

Перевод How to create a Neural Network in JavaScript in only 30 lines of code.
В этой статье мы рассмотрим, как можно создать и обучить нейросеть с помощью библиотеки Synaptic.js, позволяющей проводить глубокое обучение в связке Node.js с браузером. Давайте создадим простейшую нейросеть, решающую XOR-уравнение. Также можете изучить специально написанный интерактивный туториал.
Но прежде чем переходить к коду, давайте поговорим об основах нейросетей.
Нейроны и синапсы
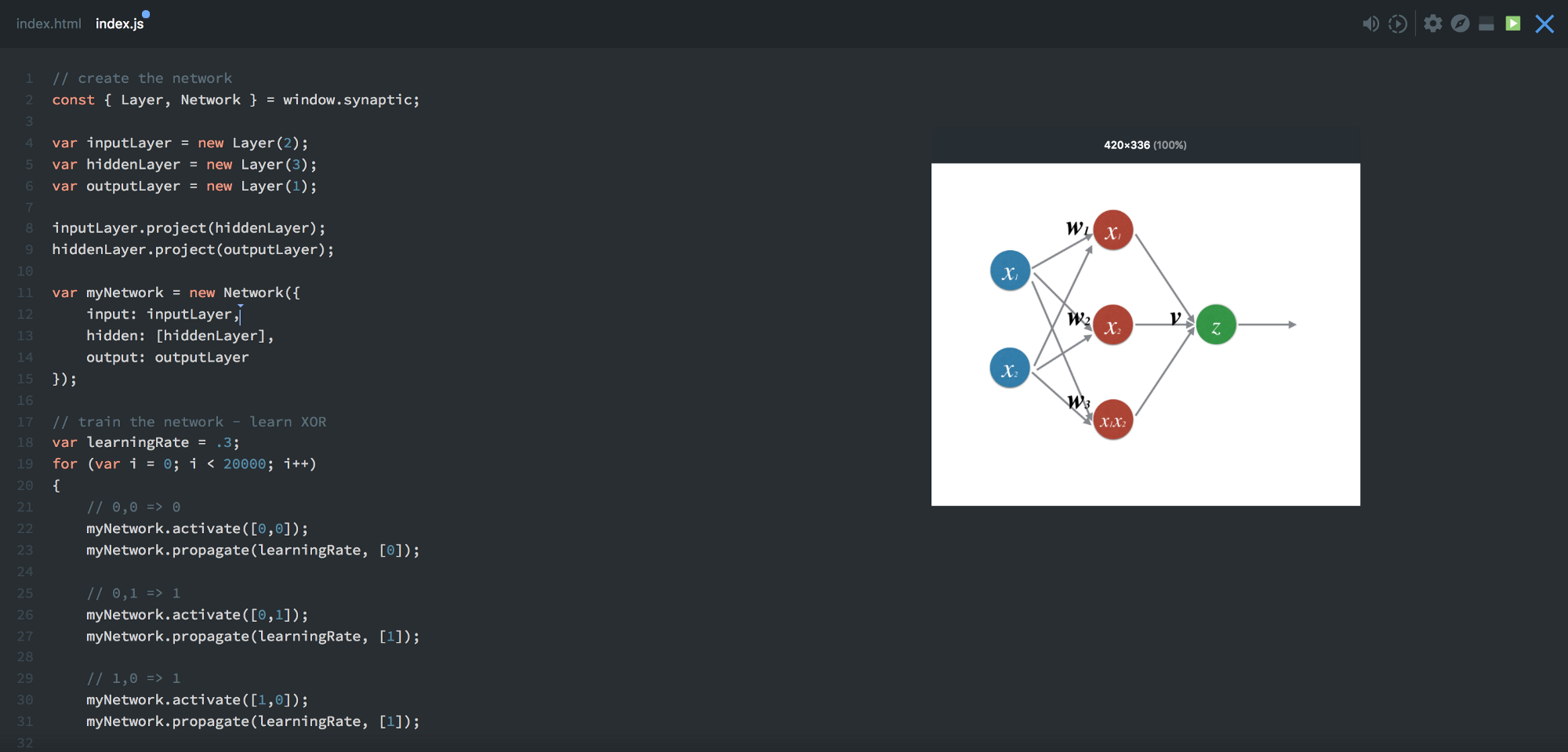
Основной «строительный» элемент нейросети, конечно же, нейрон. Как и функция, он берёт несколько входных значений и выдаёт какой-то результат. Есть разные виды нейронов. Наша сеть будет использовать сигмоиды, берущие любые числа и сводящие их к значениям в диапазоне от 0 до 1. Ниже проиллюстрирован принцип действия такого нейрона. На входе у него число 5, а на выходе 1. Стрелки обозначают синапсы, соединяющие нейрон с другими слоями нейросети.
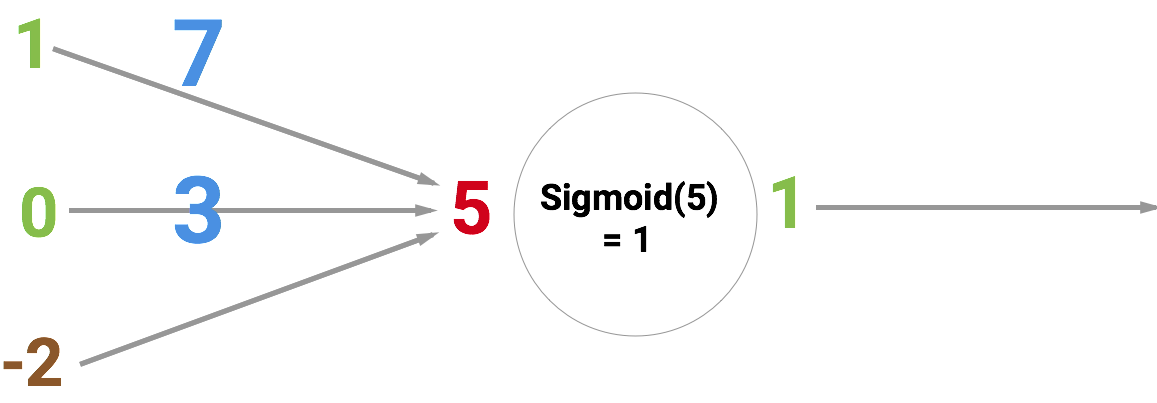
Но почему на входе у нас число 5? Это сумма трёх синапсов, «входящих» в нейрон. Давайте разберёмся.
Слева мы видим значения 1 и 0, а также смещение -2. Сначала первые два значения умножаются на их веса, которые равны 7 и 3, полученные результаты складываются и к ним прибавляется смещение, получаем 5. Это и будет входным значением для нашего искусственного нейрона.
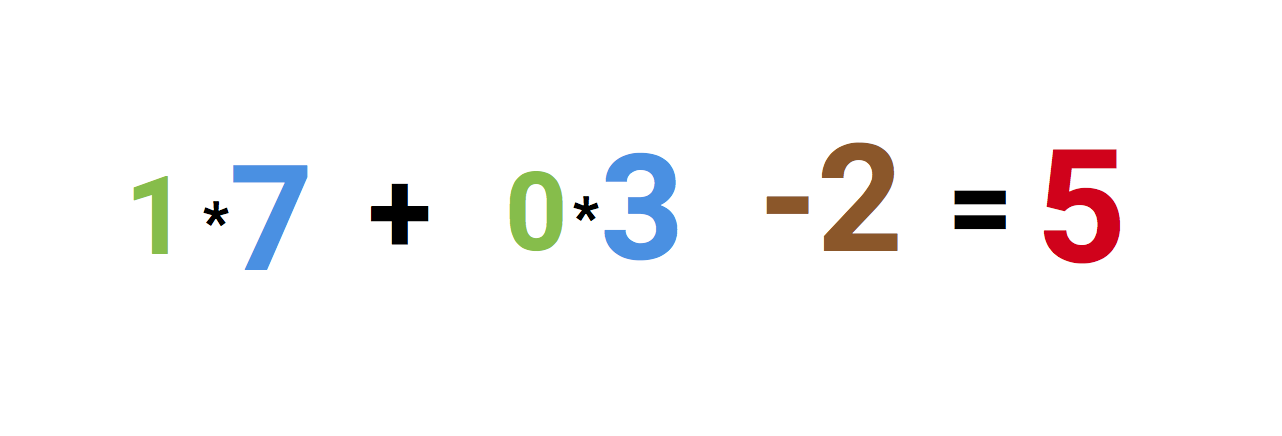
А поскольку это сигмоида, которая любое значение сводит к диапазону от 0 до 1, то выходным значением будет 1. Если такие нейроны соединить друг с другом с помощью синапсов, то получится нейросеть, по которой значения проходят от входа к выходу и трансформируются. Примерно так:
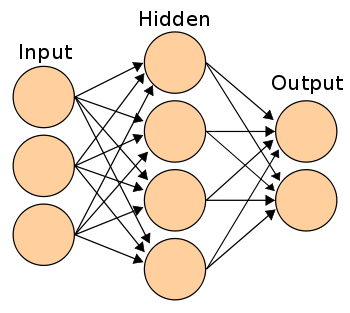
Нейросеть обучается делать обобщения ради решения всевозможных задач, например, распознавания рукописного текста или почтового спама. И умение хорошо обобщать зависит от выбора правильных весов и смещений в рамках всей нейросети.
Для обучения вы просто даёте набор образцов и заставляете нейросеть обрабатывать их раз за разом, пока она не станет давать правильный ответ. После каждой итерации вычисляется точность прогнозирования и корректируются веса и смещения, чтобы в следующий раз ответ нейросети оказался чуть точнее. Такой процесс обучения называется методом обратного распространения ошибки (backpropagation). Если провести тысячи итераций, то ваша нейросеть научится хорошо обобщать.
Работу метода обратного распространения ошибки мы рассматривать не будем, это выходит за рамки нашего руководства. Но если вас интересуют подробности, то можете почитать эти статьи:
Код
Первым делом создадим слои, и сделаем это в синаптическом режиме с помощью функции
new Layer(). Передаваемое ей число означает количество нейронов в свежем слое. Если вы не знаете, что такое слой, то посмотрите вышеупомянутый туториал.const { Layer, Network } = window.synaptic;
var inputLayer = new Layer(2);
var hiddenLayer = new Layer(3);
var outputLayer = new Layer(1);Теперь соединим слои друг с другом и инстанцируем новую сеть.
inputLayer.project(hiddenLayer);
hiddenLayer.project(outputLayer);
var myNetwork = new Network({
input: inputLayer,
hidden: [hiddenLayer],
output: outputLayer
});У нас получилась сеть по схеме 2–3–1, которая выглядит так:
Давайте её обучим:
// train the network - learn XOR
var learningRate = .3;
for (var i = 0; i < 20000; i++) {
// 0,0 => 0
myNetwork.activate([0,0]);
myNetwork.propagate(learningRate, [0]);
// 0,1 => 1
myNetwork.activate([0,1]);
myNetwork.propagate(learningRate, [1]);
// 1,0 => 1
myNetwork.activate([1,0]);
myNetwork.propagate(learningRate, [1]);
// 1,1 => 0
myNetwork.activate([1,1]);
myNetwork.propagate(learningRate, [0]);
}Мы прогнали 20 000 итераций обучения. В каждой итерации данные четыре раза прогоняются вперёд-назад, то есть на вход подаются четыре возможные комбинации значений:
[0,0] [0,1] [1,0] [1,1].Начнём с выполнения
myNetwork.activate([0,0]), где [0,0] — входные данные. Это называется прямым распространением (forward propagation), или активацией нейросети. После каждого прямого распространения нужно сделать обратное, при котором нейросеть обновляет свои веса и смещения.Обратное распространение выполняется с помощью
myNetwork.propagate(learningRate, [0]), где learningRate — константа, означающая, насколько нужно каждый раз корректировать веса. Второй параметр 0 представляет собой правильное выходное значение при входном [0,0].Далее нейросеть сравнивает получившееся выходное значение с правильным. Тем самым она определяет точность собственной работы.
По результатам сравнения нейросеть корректирует веса и смещения, чтобы в следующий раз ответить немного точнее. После 20 000 таких циклов можно проверить, насколько хорошо обучилась наша нейросеть, активировав её с помощью всех четырёх возможных входных значений:
console.log(myNetwork.activate([0,0]));
-> [0.015020775950893527]
console.log(myNetwork.activate([0,1]));
->[0.9815816381088985]
console.log(myNetwork.activate([1,0]));
-> [0.9871822457132193]
console.log(myNetwork.activate([1,1]));
-> [0.012950087641929467]Если округлить результаты до ближайших целочисленных значений, то получим точные ответы для XOR-уравнения. Работает!
На этом всё. Хотя мы лишь самую малость копнули тему нейросетей, вы уже можете самостоятельно поэкспериментировать с Synaptic и продолжить самообучение. В wiki авторов библиотеки есть ещё много хороших руководств.
Комментарии (10)

dopusteam
23.04.2018 13:56+5Вопрос: Как создать нейросеть всего из 30 строк JavaScript-кода
Ответ: использовать готовую библиотеку и не считать её строки кода

zigrus
23.04.2018 14:04+2на выходе я получил 0 или 1
а дальше что?
дал ей рукописные каляки маляки, она выдала мне выдала текст. как?
как 0 или 1 даст мне тот самый текстdopusteam
23.04.2018 14:51Не уместилось в 30 строк)
Вторая часть, наверное, будет:
Как использовать то, что получили из нейросети, созданной из 30 строк на js, за 30 строк Javascript кода

Fragster
23.04.2018 15:46+1Запихав 20000 раз всю таблицу решений для всех возможных входных сигналов мы получили почти точное (точное после округления) решение для тех же входных сигналов.
Можно что-то более приближенное к реальности? Чтобы сеть искала ответ для того, что мы в неё еще не запихивали?

Apache02
23.04.2018 21:47Synaptic не лучшая реализация:
— структура в виде отдельных нейронов. Гораздо удобнее рассматривать сеть слоями, отдельные нейроны не нужны. А если мы храним слоями, то удобнее веса хранить в матрицах. А если мы хотим сверточную, то на входе данные 3х мерный массив (x, y, rgb_channel), а это уже тензор. В архитектуру библиотеки заложено, что на входе вектор.
— backpropagate.
— В принципе все хорошо. Но каждый вызов этого механизма заставляет сеть обновить веса. А где же концепция батчей? Сеть должна уметь накапливать градиент для нескольких примеров которым учится, а потом перенастраивать веса. Нет, synaptic этого не умеет. В более современных реализациях бэкпроп и градиент хранит обучающий агент, то есть не сеть делает обратное распределение ошибки, а учитель, но я думаю это уже избыточно.
— При расчете градиента не умножается на производную от функции активации. Я писал реализацию backpropagate на JS читая medium.com/@14prakash/back-propagation-is-very-simple-who-made-it-complicated-97b794c97e5c, потом написал учителя для XOR который будет работать и с моей реализацией и с Synaptic. Оказалось, что у меня нужно раз в 5 больше итераций. Убрал умножение на производную функции активации и результаты совпали. Я не могу обосновать что это умножение нужно, но так написано во всех описаниях метода.
Моя черновая реализация на JS: github.com/Apache02/node-yann
Работает медленнее. В Synaptic круто используются оптимизации.
roryorangepants
24.04.2018 07:22То, что вы называете «уровни», традиционно в русском переводе называется «слои» (отсюда, например, термин «многослойный перцептрон»).
roryorangepants
24.04.2018 07:26+1Также, то, что в переводе названо «бацесовым значением», не имеет отношения к Байесу и обычно по аналогии с линейной регрессией называется «сдвигом», «смещением» или «константой». Или просто не переводится.

{kind=link}
AndreyMtv
Еще одинтуториал из серии "как нарисовать сову".
Раз уж вы об этом упомянули, то не хотите ли показать, как данная нейросеть рукописный текст распознает?