
В одном из наших прошлых материалов мы рассказывали про статические методы балансировки нагрузки в облаке IaaS-провайдера. Сегодня на очереди динамические методы: «пчелиный» и «муравьиный» алгоритмы, а также подход Biased Random Sampling.

/ Flickr / Quinn Dombrowski / CC BY-SA
Динамические методы балансировки, в отличие от статических, в своей работе учитывают текущее состояние всей системы и реагируют на изменения в ней. Часто информация о загруженности узлов хранится в таблице состояний, из которой системы распределения нагрузки и черпают информацию.
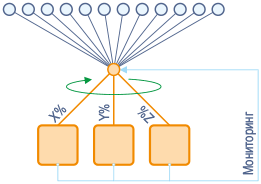
Динамическое распределение нагрузки — выполняется мониторинг
Для реализации этого подхода сеть представляется в виде виртуального направленного графа, в которой все серверы — это вершины. При поступлении запроса на выполнение какой-либо задачи, балансировщик нагрузки назначает её той вершине (узлу), которая имеет полустепень захода равную как минимум единице.
Когда узел получает задачу, процессор начинает её выполнение и параллельно сигнализирует об уменьшении числа доступных вычислительных ресурсов, декрементируя полустепень захода. Когда задача «решена», узел инкрементирует этот показатель, сообщая о высвобождении ресурсов.
Выбор начальной вершины для выполнения задачи делается случайно (отсюда и random sampling); последующие задачи назначаются узлам-соседям, которые также выбираются в произвольном порядке. Этот метод балансировки нагрузки полностью децентрализован и потому подходит для работы в облачных сетях. В том числе географически распределенных.
Ученые из Ливерпуля установили, что Biased Random Sampling, дополнительно учитывающий географическое распределение узлов в сети, позволяет снизить латентность при передаче данных на 22%. В тесте с 512 узлами, расположенными в радиусе тысячи км, средняя задержка составила примерно 70 мс (в эксперименте с сетью, не учитывающей географического распределения узлов, этот показатель составлял 92,5 мс).
Впервые эта концепция была представлена в начале девяностых годов. Она черпает вдохновение в поведении муравьев. Муравей всегда способен найти путь от источника пищи до муравейника даже в том случае, если привычный путь был «заблокирован». Для этого эти насекомые отмечают маршрут специальными феромонами. Считается, что чем сильнее этот «запах», тем ближе находится источник еды.
В контексте балансировки нагрузки в телекоммуникационных сетях это выглядит следующим образом. Сеть представляется в виде графа, и из всех возможных узлов выбирается главный, который имеет набольшее количество соседей. Коммутационные станции отображаются в узлы графа, а линии связи между ними — в ребра.
Каждый узел содержит «феромонную таблицу», в которой собраны данные об используемых ресурсах и доступных мощностях: количество памяти, число процессоров и др. Периодически из каждого узла запускаются муравьи, которые направляются в случайные узлы-приемники. «Насекомые» перемещаются между узлами, руководствуясь феромонной таблицей. Эта таблица обновляется каждый раз, когда к ней обращается муравей.
Муравьи имеют возраст, равный длине пройденного пути. Также муравьи задерживаются в узлах, переполненных вызовами. Те насекомые, которые выбирают короткий и менее загруженный путь, влияют на вероятность выбора этого маршрута последующими муравьями в большей степени, чем муравьи, выбирающие худшие по длине и загрузке пути.
Это связано с тем, что первые муравьи раньше попадают в узел-приемник и имеют меньший возраст. Новые запросы отправляются по кратчайшим незагруженным маршрутам. Это позволяет балансировать ресурсы за счет разгрузки узлов на «плотных» направлениях в сети.
Одну из вариаций этого алгоритма использует фреймворк для P2P-приложений Anthill. Эта система представляет собой самоорганизующуюся сеть соединенных «камер муравейника» — узлов, способных проводить вычисления и обрабатывать данные.
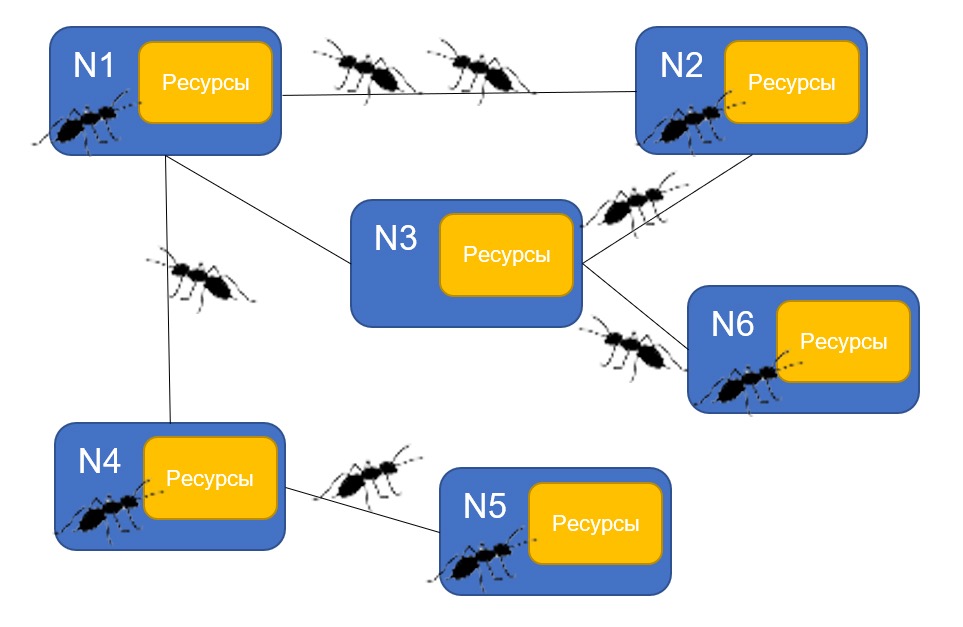
Структура сети-муравейника
Когда узел получает запрос от приложения, он запускает автономного агента — муравья, который должен выполнить поставленную задачу. Он движется по сети от узла к узлу до тех пор, пока не выполнит запрос. Перемещаясь, муравьи «носят» с собой информацию о запросе, результат и другие метаданные.
Муравьи не общаются друг с другом напрямую, вместо этого они оставляют необходимую для решения задачи информацию у менеджеров ресурсов, расположенных в посещаемых ими узлах. Например, муравей, реализующий службу поиска, может оставлять таким образом информацию о маршрутизации, которая бы помогала другим муравьям прокладывать дорогу к узлам, содержащим необходимые им данные. Подобная форма непрямой коммуникации используется и настоящими муравьями — это называется стигмергия.
Первые статьи, в которых описывался метод пчелиного роя, были опубликованы в 2005 году. Он основан на моделировании поведения пчёл при поиске нектара. В ульях есть так называемые пчелы-разведчики, которые ищут поляны с цветами. Когда они находят источник пищи, то возвращаются в улей, чтобы рассказать об этом другим с помощью специального «виляющего танца».

/ Flickr / Irregular Blog — Daedalus / CC BY-SA
Этим танцем пчела сообщает, насколько хороший нектар на поляне и как далеко она находится. После этого на её призыв откликаются пчелы-фуражиры, которые летят за разведчиком, собирают «урожай» и возвращаются в улей с «добычей». Затем пчела-фуражир может совершить одно из следующих действий: стать незанятым фуражиром, оставив текущий источник нектара, продолжить собирать его самостоятельно или позвать с собой несколько других незанятых пчел на помощь.
Эта модель применяется для балансировки нагрузки следующим образом. Первым делом вычисляется текущая нагрузка на виртуальные машины и определяется их состояние (сбалансированы, незагружены, перегружены) в зависимости от установленных ими пороговых значений. Если нагрузка на ВМ мала, то все новые задачи будут направляться ей.
В случае если в системе есть перегруженные виртуальные машины, каждая из них может принять на себя роль разведчика или фуражира. Обрабатывая запрос, виртуальный сервер вычисляет некое значение, являющееся аналогом «качества» поляны с цветами, которое демонстрирует пчелиный танец. Одним из вариантов оценки этого значения может быть время, которое затратит CPU на её выполнение. Затем сервер «рекламирует» эту задачу всей системе, как бы вывешивая её на доске объявлений — таким образом сервер принимает на себя роль разведчика. Другие серверы могут просмотреть эту доску объявлений и обработать выставленные там запросы, становясь фуражирами.
/ Flickr / Quinn Dombrowski / CC BY-SA
Динамические методы балансировки, в отличие от статических, в своей работе учитывают текущее состояние всей системы и реагируют на изменения в ней. Часто информация о загруженности узлов хранится в таблице состояний, из которой системы распределения нагрузки и черпают информацию.
Динамическое распределение нагрузки — выполняется мониторинг
Biased Random Sampling
Для реализации этого подхода сеть представляется в виде виртуального направленного графа, в которой все серверы — это вершины. При поступлении запроса на выполнение какой-либо задачи, балансировщик нагрузки назначает её той вершине (узлу), которая имеет полустепень захода равную как минимум единице.
Когда узел получает задачу, процессор начинает её выполнение и параллельно сигнализирует об уменьшении числа доступных вычислительных ресурсов, декрементируя полустепень захода. Когда задача «решена», узел инкрементирует этот показатель, сообщая о высвобождении ресурсов.
Выбор начальной вершины для выполнения задачи делается случайно (отсюда и random sampling); последующие задачи назначаются узлам-соседям, которые также выбираются в произвольном порядке. Этот метод балансировки нагрузки полностью децентрализован и потому подходит для работы в облачных сетях. В том числе географически распределенных.
Ученые из Ливерпуля установили, что Biased Random Sampling, дополнительно учитывающий географическое распределение узлов в сети, позволяет снизить латентность при передаче данных на 22%. В тесте с 512 узлами, расположенными в радиусе тысячи км, средняя задержка составила примерно 70 мс (в эксперименте с сетью, не учитывающей географического распределения узлов, этот показатель составлял 92,5 мс).
«Муравьиный» алгоритм оптимизации (Ant colony optimization)
Впервые эта концепция была представлена в начале девяностых годов. Она черпает вдохновение в поведении муравьев. Муравей всегда способен найти путь от источника пищи до муравейника даже в том случае, если привычный путь был «заблокирован». Для этого эти насекомые отмечают маршрут специальными феромонами. Считается, что чем сильнее этот «запах», тем ближе находится источник еды.
В контексте балансировки нагрузки в телекоммуникационных сетях это выглядит следующим образом. Сеть представляется в виде графа, и из всех возможных узлов выбирается главный, который имеет набольшее количество соседей. Коммутационные станции отображаются в узлы графа, а линии связи между ними — в ребра.
Каждый узел содержит «феромонную таблицу», в которой собраны данные об используемых ресурсах и доступных мощностях: количество памяти, число процессоров и др. Периодически из каждого узла запускаются муравьи, которые направляются в случайные узлы-приемники. «Насекомые» перемещаются между узлами, руководствуясь феромонной таблицей. Эта таблица обновляется каждый раз, когда к ней обращается муравей.
Муравьи имеют возраст, равный длине пройденного пути. Также муравьи задерживаются в узлах, переполненных вызовами. Те насекомые, которые выбирают короткий и менее загруженный путь, влияют на вероятность выбора этого маршрута последующими муравьями в большей степени, чем муравьи, выбирающие худшие по длине и загрузке пути.
Это связано с тем, что первые муравьи раньше попадают в узел-приемник и имеют меньший возраст. Новые запросы отправляются по кратчайшим незагруженным маршрутам. Это позволяет балансировать ресурсы за счет разгрузки узлов на «плотных» направлениях в сети.
Одну из вариаций этого алгоритма использует фреймворк для P2P-приложений Anthill. Эта система представляет собой самоорганизующуюся сеть соединенных «камер муравейника» — узлов, способных проводить вычисления и обрабатывать данные.
Структура сети-муравейника
Когда узел получает запрос от приложения, он запускает автономного агента — муравья, который должен выполнить поставленную задачу. Он движется по сети от узла к узлу до тех пор, пока не выполнит запрос. Перемещаясь, муравьи «носят» с собой информацию о запросе, результат и другие метаданные.
Муравьи не общаются друг с другом напрямую, вместо этого они оставляют необходимую для решения задачи информацию у менеджеров ресурсов, расположенных в посещаемых ими узлах. Например, муравей, реализующий службу поиска, может оставлять таким образом информацию о маршрутизации, которая бы помогала другим муравьям прокладывать дорогу к узлам, содержащим необходимые им данные. Подобная форма непрямой коммуникации используется и настоящими муравьями — это называется стигмергия.
«Пчелиный» алгоритм оптимизации (honeybee foraging)
Первые статьи, в которых описывался метод пчелиного роя, были опубликованы в 2005 году. Он основан на моделировании поведения пчёл при поиске нектара. В ульях есть так называемые пчелы-разведчики, которые ищут поляны с цветами. Когда они находят источник пищи, то возвращаются в улей, чтобы рассказать об этом другим с помощью специального «виляющего танца».
/ Flickr / Irregular Blog — Daedalus / CC BY-SA
Этим танцем пчела сообщает, насколько хороший нектар на поляне и как далеко она находится. После этого на её призыв откликаются пчелы-фуражиры, которые летят за разведчиком, собирают «урожай» и возвращаются в улей с «добычей». Затем пчела-фуражир может совершить одно из следующих действий: стать незанятым фуражиром, оставив текущий источник нектара, продолжить собирать его самостоятельно или позвать с собой несколько других незанятых пчел на помощь.
Эта модель применяется для балансировки нагрузки следующим образом. Первым делом вычисляется текущая нагрузка на виртуальные машины и определяется их состояние (сбалансированы, незагружены, перегружены) в зависимости от установленных ими пороговых значений. Если нагрузка на ВМ мала, то все новые задачи будут направляться ей.
В случае если в системе есть перегруженные виртуальные машины, каждая из них может принять на себя роль разведчика или фуражира. Обрабатывая запрос, виртуальный сервер вычисляет некое значение, являющееся аналогом «качества» поляны с цветами, которое демонстрирует пчелиный танец. Одним из вариантов оценки этого значения может быть время, которое затратит CPU на её выполнение. Затем сервер «рекламирует» эту задачу всей системе, как бы вывешивая её на доске объявлений — таким образом сервер принимает на себя роль разведчика. Другие серверы могут просмотреть эту доску объявлений и обработать выставленные там запросы, становясь фуражирами.
Другие материалы из корпоративного блога 1cloud:
Комментарии (2)

igordata
17.04.2018 01:58Прикольная статья, интересные подходы, спасибо. Следующей статьём можно сделать обзор реализаций.
mediaman
Про метод «муравьиной колонии», который используется не только для распределения нагрузки, но и для решения задачи коммивояжёра и NP-сложных задач, можно тут почитать у MIT: pdfs.semanticscholar.org/7c72/393febe25ef5ce2f5614a75a69e1ed0d9857.pdf