

Несколько дней назад компания Splunk выпустила новый релиз своей платформы Splunk 7.1 в котором, наверно, произошло самое ожидаемое изменение за последние несколько лет — да, полностью изменился графический интерфейс. В этой статье мы расскажем об основных нововведениях и улучшениях платформы. Что еще нового помимо GUI? Смотрите под кат.
Интерфейс
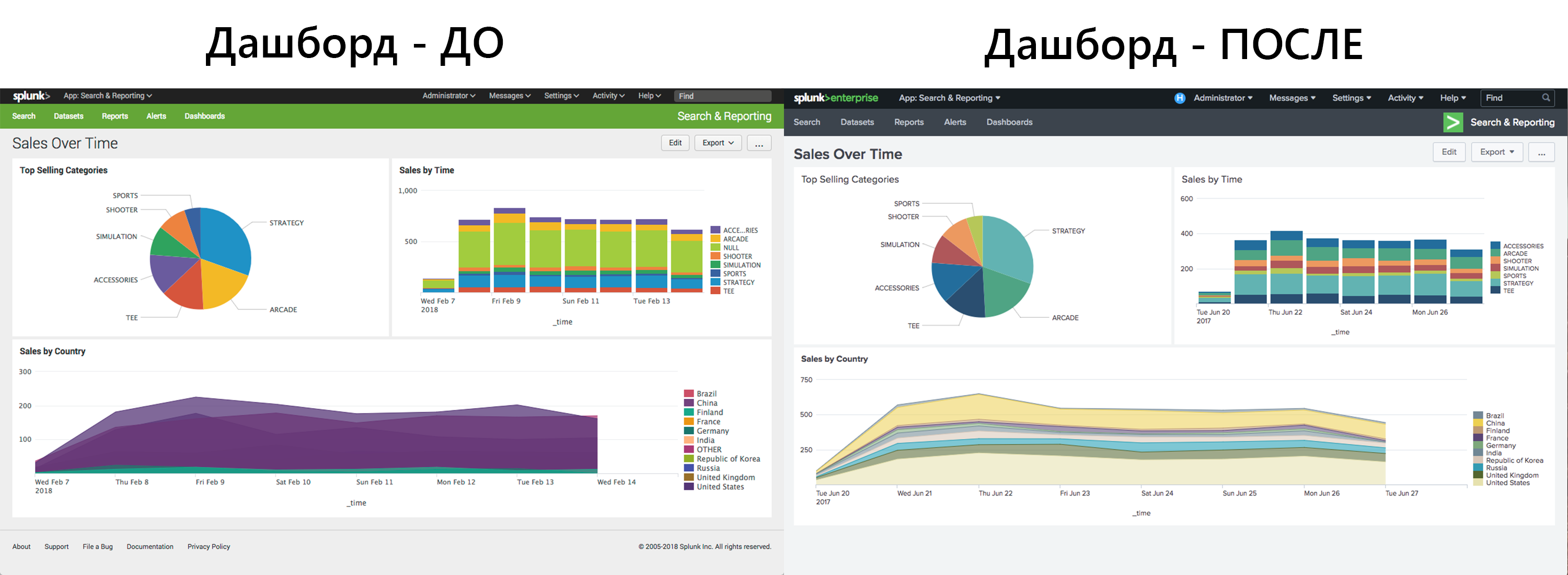
Как мы уже сказали, да, и наверно это самое заметное изменение, Splunk полностью поменял интерфейс, вплоть до изменения страницы с ошибкой. Внешний вид становится более современным и стильным. Исправлены элементы диаграмм и просмотра событий для повышения удобства восприятия информации. После обновления немного непривычно, но попользовавшись системой пару дней — привыкаешь и начинает нравится. Да, действительно нравится.
Интеграция с Apache Kafka
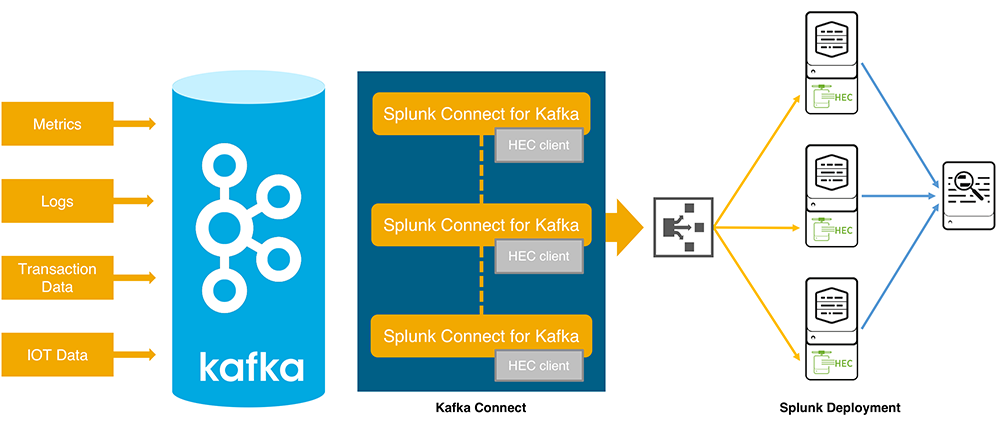
У Splunk появился коннектор для Kafka. Теперь вы можете стримить ваши данные с Kafka в инсталляцию Splunk, используя Splunk HTTP эвент коллектор. Также в этом релизе Splunk предлагает возможность интеграции с AWS Kinesis Firehose, но в наших реалиях это менее интересно. Подробное описание функционала и инструкция по деплою доступны здесь.
Контроль доступа
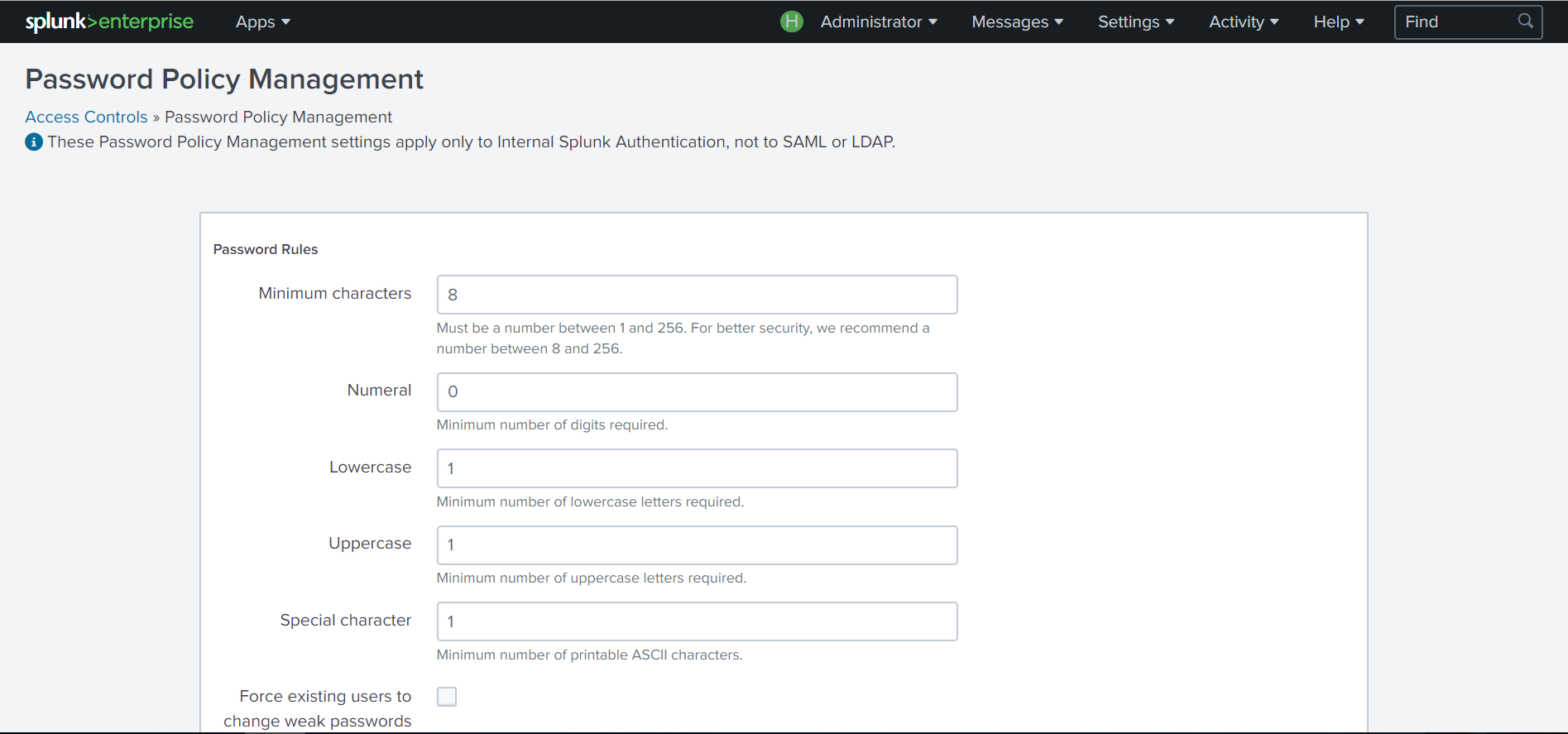
Splunk начал серьезно задумываться о безопасности своей платформы и начиная с этого релиза вы забудете о комбинации admin/changeme. Теперь вам будет предложено ввести пароль на этапе установки с требованием в 8 символов.

Также в новой версии в целях повышения безопасности появилась возможность настройки расширенных политик учетных записей. Теперь администратор Splunk может устанавливать требования к сложности пароля, срок действия, блокировку после повторных неудачных попыток входа.
Мониторинг состояния компонентов Splunk
Ура! Splunk становится более общительным. Теперь когда что-то ломается на этапе сбора/парсинга/индексирования он сам будет пытаться говорить нам об этом и нам не нужно смотреть в лог _internal и искать, что случилось.
В версии Splunk 7.1 реализована возможность мониторинга работоспособности компонентов Splunk. При отклонениях Splunk может указать причину, сообщения о возникших ошибках и дать советы для решения проблемы. Статус работоспособности указан в строке меню.


Усовершенствование метрик и новые SPL-команды
В релизе 7.0 Splunk появился новый тип индексации данных – метрики. Более подробно о них вы можете прочитать в нашем обзоре Splunk 7.0. Использование метрик повышает обработку поисковых запросов и уменьшает общую нагрузку на систему. Но в первом релизе инструментарий для работы с метриками был несколько ограничен.
В новой версии была улучшена команда mstats, а также добавлена команда mcollect.
1. Улучшение mstats
В 7.0 мы могли вычислять только один показатель в этой команде. И для того, чтобы посчитать сразу несколько приходилось использовать дополнительные инструменты, которые усложняли поисковый запрос.
Например:
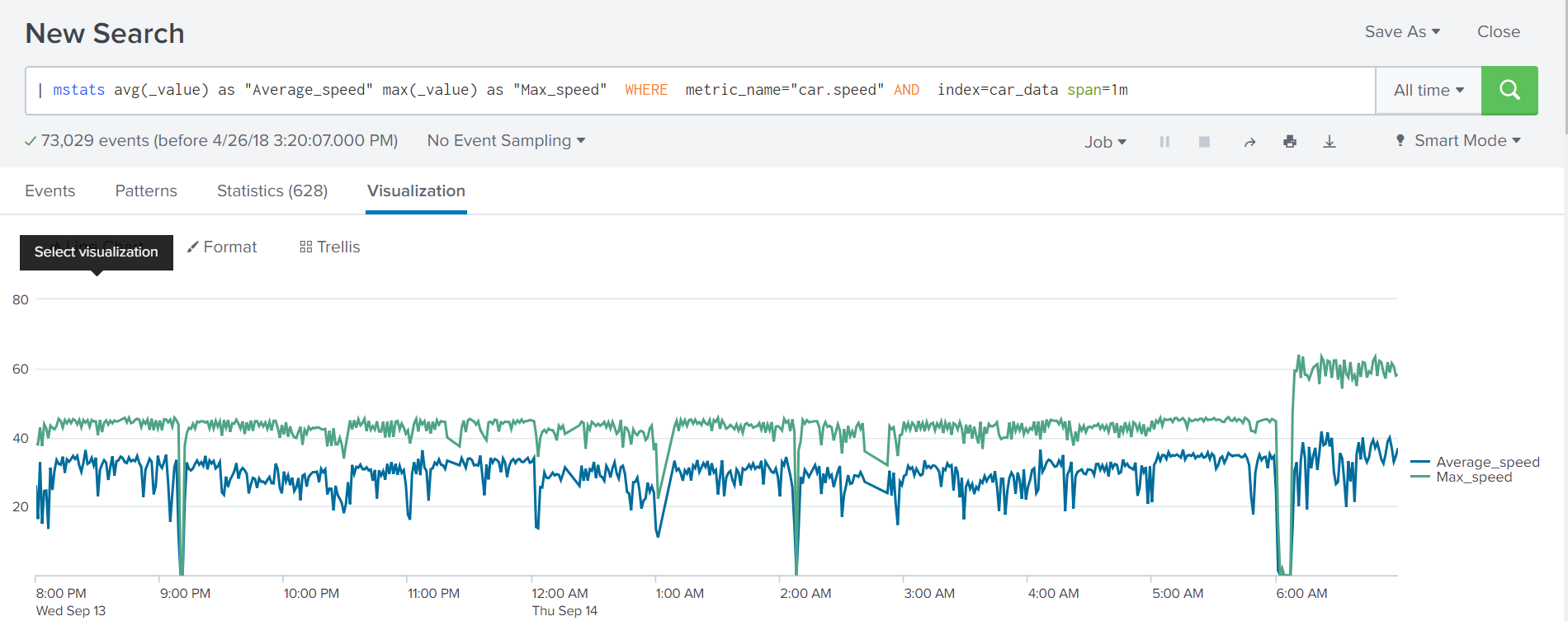
| mstats avg(_value) as "Average_speed" WHERE metric_name="car.speed" AND index=car_data span=1m
| appendcols [
| mstats max(_value) as "Max_speed" WHERE metric_name="car.speed" AND index=car_data span=1m ]В версии 7.1 появилась возможность вычислять сразу несколько показателей в одной команде.
| mstats avg(_value) as "Average_speed" max(_value) as "Max_speed" WHERE metric_name="car.speed" AND index=car_data span=1m
2. Новая команда mcollect
С помощью команды mcollect мы можем преобразовывать результаты поиска в метрики. Перед выполнением команды необходимо создать новый индекс для метрик, в который мы будем сохранять показатели.
Например, создадим метрику количества ошибок:
ERROR | stats count BY type | rename count AS _value type AS metric_name | mcollect index=my_metric_indexИ да, забыли сказать, они увеличили скорость работы с метриками в 10 раз. Теперь поиск по метрикам еще быстрее!
Обновление Machine Learning Toolkit
Также был обновлен инструментарий ML Toolkit, который позволяет получать из Ваших данных ответы на важные вопросы об аномалиях, прогнозах и разделении на кластеры, используя различные алгоритмы машинного обучения.
X-means
В первую очередь следует отметить добавление нового алгоритма кластеризации X-means, который отличается от стандартного алгоритма кластеризации, K-means, тем, что автоматически определяет оптимальное количество кластеров по Байесовскому информационному критерию. Алгоритм X-means удобно использовать, когда Вы предварительно не знаете на сколько кластеров можно разделить данные.
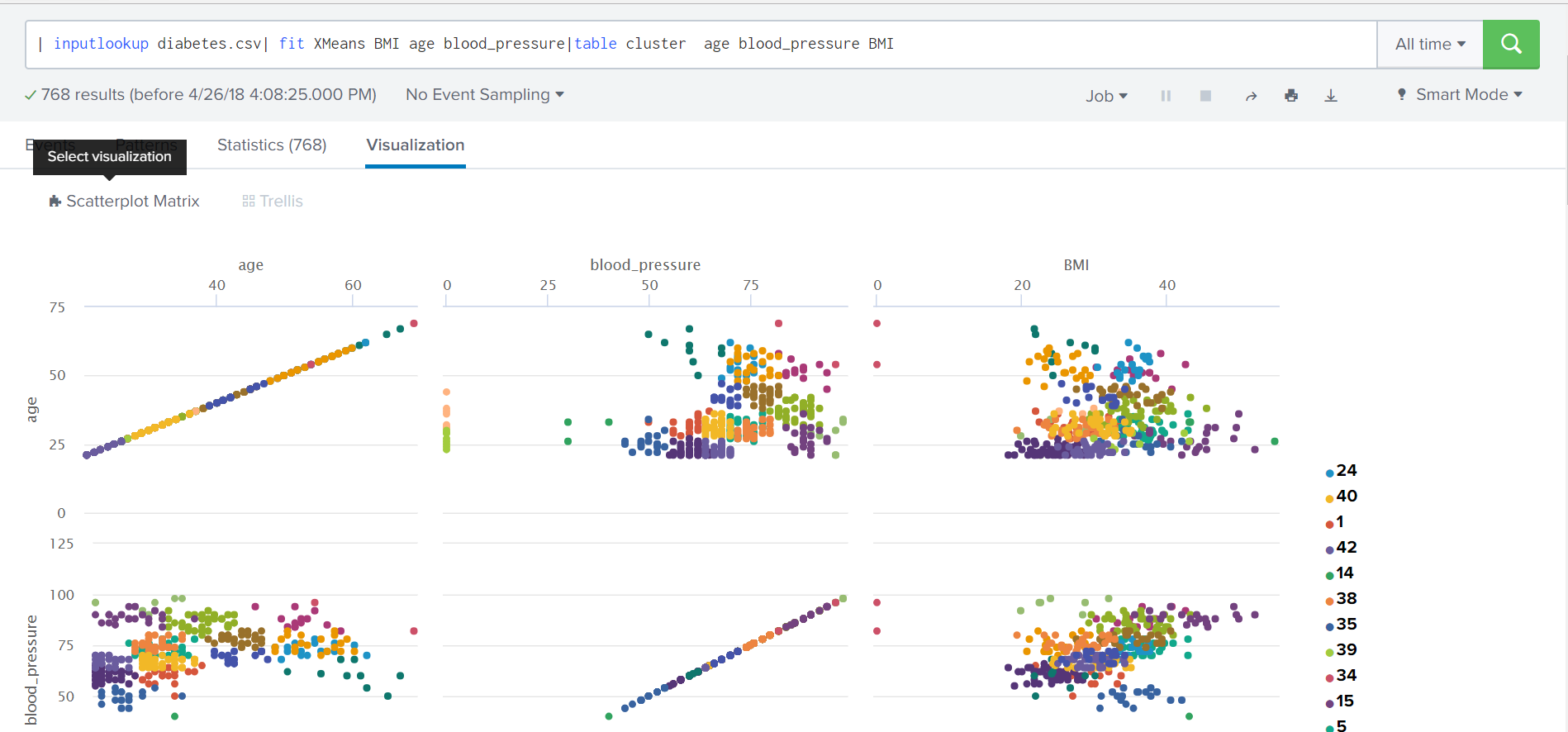
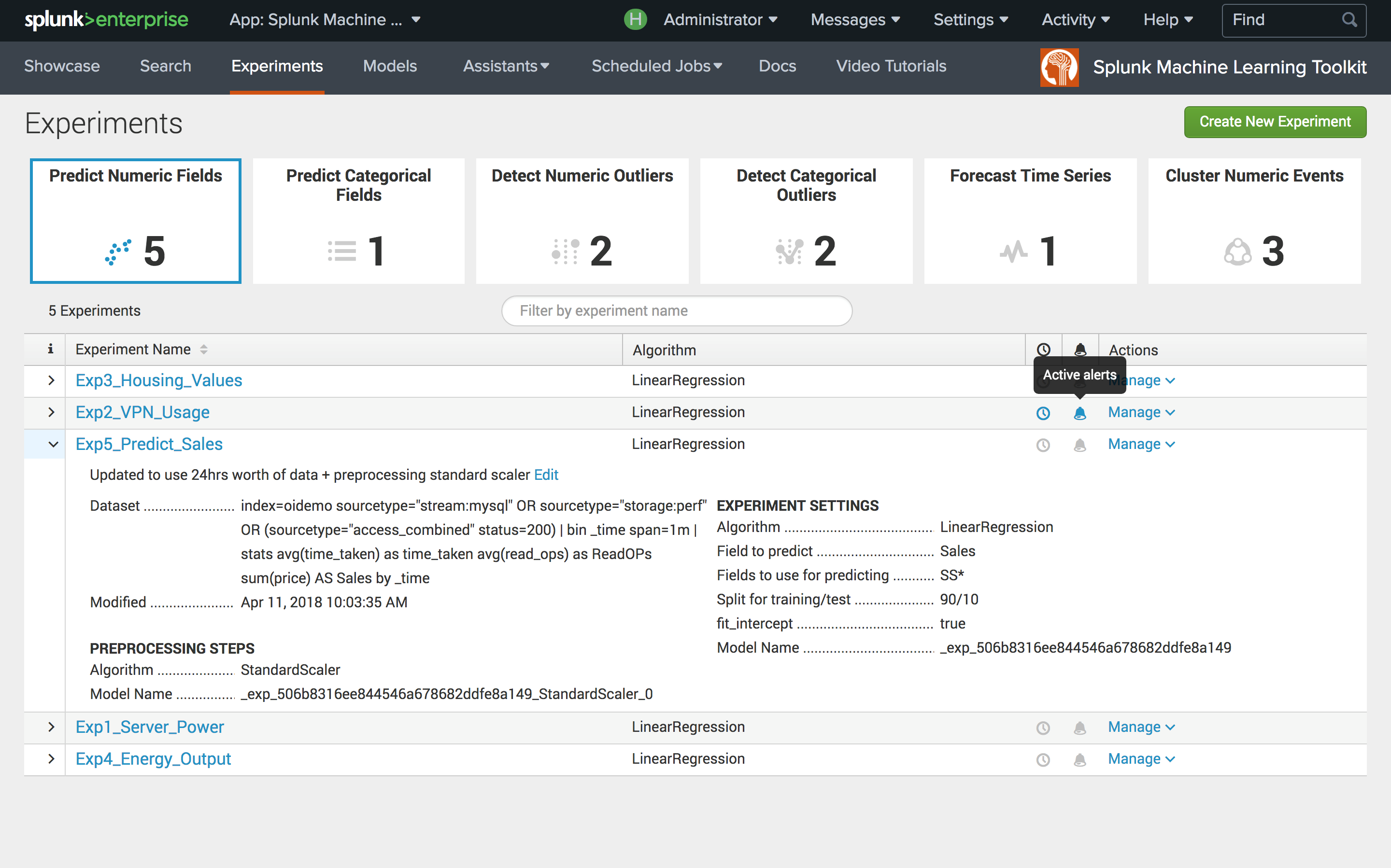
Управление моделями и экспериментами
Также появился единый интерфейс, позволяющий просматривать существующие модели и их параметров, настраивать доступ к экспериментам для различных ролей пользователей, устанавливать алерты, получать историю экспериментов и алертов.
Заключение
Конечно, в новом релизе есть еще множество нововведений и фич, например таких как: Diagnostic UI, оптимизация работы с кластерами: минимизировано влияние на работу системы при обновлениях, перезапусках, регулярных запланированных поисковых запросах и многие другие изменения. В рамках статьи мы попытались рассказать Вам о наиболее интересных нововведениях, с которыми может столкнуться каждый, кто использует Splunk.
Дополнительно
Для наиболее глубокого изучения вопроса стоит установить приложение Splunk Enterprise 7.1 Overview, а также посмотреть официальное видео релиза.
Также, не забывайте, что по любым вопросом относительно Splunk: его внедрения, обновления, разработки на нем приложений, добавления новых, сложно индексируемых событий и всего прочего мы можем помочь вам.
Мы являемся официальным Premier Партнером Splunk.

Комментарии (6)

outcoldman
27.04.2018 18:36Изменения в Контроли доступа вызовет боль для тех, кто автоматизирует установку Splunk.
У Splunk есть отличная документация, как установить изначальный пароль docs.splunk.com/Documentation/Splunk/7.1.0/Security/Secureyouradminaccount
Мы так же написали блог пост о том, как использовать теперь Splunk Docker Image www.outcoldsolutions.com/blog/2018-04-25-docker-splunk-7-1-0 после этих нововведений.
achekalin
27.04.2018 19:13Некоторое время назад все спрашивали про OpenSource конкурентов — чем они лучше Splunk. Сегодня, я смотрю, вопрос задается ровно наоборот — за что платить деньги за лицензию, и можно ли то же сделать на менее дорогих (но, как на вид, не всегда менее хороших) решениях.
SoNicKKK
28.04.2018 12:16По поводу mstats. Несколько показателей в одной команде можно было вычислять и в 7.0. В частности, ваш пример для 7.1 отлично отработал бы и в 7.0.*.
Разница в том, что в 7.0 можно было делать вычисления только по полю _value. Так что если надо было рассчитать статистику по разным метрикам, то приходилось писать что-то вроде такого:
| mstats avg(_value) as value where index=metric_index metric_name=metric1 OR metric_name=metric2 span=1min by metric_name
| timechart span=1min max(value) as value by metric_name
В 7.1 же можно имя метрики сразу писать внутри стат.функции:
| mstats avg(metric1) as metric1, avg(metric2) as metric2 where index=metric_index span=1min
Так что новый функционал тут особо не привнесли, но синтаксически стало приятнее (а использование _value в mstats теперь deprecated).
Главная проблема с метрическими индексами в том, что если повторно отправить в метрический индекс метрику с таким же именем и dimensions, то в индексе будут содержаться оба значения. Очевидно, что это может плохо повлиять на вычисляемые статистики по этим метрикам. Возможными вариантами решения проблемы могли быть либо возможность избирательно удалять данные из метрического индекса (сделать аналог команды delete), либо настройка индекса, которая позволяла бы хранить только последнее значение по имени метрики и dimensions. Но этого пока нет, и приходится очень аккуратно настраивать сбор данных в метрические индексы.
igor_suhorukov
У Slunk есть два главных недостатка: большая цена и большая задержка от поступления данных в систему до времени их доступности к анализу. При большом количестве open source конкурентов исход сравнения явно не в его пользу…
AlexKulakov
Это если сравнивать цену с ценой open source (которая ноль). Но если использовать более менее адекватную модель затрат, включающую затраты на внедрение, железо, зп сотрудников (об этом вообще никто никогда не вспоминает, хотя это ежемесячные расходы, и достаточно большие, если учесть что это квалифицированные сотрудники), затраты на поддержку, затраты на дополнительные платные фичи ( у open source они всегда есть иначе где модель монетизации бизнеса), список можно продолжать.
Судя по тому как растет его популярность, пока явно наоборот:
www.fool.com/investing/2017/04/05/splunk-in-2-charts.aspx
Здесь хотелось бы примеров, потому как не слышал о такой проблеме ранее.
outcoldman
Если мы говорим про ELK, то я рекомендую посмотреть на ответ сравнение между ELK и Splunk answers.splunk.com/answers/616416/what-is-the-difference-between-splunk-and-elk-stac.html?childToView=617933#answer-617933
С моей точки зрения, их сложно сравнивать без понимания ваших задач, и сколько времени вы готовы уделять поддержки решения.
Поэтому я бы не сказал, что это верное замечание «При большом количестве open source конкурентов исход сравнения явно не в его пользу». It depends.