формировать выверенные продуктовые предложения.
По итогам проекта:
Как сказано в кейсе, в EPAM загружаются и анализируются следующие данные:
— собственные клиентские данные
— CRM данные о клиентах
— Данные о прошлых страховых выплатах (solicitation data)
— Данные о клиентах от сторонних партнеров (коммерческие данные).
— Логи с интернет портала компании
— Данные социальных медиа.
Комментарий:
— Данные загружаются только с использованием Informatica BDM, что подозрительно с учетом вариативности источников и разнообразия Архитектуры.
— Масштаб «больших данных» — 30тБ, что очень скромно (особенно с учетом упоминания данных о 210 миллионов клиентов в их распоряжении).
— Ничего не говорится о характеристиках кластера, сроках реализации проекта, возникших сложностях при внедрении.

8. mBank. 4-й по размеру активов банк Польши
Ссылка на компанию
Ссылка на кейс
Описание компании:
mBank, был основан в 1986, на сегодня имеет 5 млн. розничных и 20 тыс. корпоративных клиентов в Европе.
Тема проекта: #Инфраструктура, #.
Цель проекта:
Существующая IT инфраструктура не справлялась с все увеличивающимися объемами данных. Из-за задержек в интеграции и систематизации данных, дата сайентисты были вынуждены работать с данными в режиме Т-1 (т.е. за вчерашний день).
По итогам проекта:
Было построено хранилище данных на инфраструктуре платформы Cloudera, наполняемое ежедневно 300Гб информации из различных источников.
Источники данных:
• Плоские файлы систем источников (в основном OLTP систем)
• Oracle DB
• IBM MQ
Продолжительность интеграции данных в хранилище уменьшилась на 67%.
ETL Инструмент — Informatica
Комментарий:
Один из редких кейсов построения банковского хранилища на технологии Hadoop. Никаких лишних пафосных фраз «для акционеров» о масштабном снижении ТСО на инфраструктуру или захвата новых рынков за счет точечного анализа данных о клиентах. Прагматичный и правдоподобный кейс из реальной жизни.
Комментарии (5)

Stas911
09.04.2018 21:22Еще недавно кейс увидел интересный у www.credolab.com — ребята сделали кредитный скоринг на основании обезличенных данных мобильного телефона (как утверждается) — т.е прога собирает данные о количество контактов, время звонков и тд вектор штук из 100 параметров и выдает скоринг по кредиту.

Belkau77 Автор
10.04.2018 06:40А можно ссылку на описание самого кейса?
С кейсами на самом деле проблема… их не очень то много можно встретить именно описанных в виде кейса, более менее подробно…
sshikov
>По итогам проекта:
>Скорость интеграции данных в хранилище уменьшилась на 67%.
Т.е., стало еще хуже? :)
Belkau77 Автор
Спасибо :)
Это ошибка в моем переводе… Не «скорость» а «продолжительность» уменьшилась.
В тексте поправил