
DISCLAIMER: вы попались на clickbait. Очевидно, что TDD нельзя назвать ошибочным, но… Всегда есть какое-то но.
Содержание
Вступление
Первые шесть лет своей карьеры я фрилансил и участвовал в начальных этапах жизни мелких стартапов. В этих проектах не было тестов… Реально, ни единого.
В этих условиях ты обязан реализовать фичи на вчера. Поскольку требования рынка постоянно меняются, тесты устаревают ещё до того, как ты их заканчиваешь. И даже эти тесты можно создать только, если ты уверен в том, что именно ты хочешь создать, а это не всегда так. Занимаясь R&D ты вполне можешь не знать каков должен быть конечный результат. И даже достигая определённых успехов, ты не можешь быть уверен, что завтра рынок (а с ним и требования) не изменятся. В целом, существуют бизнес причины для экономии времени на тестировании.
Согласен, наша отрасль — это не только стартапы.
Около двух лет назад я устроился в достаточно большую аутсорсинг компанию, которая обслуживает клиентов любых размеров.
Во время разговоров на кухне/курилке, я обнаружил, что практически все согласны с тем, что юнит-тестирование и TDD это своего рода best practice. Но во всех проектах этой компании, в которых я участвовал, не было тестов. И нет, не я принимал такое решение. Конечно же, у нас есть проекты с отличным покрытием тестами, но они ещё и довольно сильно бюрократизированы.
Так в чём же проблема?
Почему все соглашаются, что TDD это хорошо, но никто не хочет его применять?
Может TDD ошибочно? – Нет!
Возможно, в нём нет никакой выгоды для бизнеса? – И опять, нет!
Может просто разработчики ленивы? – Да! Но это не причина.
Проблема в самих тестах!
Я понимаю, что звучит это странно, но я попытаюсь это доказать.
Тесты и есть проблема!
Исходя из этого исследования наименьшая общая удовлетворённость во всей экосистеме принадлежит именно инструментам для тестирования. Так было в 2016 и 2017 годах. Я не нашёл более ранних исследований, но это уже не очень важно.
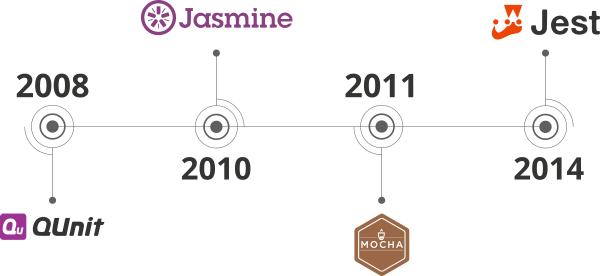
Немного истории
В 2008 году вышел один из первых JS фреймворков для тестирования (QUnit).
В 2010 появился Jasmine.
В 2011 – Mocha.
Первый релиз Jest, который я нашёл, был в 2014.
Для сравнения.
В 2010 зарелизился angular.js.
Ember появился в 2011.
React — 2013.
И так далее…
Во время написания этой статьи не был создан ни один JS фреймворк...
Во всяком случае, мной.

За этот же период времени мы увидели взлёт и падение grunt, потом gulp, после чего осознали всю мощь npm scripts и вышел в свет стабильный релиз webpack.

Всё поменялось за последние 10 лет. Всё кроме тестирования.
Небольшая викторина
Давайте проверим ваши знания. Что это за библиотеки/фреймворки?
1:
var hiddenBox = $("#banner-message");
$("#button-container button").on("click", function(event) {
hiddenBox.show();
});2:
@Component({
selector: 'app-heroes',
templateUrl: './heroes.component.html',
styleUrls: ['./heroes.component.css']
})
export class HeroesComponent{
hero: Hero = {
id: 1,
name: 'Windstorm'
};
constructor() { }
}3:
function Avatar(props) {
return (
<img className="Avatar"
src={props.user.avatarUrl}
alt={props.user.name}
/>
);
}Ответы:
Хорошо. Я уверен, что все ваши ответы были верны. Но что на счёт этих фреймворков для тестирования?
1:
var assert = require('assert');
describe('Array', function() {
describe('#indexOf()', function() {
it('should return -1 when the value is not present', function() {
assert.equal([1,2,3].indexOf(4), -1);
});
});
});2:
const sum = require('./sum');
test('adds 1 + 2 to equal 3', () => {
expect(sum(1, 2)).toBe(3);
});3:
test('timing test', function (t) {
t.plan(2);
t.equal(typeof Date.now, 'function');
var start = Date.now();
setTimeout(function () {
t.equal(Date.now() - start, 100);
}, 100);
});4:
let When2IsAddedTo2Expect4 =
Assert.AreEqual(4, 2+2)Ответы:
Вы могли угадать некоторые из них, но, в целом, они все очень похожи. Заметьте, что даже при смене языка, мало что меняется.
У нас есть, как минимум, 8 лет опыта юнит-тестирования в мире JavaScript'а.
Но мы ведь просто адаптировали уже существующее на тот момент. Юнит-тестирование, как мы его знаем, появилось намного раньше. Если взять релиз Test Anything Protocol (1987) как точку отсчёта, то мы используем текущие подходы дольше, чем я живу.
TDD ненамного моложе, если не старше. Всё это приводит нас к тому, что мы уже можем объективно оценить все плюсы и минусы.
Обзор TDD
Давайте вспомним, что такое TDD.
Разработка через тестирование (англ. test-driven development, TDD) — техника разработки программного обеспечения, которая основывается на повторении очень коротких циклов разработки: сначала пишется тест, покрывающий желаемое изменение, затем пишется код, который позволит пройти тест, и под конец проводится рефакторинг нового кода к соответствующим стандартам. (с) википедия

Но что это нам даёт?
Тесты — это формализованные требования
Это правда только частично.
TDD как практика была "переизобретена" Кентом Беком в 1999 году, в то время как Agile Manifesto был принят только 2 года спустя (в 2001). Я должен это подчеркнуть, что бы вы поняли, что TDD родился в "Золотой век" каскадной модели и этот факт определяет наиболее благоприятные условия и процессы, для которых он и был спроектирован. Очевидно, что TDD будет лучше всего работать именно в таких условиях.
Так что, если вы работаете в проекте, где:
- Требования ясны;
- Вы полностью их понимаете;
- Они стабильны и не будут часто меняться.
Вы можете создавать тесты, как формализацию требований.
Но что бы использовать существующие тесты таким же образом, необходимо выполнение и следующих пунктов тоже:
- В тестах нет ошибок;
- Они актуальны;
- И они покрывают почти все сценарии использования (не путать с покрытием кода).
Так что "Тесты — это формализованные требования" — правда только тогда, когда эти требования существуют до начала самой разработки, как в "модели Водопад" или проектах NASA, где "клиенты" это ученые и инженеры.
В определённых условиях это будет работать и с "Agile" процессами. Особенно, если что-нибудь по типу BDD будет использовано, но это уже совсем другая история.
TDD поощряет хорошую архитектуру
И опять это правда только частично.
TDD поощряет модульность, что необходимо, но недостаточно для хорошей архитектуры.
Качество архитектуры зависит от разработчиков. Опытные разработчики способны создавать отличный код, несмотря на использование или неиспользование юнит-тестирования.
С другой стороны, слабые разработчики будут создавать низкокачественный код, покрытый низкокачественными тестами, потому что создание хороших тестов — это своего рода искусство, как и само программирование.
Конечно, тесты как секс: "лучшие плохой, чем никакого вовсе". Но...
Этот тест никак не продвинет вас на пути к хорошему дизайну системы:
import { inject, TestBed } from '@angular/core/testing';
import { UploaderService } from './uploader.service';
describe('UploaderService', () => {
beforeEach(() => {
TestBed.configureTestingModule({
providers: [UploaderService],
});
});
it('should be created', inject([UploaderService], (service: UploaderService) => {
expect(service).toBeTruthy();
}));
});Потому, что он ничего не тестирует.
Обратите внимание, мы использовали 15 строк кода, чтобы ничего не протестировать.
Но и этот тест не сделает дизайн вашей системы лучше:
var IotSimulation = artifacts.require("./IotSimulation.sol");
var SmartAsset = artifacts.require("./SmartAsset.sol");
var BuySmartAsset = artifacts.require("./BuySmartAsset.sol");
var BigInt = require('big-integer');
contract('BuySmartAsset', function (accounts) {
it("Should sell asset", async () => {
var deliveryCity = "Lublin";
var extra = 1000; //
var gasPrice = 100000000000;
const smartAsset = await SmartAsset.deployed();
const iotSimulation = await IotSimulation.deployed();
const buySmartAsset = await BuySmartAsset.deployed()
const result = await smartAsset.createAsset(Date.now(), 200, "docUrl", 1, "email@email1.com", "Audi A8", "VIN02", "black", "2500", "car");
const smartAssetGeneratedId = result.logs[0].args.id.c[0];
await iotSimulation.generateIotOutput(smartAssetGeneratedId, 0);
await iotSimulation.generateIotAvailability(smartAssetGeneratedId, true);
await smartAsset.calculateAssetPrice(smartAssetGeneratedId);
const assetObjPrice = await smartAsset.getSmartAssetPrice(smartAssetGeneratedId);
assert.isAbove(parseInt(assetObjPrice), 0, 'price should be bigger than 0');
await smartAsset.makeOnSale(smartAssetGeneratedId);
var assetObj = await smartAsset.getAssetById.call(smartAssetGeneratedId);
assert.equal(assetObj[9], 3, 'state should be OnSale = position 3 in State enum list');
await smartAsset.makeOffSale(smartAssetGeneratedId);
assetObj = await smartAsset.getAssetById.call(smartAssetGeneratedId);
assert.equal(assetObj[9], 2, 'state should be PriceCalculated = position 2 in State enum list');
await smartAsset.makeOnSale(smartAssetGeneratedId);
const calculatedTotalPrice = await buySmartAsset.getTotalPrice.call(smartAssetGeneratedId, '112', '223');
await buySmartAsset.buyAsset(smartAssetGeneratedId, '112', '223', { from: accounts[1], value: BigInt(calculatedTotalPrice.toString()).add(BigInt(extra)) });
assetObj = await smartAsset.getAssetById.call(smartAssetGeneratedId);
assert.equal(assetObj[9], 0, 'state should be ManualDataAreEntered = position 0 in State enum list');
assert.equal(assetObj[10], accounts[1]);
const balanceBeforeWithdrawal = await web3.eth.getBalance(accounts[1]);
const gas = await buySmartAsset.withdrawPayments.estimateGas({ from: accounts[1] });
await buySmartAsset.withdrawPayments({ from: accounts[1], gasPrice: gasPrice });
const balanceAfterWithdrawal = await web3.eth.getBalance(accounts[1]);
var totalGas = gas * gasPrice;
assert.isOk((BigInt(balanceAfterWithdrawal.toString()).add(BigInt(totalGas))).eq(BigInt(balanceBeforeWithdrawal.toString()).add(BigInt(extra))));
})
})Наибольшая проблема этого теста — это изначальная кодовая база, но даже в таком случае его можно было существенно улучшить, даже без рефакторинга уже работающего проекта.
Вообще, влияние TDD на итоговую архитектуру приблизительно на том же уровне, что и влияние выбранной библиотеки/фреймворка, если не меньше (например, Nest, RxJs и MobX, по моему личному мнению, влияют существенно сильнее).
Но ни TDD, ни фреймворки не спасут от плохого кода и неудачных архитектурных решений.
Не существует серебряной пули.
TDD экономит время
А это уже зависит от многих факторов...
Давайте предположим, что:
- Все в проекте достаточно хорошо владеют выбранным тестовым инструментом, методологией TDD и лучшими практиками юнит-тестирования;
- И все понимают всё вышеперечисленное одинаково;
- А требования прозрачны и стабильны;
- К тому же, команда разработчиков понимает их точно так же, как и "Product Owner";
- А менеджмент готов решать все организационные проблемы, вызванные TDD (например, более длинный процесс ввода новых разработчиков в команду).
Даже в этом случае, вам необходимо сначала инвестировать время и усилия, что удлинит начальную фазу разработки и только спустя какое-то время вы получите выгоду, сократив необходимое время на исправление ошибок и поддержку продукта.
Конечно, второе может быть больше чем стартовая инвестиция и в этом случае выгода от TDD очевидна.
Так же в некоторых случаях вы сможете сэкономить время и на внедрении новой функциональности, поскольку тесты будут сразу выявлять непреднамеренные изменения.
Но в реальном мире, который очень динамичен, требования могут измениться и то, что было корректным поведением раньше, станет некорректным. В этом случае вам необходимо переписать тесты в связи с новыми реалиями. И, очевидно, приложить новые усилия, которые не окупятся сразу же.
Вы даже можете попасть в цикл подобного типа:
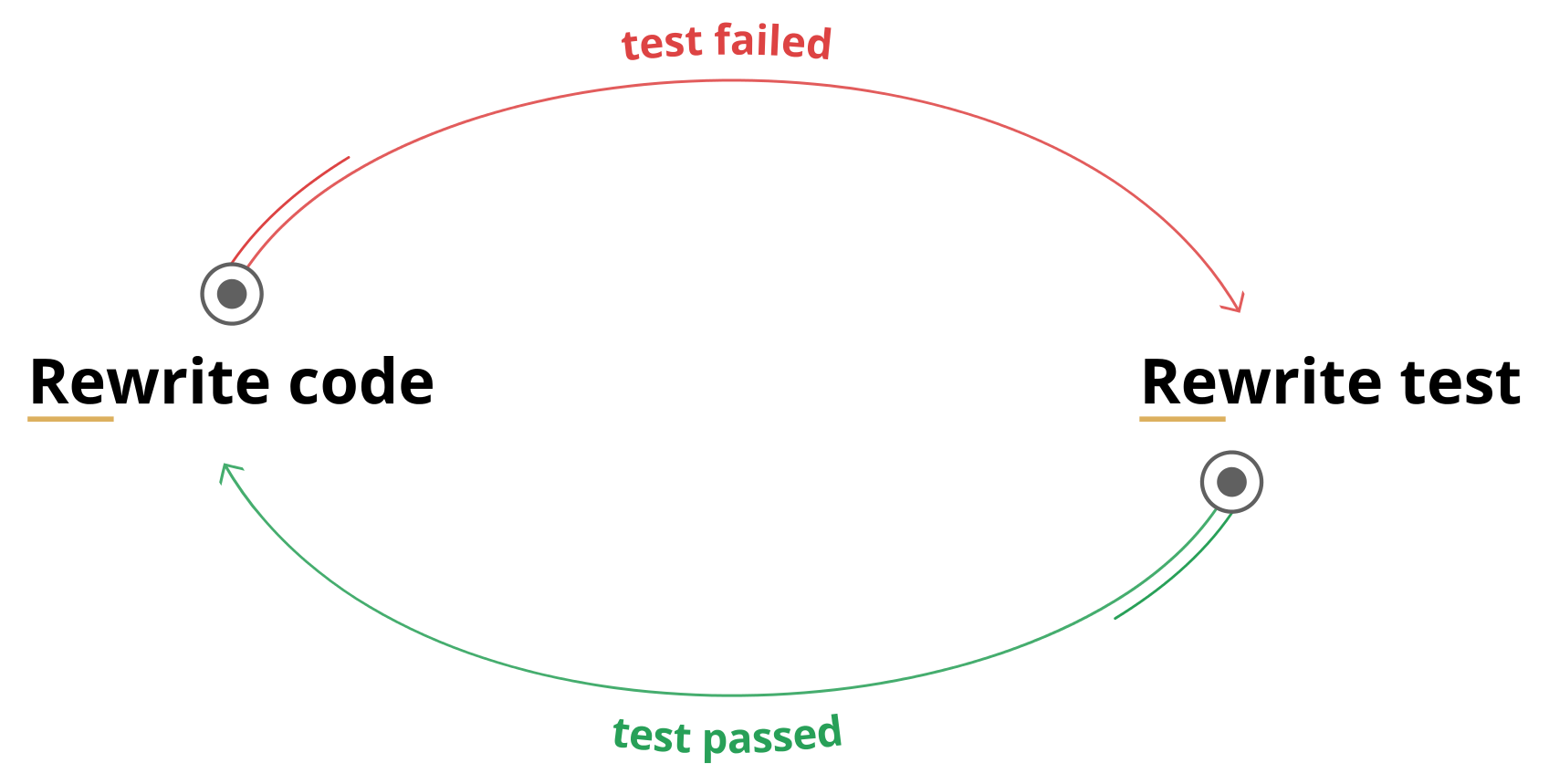
Ладно, этот цикл противоречит принципам TDD. Но следующий уже нет:

Попробуйте найти в них значимые различия.
Тесты — это лучшая документация
Нет. Они хороши в этом, но однозначно не лучшие.
Давайте взглянем на документацию angular:
Или react:
Как вы думаете, что в них общего? — Они обе построены на примерах кода. И даже более того. Все эти примеры можно легко запустить (angular использует StackBlitz, а react — CodePen), так что вы можете увидеть, что оно даёт на выходе и что произойдёт, если вы что-то измените.
Конечно же, там так же есть и простой текст, но это как комментарии в коде — они вам нужны только если вы что-то не поняли из самого кода.
Исполняемые примеры кода — вот лучшая документация!
Тесты близки к этому, но недостаточно.
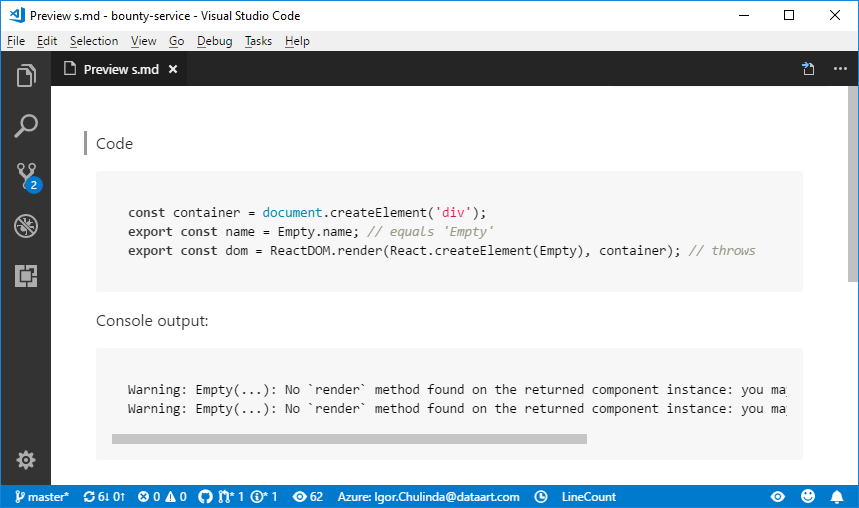
describe('ReactTypeScriptClass', function() {
beforeEach(function() {
container = document.createElement('div');
attachedListener = null;
renderedName = null;
});
it('preserves the name of the class for use in error messages', function() {
expect(Empty.name).toBe('Empty');
});
it('throws if no render function is defined', function() {
expect(() =>
expect(() =>
ReactDOM.render(React.createElement(Empty), container)
).toThrow()
).toWarnDev([
// A failed component renders twice in DEV
'Warning: Empty(...): No `render` method found on the returned ' +
'component instance: you may have forgotten to define `render`.',
'Warning: Empty(...): No `render` method found on the returned ' +
'component instance: you may have forgotten to define `render`.',
]);
});Это небольшой кусочек из реального теста в react. Мы можем выделить примеры кода из него:
container = document.createElement('div');
Empty.name;container = document.createElement('div');
ReactDOM.render(React.createElement(Empty), container);Всё остальное это вручную написанный инфраструктурный код.
Давайте будем честными, пример теста выше намного менее читабельный чем настоящая документация. И проблема не в этом конкретном тесте — я уверен, что ребят из facebook знают, как писать хороший код и хорошие тесты :) Весь этот мусор из инструментов тестирования и assertion библиотек, как it, describe, test, to.be.true просто захламляет ваши тесты.
Кстати, есть библиотека, которая называется tape с минималистичным API, потому что любой тест можно переписать, используя толькоequal/deepEqual, а думать в этих терминах это в целом хорошая практика для юнит-тестирования. Но даже тестам дляtapeещё очень далеко до просто исполняемых примеров кода.
Но стоит заметить, что тесты всё ещё вполне пригодны для использования в качестве документации. У них действительно ниже вероятность быть устаревшими, а наше сознание просто выкидывает лишнее, когда мы их читаем. Если мы попробуем визуализировать то, во что превращается тест в нашей голове, то это будет выглядеть приблизительно так:
Как вы видите, это уже намного ближе к реальной доке, чем изначальный тест.
Немного выводов
- Тесты — это формализованные требования если они стабильны;
- TDD поощряет хорошую архитектуру если разработчики достаточно квалифицированы;
- TDD экономит время если вы его вложите сначала;
- Тесты — это лучшая документация если нет других исполняемых примеров кода.
Значит TDD всё-таки ошибочно? — Нет, TDD не ошибочно.
Оно указывает правильно направление и поднимает важные вопросы. Мы просто должны переосмыслить и изменить способ его применения.
В чём же решение?
Не воспринимайте TDD как "серебряную пулю".
Не воспринимайте его даже как процесс по типу Agile, например.
Вместо этого сфокусируйтесь на его реальных сильных сторонах:
- Предотвращение непреднамеренных изменений, другими словами фиксирование существующего поведения как своего рода 'базовой линии' (англ. термин 'baseline' нам ещё пригодится);
- Использование примеров из документации, как тестов.
Думайте о юнит-тестировании как о инструменте разработчика. Как линтер или компилятор, например.
Вы не будете спрашивать у Product Owner'а разрешения на использование линтера — вы просто будете его использовать.
Когда-нибудь это станет реальностью и для юнит-тестирования. Когда необходимые для TDD усилия будут на уровне использования тайпчекера или бандлера. Но до этого момента, просто минимизируйте свои затраты, создавая тесты максимально похожими на исполняемые примеры и используйте их как текущий baseline состояния вашего проекта.
Я понимаю, что это будет сложно, особенно учитывая тот факт, что большинство популярных инструментов спроектированы для других целей.
Правда, я создал один такой, беря во внимание все вышеописанные проблемы. Он называется

Базовая концепция очень проста. Пишите код:
export function sampleFn(a: any, b: any) {
return a + b + b + a;
}И просто используйте его в вашем тесте:
import { sampleFn } from './index';
export = {
values: [
sampleFn(1, 1),
sampleFn(1000000, 1000000),
sampleFn('abc', 'cba'),
sampleFn(1, 'abc'),
sampleFn('abc', 1),
new Promise(resolve => resolve(sampleFn('async value', 1))),
],
};NOTE: тест, конечно же, очень синтетический — просто для демонстрации.
Потом выполняете команду baset test и получаете временный baseline:
{
"values": [
4,
4000000,
"abccbacbaabc",
"1abcabc1",
"abc11abc",
"async value11async value"
]
}Если значения верны, выполняете baset accept и коммитите созданный baseline в ваш репозиторий.
Все последующие прогонки тестов буду сравнивать существующий baseline со значениями, экспортированными из ваших тестов. Если они отличаются, тест провален, иначе — пройден.
Если требования изменились, просто измените код, прогоните тесты и примите новый baseline.
Этот инструмент всё ещё оберегает вас от непреднамеренных изменений, при этом требует минимальных усилий. Всё что вам нужно, это просто написать исполняемый пример кода, который, к тому же, является основой хорошей документации.
Несколько примеров
Использование с react. Вот этот тест:
import * as React from 'react';
import { jsxFn } from './index';
export const value = (
<div>
{jsxFn('s', 's')}
{jsxFn('abc', 'cba')}
{jsxFn('s', 'abc')}
{jsxFn('abc', 's')}
</div>
);создаст такой .md файл как baseline:
exports.value:
<div data-reactroot="">
<div class="cssCalss">
ss
</div>
<div class="cssCalss">
abccba
</div>
<div class="cssCalss">
sabc
</div>
<div class="cssCalss">
abcs
</div>
</div>Или с pixi.js:
import 'pixi.js';
interface IResourceDictionary {
[index: string]: PIXI.loaders.Resource;
}
const ASSETS = './assets/assets.json';
const RADAR_GREEN = 'Light_green';
const getSprite = async () => {
await new Promise(resolve => PIXI.loader
.add(ASSETS)
.load(resolve));
return new PIXI.Sprite(PIXI.utils.TextureCache[RADAR_GREEN]);
};
export const sprite = getSprite();Этот тест создаст такой baseline:
exports.sprite:

Немного про планы
Я обязан сказать, что этот инструмент ещё на очень ранней стадии разработки и впереди ещё очень много нововведений, например:
- Watch/Workflow mode
- TAP compatibility
- Git acceptance strategy
- VS Code extension
- … и, как минимум, 24 других.
Только около 40% от запланированного было реализовано. Но вся базовая функциональность уже работает, так что можете попробовать поиграться с ней. Может быть вам даже понравится, кто знает?
Комментарии (78)

zloddey
11.04.2018 21:57А, прикольно. Чувак переизобрёл Approval Testing. В целом подход неплох как дополнение к остальным инструментам, но свои ограничения есть и у него. Стоит только просочиться недетерминированности в тестируемый код — и прощай, красота! Придётся точно так же обкладывать код тестов "инфраструктурными" костылями для приведения результата к приемлемому виду.
Простеший пример: как протестировать банальный
random(a, b)? С классическими юнит-тестами мы можем, к примеру, сделать проверки на то, что результат лежит междуaиb, а также что при нескольких вызовах подряд получаются разные результаты. Эти тесты будут работать стабильно. А вариант "записали результат один раз, затем сравниваем следующие результаты с ним" уже не будет работать, потому что честный рандом должен возвращать совсем другие значения.
Но статье поставил плюс. Если разработчики будут уметь использовать разные типы автотестов наиболее подходящим образом, это будет хорошо.

Igmat Автор
12.04.2018 01:13Тут есть два момента:
- Сейчас действительно сложно тестить не детерминированные вещи — для этого ведётся работа над тасками #16 и #17, что бы дать возможность спокойно мокнуть рандом или тот же Date.now без лишних телодвижений.
- Если речь идёт о собственном генераторе псевдослучайных чисел, то у него зачастую есть сид значение, которое его детерминирует.

powerman
12.04.2018 02:24Помимо случайных чисел полно других вещей. Сейчас большая часть кода выполняется параллельно (по крайней мере на сервере), поэтому нередко предсказать в каком порядке будут происходить события и приходить данные нельзя в принципе — приходится либо их вручную искусственно синхронизировать или упорядочивать в самом тесте, либо писать тест в стиле "будет получено от 2-х до 5-ти значений, среди которых должно быть значение X", либо мокать кучу всего.
Igmat Автор
12.04.2018 12:50- ЛЮБОЙ тест можно привести к использованию
equalsиdeepEquals. Если нужна именно логика "будет получено от 2-х до 5-ти значений, среди которых должно быть значение X", то вы можете экспортировать булевое значение, которое принимаетtrueименно в таких условиях, и получить тест дляbaset. - Такой тест выглядит весьма странно, недетерминированное поведение модуля это уже запашок. Код, который возвращает разные значения (возвращение одних и тех же результатов в разном порядке — это по сути возвращение разных результатов) для одних и тех же входных параметров, потенциально ведёт к огромному количеству ошибок. Поэтому ИМХО их либо нужно синкать, либо разбивать на отдельные модули, либо… Ещё миллион вариантов, но они уже зависят от конкретной задачи.
powerman
12.04.2018 20:13Просто задачи бывают разные. Представьте, например, что нужно отправить запрос в поисковый кластер. Поскольку разные узлы в кластере могут быть недоступны/перегружены, а ответ нужен быстро — он отправляется параллельно на несколько узлов кластера, т.е. дублируется. Разные узлы могут иметь разные данные (eventual consistency), поэтому могут возвращать немного отличающиеся результаты. Happy testing. :)
Igmat Автор
12.04.2018 20:40Это явно не кейс для юнит-тестирования. Либо же кластер должен быть мокнут.
- ЛЮБОЙ тест можно привести к использованию
zloddey
12.04.2018 09:30К слову, прошу прощения за "чувак". На автомате решил, что это перевод. Уж больно часто в последнее время вижу именно переводы, если дело касается большой и обстоятельной статьи.
Не планировал делать комментарий в offensive стиле, но не заметил, как он сам по себе получился таким. Отредактировать уже не могу, поэтому делаю то, что могу — извиняюсь.
Igmat Автор
12.04.2018 12:42Ничего страшного:)
Технически я статью сначала писал на английском, а потом переводил, так что это могло повлиять на ощущения от прочтения.

retran
12.04.2018 18:10+3как протестировать банальный random
Справедливости ради, банальный random вполне себе детерминирован и возвращает одну и ту же последовательность чисел при одном и том же seed.
Реальной недетерминированности в коде на самом деле практически нет, разве что какие-либо race condition, которых вообще не должно быть (а тестирование конкуррентного кода — это, собственно, не совсем юнит-тестирование).powerman
12.04.2018 20:16Детерминирован обычный ГПСЧ. Но есть ещё крипто-ГПСЧ вроде /dev/urandom, там нет seed (ну, формально есть, но задать его в тесте не получится, а если бы и получилось, то толку бы всё-равно не было).
Igmat Автор
12.04.2018 21:02Я конечно не специалист в криптографии, но мне казалось, что настоящая случайность требует специализированного железа, а всё остальное, всё равно, так или иначе детерминировано.
powerman
12.04.2018 21:43Криптографически стойкие ГПСЧ постоянно подмешивают в текущее значение seed доступную им энтропию, по мере поступления этой энтропии. Она берётся из таких непредсказуемых вещей как события от клавиатуры, мышки, прерывания сетевой карты… http://man7.org/linux/man-pages/man7/random.7.html
retran
13.04.2018 10:17Мне кажется, что тестирование таких штук — это уже не совсем то о чем писал Бек.
oxidmod
12.04.2018 21:23Простеший пример: как протестировать банальный random(a, b)?
Так же, как и time()zloddey
13.04.2018 10:29Именно об этом я и писал в своём комментарии:
Придётся точно так же обкладывать код тестов "инфраструктурными" костылями для приведения результата к приемлемому виду.
Т.е., в случае недетерминированного поведения тестируемого кода придётся либо закрывать моками внешние источники недетерминированности, либо "причёсывать" получившийся результат до того, как он будет записан в baseline.
Другими словами, у каждого подхода к автотестам есть свои ограничения и неудобные места. Но, как оказалось позже, автор это тоже хорошо понимает.


andreyverbin
12.04.2018 03:12+2По моему все обсуждения тестов игнорирую самое важное. XP и TDD после него было предложено и опробовано в проекте на SmallTalk. Я совсем немного писал на этом языке и самое важное, что сразу бросается в глаза — не вы запускаете программу из IDE, а IDE интегрировано в программу. Вы можете затем IDE в релизе «вырезать» Как результат исчезает понятие «компиляция», вы просто меняете методы в работающей программе. В такой среде все внешние зависимости как правило тоже доступны. Проблема сложных сетапов исчезает, моки почти не нужны, а там где нужны Smalltalk позволяет все легко заменить. В такой среде вы действительно можете эффективно писать тесты и они действительно будут очень похожи на примеры кода. Причем ваши тесты будут ближе к тому, что называется сейчас интеграционным. Работать все будет быстро, тесты ведь запускаются в уже работающей IDE-программе.
ИМХО тестировать нужно только то, что может вызвать клиент вашей программы. По возможности избегая моков и тестирования всяких внутренних штук. Бизнес может и меняется очень быстро, но поля формы логина и логика его обработки довольно стабильна. То же касается и других требований, никто из бухгалтерии тракторный завод не делает, изменения более-менее плавные. А значит и формат входа и выхода более менее стабилен. Плюс нам платят как раз за то, чтобы при правильном вводе был правильный вывод, это и надо проверять на 100%. Остальное опционально.
Я этого подхода придерживаюсь уже 5 лет и с тех пор полюбил тесты. До этого, в течение пяти лет пытался научиться писать правильные юнит тесты, по заветам из книжек. Результат
- гора моков — время, файлы, бд, сеть, ui, библиотеки, работающие со всем перечисленным. Тесты ведь должны быть независимыми и работать быстро. Что делать в line of business системах, которые, по сути, прослойки между юзером и БД, особо не уточняется.
- Куча тестов на каждый модуль-класс.
- Почти 0 багов ловится тестами, покрытие 80%.
- Тесты массово валятся при малейшем рефакторинге (из за моков).
- Поддержка тестов стоит больше поддержки программы.
А если работать с реальной системой, а не горой моков, то тестов становится в разы меньше и они работают — ловят баги и кушать особо не просят.
areht
12.04.2018 04:43+1> гора моков — время, файлы, бд, сеть, ui, библиотеки, работающие со всем перечисленным
если у вас glue code — да, на него юнит-тесты писать занятие неблагодарное.
И у вас же небольшая команда?

kwolfy
12.04.2018 07:34-1Поддерживаю все сказанное выше. Говоря о каких либо библиотеках где связность кода небольшая юнит тесты действительно оправдывают себя, но если мы говорим о бизнес-проекте с большим количеством взаимозависимых частей намного эффективнее писать интеграционные тесты. Жаль только мир охватил хайп unit-тестирования, как и со всяким хайпом инструмент используют везде не проводя анализ целесообразности писать тонны тестов с миллионом моков только лишь для того чтобы сказать — у нас 95% покрытие кода. Найдутся люди которые скажут что за зависимость модулей в аду отдельный котел, но непонятно как они строят проекты без зависимых частей, реальные проекты, а не вот мой синтетический проект с двумя моделями.
Все что сказано выше относится к проектам с <5 разработчиков/направление, думаю unit оправдывает себя в больших компаниях где над каждым модулем работает отдельная командаareht
13.04.2018 18:54> Говоря о каких либо библиотеках где связность кода небольшая юнит тесты действительно оправдывают себя, но если мы говорим о бизнес-проекте с большим количеством взаимозависимых частей намного эффективнее писать интеграционные тесты.
Я ничего подобного не писал, если что )
glue code — это скорее те самые 5%, непокрытые тестами, а никак не 95%.
powerman
12.04.2018 07:52+1Описанное говорит о том, что Вы успешно освоили вариант тестирования близкий к BDD, а модульное тестирование — пока нет.
Одна проблема с высокоуровневыми тестами в том, что они проверяют только типичные способы использования, и при этом обычно вызывается далеко не весь написанный код (я сейчас даже не столько про формальную цифру покрытия кода в процентах, сколько про тщательность этого покрытия — если код был вызван, то это ещё не означает, что он был вызван во всех стоящих тестирования вариантах, и не означает, что результат его работы был действительно тщательно проверен тестом).
Другая проблема в том, что без моков почти невозможно потестировать код на обработку низкоуровневых ошибок (вроде "сетевой запрос к микросервису отвалился по таймауту" или "отвалилось подключение к БД").
Результат — это скорее приёмочные тесты, которые говорят о том, что запрошенный функционал реализован, и выглядит относительно рабочим.
А модульные тесты отвечают на совсем другие вопросы. Они никак не могут подтвердить, что приложение реализовало запрошенный бизнесом функционал. Зато они могут подтвердить, что написанный программистом код делает именно то, что ожидает этот программист. И делает это во всех возможных ситуациях, предусмотренных программистом — включая всевозможные ошибки.
Что делать в line of business системах, которые, по сути, прослойки между юзером и БД, особо не уточняется.
Вообще-то уточняется. Делать такую архитектуру, в которой модуль бизнес-логики можно выполнять и тестировать вообще без UI и без БД. А UI и БД делать отдельными модулями, со своими отдельными тестами, которым не нужен модуль бизнес-логики. Крайняя степень этого подхода отлично описана Дядюшкой Бобом: Чистая архитектура. Не обязательно делать всё настолько экстремально чтобы получить тестируемый код, но идея примерно такая.
andreyverbin
13.04.2018 00:21Основная мысль была в том, что в Smalltalk, откуда все это идет, юнит тесты очень похожи на то, что мы называем интеграционным, в силу особенностей среды. А то, что мы делаем с моками это, в большинстве случаев, очень вредные действия.
По сути ваш ответ заключается в обсуждении необходимой степени подробности тестов, это я и прокомментирую.
Высокоуровневые тесты действительно не скажут вам, что будет если отвалится сеть. Можно в систему даже внести специальные «ручки», чтобы такие ошибки генерировать. Или же стабы/моки использовать в таких сценариях. Я предпочитаю «ручки», потому что с ними проще работать.
Утверждение (готов доказать как теорему) — чем тщательнее мы проверяем наш код тестом, тем больше информации о нашем коде перетекает в тест и тем сильнее он связан с нашим кодом. Чем сильнее эта связь, тем сильнее нужно менять тест при изменении нашего кода. «Идеальный» тест, проверяющий все возможные состояния, позволит нам точно восстановить алгоритм. Менее «идеальный» тест позволит восстановить только часть.
Пример — алгоритм сортировки qsort. Если мы проверяем, что алгоритм переключается на bubble sort при малом размере сортируемого диапазона, то такой тест нужно будет «убить» если мы переключимся на merge sort. При этом вход и выход останутся неизменными, клиенту этого кода будет, чаще всего, все равно.
Жуткая спекуляция — возможно этот эффект можно связать с эффектом ухудшения качества статистической модели при превышении определенного порога сложности, который специфичен для задачи. Это в статистике часто бывает и в ML в виде переобучения — когда модель точно повторяет данные, но слишком хрупкая, чтобы эффективно обобщать реальность.
Я это все к чему — тесты задают неявную модель системы. Если эта модель слишком подробная, она становится хрупкой и требует постоянной подгонки под изменяющуюся систему. Мы это видим, как необходимость переделывать много тестов при изменениях системы.
К сожалению умные книжки не дают рекомендаций по нахождению оптимальной «подробности» или «тщательности» тестов для заданной системы. Отсюда и все разговоры о unit vs integration vs functional vs regression vs any-other-type-of-tests. Нам, по сути, нужна теория, которая бы позволила определить степень подробности тестов для заданной системы и требований качества. Пока такой теории нет я плюю на разницу между unit/не unit, игнорирую авторитетов и пытаюсь найти оптимум «тщательности» путем последовательных приближений. Ошибку приближения оцениваю по степени попаболи от тестов при рефакторинге системы.VolCh
13.04.2018 09:55+2«Идеальный» тест, проверяющий все возможные состояния, позволит нам точно восстановить алгоритм. Менее «идеальный» тест позволит восстановить только часть.
Пример — алгоритм сортировки qsort. Если мы проверяем, что алгоритм переключается на bubble sort при малом размере сортируемого диапазона, то такой тест нужно будет «убить» если мы переключимся на merge sort. При этом вход и выход останутся неизменными, клиенту этого кода будет, чаще всего, все равно."Идеальный" (юнит-)тест не должен проверять все возможные состояния, и, тем более, позволить восстановить алгоритм. Скажем, тестирование функции суммирования целых чисел, не должно позволить понять проводится суммирование вызовом оператора языка, инкрементом в цикле или работой с двоичным представлением. То же и с qsort — юнит-тесту должно быть все равно как и что там вызывается. Собственно смена алгоритмов сортировки под капотом qsort в терминах TDD — фаза рефакторинга. Сначала пишем тест на сортировку, он падает, пишем пузырёк, например, тест проходит, а потом начинаем рефакторить, оптимизировать так, чтобы тест не падал, но проходил быстрее. Собственно юнит-тест в таком процессе служит инструментом контроля того, что функция всё ещё сортирует.
Я это все к чему — тесты задают неявную модель системы.
Тесты не задают неявную модель системы, они явно проверяют соответствует ли модель, реализованная в коде, модели заданной в тестах.
andreyverbin
13.04.2018 16:24-1«Идеальный» (юнит-)тест не должен проверять все возможные состояния, и, тем более, позволить восстановить алгоритм.
Собственно я с этого и начал, надо проверять вход и выход самого большого куска кода, в идеале всей программы. Более маленькие компоненты проверять только если это оправдано. В этом ключе споры unit vs integration вообще смысл теряют.
Про qsort — если я тестирую класс Sorter и в тестах мокаю сервис ISmallRangeSorter, то это говорит кое-что о том, как реализована сортировка.
Тесты не задают неявную модель системы, они явно проверяют соответствует ли модель, реализованная в коде, модели заданной в тестах.
В коде у нас не модель, в коде у нас сама система и есть. Код, в свою очередь, может моделировать что-то, но в данном контексте это не важно. В тестах есть знание о коде и чем подробнее тесты тем больше знания «просачивается» в тесты и тем сильнее они связаны.VolCh
13.04.2018 16:58+1Собственно я с этого и начал, надо проверять вход и выход самого большого куска кода, в идеале всей программы. Более маленькие компоненты проверять только если это оправдано.
Я исключительно об юнит-тестах. Если уж решили тестировать маленький компонент, то идеальный тест не должен проверять все состояния, он должен проверить все сценарии использования.
Про qsort — если я тестирую класс Sorter и в тестах мокаю сервис ISmallRangeSorter, то это говорит кое-что о том, как реализована сортировка.
Ровно столько же сколько обычному клиенту, которому нужно передать в Sorter реальную реализацию ISmallRangeSorter.
В коде у нас не модель, в коде у нас сама система и есть. Код, в свою очередь, может моделировать что-то, но в данном контексте это не важно. В тестах есть знание о коде и чем подробнее тесты тем больше знания «просачивается» в тесты и тем сильнее они связаны.
В коде у нас модель + UI, система — это модель + UI + инфраструктура. В тестах должно быть знание о модели в тестируемом коде, тесты должны проверять корректность реализации модели в коде. Когда мы в тестах используем какие-то знания о коде, которых нет у его клиентов, нет в его контракте, то не очень понятно, что мы тестируем и зачем.
areht
13.04.2018 20:29> Про qsort — если я тестирую класс Sorter и в тестах мокаю сервис ISmallRangeSorter, то это говорит кое-что о том, как реализована сортировка.
Простите, а ILargeRangeSorter вы не мокаете?
> В тестах есть знание о коде и чем подробнее тесты тем больше знания «просачивается» в тесты и тем сильнее они связаны.
И именно это позволяет найти где именно проблема.
Простой пример: вы тестируете хеш-функцию, на вход пришла строка, на выходе — (да/нет). При входе «Ага!!! — сказали суровые сибирские мужики» у вас изменился выход. Кода — 100 000 строк. Что делать планируете?andreyverbin
14.04.2018 01:37Весь посыл моих сообщений состоит в нескольких простых идеях
— Unit тесты пошли из Smalltalk, а там они скорее похожи на то, что сейчас называется интеграционными тестами.
— Я противопоставляю подробность тестов их хрупкости. Чем более подробен тест, тем сильнее он завязан не реализацию и тем сложнее рефакторинг.
Как вывод, я предлагаю
— забыть о разговорах unit vs integration
— по возможности воспринимать всю программу как черный ящик и тестировать вход и выход, не влезать во внутренности этой самой программы.
Вы с чем из вышеперечисленного несогласны?
Предложенная вами хеш-функция отображает строки на bool. Это очень плохая хеш функция, вне зависимости от ее реализации.areht
14.04.2018 02:39Unit тесты пошли из Smalltalk, а там они скорее похожи на то, что сейчас называется интеграционными тестами.
Честно говоря, не понимаю к чему это. Сейчас юнит тестами называют юнит тесты. К чему эти упражнения в этимологии?
Чем более подробен тест
Не понимаю опять же, что за подробный тест? Это тоже что-то из Smalltalk?
Это очень плохая хеш функция, вне зависимости от ее реализации.
А никто не обещал хорошего легаси, а вам надо починить исходя из концепции «тестируем вход и выход».
Если вы мне объясните как — я подумаю соглашаться ли с вами. Но раз Вы от ответа уходите — видимо концепция не очень.
И про ILargeRangeSorter очень конкретный вопрос, предположу, что у вас и с моками проблемы не из-за моков.

dmbreaker
12.04.2018 08:28Только, пожалуйста, не путайте unit testing и TDD — это существенно разные подходы. К TDD большая часть описанных проблем отношения не имеет.
Druu
12.04.2018 10:12> Тесты — это формализованные требования если они стабильны;
Это верно только для тестов по типу черного ящика, что чаще всегда неверно для TDD.

i360u
12.04.2018 13:06TDD примерно раза в полтора увеличивает сроки разработки. На это, обычно контраргументом является то, что потом время будет сэкономлено на поддержке и развитии. Однако на практике, часто все выливается в рефакторинг с новыми тестами, которые дополнительно отнимают уйму времени. На мой взгляд, тестами должны быть покрыты только критические части системы, в остальных случаях это никак не окупиться, особенно в небольших проектах.

Neikist
12.04.2018 14:12+1Хз, а мне тесты помогают наоборот. Например писал тут на плюсах внешнюю компоненту для 1с, без тестов на почти незнакомом языке я бы задолбался выполнять сборку компоненты, встраивание в 1с, ручное тестирование, а с тестами все пошло гораздо проще и быстрее, поскольку обратную связь получал почти моментально. Ну и для самой 1с применять начал немного, заметно легче без необходимости перед каждым релизом (раз в две недели) проверять автоматически не сломалось ли чего, а не вручную.
DistortNeo
12.04.2018 15:22> Весь этот мусор из инструментов тестирования и assertion библиотек, как it, describe, test, to.be.true просто захламляет ваши тесты.
А ещё напрягает лапша из кода.
У теста должна быть чёткая структура: arrange, act, assert.Igmat Автор
12.04.2018 17:22Хреново может быть написан как код, так и тест. Проблема в том, что при существующих инструментах правила написания кода отличаются от правил написания теста, в то время, как в BaseT, я стараюсь свести эти правила воедино.
justboris
12.04.2018 13:37В Jest есть функциональность snapshot testing. Там делается то же самое что и у вас: значения сохраняются в специальные файлы, при следующем запуске результат сравнивается с эталоном.
Идея хорошая, но таких тестов недостаточно, чтобы быть уверенным в надежности своего кода и тестов. Нужны еще более четкие assertions, явно говорящие про ожидаемый результат.
Igmat Автор
12.04.2018 14:06Да, я в курсе про snapshot testing. Но это узкоспециализорованная фича для конкретного случая с реактом.
Как раз в подходе с
baselineесть четкое определение ожидаемого результата. Как я уже упоминал любой тест можно переписать используя толькоequals/deepEqualsи в целом такой подход очень правильный даже для уже популярных инструментов. Тот же Tape собственно ограничился необходимым минимумом для такого тестирования.
В BaseT я пошёл чуток дальше, если тесты должны ограничиватся только сравнением с ожидаемым значением, то лучше избежать ручного задания ожиданий (разработчик может ошибится при их подсчёте), а доверить это машине, которую потом перепроверит человек.
И так довольно часто видел как пишутся тесты (общая структура), потом пишется нетривиальный код, берётся его оутпут, оценивается на корректность разработчиком, и вставляется в тест, как ожидаемое значение. Та и сам так делал. Зачем это делать руками, если это может сделать софт, а нам нужно только принять или не принять расчитанное значение?

pterolex
12.04.2018 19:51Да, я в курсе про snapshot testing. Но это узкоспециализорованная фича для конкретного случая с реактом.
Почему же? Snapshot тесты поддерживают любые значения, в том числе Immutable.jsIgmat Автор
12.04.2018 20:04Потому что всё равно нужно добавлять разный мусор и явно делать
expect(..).toMatchSnapshot()
import React from 'react'; import Link from '../Link.react'; import renderer from 'react-test-renderer'; it('renders correctly', () => { const tree = renderer .create(<Link page="http://www.facebook.com">Facebook</Link>) .toJSON(); expect(tree).toMatchSnapshot(); });
Более того, библиотека не построена вокруг этого функционала, а его просто добавили к ней извне для покрытия определённых кейсов т.е. ни резолверов для разных типов данных (эти примеры работают как раз благодаря ним), ни другие аксептанс стратегии, ни использование доки как тестов или тестов как доки сразу в удобном для чтения виде, ни сайд-эффект коллекторы не могут быть там добавлены без существенного изменения всего инструмента.
justboris
13.04.2018 10:27ни резолверов для разных типов данных
Как нет? вот же, snapshotSerializers.
Кроме того, в
baset-resolver-reactвы "снапшотите" только html, аreact-test-rendererпоказывает еще обработчики событий, и другие свойства, невидимые в html. Поэтому вам бы тоже лучше использовать test-renderer под капотом, а неrenderToString
ни использование доки как тестов или тестов как доки сразу в удобном для чтения виде
"удобный для чтения вид" подразумевает аккуратные и короткие листинги, показывающее только то, что важно. Выплевывать в документацию полный вывод — не очень читаемо. А если не снапшотить полный вывод, то страдает тестовое покрытие.
Igmat Автор
13.04.2018 12:06- Спасибо за наводку на
react-test-renderer, обязательно посмотрю внимательней и скорее всего заюзаю его вместо рендера в строку. snapshotSerializers— это совершенно не то же самое, что и резолвер.
Начнём с того, что, во-первых, исходя из этой строки они просто сравнивают полученный вывод с снэпшотом сравнением строк. Вbasetот этого отказались (хотя фолл-бек к этому есть).
Во-вторых, предназначение сериалайзера изJest— это форматированние снэпшота, т.е. это та функция, которую делаютbaselinerмодули у меня. Они правда и сериализуют, и десериализуют, что позволяет им дописывать дополнительный контент, который не приведёт к поломке теста при изменении несущественных элементов (например md-baseliner со временем научится дописывать текстовые доки к блокам кода, что сделаетbaselineближе к докам).
В-третьих, резолвер, именно резолвит, а не сериализует. То есть к нескольким экспортам из одного файла могут быть применены разные резолверы (например, для реакта и пикси) и записанны в один бейзлайн.
В-четвёртых, экспорты проходяться рекурсивно, умеют находить циклические ссылки (и по особому их разруливают), резолвят промисы и делают ещё кучу всего.
Как вывод, резолвер — это совершенно другая абстракция, для которой можно сейчас найти ещё миллион отличий (большая часть из которых, скорее всего, будет положительными)- Я стараюсь делать всё, что бы получился "удобный для чтения вид", с тем же pixi, я рендерю картинку. Оутпуты могут быть разными для этого и придуманы резолверы, сайд-эффект коллекторы и бейзлайнеры, поэтому я думаю, что можно будет придумать самый удобный вид для отображения всего этого добра в итоговом бейзлане-доке.
- Спасибо за наводку на

arvitaly
12.04.2018 14:42+2Нет никаких проблем тестировать чистые функции, хоть так, хоть эдак опиши ожидаемые результаты.
Основная проблема — это сайд-эффекты и mock-объекты, особенно в ООП, где ссылочные зависимости могут быть очень большими.Igmat Автор
12.04.2018 15:03+1Тут полностью согласен. Хотя ИМХО тестирование чистых функций в BaseT проще, чем в других инструментах, а по поводу сайд-эффектов:
- Для pixi.js это как раз и было проблемой, потому что главный результат рендеринга их
DisplayObjectа это и есть побочный эффект. Но посольку я понимал, что подобное будет встречатся, был предусмотрен API для специфических резолверов и в итоге реализацияpixi-resolverбыла довольно простой и потребовала совсем небольшое кол-во кода.
К тому же, в планах реализовать резолверы для всех популярных либ (для реакта уже есть, ангуляр в ближайшей перспективе) - В планах так же side-effects collectors API + реализации самых распростронённых кейсов, типа сериализация результирющего DOM или изменений в файловой системе/базе данных.
Удобного АПИ для моков пока нет (хотя никто не мешает делать их руками), но оно в процессе.
- Для pixi.js это как раз и было проблемой, потому что главный результат рендеринга их

alexey-lustin
12.04.2018 15:24+3Статье действительно нужно поставить плюс, потому что поднимаются верные вопросы — что уже немаловажно. Но уж коли в одном месте были упомянуты «серебряная пуля» и формулировка «tdd ошибочно» я прямо вынужден прокоментировать.
Понимаете как штука — bdd, tdd, cicd, code coverage, linters, contionious code coverage, uat и другие веселые аббревиатуры типа atdd они в целом лежат в плоскости качества продукта.
И если убрать «холивар» в части что лучше tdd, bdd или atdd мы с вами в целом должны говорить о том какие методики применяются чтобы не накопить технический и архитектурный долг, что по умному называется QA (и это не question&answers). Вы может не знаете — но есть тесты на архитектуру приложения и линтеры для архитектуры, причем как и тесты (поведение) пишутся такие тесты до старта проектирования, а потом еще и проверяются автоматически на сервере сборок.
Проблемы которые вы описали в статье очень похожи на проблемы которые описал Дэн Норт в своей исходной статье про dannorth.net/introducing-bdd
В проекте cucumber.js в целом ваш baseline делается на основе Scenarion Outline и Examples и концепции hooks чтобы генерировать страницы.
собственно в этой части даже были эксперименты Мэта Вейна выродившиеся в попытку создать даже такой сервис relishapp.com/cucumber/cucumber-js/docs/world-constructor-callback-with-object
То есть я так понимаю вы потихоньку придете и к bdd и к live documentation — наиболее упоротые бехавойристы делают автоматически gif файлы демонстрирующие и одновременно проверяющие поведение.
Если подытожить — вы затеяли хороший и интересный проект: подписался на него ;-)
P.S. Серебряная Пуля кстати существует — это мороженное из Тулы ;-)Igmat Автор
12.04.2018 17:39Спасибо за такой обстоятельный и позитивный комментарий:)
BDD в целом и кукумбер в частности мне были довольно интересны, но в целом это поход в другую сторону — и я не считаю это неправильным, просто другим.
BDD это движение от юнит-тестов к более высокому уровню абстракции, что в целом очень интерестно и делает поведенческие тесты настоящей формализацией требований, в чём ИМХО кроется огромное кол-во разных плюсов. Но…
BDD это процесс, к тому же даже в большей степени чем TDD, возможно даже в большей степени чем какой-нибудь Agile/Scrum. Это не плохо и не хорошо, просто требует достаточно серъёзных организационных затрат + подключение к процессу, как минимум, BA т.е. это всё уже выходит далеко за рамки просто инструмента для разработчиков.
В то время как BaseT — это, наоборот, движения от процесса (TDD) к простому, как угол дома, инструменту. И да в BaseT есть амбиции на создание в том числе и чего-то близкого к live documentation (таски #11 и #14), если я правильно понял о чём этот термин.
К тому же, если BaseT + другой фреймоврк для юнит-тестирования (типа Jest/Mocha/Tape) — это ИМХО глупость и они скорее будут мешать друг другу, то BaseT + BDD (тот же кукумбер), вполне могут дополнять друг друга.

netch80
12.04.2018 16:50> В 2008 году вышел один из первых фреймворков для тестирования
Видимо, это только для Javascript? Потому что тут, например, говорят про 1991 год для концепции, 1994 для (неживых сейчас) тулзов типа SUnit, 1998 для JUnit… А тут — про 1989 год. Эти даты всё-таки ближе к истине. Хотя, думаю, отдельные реализации в доинтернетовскую эпоху были и сильно раньше.
> Очевидно, что TDD нельзя назвать ошибочным, но…
Я думаю, таки можно. Уже писал на хабре, и в других местах.
Хотя, если оборотной стороной фанатения от TDD является массовое вхождение тестовых фреймворков в обычную практику, то его можно похвалить уже за это :)Igmat Автор
12.04.2018 18:00+1Да, речь шла о первом фреймоврке для JS, наверное стоит уточнить в самой статье.
В самой статье я ссылался на Кента Бека ("переоткрыл" TDD в 1999) и эту любопытную заметку про возраст TDD.
Само же юнит-тестирование я считал от появления TAP в 1987 т.е. даже раньше чем указанный вами 1989, но суть была не в полной энциклопедической достоверности, а в том, что бы показать, что эти подходы существуют уже очень давно (дольше, чем я живу, например).
А теперь от истории к действительно важному:)
Прочитал тот ваш прошлогодний коммент, жаль не могу лайк поставить т.к. "срок голосования истёк" :(
В целом согласен, поэтому и написал следующее:
Значит TDD всё-таки ошибочно? — Нет, TDD не ошибочно.
Оно указывает правильно направление и поднимает важные вопросы. Мы просто должны переосмыслить и изменить способ его применения.И в BaseT я хочу добится не использования правила "test first", а просто написания теста и кода по сути паралельно, что, кстати, вроде довольно неплохо будет ложиться на те наукоемкие примеры, что вы приводили у себяю
VolCh
13.04.2018 10:04Надо понимать, что цель юнит-тестов — фиксация поведения и для достижения этой цели не важно пишутся тесты до, после или параллельно. TDD же постулирует, что сначала нужно описать желаемое поведение в тестах, а уж потом подогнать код под него.
DistortNeo
13.04.2018 11:14TDD же постулирует, что сначала нужно описать желаемое поведение в тестах, а уж потом подогнать код под него.
Даже больше. TDD предполагает, что за одну итерацию добавляется один, максимум несколько тестов, а не описывается весь функционал сразу.

ganqqwerty
12.04.2018 18:44> TDD родился в «Золотой век» каскадной модели
Вроде ж в 1998 уже Rational Unified Process появился и водопад хаяли все кому не лень.Igmat Автор
12.04.2018 19:094-ое издание PMBOK, в котором впервые отошли от каскадной модели в сторону гибридной (то есть признали достижения гибких методологий) вышло только в 2008 году.
Так что ИМХО всё время ДО этого момента всё ещё «Золотой век» водопада, несмотря на то, что итеративные методологии использовались и задолго до этого, но это не было так распространенно.
NtsDK
12.04.2018 20:23Большая проблема тестов заключается в дороговизне их разработки и поддержки. Поскольку тест тесту рознь, то можно посмотреть на дешёвые виды тестирования.
К таковым я отношу:
1. Статический анализ. Несмотря на то, что eslint, вообще говоря, не про тестирование, он может выявлять ошибки вида «данной функции в этом контексте нету».
2. Smoke тесты. Да, ими много не натестируешь, но это намного лучше, чем ничего.
3. Развитие идеи snapshot тестов. Вот у нас есть «что-то», что требует тестирования. Нам нужно это сверить с «чем-то». Вопрос с чем?
Один из вариантов — у вас есть старая версия системы и новая. У вас есть внутри функция. На нее вы ставите перехватчик, который складывает в базу данных записи «функция на аргументы такие дала результат такой». Накопили результаты со старой версии и стали сверять с результатами перехватчика с той же функции в новой версии. Возможно у этого подхода уже есть свое умное название, но я не встречал.Igmat Автор
12.04.2018 20:59- Тут ещё можно добавить TypeScript, хотя этот инструмент тоже совсем не про тестирование.
- Многие интеграционные тесты похожи на смоки.
- Так BaseT, в каком-то смысле, именно про это. Более того в нём уже даже есть функция генерации использований (команда scaffold, правда она совсем сырая и требует ещё очень много доработок).
Так что присоединяйтесь, если я ваши мысли правильно понял :)
ganqqwerty
13.04.2018 03:14Инструмент, который создал автор, на мой взгляд, просто прекрасен, потому что он хотя бы пытается сделать шаг вперед по сравнению с тем, что имеется: пытается как-то помочь программисту, сэкономить его время. Вопрос, какие есть еще подходы?
Со стороны хайтека
Из каждого утюга слышим про deep learning и african intelligence, а в мире e2e тестирования не придумано ничего сложнее protractor'a? Можно обучить машину играть в atari-игры, но нельзя заставить ее понаблюдать за десятком-другим тест-запусков, которые делаются тестером и заставить громко кричать когда результаты «выглядят как-то не так» или когда «кажется, что что-то упало»?
Со стороны IDE
Каждый раз когда я тестирую ангуляр-компонент, я лезу в документацию о том, как мокнуть что-то, как быть если есть роутер, как быть, если у меня что-то стало асинхронным. Напрашивается же сразу кнопочка в WebStorm, позволяющая inject'нуть сервис, да так, чтобы он сразу же мокнулся в соответсвующем spec-файле.
Со стороны эвристик
ангуляровский ng-cli вот генерирует тест для компонента по умолчанию, типа создал компонент, а потом expect этот компонент to be true. Это примитивнейшая эвристика, можно ли придумать другие, более интересные, пусть и не верные для абсолютно всех компонентов? Например, если я передал в input компонента какой-то текст, то ЧТО-ТО ПОХОЖЕЕ на этот текст должно быть выведено в html.
Со стороны тестовых данных
Мой тестовый модуль существует не в изоляции. Мою функцию регулярно вызывают с совершенно определенным набором параметров. Кто? Да я сам, когда запускаю свое поделие по триста раз за день, или вот мои пользователи. Почему бы не собирать статистику о том, какие параметры реалистичны и наиболее часты, тем самым генерируя наборы тестовых данных?Igmat Автор
13.04.2018 12:58+1Спасибо, я очень рад, что вам понравилось :)
ВBaseTполно планов на что-то подобное. Часть из которых перечислена здесь
- Со стороны IDE: есть идея сделать Workflow mode (очевидно, совместимый с любой IDE), который будет отслеживать изменения в сорсах и для начала скаффолдить тесты для экспортов, которые не протестированны. С изменением сигнатур, как в описаном сценарии, уже сложнее, но тоже можно что-то придумать.
- Со стороны эвристик: scaffold команда уже сейчас использует более сложные эвристики (правда работает только в тайпскрипте пока что) для генерации первоначальных тестов, но там ещё огромное пространство для улучшений.
- Со стороны тестовых данных: сбор статистики использования для тестовых данных — это интересная идея, но пока не вижу простых способов её реализации. С другой стороны TypeScript умеет находить использования того или иного класса/модуля/функции в вашем коде, и я собираюсь это заюзать для скаффолда тестов, используя реальные примеры применения модуля, что по идее должно существенно автоматизировать начальное создание тестов, ещё и с довольно неплохим качеством.
- Со стороны хайтека: к сожалению, не вижу как это можно было бы легко прикрутить к e2e тестированию, но машинным обучением точно можно было бы улучшить качество эвристик для скаффолда тестов. Но, с моей стороны, это для начала требует более качественной реализации scaffold комманды.
Собственно, всё реально, и над этим уже идёт работа — всё вышеперечисленное в том или ином виде описано в тасках #65 и #66. Так что следите за новостями, а лучше присоединяйтесь — я буду рад любому фидбеку и/или идее.

vyatsek
13.04.2018 19:26"TDD как практика была "переизобретена" Кентом Беком в 1999 году, в то время как Agile Manifesto был принят только 2 года спустя (в 2001). Я должен это подчеркнуть, что бы вы поняли, что TDD родился в "Золотой век" каскадной модели и этот факт определяет наиболее благоприятные условия и процессы, для которых он и был спроектирован. ”
Автор что ты несёшь?? Какая каскадная модель?! В то время уже вовсю и везде говорил про RUP и MSF.
RUP важное и серьезнейшая попытка формализовать процесс разработки. Фазы и этапы которого актуальный по сей день. Каскадная модель была лишь первой попыткой формализовать процесс разработки, более того Ройс уже в 1970 году показывает ее несовершенство. Хватит уже спекуляций на тему каскадной модели. В 1970 года процесс разработки софта был совершенно иной, но уже тогда говорили о несовершенности каскадной модели.
А уж тем более во времена 2000 в эпоху борланда, vcl и mfc никто о каскаде и не думал.
Почитайте историю чтобы не нести ахинею. Статью дальше читать не сталIgmat Автор
13.04.2018 20:40Говорили продвинутые люди и была повсеместно принята — это две абсолютно разные вещи.
И про Ройса я знаю ещё то, что его статья с, так называемой, критикой — это по сути первая формализация каскадной модели.
А вам стоит обратить внимание на то, что только с 4-го издания PMBoK (2008 год) в нём появляются элементы гибких методологий, хотя до этого там был ТОЛЬКО водопад. Я надеюсь вы помните о том, что этот гайд де-факто стандарт для управления проектами.vyatsek
14.04.2018 00:56А вам стоит обратить внимание на то, что только с 4-го издания PMBoK (2008 год) в нём появляются элементы гибких методологий, хотя до этого там был ТОЛЬКО водопад.
Автор, вы читать умеете? Еще раз, посмотрите на на RUP и MSF, лично сам в 2001 читал про RUP, UML (и перелопачивал citforum.ru) и как применять его в Rational Rose.
Я не знаю что там было в PMBok, но в 2000 мы писали софт, примерно точно так же как сейчас, надо вот сделать такую хрень, сколько примерно эть времени займет и дайте что-нить посмотреть пораньше.
Хватит уже менеджить по книжкам. Вы писали в 2000 году софт? Если нет, то и нечего минусовать. Если писали то где и как. Как же задолбали книжные черви всезнайки с якобы опытом в разработке софта.
vyatsek
14.04.2018 01:03Автор почитайте книги Айвара Якобсона, Гради буча, прежде чем говорить о «золотом веке» каскадной модели.
vyatsek
14.04.2018 01:10А вам стоит обратить внимание на то, что только с 4-го издания PMBoK (2008 год) в нём появляются элементы гибких методологий, хотя до этого там был ТОЛЬКО водопад.
Приведите пожалуйста страницы.
powerman
Я не уверен, что автоматизация задания/обновления результатов теста — хорошая идея. Я немного с этим экспериментировал когда-то давно, по моим наблюдениям, если результат теста не задаётся человеком вручную изначально (максимум, копируется из вывода провалившегося теста) — в тесты проникает немало некорректных "ожидаемых" результатов. Пытаться по diff-ам понять, правильно ли изменились вон те 8 результатов из 42 — сложно, требует слишком много внимания, и обычно заканчивается принятием изменений механически. Конечно, существуют ситуации, когда такой подход не просто приемлем, а чуть ли не единственно возможный (когда данных слишком много и/или их практически невозможно предсказать и задать вручную), но это исключения, а не правило.
Конечно же, его принимали Вы. Согласившись работать на этих проектах вообще, и согласившись и писать свой код без тестов в частности. Я в этом отношении практикую жёсткую политику: если мне не дают нормально организовать на проекте тестирование, CI/CD, и фиксить архитектурные проблемы — я просто отказываюсь заниматься в таких условиях багфиксами. Потому что если архитектурно в проекте допускается возможность race condition, и в примерно этом месте происходит фигня — то на расследование каждого такого конкретного случая (на предмет а не баг ли это или просто архитектурная особенность проявилась) уйдёт немало времени, причём зачастую впустую. И пусть время своей жизни на такую бессмысленную деятельность тратит кто-то другой, кто на это согласен.
Поскольку Вы осознанно сделали заголовок статьи таким, каким сделали, я тоже проигнорирую что статья про JS и прокомментирую в общем, например на опыте Go.
Это не совсем так. Есть упомянутое Вами BDD. Но гораздо важнее то, что требования существуют на разных уровнях! Если в проекте нужна функция складывающая два числа — её требования не будут меняться. А если изменятся — скорее всего это будет означать, что старую функцию надо выкинуть, и написать новую. При правильном определении небольших отдельных компонентов/модулей/библиотек/микросервисов проекта, слабо связанных с остальными, требования к ним будут составляться самими программистами, и будут редко изменяться из-за изменений требований бизнеса — чаще требования бизнеса просто будет делать некоторые из этих компонентов ненужными, и, вместо их бесконечного изменения до полной неузнаваемости относительно начальной версии, такие компоненты будут просто выбрасываться и заменяться новыми. А для тестирования высокоуровневых требований бизнеса есть BDD, и за счёт реально высокого уровня такие тесты тоже получаются более стабильными.
Весь раздел не очень корректен. Фактор здесь только один: будет ли код поддерживаться. Если это одноразовый скрипт или простой прототип — тесты время не сэкономят. Но практически во всех остальных случаях начальное написание кода (до его первого реального изменения, будь то вследствие найденных багов или изменённых требований) занимает незначительный процент общего времени разработки проекта — и в этих условиях тесты всегда экономят время, и значительно.
Конечно, чтобы от тестов была польза — надо уметь их писать. Но это касается и программирования, и даже готовки еды. Суть текущих проблем с тестами в том, что, почему-то, считается что любой программист автоматически умеет писать тесты — а это не так. Этому надо учиться, так же как надо учиться писать под определённую ОС, на определённом языке, фреймворке, бэк или фронт, быстро или безопасно, etc.
В Go из коробки поддерживаются тесты, которые являются исполняемыми примерами кода: func Example…(){…}.
Это очень верно. И, опять же, в Go всё это так и реализовано — компиляция, тестирование и даже линтер запускаются одной командой, доступной сразу после установки самого Go. Плюс ещё генерация документации из исходников, с теми самыми исполняемыми примерами кода.
В Go эта проблема обычно решается написанием тестов в табличном стиле. Это тоже не серебряная пуля, но большинство тестов в таком виде намного проще и писать и читать, потому что инфраструктурный код полностью отделён от входных и выходных значений теста.
Igmat Автор
Этого требует TDD — тест пишет разработчик, который реализовывает задачу. Я согласен, что писать правильные тесты сложно, поэтому и предлагаю инструмент, для которого дополнительные знания не нужны — просто используй код, который написал.
powerman
Это не нормально, и так быть не должно. Время от времени такое допустимо и неизбежно, но если это происходит "всё время" — скорее всего это признак того, что разработчик ещё не научился нормально писать тесты, и они получаются слишком хрупкими.
На самом деле всё наоборот. Многие относятся к тестам как к чему-то второсортному, что можно делать в спешке, на скорую руку, и грязно. Проблема именно в этом отношении — тесты это такой же код, их тоже надо писать достаточно чисто, рефакторить, местами даже продумывать, создавать для них вспомогательные объекты/функции, а иногда и полноценные библиотеки. Штатно на тесты необходимо выделять столько же времени, сколько на написание основного кода, и не надо это время пытаться "оптимизировать" — ничем хорошим это не закончится.
Ну, вы же не поставите джуниора писать ядро системы, потому что архитектор требует чтобы ядро было написано в принципе. TDD требует чтобы тесты писались до кода, разработчиком этого кода. TDD не требует чтобы эту задачу поручали разработчику, который не умеет писать тесты.
Вообще, лично я не сторонник TDD. Я пишу обычные модульные тесты после кода, плюс иногда высокоуровневые тесты, которые по природе скорее относятся к BDD (хотя я так и не проникся BDD-шной терминологией и обычно пишу эти тесты в том же стиле, что и модульные). Плюс интеграционные и нагрузочные, по необходимости. При покрытии кода качественно написанными модульными в районе 80-90% BDD и интеграционные редко приносят дополнительную пользу, основная польза есть только от нагрузочных.
Igmat Автор
Не обязательно — вполне может быть ситуация, что меняются высокоуровневые требования, что ведёт к переписыванию высокоуровневых тестов. Да, тесты атомарных элементов (тех, у которых нет зависимостей) не должны попадать в ситуацию постоянного переписывания, но тесты более сложных сущностей (композиция нескольких атомарных модулей для реализации собственно реальной бизнесс-логики) вполне могут постоянно переписыватся из-за того, что требования изменяются и уточняются в процессе разработки и паралельной эксплуатации.
Мы всё время создаем инструменты, которые ускоряют процесс разработки, почему вдруг мы не должны оптмизировать время на тестирование?
Юнит-тесты (именно они, без учёта поведенческих) сами по себе (без кода, который они тестируют) не приносят никакой пользы. От них появляется смысл только тогда, когда есть код.
Относится к тестам так же как и к коду имеет смысл только при работе над поведенческим/интеграционным/нагрузочным тестированием, в других случаях затраты на них просто никогда не окупятся.
Именно поэтому юнит-тесты часто пропускаются в реальных проектах, я же пытаюсь сделать их частью процесса разработка, давая максимально возможный value от тестов, при минимальных трудозатратах.
Идея в том, что бы сделать умение писать тесты максимально близким к умению писать код. В таком случае, не будет проблем с внедрением тестирования в проекты, потому что любой джун сможет не только написать небольшой кусочек системы, но и написать на него тесты, что понизит порог вхождения в проект и повысит его общее качество.
Судя по всему у нас кардинально разный опыт в разработке/тестировании. Я никогда не видел качественного покрытия в 80%-90% без использования TDD или выделения отдельной фазы (минимум в пару месяцев, в зависимости от размера проекта) на покрытие кода тестами, без внедрения нового функционала. Последний вариант я встречал вообще только 1 раз т.к. клиент зачастую не готов платить за что-то абстрактное без чёткого понимания ответа на вопрос "где деньги?".
В целом одна из идей, в том что бы сделать TDD менее формальным, спустить его с уровня процесса до уровня инструмента так, что бы тест писался вместе с кодом и разделение на написание теста/написание кода потеряло смысл.
powerman
Да, я забыл уточнить, что имел в виду модульные тесты.
Это чепуха. То же самое можно было бы сказать про рефакторинг: раз он не изменяет поведение кода, то затраты на него никогда не окупятся. Оно окупается как раз на том, что качественно написанный тест перестаёт "всё время ломаться".
Всё банально: сначала делается декомпозиция, и получаем небольшой модуль, который пишется за 2-4 дня, после чего ещё пару дней он обвешивается юнит-тестами. Суть в том, что без юнит-тестов написание кода нельзя считать завершённой, потому что "не протестированный код == нерабочий код".
Меня же попросили не написать функцию с определёнными входными/выходными значениями, которая делает что-то неопределённое, а написать функцию, которая делает что-то вполне конкретное. Как без юнит-тестов, ни разу не запустив эту функцию, я могу считать поставленную мне задачу выполненной? Такой подход вне программирования обычно называется халтура. Представьте, что вы в магазине попросили "300г колбасы A", а вам дали "тут вроде меньше полкило колбасы, взятой вроде из того отдела где обычно лежит в т.ч. и A".
Igmat Автор
Я не предлагаю халтурить.
Я не предлагаю не писать тесты.
Я предлагаю тратить минимальное количество времени на получение максимально хоршего результата.
И да, для чего-то близкого к BDD, где тест сам по себе (даже в отрыве от кода, который он покрывает) представляет ценность, отношение должно быть такое же как к коду. Но...
С этим я полностью согласен, но зачем
ещё пару дней его обвешивать юнит-тестами, если можно создать инструментарий, который будет требовать на это только пару часов. И то, если делать это пост-фактум, хотя можно делать и паралельно в 3 окнах:входными даннымиНе вижу смысла держаться за существующий инструментарий и подходы, когда их можно улучшить.
powerman
Я на это уже отвечал в самом первом комментарии: предлагаемый инструментарий приведёт к тому, что в тестах очень часто будут некорректно заданы ожидаемые значения. Это не вопрос некорректного инструмента, это вопрос психологии и используемого процесса. Другое дело, что если текущий процесс предполагает в 95% тупое копирование ожидаемых результатов из вывода провалившегося теста в код вручную — тогда ваш инструмент действительно будет полезен для оптимизации текущего процесса… только вот процесс этот, на мой взгляд, проблемный по своей природе и лучше его не оптимизировать инструментами а заменить на более надёжный.
Igmat Автор
Просмотреть результаты, которые тебе предложила программа НАМНОГО проще, чем посчитать их самому и внести в тест.
Поэтому ИМХО вероятность того, что в бейзлайн проникнут некорректные значения не выше (а возможно и ниже), чем вероятность бага во вручную написанном тесте.
А что более важно, так это то, что упрощения процесса написания теста приведёт к тому, что будет покрыто больше кейсов т.к. необходимость писать инфраструктурный код больше не будет останавливать разработчика.
Более сложный процесс (ваш), не значит более надёжный. Мне кажется, что мой, более простой процесс, не менее надёжен. К тому же, он предлагает помощь при самом написании кода как я описывал здесь, что увеличивает количество проверяемых значений ещё на этапе разработки, а выкидывать проверочные кейсы, мне кажется, в голову никому не придёт.
powerman
Конечно. В этом-то и проблема. Вручную приходится задумываться над каждым результатом… А почему? А потому, что пока над ним не задумаешься — ты не знаешь, какой результат верный. Если вместо этого тебе сразу показывают готовый результат, причём не один а сразу кучу — ты не будешь над ними задумываться… Но ведь это не отменяет вышеупомянутый факт, что пока не задумаешься — не определишь верный ответ! В результате предложенный программой набор результатов принимается без тщательной проверки на корректность, достаточно чтобы сходу на глаза не попалась какая-то явная чушь в результатах.
Это не так. Когда ошибка делается вручную, она почти всегда приводит к тому, что тест проваливается и ошибка исправляется — вероятность сделать вручную в ожидаемом результате ту же ошибку, которую делает тестирумый код крайне мала.
А вот в вашем подходе, принятые пачкой результаты, среди которых затесалось несколько некорректных — никогда не приведут к провалу теста, и останутся незамеченными.
Igmat Автор
Тот разработчик, который поленится задуматся над предложенными результатами и просто их примет, в случае с классическим подходом просто не будет писать тест вообще или покроет только самые тривиальные случаи.
Я не говорю, что мой подход решает все проблемы. Но практика показывает что обычное юнит-тестирование слишком трудозатратно и это ведёт к тому, что его просто не делают.
Я не верю, что смогу переобучить и сподвигнуть большинство на правильное использование юнит-тестирования.
Я даю более простой инструмент и метод в надежде на то, что им будут охотнее пользоватся, ведь тесты как секс: "лучше плохой, чем никакого вовсе".
А при грамотном подходе к тестированию, ни в классическом подходе, ни в моём не будет серьёзных пробелов.
VolCh
С таким инструментом хорошо фиксировать поведение имеющегося кода, не важно, корректное оно или нет. Например, перед релизом зафиксировать.
Но проверять код на корректность с ним хуже чем с классическим тестами, особенно по TDD.
mayorovp
Только не перед релизом, а перед рефакторингом.
VolCh
От цикла разработки зависит.
Igmat Автор
Я в самой статье писал, что TDD применим для проверки кода на корректность только в довольно ограниченном количестве случаев.
А фиксируют существующее поведение классический TDD не лучше, чем тот метод, что я предлагаю, если не хуже.
Если же мы хотим именно проверки на соответсивие требованиям, то лучше использовать BDD, и в таком случае BDD + BaseT выглядит ИМХО намного интереснее, чем BDD + TDD.
VolCh
Можно цитату конкретную? Пробежался — не нашёл. Или вы под корректностью имеете в виду соответствие формальным требованиям типа ТЗ?
Igmat Автор
Вот ссылка на нужную часть статьи.
Igmat Автор
При этом в BaseT можно написать абсолютно любой тест. Вам ничто не мешает, сделает сложный assertion и экспортировать булево значение в baseline.