
А вот внедряют аналитику все по-разному: кто-то покупает сторонние решения (просто, но негибко), кто-то пишет под себя (долго и дорого), а кто-то пока просто считает несколько базовых метрик силами программистов и не заморачивается.
Поэтому я расскажу об инструменте, который будет полезен для всех. Кто только начинает выстраивать аналитику — сможет «на коленке» создать систему с нуля, а компании с уже готовыми решениями — «бустануть» свой подход.

Речь пойдет об Apache Zeppelin. Это многофункциональная интерактивная оболочка, которая позволяет выполнять запросы к различным источникам данных, обрабатывать и визуализировать результаты.
Достаточно близкий аналог — Jupyter Notebook, но Zeppelin несколько более заточен под работу с базами данных. Он использует концепцию «интерпретаторов» — плагинов, которые обеспечивают бэкэнд для какого-либо языка и/или БД.
Zeppelin, как и Jupyter, для пользователя выглядит как набор файлов-ноутбуков, состоящий из параграфов, в которых пишутся и исполняются запросы. С помощью встроенных визуализаторов ноутбук с набором запросов легко превратить в полноценный дашборд с данными.
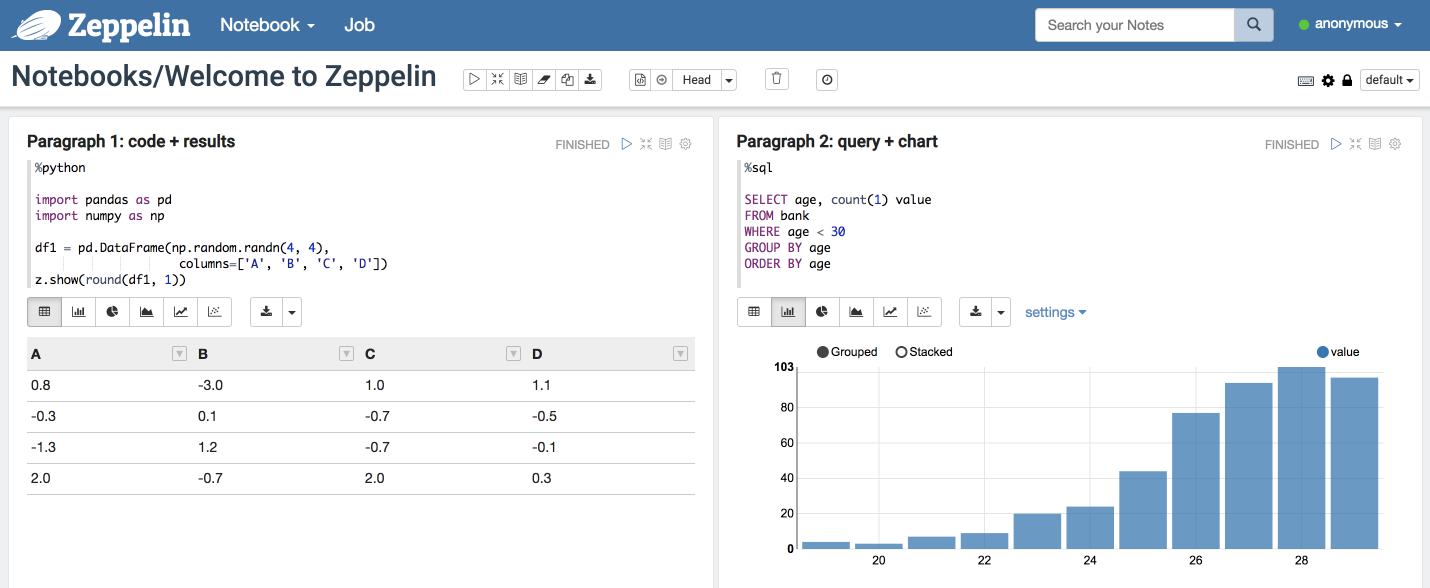
Намеренно не будем касаться вопросов установки и настройки — это есть и в документации на сайте, и в сети можно найти несколько туториалов под разные БД. Цель статьи — рассказать о пользовательской стороне вопроса, интересных применениях инструмента (в том числе не самых очевидных) и преимуществах, которые аналитики могут из него извлечь, вне зависимости от того, каким решением они уже пользуются.
В качестве примеров расскажу, для чего мы используем его в Pixonic (как раз тот кейс, когда в компании уже есть собственная производительная система аналитики).
Итак, пойдем по порядку.
Всеядность Zeppelin
Комбинирование различных источников данных — в рамках одного дашборда
— одно из его ключевых преимуществ. В рамках стандартной сборки включено внушительный набор интерпретаторов (к NoSQL и реляционным базам).
На практике это дает следующее:
- Большинство компаний с уже работающими БД и системами аналитики могут использовать его «из коробки» (насколько это применимо к опенсорсным продуктом, хех). Энтузиасты же с более экзотичными БД могут написать интерпретатор самостоятельно, о чем на сайте продукта есть статья.
- Небольшие компании, при желании, могут построить свою систему аналитики исключительно из БД и Zeppelin в качестве интерфейса.
- Как показывает опыт общения с коллегами — у многих данные могут стекаться из разных источников, храниться в разных базах (ле-е-егаси!), кто-то может пользоваться дополнительно сторонними сервисами аналитики. Соответственно, перед аналитиками порой встают задачи «подружить» такой зверинец между собой. Zeppelin же позволяет внутри одного ноутбука использовать свой интерпретатор для каждого параграфа, что позволит выводить результаты запросов к разным источникам в одном месте.

Zeppelin + Python/R
Zeppelin — это не только веб-интерфейс для различных баз данных, но и может выступать интерактивной оболочкой для выполнения скриптов на языках программирования. В него входят интерпретаторы для R и Python, потому он вполне может выступать альтернативой привычным RStudio и Jupyter. Да, он предоставляет меньше возможностей, чем специализированные IDE (например, нет автоподстановки), но это компенсируется преимуществами, о которых поговорим ниже.
В связке с тем же Python’ом могущество Zeppelin многократно возрастает: тут тебе и возможность получения данных по API из сторонних сервисов (привет предыдущему пункту), и возможность производить обработку данных помимо обычных запросов к БД, а также автоматизация этих процессов. Zeppelin поддерживает обновление дашбордов по крону без лишних телодвижений (опять же, беглый взгляд на решения коллег показывает, что эту, вроде бы тривиальную задачу, порой приходится решать весьма хитровыдуманными способами). Ну и на сладкое: в нем есть встроенная система контроля версий — примитивная, но достаточная для большинства задач аналитиков.
Мы в компании активно используем Python наряду с AppMetr (внутренняя система аналитики) для проведения сложной обработки данных. Потому, идея попробовать Zeppelin появилась именно применительно к нашим скриптам — мы увидели в этом потенциал упростить ряд рутины, связанной, например, с визуализацией результатов.
Визуализация всего на свете — одним кликом
Zeppelin может отображать выведенные в параграфе данные в виде нескольких базовых визуализаторов, работающих по принципу сводных диаграмм: в интерфейсе выбираются поля, по которым будут строиться оси и как будут агрегироваться выводимые значения. Получившиеся диаграммы кликабельны и позволяют с легкостью посмотреть данные в разных разрезах.
Эта, с виду скромная, функциональность покрывает до 95% задач аналитиков по визуализации результатов. Можно прекратить бесконечный экспорт выгрузок в Excel только для построения графика, и даже забыть такие страшные слова как matplotlib, bokeh и ggplot2 — результаты работы скриптов также превращаются в графики парой кликов.
Впрочем, для более сложных визуализаций названия графических библиотек можно вспомнить снова — Zeppelin имеет встроенную интеграцию с самыми популярными графическими библиотеками для Python и R:
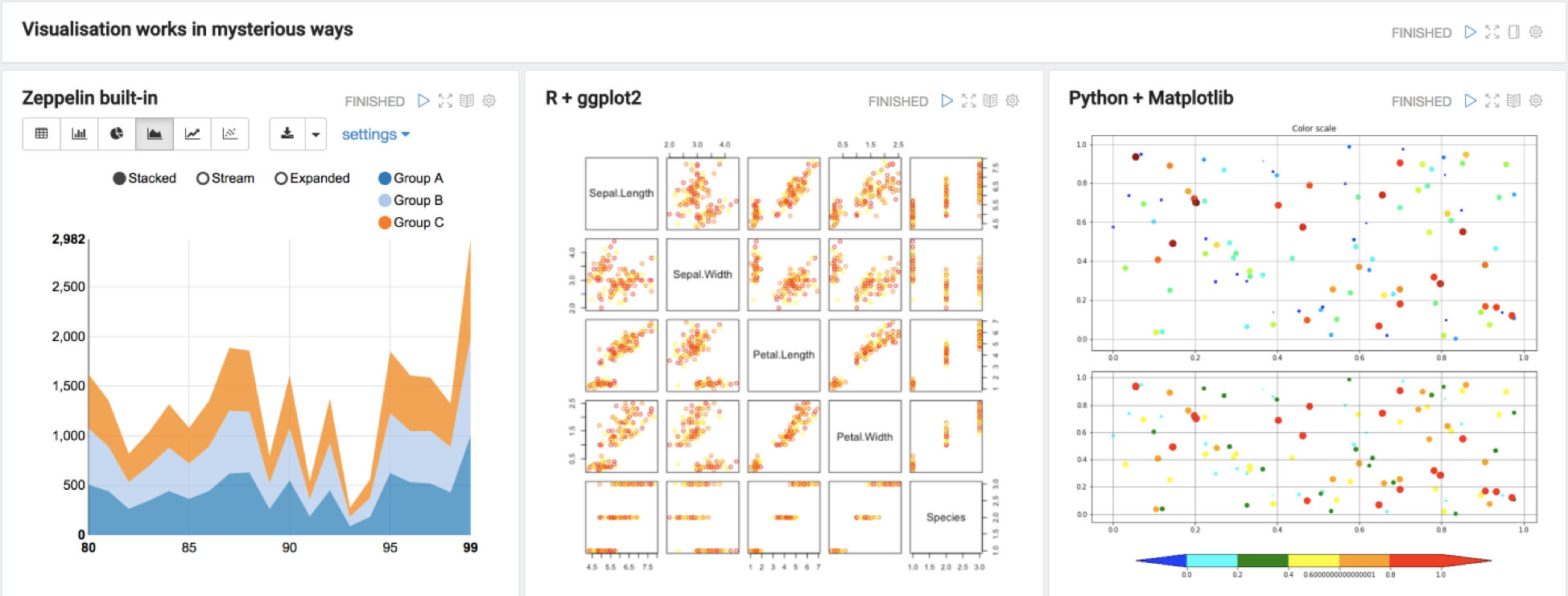
Совместная работа и настройка интерфейсов
Zeppelin может работать локально и использоваться просто как инструмент аналитика, но если развернуть его на сервере, можно при желании превратить его в корпоративный аналитический сервис с авторизацией через LDAP и настройками доступа. В зависимости от потребностей в аналитике, он может выступать как набором дашбордов по метрикам проекта, так и общим хранилищем скриптов и выгрузок, или, например, пространством для совместной работы аналитиков. Приятный бонус: пропадает необходимость обмениваться какими-то файлами или заводить новый док в Confluence — можно просто скинуть ссылку на дашборд.
В этом аспекте важную роль играет гибкость в настройке интерфейса и возможность генерировать простые формы для ввода значений. Конечно, аналитики чувствуют себя комфортно при виде SQL запросов и коде на R, но вот неподготовленных юзеров это может вгонять в ступор. Поэтому в дашборде Zeppelin можно скрыть код (что, например, проблема для Jupyter’а), сделать поля для ввода дат и других меняющихся параметров и отдать заказчику опрятную и понятную форму.
В нашей компании многие процессы завязаны на аналитику, поэтому разным отделам периодически нужны какие-то специфические выгрузки, например пересчитать балансную таблицу по свежим данным. Для таких вещей у нас давно написаны скрипты, но их еще должен кто-то запускать. А вы пробовали когда-нибудь научить пользоваться Jupyter’ом 20 геймдизайнеров? В итоге мы элегантно решили эту проблему, переложив скрипты в Zeppelin, где, например, ГД могут получить нужные им данные, просто нажав одну кнопку. Или не одну:
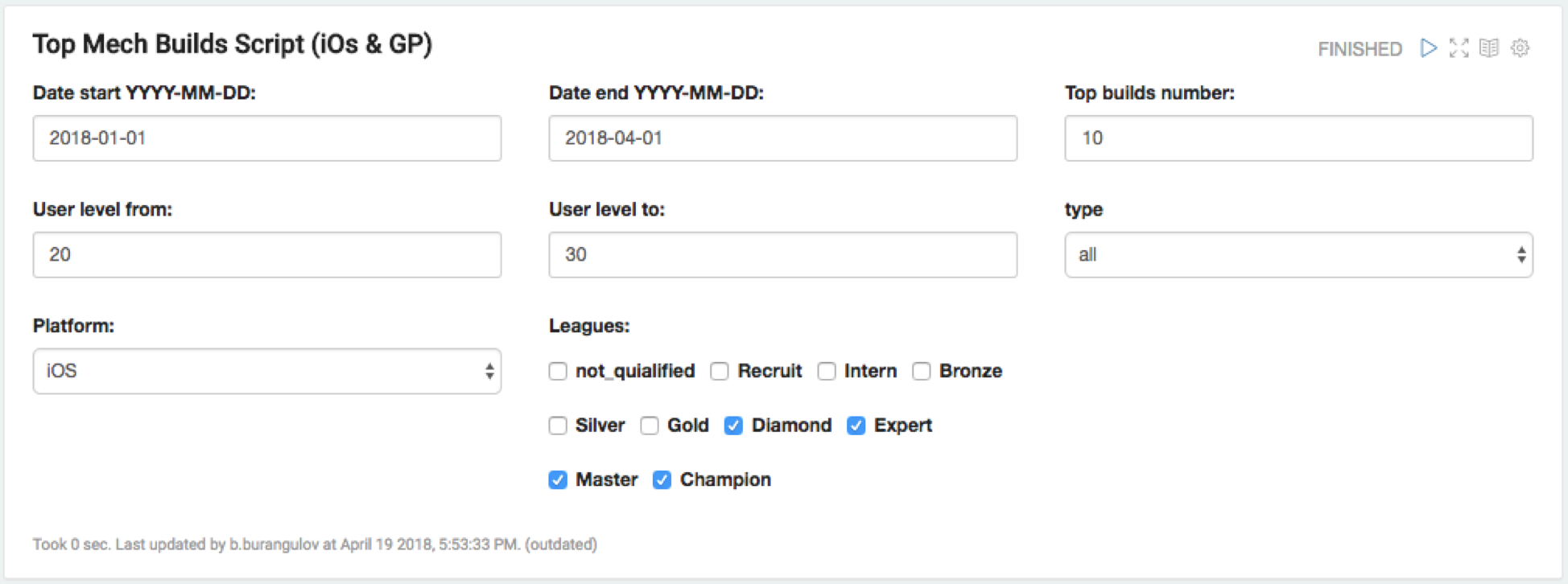
Что очень важно в этом моменте — так это то, что вся подготовка интерфейсов и настройка происходит исключительно силами самих аналитиков, без привлечения программистов (или, упаси боже, UX-ров).
Преимущества параллельных процессов
Zeppelin работает в несколько процессов, из чего вытекает интересный бонус — он позволяет запускать отдельный инстанс Python’а как для каждого ноутбука, так и для каждого юзера. Таким образом, без хитрых настроек можно запускать несколько объемных скриптов обработки параллельно — просто делая это в разных ноутбуках, и продолжать работу не дожидаясь завершения. Это работает и в случае локальной копии, а при разворачивании на сервере — так и вообще можно вынести часть вычислений с локальных компьютеров, выполняя их на сервере.

Встраивание параграфов в сайты
Если у вас развернут Zeppelin на сервере, то можно получить ссылку на любой из ваших параграфов (с результатами запроса или графиком) и опубликовать его как iframe на сайте (это делается очень просто, на сайте есть туториал). В практике аналитиков нечасто нужно публиковать какие-то результаты на внешних ресурсах, но это может быть очень удобно для добавления визуализаторов во внутренних сервисах (в том же Confluence). Так можно создавать отчеты, в которых есть интерактивные формы и визуализаторы прямо в тексте.
Self-describing reports
Поддержка markdown позволяет добавлять в дашборды, помимо графиков и таблиц, параграфы с форматированным текстом. В результате можно делать наглядные отчеты с описаниями, где пользователь сразу может посмотреть данные по какой-то проблеме, увидеть это все на графиках и прочитать интерпретацию результатов от аналитиков. В отличии от Jupyter’а, в котором также есть поддержка markdown, в Zeppelin делать интерактивные формы и визуализировать результаты получается намного быстрее, а результат получается более аккуратным и доступным для конечного пользователя, что немаловажно.
Таким образом, это быстрая и наглядная альтернатива обычным исследованиям аналитиков. Как правило, работа аналитиков строится так: аналитики получают задачу изучить какой-то аспект игры. Они готовят данные, проверяют гипотезы, визуализируют подтверждающие результаты, скажем, диаграммами и пишут отчет (например, в confluence). Это правильный, но довольно кропотливый процесс. В нашем же случае можно не тратя лишнего времени набросать ноутбук с этими самыми выгрузками и скриптами, тут же проиллюстрировать результаты графиками, а в соседних параграфах описать свои выводы:

Конечно, Zeppelin есть за что поругать, он все еще не всегда стабильно работает (все же это опенсорс), веб-интерфейс кушает много оперативной памяти, кому-то может не хватать функций полноценных IDE. Но уже есть ряд интересных юзкейсов, где он может быть полезен — потому он однозначно заслуживает внимания аналитиков (ну и, конечно, чем больше будет коммьюнити, тем лучше может он стать в перспективе).
Для небольших компаний он может стать основным инструментом, так как позволяет надстроить полноценную систему аналитики над базой данных. Для более крупных компаний с уже сложившимся инструментарием аналитики — полезным дополнением, который не заменит основную систему, но даст несколько полезных преимуществ.
Комментарии (17)

potan
24.06.2018 19:46Jupyter поддерживает многие языки, включая Scala и Julia. А в Zeppelin сложно такую поддержку добавлять?

lonely_luckily Автор
24.06.2018 19:56Не могу ответить на 100%, так как сам ни разу этим не занимался и подводных камней не знаю, но инструкция (ссылка) выглядит довольно простой.
strobegen
25.06.2018 16:09Scala поддерживается встроенным интерпритатором для Spark (но ограничена версией которую поддерживает сам Spark), посмотреть что есть можно тут zeppelin.apache.org/supported_interpreters.html
Надо сказать в Jupyter единственный более менее рабочий вариант использовать Scala это Apache Toree и там тоже не все идеально.
Stas911
24.06.2018 19:47Смотрел его несколько лет назад — был откровенно сырой, как сейчас с этим?
lonely_luckily Автор
24.06.2018 20:05Насколько могу судить, у нас довольно стабильно работает, функциональности под наши задачи хватает. Попробуйте ради интереса глянуть снова, вполне возможно стало лучше с тех пор.
Stas911
24.06.2018 23:39Я вообще Python и JupyterLab предпочитаю (или SparkNotebook, если для Spark/Scala), но надо будет глянуть
Bloxy
24.06.2018 20:18Сравнивали ли вы с другими альтернативами, например с SuperSet? Судя по картинкам они функционально похожи, и от того же Apache. И в этой категории есть также множество коммерческих продуктов — почему все таки Zeppelin?
Yo1
24.06.2018 20:31главная фишка зепелин — он работает с хадупом через spark, суперсет судя по описанию просто еще один визуализатор sql, поддержка hive или спарк даже не заявлена.
lonely_luckily Автор
24.06.2018 20:39+1Увы, подробно альтернативы мы не изучали, так как решение использовать Zeppelin было скорее стихийным, нежели запланированным. Дело в том, что у меня уже был опыт работы с ним (в связке с Impala), и мы в отделе немного поэкспериментировали с ним как со средой для запуска Python-скриптов. Ну и обнаружили пару способов упростить часть нашей рутины)
Конечно, на рынке есть более продвинутые коммерческие решения для подобных задач, с более богатой функциональностью. Но, как мне кажется, лаконичные опенсорсные решения могут быть полезны небольшим игровым студиям.
Stas911
24.06.2018 23:37Еще Zeppellin ставится почти автоматом на дистрибутивы Hadoop (одну гулку отметить) — тоже немаловажно для небольших фирм может быть
pphator
25.06.2018 12:16+1По-моему опыту, с точки зрения разработки Zeppellin вчистую уступает Jupyter. С точки зрения визуализации результата — Zeppellin выигрывает.
sshikov
Не, я понимаю, что вопрос «чем это лучше юпитера» сложный с неоднозначным ответом, но откровенно говоря, он остался нераскрытым. Пару плюсов привели, про минусы умолчали… В общем, какое-то незавершенное впечатление осталось.
lonely_luckily Автор
Вопрос и впрямь непростой)
По моему мнению, основные преимущества над Jupyter — это быстрая встроенная визуализация и возможность адаптировать ноутбук для пользователей, не связанных с аналитикой: набросать инструменты ввода встроенными командами, скрыть все блоки кода, переключить на вид отображения, в котором сложно что-либо сломать.
По поводу минусов — все же Jupyter как «IDE для питона» дает куда больше — хотя бы ту же автоподстановку.
sshikov
Согласен, сделать из ноутбука форму для конечного потребителя — идеологически это хорошая вещь.
Хотя у нас такое не приживается, в первую очередь наверное потому, что юпитер развернут на хадупе, и конечных пользователей туда не особо пускают, самые конечные пользователи — это Data Science, а от них скрывать код на питоне не требуется, они обычно и есть его авторы.
Присоединюсь к вопросу насчет скалы и спарка — пробовали?
lonely_luckily Автор
Ну да, вы правы, тут уже вопрос цели и того, кто будет пользоваться. Spark идет «из коробки», про написание интерпретаторов под другие языки ответил ниже.
igor_suhorukov
Спасибо за обзор, как раз решаем Jupyter или Zeppelin. Zeppelin менее матёрым кажется пока
frrrost
На стапелях Jupyter, кстати, уже давно готовится идейное продолжение — JupyterLab (https://blog.jupyter.org/jupyterlab-is-ready-for-users-5a6f039b8906)
Пока отличия по большей части интерфейсные — но с ним уже удобнее работать, чем с обычным Юпитером. Надеюсь, до расширенной и упрощенной визуализации данных «из коробки» руки тоже дойдут.
Ну и бонус для тех, кто уже успел поработать с Jupyter — старые ноутбуки открываются в новой оболочке без необходимости конвертации.